01_Analysis B Tree
Every insertion is starting with insert function in main.c file.
// 'insert funtion' located in 'bpt.c'
node * insert( node * root, int key, int value ) {...}In each cases below, the insert function does different operation.
If a duplicate value exists, ignore its insertion.
Duplicate value is checked by find function.
find function gets node which has proper range for the value by find_leaf function.
If there is no record having the value, find function returns NULL else it returns record having the value.
Summary for call path in this case.
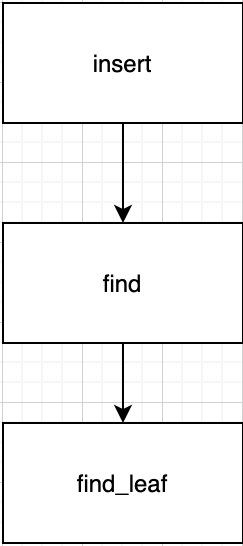
First, it checks for the duplicate value, even though it is empty tree. (Case 1)
From now on Case 2's unique function call.
When tree does not exist yet, first it makes a new record for the value by make_record function and it builds a new tree by start_new_tree function with new record.
In start_new_tree function, it makes leaf node by make_leaf and make_node function.
Summary for call path in this case.
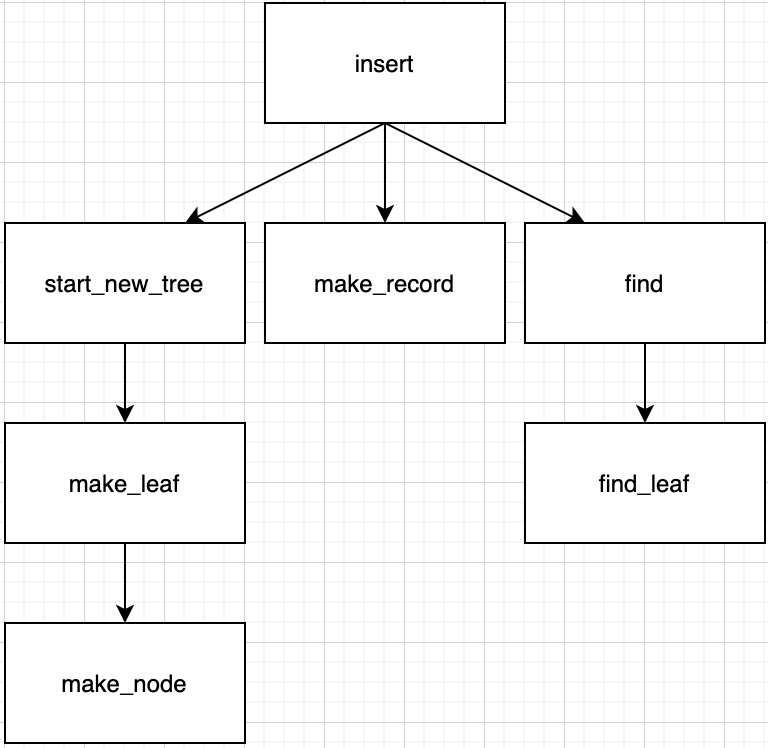
Suppose tree is not empty. It means we don't have to call functions to make new tree like Case 2.
First, do the duplicate value check. (Case 1)
Second, make a new record for the value. (Case 2)
From now on Case 3's unique function call.
It gets node which has appropriate position for the value by find_leaf function.
Node's num_keys is less than order - 1 means there is room for new record. So, just insert new record into node without splitting by insert_into_leaf function.
Summary for call path in this case.
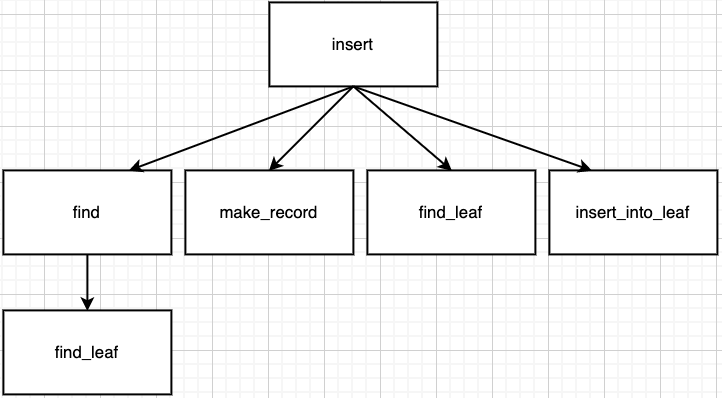
Suppose tree is not empty. It means we don't have to call functions to make new tree like Case 2.
First, check the duplicate value. (Case 1)
Second, make a new record for the value. (Case 2)
Third, find appropriate leaf node for new record. (Case 3)
From now on Case 4's unique function call.
Node's num_key is not less then order - 1 means there is no room for new record. So, split node into two (original node + new node) and insert new record into appropriate node among them by insert_into_leaf_after_splitting function.
Make a new leaf node for splitting by make_leaf function.
We can know where to split in original node for splitting by cut function.
After split into two nodes, to add new node's key to parent node, call insert_into_parent function.
Summary for call path until now.
