Make GLM 5.2 See Images in Claude Code with 1flowbase CN
GLM-5.2 最近在 Claude Code、OpenCode、Cline 等 Coding Agent 场景里热度很高。它适合长上下文、工程任务和代码推理,但在很多 Agent 客户端接入链路里,GLM-5.2 仍然应该被当作文本优先的 coding model 使用。例如 Z.ai 官方切换模型文档在 Cline 配置里明确提示关闭图片支持。
这会带来一个很真实的问题:
Claude Code 可以拿到截图。
GLM-5.2 很会写代码和做规划。
但 GLM-5.2 文本模型链路不能直接吃 raw image input。
1flowbase 的解法不是简单换模型,而是把工作流发布成一个虚拟模型接口:外部客户端仍然只调用一个模型名,1flowbase 在内部拦截图片输入,把图片交给多模态模型工具处理,再把结构化视觉结果返回给 GLM-5.2 继续推理和写代码。
最终效果类似这样:
Claude Code
-> 1flowbase 虚拟模型接口
-> GLM-5.2 主文本模型
-> 挂载的视觉工具
-> GLM-5V-Turbo / Gemini / GPT 视觉模型
-> 结构化视觉结果
-> GLM-5.2 输出最终代码或方案
这篇教程整理自原始 LINUX DO 实测帖:1flowbase 重磅升级 - 将文本模型升级多模态 - GLM 5.2,DeepSeek V4 均跑通验证。
GLM-5.2 的优势是长上下文、coding、agentic engineering。Z.ai 官方也把它定位在长任务和 coding agent 场景:GLM-5.2: Built for Long-Horizon Tasks。
