What version of the Codex App are you using (From “About Codex” dialog)?
26.519.2081.0 (Codex.exe ProductVersion: 26.519.21041) Bundled backend CLI (Linux ELF run inside WSL2): codex-cli 0.131.0-alpha.9 Last known-good version before this crash: 0.130.0-alpha.5
What subscription do you have?
ChatGPT Pro
What platform is your computer?
Microsoft Windows NT 10.0.26200.0 x64 Detail: Windows 11 Enterprise, build 26200, 64-bit. Codex App backend runs as a Linux ELF inside WSL2 (Ubuntu-24.04, kernel 6.6.87.2-microsoft-standard-WSL2).
What issue are you seeing?
After Codex Desktop auto-updated from 0.130.0-alpha.5 to 0.131.0-alpha.9, the app refuses to start. The first user-facing dialog is:
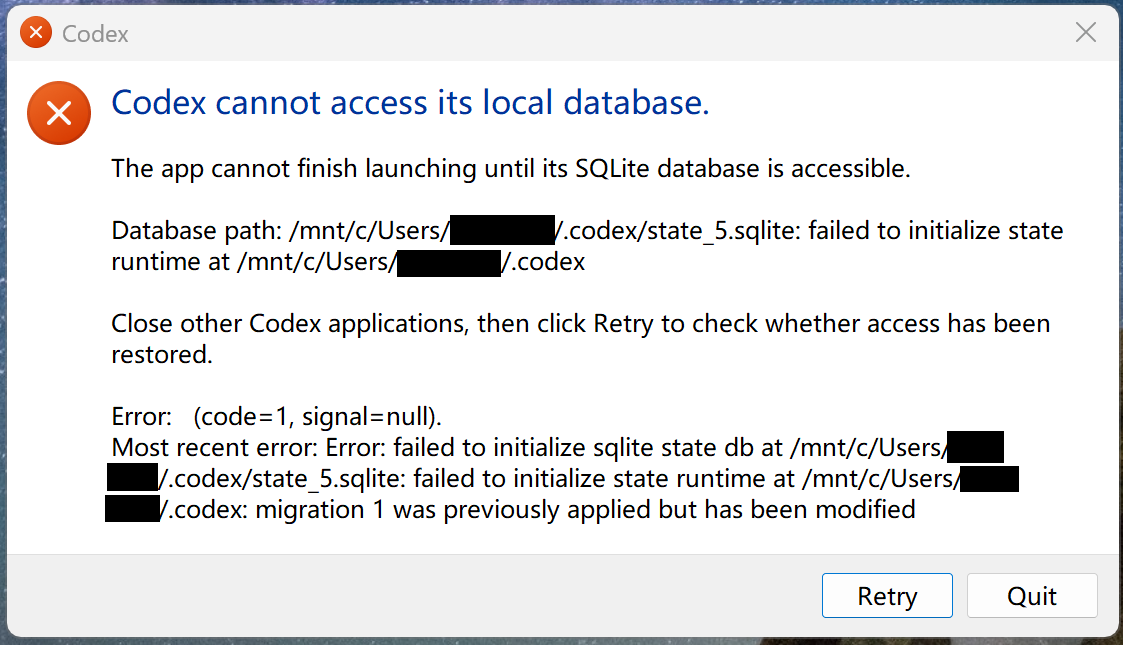
Codex cannot access its local database.
The app cannot finish launching until its SQLite database is accessible.
Database path: /mnt/c/Users/<user>/.codex/state_5.sqlite: failed to initialize state runtime at /mnt/c/Users/<user>/.codex
Close other Codex applications, then click Retry to check whether access has been restored.
Error: (code=1, signal=null).
