Do not force download by default in ORTModel#356
Conversation
|
The docs for this PR live here. All of your documentation changes will be reflected on that endpoint. |
 philschmid
left a comment
philschmid
left a comment
There was a problem hiding this comment.
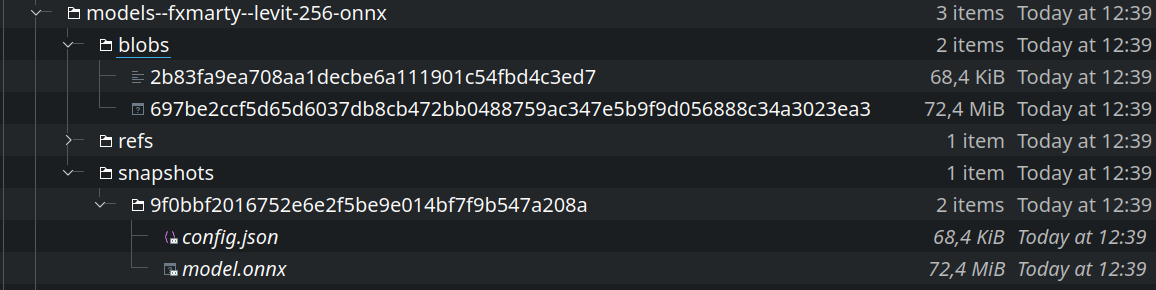
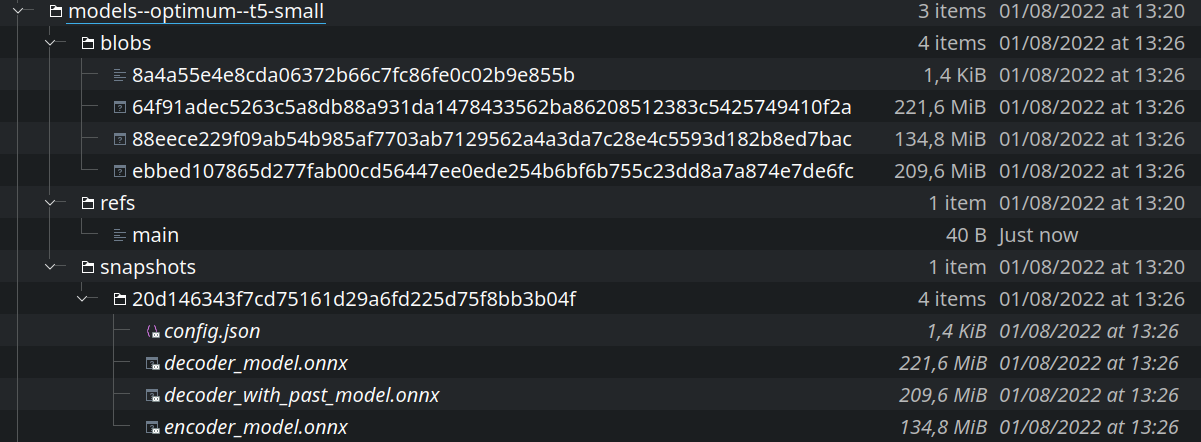
That's awesome! But we have to add test to validate that it is working as expected. Especially since we are storing the "model.onnx" files at the top level with out any hash. So there is no way for the library to know if the cached "model.onnx" is the correct one or not.
We can add the local_files_only argument to the from_pretrained method and have then working and failing tests for "cached" and regular models. As well as for loading different models after each other to make sure we have the correct ones loaded.
See documentation: https://huggingface.co/docs/huggingface_hub/package_reference/file_download#huggingface_hub.hf_hub_download.local_files_only
We should also check that this works for the seq2seq models.
