Gecoscc:sistemas

El centro de control de GECOS o GECOS Control Center (GCC) es un sistema complejo que tiene varios componentes que iremos comentando a continuación.
La filosofía de este sistema es conseguir que el administrador pueda gestionar un árbol de nodos (estaciones de trabajo, usuarios, unidades organizativas, grupos, impresoras, repositorios y almacenamientos remotos) de manera sencilla y rápida.
GCC proporciona gestión de usuarios (pestaña de administradores), una sección de informes, y la aplicación principal desde la cual se gestiona el árbol. En esta sección nos centraremos en esta última aplicación dado que ambas otras dos carecen de complejidad.
Es el componente más importante del centro de control.
Aunque toda web tiene un front-end y un back-end, en este sistema la separación es más notable dado que que el front-end no es un sistema simple que se usa para visualizar los datos, sino que en front-end se encierra una aplicación la cual se comunica mediante Ajax con el back-end. Opcionalmente también existe una comunicación inversa mediante WebSockets desde el back-end hacia el front-end.
Es una aplicación javascript la cual usar el framework backbone con marionette desde la cual se nos presenta un árbol paginado de diferentes tipos de nodos. Los nodos que pueden tener hijos son solo las unidades organizativas y dominios (unidades organizativas de primer nivel), el resto de tipos de nodos solo pueden ser nodos hojas.
Además de esta clasificación existen nodos activos y nodos pasivos. Los nodos activos (estaciones de trabajo, usuarios, unidades organizativas y grupos) son susceptibles de añadirles una política, los nodos pasivos (repositorios de software, impresoras y almacenamientos remotos) podrán ser parámetros de algunas de estas políticas.

El fron-end intenta ser lo más autónomo posible, es decir intenta que un usuario administrador pueda añadir, modificar y borrar nodos, añadir y eliminar políticas sin tener que realizar peticiones (salvo peticiones de lectura: GET) al back-end. Con lo que conseguimos poder modificar muchos nodos de una manera muy rápida, ya que todo se va almacenando en el navegador. Cuando el administrador ha terminado debe darle al botón "aplicar cambios" que se encuentra arriba a la derecha y todos los cambios que éste haya realizado se ejecutarán en lotes.
El backend que usa el centro de control está desarrollado en pyramid, un framework escrito en python.
Este se encarga de insertar, modificar y borrar objectos de la base de datos y de comunicarse con otros componentes. Este backend tiene una serie de APIs, la mayoría para comunicarse con el front-end, pero también tiene otras para comunicarse con el gestor de colas, Gecos Config Assistant (GCA), con el agente Gecos Chef Snitch (GCS), con el servidor de Chef y con los sistemas de sincronización.
Cuando el back-end habla con el front-end se ayuda del gestor de colas para que el front-end espere lo mínimo posible. Por ejemplo si un administrador añade una política a una unidad organizativa, la cual contiene 1000 estaciones de trabajos, el GCC tendrá que escribir en mil nodos chef. El tiempo de realizar las 1000 modificaciones puede ser muy alto, con lo que el backend solo guarda la política en la unidad organizativa y crea una tarea que haga ese trabajo.
La base de datos elegida es mongodb. Ha sido elegida esta base de datos no relacional por los siguientes motivos:
- Es un motor de base de datos muy sencillo de escalar. Este es un proyecto pensado para una gran corporación con una flota muy grande de estaciones de trabajo, por lo que necesita poder crecer fácilmente.
- Es un motor muy rápido, con lo que tanto por el anterior punto como por este evitamos que la base de datos sea un cuello de botella.
- Los documentos (equivalentes a registros en SQL) de una colección (equivalentes a tablas en SQL) no tienen que tener los mismos campos. Dada la singularidad de nuestro entorno en la que hay 7 tipos de nodos diferentes, las consultas y el esquema de la base de datos (en mongo no hay esquema propiamente dicho) se simplifican mucho.
