Indirection in commands and queries
We can solve any problem by introducing an extra level of indirection – states the old adage. We will not explain how this rule drives deep learning, at least for now. Instead, let’s concentrate our effort on indirection in communication between services.
Each component operates its own domain model [DDD] which translates into objects and/or procedures convenient for use in the component’s subdomain. However, should a system cover multiple subdomains, the best models for its parts to operate start to mismatch. Furthermore, they are likely to diverge progressively over time as requirements heap up and the project matures.
If we want for each module or service to continue with a model that fits its needs, we have to protect it from the influence of models of its neighbor components by employing indirection – a translator – between them.
In a system of subdomain-dedicated Services a service may need to operate entities that are defined in another service’s subdomain. For example, the financial and recruiting departments’ software operates employees, but the employee data which each department needs is different. Moreover, it also differs from the employee records in the HR department which is responsible for adding, editing, and discarding the employees. We don’t want our accountants to spend their nights seeking the correlation between salaries, birthday horoscopes from HRs, and MBTI test scores from the recruiters.
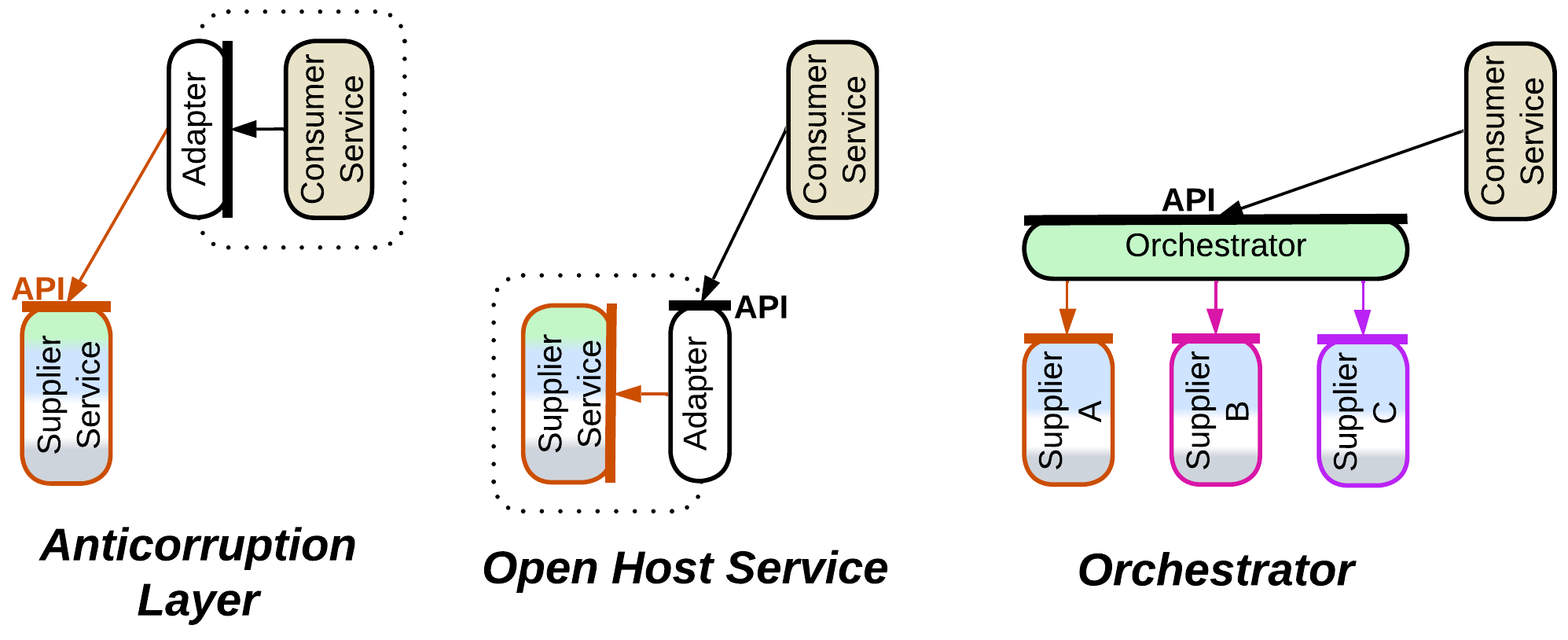
More often than not our system consists of services that command each other: via RPCs, requests, or even notifications – no matter how, one component makes a call to action which other(s) should obey.
In such a case we employ an Adapter between two services, or an Orchestrator when cooperation of several services is needed to execute our command:
- An Anticorruption Layer is an Adapter on the dependent service’s side: as soon as we call another service, we start depending on its interface, while it is in our interest to isolate ourselves from its peculiarities and possible future changes. Thus we should better write and maintain a component to translate the foreign interface, defined in terms of the foreign domain model, into terms convenient for use within our code. Even if we subscribe to notifications, we may also want to have an Adapter to transform their payload.
