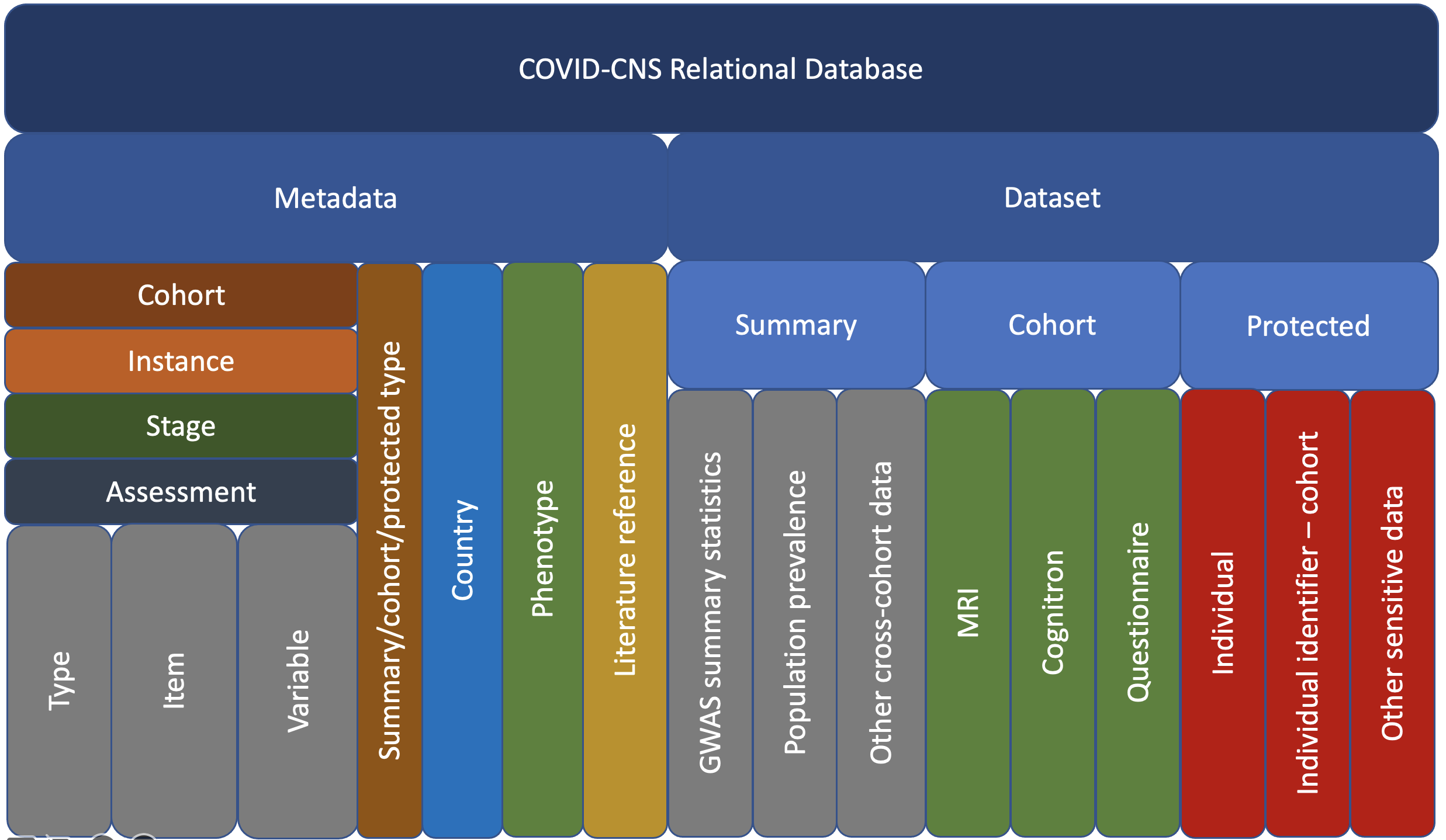
2. PhenoDB overview
-
metMetadata schema. Holds metadata of the individual level data in the coh and sec schemas, and of the summary level data in the sum schema. -
cohCohort data schema. Holds individual level data. Each entry over time is saved to preserve old versions of data in case of new imports overwriting older imports. -
secSecure cohort data schema. Holds more sensitive individual level data that is always deemed to be hidden from a standard extraction. This can be individual identifiable identifiers such as study participant ID's, personal contact information etc. -
sumSummary data schema. This schema holds non-individual level data and aggregated summary statistics such as phenotype population prevalences and genotype association dataset specific data.
Tables and views in this schema are generally friendly to read and interact with manually, in contrast to the tables in the coh schema. The tables are named and created to model most entities and relations of the database. The drawback of this is that old versions of the data in these tables are not saved.