Mongodb es un sistema muy sencillo de usar. Ejemplos de algunas búsquedas, modificaciones, y borrados:
Todos los nodos:
db.nodes.find() // Para avanzar escribir it
Búsqueda de un nodo por su id
// Las búsquedas se realizan mediante un objecto JSON
db.nodes.find({_id: ObjectId("5375c99400251c1a1f726de4")}) // Id obtenido de la URL del GECOSCC
Búsqueda de un nodo por su nombre
db.nodes.find({name: "My computer"})
Búsqueda de todos los nodos que cuelgan de una unidad organizativa
// 5368a26500251c1c2f0db19c es el Id de la unidad organizativa
db.nodes.find({path: {"$regex": ".*5368a26500251c1c2f0db19c.*"}}
)
Actualización de un nodo
// El primer parámetro es un objecto JSON como los anteriores, indica a quien va afectar la actualización
// El segundo es el nuevo objeto en mongo, o si se indica la opción $set solo
// cambiará los campos que se indiquen
db.nodes.update({_id: ObjectId("5368a26500251c1c2f0db19c")}, {"$set": {address: "My address"}}
)
Borrado del historial de tareas
db.jobs.remove({})
Borrado del historial de tareas del administrador con nombre de usuario admin
db.jobs.remove({administrator_username: "admin"})

El gestor de colas utilizado es Celery. Celery es un gestor para realizar tareas asíncronas escrito en Python.
Gracias a este gestor de colas conseguimos realizar tareas muy costosas en tiempo sin bloquear al usuario final. Este gestor de colas se usa cuando el back-end habla con el servidor Chef.
Los resultados de estas tareas aparecen en el recuadro de "Mis tareas", abajo a la izquierda. No confundir tareas de celery con este historial de tareas. Una tarea de celery puede crear y/o actualizar una, varias o ninguna tarea de las que aparece en "mis tareas".
Chef es una herramienta de gestión de la configuración escrita en Ruby y Erlang. Con esta herramienta y un conjunto de cookbooks (los cuales cada uno contienen un conjunto de recetas) conseguimos configurar una flota de estaciones de trabajo.
Cada una de las estaciones de trabajo que aparecen en el GCC (siempre que estén vinculadas) corresponde con un nodo en el servidor chef. En este nodo chef se aplana la configuración de la estación de trabajo. Es decir, si tenemos una estación de trabajo que recibe políticas de su unidad organizativa padre, de su unidad organizativa abuelo, de un par de usuarios y de un grupo; en el nodo chef tendrá todas esas políticas aplicadas, sin embargo en el centro de control cada política se guardará en donde nosotros la hemos añadido.
Cada cierto tiempo un agente llamado Gecos Chef Snitch (GCS)se ejecutará en el puesto, sincronizando este con los valores guardados en Chef y ejecutando una serie de recetas con lo que todos los equipos quedarán siempre configurados tal como el administrador haya decidido.
Alta disponibilidad (High Availability) es un protocolo de diseño del sistema y su implementación asociada que asegura un cierto grado absoluto de continuidad operacional durante un período de medición dado.
Cualquier sistema informático posee puntos de fallo en su arquitectura. Estos puntos de fallos son aquella piezas de software o hardware que son responsables de una tarea concreta. Si esta pieza de software o hardware falla el sistema se resiente y puede llegar a la inoperatiblidad.
Para asegurar la alta disponibilidad en un sistema es fundamental conocer los posibles puntos de fallos de su arquitectura, de esta forma podemos analizar la pieza de software o hardware y averiguar cual es la forma óptima para asegurar la integridad y funcionamiento del sistema.
La técnica más habitual para asegurar la alta disponibilidad de un servicio es la de dotar de redundancia a sus elementos. Es decir si detectamos que un posible punto de fallo es una pieza concreta de software o hardware, añadiremos al menos una pieza exactamente igual a la anterior para que esta recoja el testigo de dar servicio en el caso de que la primera se vea afectada por un fallo.
En nuestro caso vamos a tener una o varias pilas de servicios completas del sistema, de tal forma que si una de ellas cae, otra le releve el servicio.
Para conseguir esto debemos asegurarnos de dos puntos fundamentales:
- Todas las pilas deben tener el mismos software con la misma versión.
- Los datos deben estar replicados en todas las pilas.