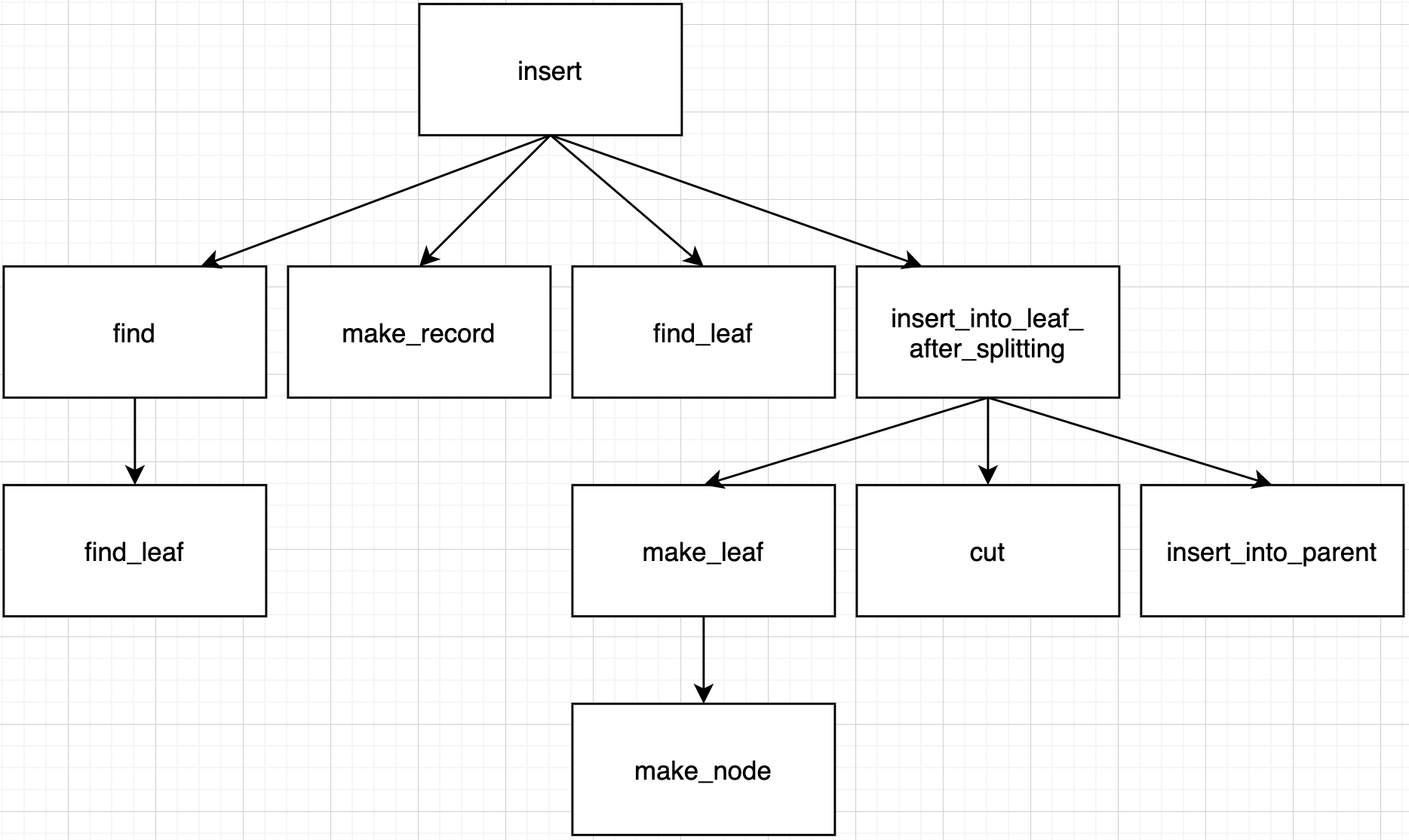
In Case 4, there are 3 different cases.
It means that tree needs new root. So, make a new root, insert new node's key into new root and let root's pointer points new children by insert_into_new_root function.
Summary for call path in this case.
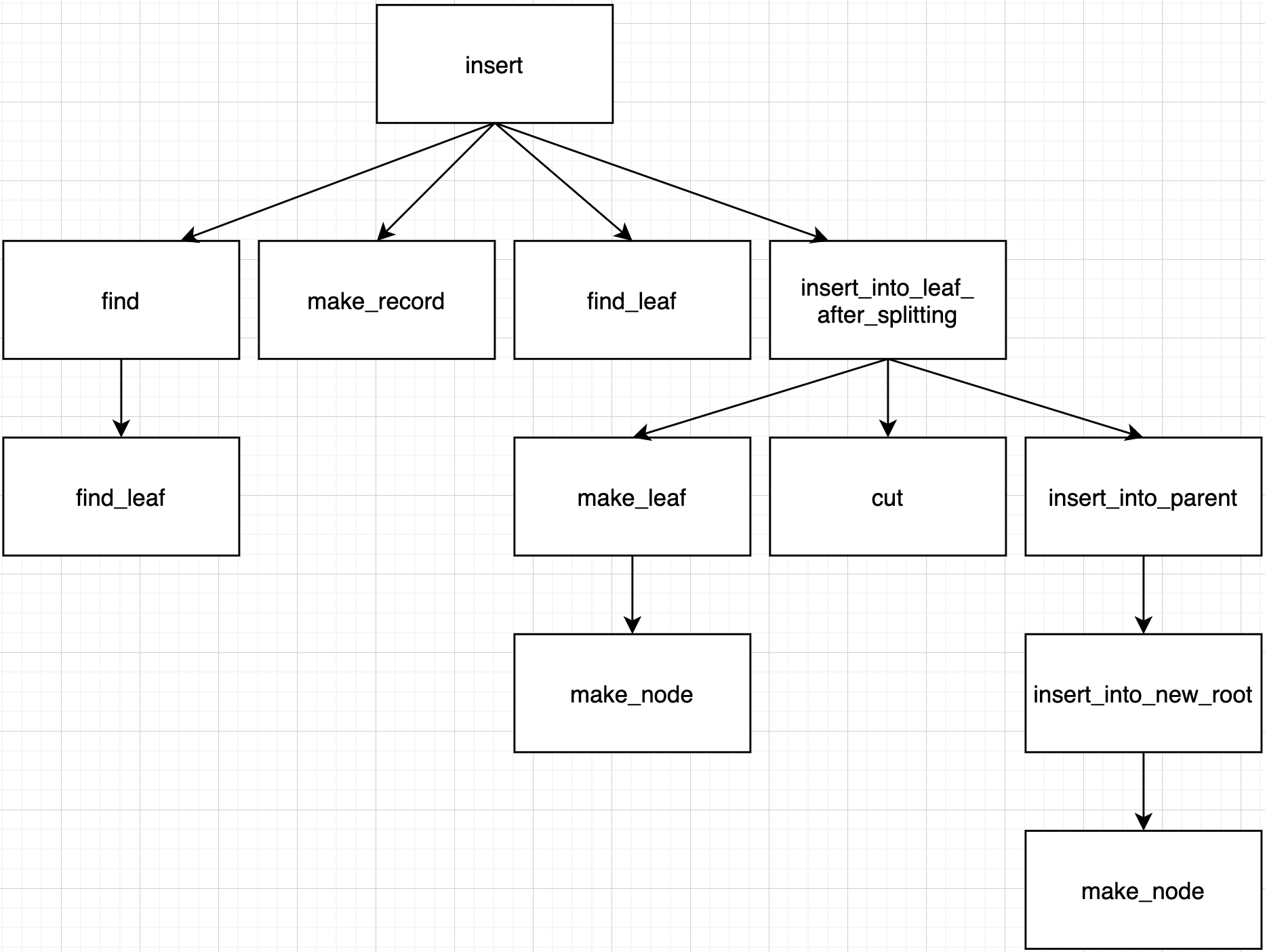
Find original node's index in parent by get_left_index function to insert new node into right position of parent.
