Conversation
TODO: - Add comments - Rethink the matching of secrets (flushN() + lookForMatches()). The current mechanism is pretty inefficient by continuously searching the part of the buffer that is being flushed + maxLookback number of bytes before that. This means that if the program that is being masked uses a lot of small writes, we're doing a regexp lookup many times over on the same text. The previous implementation did this better by only checking every byte once. However, this code was much more complex. There must be a middle-ground here between complexity and performance.
|
Should have said this in the PR description: but for now I'm mainly looking for a high-level review. So: is this new structure we want to go ahead with? Then I'll polish it. |
|
Small suggestion: @jpcoenen if you want high level overview, maybe draw a quick diagram of how it works? Even a handdrawn sketch would help. |
|
Will do 👍 That's coming tomorrow. |
This gets rid of the maxLookback. Every byte is only checked once for a secret. It does require some comments. Looks very complicated at first, but with some proper documentation, it is not at all. Mainly because concerns are strictly separated.
A lot cleaner now. And we're back to using <redacted by SecretHub> instead of *****.
|
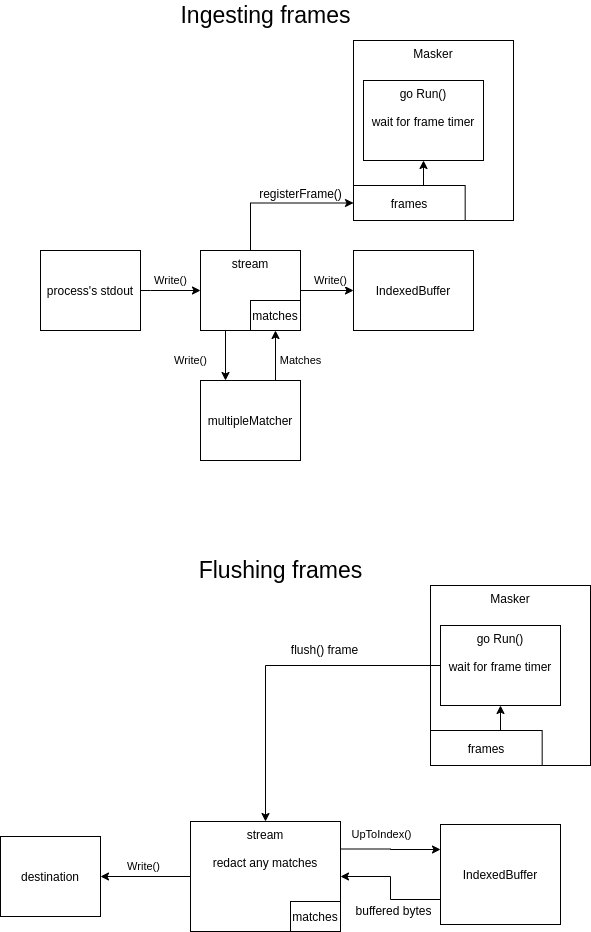
@SimonBarendse @mackenbach I've done quite a rewrite. It might still look very complex. However, I think that it has been reduced to the inherent complexity of the required behaviour. The signature of every function is as simple as I could get it. A global overview of how it works (also included a diagram; hope it helps): Ingesting frames
Flushing frames
|
There was a problem hiding this comment.
Very comprehensive rewrite/refactor. It looks like you were able to reuse quite a lot of the old logic that was sound and simplified the rest. I have quite a few comments, mostly architectural and naming/documentation.
Note: Last time we touched this functionality, I also made remarks as to the readability and complexity of the code and we then decided to improve that later... which became never. So I hope we can prioritize readability and simplicity now to avoid having to do the same dance a third time.
On the requirements side, I have a few questions that I think are good to tick off explicitly:
- Is the secret masking constant-time? If so, I feel we should mention that somewhere.
- Is the masking still a best-effort attempt? If so, I feel we should mention that somewhere.
- Does it work nicely with the TTY cases where output is written line-by line?