- An Open Host Service resides on the other side of the connection – it is an Adapter that a service provider team installs to hide the implementation details of their service from its users. It will typically translate from the provider’s domain model into a more generic (subdomain-agnostic) interface suitable for use by services that implement other subdomains.
- An Orchestrator (which can be an API Composer, Process Manager, or Saga Orchestrator) spreads a command to multiple services, waits for each of them to execute its part, and cleans up after possible failures. It tends to be more complex than other translators because of the coordination logic involved.
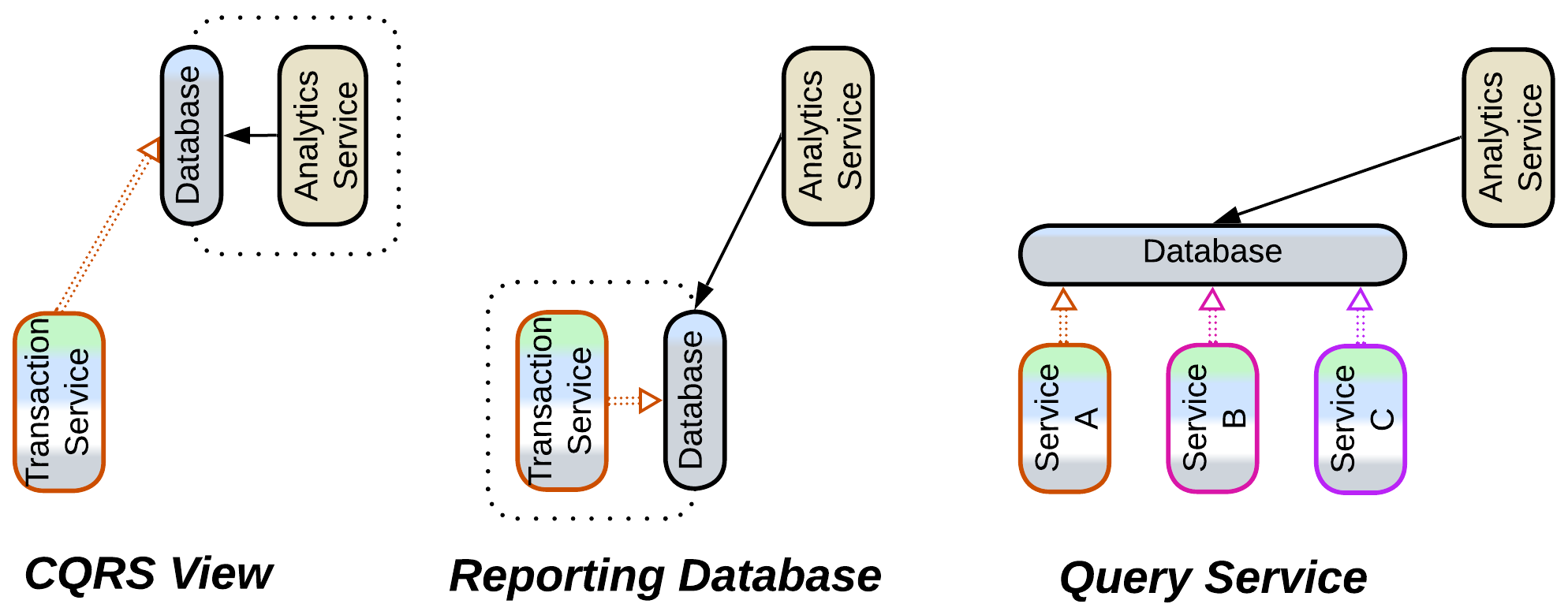
There is often another aspect of communication in a system, namely, information collection and analysis. And it runs into a different set of issues which cannot be helped by mere interface translation.
Each service operates and stores data in its own format and schema which matches its domain model, as discussed above. When another service needs to analyze the foreign data according to its own domain model, it encounters the fact that the foreign format(s) and schema(s) don’t allow for efficient processing – in the worst case it would have to read and re-process the entire foreign service’s dataset to execute its query.
The solution employs an intermediate database as a translator from the provider’s to the consumer’s preferred data access mode, format, and schema:
- A CQRS View resides in the data consumer and aggregates the stream of changes published by the data provider. This way the consumer can know whatever it needs about the state of the provider without making an interservice call.
- Data Mesh is about each service exposing a general-use public interface for streaming and/or querying its data. Maintaining one often requires the service to set up an internal Reporting Database.
- A Query Service aggregates streams from multiple services to collect their data together, making it available for efficient queries (joins).