Parent's num_keys is less than order - 1 means there is room for new key. So, insert new key into parent without splitting by insert_into_node function.
Summary for call path in this case.
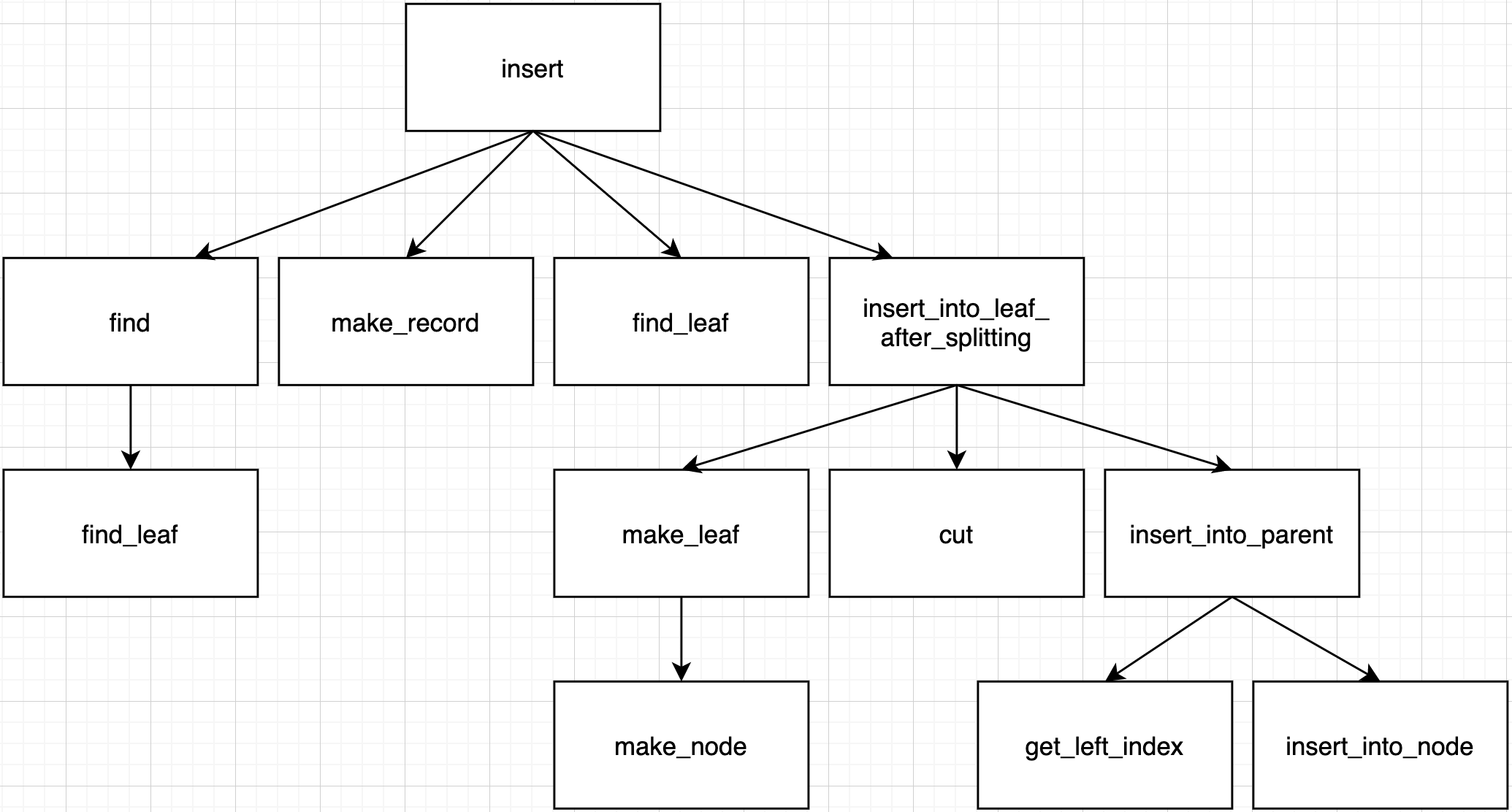
Find original node's index in parent by get_left_index function to insert new node into right position of parent.
Parent's num_keys is not less than order - 1 means there is no room for new key. So, split parent node and insert new key into right parent node by insert_into_node_after_splitting function.
