This repository was archived by the owner on Jun 3, 2025. It is now read-only.
ConvInteger quantization conversion for quant refactor #644
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
8b1b8b9 to
e36e707
Compare
e36e707 to
32b5c19
Compare
32b5c19 to
c7b8d0f
Compare
c7b8d0f to
47ea29e
Compare
anmarques
approved these changes
Apr 7, 2022
Merged
anmarques
added a commit
that referenced
this pull request
Apr 8, 2022
* Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantization. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantization. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed testing files * Style and quality fixes. * Changed call to get_qat_qconfig to not specify symmetry and data type arguments for default case. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantization. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed testing files * Style and quality fixes. * Changed call to get_qat_qconfig to not specify symmetry and data type arguments for default case. * Changed default number of activation and weight bits from None to 8. * Revert "Changed default number of activation and weight bits from None to 8." This reverts commit 95e966ed929fa3512331a73667d5ba2ac3d594b1. * Revert "Changed call to get_qat_qconfig to not specify symmetry and data type arguments for default case." This reverts commit a675813. * Lumped qconfig properties into a dataclass. * Lumped qconfig properties into a dataclass. * Lumped qconfig properties into a dataclass. * Resetting conv and linear activation flags to True. * Renamed class BNWrapper as _BNWrapper. * Added logging messages for when tensorrt forces overriding of configs. * Style and quality fixes. * ConvInteger quantization conversion for quant refactor (#644) * ConvInteger quantization conversion for quant refactor * [quantization-refactor] mark/propagate conv export mode (#672) * batch norm fold with existing bias param bug fix * Quantization Refactor Tests (#685) * rebase import fix * update manager serialization test cases for new quantization params Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com> Co-authored-by: spacemanidol <dcampos3@illinois.edu> Co-authored-by: Benjamin <ben@neuralmagic.com>
dbogunowicz
pushed a commit
that referenced
this pull request
Apr 11, 2022
* Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantization. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantization. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed testing files * Style and quality fixes. * Changed call to get_qat_qconfig to not specify symmetry and data type arguments for default case. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantization. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Removed output quantization from conv layers * Added _Add_ReLU module that enables QATWrapper for quantizaiton. * Removed quantization of output for linear and conv layers by default. Removed fusing of BN and ReLU by default. * Minor fixes. Style and quality fixes. * Added support to freezing bn stats. * Added mode argument to wrapping of train function in BNWrapper * Set BN fusing back as default. * Set BN fusing back as default. * Fixed custom freeze_bn_stats. * Temporary files for evaluating changes to graphs. * Added support to tensorrt flag. Moved the computation of quantization range to get_qat_config_config where it has full information about data type. * Added support to TensorRT quantization * Included check to account for when weight_qconfig_kwatgs is None. * Modified argument names for backwards compatibility. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Updated documentation to reflect changes. * Fixed default weights data type. * Style and quality fixes. * Removed unused method * Removed testing files * Style and quality fixes. * Changed call to get_qat_qconfig to not specify symmetry and data type arguments for default case. * Changed default number of activation and weight bits from None to 8. * Revert "Changed default number of activation and weight bits from None to 8." This reverts commit 95e966ed929fa3512331a73667d5ba2ac3d594b1. * Revert "Changed call to get_qat_qconfig to not specify symmetry and data type arguments for default case." This reverts commit a675813. * Lumped qconfig properties into a dataclass. * Lumped qconfig properties into a dataclass. * Lumped qconfig properties into a dataclass. * Resetting conv and linear activation flags to True. * Renamed class BNWrapper as _BNWrapper. * Added logging messages for when tensorrt forces overriding of configs. * Style and quality fixes. * ConvInteger quantization conversion for quant refactor (#644) * ConvInteger quantization conversion for quant refactor * [quantization-refactor] mark/propagate conv export mode (#672) * batch norm fold with existing bias param bug fix * Quantization Refactor Tests (#685) * rebase import fix * update manager serialization test cases for new quantization params Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com> Co-authored-by: spacemanidol <dcampos3@illinois.edu> Co-authored-by: Benjamin <ben@neuralmagic.com>
Sign up for free
to subscribe to this conversation on GitHub.
Already have an account?
Sign in.
