CUDA-accelerated C++ implementations of robotics algorithms, based on PythonRobotics and CppRobotics.
Each algorithm leverages GPU parallelism for significant speedup over CPU-only implementations.
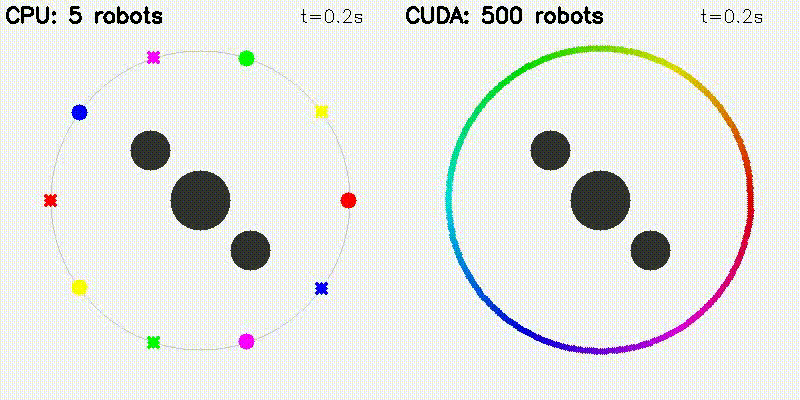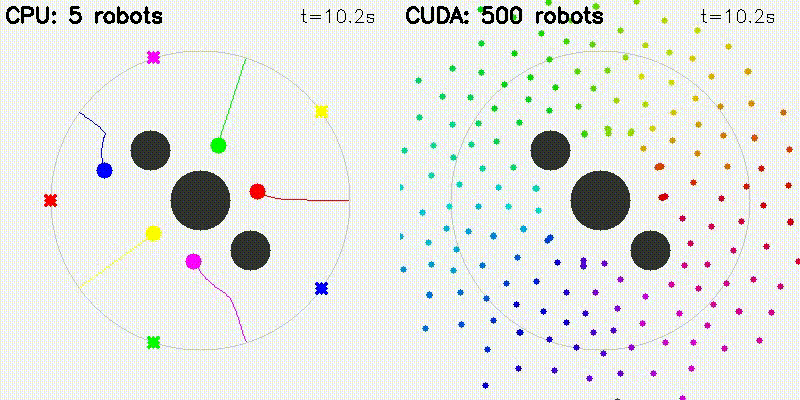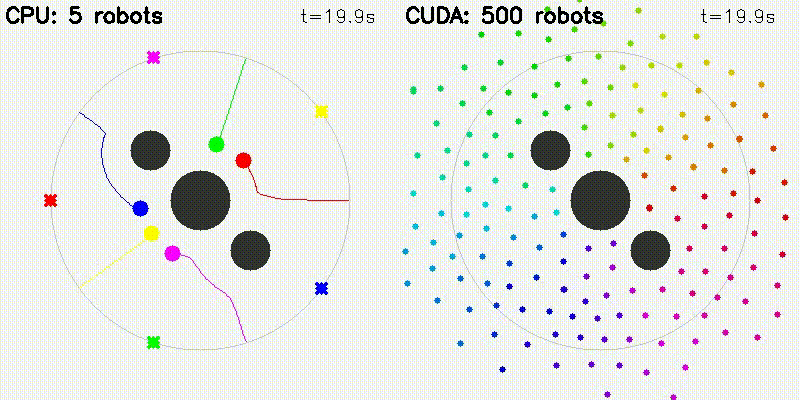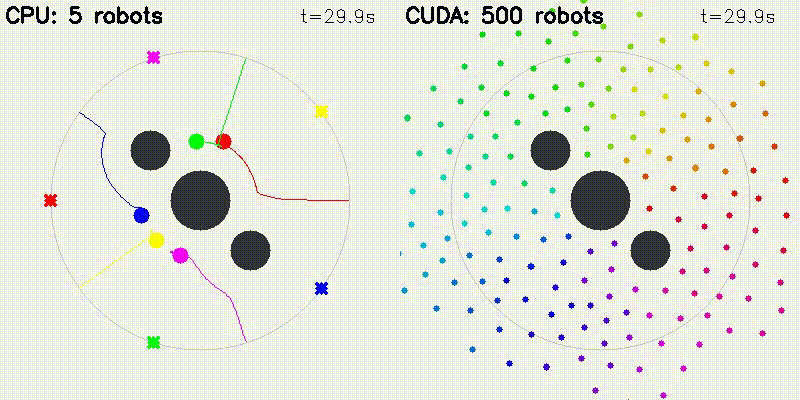
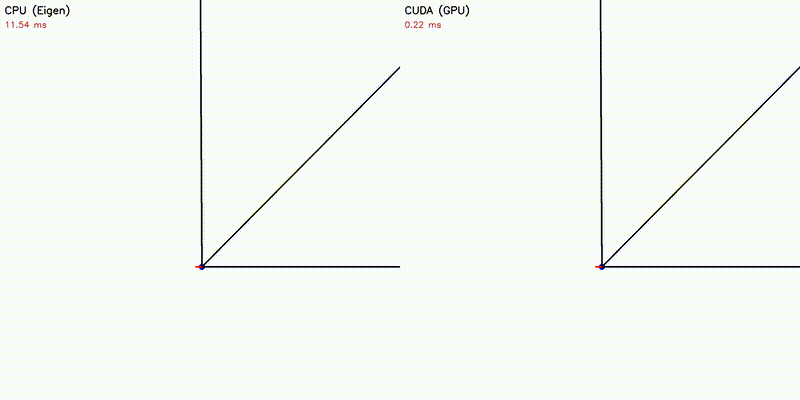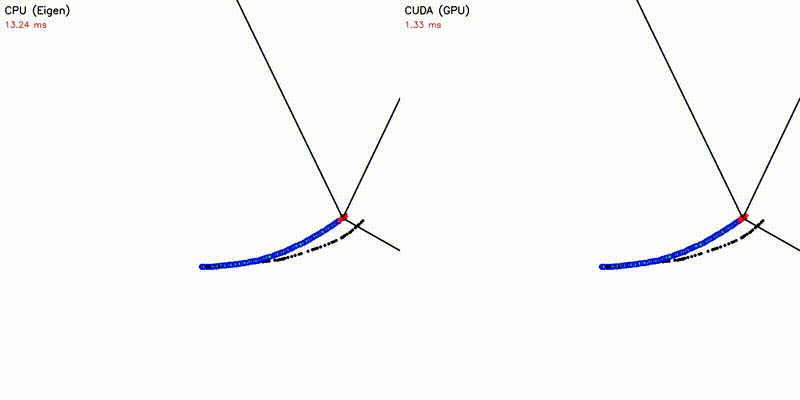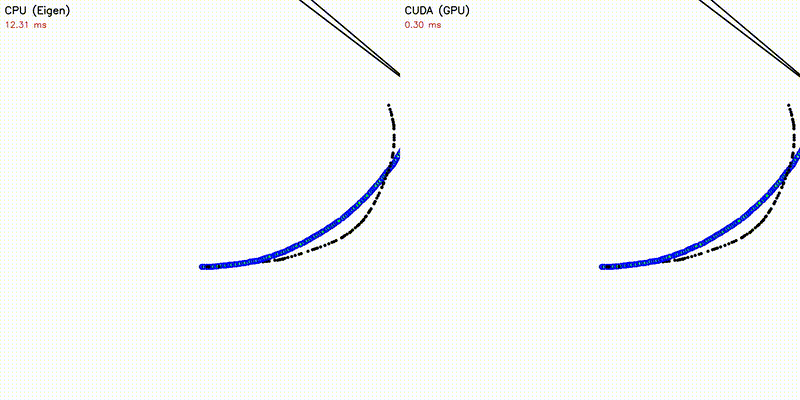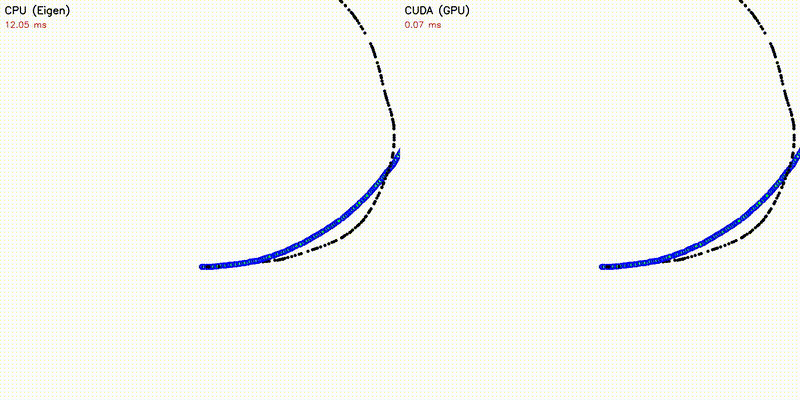
GPU enables orders-of-magnitude more particles/samples, resulting in visually better results. All comparisons below use the same algorithm on CPU and GPU — the only difference is sample/particle count enabled by GPU parallelism:
| Multi-Robot: CPU 5 robots vs CUDA 500 robots | Particle Filter: CPU 100 vs CUDA 10,000 particles |
 |