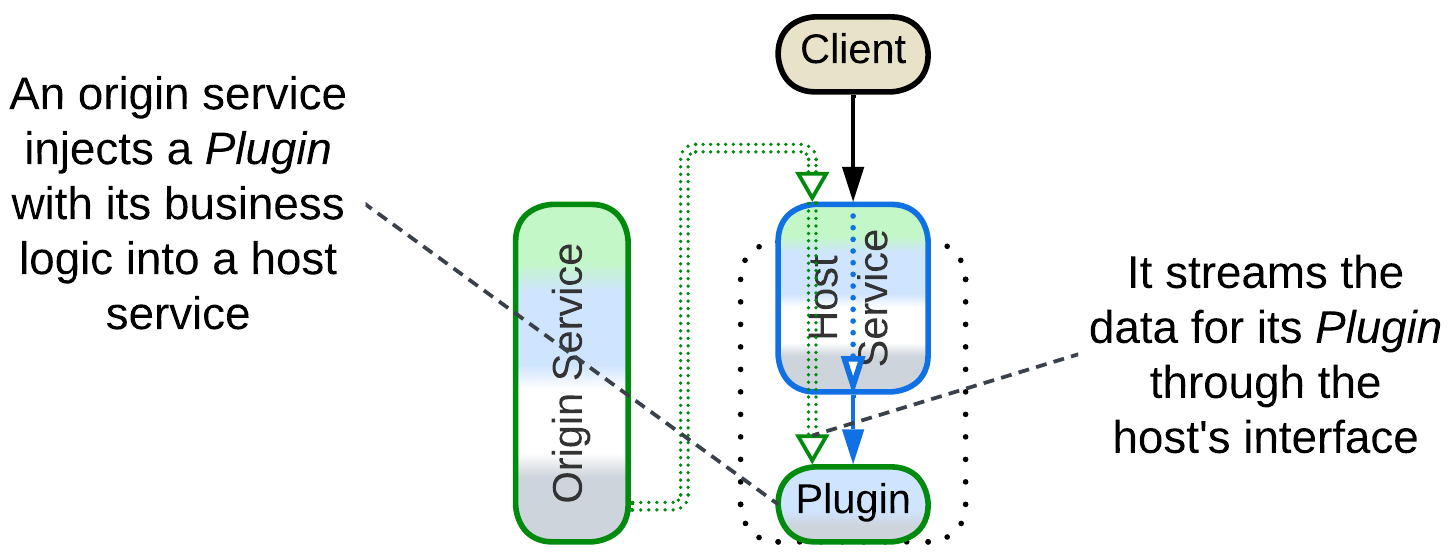
Ambassador Plugins (called Extensions by Uber) employ both logic and data indirection. When a service needs to modify the behavior of another service, it both writes a Plugin for the target service and extends its domain events stream with opaque data fields which the newly created Plugin can operate without consulting its origin service. The host (Plugin’s target) service passes the extra data fields to the Plugin which processes them and stores the data it needs in a dedicated table in its host’s database.
When the service with Plugins has to make a decision, it calls every registered Plugin as a part of its workflow. The Plugin reads the data it saved to its host’s database, processes it according to the business rules or its origin subdomain, and returns results – without any slow and failure-prone interservice calls!
We see that though command-dominated (operational or transactional) and query-dominated (analytical) systems differ in their problems, the architectural solutions which they employ to decouple their component services match perfectly:
- Anticorruption Layer or CQRS View is used on the consumer’s side,
- Open Host Service or Data Mesh’s Reporting Database is on the provider’s side,
- Orchestrator or Query Service coordinates multiple providers.
Which shows that the principles of software architecture are deeper than the CQRS dichotomy itself.
| << Dependency inversion in architectural patterns | ^ Comparison of architectural patterns ^ | Ambiguous patterns >> |
|---|
Analytics
Appendices
- Acknowledgements
- Books referenced
- Copyright
- Disclaimer
-
Evolutions of architectures
- Evolutions of a Monolith that lead to Shards
- Evolutions of a Monolith that result in Layers
- Evolutions of a Monolith that make Services
- Evolutions of a Monolith that rely on Plugins
- Evolutions of Shards that share data
- Evolutions of Shards that share logic
- Evolutions of Layers that make more layers
- Evolutions of Layers that help large projects
- Evolutions of Layers to improve performance
- Evolutions of Layers to gain flexibility
- Evolutions of Services that restructure services
- Evolutions of Services that add layers
- Evolutions of a Pipeline
- Evolutions of a Middleware
- Evolutions of a Shared Repository
- Evolutions of a Proxy
- Evolutions of an Orchestrator
- Evolutions of a Sandwich
- Format of a metapattern
- Glossary
- History of changes
- Index of patterns
- Martin Fowler's Bliki
- Software Architecture Chronicles
- Patterns and Principles
- UI and UX Patterns
- Enterprise Integration Patterns
- Microservices Patterns
- Gang of Four Design Patterns
- Game Programming Patterns
- PLoP Archive
- Metapatterns website