In this case, we need recursive function call between insert_into_parent and insert_into_node_after_splitting. Because, split parents's parent can be split because of k_prime (no room for new key). If parents's parent has room for k_prime, we call insert_into_node function and recursive call ends.
Summary for call path in this case.
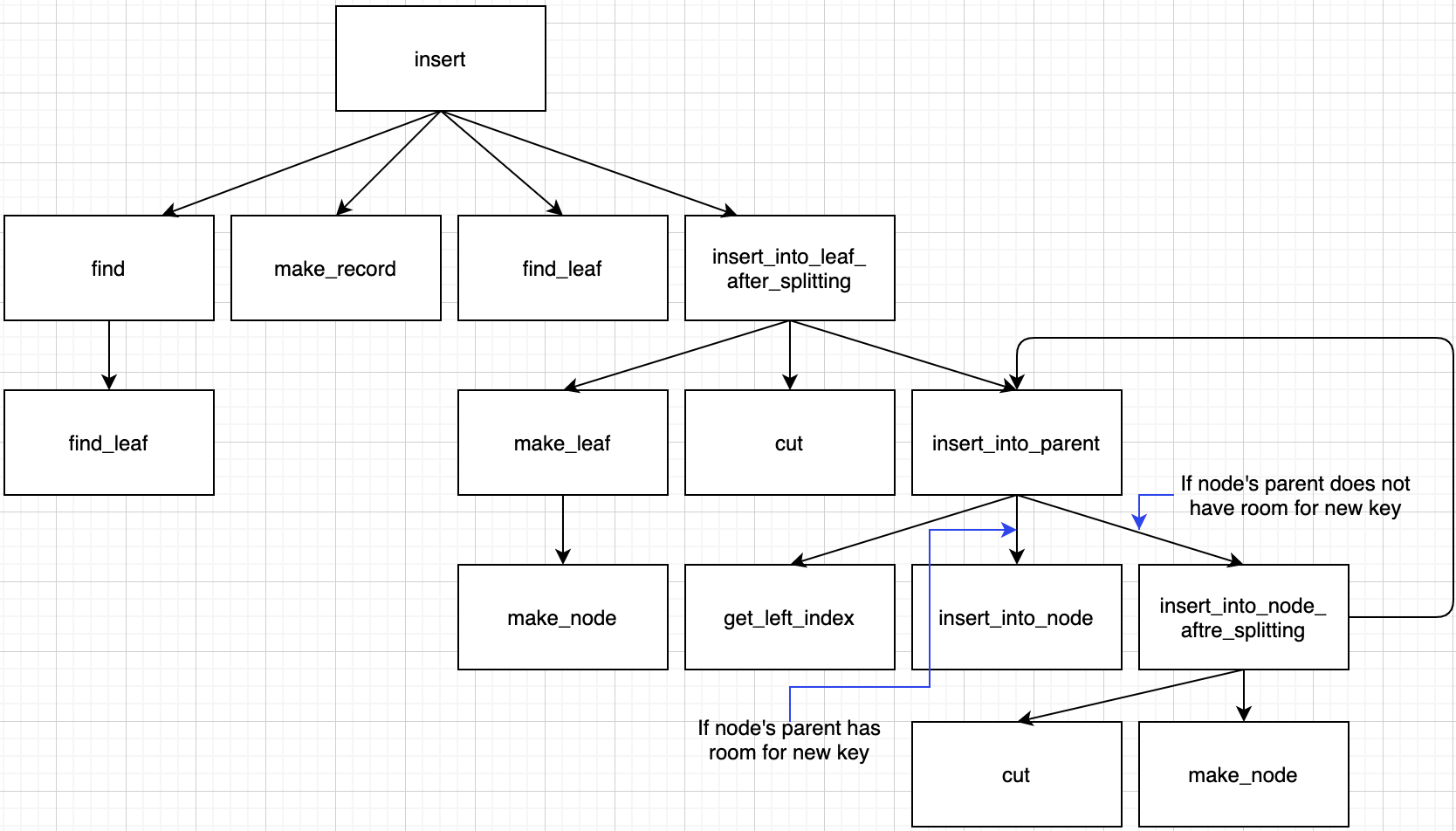
Every deletion is starting with delete and destroy_tree function in main.c file.
// 'deletion funtion' located in 'bpt.c'
node * delete(node * root, int key) {...}
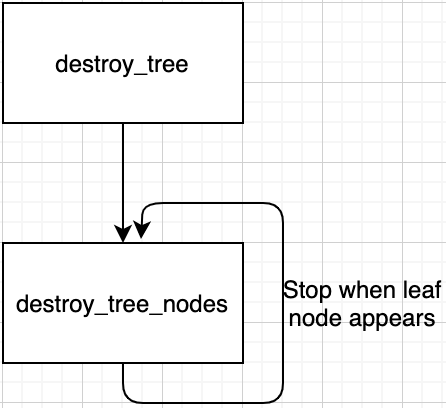
node * destroy_tree(node * root) {...}destroy_tree function calls destroy_tree_nodes function and destroy_tree_nodes calls itself recursively until leaf node appears.
Summary for call path in this case.
It calls find and find_leaf functions to find key_record and key_leaf. If both of them are not NULL, call delete_entry function.
Remove record by remove_entry_from_node function.
Summary for call path until now.
