



Every RAG pipeline has the same failure mode. The LLM takes five retrieved chunks, ignores three of them, and generates a response that cites facts from nowhere. Your retriever did its job. Your prompt did its job. The output still contains unsourced claims and you have no way to know until a user catches it.
Existing tools don't solve this at runtime:
- RAGAS evaluates offline. It can't catch a hallucination before it reaches a user.
- LLM guardrails handle safety and policy enforcement well - toxicity, jailbreaks, off-topic content. Their provenance validators strip unsupported sentences but don't return a structured claim→URL map, a compliance rate, or a source allowlist.
- Prompt engineering reduces the problem. It doesn't eliminate it.
Dokis sits inline between retrieval and response delivery and returns a runtime trust report for the exact answer your system is about to ship. It acts as a provenance and enforcement boundary in real time.
Now it answers two separate questions:
- is this supported?
- is this support fresh enough to trust?
Dokis does three trust checks in one deterministic runtime pass:
1. Pre-retrieval enforcement. Strip chunks whose source URL is not on your allowlist before they enter the prompt.
2. Post-generation support auditing. Extract verifiable factual claims from the response using the default deterministic Claimify-inspired extractor. Match each claim to the best supporting chunk using BM25 lexical scoring by default. Build a claim → chunk → URL provenance map. Compute a compliance rate.
3. Temporal trust evaluation. If freshness policy is configured, derive source age from chunk metadata and distinguish supported_fresh, supported_stale, and unsupported. Return stale-source details, freshness-aware claim verdicts, policy issues, and a final trust verdict.
No LLM call or API key is required for the default BM25 path. Output is deterministic for identical inputs and config.

import dokis
result = dokis.audit(query, chunks, response)
print(result.compliance_rate) # 0.91
print(result.passed) # True
print(result.trust_passed) # True
print(result.provenance_map) # {"Aspirin inhibits...": "https://pubmed.com/1"}
print(result.violations) # claims with no source
print(result.claim_verdicts) # supported_fresh / supported_stale / unsupported
print(result.policy_issues) # [] | ["blocked_sources"] | ...
print(result.enforcement_mode) # "guardrail"
print(result.enforcement_verdict) # "passed"dokis audit sample_audit.jsonThe CLI reads a JSON file containing query, chunks, and response. If a
provenance.toml file is present in the current directory or beside the input
file, Dokis loads it automatically so the report reflects your real allowlist,
threshold, matcher, freshness policy, and enforcement mode. Use --config path/to/file.toml to
override that discovery. Use --no-color for plain output. Exit code is 0
when the full trust result passes, 1 when it fails policy/trust checks, and 2
for CLI/input errors.
import dokis
config = dokis.Config(
allowed_domains = ["pubmed.ncbi.nlm.nih.gov", "cochrane.org"],
min_citation_rate = 0.85,
claim_threshold = 0.3,
enforcement_mode = "guardrail",
max_source_age_days = 365,
stale_source_action = "fail",
)
clean_chunks = dokis.filter(raw_chunks, config)
response = llm.invoke(build_prompt(query, clean_chunks))
result = dokis.audit(query, clean_chunks, response, config=config)
if not result.trust_passed:
raise dokis.ComplianceViolation(result)from dokis.adapters.langchain import ProvenanceRetriever
retriever = ProvenanceRetriever(
base_retriever=your_existing_retriever,
config=dokis.Config(allowed_domains=["pubmed.ncbi.nlm.nih.gov"]),
)
docs = retriever.invoke(query)from dokis.adapters.llamaindex import ProvenanceQueryEngine
engine = ProvenanceQueryEngine(
base_engine=your_existing_engine,
chunks=source_chunks,
config=dokis.Config(min_citation_rate=0.80),
)
response = engine.query("What reduces fever?")
result = response.metadata["provenance"]dokis audit input.json
dokis audit input.json --config provenance.tomldokis audit currently expects a file path. Stdin piping is not supported.
from dokis import ProvenanceMiddleware, Config
mw = ProvenanceMiddleware(Config(
allowed_domains = ["pubmed.ncbi.nlm.nih.gov", "cochrane.org"],
min_citation_rate = 0.85,
matcher = "bm25",
claim_threshold = 0.3,
enforcement_mode = "guardrail",
max_source_age_days = 365,
stale_source_action = "fail",
))
result = mw.audit(query, chunks, response)result = await mw.aaudit(query, chunks, response)pip install dokis # BM25 default, zero cold start
pip install dokis[semantic] # adds SentenceTransformer matching
pip install dokis[nltk] # adds NLTK sentence splitting
pip install dokis[langchain] # adds LangChain ProvenanceRetriever
pip install dokis[llamaindex] # adds LlamaIndex ProvenanceQueryEnginedokis.Config(
allowed_domains = [],
min_citation_rate = 0.80,
claim_threshold = 0.35,
extractor = "claimify", # "claimify" | "regex" | "nltk" | "llm"
matcher = "bm25", # "bm25" | "semantic"
model = "all-MiniLM-L6-v2",
enforcement_mode = "guardrail", # "audit" | "guardrail" | "enforce"
max_source_age_days = None, # optional freshness policy
stale_source_action = "warn", # "warn" | "fail"
source_date_metadata_key = None, # optional metadata key override
domain = None,
)fail_on_violation still works as a backwards-compatible alias for
enforcement_mode="enforce", but enforcement_mode is the recommended
interface for new configs and examples.
