Fine-tune packed BackpropInput #7386
Conversation
 Linchenn
left a comment
Linchenn
left a comment
There was a problem hiding this comment.
Reviewable status: 0 of 1 approvals obtained
tfjs-backend-webgl/src/conv_backprop_packed_gpu.ts line 78 at r1 (raw file):
if (idyCVal && idyCVal2) { for (int d2 = 0; d2 < ${convInfo.outChannels}; d2 += 2) { vec4 wValue = getW(wRPerm, wCPerm, d1, d2);
Even though the three branches have the same codes, we still should not move the if-branches into the for loop. Otherwise the performance drops (for Conv2DBackpropInput op, drops ~10%), probably because the if-branches will be executed for each iteration (then threads probably would be stalled/synced in each iteration).
Code quote:
for (int d2 = 0; d2 < ${convInfo.outChannels}; d2 += 2) {
vec4 wValue = getW(wRPerm, wCPerm, d1, d2);
 pyu10055
left a comment
pyu10055
left a comment
There was a problem hiding this comment.
great work, thanks!
Reviewable status:
complete! 1 of 1 approvals obtained (waiting on @qjia7)
|
Benchmark on Samsung Galaxy S22 Ultra: Before this PR (with packed ConvBackpropInput): After this PR: |
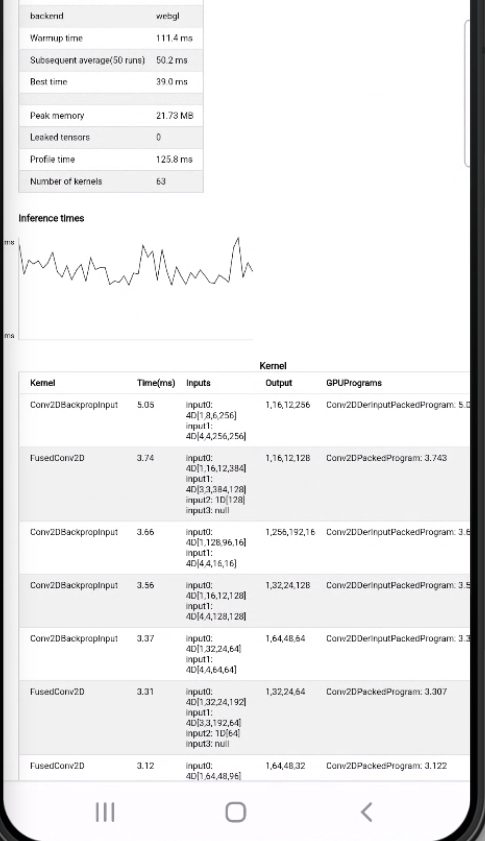