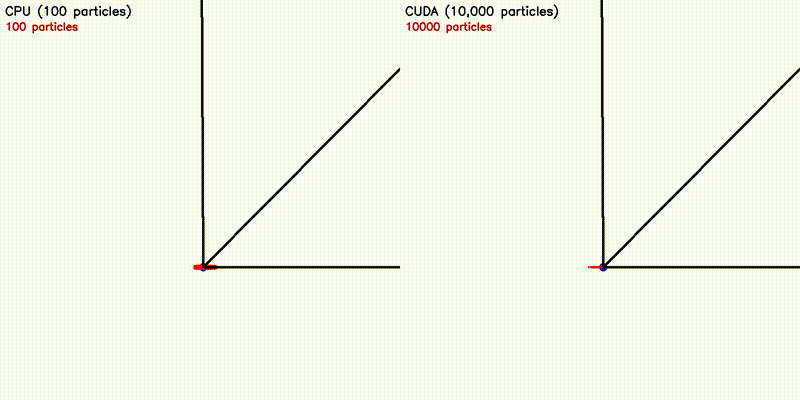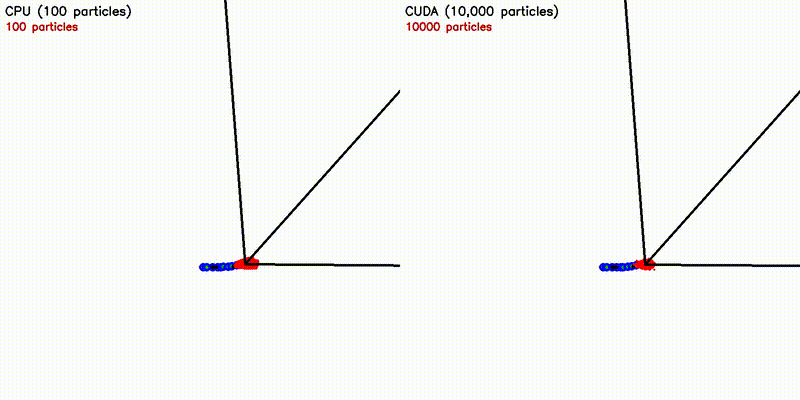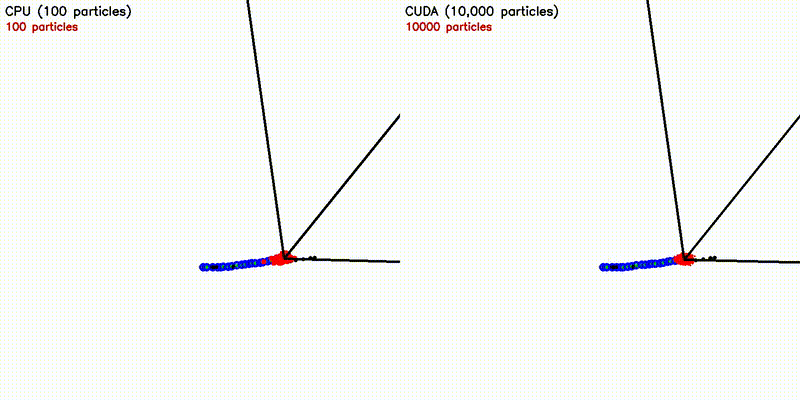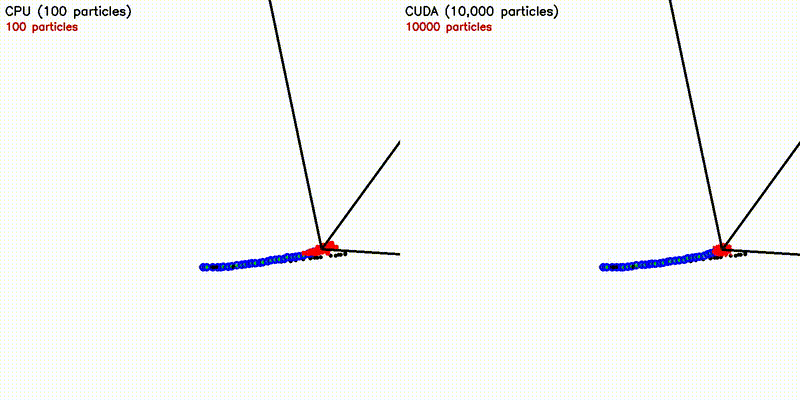 |
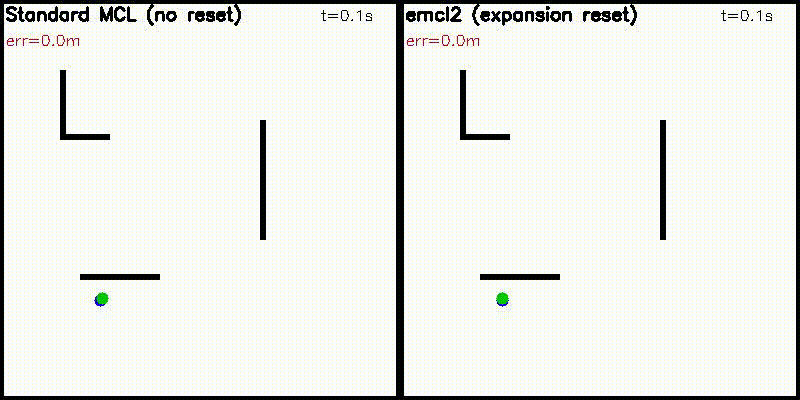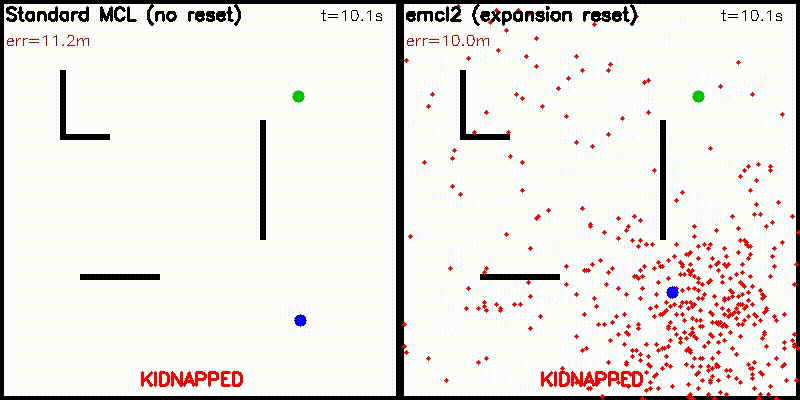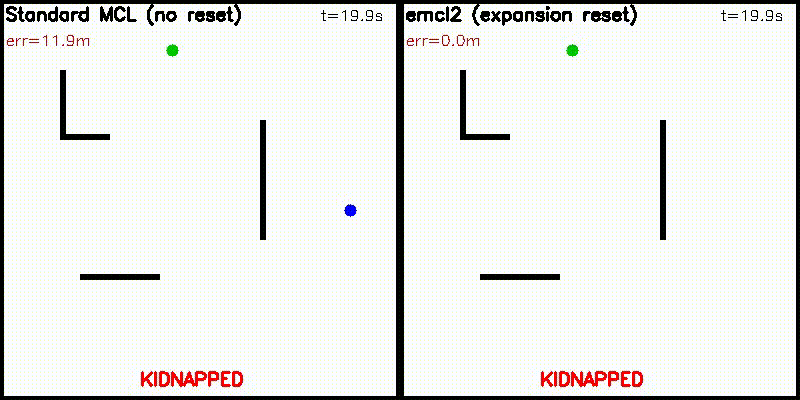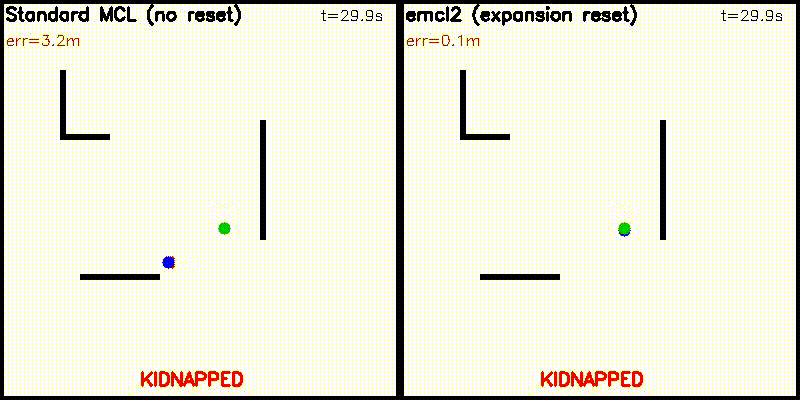
| DWA: CPU 50 vs CUDA 50,000 samples | emcl2: Standard MCL (fails) vs Expansion Reset (recovers) |
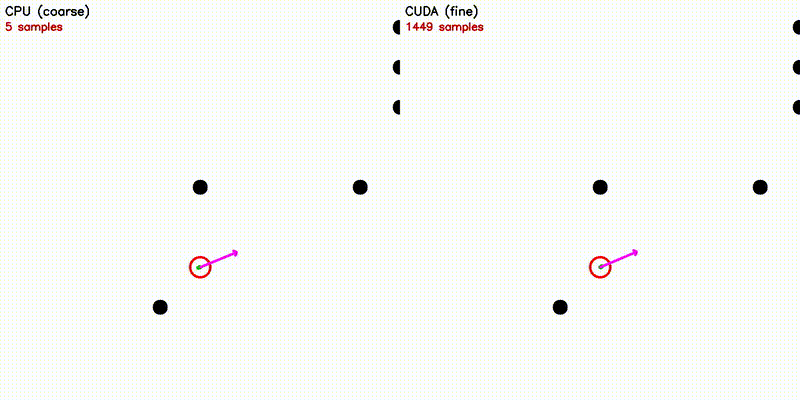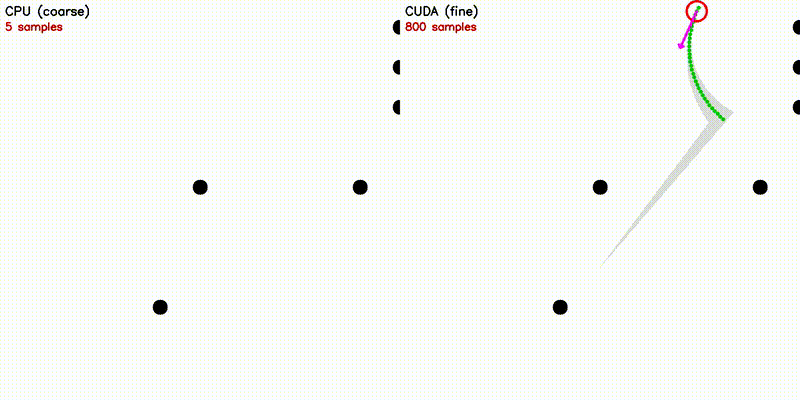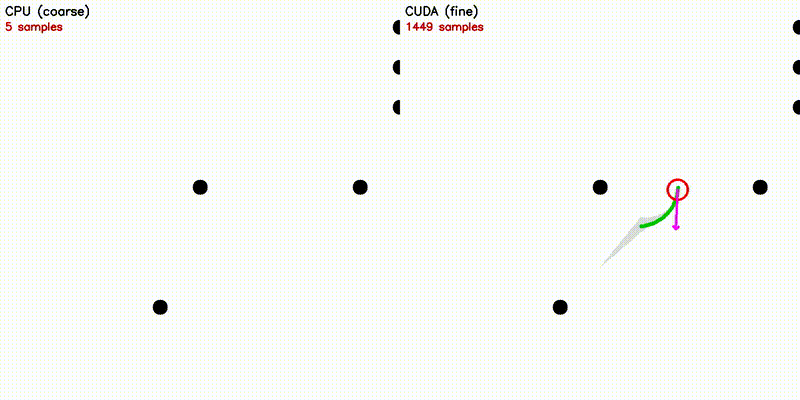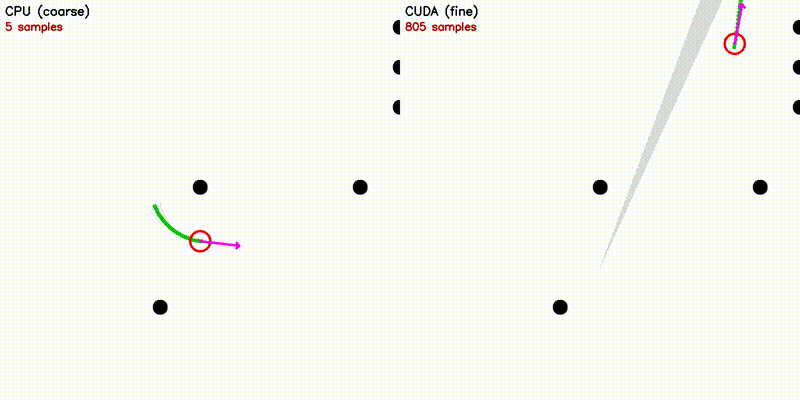 |
 |
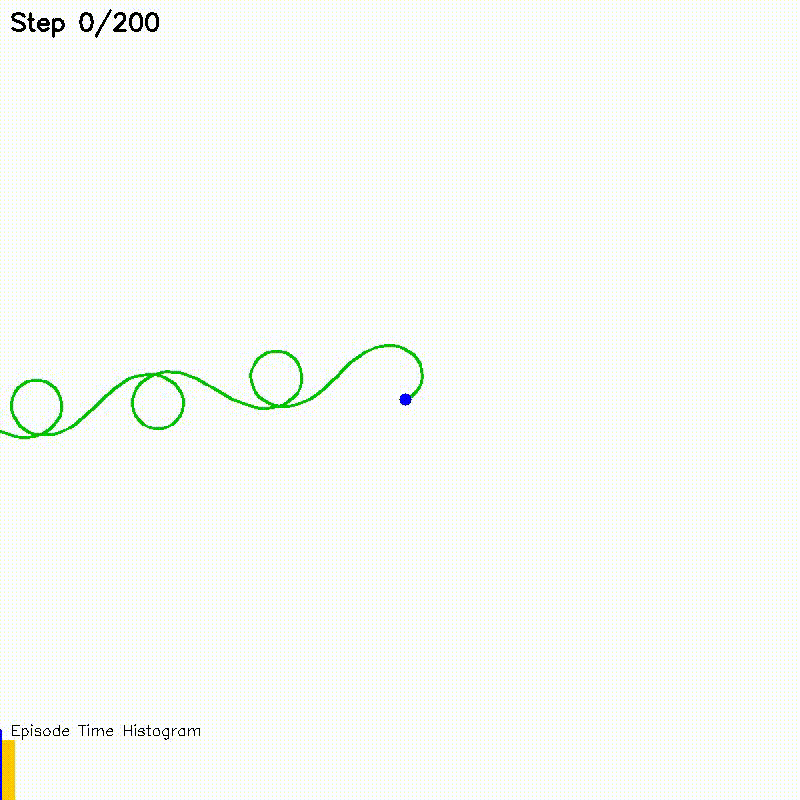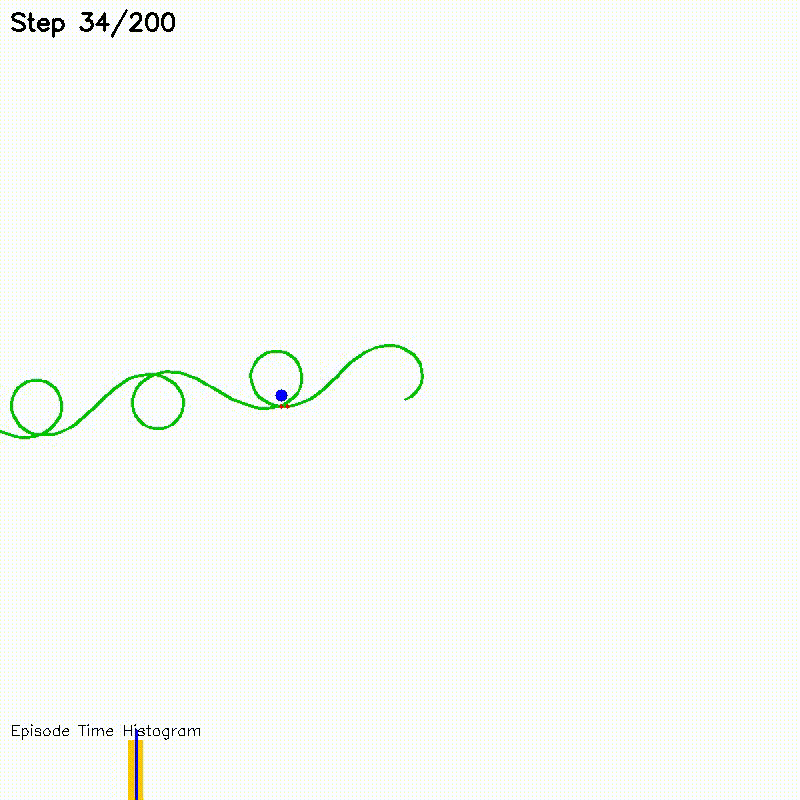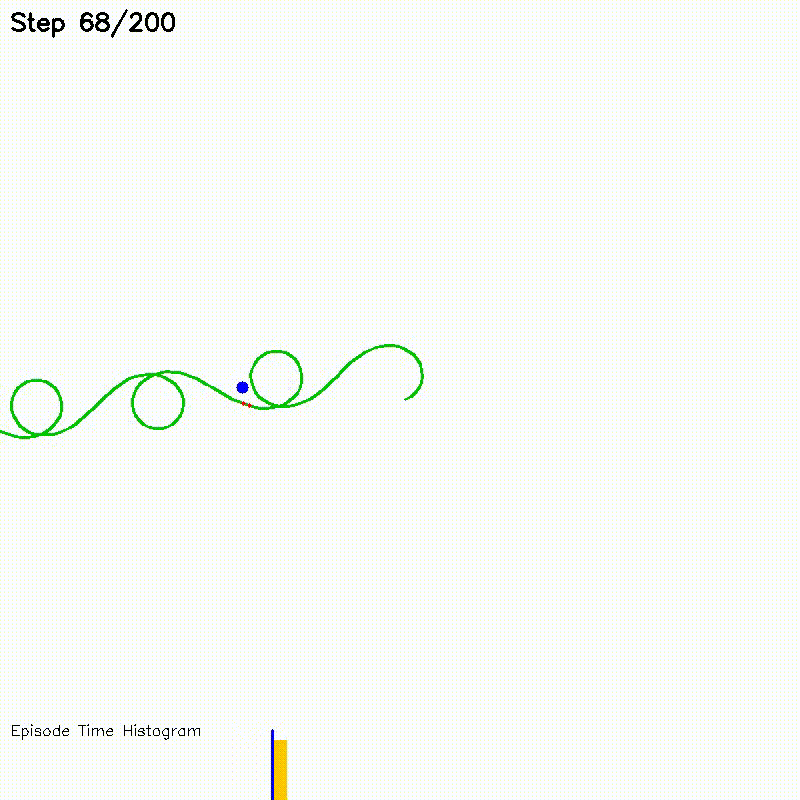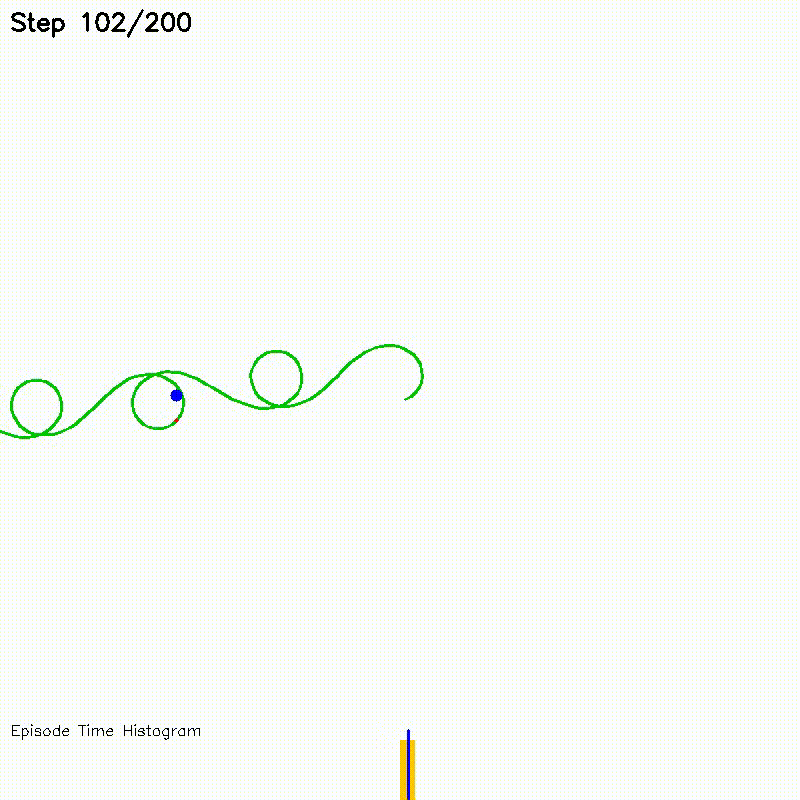
| Value Iteration: CPU vs CUDA convergence | Particle Filter on Episode (PFoE) |
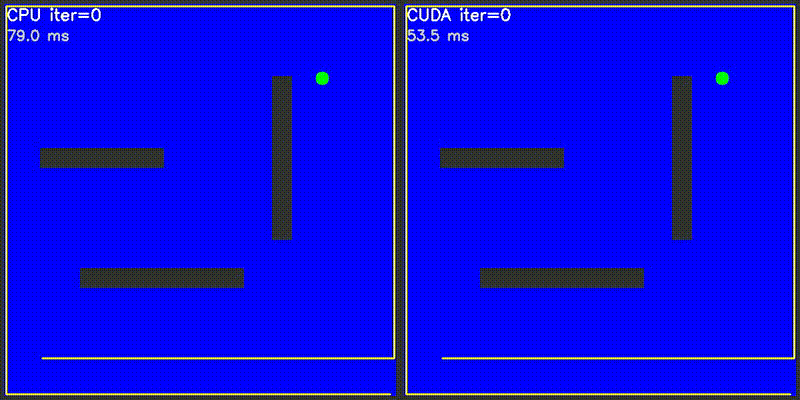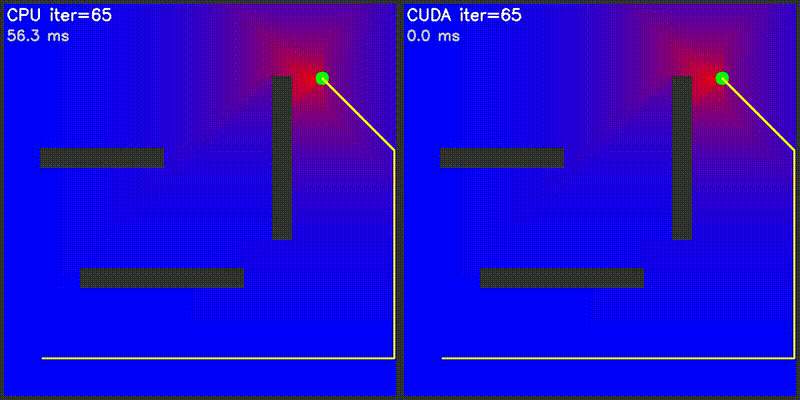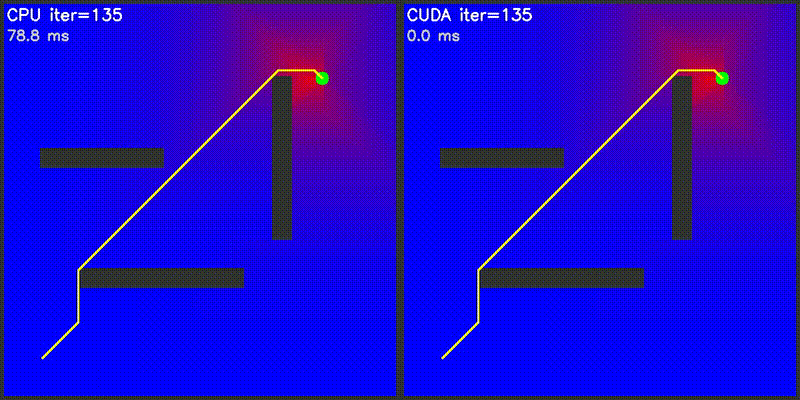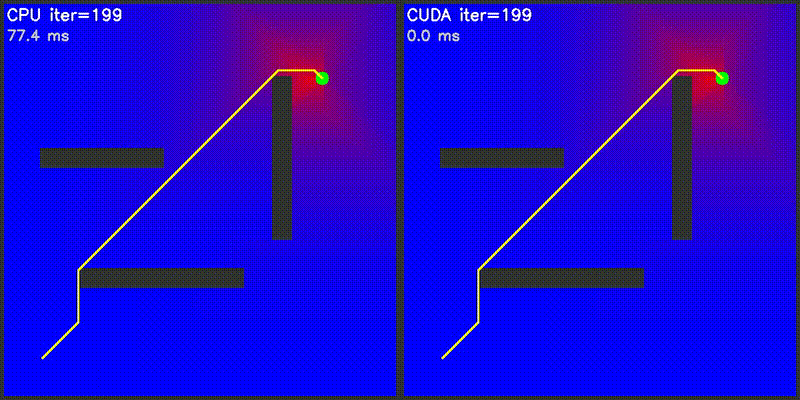 |