但前端、UI、设计稿、截图复刻、图表分析这类任务不只需要文本推理。用户经常要问:
看这张截图,帮我复刻页面。
看这个 UI,告诉我布局哪里错了。
看这张图,生成 React / Tailwind 代码。
看这个 PDF 图表,抽出数据再分析。
如果只给主模型一个高层图片描述,它很难处理细节。更好的方式是让视觉模型先负责“看”,主力文本模型再负责“想、写、改、总结”。
Z.ai 已经有 GLM-5V-Turbo 这类多模态 Coding 模型,支持图片、视频、文本和文件输入:GLM-5V-Turbo 文档。1flowbase 可以把它挂成 GLM-5.2 的工具。
普通模型路由器通常是在多个模型里选一个。1flowbase 做的是把多个模型和工具组合成一个新的虚拟模型:
- GLM-5.2 做主力模型,负责规划、推理和代码输出
- 图片输入先被拦截,不直接打到文本模型
- GLM-5V-Turbo、Gemini、GPT vision 或 OCR 模型作为工具被调用
- 多模态模型返回结构化视觉上下文
- GLM-5.2 基于视觉上下文继续完成最终回答
- 整个工作流可以发布为 Claude / OpenAI 兼容接口
- 每个节点的输入、输出、工具调用、Token、延迟、失败原因和日志都可见
对 Claude Code 来说,它只是调用了一个模型;对你来说,背后是一条可观测的多模型工作流。
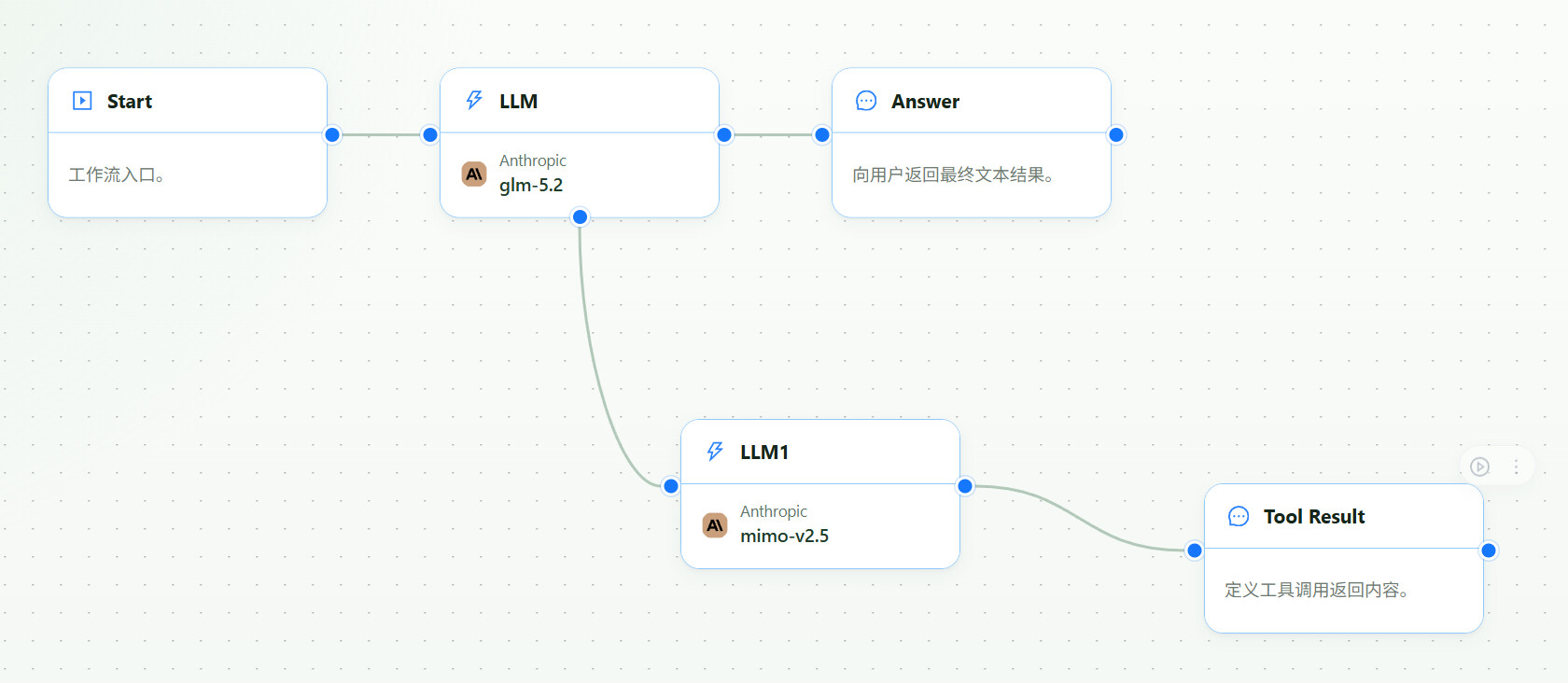
最小可用结构如下:
用户消息 + 图片
-> 主 LLM:GLM-5.2
-> 工具注册:vision_analyzer
-> 分支 LLM:GLM-5V-Turbo 或其他视觉模型
-> Tool Result:详细视觉分析
-> 主 LLM:最终回答、代码补丁或执行计划