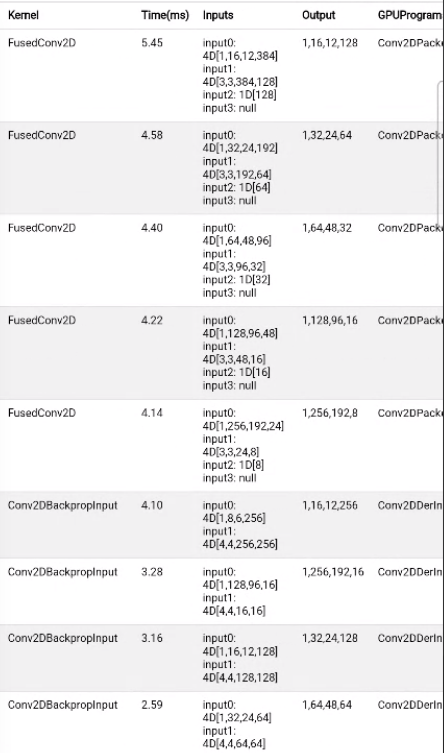
|
I just saw a big regression on Intel devices (both CFL and ADL) with this PR. Before (ADL) |
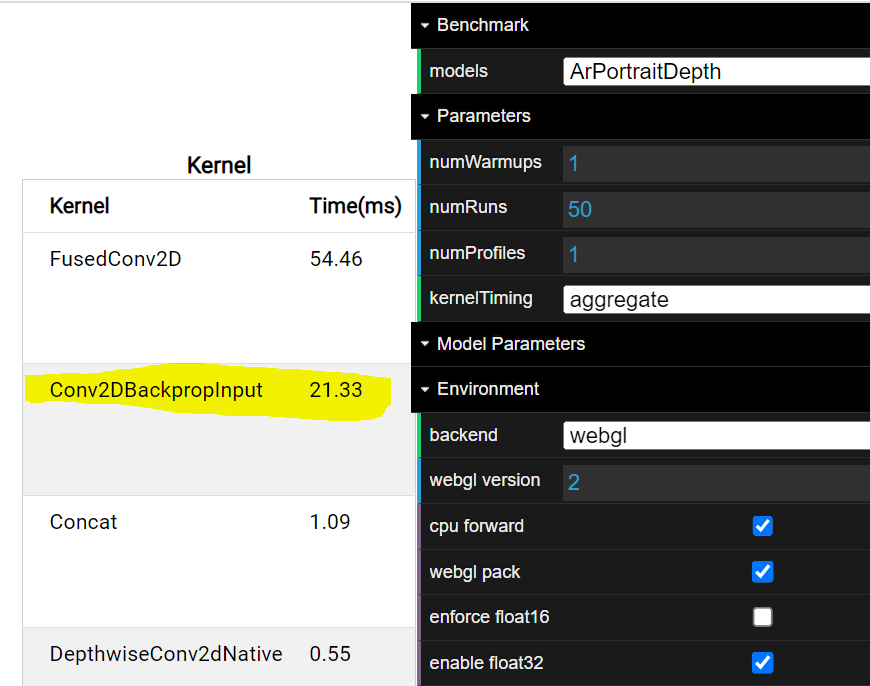
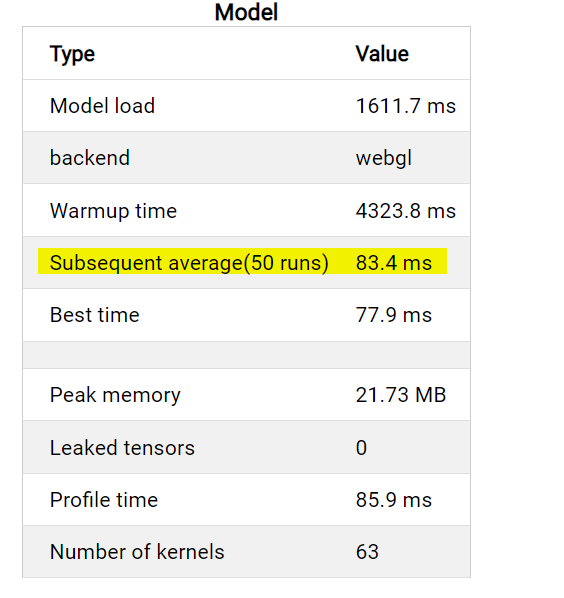
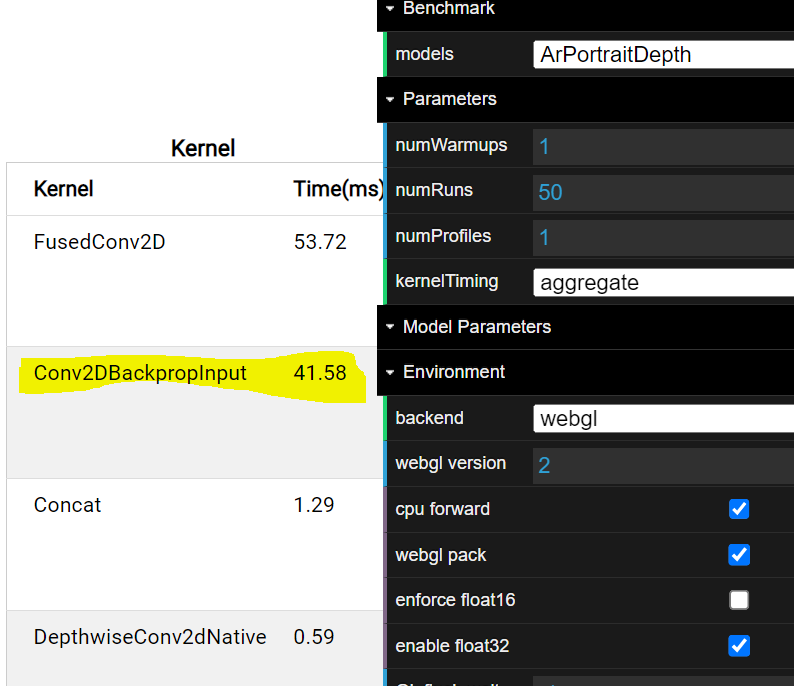
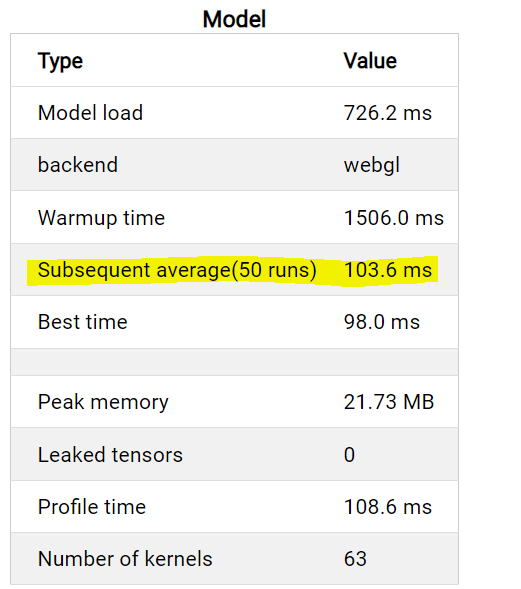
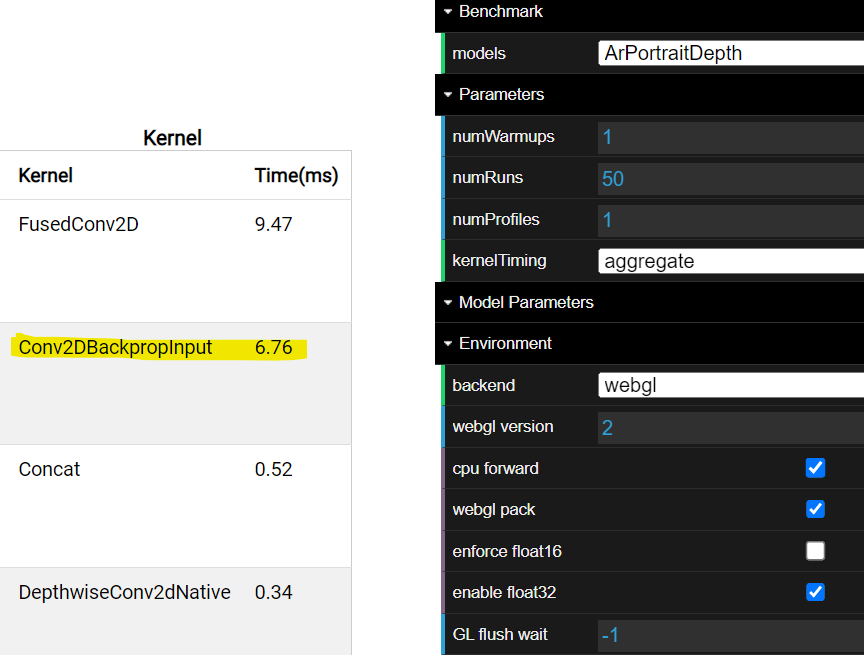
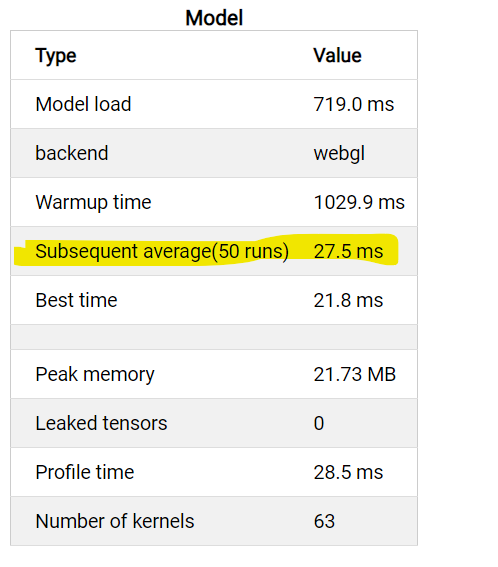
|
It's surprising that there is such a big regressions for Intel devices. But the similar algorithm works well for webgpu. It may be a driver bug if it only happens on Intel devices. I