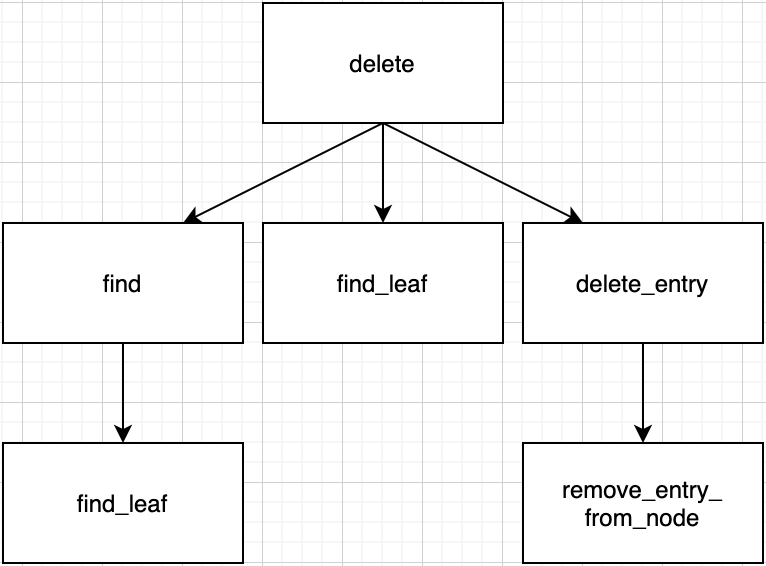
Because it is root, we don't have to modify structure. Just call adjust_root function.
Summary for call path in this case.
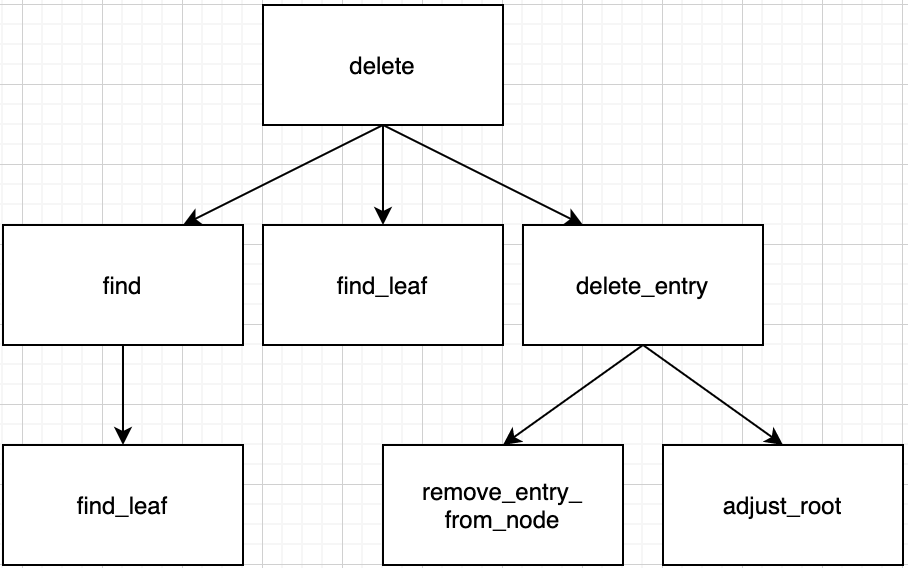
min_keys is the value that limits the minimum value of num_keys in node. It is determined by cut function. If num_keys is equal or more than this, just return root in delete_entry function.
Summary for call path in this case.
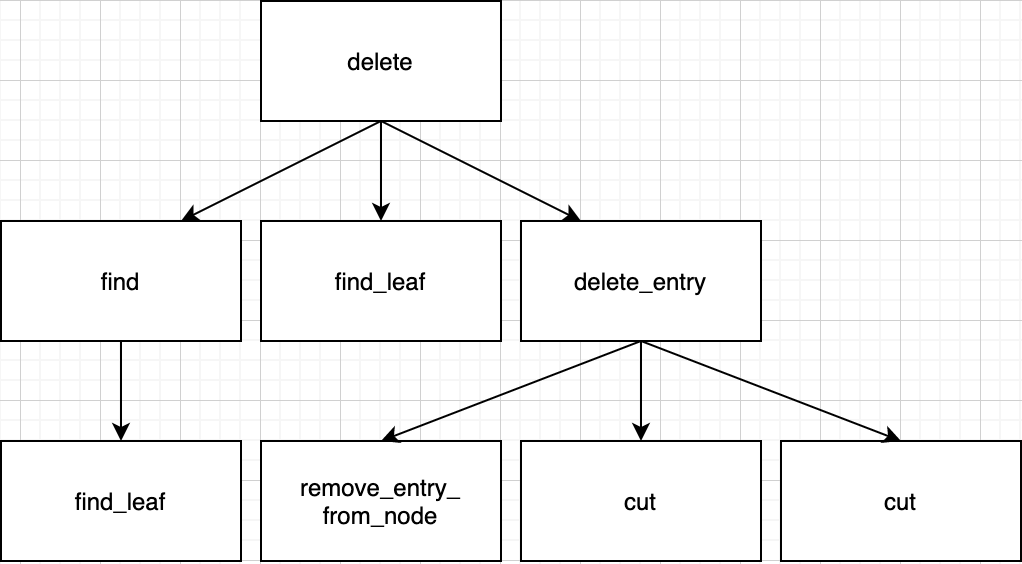
Get neighbor_index by get_neighbor_index function. neighbor_index is nearest neighbor (sibling) index of parameter node. If neighbor is not exist, it returns -1 for special case.
Assume that just one coalesce_nodes function call can modify tree well.
If sum of neighbor node and me is less than capacity, do the merge by coalesce_nodes function. We should delete node which key is deleted from, because its all keys move to neighbor node, there is no keys. This can be dealt by delete_entry function.
In delete_entry function, deletion will end with Case 1 or 2.
Summary for call path in this case.
