Conversation
cc8183d to
341b5fa
Compare
2e72678 to
5d2d57e
Compare
|
@mrambacher could you please review this PR? thanks! |
|
If we took the space spent on reverse links and instead dedicated that to reducing load factor on the hash table, how much speed improvement is seen? Btw, we know a lot of improvement in LRUCache should be possible, especially because it uses a lot of unpredictable branching and indirection. |
 mrambacher
left a comment
mrambacher
left a comment
There was a problem hiding this comment.
So I ran some performance tests via db_bench (seekrandom, readrandom) using these changes. The performance improvement is about 1%.
Perf runs of the new versus original code shows:
New:
3.86% 0.12% ShardedCache::Insert
3.52% 0.13% LRUCacheShard::Insert
3.01% 0.02% LRUCacheShard::Lookup
2.83% 2.83% LRUHandleTable::FindPointer
1.66% 0.27% LRUCacheShard::EvictFromLRU
1.34% 1.34% LRUCacheShared::LRU_Remove
Original:
4.53% 0.13% ShardedCache::Insert
4.13% 0.15% LRUCacheShard::Insert
2.00% 0.02% LRUCacheShard::Lookup
2.31% 2.31% LRUHandleTable::FindPointer
1.99% 0.10% LRUCacheShard::EvictFromLRU
1.34% 1.34% LRUCacheShared::LRU_Remove
Note that in this test, perf is showing most of the time is in ZSTD compression.
I think making a change like this is probably worthwhile, but I wonder if the same thing can be accomplished without the extra "prev" pointer. For example, what if FindPointer would return both the current and prev entry -- could you accomplish the same thing? The size of the metadata for the cache entry should be kept to a minimum.
Have you done any experiments or calculations that show how the change in the metadata size affects the number of entries that can be stored in the cache? Are items evicted more frequently and at what rate/size?
I support this performance improvement, but would like to better understand the tradeoffs we are making here.
|
|
||
| namespace ROCKSDB_NAMESPACE { | ||
|
|
||
| class LRUHandleTableTest : public testing::Test {}; |
There was a problem hiding this comment.
Is there a reason not to put these tests in the existing lru_cache_test file?
There was a problem hiding this comment.
Just want to keep these tests independent, lru_cache_test for LRUCacheShard and cache_hash_table_test for internal LRUHandleTable.
|
Do we supposed to resize the hash table to more than 1.5 X number of elements? There aren't supposed to be many hash table buckets with more than 1-2 elements, right? Can you measure how frequently we remove an elements that is in the third position or lower in your test that shows the improvement? |
For kicks, I am running some experiments now to test this out using the seekrandom test. I can see the depth of the list reaching 8 deep. Here is a couple samples of the depths. Each element in depth represents a count of how many lists had that depth for a given table (e. g., the first table had 2981 lists with no elements, 3062 with 1, 1511 with 2, etc). So a rough estimate is that 8-10% of the lists within a table have a depth of >=3 and 2% of the lists have a depth >= 4. |
Interesting. If we change these two thresholds: https://github.com/facebook/rocksdb/blob/master/cache/lru_cache.cc#L73-L75 and https://github.com/facebook/rocksdb/blob/master/cache/lru_cache.cc#L44 to keep the hash table larger, what would be the result? |
|
Another interesting point is that there is approximately 35% of the lists that contain no elements. From my print statements, it appears as if that percentage stays roughly constant as the size of the list increases (as more elements are added to the cache). |
Seems not possible to implement it like that, I aim to reduce list iteration when call |
8 bytes of
|
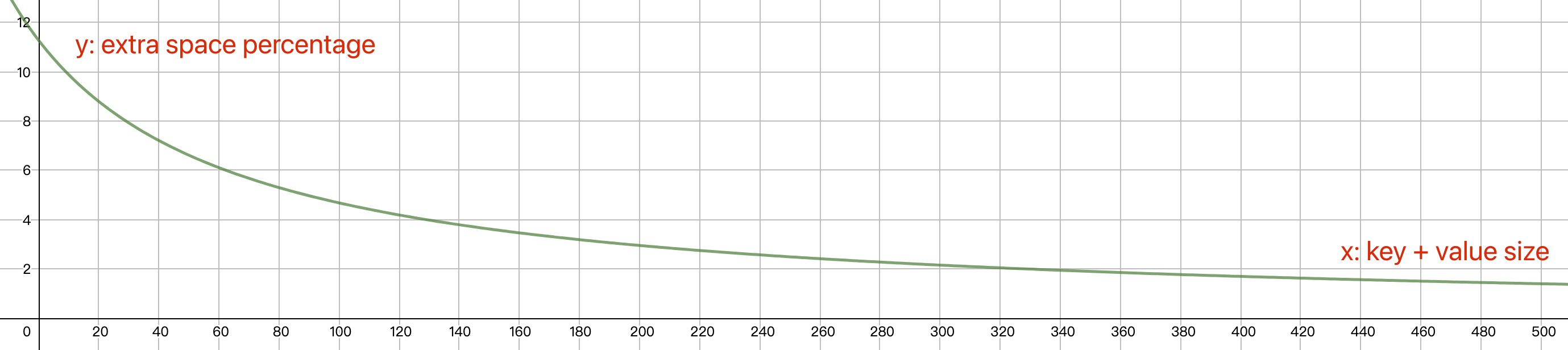
When LRUCache insert and evict a large number of entries, there are
frequently calls of LRUHandleTable::Remove(e->key, e->hash), it will
lookup the entry in the hash table. Now that we know the entry to
remove 'e', we can remove it directly from hash table's collision list
if it's a double linked list.
This patch refactor the collision list to double linked list, the simple
benchmark CacheTest.SimpleBenchmark shows that time cost reduced about
18% in my test environment.