Most recent error: Error: failed to initialize sqlite state db at /mnt/c/Users/<user>/.codex/state_5.sqlite: failed to initialize state runtime at /mnt/c/Users/<user>/.codex: migration 1 was previously applied but has been modified
Two distinct bugs fire in sequence:
Symptom A (fires immediately on launch)
Codex cannot access its local database
Location: /mnt/c/Users/<user>/.codex/state_5.sqlite
Cause: failed to initialize state runtime at /mnt/c/Users/<user>/.codex:
migration 1 was previously applied but has been modified
The "Repair Codex local data now? [y/N]" prompt is destructive — accepting wipes thread metadata. Declining leaves Codex unusable.
Symptom B (fires after Symptom A is patched)
timed out waiting for state db backfill at /mnt/c/Users/<user>/.codex
after 30s (status: running)
The GUI gives up after 30 s even though the backend's own backfill lease is 900 s (PR #11377), and the backend would have completed in ~50 s on my install (325 active sessions + 40 archived = ~3.5 GB total session jsonl).
Root cause A — logs_2.sqlite migrations modified in place
The SQL bytes of migration 1 (logs) and migration 2 (logs feedback log body) were edited in place between 0.130.x and 0.131.x. sqlx hashes each migration's SQL bytes with SHA-384 at build time, stores the hash in the binary, and refuses any DB whose stored checksum doesn't match — even when the resulting final table schema is fully forward-compatible. This violates sqlx's documented "migrations are immutable once published" contract.
Concrete checksum drift (full anchor list in attached codex-checksums-0.131.0.json):
| Migration |
DB-stored hash (post-0.130) |
Binary-embedded hash (0.131) |
logs_2 m1 logs |
F477E605… |
009639EAFE599BE9… |
logs_2 m2 logs feedback log body |
5C82B1A6… |
CF6C93AF074A9022… |
All 32 state_5.sqlite migration checksums do match between versions, so this is isolated to logs_2.sqlite. Both old and new SQL produce the same final 12-column logs table — the difference is in the SQL bytes themselves, not in any schema-meaningful change.
Root cause B — hard-coded 30 s GUI backfill cap
The GUI startup gate waits for state_5.sqlite.backfill_state.status='complete' with a hard-coded 30 s deadline. The string literal "timed out waiting for state db backfill at {} after {}s (status: {})" is in the binary, but there is no env var, config knob, or CLI flag controlling that 30 s. The backend's own lease is 900 s, so the GUI cap is internally inconsistent with the backend's design.
For users with non-trivial session histories (a few hundred MB+), a cold backfill routinely takes 30–120 s, so the GUI gives up while the backend is still making progress.
0.132.0 does NOT fix either
The rust-v0.132.0 changelog (latest as of 2026-05-20) lists 24 bug fixes; none touches the migrator validation path or the GUI startup timeout.
The closest upstream work is PR #16924 (merged 2026-04-06), which relaxes the migrator only when the DB has migrations the binary doesn't know about (DB newer than binary). That does NOT cover the symmetric case here, where the binary has the same migration's SQL bytes hashing to a different value than what's recorded in the DB.
What steps can reproduce the bug?
- Install Codex Desktop
0.130.0-alpha.5 (or any 0.130.x release) and use it daily for ≥1 day so logs_2.sqlite accumulates rows and _sqlx_migrations is populated with checksums computed from that version's migration SQL bytes.
- Let auto-update jump to
0.131.x (0.131.0-alpha.9 in my case via MSIX OpenAI.Codex 26.519.2081.0).
- Launch Codex → immediate
migration 1 was previously applied but has been modified crash (Symptom A).
- Manually
UPDATE _sqlx_migrations SET checksum = ? in logs_2.sqlite for version IN (1, 2) with the binary-expected values, then relaunch. With > ~50 MB total session jsonl on disk: GUI hits the 30 s backfill timeout (Symptom B).
A reproducible recovery toolkit at https://github.com/xdifu/codex-repair extracts the binary-expected checksums automatically (via SHA-384 anchor scanning + DB description-based cluster localization) and applies the schema-verified fixes. python codex-repair.py doctor against any affected install reports the same drift; python codex-repair.py extract-checksums --json produces the full evidence list attached here.