- Ends with Case 1
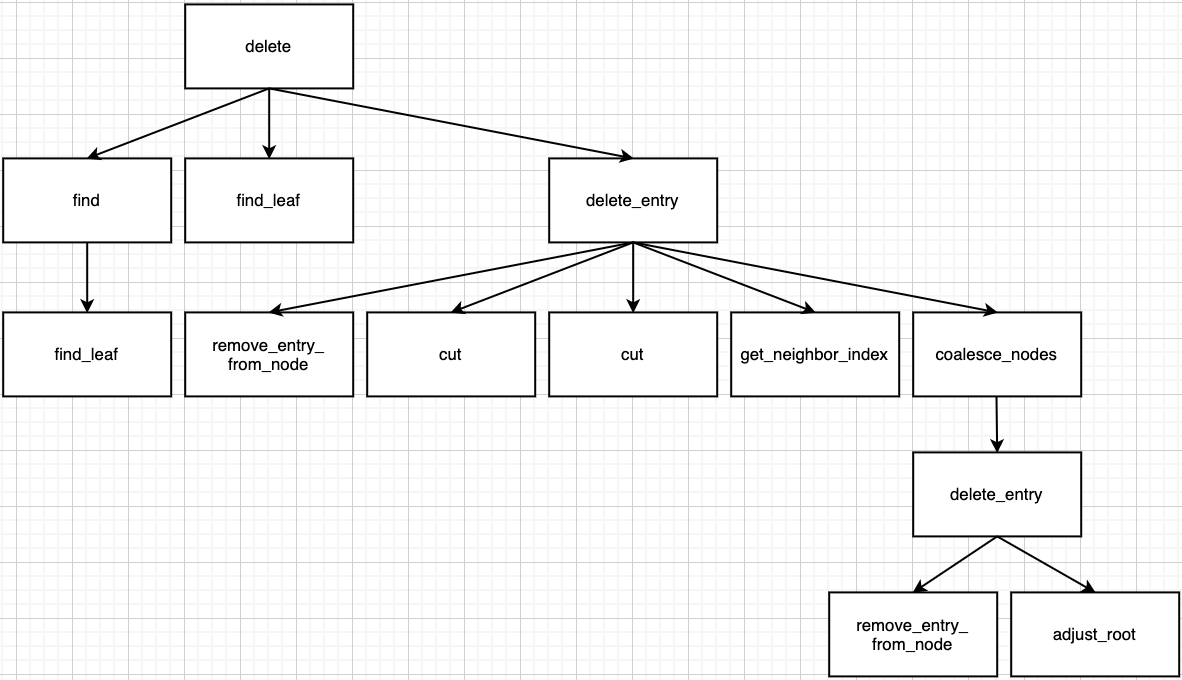
- Ends with Case 2
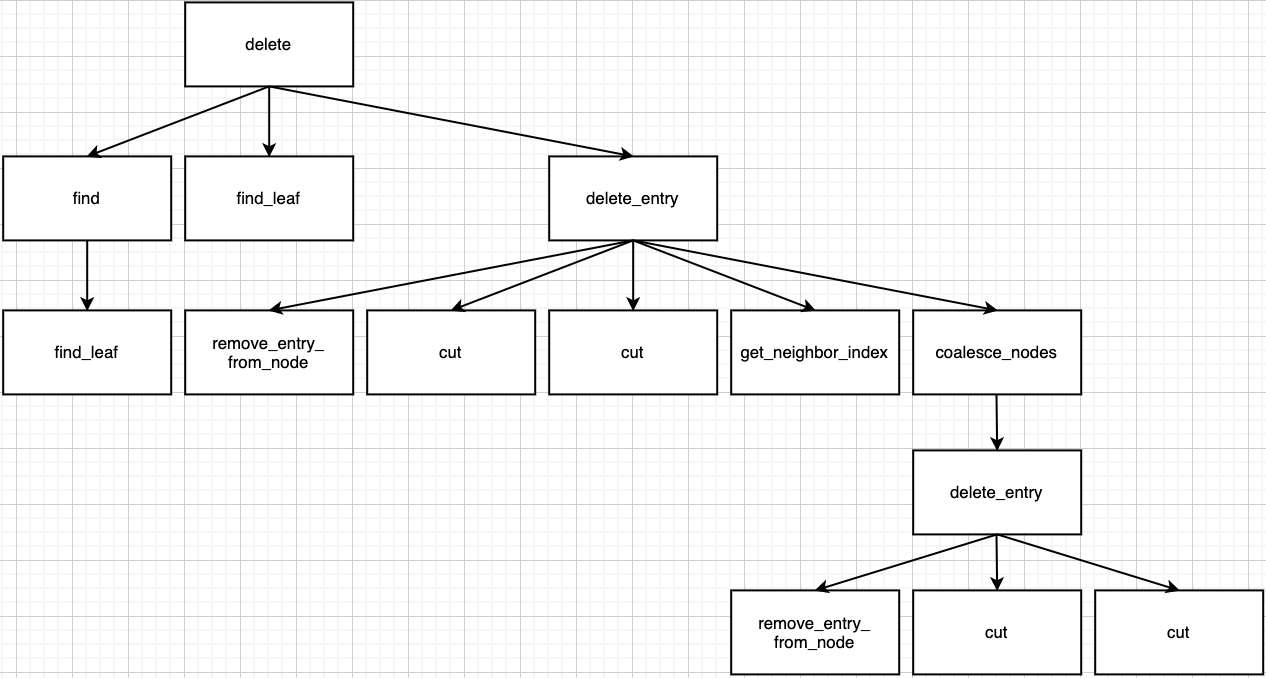
If sum of neighbor node and me is equal or more than capacity, do the split by redistribute_nodes function.
Summary for call path in this case.