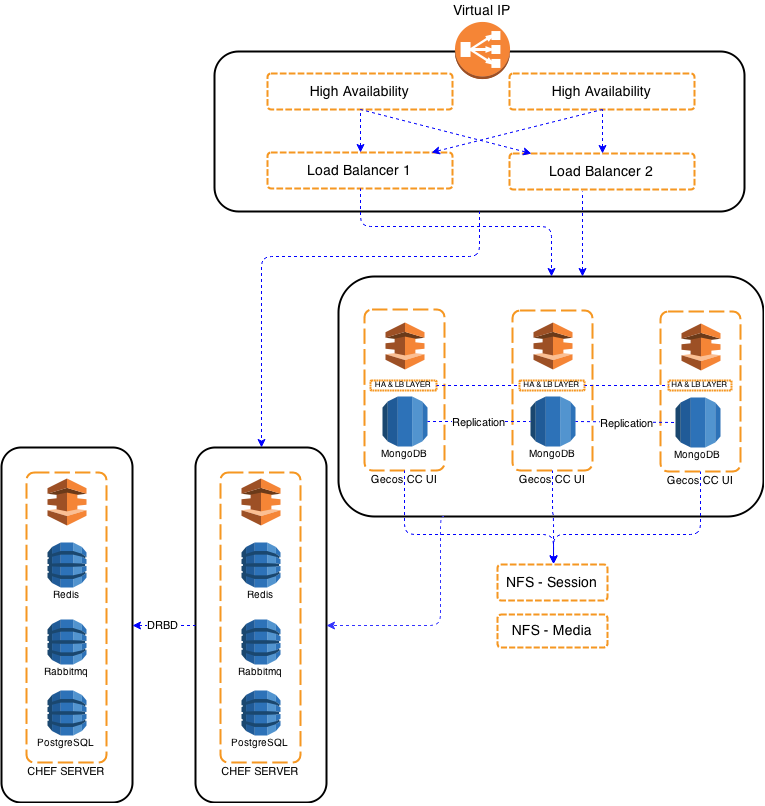
Para conseguir esto vamos a utilizar las herramientas KeepAlived, DRBD, HaProxy.
El proceso de instalación lo fragmentaremos en tres bloques, el primero es nuestro punto de entrada y estará compuesto por Keepalived y Haproxy, el segundo es el software Gecos CC UI, y el tercero Chef Server.
KeepAlived es una aplicación basada el uso de protocolo VRRP, simulando un router virtual que recepcionará las peticiones y las enrutará donde le establezcamos en su configuración. Esta configuración se caracteriza por ser sencilla y fácil de entender. Su tolerancia a fallos reside en el balanceo de las direcciones flotantes que le establezcamos entre los nodos que compongan el cluster.
En sistemas de paquetería RPM:
- yum install -y keepalived
En sistemas de paquetería DEB:
- apt-get install -y --no-install-recommends keepalived
Cuando configuremos Keepalived debemos establecer cuantos nodos compondrán el cluster de balanceo y la prioridad que cada uno de ellos tendrá. Para nuestra configuración estableceremos dos nodos. Antes de empezar a realizar cambios, hagamos una copia del archivo /etc/keepalived/keepalived.conf
/etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
interface eth0
state MASTER
virtual_router_id 51
priority 101 # 101 on master, 100 on backup
authentication {
auth_type PASS
auth_pass keepmesynced
}
virtual_ipaddress {
10.10.10.110/24 dev eth0 label eth0:ha
}
track_script {
#chk_iptables
}
}
En todos los nodos implicados, debemos insertar la siguiente línea en el archivo /etc/rc.local
echo 1 > /proc/sys/net/ipv4/ip_nonlocal_bind
Haproxy es una aplicación incluida en la mayoría de las distribuciones, que entre sus principales características destaca su velocidad y fiabilidad. El servicio ofrece a todos los usuarios un proxy TCP y HTTP de alta disponibilidad con control de balanceo de carga.
