[Brainstorming] Computation Placement on NeuronCore Engines #941
Description
Hi,
I’m curious about the possibility of programming different computations on the various engines of NeuronCore, which consists of Tensor, Vector, Scalar, and GPSIMD Engines.
My interest was sparked by reading the Custom Operators API documentation, which mentions that Custom Operators C++code and data are specifically placed on the GPSIMD engine for computation (see in this Figure: https://awsdocs-neuron.readthedocs-hosted.com/en/latest/_images/ncorev2_gpsimd_memory.png). This made me wonder if similar capabilities exist for the other three engines: Tensor, Vector, and Scalar Engines.
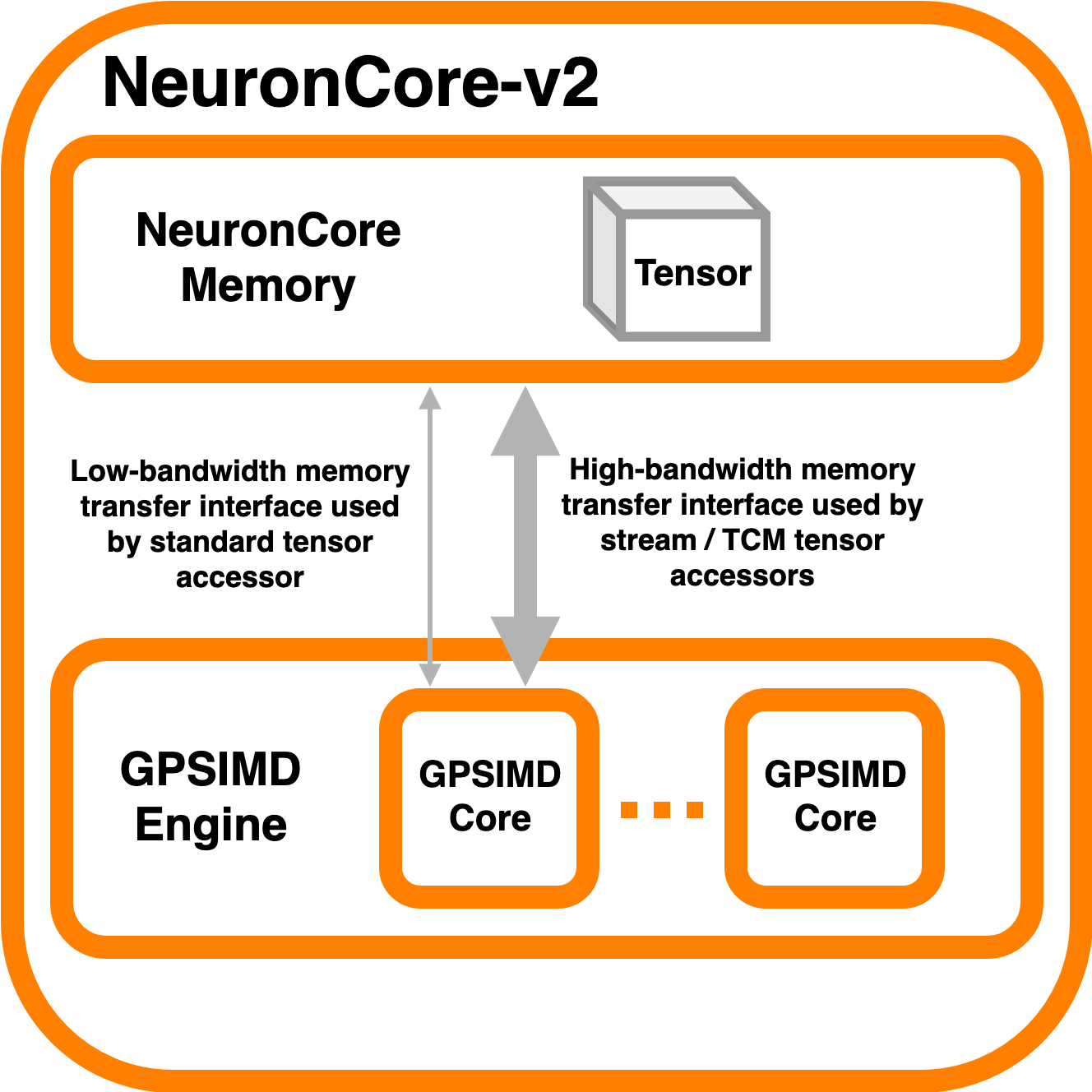{kind=link}
If this is possible, at which abstraction level can the placement over engines be programmed? Is it at the ML-framework level, XLA level, HLO-IR level, or even lower at the neuron-compiler level?
(I guess not at ML-framework-level, because computation in frameworks are not fully aware of execution device.)