- How does it handle multi-line secrets? And if multi-line secrets are written line by line, how does that affect the masking behavior?
- Does it work nicely with (non-TTY) cases where bytes are not buffered before being written to our
writer? If I understand your code correctly, that would mean every frame is one byte long? - Does it not write to both (
stderrandstdout) output streams at the same time (at least in the TTY cases)? In other words, does it keep both output streams from interfering? - Finally, and this is one that didn't come up in the requirements discussion but I realized while reviewing (see also comments in the review): can this run without errors for a long time and with a lot of output being processed over time (e.g. a use case where a server is wrapped with
secrethub runand runs for a year, writing log lines tostdout)?
Overall, very well done. I'm happy we are able to (finally) fix this and in a pretty elegant way too.
| // Run continuously flushes the input buffer for each frame for which the buffer delay has passed. | ||
| // This method should be run in a separate goroutine. | ||
| // If a struct is passed on flushAllChan, all pending frames are flushed to the output and the method returns. | ||
| func (m *Masker) Run() { |
There was a problem hiding this comment.
Is it Run() or Start()? If Start() makes more sense, then I'd expect there to be a Stop() function too probably. Now the stopping behavior seems to be controlled by the flushAllChan, which is private, but is documented in the public docs here.
There was a problem hiding this comment.
Also, do 'streams' still accept write calls after Flush has been called? And is that desired (and documented)?
There was a problem hiding this comment.
Good suggestion.
Also, do 'streams' still accept write calls after Flush has been called? And is that desired (and documented)?
// This should be run after all input has been written to the io.Writers of the streams.
I'll see whether I can make this a little more explicit.
There was a problem hiding this comment.
You will get a panic if you write to a masked io.Writer after calling Close(). I've documented that behaviour. Catching without a panic requires some messy logic because streams would have to know whether the masker has stopped or not.
There was a problem hiding this comment.
Should we catch that error? You could wrap the streams with a very simple io.Writer interface that does exactly that one check. Can be a simple writeFunc or something.
There was a problem hiding this comment.
Hmm, interesting approach. Will look into it.
There was a problem hiding this comment.
Getting this solid is not as easy as I thought. For example, what happens if your in a write when you stop the masker? At the moment the behaviour is undefined because you're using the masker wrong. If we start guarding for this, I feel like we should do it properly, but that again adds some complexity. Is that what we want?
There was a problem hiding this comment.
Yes, there's definitely a tradeoff here. Consider adding to the docs that writing to any of the writers (/streams?) after calling Masker.Close() causes a panic. I think that should cover it well enough for now and we can add complexity when we find a valid use case for it.
There was a problem hiding this comment.
 SimonBarendse
left a comment
SimonBarendse
left a comment
There was a problem hiding this comment.
Are you still looking for only a high level review?
Based on your diagram, the high level implementation looks good! Looks like the two important jobs, masking and buffering/timeouts are nicely separated.
Is there a need for the bytes to go through the masking first and then in the buffer? Seems like going from the stdout write directly to the buffer could simplify it a bit more, because the bytes don't have to pass through the "stream" (masking engine) one more time. But, while this might seem complex in the diagram it might work out pretty smooth in the implementation?
Always welcome, but I am pretty convinced now that this architecture is more solid than the previous one.
I don't really get what you mean here. If you think it's important, let's discuss it face-to-face. |
This makes it clear what is configurable and what not.
Otherwise no secrets get matched if buffering is disabled. To compensate for matching logic now affecting the buffer delay, a compensating offset is introduced.
|
@SimonBarendse should I focus the review on the code or more on the functionality? |
|
@jpcoenen one question that just hit me: what happens if you have a secret to match that is max size (~512KB if I recall correctly)? Would that create a lot of detectors? Or does it have to do with the starting sequence of the secret? |
It only checks for repetitions of the start of the secret. So the size should not matter, only the degree of repetition. If it starts with That does indeed create >300 detectors. If it starts with: It does with 1 detector. Would the first scenario be something we want to guard against? |
|
Great explanation, thanks!