extractor="claimify" is the default deterministic extractor. It is
English-oriented and Claimify-inspired, with verifiable-claim selection,
conservative decomposition, and simple bullet/list handling for RAG-style
answers. It does not reproduce Claimify, does not perform citation
faithfulness checks or full decontextualization, and does not add an LLM, API,
model, or mandatory dependency. The legacy splitter remains available with
extractor="regex" for users who want the old sentence-boundary behavior.
Dokis now uses extractor="claimify" by default. The goal is better
factual-claim selection before provenance matching, without adding an LLM call,
model download, runtime network call, or mandatory dependency.
On the public microsoft/claimify-dataset factual-claim selection benchmark:
| Extractor | Precision | Recall | F1 |
|---|---|---|---|
regex |
0.645 | 0.975 | 0.776 |
nltk |
0.645 | 0.976 | 0.776 |
claimify default |
0.742 | 0.881 | 0.805 |
This benchmark measures Selection-stage factual-claim detection only. It does not measure full Claimify reproduction, element-level coverage, citation faithfulness, answer correctness, or hallucination prevention.
For development feedback, the claim selection benchmark can be run from the repo root:
python benchmarks/run_claim_extraction.pyIt downloads the public microsoft/claimify-dataset CSV at benchmark runtime
and compares extractor selection against the dataset's
contains_factual_claim labels. This benchmark is not part of the runtime
package contract and adds no mandatory dependency.
claim_threshold by matcher:
matcher="bm25": normalised per-query BM25 score. Recommended:0.3–0.5.matcher="semantic": cosine similarity. Recommended:0.65–0.85.
Freshness policy:
- Set
max_source_age_daysto enable temporal trust checks. - Dokis derives source dates from
Chunk.metadata, checking a configured key first and then common keys likepublished_at,date, andyear. - Year-only metadata is treated conservatively as January 1 of that year.
stale_source_action="warn"surfaces stale support without failing trust.stale_source_action="fail"makes stale supporting evidence fail the final trust result.
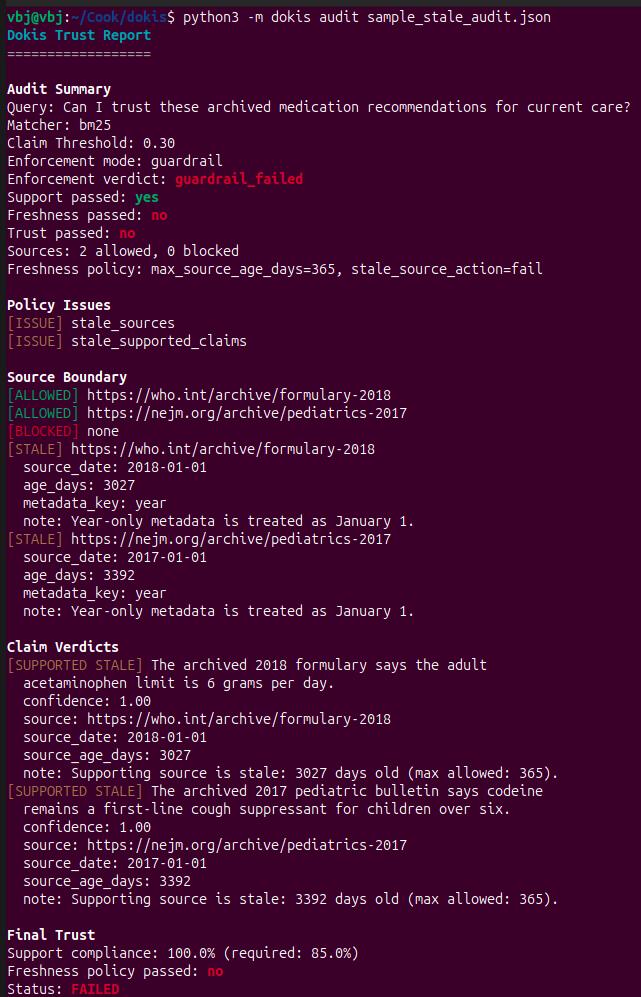
dokis audit sample_stale_audit.jsonThe stale demo is intentionally unsettling: every claim is grounded, but only in archived guidance that is years too old. Dokis marks the claims as supported_stale, shows the stale source ages, keeps result.passed == True, and still fails result.trust_passed because support alone is not enough.
