0.7 FAQs
Q: How do I download my application's code bits after its been deployed?
Assuming you are an organization admin or you have permissions to push apps to the organization, then on Linux/Mac run this command from Cloud Foundry (CF):
curl -H "Authorization: `cf oauth-token|grep bearer`" http://api.<YOUR_TARGET_URI>/v2/apps/`cf app <YOUR_APP_NAME> --guid`/download > <YOUR_APP_NAME>.zip
Once the download is finished, the zip file contains the code bits for your app.
You can also use the CF plugin "download" described here:
https://github.com/ibmjstart/cf-download
However, this plugin fails to download protected files like ‘application.conf’ in some situations.
Q: How can I upload files on the Trusted Analytics Platform?
You can use cURL for uploading single or multiple files as described here or run prepared scripts.
Q: My Python-based application requires some Python dependencies to be installed; how do I work around that?
It is very common for applications to have dependencies. A great How To is described here:
https://github.com/cloudfoundry/python-buildpack
Q: I created a service on Marketplace. How can I access it from my application?
Read the article on Binding your application to a service and accessing the application here.
Q: How can I use the Scoring Engine API in my spark-tk application?
To start using the Scoring Engine for Spark-tk API in your application, first create an instance of the Scoring Engine for Spark-tk service on Services > Marketplace. Make sure you choose the Scoring Engine for Spark-tk. A prerequisite is that the spark-tk model is stored on HDFS, which needs its path passed as an additional parameter while creating the Scoring Engine instance, as shown below.

Then you bind your application with the Scoring Engine for Spark-tk service, so the application can read the current url base of the Scoring Engine. Instructions on how to bind a service instance to your application can be found in the previous question (Q: I created a service on Marketplace. How can I access it from my application?).
With the steps above completed, you can start querying the Scoring Engine API under <base_url>/v1/score?data={} endpoint, putting your data samples into brackets. The Scoring Engine will score the input data value against the trained model and return an answer.
To see a sample use of the Scoring Engine API in a Java application, visit our space-shuttle-demo repo at https://github.com/trustedanalytics/space-shuttle-demo.
For more information about the Scoring Engine, visit our scoring engine repo at https://github.com/trustedanalytics/scoring-engine.
If you need to perform transformations on data prior to performing scoring, the Scoring Pipeline may be better option for you than the Scoring Engine. Visit the scoring pipeline repo at https://github.com/trustedanalytics/scoring-pipelines.
Q: How can I use the Scoring Engine API in my application (I am using ATK)?
To start using Scoring Engine API in your application, you must create an instance of the TAP Scoring Engine service on Marketplace. A prerequisite is the ATK model stored on HDFS, which needs its path passed as an additional parameter while creating the Scoring Engine instance, as shown below.
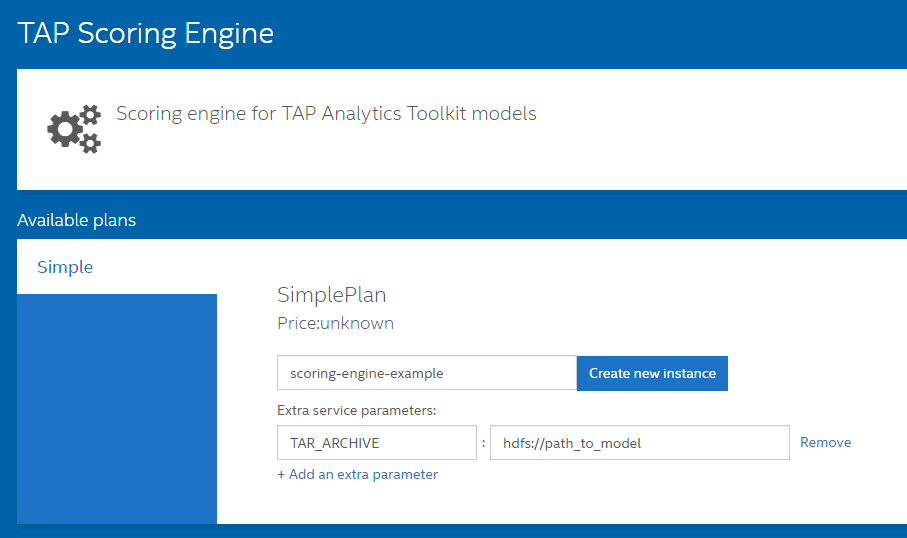
Then you bind your application with the Scoring Engine service, so that application can read the current url base of the Scoring Engine. Instructions on how to bind a service instance to your application can be found in the previous question (Q: I created a service on Marketplace. How can I access it from my application?).