No I think it's fine. It would be a very weird edge case and caused by weird behavior on the part of the user. Although we could implement a limit, e.g. max 100 repeating first characters, and document that if the limit is exceeded it isn't guaranteed to mask all (partial) matches? It's a tiny edge case though. We could also implement it when someone runs into an issue. Right now, the way I get it is that it still masks fine, just the memory (and CPU?) footprint increase hugely, right? That's acceptable for a very weird edge case for now I'd say. |
A good question deserves a good answer.
Yep. Probably becomes unusable. I agree with your conclusion. |
|
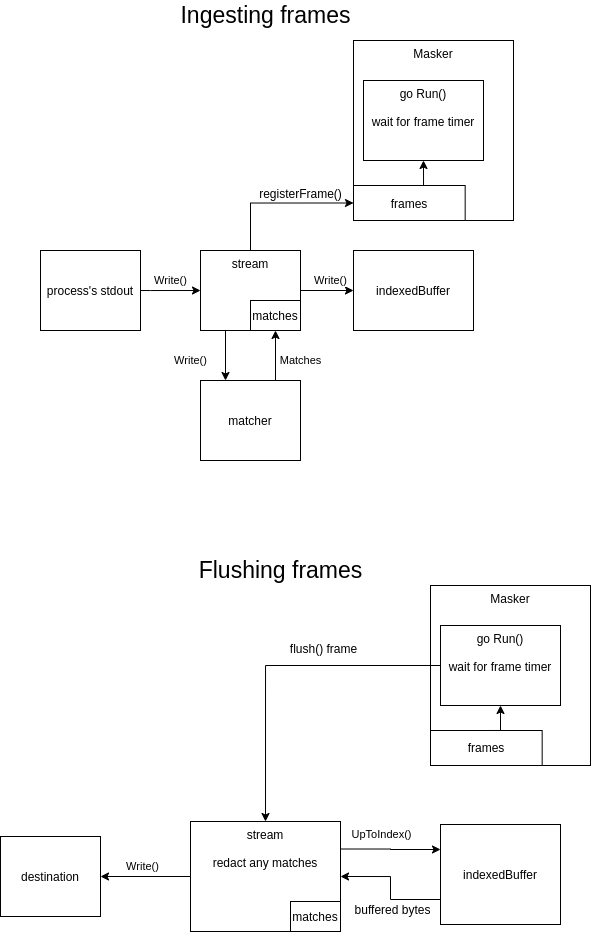
Updated the diagram: |
|
Solid, with the new diagram you really see how a very complex technical problem can be solved elegantly with no more than necessary complexity. Very good stuff guys. One tiny typo: I think it's called |
|
Okay stupid question that might fuck up your day: how does the For instance, we've encountered a few times UTF16 encoding on Windows. Now I don't know what encoding windows uses for
|
That's a good point. At the moment, if something is written to Unicode characters themselves are supported. For now, we could ask to the docs that only |
|
Awesome, good balanced response.
Do we want to add a test for good measure?
Yes let's do that. |
SimonBarendse
left a comment
There was a problem hiding this comment.
@SimonBarendse should I focus the review on the code or more on the functionality?
@florisvdg As discussed in person during standup, I asked mainly for shared understanding and code ownership to ensure we can maintain this properly and smoothly. This is a complex piece of code, which I think deserves the attention of all of us. Any questions you might have can be reflected in the documentation, to further enhance maintainability.
This is good to go 🚀, but let's make sure to go over this soon @florisvdg , while it's still fresh in our heads.

|
Before shipping, could you still address this @jpcoenen ?
|
|
PR descriptions get committed, right? If so, please edit it so it's a bit more helpful for later. |
The check was not really necessary anyway.

|
@SimonBarendse this means you tested it? |
Yes |
Complete rewrite of the masking functionality, with the following goals:
stdoutandstderrgetting mixed when written approximately at the same time. (stdout and stderr mixed in secrethub run #196 )