This repository was archived by the owner on Jun 3, 2025. It is now read-only.
fix QAT->Quant conversion of repeated Gemm layers with no activation QDQ #698
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
natuan
approved these changes
Apr 11, 2022
markurtz
approved these changes
Apr 11, 2022
markurtz
added a commit
that referenced
this pull request
May 2, 2022
* Avoid numerically unstable log (#694) * fix QAT->Quant conversion of repeated Gemm layers with no activation QDQ (#698) * Revert rn residual quant (#691) * Revert ResNet definition to not quantize input to add op in residual branches. * Correct typo. Co-authored-by: Mark Kurtz <mark@neuralmagic.com> * Fix: Add linebreak before 'Supplied' for better readability (#701) * Bump notebook in /research/information_retrieval/doc2query (#679) Bumps [notebook](http://jupyter.org) from 6.4.1 to 6.4.10. --- updated-dependencies: - dependency-name: notebook dependency-type: direct:production ... Signed-off-by: dependabot[bot] <support@github.com> Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com> Co-authored-by: Mark Kurtz <mark@neuralmagic.com> Co-authored-by: Michael Goin <michael@neuralmagic.com> * Added integration to masked_language_modeling training command (#707) * Switch off fp16 on QAT start (#703) * Switch off fp16 on QAT start * address: review comments * Disable fp16 when torch version is lesser than `1.9` * Fix transformer prediction step (#716) * Fix for prediction step when teacher model has more inputs than student. * Updated signature of prediction_step method. * Style and quality fixes. * bump main to 0.13 (#696) Co-authored-by: dhuang <dhuang@dhuangs-MacBook-Pro.local> * Fix: default python log calls to debug level (#719) * Feature/integrations (#688) * added tutorials to root readme split by domain * readme update * edited text/structure * grammar edits * fix QATWrapper not properly overwritting qconfig properties for symmetric activations (#724) * re-add fix symmetric zero points for unit8 quantization (#604) (#725) * Fix 'self' and 'disable' not working for transformers distillation (#731) * Click refactor for SparseML-PyTorch integration with Image Classification models (#711) * Click refactor for SparseML-PyTorch integration * Click refactor for `Pruning Sensitivity` analysis (#714) * Click refactor for SparseML-PyTorch pr_sensitivity analysis integration * Review comments from @KSGulin * Click refactor for SparseML-PyTorch `lr-analysis` integration (#713) * Click refactor for SparseML-PyTorch lr-analysis integration * Review comments from @KSGulin * Click refactor for SparseML PyTorch `export` integration (#712) * Click refactor for SparseML-PyTorch export integration * Review comments from @KSGulin * Addressed all review comments from @bfineran, @dbogunowicz and @KSGulin * Regenerate and Update the train-cli docstring due to changes in a few cli-args * `nm_argparser.py` not needed anymore * removed `nm_argparser.py` from init * Remove All CLI args aliases and updated doctrings accordingly * [Fix] Follow-up fix for #731 (Fix 'self' and 'disable' not working for transformers distillation) (#737) * initial commit * added more files and fixed quality * Update trainer.py * Added flag to exclude quantization of embedding activations. (#738) * Added flag to exclude quantization of embedding activations. * Updated testing to contemplate quantize_embedding_activations flag. * Updated testing to contemplate quantize_embedding_activations flag. * Updated debugging * Revert "Updated debugging" This reverts commit 449703d. * Corrected order of arguments to pass assertion. * Update src/sparseml/version.py Co-authored-by: Eldar Kurtic <eldar.ciki@gmail.com> Co-authored-by: Benjamin Fineran <bfineran@users.noreply.github.com> Co-authored-by: Alexandre Marques <alexandre@neuralmagic.com> Co-authored-by: Konstantin Gulin <66528950+KSGulin@users.noreply.github.com> Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com> Co-authored-by: Michael Goin <michael@neuralmagic.com> Co-authored-by: Rahul Tuli <rahul@neuralmagic.com> Co-authored-by: dhuangnm <74931910+dhuangnm@users.noreply.github.com> Co-authored-by: dhuang <dhuang@dhuangs-MacBook-Pro.local> Co-authored-by: Ricky Costa <79061523+InquestGeronimo@users.noreply.github.com> Co-authored-by: dbogunowicz <97082108+dbogunowicz@users.noreply.github.com>
Sign up for free
to subscribe to this conversation on GitHub.