With all the steps above satisfied, you can easily start querying the Scoring Engine API under <base_url>/v1/score?data={} endpoint, putting your data samples into brackets. The Scoring Engine will score the input data value against the trained model and return an answer.
To see a sample use of the Scoring Engine API in a Java application, visit our [space-shuttle-demo repository] (https://github.com/trustedanalytics/space-shuttle-demo).
For more information about the Scoring Engine, read our [Trusted Analytics Platform Package docs] (http://trustedanalytics.github.io/atk).
Q: My data is in a SQL database; how can I easily load it into TAP?
You can schedule a data import from your SQL database. Please check the data import section for details.
Q: How do I deploy an example Java application?
git clone https://github.com/cloudfoundry-samples/spring-music.git cd spring-music ./gradlew assemble cf push
If you are developing your own application with Maven:
vim manifest.yml # see https://github.com/cloudfoundry-samples/spring-music/blob/master/manifest.yml for reference
mvn clean package
cf push -n [hostname] # your application will be visible under [hostname].domain.com
Q: My application didn't run on CF. What should I do?
-
Check if your jar is working:
java -jar target/[jar-name].jar -
Check cf logs
cf logs [app-name] --recent -
If you get ERR Instance (index 0) failed to start accepting connections...
- try to change the memory in manifest to 512 MB or 1 GB, or
- verify that you didn't use a specific port.
Q: How do I provision a sample (PostgreSQL) service?
cf create-service postgresql93 free spring-music-pg
cf bind-service spring-music spring-music-pg
cf restart spring-music
Q: How can I get a shell session for my application?
You can get a new container in Cloud Foundry containing your application code with the cf-ssh tool. See https://blog.starkandwayne.com/2014/07/14/running-one-time-tasks-in-cloud-foundry/
Q: How do I run Warden on the runner machine to troubleshoot a container?
On the jump box:
`bosh ssh runner_z1/0`
`export PATH=/var/vcap/packages/ruby/bin:$PATH`
`cd /var/vcap/data/packages/warden/<TAB>/warden`
`./bin/warden --socket /var/vcap/data/warden/warden.sock`
From that point, you can do the things as specified in [the Cloud Foundry troubleshooting docs] (http://docs.cloudfoundry.org/running/troubleshooting/troubleshooting-warden-services.html).
Q: Where do I get cf-ssh?
You can read a blog post about it or you can just do the following:
cd ~/bin
wget https://raw.githubusercontent.com/danhigham/tmate-bootstrap/master/scripts/cf-ssh -O cf-ssh
chmod +x cf-ssh
Q: How do I view the current memory and disk usage of Cloud Foundry?
Log on to the jump box and run the dea_ads command.
Q: How do I view all the current logs within Cloud Foundry?
Log on to the jump box and run the nats_sub command.
Q: What languages and frameworks are inherently supported with Trusted Analytics Platform?
