OptimizedInboxTextEncoder's ctor makes it impossible to allow '+' despite UTF-7's removal #65130
Description
Description
System.Text.Encodings.Web prohibits 5 HTML-specific characters from being non-encoded in the 3 encoder subclasses included in the package (HtmlEncoder, JavaScriptEncoder, and UrlEncoder).
The '+' character is included for reasons relating to UTF-7, but UTF-7 support was dropped by .NET in .NET 5.0, thus rendering the necessity of this escape questionable, imo.
However the actual problem that I'm experiencing is that it is currently impossible to override this and re-allow '+' when using any of the System.Text.Encodings.Web.TextEncoder subclasses; this is because the internal type OptimizedInboxTextEncoder always calls ForbidHtmlCharacters() after it processes the allow-list from the user-supplied TextEncoderSettings object.
This is a problem for me because I need to render HTML without HTML-entitizing any '+' characters (in my case, for compatibility with downstream software that expects + to be rendered literally, but in principle, I've come to expect escape-hatches in .NET for problems like this).
None of the documentation for TextEncoderSettings states that HTML character escapes cannot be overridden. The AllowCharacter method documentation lists no caveats.
I do see the HtmlEncode_AllRangesAllowed_StillEncodesForbiddenChars_Extended test-case does test that + is encoded with HtmlEncoder.Create(UnicodeRanges.All); but this does not consider explicit calls to AllowCharacter('+').
Reproduction Steps
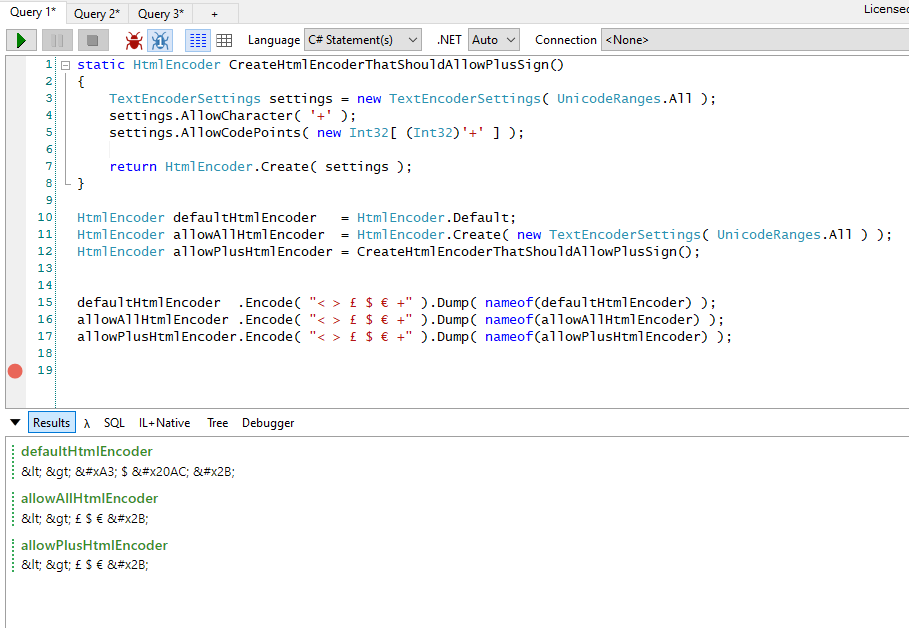
This is a test-case I ran in Linqpad 7, targeting .NET 6, including NuGet package System.Text.Encodings.Web version 6.0.0 (the latest version as of 2022-02-10).
static HtmlEncoder CreateHtmlEncoderThatShouldAllowPlusSign()
{
TextEncoderSettings settings = new TextEncoderSettings( UnicodeRanges.All );
settings.AllowCharacter( '+' );
settings.AllowCodePoints( new Int32[ (Int32)'+' ] ); // Just to make sure...
return HtmlEncoder.Create( settings );
}
HtmlEncoder defaultHtmlEncoder = HtmlEncoder.Default;
HtmlEncoder allowAllHtmlEncoder = HtmlEncoder.Create( new TextEncoderSettings( UnicodeRanges.All ) );
HtmlEncoder allowPlusHtmlEncoder = CreateHtmlEncoderThatShouldAllowPlusSign();
defaultHtmlEncoder .Encode( "< > \" £ $ € +" ).Dump( nameof(defaultHtmlEncoder) );
allowAllHtmlEncoder .Encode( "< > \" £ $ € +" ).Dump( nameof(allowAllHtmlEncoder) );
allowPlusHtmlEncoder.Encode( "< > \" £ $ € +" ).Dump( nameof(allowPlusHtmlEncoder) );
I get this output:
defaultHtmlEncoder:
"< > " £ $ € +"
allowAllHtmlEncoder:
"< > " £ $ € +"
allowPlusHtmlEncoder:
"< > " £ $ € +"
Expected behavior
I expect TextEncoder.Create to respect TextEncoderSettings.AllowCharacters over its internal defaults.
Actual behavior
'+' characters are always escaped and this cannot be overridden by consumers.
Regression?
No response
Known Workarounds
No response
Configuration
- .NET 6, .NET 5, .NET Core 3.1, .NET Framework 4.8
- Windows 10 20H2
- x64
- Issue is not specific to configuration.
Other information
No response