同样的模式也可以用于 DeepSeek V4 或其他强文本模型。核心思想是:
文本模型继续做主力推理。
多模态模型作为工具负责看图。
1flowbase 负责拦截、编排、发布和记录日志。
在主 LLM 节点里开启工具挂载能力,然后注册一个视觉工具,让主模型在遇到图片、截图、UI、PDF 页面或图表时主动调用。
推荐工具名:
vision_analyzer
image_understanding
ui_screenshot_reader
design_to_code_helper
工具标识只建议使用大小写字母、数字和下划线。
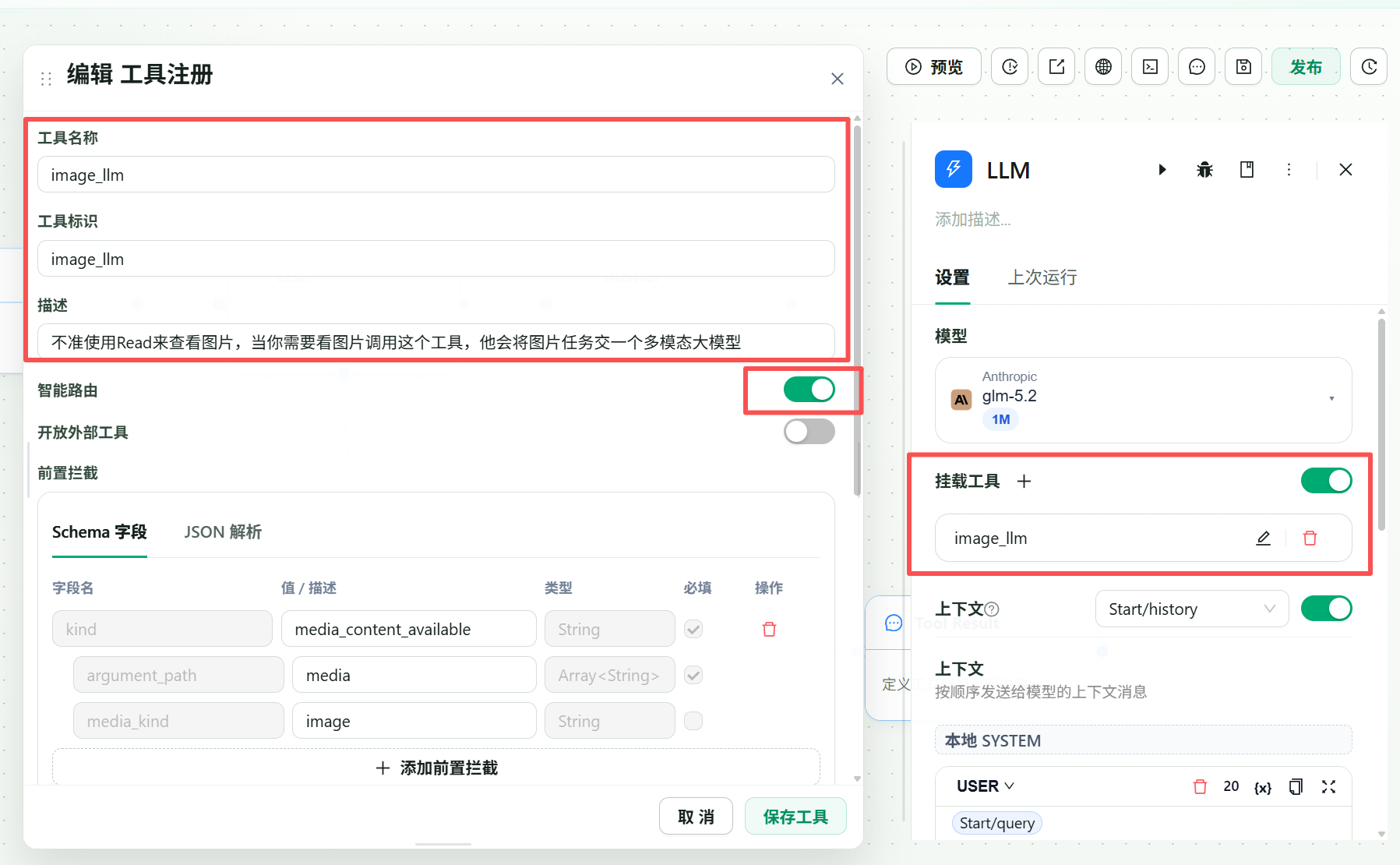
工具描述要写清楚什么时候调用,例如:
当用户提供图片、截图、UI 设计稿、图表、PDF 页面,或任务需要视觉理解时,调用这个工具分析图像内容并返回结构化视觉信息。
如果把图片直接塞给文本模型,上游供应商可能会报错,因为该模型链路不支持图片。因此需要配置前置拦截,把图片引用交给工具参数。
图片拦截 JSON:
[
{
"kind": "media_content_available",
"media_kind": "image",
"argument_path": [
"media"
]
}
]含义是:当请求里存在图片媒体内容时,把它暴露到工具参数的 media 路径。
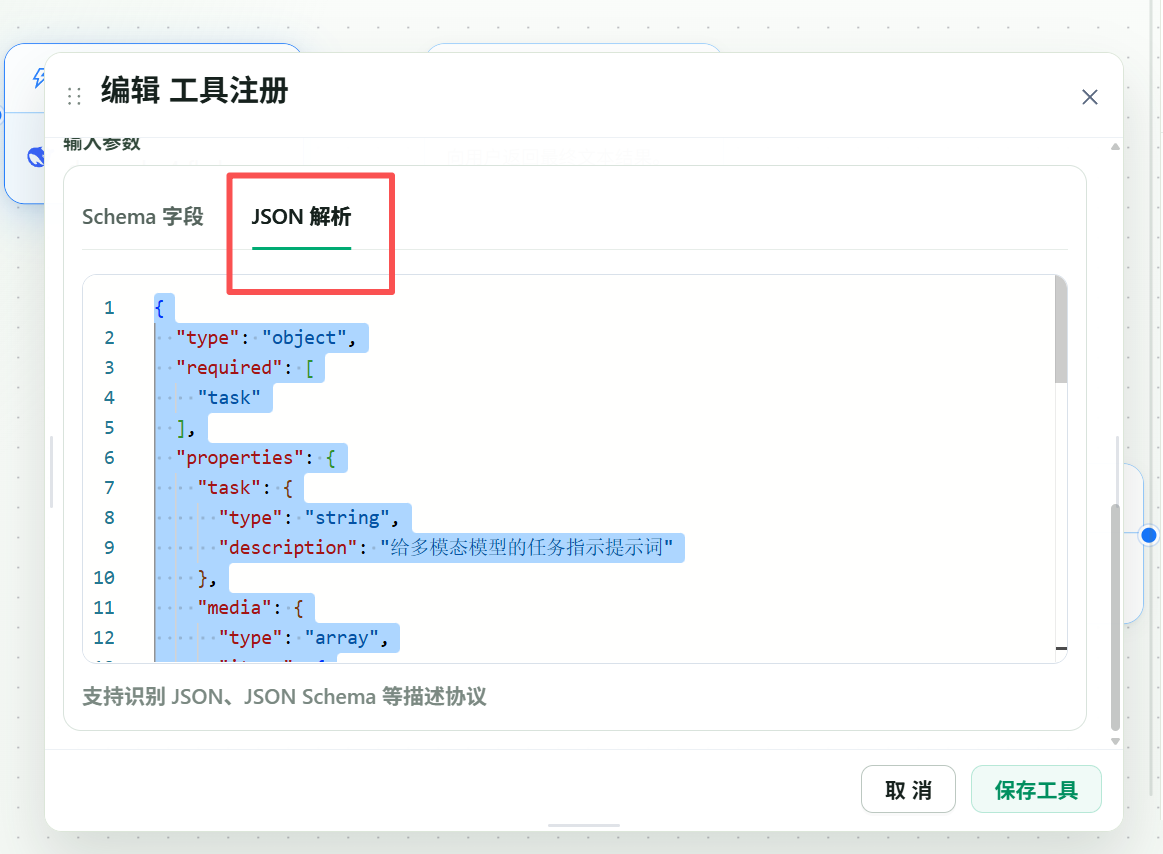
主模型需要知道怎么调用这个视觉工具。可以直接使用下面的 JSON Schema:
{
"type": "object",
"required": [
"task"
],
"properties": {
"task": {
"type": "string",
"description": "给多模态模型的任务指示提示词"