-
assessmentAssessments, characterised by a code and version code. Corresponds to a typical standardised questionnaire, but can capture anything of the sort from other kinds of assessments. Different types of assessments are modelled by theassessment_type. Each version of assessment will have its own row and identifier. -
assessment_itemAssessment items, characterised by anassessment,assessment_item_typeand an item code. Assessment items groupsassessment_item_variables into groups that generally corresponds to an item in a questionnaire or the corresponding for otherassessment_types (has its own question text or description, but multiple pieces of data). -
assessment_item_typeAssessment item types; an entity created to characteriseassessment_items to allow for multiple different types in one assessment. Characterised by anassessment_type(describing the typical assessment type that this item type may be associated with), and a code. An example of this would be an assessment that combined questionnaire type items and interview or imaging items. A typical use would be to be able to filter among multiple items across assessments. -
assessment_item_variableAssessment item variables, characterised by anassessment_itemand a code, is the entity modelling the most granular piece of individual cohort data in the database. Each assessment item variable should correspond to a column in a table under the 'coh' schema. -
assessment_typeAssessment types, characterised by a code, describes the top sorting category for an assessment. An assessment can only have one assessment type, which may make it more useful to create detailed assessment item types instead. The default assessment types (which were rather arbitrarily created and named) are:- Questionnaire - A questionnaire type of assessment, either on paper or digitally distributed.
- Interview - An interview type of assessment.
- Imaging - An imaging type assessment.
- Biological sample - An assessment made on a biological sample.
- Cognitive test - A cognitive test performed using either a technical platform or other means to assess the result.
- Probe - Any kind of non-imaging technical measurement.
-
cohortCohorts, characterised by a code. An entity to model a cohort. All individual level cohort data are sorted under acohortinstanceof a cohort entity. -
cohortinstanceAn instance of a cohort, characterised by acohortand a code. Created to hold different versions, iterations, or sub-cohorts sorted under one cohort entity. This can for example be used to separate data extractions with different compositions of assessments, participants, or data. -
cohortstageA stage of a cohort (study), characterised by acohortand a code. Stages were created to represent timepoints or parallel stages of a cohort study. -
countryCountries in the world. Used for annotating other entities with countries. -
phenotypePhenotypes, that is; a measurement concerning a commonly shared trait of an organism, characterised by a code. Historically used to describe summary type data such as GWAS summary statistics or population prevalences. Planned to additionally be linked to assessments (but still not decided how this should be done, i.e. 1:many or many:many). -
phenotype_assessment_typeAssessment type for phenotypes, characterised by a code. Used to describe how a measurement was measured for summary type data. Hypothetically possible to better harmonise with assessments and assessment_types. -
phenotype_categoryCategory for phenotypes, characterised by a code. For searching and sorting in a repository of phenotypes. Multiple categories are possible to assign to each phenotype. -
phenotype_phenotype_categoryLink table to link phenotypes with multiple phenotype categories. -
phenotype_typePhenotype type, characterised by a code. -
populationAn entity to model ancestry for GWAS or similar. Used for summary type data. -
referenceAn external reference to a publication. -
summarySummary level data entity, characterised by a sort code, sort counter (numeric integer), andsummary_type. Each row is referenced by rows in tables holding summary level data under the 'sum' schema. -
summary_typeThe type of summary level data. Characterised by a code.
The tables under the 'coh' schema holds the individual level cohort data in multiple import instances. This means that there may be multiple rows that contain data for the same variable. To read the latest version of each variable from the cohort data tables, you can use the coh.create_current_assessment_item_variable_tview function to create a temporary view of your selection from which to read, as described in the code templates.
The cohort data tables are mapped to the corresponding metadata and named following the convention: [cohort code]_[cohortinstance code]_[assessment code]_[assessment version code]_[table index] The naming convention is used to link information about cohorts, cohortinstances, and assessments with the right table for insertion and extraction. The table index is used as an array index to reference multiple tables in case the number of variables for a certain cohortinstance/assessment combination is seen to exceed the maximum number of columns in a PostgreSQL table.
Data columns in the cohort data tables similarly follow the naming convention: [item code]_[variable code] Standardised metadata columns are prefixed with an underscore and have a specific function or meaning.
There should be a cohort data table holding each item and variable defined by the metadata. In the current live version, tables for older cohortinstances (representing experimental data imports) may have been removed.
The secure schema holds two tables:
-
individualIndividuals. Each row holds information on one individual, which theoretically can be shared across cohorts. -
individual_cohortinstance_identifierCohortinstance specific data about an individual. Characterised by anindividual, an internal unique UUID-identifier, and a string meant to hold the study/cohort participant ID.
The general idea of these tables is that the individual table can be rather static and would not require much update while each cohortinstance may update the data on each individual chronologically. Each cohortinstance generates new UUID identifiers for participants as to not have these shared across cohorts or cohortinstances. This is to allow for the use of these UUID identifiers, which are easily regenerated with a new cohortinstance, rather than the study/cohort participant ID, which may be globally identifiable.
Each table in the 'sum' schema represents one summary_type, which holds data specific to that type. Otherwise all summary data share the data in the met.summary table. The summary data functionality is still a WIP, and some relations and conventions are not fully defined.