Already have an account?
Sign in.
3 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
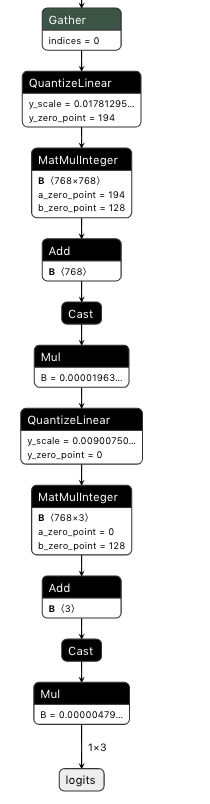
this PR fixes a bug where repeated QAT Gemm nodes whose outputs are not quantized by a QDQ may be picked up by the wrong QAT->Quant conversion step if the converter mistakes the input QDQ block for the second Gemm node to be the output QDQ. block of the previous.
Base QAT graph:
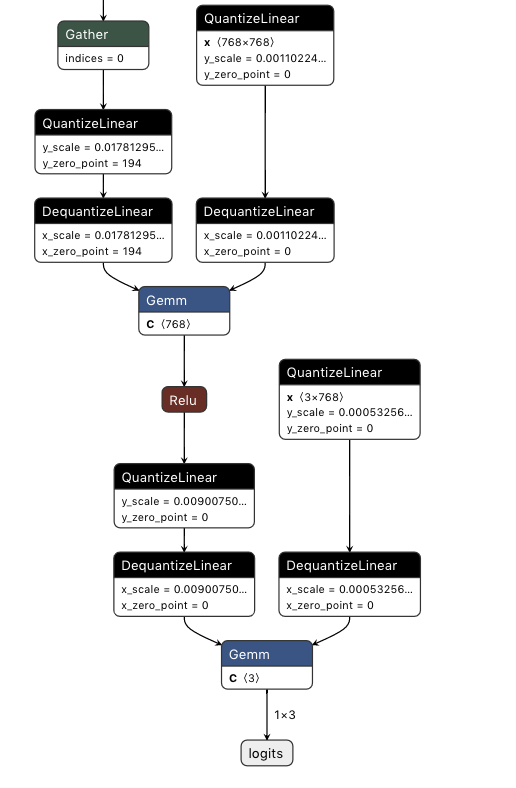
Incorrect Conversion (first Gemm is converted to wrong op type, second Gemm not converted and weights are deleted):
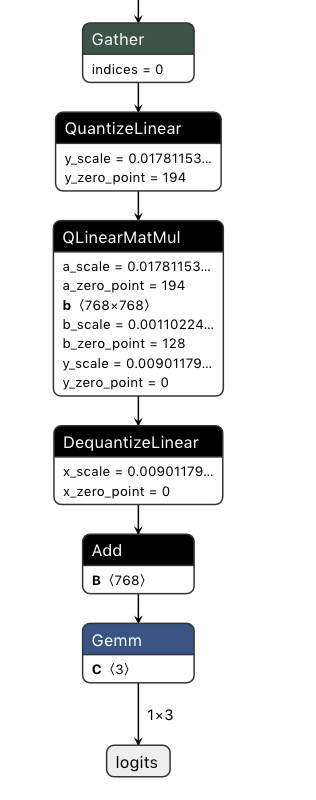
Corrected Conversion (Two repeated MatMulInteger with bias add blocks):