Add non_blocking kwarg to send_to_device()#607
Add non_blocking kwarg to send_to_device()#607NouamaneTazi merged 6 commits intohuggingface:mainfrom
non_blocking kwarg to send_to_device()#607Conversation
- to make .to() run asynchronously
 sgugger
left a comment
sgugger
left a comment
There was a problem hiding this comment.
Thanks for your PR!
Since this method is used everywhere (and not just in the big model inference) can we put the non_blocking argument (with default to True) as an arg to send_to_device? This way if we see it causes some problem in another part of the lib, we can set it off without touching big model inference.
|
The documentation is not available anymore as the PR was closed or merged. |
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread. Please note that issues that do not follow the contributing guidelines are likely to be ignored. |
|
Hi @sgugger, was there a reason that this was closed and not merged? I came across this when I was about to request the same thing. |
|
@Chris-hughes10 it was automatically closed by the stale bot due to the absence of activity. @NouamaneTazi is still investigating whether this could have some negative impact sometimes. |
Should we make .to(non_blocking=True) the default in accelerate?Let’s use this script to find out import torch
if __name__ == '__main__':
seed = 0
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
stream = torch.cuda.current_stream()
x = torch.rand(32, 256, 220, 220).cuda()
t = (x.min() - x.max()).to(torch.device("cpu"), non_blocking=False) # try with False then True
# t = (x.min() - x.max()).to("cuda:1", non_blocking=True) # try GPU0 to GPU1 copy
print(stream.query()) # False - Checks if all the work submitted has been completed.
print(t)
stream.synchronize() # wait for stream to finish the work
print(stream.query()) # True - work done
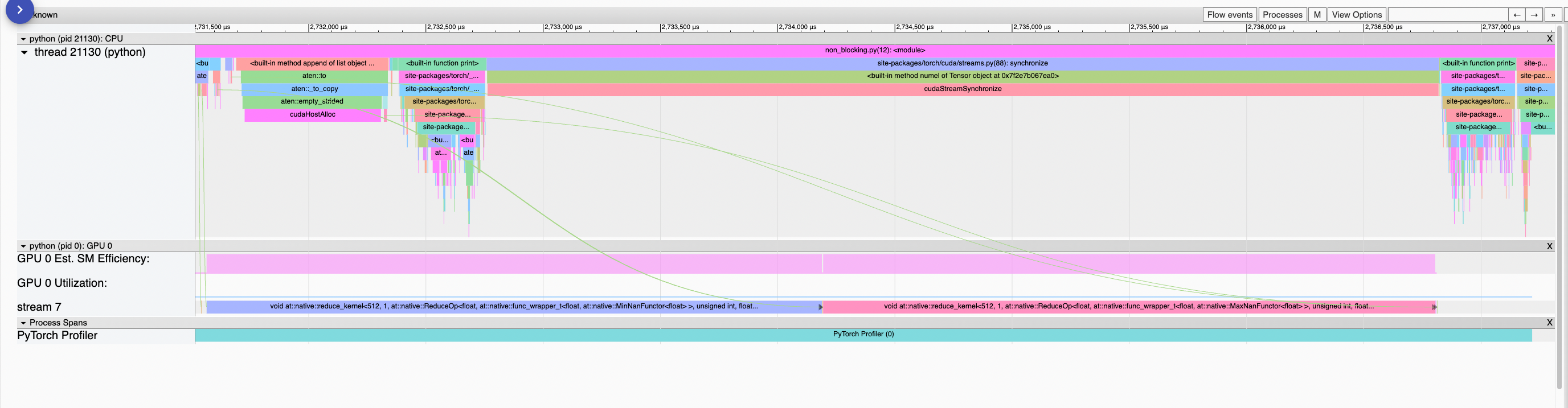
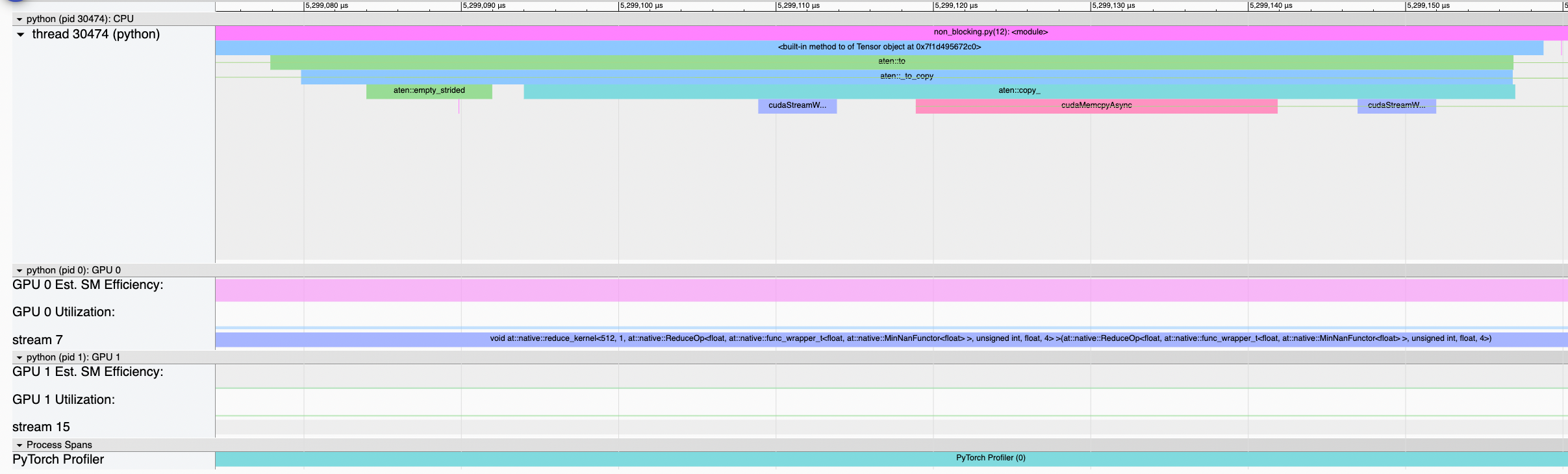
print(t)Copy to CPU with non_blocking=False (default)In this case Copy to CPU with non_blocking=TrueIn this case the CPU submits the kernels for Copy to another GPU with non_blocking=TrueIt seems that the
tldr;
=> It’s good to support that argument in accelerate but it’s better to keep the default as it is, just like it’s the case in Pytorch |


… pr/NouamaneTazi/607
|
@NouamaneTazi These are really interesting insights! If you are looking at inspecting signatures, do you think it would be too much complexity to set non-blocking automatically based on whether it is CPU -> GPU transfer or GPU -> CPU transfer by inspecting the tensor's current device? If you like the idea, perhaps this would be a different feature though, toggled by an accelerator flag? |
|
@Chris-hughes10 CPU -> GPU and GPU -> CPU both lead to the same issues as mentioned above. Only GPU -> GPU is the safe operation but as I said above, it seems that it requires the two GPUs synchronization whether we set |
Apologies, I misread the post above. Please ignore my previous suggestion! |
send_to_device() run asynchronouslynon_blocking kwarg to send_to_device()
The .to() seems to throttle the forward pass, by creating a
cudaStreamSynchronizeeverytime theAlignDevicesHookis called.For example, I managed to reduce Walltime for a single forward pass of
bloom-175bby 15% (with profiling on) by applying this fix.cc @sgugger