En sistemas de paquetería RPM:
- yum install -y haproxy
En sistemas de paquetería DEB:
- apt-get install -y haproxy
Cuando configuremos Haproxy debemos definir un frontend y un backend con los nodos que compondrán el cluster de balanceo. Para nuestra configuración estableceremos dos nodos. Antes de empezar a realizar cambios, hagamos una copia del archivo /etc/haproxy/haproxy.cfg
/etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local0 debug
maxconn 10000
user root
group root
daemon
defaults log global mode tcp retries 3 maxconn 6000 timeout connect 30000 timeout client 1h timeout server 1h
frontend gecos-loadbalancer bind 10.10.10.110:80 monitor-net 127.0.0.1/32 default_backend gecos-loadbalancer
backend gecos-loadbalancer mode http balance roundrobin http-check disable-on-404 http-check expect string bootstrap-admin-without-padding option httpchk GET /login/ HTTP/1.1\r\nHost:\ dominio.junta-andalucia.es cookie session prefix indirect nocache server gecos1 10.10.10.201:80 check cookie gecos1 server gecos2 10.10.10.202:80 check cookie gecos2
Configuración de logs para haproxy
Crear el archivo /etc/rsyslog.d/haproxy.conf con el siguiente contenido
$ModLoad imudp
$UDPServerRun 514
$template Haproxy,"%msg%\n"
local0.=info -/var/log/haproxy.log;Haproxy
local0.notice -/var/log/haproxy-status.log;Haproxy
local0.* ~
Reiniciar el servicio rsyslog
/etc/init.d/rsyslogd restart
Chef Server tiene un único modo para garantizar un sistema de alta disponibilidad, éste modo es crear un espejo del sistema mediante DRBD, que nos garantizará la sincronización en tiempo real entre nodos del cluster. El escenario que describe este manual está compuesto por dos nodos Chef Server con DRBD. En este supuesto, el nodoA tiene IP 10.10.10.210 y el nodoB 10.10.10.211
Descargaremos el script de instalación y realizaremos un cambio en una línea para excluir la instalación del Gecos CC UI
Original: run_list": [ "run_list": [ "recipe[gecoscc-chef-server]","recipe[gecosccui]" ],
Modificada: run_list": [ "run_list": [ "recipe[gecoscc-chef-server]" ],
Otorgar permisos de ejecución y lanzar la instalación, sólo en el NodoA:
chmod 755 gecoscc-chef-server-install.sh
./gecoscc-chef-server-install.sh
Cuando finalice el proceso de instalación en el NodoA, apagaremos este nodo. Ahora asignaremos temporalmente la IP del NodoA al NodoB y comenzaremos con la instalación en el NodoB, es muy importante que la instalación se efectúe en ambos con la misma IP. Tras la finalización del proceso de instalación en el NodoB, pararemos los servicios y restablecer la IP original 211.
chef-server-ctl stop
Arrancar el NodoA y verificar que los servicios de chef server arrancan correctamente.
En este punto, tenemos dos nodos independientes, el NodoA está iniciado con los servicios en ejecución y el NodoB con los servicios detenidos.
DRBD. Es un servicio que se encarga de mantener una réplica exacta entre varias particiones de distintos servidores. De esta forma los datos están siempre presentes y actualizados en todos los servidores.
En sistemas de paquetería RPM:
Agregamos el repositorio "elrepo" para instalar DRBD
rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
yum install drbd84-utils kmod-drbd84 -y
Es muy importante que la relación IP servidor no se rompa, para ello lo establecemos en el archivo /etc/hosts:
IP_SERVIDOR_1 hostname_servidor_chef_1
IP_SERVIDOR_2 hostname_servidor_chef_2
Desactivar SELINUX e iptables (ambos nodos)
setenforce 0
Editar el archivo /etc/sysconfig/selinux y establecer:
SELINUX=disabled
/etc/init.d/iptables stop chkconfig --del iptables
Cargar módulo (probar que al reiniciar se mantiene)
modprobe drbd
Reiniciar para comprobar que el módulo se carga correctamente
shutdown -r now
En sistemas de paquetería DEB:
- apt-get install -y --no-install-recommends drbd8-utils drbd8-module
apt-get install drbd8-utils
Usaremos un disco para crear una partición dedicada a la replicación y almacenamiento de los datos (ambos nodos) (n, p, 1, w)
fdisk -cu /dev/sdX
En el fichero de configuración de drbd incluimos:
include "drbd.d/cluster_db.res";
En todos los servidores creamos el archivo /etc/drbd.d/cluster_db.res
resource r0 {
startup {
wfc-timeout 30;
outdated-wfc-timeout 20;
degr-wfc-timeout 30;
become-primary-on hostname_chef_server_1;
}
net {
cram-hmac-alg sha1;
shared-secret sync_disk;
}
syncer {
rate 10M;
al-extents 257;
on-no-data-accessible io-error;
}
on hostname_chef_server_1 {
device /dev/drbd0;
disk /dev/sdXN;
address IP_chef_server_1:7788;
flexible-meta-disk internal;
}
on hostname_chef_server_2 {
device /dev/drbd0;
disk /dev/sdXN;
address IP_chef_server_2:7788;
meta-disk internal;
}
}
Copiarlo exactamente igual a los demás nodos:
scp /etc/drbd.d/clusterdb.res 10.10.10.207:/etc/drbd.d/
scp /etc/hosts 10.10.10.207:/etc/
iciar discos (ambos nodos)
dd if=/dev/zero of=/dev/sdb1 (Esto no hace falta, pero se puede hacer)
drbdadm create-md r0
Iniciar el servicio y conectar la unidad DRBD
/etc/init.d/drbd restart
drbdadm attach r0
drbdadm connect r0
SOLO en el nodo PRIMARIO (elegir uno de los dos)
drbdadm -- --overwrite-data-of-peer primary all
Comprobar el estado del raid
cat /proc/drbd
Paramos los servicios chef en ambos nodos
chef-server-ctl stop
chef-server-ctl kill
Dar formato a la unidad (nodo primario)
mkfs.ext4 /dev/drbd0
mkdir /var/replica (ambos nodos)
mount /dev/drbd0 /var/replica
Almacenamos los datos en la partición réplica (debemos llevar a cabo este paso en ambos nodos, pero sólo podrá hacerse cuando éste nodo tenga la partición “primaria”, en otro caso no permite el montaje de la unidad. Por ahora se hará en el nodo que esté como primario.
