Reset database and device servers for each test (attempt 2) #640
Conversation
05ebc53 to
5889306
Compare
 bourtemb
left a comment
bourtemb
left a comment
There was a problem hiding this comment.
@mliszcz , I love this PR.
It seems to really speed up the tests and should help to make them more reproducible, especially when we run them independently.
Since this PR is also about parallelizing stuffs, please consider compiling using -j 2 option to speed up even more the Travis tests (Travis machines have 2 cores) like in the following commit:
dbcef00
I did the test with make -j 2 in Travis and got some good results in terms of speed:
https://travis-ci.org/bourtemb/cppTango/builds/625802785
compared to:
https://travis-ci.org/tango-controls/cppTango/builds/625414079
I don't like much the retry at the end for the tests which failed because Travis will report green if the tests which previously failed are passing the second time, and this might hide some issues and I'm afraid people won't have a look at the logs when Travis is green. I would prefer people to re-trigger manually the build in this case. It would encourage us to fix the tests which are failing more often even though I can understand such a situation could annoy people so I can accept the proposed solution for the moment, especially because more tests might fail if we run them in parallel, depending on the load of the Travis machine at the time of the Travis build.
I didn't find the time to test it on my machine. That's why I don't approve it for the moment.
But please feel free to merge if you feel confident enough.
This PR should not break anything in the Tango library.
|
Nice work! If I understand correctly there is roughly a 20% (from 25 to 20 minutes) decrease in the time needed to run the tests? The will help cool the planet and make developers happy! Well done! |
|
Hi Andy, With current configuration (8 parallel tests), there is 75% (3/4) decrease in test-suite time, e.g. on Debian 10:
The overall build time decreases by ~10 minutes. |
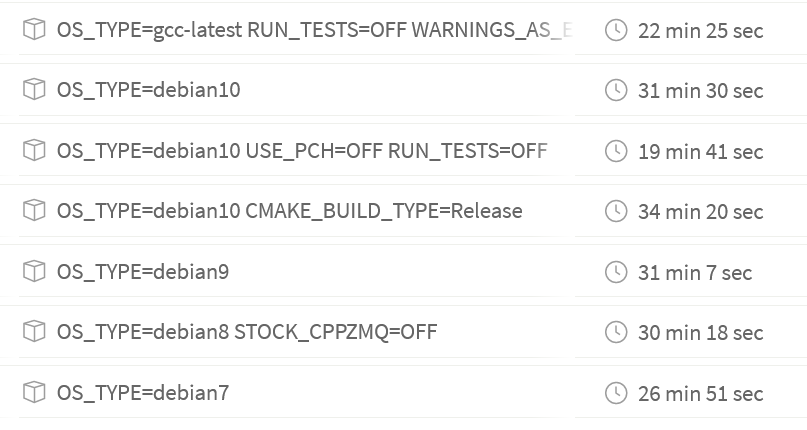
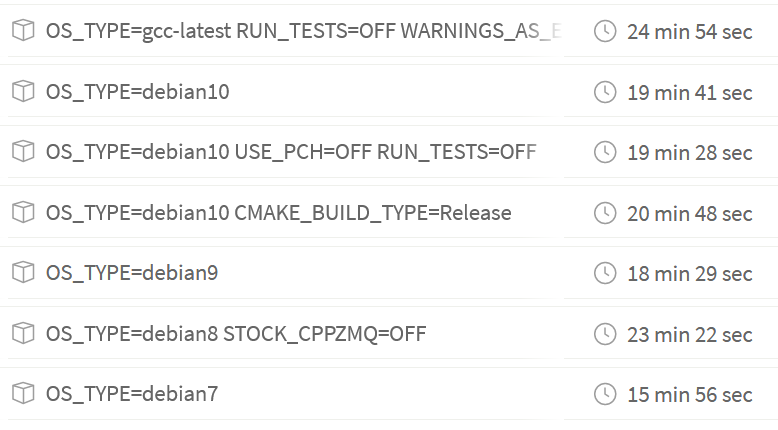
|
I did some more tests: -j12 https://travis-ci.org/tango-controls/cppTango/builds/627128708?utm_source=github_status&utm_medium=notification If there are two numbers in 'Time' column, it means: (all tests in parallel) + (rerun of failed tests).
