Fix repeated actions on repository feed #20738
Conversation
- Before understanding why this patch is here. The actions table stores the actions, this includes commenting on a issue, merging a pull request and pushing a tag etc. However, due to historical (and likely performance) reason, each action(e.g. commenting on a issue) is duplicated for each user(such as the poster, watcher of that issue and repository etc.). - This means, if you only specify the `repo_id` you will end up with a lot of duplicated actions. We fix this by de-duplicating the actions by their `created_unix`. While this isn't a perfect way of solving this problem, it will do the job for 99%. Only problems will arise for highly active repositories in which actions are being taken on the same second.
- Backport go-gitea#20738 - Before understanding why this patch is here. The actions table stores the actions, this includes commenting on a issue, merging a pull request and pushing a tag etc. However, due to historical (and likely performance) reason, each action(e.g. commenting on a issue) is duplicated for each user(such as the poster, watcher of that issue and repository etc.). - This means, if you only specify the `repo_id` you will end up with a lot of duplicated actions. We fix this by de-duplicating the actions by their `created_unix`. While this isn't a perfect way of solving this problem, it will do the job for 99%. Only problems will arise for highly active repositories in which actions are being taken on the same second.
|
Unrelated, but we should probably migrate those unix timestamps in DB to millisecond precision at some point. |
|
Won't this cause issues where branch is deleted when merging? In such cases, both actions are on same second |
That would indeed cause such issue, but there's currently no better way of handling these kind of edge-cases. The actions table is fundamentally flawed for this task. |
|
Not exactly correct. If you want to avoid duplicated actions you should deduplicate them by content AND timestamp. Also we definitely should do what @silverwind proposed, the sooner the better. |
It would only cover a handful of more edge-cases, not every action has content. Most are generated on the fly. |
|
Some other cases that this PR causes issues with:
|
By content I meant overall action entity sans for-whom (ie. all columns in |
I don't think that's the correct way, I'm not even sure if that's efficient for a SQL server. That's more than a hack to fix this. |
It is the only way to do it properly and not lose data. Usually you'd fetch it from SQL first and then filter it once data is in memory (we already fetch it in order to display it). I don't think you can fix this by a simple hack, it's a bigger issue that requires migration of entire actions table to be more friendly for such use-cases. We can't really call these "edge-cases". My daily activity consists 90% of actions that would be affected (see #20738 (comment), mostly review and merge) and considering core nature of actions affected (review, comment, push, merge) it is not something we can play around with freely; users are relying on seeing these actions on feeds. |
|
Is it covered by tests? I guess the change will produce SQLs like IIRC, Correct me if I am wrong or I misunderstood something. |
Whatever we decide here, it won't lose data. We don't modify any items in the database we just restrict what we receive.
However that's not an option here as for larger repository we can end up fetching multiple times just to de-deplicate one action, the database should take care of this.
Yeah and I'm currently not in to do that as just thinking about it gives me a headache, this will PR does solve the issue with repeated actions and we can deal with a proper long-term fix later on, which requires a complex migration that handles every edge case.
I'm sorry but on which feed? We are currently just talking about the repository RSS that is borked(example), I don't think anybody is relying on this currently and if they do they also see "Oh this data is crap and repeated".
I have no idea, this is why we're using a ORM right? I see many other occurrences of GroupBy. And we only select |
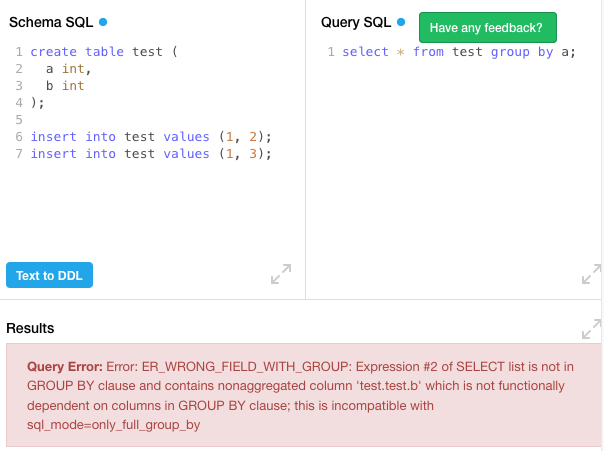
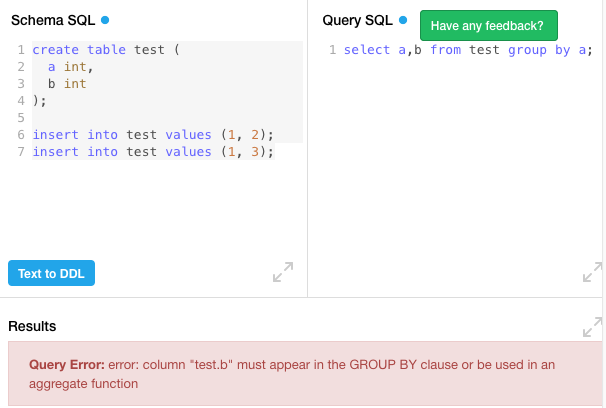
create table test (
a int,
b int
);
insert into test values (1, 2);
insert into test values (1, 3);
select * from test group by a;db-fiddle: MySQL
PostgreSQL
|
|
So what's the problem? Why does other SQL queries work that just uses GroupBy? And what's the proposed fix? |
The problem is that the non-standard SQL will cause errors
Maybe they were all written correctly? (I did a quick check, yes, all GroupBy I checked were written correctly before)
#20738 (comment) , the standard SQL syntax is Update: I am talking about the SQL only. I have no idea (and haven't thought) about how to improve the RSS feed at the moment. Maybe the solution is more complex than it looks like. |
|
Hmm, tests are passing and seems like this was already covered by test-cases. I now added a explicit test case for this bug, 11a82cb. Maybe XORM is doing some tricky things to make this work 🤷🏽. |
|
For a big instance, |
I've added |