cp -a /var/opt/chef-server /var/replica/chef-server #(SOLO nodo prinpial)
rm -fr /var/opt/chef-server #(ambos nodos)
ln -s /var/replica/chef-server /var/opt/chef-server #(ambos nodos)
Podemos iniciar de nuevo chef-server
chef-server-ctl start
podemos ver el estado de la sincronización en
cat /proc/drbd
Ahora en todos los servidores creamos el sistema de archivos y guardamos en el todos los datos del sistema
#paramos los servicios
chef-server-ctl stop
chef-server-ctl kill
#montamos el sistema de archivos
mkfs.ext4 /dev/drbd0
mkdir /var/replica
mount /dev/drbd0 /var/replica
#almacenamos los datos en la partición de replica
cp -a /var/opt/chef-server /var/replica/chef-server
rm -fr /var/opt/chef-server
ln -s /var/replica/chef-server /var/opt/chef-server
Si en algún momento el sistema principal sufre una caída, el NodoB debe asumir que será el principal, permitiendo así el montaje de la unidad de chef-server donde está la información replicada.
drbdadm -- --overwrite-data-of-peer primary all
mount /dev/drbd0 en /var/opt/chef-server
En el punto componentes_del_centro_de_control hemos definido cada una de las partes que componen el centro de control, serán varios de estos componentes los que debemos modificar para permitir el uso del servicio en alta disponibilidad con balanceo de carga. Para empezar definimos un mínimo de 3 nodos, que viene fijado por [MongoDB(http://www.mongodb.org), que requiere un nodo Primario, otro secundario y un árbitro para la configuración Replication Set que vamos a usar.
Descargaremos el script de instalación y realizaremos un cambio en una línea para excluir la instalación del servidor Chef
Original: run_list": [ "run_list": [ "recipe[gecoscc-chef-server]","recipe[gecosccui]" ],
Modificada: run_list": [ "run_list": [ "recipe[gecosccui]" ],
Otorgar permisos de ejecución y lanzar la instalación:
chmod 755 gecoscc-chef-server-install.sh
./gecoscc-chef-server-install.sh
Este proceso se llevará a cabo en todos los nodos GecosCC UI
Para dar las máximas garantías en la configuración, MongoDB debe tener visibilidad entre todos los nodos que formarán parte del replicationSet; el mejor modo para garantizar para ello introduciremos en el /etc/hosts de los componentes del cluster sus direcciones IP y nombre de máquina.
10.10.10.151 mongodb1
10.10.10.152 mongodb2
10.10.10.153 mongodb3
**Adaptar los nombres de los sistemas implicados
Agregar el repositorio para la instalación de MongoDB e instalar el software:
vi /etc/yum.repos.d/mongodb.repo
[mongodb]
name=MongoDB Repository
baseurl=http://downloads-distro.mongodb.org/repo/redhat/os/x86_64/
gpgcheck=0
enabled=1
yum install -y mongodb-org haproxy keepalived
En los 3 nodos de mongodb configuraremos el archivo /etc/mongod.conf con los siguientes parámetros:
dbpath=/var/lib/mongo
#bind_ip=127.0.0.1 # Comentar la líinea
port=27017
rest=true
cpu=true
fork=true
replSet=rs0
Sobre el nodo1, crearemos el replicationSet:
[root@centosMongodb1 ~]# mongo
MongoDB shell version: 2.6.7
connecting to: test
Welcome to the MongoDB shell.