Java, python, nodejs, scala, go, ruby, PHP
| Language | Runtime | Framework |
|---|---|---|
| Java | Java 6, Java 7, Java 8 | Spring Framework 3.x, 4.x |
| Ruby | Ruby 1.8, Ruby 1.9, Ruby 2.0 | Rails, Sinatra |
| Node.js | V8 JavaScript Engine (from Google Chrome) | Node.js |
| Scala | Scala 2.x | Play 2.x, Lift |
| Python | Python | |
| PHP | PHP |
Q: Does Trusted Analytics Platform support all common buildpacks traditionally supported with Cloud Foundry?
Yes, details below:
| buildpack | download |
|---|---|
| java_buildpack | java-buildpack-v3.0.zip |
| ruby_buildpack | ruby_buildpack-cached-v1.3.0.zip |
| nodejs_buildpack | nodejs_buildpack-cached-v1.2.1.zip |
| go_buildpack | go_buildpack-cached-v1.2.0.zip |
| python_buildpack | python_buildpack-cached-v1.2.0.zip |
| php_buildpack | php_buildpack-offline-v3.1.0.zip |
| staticfile_buildpack | staticfile_buildpack-cached-v1.0.0.zip |
Q: What is the dependency of Trusted Analytics Platform on CDH?
The platform depends on CDH to provide big data capabilities and to be able to use the Analytics Toolkit (ATK). At this moment, TAP does not support any other distribution of Apache Hadoop.
Q: What tools can be used with the Analytics Toolkit?
The Analytics Toolkit can be accessed using Python. The Analytics Toolkit also requires CDH with Spark running on it.
Q: What data is supported in the Console > Data Catalog > Submit Transfer?
Any data set that is publicly available via HTTP protocol, can be downloaded to TAP.
Additional ways to obtain data include:
- Client (Data producers) —> Websocket —> Kafka —> HDFS
- Client (Data producers) —> MQTT broker —> HDFS
Q: Where can I find a list of all supported CF commands?
All Cloud Foundry CLI command documentation can be found at www.cloudfoundry.org
Also, cf —help lists all available commands.
Q: How can I use the Hue Oozie workflow editor with Trusted Analytics Platform?
There is a wiki section - Using Oozie Workflow Scheduler on TAP - which covers this topic.
Q: In Console > User management, what is the difference between “space” and “organization”?
The hierarchy is that an organization contains a space.
You can think of a space much like a department within an organization.
There is no fixed meaning to space; you may use this subdivision as you wish.
For instance, “dev”, “test”, or “prod” are good space names.
A user must be a "space developer" in order to deploy applications.
Q: How do I add new services to Console > Marketplace?
There are Cloud Foundry commands to add services to Marketplace.
Refer to Cloud Foundry documentation for information on development of new services (how to code a new service).
Q: How much time should I give an application to re-stage?
It depends on the application start-up procedure. If the application start-up procedure is long, it will take time. (CF timeout defaults are set to 15 minutes for staging and 5 minutes for start-up; you can change those if needed.)
Q: How do I configure an application to automatically re-stage or deploy another instance of itself?
- Write scripts on Unix to automatically re-stage using cf command line.
- The ‘cf’ command line can be used to deploy another instance. Note: adding a new instance will increase TAP environment cost if it is deployed in AWS.
- Write application-specific scaling scripts.
Q: What are Some Best Practices for Resource Utilization with TAP 0.7?
The following guidelines will help you monitor and utilize resources for TAP 0.7. The guidelines vary depending on your TAP implementation. ####Cloud Foundry (CF) Runners
In a standard TAP deployment on CF, you initially have two runners. You can watch these runners using one of the following methods:
-
On jumpbox as a root:
bosh vms –vitalsThis command shows you all the information about your CF virtual machines, which include TAP runners.
-
If you log in to your TAP console as an admin, you see Operations in the upper left menu. Select Operations, then select Platform Dashboard. Select the DEA tab to see how many more applications can be staged, as shown below.

-
Log in to jumpbox as root.
-
Edit cf.yml to increase the value of the instance number (line 257).
-
Deploy the updated cf.yml file, as follows:
bosh deployment cf.ymlbosh deploy -
Check all changes (only the number of instances should change), and then confirm them.