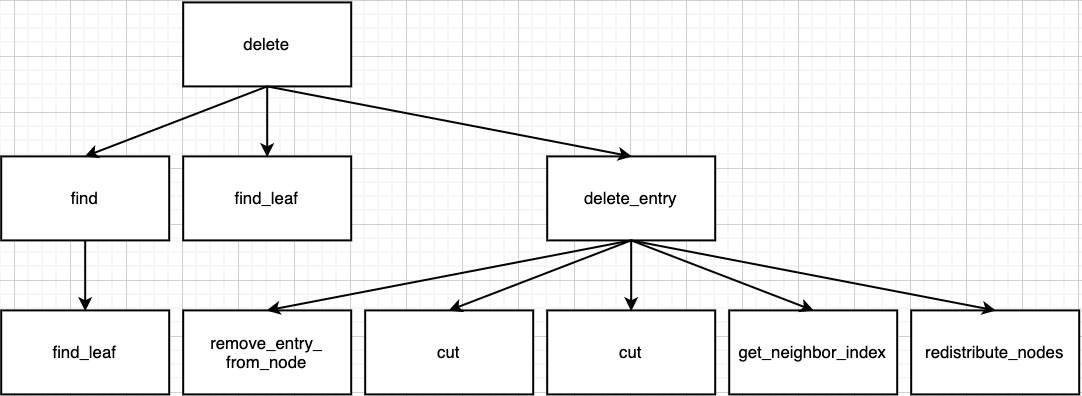
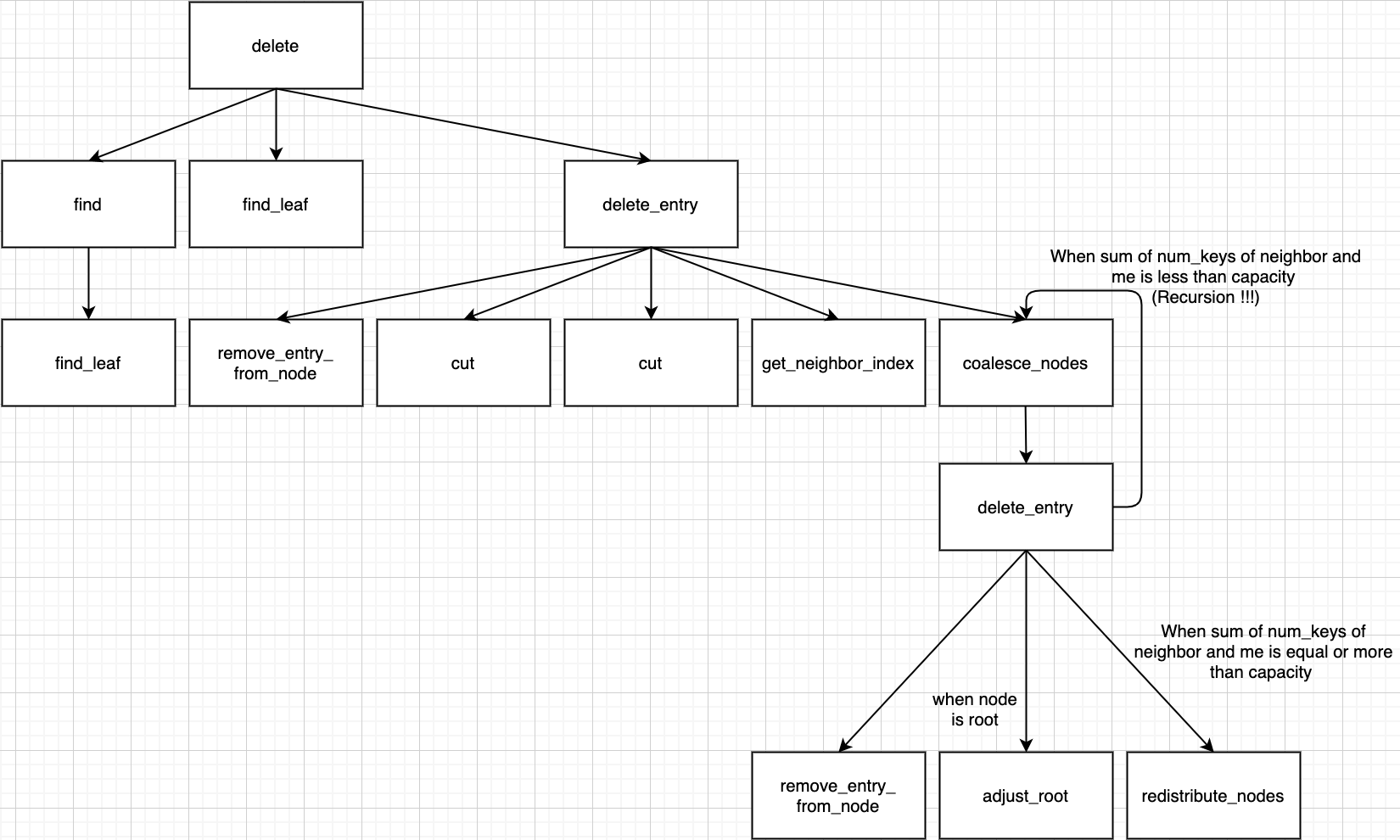
In Case 3 - 1, if parent node's num_keys is less than min_keys, parent node needs adjust too by coalesce_nodes or redistribute_nodes function.
This case is terminated by 1, 2, 3 and be recursive by 4.
adjust_root- num_keys ≥ min_keys
- redistribute_nodes
- coalesce_nodes → recursion
Summary for call path in this case.
insertion이 발생하면 제일 먼저, find_leaf 함수를 이용해 insert되는 record가 들어가야 하는 적절한 leaf node를 찾습니다.
만약 해당 leaf node가 가득 차 있다면 leaf node를 두개로 분할해야 합니다.
leaf node를 분할하고 record를 insert하기 위해서 insert_into_leaf_after_splitting 함수를 호출합니다.
위 함수에서 새로운 leaf node를 생성하고 record가 들어가야 하는 위치인 insertion_index를 찾습니다. insertion_index는 record의 key 대소관계 비교를 통해 찾아 집니다.
temp_node에 기존 leaf node의 record들과 insert된 record를 insertion_index를 사용하여 순서에 맞게 모두 삽입한 뒤 기존 leaf node의 record들을 모두 삭제합니다.