For interactive help, type "help".
For more comprehensive documentation, see
http://docs.mongodb.org/
Questions? Try the support group
http://groups.google.com/group/mongodb-user
Server has startup warnings:
2015-02-05T13:22:24.660-0500 ** WARNING: --rest is specified without --httpinterface,
2015-02-05T13:22:24.660-0500 ** enabling http interface
rs.initiate() rs0:PRIMARY> rs.add("mongodb2") { "ok" : 1 } rs0:PRIMARY> rs.addArb("mongodb3") { "ok" : 1 } rs0:PRIMARY>
**Adaptar los nombres de los sistemas implicados
Verificamos que el estado es correcto y que los nodos se han agregado correctamente al replicationSet:
rs0:PRIMARY> rs.status()
{
"set" : "rs0",
"date" : ISODate("2015-02-05T22:09:01Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "mongodb1:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1493,
"optime" : Timestamp(1423160954, 1),
"optimeDate" : ISODate("2015-02-05T18:29:14Z"),
"electionTime" : Timestamp(1423172682, 1),
"electionDate" : ISODate("2015-02-05T21:44:42Z"),
"self" : true
},
{
"_id" : 1,
"name" : "mongodb2:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 1445,
"optime" : Timestamp(1423160954, 1),
"optimeDate" : ISODate("2015-02-05T18:29:14Z"),
"lastHeartbeat" : ISODate("2015-02-05T22:09:01Z"),
"lastHeartbeatRecv" : ISODate("2015-02-05T22:08:59Z"),
"pingMs" : 0,
"syncingTo" : "mongodb1:27017"
},
{
"_id" : 2,
"name" : "mongodb3:27017",
"health" : 1,
"state" : 7,
"stateStr" : "ARBITER",
"uptime" : 1493,
"lastHeartbeat" : ISODate("2015-02-05T22:09:01Z"),
"lastHeartbeatRecv" : ISODate("2015-02-05T22:09:01Z"),
"pingMs" : 0
}
],
"ok" : 1
}
Agregar al arranque del sistema los servicios implicados:
chkconfig mongod on
chkconfig haproxy on
chkconfig keepalived on
Operaciones con los servicios implicados:
/etc/init.d/mongod {start,stop,restart,status}
/etc/init.d/haproxy {start,stop,restart,status}
/etc/init.d/keepalived {start,stop,restart,status}
Definir una dirección IP interna para el frontal de MongoDB, en nuestro ejemplo la 10.10.10.150
vrrp_instance VMONGO_1 {
interface eth0
state MASTER
virtual_router_id 150
priority 101 # 101 on master, 100 on backup
authentication {
auth_type PASS
auth_pass keepmesynced
}
virtual_ipaddress {
10.10.10.250/24 dev eth0 label eth0:ha
}
}
**Adaptar a los interfaces de red del servidor en el que vamos a trabajar. En el ejemplo el interfaz de red es eth0
Introducir la siguiente línea en el /etc/rc.local
echo 1 > /proc/sys/net/ipv4/ip_nonlocal_bind
Arrancar el servicio keepalived
/etc/init.d/keepalived start
Configuración de haproxy para el balanceo para el sistema, modo failover, basado en el estado de los nodos, ya que solo se puede escribir en el nodo "master".
global
log 127.0.0.1 local0 debug
user root
group root
maxconn 10000
daemon
defaults log global mode tcp retries 3 maxconn 10000 timeout connect 5000 timeout client 1h timeout server 1h
frontend mongodb bind 10.10.10.250:29017 monitor-net 127.0.0.1/32 default_backend mongodb-backend
backend mongodb-backend balance roundrobin option httpchk GET /isMaster HTTP/1.1 http-check disable-on-404 http-check expect string ismaster"\ :\ true server gecoscc1 10.10.10.201:27017 check port 28017 inter 2000 rise 2 fall 3 server gecoscc2 10.10.10.202:27017 check port 28017 inter 2000 rise 2 fall 3
Arracar el servicio de HAProxy en cada nodo
/etc/init.d/haproxy start
Editaremos en el archivo /opt/gecosccui-2.1.9/gecoscc.ini la dirección de MongoDB para que quede siempre apuntando a la IP de balanceo, la que siempre apunta al máster.
mongo_uri = mongodb://IP_BALANCEO:29017/gecoscc
Si tenemos la posibilidad de usar unidades desde una cabina de almacenamiento, usaremos éstas para conectarlas a los servidores de GECOSCC UI, pueden ser unidades NFS o cualquier otro tipo, ya que no requiere de velocidad en la lectura/escritura. Las unidades debemos montarlas en todos los nodos del cluster.