},
"media": {
"type": "array",
"items": {
"type": "object",
"required": [
"kind",
"path",
"source"
],
"properties": {
"kind": {
"enum": [
"image"
],
"type": "string",
"description": "媒体类型"
},
"path": {
"type": "string",
"description": "工作区内图片路径,例如 uploads/image_aionui_1781014667000.png"
},
"source": {
"enum": [
"workspace_path"
],
"type": "string",
"description": "媒体来源"
}
}
},
"description": "需要交给多模态模型处理的媒体引用"
}
}
}保存后,主模型就可以把 task 和 media 交给多模态工具。
分支 LLM 选择能看图的模型。常见选择:
-
glm-5v-turbo:GLM 原生多模态 Coding 模型 - Gemini 视觉模型:适合截图、文档、图表理解
- GPT 视觉模型:适合通用图片理解
- OCR / 文档模型:适合扫描件、表格、PDF、手写体
建议让视觉工具返回结构化结果,而不是一句泛泛的图片描述。
可以要求它返回:
- 页面布局和层级
- 可见文字
- 颜色、间距、字体、组件状态
- 图表轴线、数据点和异常值
- UI 错误、视觉异常、遮挡或错位
- 前端实现建议
这样 GLM-5.2 后续写代码时拿到的是可用上下文,而不是模糊 caption。
工作流预览跑通后,就可以发布成虚拟模型接口。
1flowbase 支持常见兼容协议:
OpenAI Responses API
OpenAI Chat Completions API
Claude-compatible Messages API
外部客户端只需要调用一个模型名,例如:
glm-5.2-vision
glm-5.2-with-eyes
glm-vision-coder
claude-code-glm-vision
而真正的执行过程由 1flowbase 在后台完成。
把 Claude Code、Cline、OpenCode、Continue 或其他本地 Agent 客户端配置到 1flowbase 发布出来的接口。
概念上需要这些信息:
Base URL:1flowbase 发布接口地址
API Key:1flowbase 应用密钥
Model:发布后的虚拟模型名,例如 glm-5.2-vision
Protocol:Claude-compatible Messages API 或 OpenAI-compatible API
然后给 Claude Code 一张截图,例如:
看这张 UI 截图,用 React 和 Tailwind 复刻这个页面。注意间距、颜色、字体、组件状态和响应式结构。
这时 GLM-5.2 仍然负责主推理和代码输出,多模态模型负责读图,1flowbase 负责中间编排。
执行后进入 1flowbase 日志,你应该能看到:
- GLM-5.2 主模型调用
- 视觉工具调用
- 被拦截的图片媒体
- 分支多模态模型执行
- 工具结果返回给主模型
- 每个节点的 Token、延迟、状态和错误
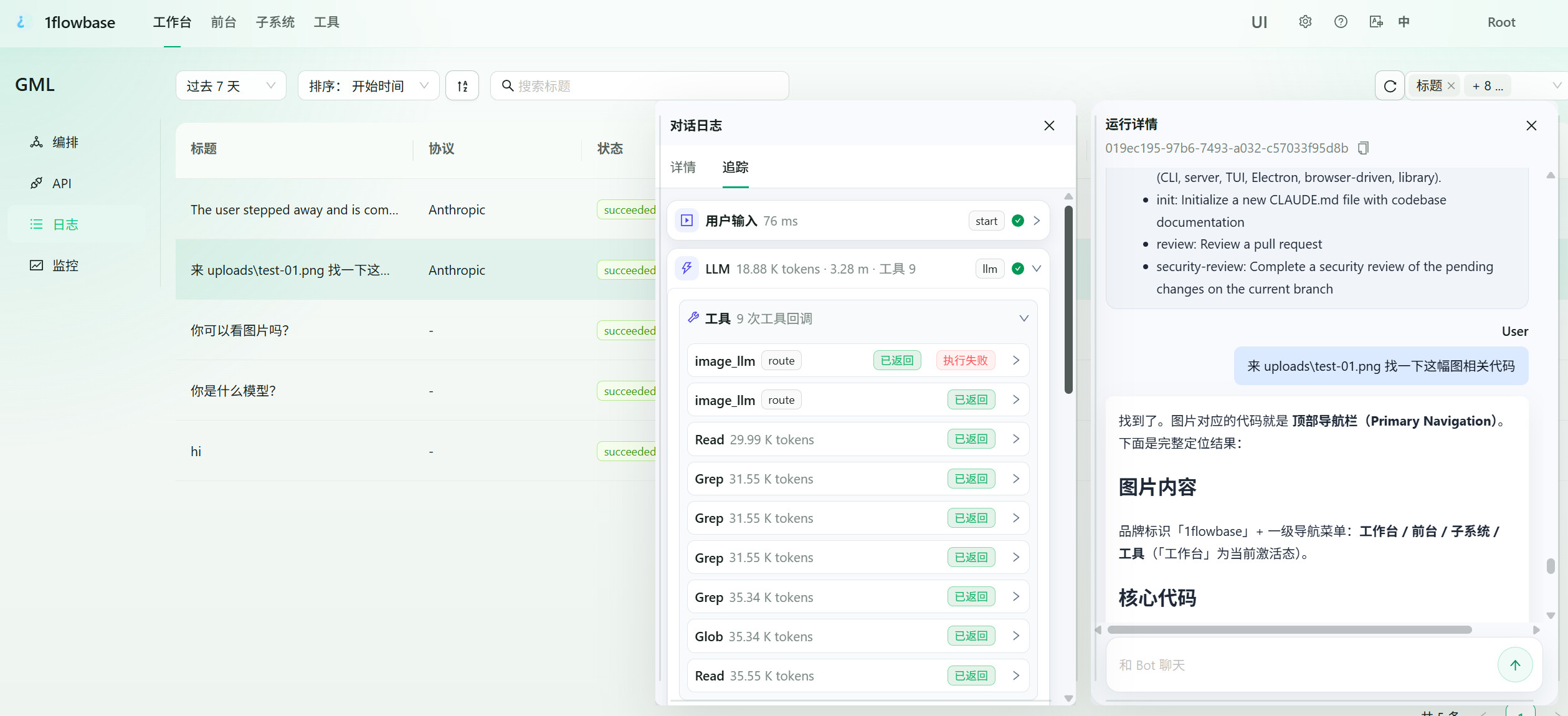
这就是 1flowbase 和黑盒代理最大的区别:你不只拿到最终回答,还能看到回答背后的模型链路。
主模型说自己看不到图怎么办?