 |
All CPU vs CUDA speed comparisons (click to expand)
| 500 Robots Collision Avoidance | Particle Filter |
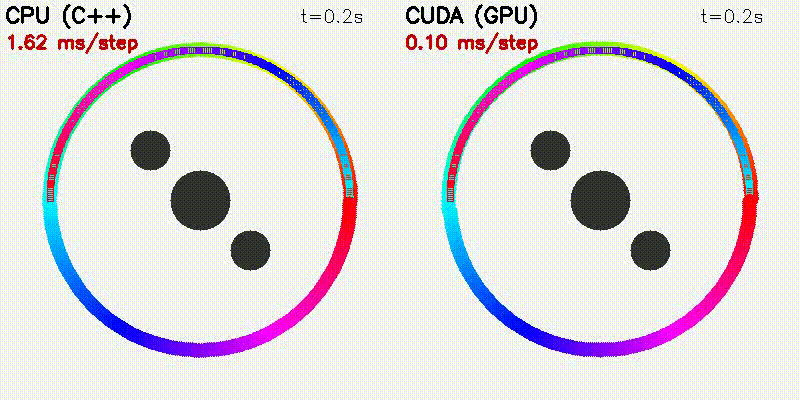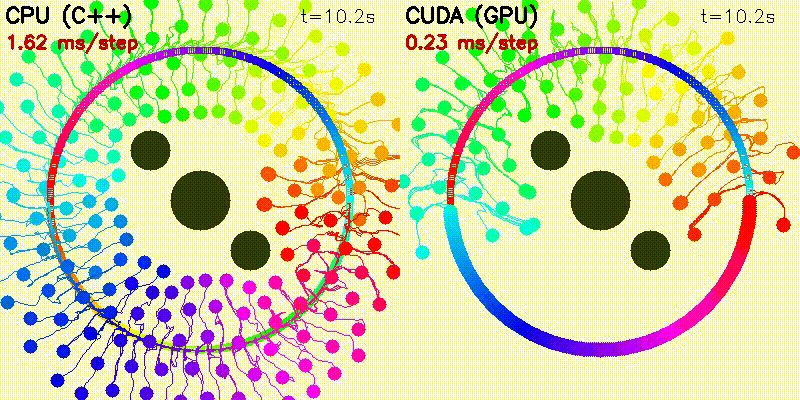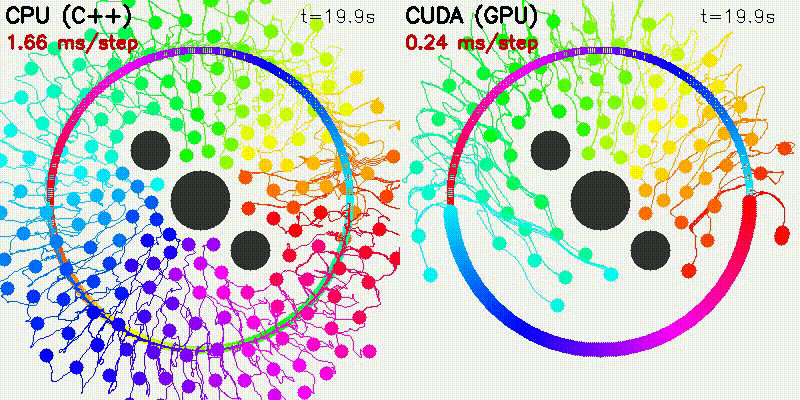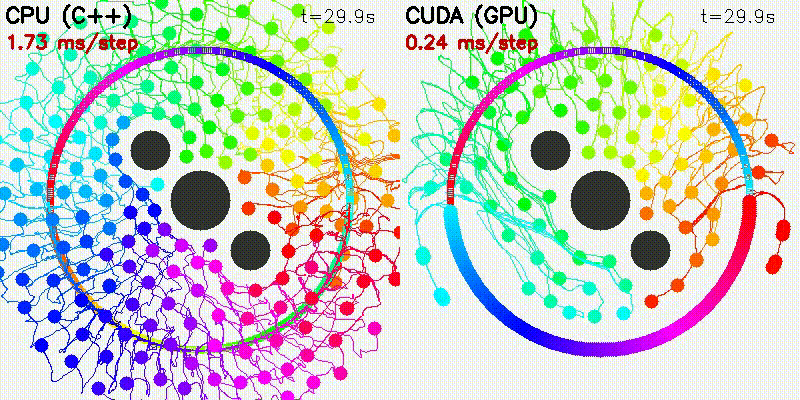 |
 |
| Dynamic Window Approach | Frenet Optimal Trajectory |
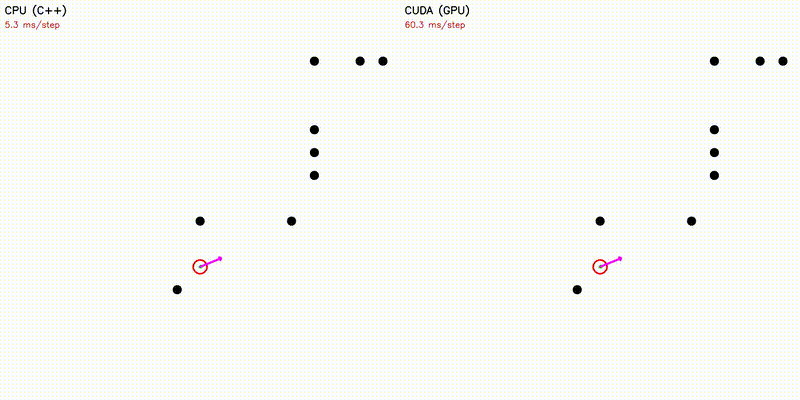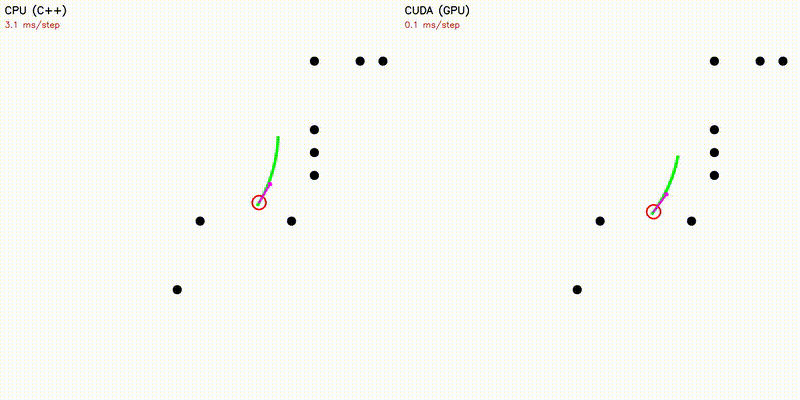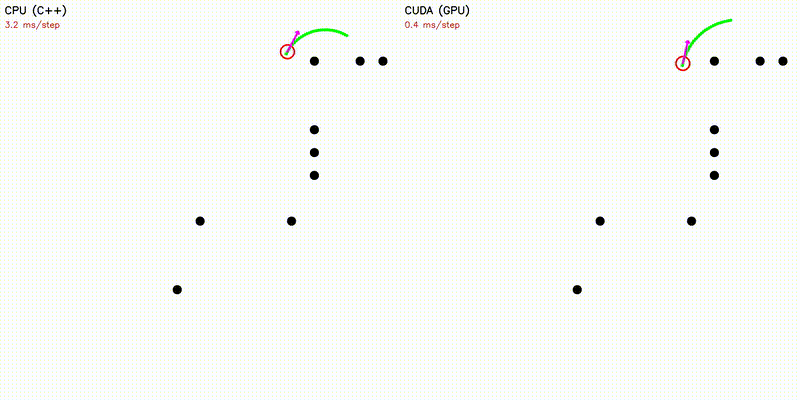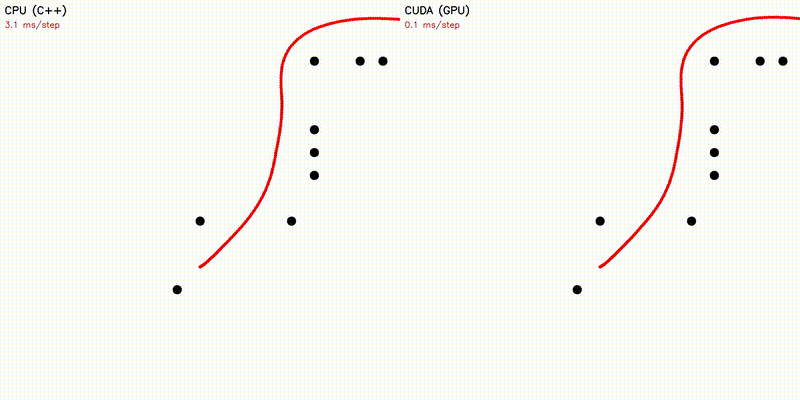 |
 |
| RRT | RRT* |
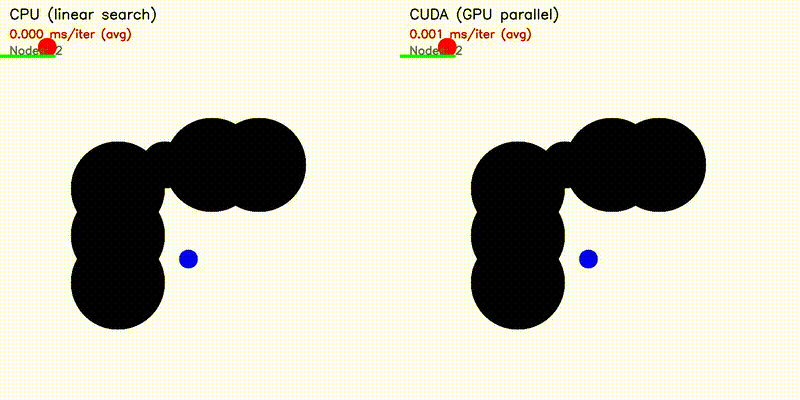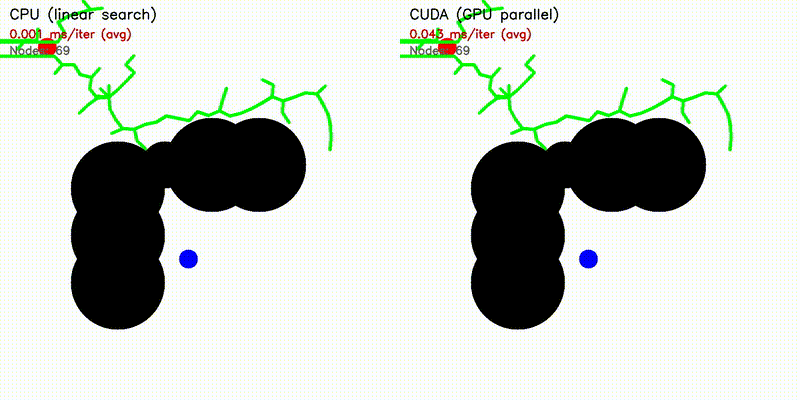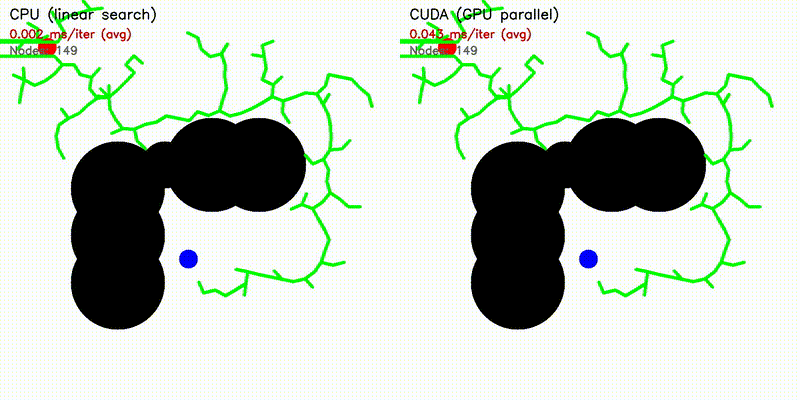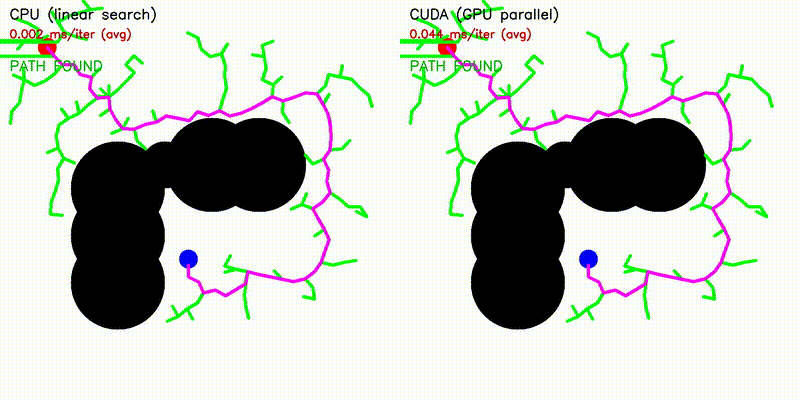 |
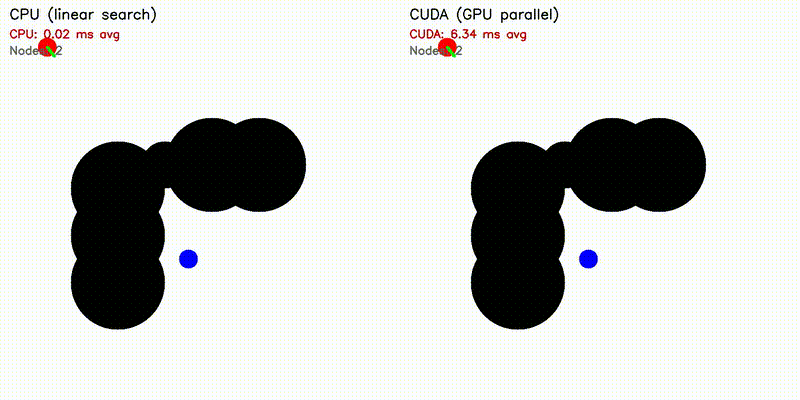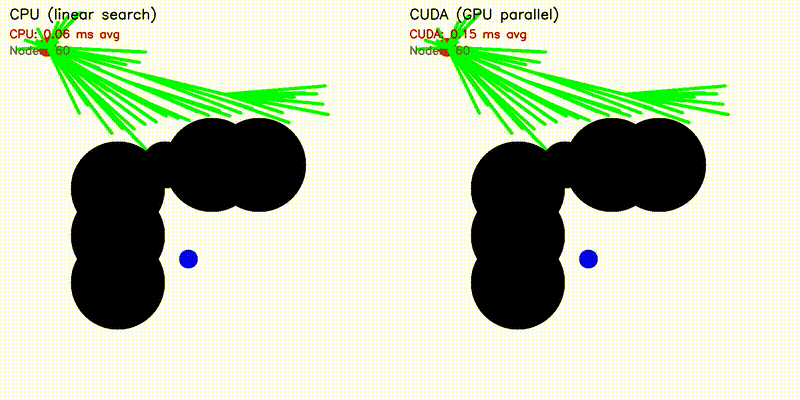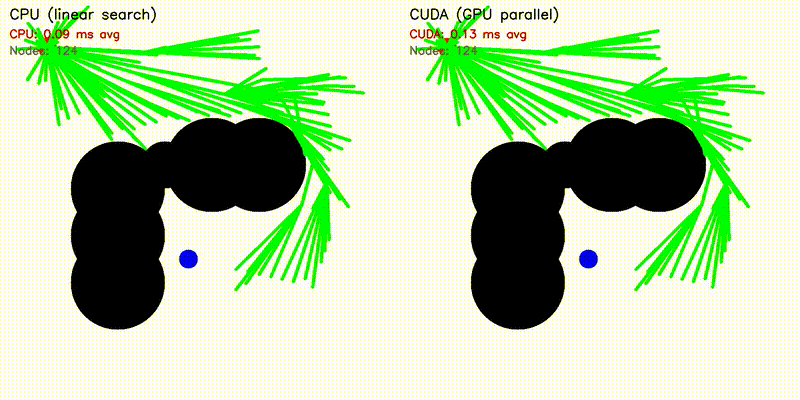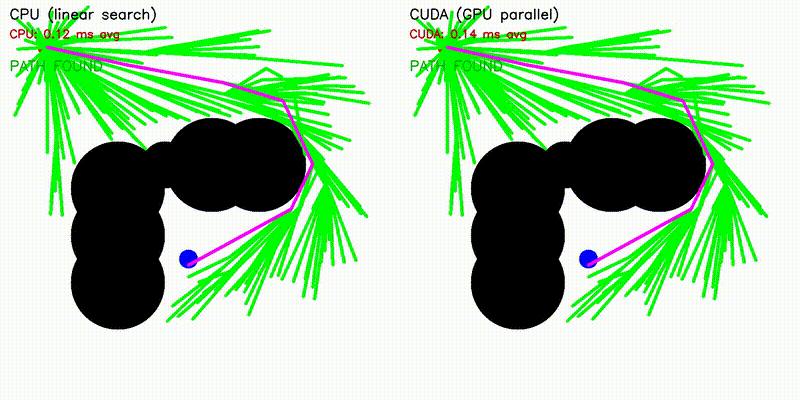 |