Para el montaje de unidades NFS, editar el archivo /etc/fstab
:/opt/gecosccui-2.1.9/sessions /opt/gecosccui-2.1.9/sessions nfs rsize=8192,wsize=8192,nosuid,noatime,soft 0 0
:/opt/gecoscc/media/users /opt/gecoscc/media/users nfs rsize=8192,wsize=8192,nosuid,noatime,soft 0 0
Desde uno de los nodos GecosCC UI crearemos el usuario administrador e importación de las policies, pero antes, debemos crear el archivo: /etc/chef-server/admin.pem, esto solo se ejecutará una vez. El contenido de este archivo es la key que obtendremos del servidor chef en la ruta: /etc/chef-server/admin.pem, o podemos acceder generar de nuevo el certificado desde el panel de administración de chef-server. Es muy importante que exista este archivo para la creación del primer usuario, ya que sin el certificado, la creación fallará.
La interfaz de usuario del centro de control utiliza un programa supervisor para evitar la interrupción de su ejecución. Para detener y arrancar el centro de control hay que utilizar este supervisor.
Para detener el centro de control paramos el supervisor con el siguiente comando:
/etc/init.d/supervisord stop
Para arrancar el centro de control iniciamos el supervisor con el siguiente comando:
/etc/init.d/supervisord start
Para detener Chef Server debemos ejecutar el siguiente comando:
chef-server-ctl stop
en el caso de que algún proceso se haya quedado bloqueado podemos ejecutar:
chef-server-ctl kill
Para iniciar Chef Server debemos ejecutar el siguiente comando:
chef-server-ctl start
GECOS Control Center está formado por muchos componentes. Cada uno de estos componentes se pueden monitorizar de muchas maneras. Existen muchas aplicaciones que pueden comprobar el estado de los componentes como nagios, zabbix, monit, munin, etc. Es por ello que vamos a indicar los puntos de medición para saber si el sistema está funcionando correctamente.
- Debe tener un proceso llamado mongod funcionando
- Un puerto de escucha 27017
- La URL http://localhost:27017/gecoscc debe devolver un mensaje 200
- Debe tener unos procesos corriendo llamados pserve,pceleryd
- Dos puertos de escucha 8010 y 8011
- Las URL http://localhost:8010 y http://localhost:8011 deben devolver un mensaje 200
- Debe tener el proceso nginx corriendo
- Deben tener los puertos 80 y 443 abiertos
- Las URLs http://localhost y https://localhost deben devolver un mensaje 200
- Debe tener el proceso supervisord corriendo
- Debe tener el proceso postgres corriendo
- Debe tener el puerto 5432 abierto
- Debe tener el proceso runsv corriendo
- El comando chef-server-ctl status debe devolver algo parecido a:
run: bookshelf: (pid 15498) 16449s; run: log: (pid 24817) 29611s
run: chef-expander: (pid 15521) 16448s; run: log: (pid 24775) 29613s
run: chef-server-webui: (pid 15526) 16448s; run: log: (pid 24971) 29603s
run: chef-solr: (pid 15546) 16448s; run: log: (pid 24730) 29614s
run: erchef: (pid 15581) 16447s; run: log: (pid 24859) 29609s
run: nginx: (pid 15623) 16447s; run: log: (pid 25129) 29597s
run: postgresql: (pid 15632) 16447s; run: log: (pid 24644) 29620s
run: rabbitmq: (pid 15650) 16446s; run: log: (pid 24316) 29631s
* Debe tener abiertos los puertos 8000 4321 5672 55044
Además de comprobar el estado de los servicios, es recomendable tener en cuenta el estado de los recursos disponibles para la ejecución de GECOS Control Center.