先看工具调用里有没有 media。如果没有,说明图片没有通过拦截规则进入工具参数。
上游文本模型直接报错怎么办? 不要把 raw image input 直接发给 GLM-5.2 文本链路。应该通过 pre-intercept 拦截图片,然后让多模态工具处理。
视觉结果太粗怎么办?
加强 task 指令。不要只让模型“描述图片”,要明确要求布局、文字、颜色、位置、组件层级、错误点和实现建议。
工具调用失败怎么办? 检查是否真的传入了图片。在原始 LINUX DO 实测里,如果没有满足前置条件,工具会被直接拦截,并提示模型要求用户重新提供图片。
成本变高怎么办? 只在用户提供图片或明确要求视觉分析时调用视觉工具。普通文本代码任务仍然走 GLM-5.2 主路径。
这篇教程覆盖这些搜索需求:
GLM 5.2 看图
GLM 5.2 图片兼容
GLM 5.2 多模态
GLM 不能读 PNG
Claude Code 看图
Claude Code 多模态
GLM-5V-Turbo Claude Code
GLM-5V-Turbo 视觉编程
看图写代码
截图复刻
设计稿还原
AI Agent 看图
给 GLM 装眼睛
OpenAI 兼容接口
Claude 兼容接口
1flowbase 虚拟模型网关
1flowbase 多模型工作流
视觉模型 + 文本模型
GLM-5.2 负责规划和写代码。
GLM-5V-Turbo 或其他视觉模型负责看图。
1flowbase 把它们组合成一个可观测、可发布的虚拟模型接口。
如果你正在用 GLM-5.2 跑 Claude Code,又希望它能处理截图、设计稿、图表或 PDF 页面,不需要等所有客户端原生支持每一种多模态链路。用 1flowbase 把视觉模型挂成工具,发布成一个兼容接口,再用日志看清每一次请求背后发生了什么。