-
Wait until the bosh deployment process ends before you upload additional applications on CF.
- Each ATK instance is a single application. Each one takes 2GB of memory from runner and some resources from CDH.
- All errors similar to could not stage an application means that all runners have been used; you must add a new runner to the cluster to continue.
- All TAP organization/users (and all CF components) use shared runners.
In TAP, one Docker machine is responsible for all services, including: jupyter, Rstudio, databases, etc. This Docker machine cannot be extended. So is important to watch Docker, as the possibility for data loss can occur if the single Docker machine fails. You can watch the Docker machine using one of the following methods:
-
On jumpbox as a root:
bosh vms –vitalsThis command shows you all the information about your CF virtual machines, which include the Docker machine.
-
bosh ssh to Docker machine and use standard tools like top, etc., for monitoring.
- There is only one Docker machine for all of TAP.
- The maximum no. of services per organization is 200. This can be changed in docker-broker.yml line 131.
- Users should delete unused services. For example, if a user did a test of jupyter and was not planning to run that service again, they should delete it.
The Cloudera footprint is fairly small when first deploying TAP, but the footprint grows over time. Therefore, it should be monitored using one of the following methods:
- Use SSH with dynamic port forwarding to jumpbox. Set the browser to use this port forwarding and use the manager address (hostname of cdh-master-2), that is cdh-master-2.node.envname.consul:7180. When you log in, you will see all the information about nodes.
- If you have access, use Ansible with standard monitoring commands (like df, etc.) from the Ansible CLI. (A FAQ to add new workers to the Cloudera cluster for TAP 0.7 is in development.)
- Three CDH masters are enough to control numerous CDH workers.
- CDH workers are the only resource that can be added to the cluster to increase TAP performance.
- To work properly, HDFS must have at least 20% remaining space prior to starting any ATK work.
Q. What is the governance model of this project?
It is our intention in the Trusted Analytics Platform engineering community, to follow an open and democratic model like that found in many of the Apache Foundation's opensource projects. The model is based on earned leadership.
As developers demonstrate their abilities by contributing new code and documentation to the Trusted Analytics project, and their contributions are acknowledged by the existing members by pulling their requests, those individual contributors will gain greater responsibility in decision-making of our project. See How the Apache Software Foundation Works
Q. What part of the project needs the most contributions?
Analytical Tooling
Installer Tools
Others
Q. What elements of this project are in use by other projects?
Many of the ~30 projects comprising the Trusted Analytics Platform depend on each other; however, some can stand on their own. All of the projects are developed in a way that should minimize the effort to use them independently.
Q: How can I use data from a SQL database to build my model?
Data from the database would need to be loaded into a dataframe for use in training a model. This is done using the importing of data through JDBC into or out of a frame.
The import from JDBC is accomplished through the "JdbcTable" command, which is used to retrieve the data from a JDBC data source.
jdbcTable = ta.JdbcTable ("test", jdbc:sqlserver://localhost/SQLExpress;databasename=somedatabase;user=someuser;password=somepassord",
"com.microsoft.sqlserver.jdbc.SQLServerDriver",
"select * FROM SomeTable")
Q: After loading data into a data frame, how can I add/delete/update columns?
Within the Analytics Toolkit, there is an add_columns command for adding columns to a dataframe:
frame.add_columns(lambda row: row.age - 18, ('adult_years', ta.int32))
Multiple columns can also be added using the same command:
frame.add_columns(lambda row: [row.tenure / float(row.age), row.tenure / float(row.adult_years)], [("of_age", ta.float32), ("of_adult", ta.float32)])
To delete a column, there is a drop_columns command:
frame.drop_columns(["column_b", "column_d"])
There are also flatten and unflatten commands when dealing with frames that let you spread data to multiple rows based upon a string delimiter.
frame.flatten_columns(['b','c'], ',')
frame.unflatten_columns(['b','c'])