Investigation summary
- Located the actual backend binary:
%USERPROFILE%\.codex\bin\wsl\<hash>\codex (Linux ELF in WSL2, not the MSIX-bundled Windows Codex.exe). The crash path /mnt/c/... was the WSL view of the Windows drive.
- Extracted all 33 embedded migration checksums (32 for
state_5.sqlite, 2 for logs_2.sqlite) from the backend ELF by scanning for (sql, sha384(sql)) byte-adjacency anchors.
- Diffed extracted checksums against each DB's
_sqlx_migrations rows — found mismatch only for logs_2 m1 and m2.
- Verified the actual
logs table schema (PRAGMA table_info(logs) shows all 12 expected columns including feedback_log_body, thread_id, process_uuid, estimated_bytes) is fully compatible with both the old and new migration SQL — proving the change is cosmetic.
- Rewrote
_sqlx_migrations.checksum for the 2 affected rows. Symptom A cleared; Symptom B appeared.
- Confirmed Symptom B's 30 s timeout is hard-coded by grepping the binary for the timeout literal and related env-var names; no config path exists.
- Backfilled manually from Python (parsing
sessions/**/*.jsonl first-line session_meta), bypassing the 30 s GUI cap, then UPDATE backfill_state SET status='complete'. Codex started cleanly with full thread history intact.
Full archeology and the 5-phase timeline in docs/root-cause-analysis.md.
What is the expected behavior?
Symptom A: a Codex App update should never fail to open a 0.130.x-created logs_2.sqlite when the final table schema is fully forward-compatible. Either:
-
Fix 1 (preferred, OpenAI-internal hygiene): never modify a published migration. Express the new desired schema as 003_…sql / 004_…sql rather than editing 001_…sql / 002_…sql in place. This is the canonical sqlx approach and avoids any client-side compatibility shim.
-
Fix 2 (defensive, in codex-rs/state/src/runtime.rs): in the migrator's VersionMismatch arm, resolve the binary-expected SQL for the failing migration, parse its CREATE TABLE / ALTER TABLE / ADD COLUMN targets, run PRAGMA table_info(<table>) on the live DB, and if every expected column is already present, UPDATE _sqlx_migrations SET checksum = <new_hash> and log a warning. This is symmetric to PR #16924, which already forgives the opposite direction.
-
Fix 3 (minimum-effort escape hatch): accept CODEX_TOLERATE_MODIFIED_MIGRATIONS=1 env var that triggers Fix 2's code path explicitly.
Symptom B: the GUI's 30 s backfill cap should either be removed (let the backend run to its own 900 s lease boundary with a progress indicator) or made configurable via ~/.codex/config.toml (e.g. [startup] backfill_timeout_secs = 30). The current 30 s vs 900 s mismatch between GUI and backend is internally inconsistent and breaks any install with non-trivial session history.
Additional information
Platform reach
This is not a Windows-only bug, even though Windows users hit it first/worst:
A fix should target the cross-platform Rust source (codex-rs/state/src/runtime.rs),
not any Windows-specific code path.
User-side recovery (already works today, no upstream fix needed)
A standalone Python toolkit is published under Apache-2.0 at https://github.com/xdifu/codex-repair.
Capabilities:
- Auto-locates the active backend binary (no hard-coded hash subdir).
- Extracts every embedded migration checksum by scanning the ELF for
(sql, sha384(sql)) anchors, using DB-known migration description strings as a cluster locator (robust across future binary versions — no version-pinned constants).
- Diffs against each DB's
_sqlx_migrations.
- Verifies schema compatibility via
PRAGMA table_info before rewriting any checksum (refuses unsafe updates).
- Reproduces backfill in Python independent of the 30 s GUI cap, then marks
backfill_state.status='complete' with full session metadata.
- Has a
--use-isolated-copy mode that copies the DBs to a temp dir before reading, so it's safe to run a diagnose pass while Codex is open.