| A* | Dijkstra |
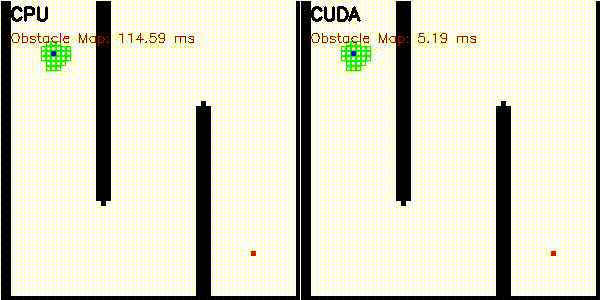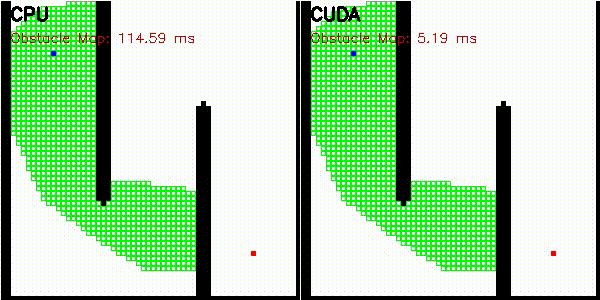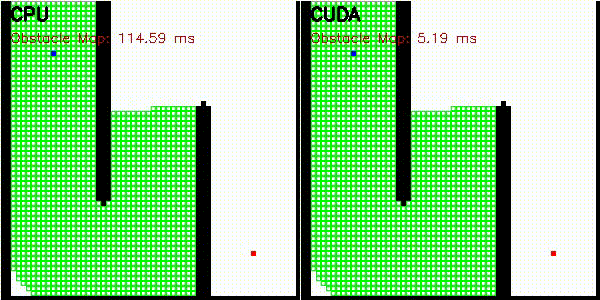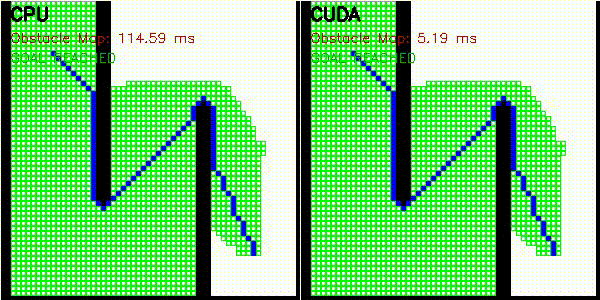 |
 |
| Potential Field | Voronoi Road Map |
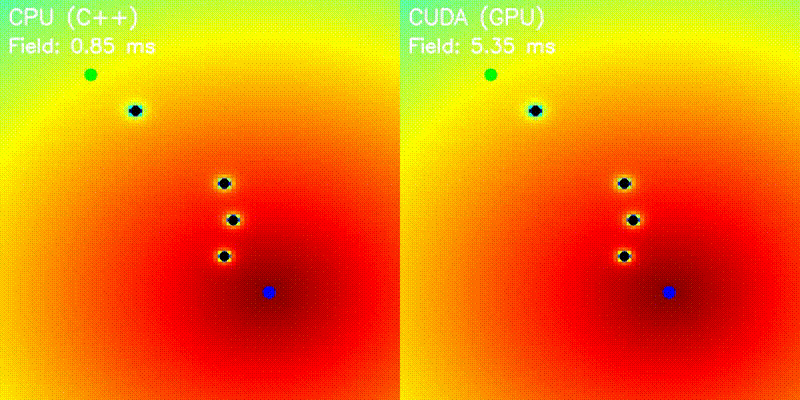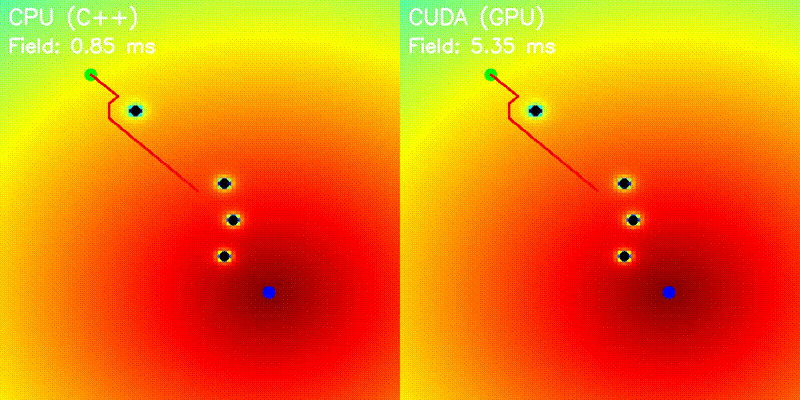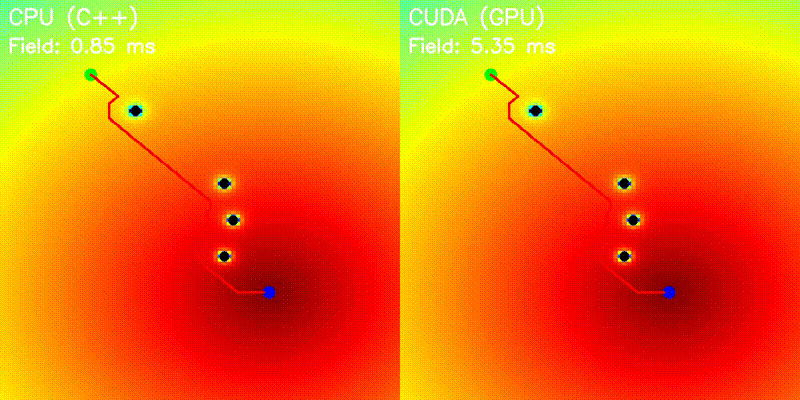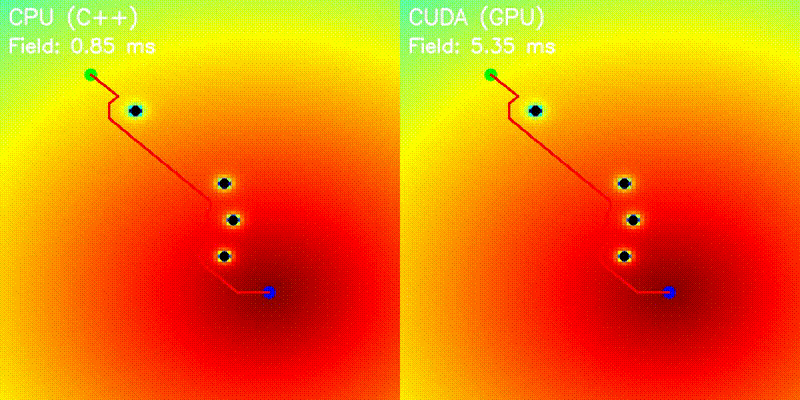 |
 |
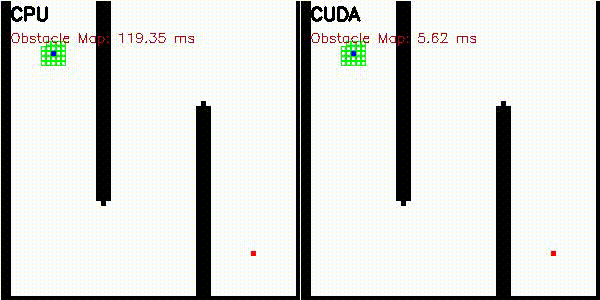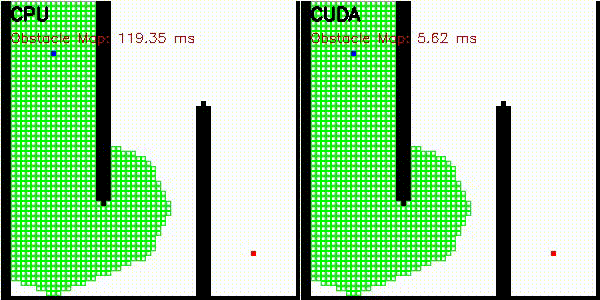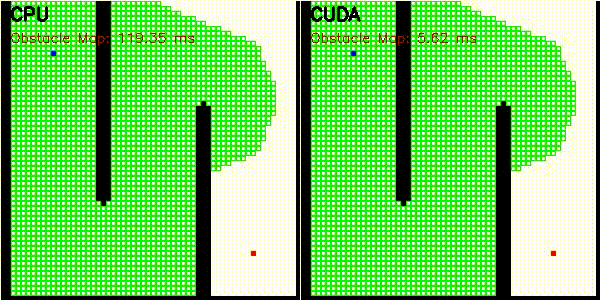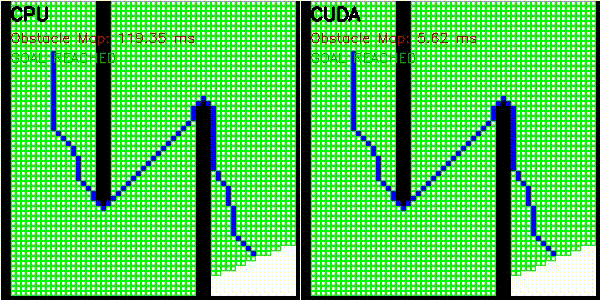
| 3D RRT (Drone)* | Occupancy Grid Mapping |
 |
 |
| FastSLAM 1.0 | AMCL |
 |
 |
Recent additions push the repository beyond direct CUDA ports of classic robotics algorithms into differentiable building blocks, GPU-native learning systems, point-cloud processing, and large-scale swarm optimization.