Manually re-triggering the build in case of a failure will be extremely inconvenient, because most of the time some tests are failing. I'm afraid that Ci will be red all the time (if you restart the build, some other test may fail in the next run). Reducing the number of parallel jobs helps a bit, but we need at least two parallel jobs, otherwise execution time will be longer than without this PR (database setup overhead). @bourtemb what do you think? How much tests we should run in parallel? Should we re-run failures? |
.travis/run_ctest.sh
Outdated
| #!/usr/bin/env bash | ||
|
|
||
| if ! ctest \ | ||
| -output-on-failure \ |
There was a problem hiding this comment.
I think a dash is missing here: -output-on-failure => --output-on-failure
491ece4 to
f5d0bf3
Compare
Good point!
I think it is reasonable to think that it should not fail with 2 parallel jobs on a machine with 2 cores. I've tried on one of our machines (not a vm), a beast with 24 cores and I got about the same duration when running 24 parallel tests (~95 s, all tests passed) and when running 22, 30 or 36 parallel tests (~96 seconds, all tests passed Lightning fast compare to what we had before!). It's even slightly longer when going over 24 parallel tests in my use case. ~100 s with 48 parallel tests on a 24 cores real machine.
Now that |
Please remember that this PR adds ~5 overhead to each test (for starting mysql container). This is extra 500 on top of the current test suite run time with single database (~1000s). So running with -j2 the test run should take (~1500/2) I've just tested with two tests in parallel (ad161d9). On Debian 10 test suite took: 725.86 sec. As expected. No failures in any job. Now it gets complicated if you add more cores and more tests. On a 2-core VM on my laptop (and on a 2-core travis machine) I can usually run 8 parallel tests with no failures. This is because our tests are IO-bound, sleeping most of the time - client waits for the server's response, server waits for a command, etc. On the other hand, if you try to run too much parallel tests, the processes are fighting for CPU time, context switches are frequent, maybe there are some caching issues if process is re-scheduled on another core, etc. ... I don't think that we can come up with a simple formula for calculating optimal number of parallel tests. Either we run as many tests as we have cores available or we empirically check how many we can run (with acceptable number of failures). So, do you prefer to run with two parallel tests and remove the re-run option? I can adapt the PR accordingly.
I guess you're right here. Just check build times for some other PRs. Sometimes there is a 2-3 minute difference for the same job.
Basing on travis logs from my previous post, at least these are failing: BTW we must do something with |
|
Very nice! I got |
I would prefer that indeed. In any case, appveyor builds are still much slower than the Travis builds.
This test is a bit special since we have to wait for the reconnection to happen so there are some long sleep calls but there is probably room for improvement indeed since the reconnection should happen after 10 seconds and we have some sleep calls of 40 seconds. |
|
@bourtemb I'll remove the re-run feature in the coming days then. |
The test runner will start a fresh environment (database and device servers) for each test case.
The scripts are not needed anymore as ctest command sets the test environment up.
If some tests failed during parallel run, try to re-run them sequentially to see if the failure is permanent.
Extract setup scripts so that it is possible to run the setup manually and then attach the debugger or perform some additional configuration.
Run up to (num of CPUs) tests in parallel to avoid overloading the machine and to reduce the number of failures of unstable tests.
Since we are running up to (num of CPUs) tests in parallel, no failures are expected.
ad161d9 to
0c13be4
Compare
The owning group of docker socket varies between different docker packages and different operating systems. Official docker-ce package uses gid 957 while docker.io package on Ubuntu 20.04 uses gid 103. New group with matching gid matching docker host is added to the cpp_tango container to allow tango user access the docker socket.
bourtemb
left a comment
There was a problem hiding this comment.
Thanks @mliszcz for the great work!
Looks good to me.
I think we should re-enable COVERALLS and SONAR_SCANNER at some point (unless I forgot a decision which was taken about that) for at least one Travis build but this could be done in another PR.
Sonar and Coveralls were disabled in 226d70c and this was unnoticed until now. We again enable those integrations.
|
@mliszcz Go for it! |
Another approach to #568. Changes (compared to #568):