Load from TOML:
# method is named from_yaml for backwards compatibility - pass a .toml file
config = dokis.Config.from_yaml("provenance.toml")result.compliance_rate # float
result.passed # bool - support/compliance only
result.freshness_passed # bool
result.trust_passed # bool - final trust outcome
result.violations # list[Claim] (derived unsupported claims)
result.stale_claims # list[Claim] (derived supported-but-stale claims)
result.provenance_map # dict[claim_text, source_url] (derived supported claims)
result.blocked_sources # list[str] (backwards-compatible)
result.blocked_source_details # list[BlockedSource]
result.source_freshness_details # list[SourceFreshness]
result.claim_verdicts # list[ClaimVerdict]
result.policy_issues # includes stale_sources / stale_supported_claims
result.has_blocked_sources # bool
result.has_unsupported_claims # bool
result.has_stale_sources # bool
result.has_stale_supported_claims # bool
result.has_unknown_source_ages # bool
result.enforcement_mode # "audit" | "guardrail" | "enforce"
result.enforcement_verdict # "passed" | "..._failed" | "enforce_raised"
result.raised_on_violation # bool
result.claims # list[Claim] (full per-claim audit records)
claim.text # str
claim.supported # bool
claim.confidence # float - always set, even when False
claim.source_url # str | None
claim.source_chunk # Chunk | None
claim.freshness_status # "fresh" | "stale" | "unknown" | "not_applicable"
claim.source_date # date | None
claim.source_age_days # int | None
blocked.url # str
blocked.domain # str | None
blocked.reason # "domain_not_allowlisted" | "malformed_source_url" | "missing_source_url"
verdict.claim_text # str
verdict.verdict # "supported" | "unsupported"
verdict.trust_status # "supported_fresh" | "supported_stale" | ...
verdict.confidence # float
verdict.supporting_url # str | None
verdict.note # str | None
record = result.model_dump_json() # fully JSON-serialisable trust reportMeasured on Python 3.12. Medians over 10 warm runs.
| Matcher | Cold start | What loads |
|---|---|---|
bm25 (default) |
~0 ms | Nothing - pure Python |
semantic |
~1,666 ms | all-MiniLM-L6-v2 (~80 MB) |
| Matcher | Median | p95 |
|---|---|---|
bm25 (default) |
0.96 ms | 1.29 ms |
semantic |
21.99 ms | 31.45 ms |
BM25 is 23× faster per audit call. The BM25 index is cached per chunk set - repeated calls against the same chunks stay sub-millisecond.
pip install dokis |
pip install dokis[semantic] |
|---|---|
| ~42 MB (pydantic + numpy + bm25s) | ~135 MB (+ model weights) |
| Matcher | Grounded detected | Ungrounded rejected |
|---|---|---|
bm25 (default) |
5/5 | 4/4 ✦ |
semantic |
5/5 | 4/4 ✦ |
✦ In this tiny hand-written benchmark, both matchers rejected all ungrounded claims that reached the matcher, for an effective ungrounded rejection rate of 100%.
| Dokis | RAGAS | LLM guardrails | |
|---|---|---|---|
| Runtime enforcement | ✅ | ❌ offline only | ✅ |
| No LLM call needed | ✅ | ❌ | partial ✦ |
| Per-claim provenance map | ✅ | partial | partial ✧ |
| Source allowlisting | ✅ | ❌ | ❌ |
| Compliance rate per response | ✅ | ❌ | ❌ |
| LangChain integration | ✅ drop-in retriever | ✅ evaluation wrapper | varies |
| JSON-serialisable audit log | ✅ per-response | ❌ | ❌ |
| Cold start | ~0 ms | - | varies |
| Core install size | ~42 MB | - | - |
✦ ProvenanceEmbeddings uses no LLM call. ProvenanceLLM requires one. ✧ Guardrails strips unsupported sentences from the response. Dokis returns a structured claim→URL map you can store and query.
Three working demos in dokis-examples:
- 01 - Local files - txt files + BM25 + Ollama
- 02 - Chroma vector store - Chroma + nomic-embed-text + Ollama
- 03 - Live web search - Serper API + domain allowlisting + Ollama
pip install dokis installs exactly three packages: pydantic>=2.0, numpy>=1.26, bm25s>=0.2.
MIT