| Project | Binaries | Highlights |
|---|---|---|
| Autodiff + GPU MLP foundation | test_autodiff, test_gpu_mlp |
Dual-number forward-mode autodiff and a compact GPU MLP training/inference engine used as the base for later research-style experiments. |
| Differentiable MPPI | diff_mppi, comparison_diff_mppi, benchmark_diff_mppi, benchmark_diff_mppi_cartpole, benchmark_diff_mppi_dynamic_bicycle, benchmark_diff_mppi_manipulator, benchmark_diff_mppi_manipulator_7dof |
Augments MPPI with a short autodiff refinement stage. Evaluated on 2D dynamic-obstacle navigation, CartPole, dynamic-bicycle, 2-link planar arm, and 7-DOF serial arm. Includes 8 feedback baselines, matched-time tuning, mechanism analysis, and uncertainty follow-ups. On the hard dynamic_slalom task, the hybrid controller is the only method that succeeds under matched compute budgets across 6 non-hybrid baselines. |
| Neural SDF Navigation | neural_sdf, sdf_potential_field, sdf_mppi, comparison_sdf_nav |
Learns 2D signed distance fields with a GPU MLP, then uses them for potential-field planning and MPPI on non-circular obstacle layouts. |
| Neuroevolution for Cart-Pole | neuroevo, comparison_neuroevo |
Evolves 4096 neural policies in parallel on GPU and compares them against a CPU baseline with side-by-side learning curves. |
| MiniIsaacGym | mini_isaac, mini_isaac_rl |
Runs thousands of CartPole environments in parallel on GPU and trains a compact policy with GPU-side REINFORCE updates. |
| CudaPointCloud | voxel_grid_filter, statistical_filter, normal_estimation, gicp, ransac_plane, benchmark_pointcloud |
GPU voxel filtering, outlier removal, PCA normals, plane extraction, and GICP registration. Supports PLY/KITTI/XYZ file input. Normal estimation reaches 3,171x speedup at 10K points. |
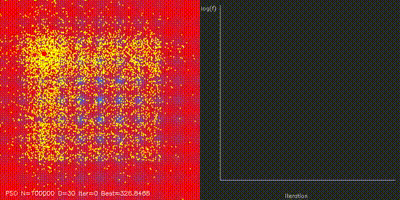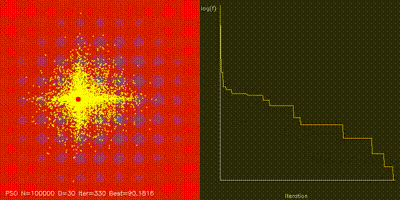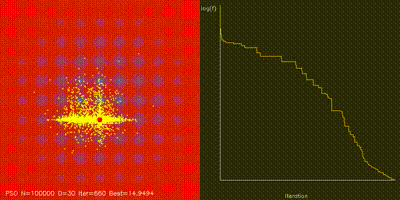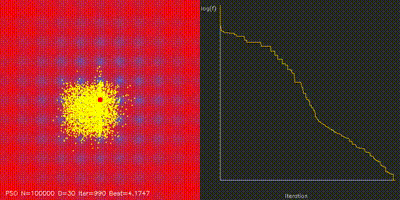
| Swarm Optimization | pso_cuda, differential_evolution, cma_es, aco_tsp, comparison_swarm |
Large-scale PSO, DE, CMA-ES, and ACO implementations with animated convergence comparisons. |
| MPPI vs Differentiable MPPI | Differentiable MPPI trajectory rollouts |
 |
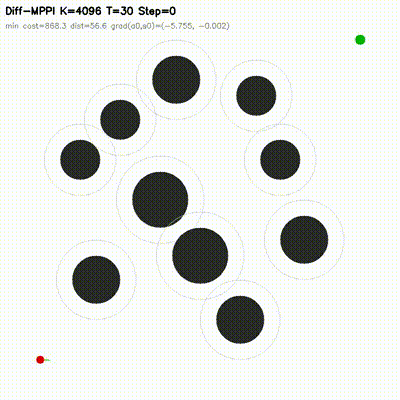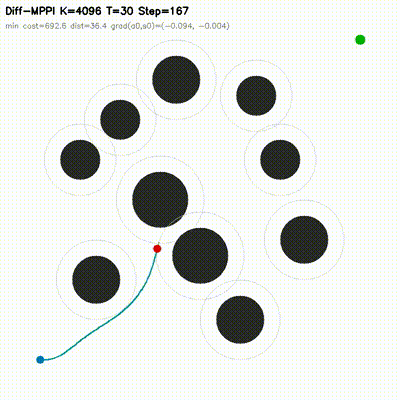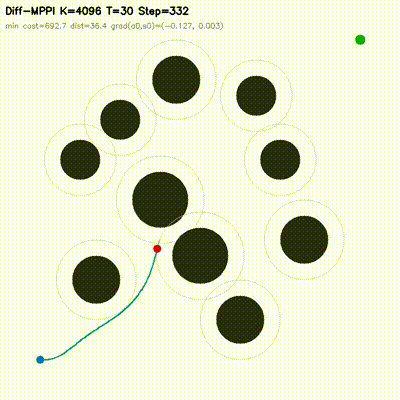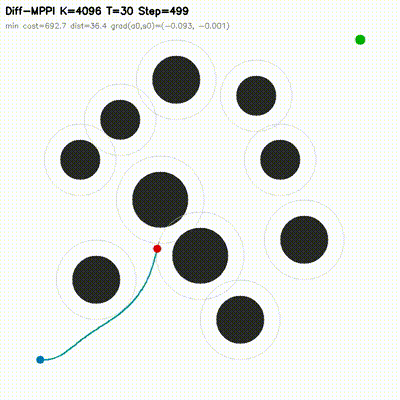 |
| Neural SDF vs true field | Neural SDF MPPI vs circle approximation |
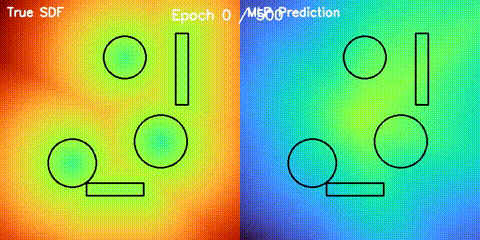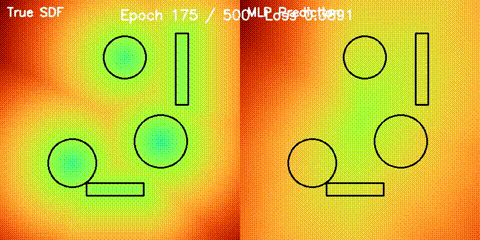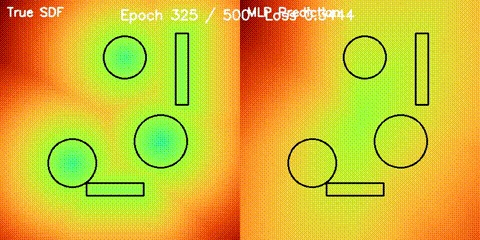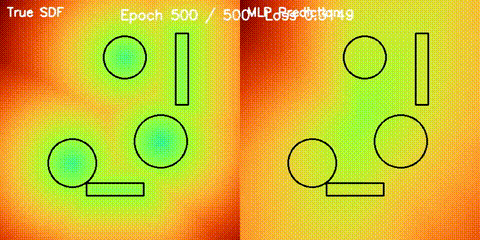 |
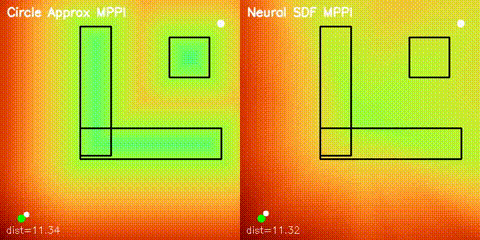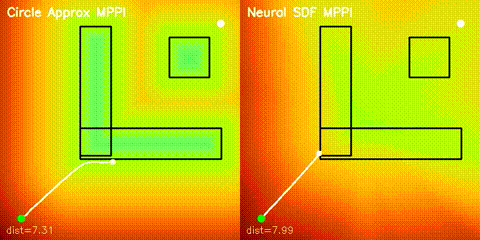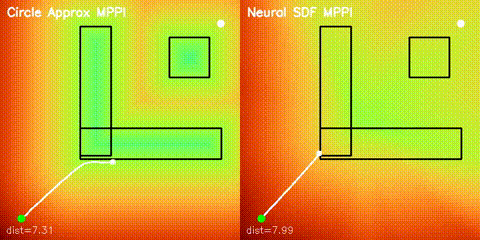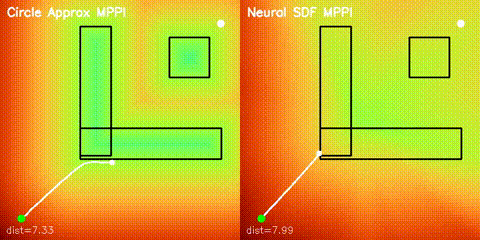 |
| Neural SDF potential-field navigation | Neural SDF MPPI rollout |
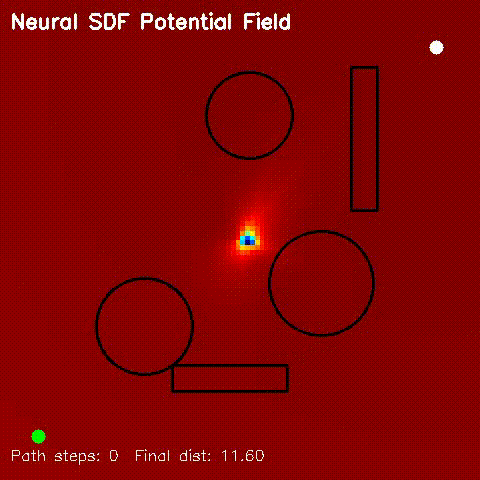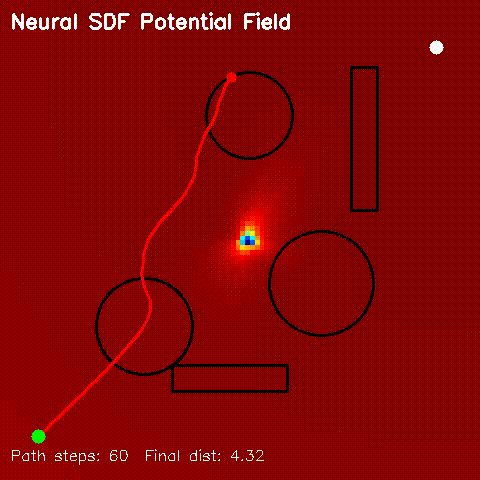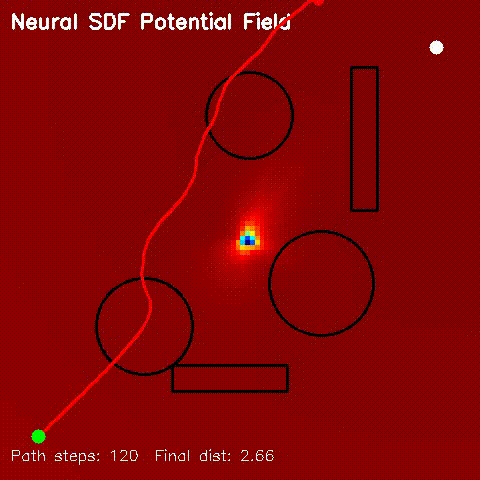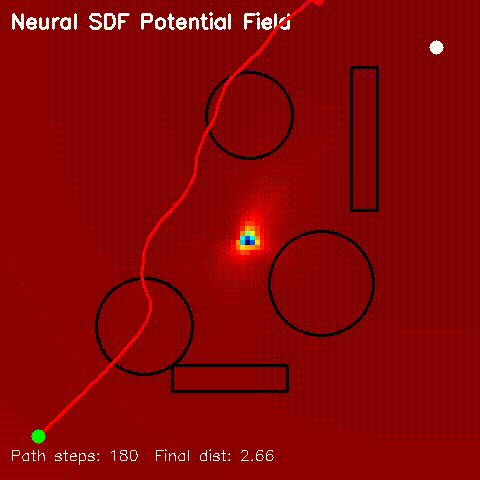 |
 |
| Neuroevolution: CPU 100 vs CUDA 4096 individuals | Swarm Optimization: PSO vs DE vs CMA-ES |
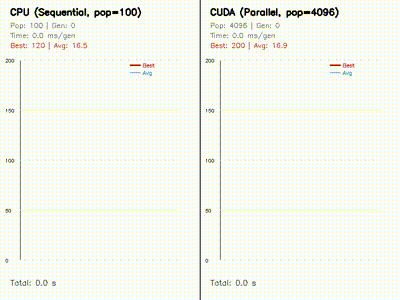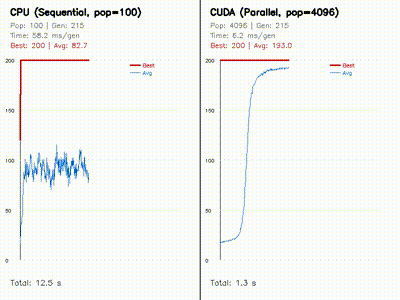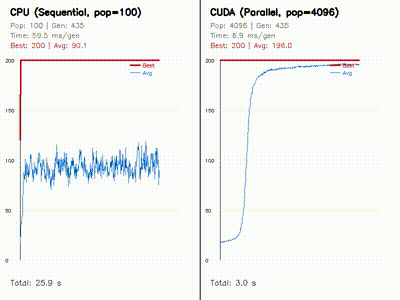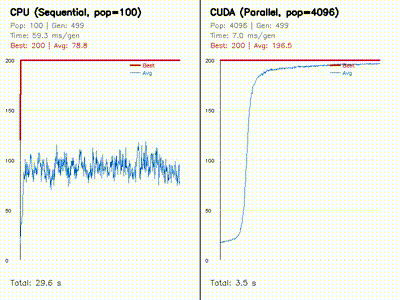 |
 |
| GPU Neuroevolution Cart-Pole replay | Particle Swarm Optimization |
 |
 |
| 4096-way CartPole simulation | MiniIsaacGym REINFORCE training |
 |
 |
| Ant Colony Optimization for TSP | |
 |
Recent research-style additions are summarized on the GitHub Pages gallery:
Concise highlights:
| Area | Key result |
|---|---|
| Diff-MPPI, dynamic navigation | At matched 1.0 ms budget on dynamic_slalom: diff_mppi_3 is the only successful controller (dist 1.91) across 6 non-hybrid baselines (best non-hybrid: feedback_mppi_fused at 10.30). |
| Diff-MPPI, 7-DOF manipulator | At K=512 on 7dof_dynamic_avoid: diff_mppi_3 reaches success=1.00 at 0.84 ms, while feedback_mppi_ref reaches 0.75 at 4.01 ms. The hybrid controller is 4.8x faster and more reliable. |
| Diff-MPPI, 2-link manipulator | On arm_static_shelf at K=256: feedback_mppi_ref and feedback_mppi_cov both reach success=1.00 at 0.15 final distance, while vanilla MPPI stays at 0.00. |
| Diff-MPPI, faithful baseline | A two-rate feedback_mppi_faithful variant with current-action-only gains fails even at K=8192 (2.1 ms), confirming that per-step replanning or hybrid refinement is necessary for dynamic-obstacle tasks. |
| Neural SDF navigation | Learned 2D SDFs with potential-field planning and MPPI rollouts on non-circular obstacle layouts. |
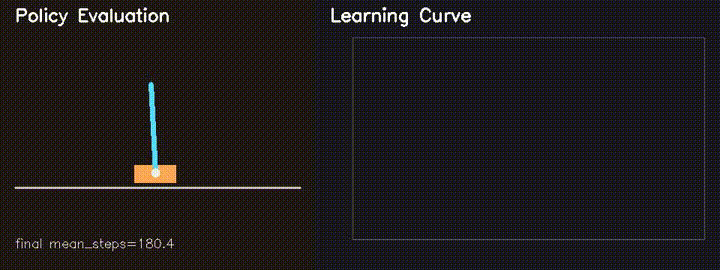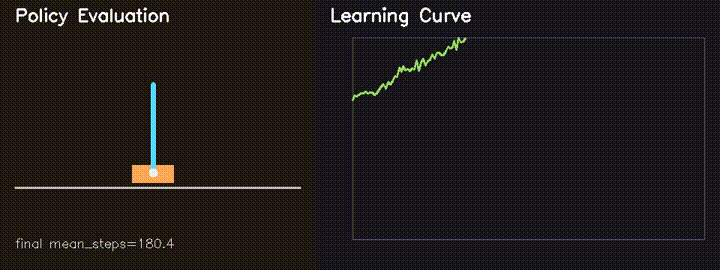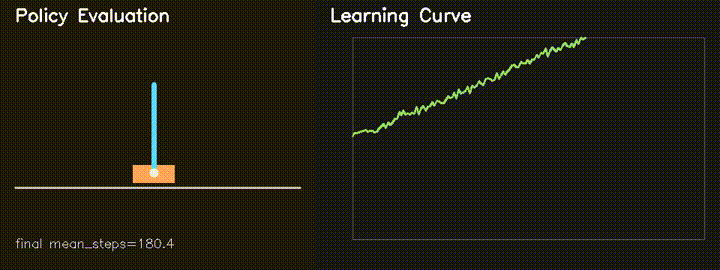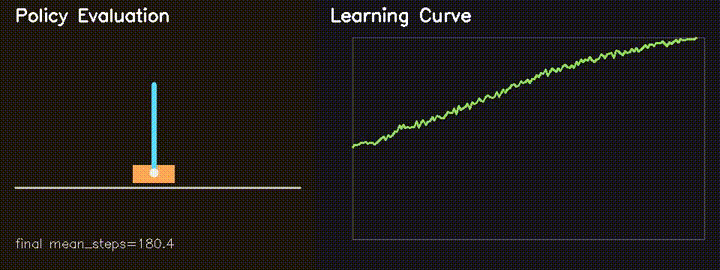
| MiniIsaacGym RL | GPU REINFORCE CartPole: average survival 82.6 to 180.4 steps in 160 generations. |
| CudaPointCloud | Normal estimation reaches 3,171x speedup at 10K points, RANSAC plane 547x at 100K. Supports --ply/--kitti/--xyz file input. |
| Swarm / neuroevolution | GPU PSO, DE, CMA-ES, ACO, and 4096-way neuroevolution with animated comparisons. |
Full experiment commands and detailed results (click to expand)
Fixed rollout budget:
./bin/benchmark_diff_mppi --quick
python3 scripts/summarize_diff_mppi.py --csv build/benchmark_diff_mppi.csv
python3 scripts/plot_diff_mppi.py --csv build/benchmark_diff_mppi.csv --out-dir build/plotsCap-based wall-clock sweep:
./bin/benchmark_diff_mppi --k-values 256,512,1024,2048,4096,6144,8192 --csv build/benchmark_diff_mppi_wall_clock.csv
python3 scripts/summarize_diff_mppi.py --csv build/benchmark_diff_mppi_wall_clock.csv --time-caps 1.1,1.5,2.0
python3 scripts/plot_diff_mppi.py --csv build/benchmark_diff_mppi_wall_clock.csv --out-dir build/plots --time-caps 1.1,1.5,2.0The benchmark writes per-episode CSV metrics, including the strengthened nominal-linearization feedback_mppi baseline, the release-style current-action feedback_mppi_ref baseline, the rollout-sensitivity feedback_mppi_sens baseline, the covariance-regression feedback_mppi_cov baseline, the heavier fused feedback_mppi_fused baseline, the lower-rate-replan feedback_mppi_hf baseline, and the grad_only_3 ablation. The summarizer emits Markdown and LaTeX tables for fixed-budget, cap-based wall-clock, and equal-time target comparisons, and the plotter generates PNG/PDF figures in build/plots/, including diff_mppi_final_distance_vs_time_cap.* and diff_mppi_final_distance_vs_equal_time.*. A reader-facing summary now lives in the README section above and on GitHub Pages; detailed local working notes remain under paper/.
