Conversation
| if (_runningJobs.size() == 0) { | ||
| break; | ||
| } | ||
| Utility::sleep(1); |
There was a problem hiding this comment.
This is required, because if composite job gets aborted, but one of the job isnt, it will not finalize adding file to journal
There was a problem hiding this comment.
but that's not acceptable. You can't let the main thread sleep like this.
You need to find a better way to wait that the job is actually finished (by listening to the finished signal or so)
There was a problem hiding this comment.
Ohh, true, just tested and it stops the main thread, yep will do that with signals
| foreach (AbstractNetworkJob *job, _jobs) { | ||
| // Abort only PUT and MKDIR jobs, since abording MoveJob | ||
| // might result in conflict. | ||
| if (job->reply() && !job->inherits("OCC::MoveJob")) { |
There was a problem hiding this comment.
if it is not MoveJob, just exit. (Wont it result in tmp new chunking directory be left without deletion, is server deleting periodicaly these tmp directories? @DeepDiver1975 )
There was a problem hiding this comment.
nitpick: use qobject_cast (more efficient and also compile-time checked)
Also, we shold probzbly decrease the timeout. For example, if the abort happens because the connection was detected to be dropped, we should not wait a full HTTP timeout again, IMHO.
There was a problem hiding this comment.
And to answer your question about stale directory, the next sync will resume the upload, so it won't be stale.
There was a problem hiding this comment.
Changed to qobject_cast.
 ogoffart
left a comment
ogoffart
left a comment
There was a problem hiding this comment.
That goes in the right direction,
Also the chunkingv1 need to be changed not to abort the last job. This is also what is used when the file is too small to be split in chunks.
| if (_runningJobs.size() == 0) { | ||
| break; | ||
| } | ||
| Utility::sleep(1); |
There was a problem hiding this comment.
but that's not acceptable. You can't let the main thread sleep like this.
You need to find a better way to wait that the job is actually finished (by listening to the finished signal or so)
| foreach (AbstractNetworkJob *job, _jobs) { | ||
| // Abort only PUT and MKDIR jobs, since abording MoveJob | ||
| // might result in conflict. | ||
| if (job->reply() && !job->inherits("OCC::MoveJob")) { |
There was a problem hiding this comment.
nitpick: use qobject_cast (more efficient and also compile-time checked)
Also, we shold probzbly decrease the timeout. For example, if the abort happens because the connection was detected to be dropped, we should not wait a full HTTP timeout again, IMHO.
I think it's better to hook into how UploadDevice is used and from there control an abort. Then you for sure know you didn't send all bytes and can safely abort. |
|
@ogoffart can you have a look on this approach? One disadvantage is that now after paused, MOVE job continues (1st stage): after it is finished, view switches to (2nd stage): One thing is that the button resume sync is still available also in "1st stage", not sure what happens if it still processes MOVE, but someone clicks resume in that time. @SamuAlfageme I did manual testing and for ChunkingNG problem is solved. |
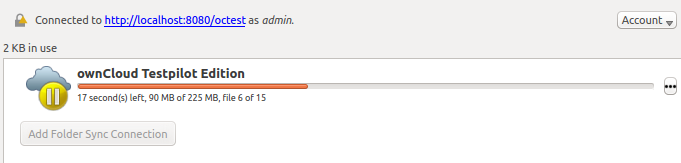
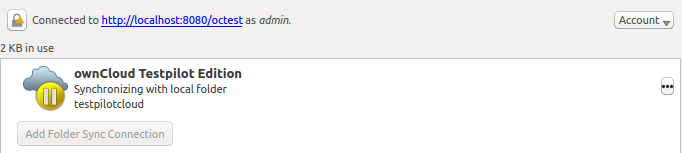
There was a problem hiding this comment.
That's not needed, abort was already sent
So you don't need to put abortJobs in a different function
There was a problem hiding this comment.
The idea here was to force the abort. Thus if after 5 seconds they did not finish, you kill the job just by sending abort jobs again, please have a look on chunkingng implementation
There was a problem hiding this comment.
Hmm, maybe in fact I dont need it also... it will roll back to what was before this PR for the jobs which did not terminate within 5sec
There was a problem hiding this comment.
You need to count the jobs and only emit the signal when ALL subjobs have finished their abort.
There was a problem hiding this comment.
Ah no. i got confused with CompositeJob.
Well, you don't need a slot for this single line, just connect to SIGNAL(abortFinished())
There was a problem hiding this comment.
abortFinished signal is being send after 5 seconds timeout regardless if jobs terminated in that time or not. I give jobs max 5 seconds to finish what they started after receiving first abort signal.
There was a problem hiding this comment.
maybe I should change namings, since I see your confusion.
There was a problem hiding this comment.
@ogoffart so I can connect signal to signal?
|
Looks mostly good. But don't forget the put in the V1, this one is even more important as it happens more often. |
|
Yep, I will do now V1, just wanted to verify that aborting implementation will work for NG (if it will work there, it will probably work everywhere just by implementing abort() in the job) |
89b7324 to
6d533eb
Compare
|
Guys, I tried also the version where CompositeJob waits for aborts from its child, but for some reason with "not aborted MOVE", it was not working properly (looks like a mix of finished and abortFinished signals or even their lack messes things). It took me quite long to debug everything. Should I try once again Timeout in the job itself, or keep with version of timeout in composite job (which will finish sync run no matter what since it does not care if subjob finished abort or not) ? |
|
@ogoffart @guruz @SamuAlfageme PR ready, fixes both V1 and NG |
| void PropagatorCompositeJob::abort() | ||
| { | ||
| foreach (PropagatorJob *j, _runningJobs) | ||
| j->abort(); |
| foreach (PropagatorJob *j, _runningJobs) | ||
| j->abort(); | ||
| } | ||
| virtual void abort() Q_DECL_OVERRIDE; |
There was a problem hiding this comment.