Los recursos que deberemos medir son:
- Carga de las CPUs
- Memoria consumida
- Espacio en disco ocupado por las distintas particiones del sistema
- Tiempo de respuesta I/O
- Ancho de banda utilizado en las tarjetas de red
Antes de poder realizar copias de seguridad del servidor Chef es necesaria la instalación de la gema de Ruby knife-backup ejecutando el siguiente comando:
gem install knife-backup
Para crear una copia de los datos del servidor Chef en el directorio ./backups hay que asegurarse de que el servidor se encuentra parado y ejecutar el siguiente comando:
knife backup export -D ./backups -u admin -k /etc/chef-server/admin.pem
Para restaurar la copia creada:
knife backup restore -D ./backups -u admin -k /etc/chef-server/admin.pem
El script de instalación del Centro de Control GECOS crea un fichero de configuración para knife en ///tmp/knife.rb//. Es posible copiarlo a una ubicación permanente y utilizarlo en las operaciones de backup y restore. Para utilizar este fichero, se añade la opción //-c <ubicación-del-fichero>// al comando //knife//.
El comando mongodump realiza copias de seguridad de la base de datos del Centro de Control, mongodb.
Para realizar una copia completa de la base de datos que está ejecutándose en la máquina local (127.0.0.1 o localhost) y en el puerto 27017 (puerto por defecto de mongodb), utilice el siguiente comando:
mongodump
Por defecto mongodump almacena la copia de los datos en el directorio dump/.
También puede especificar el host y el puerto de la base de datos, así como el directorio donde se guardará la copia:
mongodump --host mongodb.example.net --port 27017 --out /data/backup/
El comando mongorestore restaura una copia previamente creada.
Para restaurar una copia que se encuentra en el directorio dump/ ejecutamos el siguiente comando:
mongorestore dump/
Para restaurar una copia en una base de datos que se encuentra en otro host:
mongorestore --host mongodb.example.net --port 3017 --username user --password pass dump/
En el manual de mongodb se encuentra toda la información necesaria acerca del uso avanzado de mongodump y mongorestore, así como otros posibles métodos de copia y restauración de la base de datos.
Por defecto las claves de los usuarios de centro de control están almacenadas en /opt/gecoscc/media/users/. Para hacer una copia o cambiar las claves de lugar efectúe una copia de este directorio.
Puede cambiar la ruta en la que el centro de control buscará las claves de los usuarios, para ello modifique el campo firstboot_api.media del archivo de configuración del centro de control.
La Gestión de la Capacidad es la encargada de que todos los servicios TI se vean respaldados por una capacidad de proceso y almacenamiento suficiente y correctamente dimensionada.
Sin una correcta Gestión de la Capacidad los recursos no se aprovechan adecuadamente y se realizan inversiones innecesarias que acarrean gastos adicionales de mantenimiento y administración. O aún peor, los recursos son insuficientes con la consecuente degradación de la calidad del servicio.
Las características recomendadas del hardware para que GECOS Control Center tenga un rendimiento óptimo son:
- 8 cores 2.0 GHz AMD 41xx/61xx o Intel Xeon 5000/E5 CPUs
- 16GB RAM
- 2 x 300GB SAS en RAID 1
- Tarjeta RAID por hardware
- Tarjeta de red 1 GigE
- 80 GB de espacio en /opt
- 80 GB de espacio en /var
Hay puntos del sistema que irán creciendo o reduciendo dependiendo de la carga del sistema o de la cantidad de datos almacenados.
Podemos observar que la carga puntual del sistema incidirá en:
- Carga de las CPUs
- Memoria consumida
- Ancho de banda y tiempo de respuesta de I/O
Si durante la monitorización de los recursos del sistema observamos que los anteriores indicadores están al límite, deberemos aumentar la capacidad de los mismos añadiendo más hardware o afinando la configuración del sistema para que se adapte a las demandas particulares de carga del entorno.
Por ejemplo, para mantener optimizado el espacio ocupado por los datos de GECOS Control Center debermos ejecutar los siguientes comandos cada cierto tiempo (una tarea en CRON cuando el sistema está en baja carga es lo óptimo):
- Optimizar la base de datos PostgreSQL:
su opscode-pgsql -c "/opt/chef-server/embedded/bin/vacuumdb --all --analyze"
* Optimizar la base de datos MongoDB:
su mongod -c "mongod --repair"
* Optimizar los índices de Solr:
curl 'http://localhost:8983/solr/update?optimize=true&maxSegments=10&waitFlush=false'