Exact matched-time tuning:
python3 scripts/tune_diff_mppi_time_targets.py --preset dynamic_navThis search tunes K per planner and scenario to hit shared controller-time targets directly, instead of selecting the nearest value from a fixed sweep. The script writes tuned episode rows to build/benchmark_diff_mppi_exact_time.csv, a search trace to build/benchmark_diff_mppi_exact_time_search.csv, and a summary to build/benchmark_diff_mppi_exact_time_summary.md.
Mechanism analysis:
./bin/benchmark_diff_mppi --scenarios dynamic_slalom --planners mppi,feedback_mppi,diff_mppi_1,diff_mppi_3 --seed-count 1 --k-values 1024 --csv build/benchmark_diff_mppi_mechanism.csv --trace-csv build/benchmark_diff_mppi_mechanism_trace.csv --trace-max-steps 80
python3 scripts/plot_diff_mppi_mechanism.py --trace-csv build/benchmark_diff_mppi_mechanism_trace.csv --benchmark-csv build/benchmark_diff_mppi_feedback_dynamic_pair.csv --scenario dynamic_slalom --out-dir build/plots_mechanismThis trace workflow records the sampled nominal controls, final refined controls, and local control gradients for each episode step and horizon step. In the current dynamic_slalom trace at K=1024, diff_mppi_1 shows mean early-horizon correction 0.018 versus late-horizon correction 0.001, and diff_mppi_3 shows 0.025 versus 0.001, with peak first-action corrections 0.032 and 0.047. That front-loaded profile supports the intended interpretation: the autodiff stage mostly sharpens the near-term controls that are actually executed, rather than replacing the whole sampled plan.
Dynamic-obstacle follow-up:
./bin/benchmark_diff_mppi --scenarios dynamic_crossing,dynamic_slalom --k-values 256,512,1024,2048,4096,6144,8192 --csv build/benchmark_diff_mppi_feedback_dynamic_pair.csv
python3 scripts/summarize_diff_mppi.py --csv build/benchmark_diff_mppi_feedback_dynamic_pair.csv --time-caps 1.0,1.5 --time-targets 1.0,1.5
python3 scripts/plot_diff_mppi.py --csv build/benchmark_diff_mppi_feedback_dynamic_pair.csv --out-dir build/plots_feedback_dynamic_pair --time-caps 1.0,1.5 --time-targets 1.0,1.5This follow-up now includes two moving-obstacle tasks, a strengthened nominal-linearization feedback_mppi baseline, a release-style current-action feedback_mppi_ref baseline, a release-weighting feedback_mppi_release baseline, a rollout-sensitivity feedback_mppi_sens baseline, a covariance-regression feedback_mppi_cov baseline, a heavier fused feedback_mppi_fused baseline, a closer low-rate-replan feedback_mppi_hf execution baseline, the earlier grad_only_3 ablation, and exact-time tuning presets for the lighter, release-style, covariance, architecture-gap, and heavy-feedback comparisons. In the current fixed-budget benchmark, all seven feedback baselines improve over vanilla MPPI on dynamic_crossing; at K=256, feedback_mppi_fused is still the strongest current feedback row at success=1.00 and final_distance=1.87 versus mppi at 0.00 / 3.04, while feedback_mppi_ref reaches 1.00 / 1.90 at 0.62 ms and the newer feedback_mppi_release reaches 1.00 / 1.86 at 0.61 ms. On the harder dynamic_slalom, none of the feedback baselines solve the task, and feedback_mppi_release shows why matching the released weighting alone is not enough: at K=256 it drifts to final_distance=19.12, while feedback_mppi_ref reaches 11.87, feedback_mppi_cov reaches 11.49, feedback_mppi_hf reaches 13.62, feedback_mppi_fused remains the strongest non-hybrid controller at 10.28, and Diff-MPPI remains successful at 1.89. The new feedback_mppi_ref line is useful because it is materially closer to the released Feedback-MPPI gain computation: it uses rollout initial-state sensitivities and a current-action covariance update rather than a full horizon tracker. The newer feedback_mppi_release line moves one step closer again by matching the released weight update shape, and it confirms that this closer proxy helps on the easier task without closing the hard-task gap. Under a 1.0 ms cap, feedback_mppi_release lowers terminal distance from 3.04 -> 1.93 on dynamic_crossing, but on dynamic_slalom it remains at 19.11; the same cap for feedback_mppi_ref gives 1.87 and 11.89. A targeted exact-time sweep now shows the same qualitative behavior at shared controller times: feedback_mppi_ref tunes to K=1263 @ 1.002 ms and K=2362 @ 1.482 ms on dynamic_crossing, reaching final distances 1.95 and 1.89, and to K=1150 @ 1.023 ms and K=2190 @ 1.472 ms on dynamic_slalom, reaching 11.89 in both cases; feedback_mppi_release tunes to K=1062 @ 1.009 ms and K=2173 @ 1.530 ms on dynamic_crossing, reaching 1.93 and 1.90, but to K=901 @ 1.007 ms and K=2033 @ 1.530 ms on dynamic_slalom, where it stays near 19.11-19.13. The feedback_mppi_cov line now has exact-time rows too: K=219 @ 1.474 ms and K=292 @ 1.964 ms on dynamic_crossing reach 1.92 and 1.91, while K=211 @ 1.490 ms and K=293 @ 1.971 ms on dynamic_slalom reach 11.72 and 11.68. The feedback_mppi_hf line is still useful because it narrows the controller-architecture gap by reusing local gains between replans instead of running the full solver every step; exact-time tuning now lands it near K=285 @ 0.978 ms, K=368 @ 1.486 ms, and K=443 @ 1.989 ms on dynamic_crossing, and K=276 @ 0.989 ms, K=369 @ 1.498 ms, and K=441 @ 1.980 ms on dynamic_slalom. The heavier feedback_mppi_fused line now also has a targeted 2.0 ms exact-time spot check: K=153 @ 1.968 ms on dynamic_crossing gives success=1.00, final_distance=1.94, while K=137 @ 1.993 ms on dynamic_slalom gives final_distance=10.51. This is still intentionally described as "closer" rather than "faithful": feedback_mppi_ref narrows the released-gain gap, feedback_mppi_release narrows the released-weighting gap, feedback_mppi_cov narrows the covariance-gain gap, feedback_mppi_hf narrows the controller-architecture gap, and feedback_mppi_fused narrows the gain-estimation gap, but none reproduces the full controller stack of the recent literature. The current write-up is in paper/diff_mppi_novelty_followup.md, and the current ICRA/IROS submission-gap assessment is in paper/icra_iros_gap_list.md.