can report an issue to our driver team. But it will be good if we can skip this optimization for Intel devices on TFJS level temporarily. |
Originally, we use
idyCValandidyCVal2(could only be 0.0 or 1.0) to indicate ifresult.xyandresult.zware valid andresult.xy * idyCValandresult.zw * idyCVal2could return the results to avoid checking through if-branches.If stride is 1, both
idyCValandidyCVal2are always1.0and the original solution performs well. However, if stride is 2, whenever, only one ofidyCValandidyCVal2is1.0, which means either computingresult.xyorresult.zwis wasting of time.As a result, this PR adds the if-branches to check
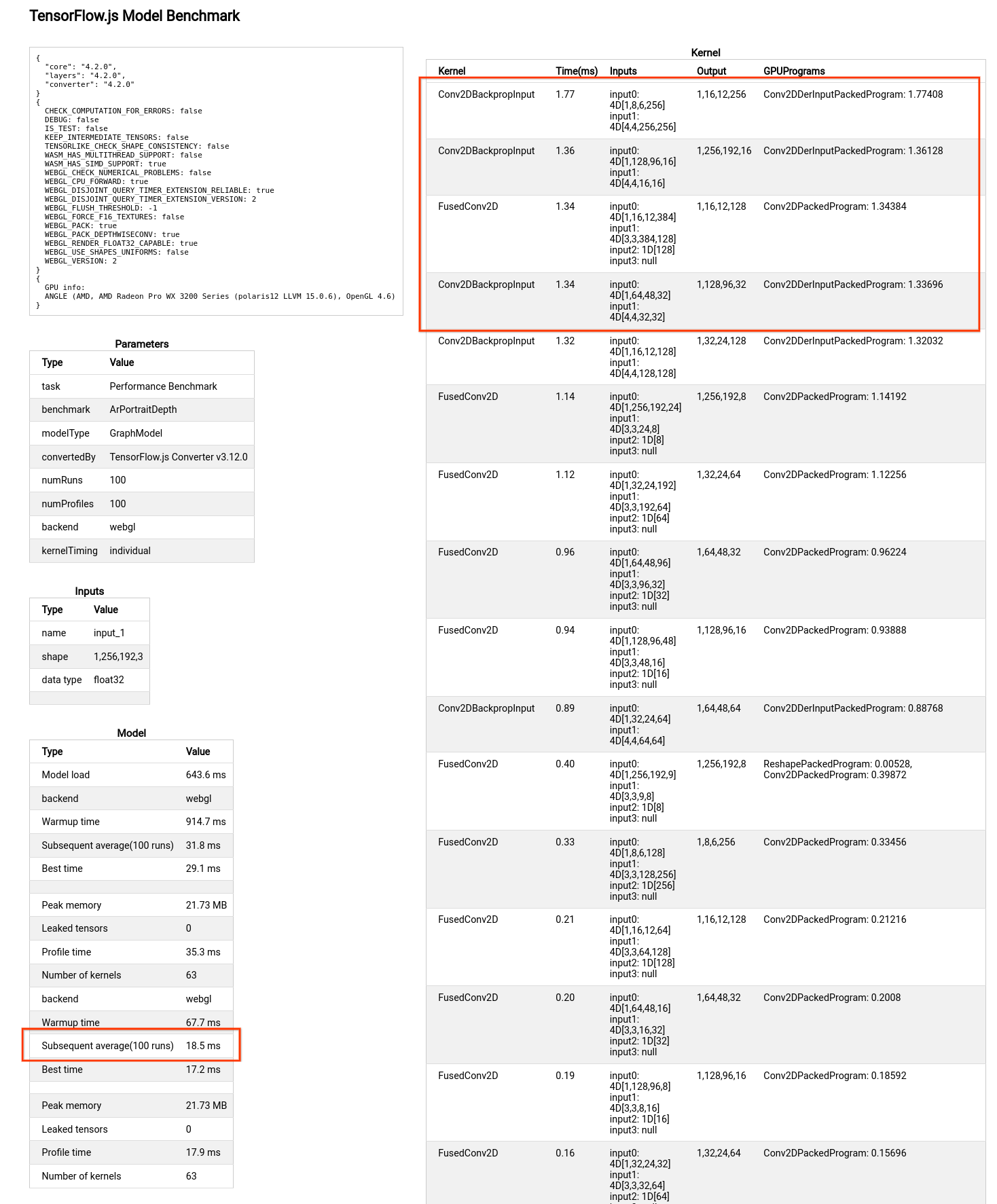
idyCValandidyCVal2before computing, instead of always computingresult.xy * idyCValandresult.zw * idyCVal2. This improves Conv2DBackpropInput ops in ArPortraitDepth ~40% and ArPortraitDepth model is improved from 23ms to 18.5ms (Benchmarked on LENOVO P620 2021).Before the PR:
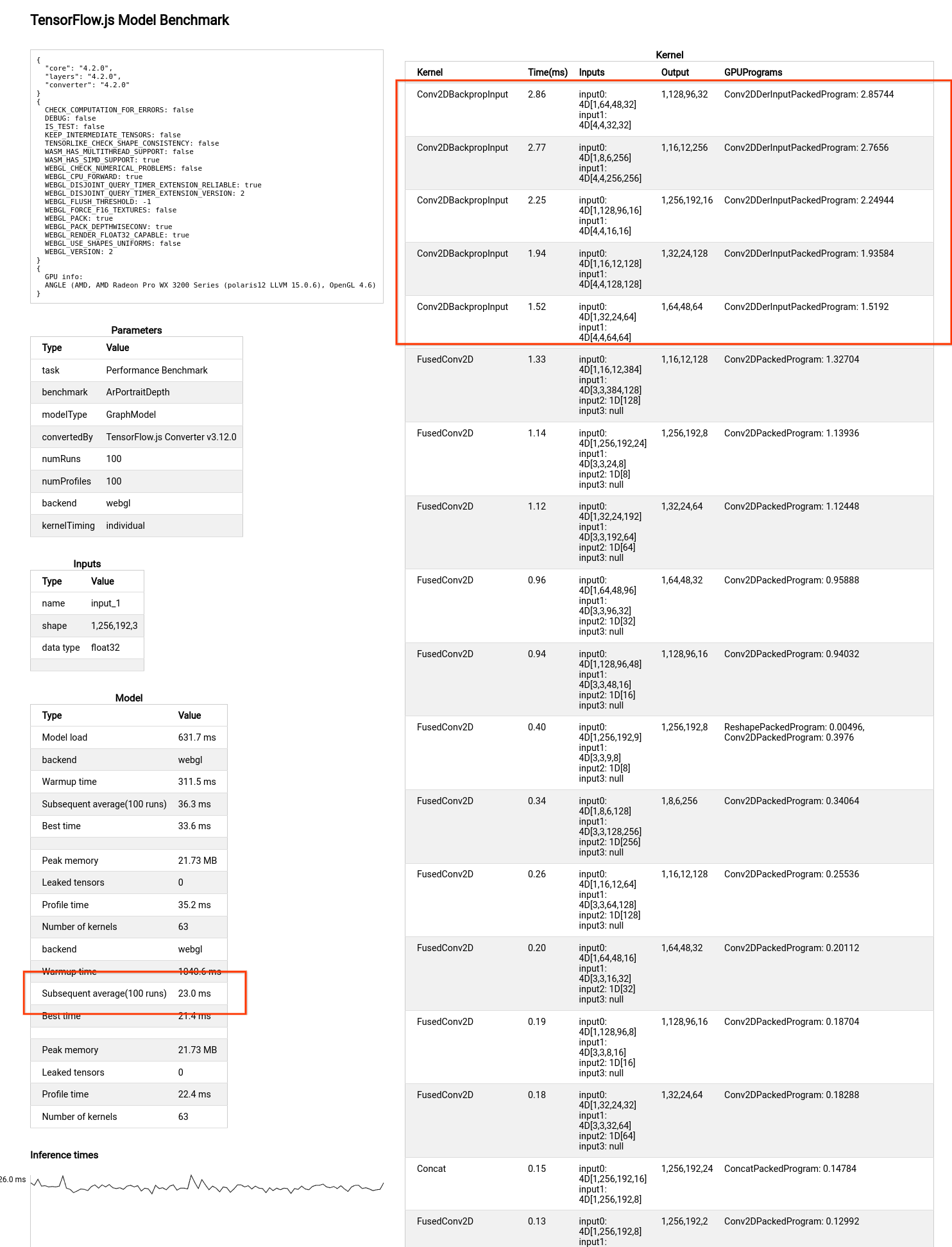
After the PR:
Reference #7371.
To see the logs from the Cloud Build CI, please join either our discussion or announcement mailing list.
This change is