[zh hans] Red System compiler overview chinese translation
官方原文:http://www.red-lang.org/2011/05/redsystem-compiler-overview.html
red-system/
%compiler.r ; Main compiler code, loads everything else
%emitter.r ; Target code emitter abstract layer
%linker.r ; Format files loader
%rsc.r ; Compiler's front-end for standalone usage
formats/ ; Contains all supported executable formats
%PE.r ; Windows PE/COFF file format emitter
%ELF.r ; UNIX ELF file format emitter
library/ ; Third-party libraries
runtime/ ; Contains all runtime definitions
%common.reds ; Cross-platform definitions
%win32.r ; Windows-specific bindings
%linux.r ; Linux-specific bindings
targets/ ; Contains target execution unit code emitters
%target-class.r ; Base utility class for emitters
%IA32.r ; Intel IA32 code emitter
tests/ ; Unit tests
system/words/ ; global REBOL context
system-dialect/ ; main object
loader/ ; preprocessor object
process ; preprocessor entry point function
compiler/ ; compiler object
compile ; compiler entry point function
emitter/ ; code emitter object
compiler/ ; short-cut reference to compiler object
target/ ; reference the target code emitter object
compiler/ ; short-cut reference to compiler object
linker/ ; executable file emitter
PE/ ; Windows PE/COFF format emitter object
ELF/ ; UNIX ELF format emitter object
Note: the linker file formats are currently statically loaded, this will be probably changed to a dynamic loading model.
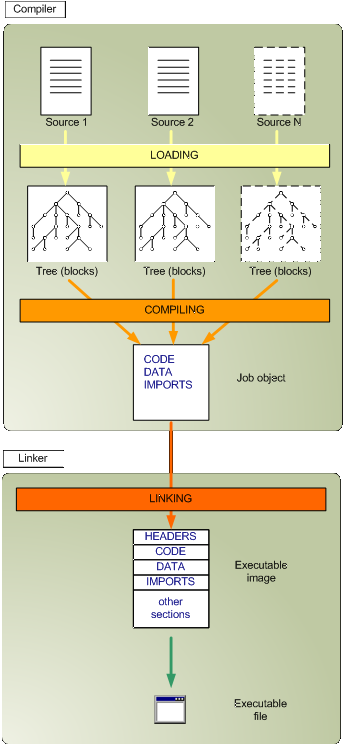
这个准备阶段会把纯文本的源码转化成内存中的表示形式(类似 AST)。包含三个步骤:
- 源码从纯文本格式预处理成符合 REBOL 语法的格式
- 用 REBOL 的
load函数把源码转化成嵌套的 block 树结构 - 解析源码中的编译指令(例如
#include和#define)
编译器用 递归下降 parser 编译源码树,并尝试用它内部的规则和组装(rules and emits)来匹配关键词和值:
-
code buffer中对应的机器码 -
data buffer中全局变量和复杂数据结构(例如c-string!和struct!字面量)
编译阶段的内部入口函数是 compiler/comp-dialect。每一个 compiler/comp-* 函数都是对应 Red/System 语言规范 的一个(或一组)语法规则来递归分析源码。
每次匹配到一条表达式都直接生成 本地机器码,没有生成中间表达形式( IR,Intermediate Representation)。这是最简单的处理方式,但没有生成 IR 就无法对生成的机器码进行有效的优化。等 Red/System 用 Red 重写后,我们会引入一个简单的 IR 来优化机器码。
如你所知,Red/System 程序的入口在源码的最开始处。在编译阶段,首先编译全局 context 中的源码,紧接着收集所有函数继续编译。因此生成的代码是按照下面的方式来组织的:
- 全局代码(including proper program finalization)
- 函数1
- 函数2
- ...
编译的过程:
- 全局符号表(symbol table)
- 机器码的代码段(machine code buffer)
- 全局的数据段(a global data buffer)
- 外部库的函数列表(这些通常是 OS API 的映射)
在编译器进入链接之前,它可以按照上述的方式处理一个或多个源码文件。
链接的目标是生成目标操作系统可以加载的可执行文件,因此可执行文件必须符合目标操作系统的 ABI,例如 Windows 的 PE 和 Linux 的 ELF。
链接时用全局符号表来打包 code 和 data 缓冲区(见 linker/resolve-symbol-refs),为所指向的资源(变量,函数,全局数据)插入最终的内存地址。把不同的部分分组拼装到所谓的节(section),然后这些节被组装成段(segment,例如 ELF)
最后,用来描述可执行文件的头部信息和节/段被插入完整的文件中,然后写到磁盘,整个过程就结束了。
静态链接外部库(*.lib,*.a 等)的相关内容以后需要时再加进来。
我希望这个简短的描述能够让你对 Red/System 编译器的工作有个了解。