Standard is standard .... I do not think it's right to do The unit tests only run with SQLite, SQLite can bear the non-standard SQLs (you can try it on https://sqlite.org/fiddle/). I just tried to put the code in integration tests and started the CI, I would suppose the tests fail there. See https://drone.gitea.io/go-gitea/gitea/59003/2/14 and https://drone.gitea.io/go-gitea/gitea/59003/3/8 |
|
This is beyond my knowledge of SQL, feel free to push commits to make it the SQL standard. |
Sorry but I can not help to modify the SQL at the moment, it comes to the problem I mentioned in #20738 (comment)
I have no idea about how to help to improve the feed list at the moment. 😂 |
|
Okay I think I might have something, what if we only request the action's id via the group_by query and then use a generic Ex. create table test (
a int,
b int,
id int
);
insert into test values (1, 2, 1);
insert into test values (1, 3, 2);
insert into test values (2, 3, 3);
insert into test values (2, 7, 4);
insert into test values (1, 3, 5);
insert into test values (5, 3, 6);
select * from test where id in (select min(id) as id from test group by a); |
|
Yup, that's a common trick to do the select+group. However, when you do group-by, you will have new problems with pagination (the SetSessionPagination, aka |
|
Hmm unless this is SQLite acting up again. I'm now at this query and it's producing the correct results: SELECT `action`.* FROM `action` INNER JOIN `repository` ON `repository`.id = `action`.repo_id WHERE repo_id=? AND is_deleted=? AND `action`.`id` IN (SELECT min(id) as id FROM action GROUP BY `action`.created_unix, `action`.op_type, `action`.act_user_id) ORDER BY `action`.`created_unix` DESC LIMIT 30 [22 false]Which in theory should work for MySQL/PostgreSQL. And does produce the correct result on SQLite. |
|
#20744 Seems to suggest that my awful creation of SQL query still doesn't work? I don't see a lot of options anymore(that doesn't involve calling the database a thousands times in worst-case repositories), I'm also happy to just demolish the feature for now so we all can spend some time engineering a better solution to this problem as currently as-is the feature is just plain broken for repositories feeds. |
RSS feeds should not be so long, there should be a limit (say actions from past 6h). Also, having every action separate in RSS feed is unhelpful, for stuff like replies to issues there should be a single entry per repository per issue per action (reply, review) that gets updated (RSS allows to update items so that readers show them as unread again). Ideally the title of item would contain something like "X new replies to issue Y", where X is number of unique replies since user last read (on site) that issue. Basically, I do not think these feeds are useful to anyone, people would want to have feed of their notifications instead. |
That's not the issue, even 1 action can be duplicated for hunderds of users. And we need to iterate through them if the database can't de-duplicate for us. There's a hard limit of 30 actions to be shown in the RSS feed.
Unfortunately that's not the case, current system is stupid so we got to deal with it.
If it wasn't useful it wouldn't have been implemented. See #569 |
I am certain that they are useful for someone, but that does not mean they are useful in general to larger audience. The desired use-case was most likely to use them instead of webhooks, as feeds are fetch wheras hooks are push. Maybe it was necessary for someone having air-gapped instance and instead of creating a solution themselves (ie. having separate service receiving webhooks on loopback and exposing them as fetch endpoint) they decided to pollute codebase with features that now will have to be maintained. In the first place, if feature is in such broken state it should have never been approved and merged, it should've been on the original author to devise a working solution; as it stands now it just adds additional complexity and steals time from maintainers who are now left with a feature they'll have to fix and maintain in future. Anyway, that is enough for my rant. Regarding PR itself - it does seem like the solution you came up with is no-go, both technically as well as behavior-wise. I have absolutely no idea how to handle this nicely without refactoring entire Maybe consider dropping feed support for repos and orgs in general and instead add feed support for:
No idea what to do with user feed though. |
The I have read the new change: |
Confirmed that on larger repositories with quite a lot of actions this is indeed slow. I will close the PR for now and think about some kind of magical migration that will fix this. |
|
@CirnoT Please open a new issue for your concerns, this wasn't really the place to discuss such things. |
repo_idyou will end up with a lot of duplicated actions. We fix this by de-duplicating the actions by theircreated_unix,op_typeandact_user_id. So that means ifcreated_unix,op_typeandact_user_idis the same it's likely the same action but meant for meant for different users. It's only possible to create a "collision" if a user is able to create a two or more actions under a second.