Please also document here that the abort() might not be synchronous/immediate
There was a problem hiding this comment.
Actually, the PropagatorJob::abort documentation should state that this function must emit abortFinished
 guruz
left a comment
guruz
left a comment
There was a problem hiding this comment.
I'm missing a bit of info what happens in a situation where an immediate abort does not work. What will happen after those 5000msec? It will go to emitFinished but what happens with the running stuff?
Also added some other comments:)
@guruz Good question, in my observation when job finishes the sync run is already gone, thus whatever finishes after that time is ignored. I think I will try to implement "forced abort". |
|
I'm not sure, maybe the QNetworkReplys are parented to the Jobs which get deleted when SyncEngine is deleted. |
|
@guruz how to check it? @jturcotte |
|
Maybe just call For example in tests we have |
ogoffart
left a comment
There was a problem hiding this comment.
For the composite job, you need to increment a counter for every subjob you call abort(). connectconnect to the abortFinished on each job Only when all job have emited the abortFinished, you can safely emit the CompositeJob's abortFinished.
Note that all other jobs need to emit abortfinished, so you need to review every job's abort to make sure they emit that signal.
| { | ||
| // Abort first job and sub jobs | ||
| // Finished abort will be announced via abortFinished() | ||
| // (look contructor implementation) |
There was a problem hiding this comment.
(Maybe you can do the connection here.)
Here as well you need to have a counter to make sure that both jobs sent their abortFinished.
|
@ogoffart I did that, and for some reason it was not working properly e.g. finished signal never went back after aborting, and other issues... I can give a try once again on that approach.. I just discovered that I also have to be careful not to break abort mechanism on network error with move, since it will finish in infinite aborts loop (it will retry all the time). |
|
I've rebased to master and will review the current state to help move this forward. |
|
@mrow4a Looks good. My remaining worry is about what happens when abort(Async) is called twice. Do we guard against this somewhere? I've also added my test case here. |
|
I mean, if you call it again, it will basically let unfinished job run (as with previous call of abort(Async)), the other jobs were synchronously aborted with previous call. The only difference is, that now you might have 2 timers (timeout timers) running in parallel, and you add another connects on signals. @ogoffart is that a problem? |
|
@mrow4a I added a minor guard against it that seems sufficient for me. |
| PropagateUploadFileV1(OwncloudPropagator *propagator, const SyncFileItemPtr &item) | ||
| : PropagateUploadFileCommon(propagator, item) | ||
| , _startChunk(0) | ||
| , _currentChunk(0) |
There was a problem hiding this comment.
Note: this could be initialized in the header file.
There was a problem hiding this comment.
Should I step in and fix it, or @ckamm ?
There was a problem hiding this comment.
Sorry, I missed the notifications for this. Looking now.
There was a problem hiding this comment.
@mrow4a (in general, feel free to just fix issues if I'm unresponsive!)
| if (abortType == AbortType::Asynchronous && (((_currentChunk + _startChunk) % _chunkCount) == 0) | ||
| && putJob->device()->atEnd()) { | ||
| if (abortType == AbortType::Asynchronous | ||
| && _chunkCount > 0 |
There was a problem hiding this comment.
I wonder how chunk count can be 0
There was a problem hiding this comment.
chunkCount gets set by doStartUpload and the job's abort can be called before we get there.
| // since this might result in conflicts | ||
| if (PUTFileJob *putJob = qobject_cast<PUTFileJob *>(job)){ | ||
| if (abortType == AbortType::Asynchronous | ||
| && _chunkCount > 0 |
There was a problem hiding this comment.
Can you elaborate more here?
There was a problem hiding this comment.
I guess this is safety check right?
There was a problem hiding this comment.
See above. I was getting crashes because of zero chunkCount when I aborted jobs quickly.
There was a problem hiding this comment.
Ohh that would make sense did not try indeed this corner case.
|
Any progress here? |
|
@mrow4a I think you can merge this now |
|
What is happening with Jenkins build? Did you run tests locally? |
|
No, I hadn't. The test that fails to compile on jenkins works locally. The problem here is that jenkins merges on top of master, and this patch needs some adjustments to work there. I'll take care of the rebase and fixups. |
Dont abort final chunk immedietally Use sync and async aborts
_chunkCount could be 0, leading to a floating point exception I also added initializers for several uninitialized integers in the upload jobs.
|
Jenkins should pass now, let's wait and see. |
|
@DeepDiver1975 I think we might want this in 2.4, but jenkins failed in something after running the tests. Is this a transient issue where retriggering jenkins would help? Could you do that? |
|
We anyway need to merge this to the 2.4 branch if we want this in 2.4 so it will need to be re-targetted |
|
Targeted to 2.4 and merged! |
@SamuAlfageme can you verify that this fixes issue for ChunkingNG for you? I checked on my local machine and this fixed it.
@guruz I will also add similar thing, but for V1, however there I will check if the file bytes been sent or not.
Issue #5949