Usage by an affected user is one command:
python codex-repair.py fix --apply
Run history on my install: full repair from initial crash to healthy state (365 threads indexed, no errors) completed in under 5 minutes once root cause was identified.
Related upstream issues / PRs
Attached evidence
codex-checksums-0.131.0.json — full list of all 34 migration anchors (32 state_5 + 2 logs_2) extracted from my 0.131.0-alpha.9 backend binary at %USERPROFILE%\.codex\bin\wsl\7945a00f33bdc140\codex. Anyone with the same backend version can reproduce by running:
python codex-repair.py extract-checksums --json > codex-checksums-0.131.0.json
and diffing against mine to confirm identical hashes per migration.
Note
I am happy to contribute the schema-diff helper or a CODEX_TOLERATE_MODIFIED_MIGRATIONS runtime flag as a PR upstream if maintainers consider Fix 2 or Fix 3 the right direction — per the contributing guide, I'll wait for an explicit invitation before opening one.
What version of the Codex App are you using (From “About Codex” dialog)?
26.519.2081.0 (Codex.exe ProductVersion: 26.519.21041) Bundled backend CLI (Linux ELF run inside WSL2): codex-cli 0.131.0-alpha.9 Last known-good version before this crash: 0.130.0-alpha.5
What subscription do you have?
ChatGPT Pro
What platform is your computer?
Microsoft Windows NT 10.0.26200.0 x64 Detail: Windows 11 Enterprise, build 26200, 64-bit. Codex App backend runs as a Linux ELF inside WSL2 (Ubuntu-24.04, kernel 6.6.87.2-microsoft-standard-WSL2).
What issue are you seeing?
After Codex Desktop auto-updated from
0.130.0-alpha.5to0.131.0-alpha.9, the app refuses to start. The first user-facing dialog is:Two distinct bugs fire in sequence:
Symptom A (fires immediately on launch)
The "Repair Codex local data now? [y/N]" prompt is destructive — accepting wipes thread metadata. Declining leaves Codex unusable.
Symptom B (fires after Symptom A is patched)
The GUI gives up after 30 s even though the backend's own backfill lease is 900 s (PR #11377), and the backend would have completed in ~50 s on my install (325 active sessions + 40 archived = ~3.5 GB total session jsonl).
Root cause A —
logs_2.sqlitemigrations modified in placeThe SQL bytes of migration 1 (
logs) and migration 2 (logs feedback log body) were edited in place between0.130.xand0.131.x. sqlx hashes each migration's SQL bytes with SHA-384 at build time, stores the hash in the binary, and refuses any DB whose stored checksum doesn't match — even when the resulting final table schema is fully forward-compatible. This violates sqlx's documented "migrations are immutable once published" contract.Concrete checksum drift (full anchor list in attached
codex-checksums-0.131.0.json):logs_2m1logsF477E605…009639EAFE599BE9…logs_2m2logs feedback log body5C82B1A6…CF6C93AF074A9022…All 32
state_5.sqlitemigration checksums do match between versions, so this is isolated tologs_2.sqlite. Both old and new SQL produce the same final 12-columnlogstable — the difference is in the SQL bytes themselves, not in any schema-meaningful change.Root cause B — hard-coded 30 s GUI backfill cap
The GUI startup gate waits for
state_5.sqlite.backfill_state.status='complete'with a hard-coded 30 s deadline. The string literal"timed out waiting for state db backfill at {} after {}s (status: {})"is in the binary, but there is no env var, config knob, or CLI flag controlling that 30 s. The backend's own lease is 900 s, so the GUI cap is internally inconsistent with the backend's design.For users with non-trivial session histories (a few hundred MB+), a cold backfill routinely takes 30–120 s, so the GUI gives up while the backend is still making progress.