And we should check if the new cache system allows better distribution of onnx files. Currently, when a user loads and saves a onnx file it is saved at the top cache directory with model.onnx, which means if he loads a new model "from" cache it uses the old model. Thats why i went with "force_download" in the beginning.
|
When loading an onnx model with
For seq2seq models (with
which does work as well. Thanks for the suggestion to add tests, I will try to add some! When In case we passed Under the new caching system, if we pass In any case, I think the case |
* Override export of ORTSeq2SeqTrainer * Do not force download by default in ORTModel (#356) * Update OnnxConfigWithLoss wrapper * ORT optimizer refactorization (#294) * Refactorization of ORTOptimizer * Refactorization of ORTModel * Adapt examples according to refactorization * Adapt tests * Fix style * Remove quantizer modification * Fix style * Apply modifications from #270 for quantizer and optimizer to have same behavior * Add test for optimization of Seq2Seq models * Fix style * Add ort config saving when optimizing a model * Add ort config saving when quantizing a model * Add tests * Fix style * Adapt optimization examples * Fix readme * Remove unused parameter * Adapt quantization examples * Fix quantized model and ort config saving * Add documentation * Add model configuration saving to simplify loading of optimized model * Fix style * Fix description * Fix quantization tests * Remove opset argument which is onnx config default opset when exporting with ORTModels * Fix import (#360) * Fix export of decoders * Add flag to export only decoders * Fix ORTTrainer inference ort subclass parsing * Fix filenames when empty suffix given (#363) * fix(optimization): handle empty file suffix * fix(quantization): handle empty file suffix * use pathlibfor save_dir * run test again * Update optimum/onnxruntime/quantization.py Co-authored-by: Ella Charlaix <80481427+echarlaix@users.noreply.github.com> * ReRun test that failed because of cache (network) Co-authored-by: Ella Charlaix <80481427+echarlaix@users.noreply.github.com> * Override the evaluation and prediction loop in ORTSeq2SeqTrainer * Fix documentation (#369) * fix class * Update optimization.mdx * Fix label smoother device prob * Fix lm_logits and labels dimension mismatch * Clean up Co-authored-by: fxmarty <9808326+fxmarty@users.noreply.github.com> Co-authored-by: Ella Charlaix <80481427+echarlaix@users.noreply.github.com> Co-authored-by: Pierre Snell <ierezell@gmail.com> Co-authored-by: Pierre Snell <pierre.snell@botpress.com> Co-authored-by: Philipp Schmid <32632186+philschmid@users.noreply.github.com>
* Inference with ORTModel * Clean up unused imports * Replace Inference session by ort model * Inference with ORTModel * Clean up unused imports * Replace Inference session by ort model * Update modeling for custom tasks * Replace in evaluation_loop * refectoring prediction_loop * ORTSeq2SeqTrainer refactoring - Inference with ORTModel (#359) * Override export of ORTSeq2SeqTrainer * Do not force download by default in ORTModel (#356) * Update OnnxConfigWithLoss wrapper * ORT optimizer refactorization (#294) * Refactorization of ORTOptimizer * Refactorization of ORTModel * Adapt examples according to refactorization * Fix ORTTrainer inference ort subclass parsing * Replace datasets.load_metric by evaluate * Add summarization example * Enable ORT inference * Fix inference args * Mention ORT inference in READMEs * Remove repetitve code in Trainer * Update examples to trfrs 4.22.1 * Fix qa example prediction error * Update summarization/README.md * Fix logger consistency * Make readme consistent with trfrs * Put back onnx config with past and loss test
We passed by default
force_download=True, although the caching works well when passingforce_download=False. Especially when passingfrom_transformers=False, everything works as expected as the onnx model is loaded from the cachehub/subfolder.When passing
from_transformers=True, although we cache only the PyTorch model (before the new transformers cache system intransformers/cache subfolder, inhub/subfolder in the next transformers release), theforce_downloadargument is anyway ignored in_from_transformersso this PR has no impact there:optimum/optimum/onnxruntime/modeling_ort.py
Lines 239 to 303 in e903324