Uncertainty follow-up:
./bin/benchmark_diff_mppi --scenarios uncertain_crossing,uncertain_slalom --planners mppi,feedback_mppi,diff_mppi_1,diff_mppi_3 --seed-count 4 --k-values 256,512,1024,2048,4096,6144,8192 --csv build/benchmark_diff_mppi_uncertain.csv
python3 scripts/summarize_diff_mppi.py --csv build/benchmark_diff_mppi_uncertain.csv --markdown-out build/benchmark_diff_mppi_uncertain_summary.md --latex-out build/benchmark_diff_mppi_uncertain_summary.tex --time-caps 1.0,1.5 --time-targets 1.0,1.5
python3 scripts/plot_diff_mppi.py --csv build/benchmark_diff_mppi_uncertain.csv --out-dir build/plots_uncertain --time-caps 1.0,1.5 --time-targets 1.0,1.5
python3 scripts/tune_diff_mppi_time_targets.py --preset uncertain_dynamic_navThis follow-up keeps the planner on the nominal dynamic-obstacle model while executing each episode against a seed-dependent perturbed obstacle trajectory. The perturbation changes obstacle time offset, speed scale, and lateral offset, so the benchmark is a mild model-mismatch study rather than a full partial-observation benchmark. The current result is strong enough to be useful in rebuttal: at fixed budget and under exact matched-time tuning, mppi remains unsuccessful on both uncertain_crossing and uncertain_slalom, feedback_mppi recovers the easier uncertain crossing task but still fails uncertain slalom, and Diff-MPPI remains successful on both. Representative 1.00 ms rows are uncertain_crossing: mppi K=7584, dist=2.97; feedback_mppi K=2087, dist=1.87; diff_mppi_1 K=5457, dist=1.89 and uncertain_slalom: mppi K=7524, dist=14.17; feedback_mppi K=2058, dist=11.82; diff_mppi_3 K=346, dist=1.92. The current write-up is in paper/diff_mppi_uncertainty_followup.md.
Hybrid-versus-gradient-only ablation:
./bin/benchmark_diff_mppi --scenarios corner_turn,dynamic_crossing --seed-count 4 --k-values 256,512,1024,2048,4096,6144,8192 --csv build/benchmark_diff_mppi_ablation.csv
python3 scripts/summarize_diff_mppi.py --csv build/benchmark_diff_mppi_ablation.csv --time-caps 1.0,1.5 --time-targets 1.0,1.5
python3 scripts/plot_diff_mppi.py --csv build/benchmark_diff_mppi_ablation.csv --out-dir build/plots_ablation --time-caps 1.0,1.5 --time-targets 1.0,1.5This ablation isolates whether local gradients alone explain the gains. In the current benchmark, grad_only_3 improves corner_turn slightly over vanilla MPPI but fails the dynamic_crossing task completely, while the hybrid Diff-MPPI variants remain successful.
Outside-domain CartPole follow-up:
./bin/benchmark_diff_mppi_cartpole --csv build/benchmark_diff_mppi_cartpole.csv
python3 scripts/summarize_diff_mppi.py --csv build/benchmark_diff_mppi_cartpole.csv --markdown-out build/benchmark_diff_mppi_cartpole_summary.md --latex-out build/benchmark_diff_mppi_cartpole_summary.tex --time-caps 0.25,0.5,0.75 --time-targets 0.25,0.5
python3 scripts/plot_diff_mppi.py --csv build/benchmark_diff_mppi_cartpole.csv --out-dir build/plots_cartpole --time-caps 0.25,0.5,0.75 --time-targets 0.25,0.5This pilot benchmark reuses the repository's nonlinear CartPole dynamics to test Diff-MPPI outside the 2D kinematic navigation setting. The current result is mixed by design rather than oversold: on cartpole_recover, diff_mppi_3 improves over vanilla MPPI at K=256 and K=2048, while on cartpole_large_angle the best Diff-MPPI variant slightly lowers terminal stabilization error at K=512 and K=1024 but none of the planners fully solve the task. This partially addresses the "2D-only" reviewer concern, but it is still a pilot underactuated-dynamics benchmark rather than a full high-fidelity robotics evaluation. The current write-up is in paper/diff_mppi_cartpole_followup.md.
Dynamic-bicycle mobile-navigation follow-up:
./bin/benchmark_diff_mppi_dynamic_bicycle --csv build/benchmark_diff_mppi_dynamic_bicycle.csv
python3 scripts/summarize_diff_mppi.py --csv build/benchmark_diff_mppi_dynamic_bicycle.csv --markdown-out build/benchmark_diff_mppi_dynamic_bicycle_summary.md --latex-out build/benchmark_diff_mppi_dynamic_bicycle_summary.tex --time-caps 0.1,0.7,1.8 --time-targets 0.1,0.7,1.8
python3 scripts/plot_diff_mppi.py --csv build/benchmark_diff_mppi_dynamic_bicycle.csv --out-dir build/plots_dynamic_bicycle --time-caps 0.1,0.7,1.8 --time-targets 0.1,0.7,1.8
python3 scripts/tune_diff_mppi_time_targets.py --preset dynamic_bicycleThis follow-up adds a higher-order mobile-navigation benchmark with steering lag, drag, static obstacles, and moving obstacles. The default sweep focuses on the low-budget regime K={32,64,128,256}, where transfer is most informative. It now includes the closer feedback_mppi_sens baseline as well as mppi, diff_mppi_1, and diff_mppi_3. The current fixed-budget result is intentionally narrow: at dynbike_crossing, feedback_mppi_sens is a real efficiency baseline, reducing K=32 steps and cumulative cost from 196.0 / 2295.9 to 186.2 / 2099.2 with essentially unchanged terminal distance, while at dynbike_slalom the clearest low-budget rescue is still hybrid refinement, with diff_mppi_1 lifting K=32 from success=0.75 and final_distance=12.60 to success=1.00 and final_distance=2.24. At K=128 and K=256 on dynbike_slalom, feedback_mppi_sens becomes a strong efficiency competitor too, reducing steps from 255.2 -> 230.8 and 253.2 -> 236.8 with near-identical terminal distance. A reviewer-facing exact-time spot check is also available via python3 scripts/tune_diff_mppi_time_targets.py --preset dynamic_bicycle --time-targets 1.8; in that compute-matched setting, mppi, feedback_mppi_sens, and diff_mppi_1 are all competitive on terminal distance, and feedback_mppi_sens reaches dynbike_slalom with K=248 instead of K=12855 while using 17 fewer steps (2.21 -> 2.25 final distance). This should be read as a stronger mobile-dynamics pilot rather than as a closed high-fidelity evaluation gap. The current write-up is in paper/diff_mppi_dynamic_bicycle_followup.md.
Planar-manipulator follow-up:
./bin/benchmark_diff_mppi_manipulator --seed-count 4 --k-values 256,512 --csv build/benchmark_diff_mppi_manipulator.csv
python3 scripts/summarize_diff_mppi.py --csv build/benchmark_diff_mppi_manipulator.csv --markdown-out build/benchmark_diff_mppi_manipulator_summary.md --latex-out build/benchmark_diff_mppi_manipulator_summary.tex --time-caps 3.0,6.5,10.5 --time-targets 3.0
python3 scripts/plot_diff_mppi.py --csv build/benchmark_diff_mppi_manipulator.csv --out-dir build/plots_manipulator --time-caps 3.0,6.5,10.5 --time-targets 3.0This follow-up adds a custom 2-link planar arm benchmark with second-order joint dynamics, workspace obstacles, and one moving-obstacle reach task. It is still a pilot rather than a standardized manipulation benchmark, but it is a closer answer to the "2D kinematic navigation only" criticism than CartPole. The stronger current result is arm_static_shelf: at K=256, vanilla mppi stays at success=0.00 and final_distance=0.23, while diff_mppi_1 reaches success=0.75 at 0.16, feedback_mppi_cov reaches success=1.00 at 0.15, and the new feedback_mppi_ref also reaches success=1.00 at 0.15 while using only 1.90 ms per step instead of 2.65 ms. At K=512, both feedback baselines stay at 1.00 success while mppi remains unsuccessful. The harder arm_dynamic_sweep task is intentionally not oversold: no planner fully solves it yet, but the best feedback and hybrid rows reduce final distance from roughly 0.33-0.36 for mppi to 0.29-0.30. The matched-time spot-check is stronger now: python3 scripts/tune_diff_mppi_time_targets.py --preset manipulator_pilot produces shared 2.0 ms and 3.0 ms rows, where feedback_mppi_cov is best on the static shelf task and feedback_mppi_ref becomes the best feedback row on the dynamic sweep task at 3.0 ms. The current note is in paper/diff_mppi_manipulator_followup.md.
7-DOF manipulator follow-up:
./bin/benchmark_diff_mppi_manipulator_7dof --seed-count 4 --k-values 256,512,1024 --csv build/benchmark_diff_mppi_manipulator_7dof.csv
python3 scripts/summarize_diff_mppi.py --csv build/benchmark_diff_mppi_manipulator_7dof.csv --markdown-out build/benchmark_diff_mppi_manipulator_7dof_summary.md --time-targets 3.0,5.0
python3 scripts/tune_diff_mppi_time_targets.py --preset 7dof_manipulatorThis follow-up adds a Panda-like 7-DOF serial-arm benchmark with 14-dimensional state (7 joint angles + 7 velocities), 7-dimensional torque control, 3D workspace obstacles, and parallelized gradient computation (analytical dynamics Jacobian + parallel stage cost gradients across T threads). It includes two scenarios: 7dof_shelf_reach (static obstacle avoidance while reaching) and 7dof_dynamic_avoid (reaching while avoiding a moving 3D obstacle). On 7dof_dynamic_avoid at K=512, diff_mppi_3 reaches success=1.00 at final_distance=0.090 using 0.84 ms per step, while feedback_mppi_ref reaches success=0.75 at 0.283 using 4.01 ms. An additional feedback_mppi_faithful variant combining the released current-action gain computation with a two-rate controller architecture (replan every other step) was tested on the base dynamic navigation suite and found to fail even at K=8192 and 2.1 ms per step, confirming that current-action-only feedback gains lose temporal coverage between replans. The current note is in paper/diff_mppi_7dof_followup.md.
bin/benchmark_pointcloud compares CPU vs GPU implementations of voxel-grid filtering, statistical outlier removal, normal estimation, RANSAC plane fitting, and GICP registration. Both CPU and GPU use the same brute-force algorithms (no KD-trees). Supports --ply, --kitti, --xyz flags for external point cloud files.
Multi-scale results (synthetic room, both CPU and GPU use same brute-force algorithms):
| Points | Operation | CPU | GPU | Speedup |
|---|---|---|---|---|
| 1,000 | Voxel Grid | 0.67 ms | 1.76 ms | 0.4x (GPU loses) |
| 2,000 | Statistical Filter | 339 ms | 0.82 ms | 412x |
| 5,000 | Normal Estimation | 4,024 ms | 2.08 ms | 1,933x |
| 10,000 | Normal Estimation | 15,487 ms | 4.88 ms | 3,171x |
| 50,000 | RANSAC Plane | 1,518 ms | 2.78 ms | 546x |
| 100,000 | RANSAC Plane | 3,077 ms | 5.62 ms | 547x |
Speedups scale with point count because the CPU baseline is O(n^2) for k-NN operations. At small n (<2K), GPU kernel launch overhead exceeds the computation, so CPU wins on simple operations like voxel grid.
- CMake >= 3.18
- CUDA Toolkit >= 11.0
- OpenCV 3.x / 4.x
- Eigen 3
mkdir build
cd build
cmake ../
make -j8Executables are in bin/.
This repository now treats some design work as experiment -> convergence, not abstract design -> implementation.
Current process split:
core/: only the minimum interfaces that multiple variants already shareexperiments/: discardable concrete variants with different design stylesdocs/experiments.md: generated comparison resultsdocs/decisions.md: why something is kept, rejected, or not yet promoteddocs/interfaces.md: the current minimum stable contract
Concrete entrypoint:
python3 scripts/run_design_experiments.pyOne-command local repair path:
python3 scripts/design_doctor.pyCreate a new history snapshot while running the same repair path:
python3 scripts/design_doctor.py --snapshot-label local_checkRender a targeted comparison between the latest two snapshots:
python3 scripts/compare_design_snapshots.pyCheck that the latest snapshot did not regress beyond the declared policy:
python3 scripts/check_design_regressions.pyRender convergence signals from the snapshot history:
python3 scripts/render_design_convergence.pyRender the next suggested process moves from those convergence signals:
python3 scripts/render_design_actions.pyRender the helper-promotion watchlist from current shared helper usage:
python3 scripts/render_helper_promotion.pyRefresh the checked-in design docs:
python3 scripts/refresh_design_docs.pyRecord a new design snapshot and regenerate the history doc:
python3 scripts/snapshot_design_experiments.py --label local_checkRefresh the version-controlled fixture CSVs from the selected build outputs:
python3 scripts/refresh_design_fixtures.pyCheck whether the checked-in fixtures still match the configured build outputs:
python3 scripts/refresh_design_fixtures.py --check-syncScaffold a new concrete problem with 3 disposable variants:
python3 scripts/scaffold_design_problem.py cache_policy --dry-runValidate that the experiment-first guardrails still hold:
python3 scripts/validate_design_workflow.pyCheck that the scaffolder still emits the current workflow contract:
python3 scripts/check_scaffold_design_problem.pyCurrent concrete problems:
planner_selection: choose one planner configuration per dataset/scenario pairfixture_promotion: choose which benchmark fixture datasets survive into the lightweight experiment corpustime_budget_selection: choose one planner configuration per dataset/scenario/time-budget request
Each problem is implemented three different ways:
- functional scoring
- OOP / lexicographic policy objects
- staged pipeline filters
All variants consume the same aggregated input rows, answer the same request type for their problem, and are scored under the same benchmark, readability, and extensibility proxies. The process uses version-controlled fixture CSVs in experiments/data/, so design comparisons are reproducible without regenerating the heavy benchmark suite. scripts/validate_design_workflow.py now also checks that every experiment module appears in generated docs, which keeps the process state externalized instead of hiding it in code only. Nothing in experiments/ is assumed to be permanent.
The workflow is now module-driven rather than import-driven:
- each
experiments/<problem>/__init__.pypackage declares its own slug-like metadata and request builder - each problem package also owns its own report builder
scripts/run_design_experiments.pydiscovers those modules automaticallyscripts/design_doctor.pyis the promoted local entrypoint for refresh-and-validate maintenancescripts/run_design_experiments.pyalso discovers fixture CSVs automatically fromexperiments/data/experiments/data/manifest.jsondefines which benchmark CSVs are promoted into the lightweight fixture setscripts/refresh_design_fixtures.py --check-synccatches drift between checked-in fixtures and available build outputsscripts/snapshot_design_experiments.pyrecords aggregate design states intoexperiments/history/and regeneratesdocs/experiments_history.mdexperiments/history/policy.jsondefines which metrics are allowed to regress, and by how muchexperiments/history/actions_policy.jsondefines when the process shouldhold,diversify, or watch for promotionscripts/check_design_regressions.pycompares the latest two snapshots against that policyscripts/compare_design_snapshots.pyrenders the latest or selected snapshot delta without editing checked-in docsscripts/render_design_convergence.pysummarizes which quality signals have started to survive across snapshotsscripts/render_design_actions.pyturns those survival signals into explicit next-step advicescripts/render_helper_promotion.pyturns repeated helper reuse into an explicit promotion watchlist- repeated helper extraction happens in
experiments/support.pybefore any implementation is considered for promotion scripts/validate_design_workflow.pyfails if a discovered module is missing from generated docs or ifdocs/experiments.mdis stale; the runtime column is normalized during that check because it is machine-dependent
docker build -t cuda-robotics .
docker run --gpus all cuda-robotics ./bin/benchmark_pfRequires NVIDIA Container Toolkit.