0.132.0does NOT fix eitherThe
rust-v0.132.0changelog (latest as of 2026-05-20) lists 24 bug fixes; none touches the migrator validation path or the GUI startup timeout.The closest upstream work is PR #16924 (merged 2026-04-06), which relaxes the migrator only when the DB has migrations the binary doesn't know about (DB newer than binary). That does NOT cover the symmetric case here, where the binary has the same migration's SQL bytes hashing to a different value than what's recorded in the DB.
What steps can reproduce the bug?
0.130.0-alpha.5(or any 0.130.x release) and use it daily for ≥1 day sologs_2.sqliteaccumulates rows and_sqlx_migrationsis populated with checksums computed from that version's migration SQL bytes.0.131.x(0.131.0-alpha.9in my case via MSIXOpenAI.Codex 26.519.2081.0).migration 1 was previously applied but has been modifiedcrash (Symptom A).UPDATE _sqlx_migrations SET checksum = ?inlogs_2.sqliteforversion IN (1, 2)with the binary-expected values, then relaunch. With > ~50 MB total session jsonl on disk: GUI hits the 30 s backfill timeout (Symptom B).A reproducible recovery toolkit at https://github.com/xdifu/codex-repair extracts the binary-expected checksums automatically (via SHA-384 anchor scanning + DB description-based cluster localization) and applies the schema-verified fixes.
python codex-repair.py doctoragainst any affected install reports the same drift;python codex-repair.py extract-checksums --jsonproduces the full evidence list attached here.Investigation summary
%USERPROFILE%\.codex\bin\wsl\<hash>\codex(Linux ELF in WSL2, not the MSIX-bundled WindowsCodex.exe). The crash path/mnt/c/...was the WSL view of the Windows drive.state_5.sqlite, 2 forlogs_2.sqlite) from the backend ELF by scanning for(sql, sha384(sql))byte-adjacency anchors._sqlx_migrationsrows — found mismatch only forlogs_2m1 and m2.logstable schema (PRAGMA table_info(logs)shows all 12 expected columns includingfeedback_log_body,thread_id,process_uuid,estimated_bytes) is fully compatible with both the old and new migration SQL — proving the change is cosmetic._sqlx_migrations.checksumfor the 2 affected rows. Symptom A cleared; Symptom B appeared.sessions/**/*.jsonlfirst-linesession_meta), bypassing the 30 s GUI cap, thenUPDATE backfill_state SET status='complete'. Codex started cleanly with full thread history intact.Full archeology and the 5-phase timeline in
docs/root-cause-analysis.md.What is the expected behavior?
Symptom A: a Codex App update should never fail to open a
0.130.x-createdlogs_2.sqlitewhen the final table schema is fully forward-compatible. Either:Fix 1 (preferred, OpenAI-internal hygiene): never modify a published migration. Express the new desired schema as
003_…sql/004_…sqlrather than editing001_…sql/002_…sqlin place. This is the canonical sqlx approach and avoids any client-side compatibility shim.Fix 2 (defensive, in
codex-rs/state/src/runtime.rs): in the migrator'sVersionMismatcharm, resolve the binary-expected SQL for the failing migration, parse itsCREATE TABLE/ALTER TABLE/ADD COLUMNtargets, runPRAGMA table_info(<table>)on the live DB, and if every expected column is already present,UPDATE _sqlx_migrations SET checksum = <new_hash>and log a warning. This is symmetric to PR #16924, which already forgives the opposite direction.Fix 3 (minimum-effort escape hatch): accept
CODEX_TOLERATE_MODIFIED_MIGRATIONS=1env var that triggers Fix 2's code path explicitly.Symptom B: the GUI's 30 s backfill cap should either be removed (let the backend run to its own 900 s lease boundary with a progress indicator) or made configurable via
~/.codex/config.toml(e.g.[startup] backfill_timeout_secs = 30). The current 30 s vs 900 s mismatch between GUI and backend is internally inconsistent and breaks any install with non-trivial session history.Additional information
Platform reach
This is not a Windows-only bug, even though Windows users hit it first/worst:
Symptom A (sqlx migration checksum drift): 100% platform-agnostic. The
