in the loss and dloss functions, why not just use log_alpha here:
https://github.com/owkin/PyDESeq2/blob/main/pydeseq2/utils.py#L612
and here:
https://github.com/owkin/PyDESeq2/blob/main/pydeseq2/utils.py#L633
You can likewise just define log_alpha_hat once to avoid recomputing it on every function and gradient evaluation.
And since this is optimizing in the log space, I wouldn't put an alpha in the denominator (we just differentiate wrt log_alpha). Instead of:
reg_grad += (log_alpha - log_alpha_hat) / (alpha * prior_disp_var)
I would have:
reg_grad += (log_alpha - log_alpha_hat) / prior_disp_var
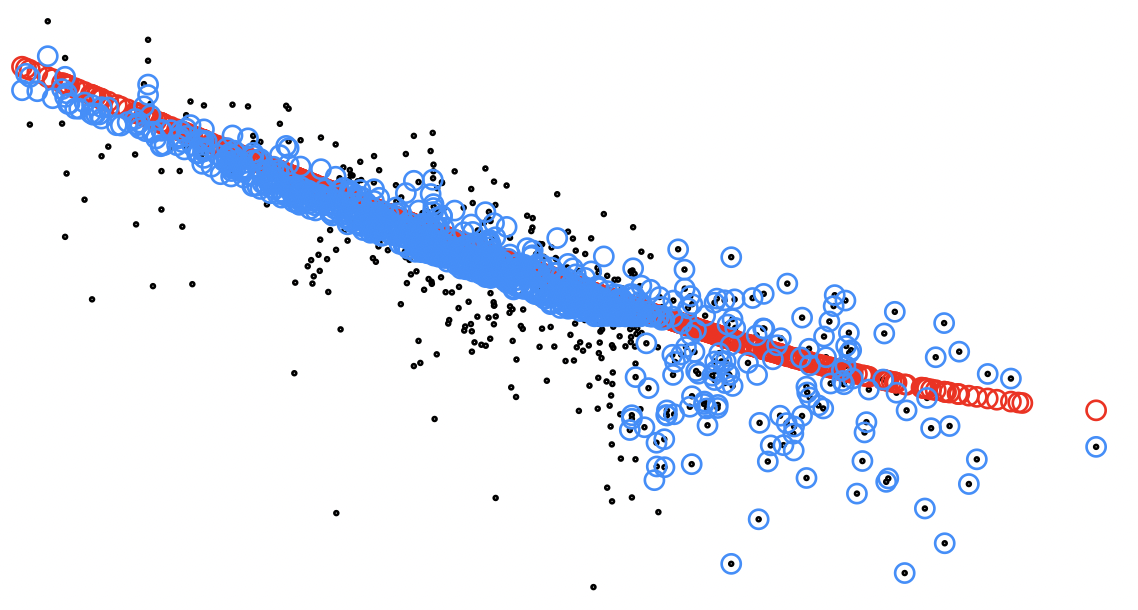
I'm not sure if this is why, but I see a lack of shrinkage sometimes for high counts (where we do shrink these in DESeq2), and I'm trying to figure out the source. Have you seen this?
in the
lossanddlossfunctions, why not just uselog_alphahere:https://github.com/owkin/PyDESeq2/blob/main/pydeseq2/utils.py#L612
and here:
https://github.com/owkin/PyDESeq2/blob/main/pydeseq2/utils.py#L633
You can likewise just define
log_alpha_hatonce to avoid recomputing it on every function and gradient evaluation.And since this is optimizing in the log space, I wouldn't put an
alphain the denominator (we just differentiate wrtlog_alpha). Instead of:reg_grad += (log_alpha - log_alpha_hat) / (alpha * prior_disp_var)I would have:
reg_grad += (log_alpha - log_alpha_hat) / prior_disp_varI'm not sure if this is why, but I see a lack of shrinkage sometimes for high counts (where we do shrink these in DESeq2), and I'm trying to figure out the source. Have you seen this?