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| Particle Filter | pf |
1000 particles: predict + weight update + resampling |
| Extended Kalman Filter | (CPU only) | 4x4 matrices - no GPU benefit |
| AMCL | amcl |
Adaptive particle count + GPU likelihood field + KLD-sampling |
| FastSLAM 1.0 | fastslam1 |
Particle x Landmark parallel EKF update (SLAM) |
| Graph SLAM | graph_slam |
GPU pose graph optimization with CG solver (SLAM) |
| PF on Episode | pf_on_episode |
Particle-filter localization over full trajectory episodes |
Each particle's motion prediction and observation likelihood computation runs as an independent GPU thread. Systematic resampling uses parallel binary search.
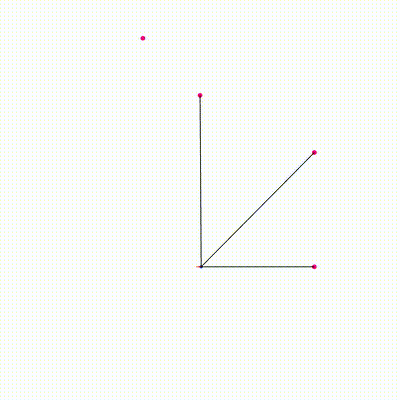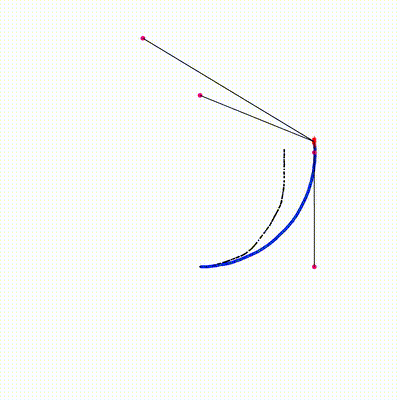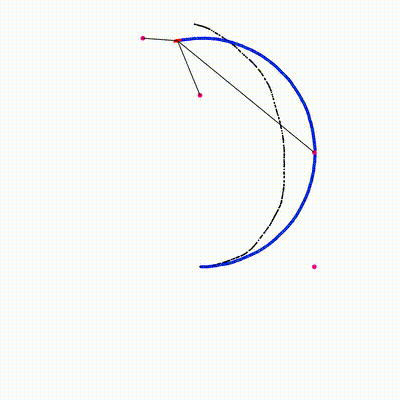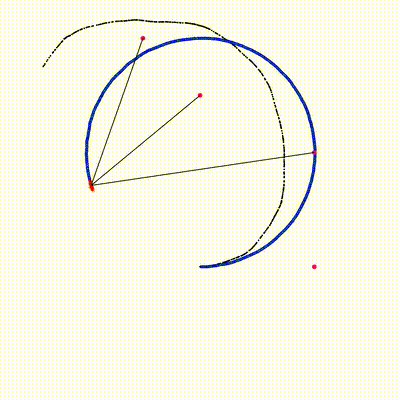
Combines particle filter (for robot pose) with per-particle EKF (for landmark positions). Each particle independently runs EKF updates for all observed landmarks on GPU. All 2x2 matrix operations (Jacobian, Kalman gain, covariance update) are inline — no Eigen on device.

| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| A* | astar_cuda |
Obstacle map construction (grid cells in parallel) |
| Dijkstra | dijkstra_cuda |
Obstacle map construction (grid cells in parallel) |
| RRT | rrt_cuda |
Nearest neighbor search + collision checking |
| RRT* | rrtstar_cuda |
Nearest neighbor + near nodes + rewiring + collision |
| RRT Reeds-Shepp* | rrtstar_rs_cuda |
Batch RS path computation + collision check (nonholonomic) |
| Informed RRT* | informed_rrtstar_cuda |
Ellipsoidal sampling + parallel NN/rewiring |
| 3D RRT* | rrtstar_3d_cuda |
3D nearest neighbor + 3D collision (drone/UAV) |
| Dynamic Window Approach | dwa |
~120K velocity samples evaluated in parallel |
| Frenet Optimal Trajectory | frenet |
~140 candidate paths: polynomial solve + spline + collision |
| State Lattice Planner | slp_cuda |
Parallel lookup table search + trajectory optimization |
| Potential Field | potential_field |
Grid-parallel potential computation (attractive + repulsive) |
| 3D Potential Field | potential_field_3d |
3D grid-parallel potential (216K+ cells, drone/UAV) |
| MPPI | mppi |
4096-sample path-integral control on GPU |
| Differentiable MPPI | diff_mppi, comparison_diff_mppi, benchmark_diff_mppi, benchmark_diff_mppi_cartpole, benchmark_diff_mppi_dynamic_bicycle, benchmark_diff_mppi_manipulator |
MPPI sampling update + autodiff control-gradient refinement + multi-scenario CSV benchmarking under fixed sample and wall-clock caps, plus nominal-linearization / rollout-sensitivity / covariance-regression / fused-feedback / high-frequency-feedback baselines, uncertain-dynamic follow-up, CartPole, dynamic-bicycle, and planar-manipulator pilots outside the base kinematic suite |
| Neural SDF Navigation | neural_sdf, sdf_potential_field, sdf_mppi, comparison_sdf_nav |
Learned implicit obstacle fields for heatmap visualization, potential fields, and MPPI |
| PRM | prm_cuda |
Parallel collision check + k-NN + edge collision |
| Voronoi Road Map | voronoi_road_map |
Jump Flooding Algorithm for parallel Voronoi diagram |
Obstacle map is constructed on GPU where each grid cell checks distance to all obstacles in parallel. Search uses CPU priority queue.
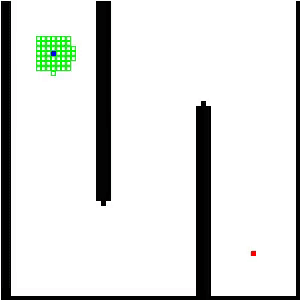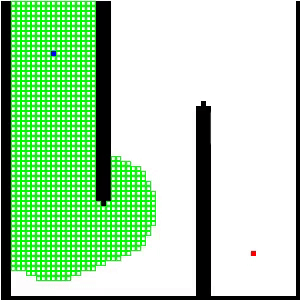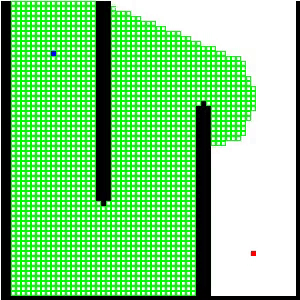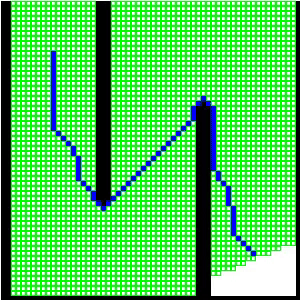
GPU-accelerated nearest neighbor search with shared-memory reduction. Collision checking also runs on GPU.

Extends RRT* with car-like kinematics (forward/reverse driving). The key GPU kernel evaluates Reeds-Shepp paths to all candidate parent nodes in parallel — each thread computes the analytical RS path (48 path types: CSC + CCC families), discretizes it, and checks collision along the entire path.
Extends RRT* with ellipsoidal focused sampling. Once an initial path is found, samples are drawn from an ellipse defined by start, goal, and current best cost — the ellipse shrinks as better paths are found, accelerating convergence. GPU handles parallel NN search, radius search, and collision checking.
Full 3D extension of RRT* for aerial navigation. Nodes are (x,y,z), obstacles are spheres. GPU kernels handle 3D nearest neighbor search, 3D radius search, and batch 3D collision checking. Visualization shows XY (top) and XZ (side) projections.
All (velocity, yaw_rate) combinations in the dynamic window are evaluated simultaneously on GPU. Each thread simulates a full trajectory and computes goal/speed/obstacle costs. Parallel reduction finds the optimal control.

Each candidate path runs as one GPU thread: quintic/quartic polynomial coefficients solved via Cramer's rule (no Eigen on device), cubic spline evaluation with binary search, collision checking, and cost computation - all fused in a single kernel.
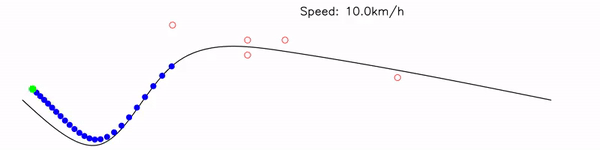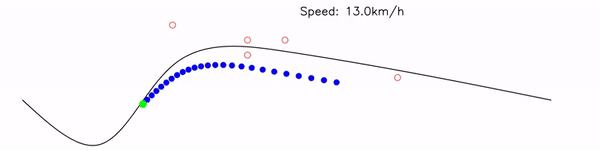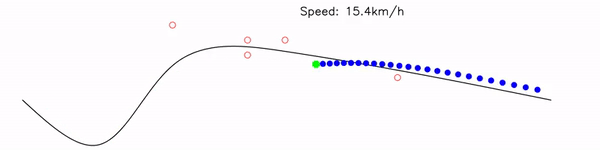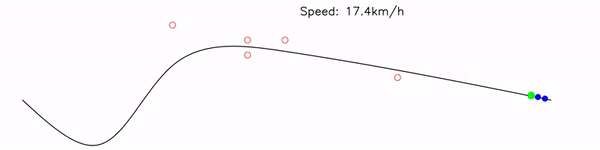
Multiple target states are optimized simultaneously on GPU. Lookup table search and trajectory optimization (Newton's method with numerical Jacobian) run in parallel.

GPU computes the entire potential field in one kernel launch: each thread calculates one grid cell's attractive potential (toward goal) and repulsive potential (from all obstacles). Path following uses gradient descent on CPU.
Extends potential field to 3D with spherical obstacles. GPU computes 216,000+ grid cells (60x60x60) in parallel. Each cell: 3D attractive potential + 3D repulsive potential from all spheres. Gradient descent over 26 neighbors (3^3 - 1). Visualization shows XY and XZ slice heatmaps.
Three GPU kernels: (1) parallel collision checking of N=500 random samples, (2) parallel k-NN search for roadmap construction, (3) parallel edge collision checking. Dijkstra path search on CPU.
Uses the Jump Flooding Algorithm (JFA) on GPU to construct a Voronoi diagram in O(log N) fully-parallel passes. Each pass, every grid cell checks neighbors at decreasing step sizes and adopts the nearest seed. Road map extracted from Voronoi edges, path found with Dijkstra.
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| ICP | icp |
GPU nearest-neighbor correspondences + batch transform updates |
| NDT | ndt |
Voxelized normal-distribution matching kernels |
| GICP | gicp |
GPU correspondences + point-to-plane system accumulation |
| Voxel Grid Filter | voxel_grid_filter |
Point-wise voxel assignment + centroid accumulation |
| Statistical Outlier Removal | benchmark_pointcloud |
Brute-force GPU k-NN mean-distance filtering |
| Normal Estimation | benchmark_pointcloud |
PCA normal estimation with one thread per point |
| RANSAC Plane | ransac_plane |
One RANSAC hypothesis per thread with device-side RNG |
Generalized ICP uses GPU nearest-neighbor search and point-to-plane system accumulation, then solves the 6x6 update on the host. The same infrastructure is reused by bin/benchmark_pointcloud to report CPU vs GPU registration throughput.
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| Neuroevolution | neuroevo |
One policy evaluation per individual, 4096 individuals in parallel |
| Neuroevolution Comparison | comparison_neuroevo |
CPU sequential evolution vs GPU population-scale evolution |
| PSO | pso_cuda |
100K particles updated in parallel |
| Differential Evolution | differential_evolution |
Population-wide mutation, crossover, and selection on GPU |
| CMA-ES | cma_es |
GPU candidate evaluation and covariance-guided search |
| ACO for TSP | aco_tsp |
Thousands of ants concurrently construct tours |
| Swarm Comparison | comparison_swarm |
Side-by-side convergence visualization for PSO, DE, and CMA-ES |
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| MiniIsaacGym CartPole | mini_isaac |
4096 environments stepped in parallel with GPU-side action generation |
| MiniIsaacGym REINFORCE | mini_isaac_rl |
GPU rollout buffer, return computation, policy-gradient construction, and MLP updates |
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| Occupancy Grid | occupancy_grid |
Ray-parallel lidar update (360 threads/scan) |
Each lidar ray is processed by one GPU thread using DDA line walking. Log-odds occupancy probability updated along each ray with atomicAdd.
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| Multi-Robot Planner | multi_robot_planner |
N robots: force computation in parallel |
Each robot computes attractive/repulsive forces from goals, obstacles, and other robots on GPU. Scales to 500+ robots.
| Algorithm | Binary | CUDA Parallelization |
|---|---|---|
| LQR Steering Control | (CPU only) | Sequential control loop |
| LQR Speed+Steering | (CPU only) | Sequential control loop |
| MPC | (CPU only) | Requires IPOPT solver |


Requires CppAD and IPOPT. Uncomment related lines in CMakeLists.txt to build.

100 steps (SIM_TIME=10s):
| Particles | CPU | CUDA | Speedup |
|---|---|---|---|
| 100 | 84 ms | 3.4 ms | 25x |
| 1,000 | 1,410 ms | 6.9 ms | 204x |
| 5,000 | 19,417 ms | 12.2 ms | 1,592x |
| 10,000 | 75,618 ms | 27.2 ms | 2,776x |
100 iterations per resolution:
| Samples | CPU | CUDA | Speedup |
|---|---|---|---|
| 9 | 1.1 ms | 1.3 ms | 0.9x |
| 405 | 54 ms | 1.4 ms | 40x |
| 1,449 | 197 ms | 1.4 ms | 140x |
| 8,421 | 1,205 ms | 1.7 ms | 705x |
Run bin/benchmark_pf to reproduce.
| Pattern | Used In |
|---|---|
| 1 sample = 1 thread (embarrassingly parallel) | PF, DWA, Frenet, State Lattice |
| Shared-memory reduction | PF (weight normalize/mean), DWA (min cost), Frenet (min cost) |
| GPU obstacle map / potential field | A*, Dijkstra, Potential Field |
| GPU nearest neighbor search | RRT, RRT*, PRM |
| Jump Flooding Algorithm (JFA) | Voronoi Road Map |
| Inline linear algebra (Cramer's rule) | Frenet (quintic/quartic solve) |
| cuRAND device-side RNG | PF |