migration SQL bytes and their SHA-384 hashes are computed at compile time from
codex-rs/state/migrations/logs_2/*.sqland baked into the Rust binary, soevery platform's binary embeds the same hashes. Any user — macOS, Linux, or
Windows — going
0.130.x → 0.131.xwith priorlogs_2.sqlitehistory hitsthe same
migration 1 was previously applied but has been modifiedwall.Mac users have already reported drift symptoms in Codex Desktop macOS project sidebar hides unarchived local threads even though SQLite/session files are intact #20608, Mac app hides older local conversations after update because bogus root-level
statussessions flood recent local history #18364, Desktop project sidebar hides active threads after state DB migration drift and stale temporary sessions #17304.Symptom B (30 s GUI backfill timeout): the 30 s constant itself is also
in the cross-platform Rust source. But the practical trigger rate is much
higher on Windows because the backend runs inside WSL2 and accesses
sessions/*.jsonlvia the 9P protocol over/mnt/c/— roughly 5–10× slowerthan native APFS/ext4. A 200-MB history that backfills in ~8 s on macOS will
routinely take 40–120 s on Windows. Mac users with multi-GB histories or
spinning-rust HDDs are still latently affected.
A fix should target the cross-platform Rust source (
codex-rs/state/src/runtime.rs),not any Windows-specific code path.
User-side recovery (already works today, no upstream fix needed)
A standalone Python toolkit is published under Apache-2.0 at https://github.com/xdifu/codex-repair.
Capabilities:
(sql, sha384(sql))anchors, using DB-known migrationdescriptionstrings as a cluster locator (robust across future binary versions — no version-pinned constants)._sqlx_migrations.PRAGMA table_infobefore rewriting any checksum (refuses unsafe updates).backfill_state.status='complete'with full session metadata.--use-isolated-copymode that copies the DBs to a temp dir before reading, so it's safe to run a diagnose pass while Codex is open.Usage by an affected user is one command:
Run history on my install: full repair from initial crash to healthy state (365 threads indexed, no errors) completed in under 5 minutes once root cause was identified.
Related upstream issues / PRs
WSL CLI cannot share Windows Codex App CODEX_HOME: migration 1 was previously applied but has been modified(open; my own earlier report; describes the WSL-sharing subset of this same root cause)Desktop project sidebar hides active threads after state DB migration drift(open; family of related drift bugs)statussessions flood recent local history #18364, Windows Desktop: sidebar/project list lost after update; search still finds threads; projectless-thread-ids workaround restores flat chats but project grouping remains broken #19873 — overlapping sidebar / thread-disappearing reports stemming from_sqlx_migrationsdrift after auto-updatefix(sqlite): don't hard fail migrator if DB is newer(merged; opposite direction)feat: prevent double backfill(introduced 900 s lease — the figure that makes the 30 s GUI cap so glaringly inconsistent)Make thread metadata updates tolerate pending backfill(open)Move sqlite logs to a dedicated database(context for whylogs_2.sqliteexists as a separate DB fromstate_5.sqlite)Attached evidence
codex-checksums-0.131.0.json— full list of all 34 migration anchors (32 state_5 + 2 logs_2) extracted from my0.131.0-alpha.9backend binary at%USERPROFILE%\.codex\bin\wsl\7945a00f33bdc140\codex. Anyone with the same backend version can reproduce by running:python codex-repair.py extract-checksums --json > codex-checksums-0.131.0.jsonand diffing against mine to confirm identical hashes per migration.
Note
I am happy to contribute the schema-diff helper or a
CODEX_TOLERATE_MODIFIED_MIGRATIONSruntime flag as a PR upstream if maintainers consider Fix 2 or Fix 3 the right direction — per the contributing guide, I'll wait for an explicit invitation before opening one.