3 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
To land after the quantization-refactor branch lands (Will remove DRAFT tag after). This PR adds support for changing the main pathway of converting quantizable convs to
ConvInteger. The advantage of this update is that activation ranges of Convs no longer need to be observed during training under theConvIntegerspec which will help reduce quantization loss while not sacrificing inference performance.Additionally, a check was added to not remove QDQ blocks immediately preceding
Addnodes. This is to give the deepsparse engine the option of representing parts of a quantizableAddoperation as INT8.Expected quantizable conv block prior conversion:
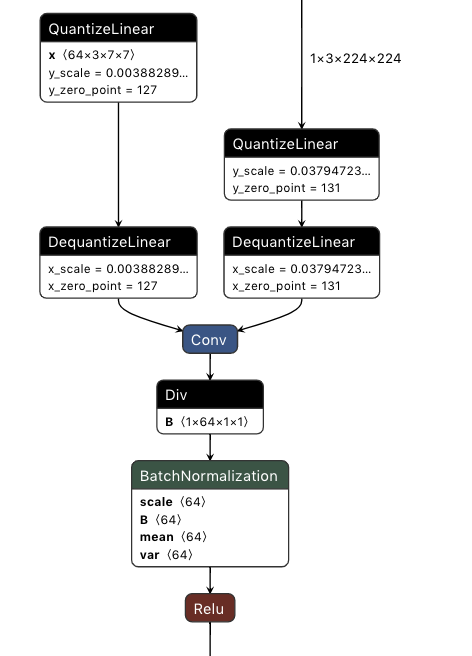
Result after conversion:
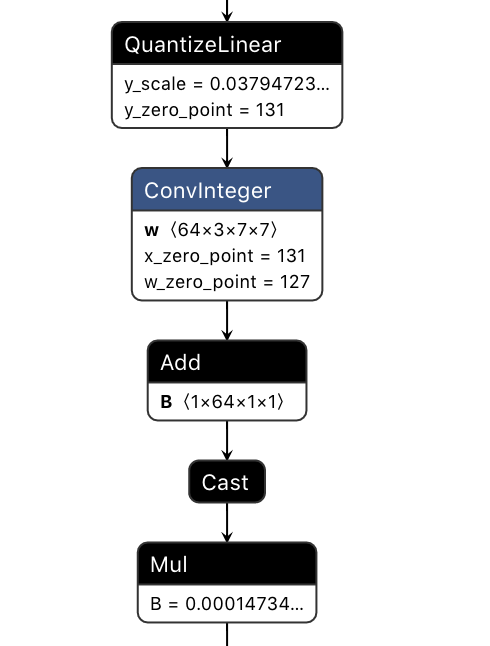
Residual add with 1 QDQ input:
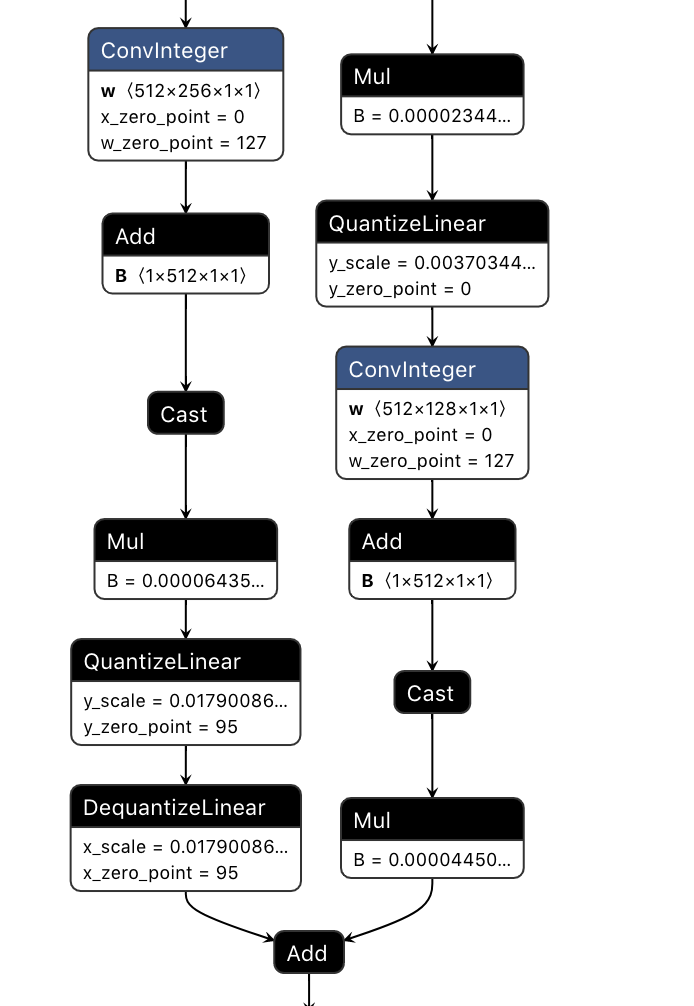
Tested against sample RN50 models from research team against ONNX checker and tested accuracy against imagenet subset