이후 cut 함수를 이용해 temp_node 안의 record들을 기존의 leaf node와 새로 만든 leaf node에 적절히 분배하고 새로운 leaf node의 parent를 기존의 leaf node의 parent와 같게 만듭니다. 위의 적절히 분배는 cut 함수로 얻어진 split 위치 이전의 temp node record들은 기존의 leaf node에 삽입하고 split 위치부터는 새로운 leaf node에 삽입하는 것을 의미합니다.
위의 과정을 거치면 새로운 key인 new_key가 만들어 집니다.
이 경우는 기존의 leaf node가 root node인 것을 말합니다. 따라서 insert_into_new_root 함수를 이용해 새로운 root node를 생성한 뒤 기존의 leaf node와 새로운 leaf node를 parent node에 연결합니다. 위에서 언급한 new_key는 root node에서 기존의 leaf node와 새로운 leaf node를 가리키는 pointer 사이의 key가 됩니다. 이후 split이 종료 됩니다.
Case 1의 조건에서 leaf node에서 split이 한번만 발생한다고 가정하였기 때문에 insert_into_node 함수를 사용해 new_key를 parent 노드에 삽입하고 parent의 pointer에 새로운 leaf node를 연결한 뒤 split이 종료 됩니다.
Case 1 - 2에서 기존 leaf node의 parent에 key와 새로운 leaf node가 들어갈 공간이 없다면 (= parent node가 가득 차 있다면), parent node를 split한 뒤 new_key가 parent node에 삽입되어야 합니다. 이는 insert_into_node_after_splitting 함수를 통해 이루어 집니다.
여기서 부터 위의 parent node를 old node, 기존의 leaf node를 left node, 삽입되어야 하는 new_key를 key, 새로운 leaf node를 right node라고 부르겠습니다.
insert_into_node_after_splitting 함수에서 split된 old node의 record들이 들어갈 new_node를 만들고 temp_keys, temp_pointers를 만들어 줍니다.
old node의 key, pointer들과 new_key, right node를 temp_keys와 temp_pointers로 순서에 맞게 옮겨 줍니다. 여기서 순서에 맞게는 old node의 left node를 가리키는 pointer의 바로 다음 pointer 위치에 right node를 가리키는 pointer가, left node와 right node를 가리키는 pointer 사이에 key가 오도록 (= temp_keys에서 key가 left node pointer index 위치에 오도록) 배치하는 것을 말합니다.
cut 함수를 통해 split 위치를 얻습니다.
temp_keys의 split - 1 위치의 key는 k_prime이 되고 k_prime 기준 왼쪽은 old node로 오른쪽은 new node로 삽입한 뒤 new node의 child들의 parent를 new node로 갱신하여 줍니다. (k_prime을 기준으로 잡은 근거는, pointer와 key들의 배치를 pointer[0] - key[0], pointer[1] - key[1], ... , pointer[x] - key[x] (=k_prime), ... , pointer[n-1] - key[n-1], pointer[n] 으로 보았을 때 기준 입니다)
위의 과정이 종료되면 insert_into_parent 함수를 호출합니다.
만약 old node가 root라면 insert_into_new_root 함수를 호출하여 insertion이 종료됩니다.
만약 old node의 parent에 k_prime과 new node가 삽입될 자리가 있다면 insert_into_node 함수를 통해 insertion이 종료됩니다.
만약 old node의 parent가 가득 찬 상태라면 insert_into_node_after_splitting 함수를 호출하여 위의 과정을 반복 실행합니다.
key를 node에서 삭제 후 node의 key 개수와 neighbor의 key 개수의 합이 capacity보다 커지는 경우 Redistribution을 실행합니다.
Redistribution은 2가지 경우로 나누어 집니다.
이 경우 node의 neighbor는 node의 오른쪽 sibling이 됩니다.
2가지 경우가 존재합니다
node의 마지막 key와 pointer의 다음 위치에 neighbor의 0번째 key와 pointer를 가져온 뒤 node의 parent의 k_prime_index 위치의 key에 neighbor의 1번째 key 값을 복사 합니다.
neighbor는 0번째 key와 pointer를 node에게 주었기 때문에 자신의 key와 pointer들을 앞으로 한 칸씩 전진 시킵니다.
node의 마지막 key 다음 위치에 k_prime을 가져오고, 마지막 pointer의 다음 위치에 neighbor의 0번째 포인터를 가져온 뒤 가져온 포인터의 부모를 node로 변경합니다. node의 parent의 k_prime_index 위치의 key 값을 neighbor의 0번째 key 값으로 변경합니다.
neighbor는 0번째 pointer를 node에게, 0번째 key를 parent에게 주었으므로 자신의 key와 pointer들을 앞으로 한칸씩 전진시킵니다.
이 경우 node의 neighbor는 node의 왼쪽 sibling이 됩니다.
2가지 경우가 존재합니다.
node의 key와 pointer들을 한 칸씩 뒤로 옮긴 뒤 neighbor의 마지막 key와 pointer를 node의 0번째 key와 pointer로 가져옵니다.
이후 node의 parent의 k_prime_index의 key 값을 node의 0번째 key 값으로 복사합니다.
node의 key와 pointer들을 한 칸씩 뒤로 옮긴 뒤 neighbor의 마지막 pointer를 node의 0번째 pointer로 가져오고 k_prime 값을 node의 0번째 key로 가져옵니다. 가져온 pointer의 parent를 node로 변경합니다.
이후 parent의 k_prime_index 위치의 key에 neighbor의 마지막 key를 가져옵니다.
key를 node에서 삭제 후 node의 key 개수와 neighbor의 key 개수의 합이 capacity보다 작아지는 경우 Coalesce을 실행합니다.
만약 node의 neighbor가 node의 오른쪽 sibling인 경우, node가 neighbor를 가리키게 neighbor가 node를 가리키게 바꾸어 줍니다.
Coalesce는 2가지 경우로 나누어 집니다.
neighbor 마지막 key와 pointer 뒤에 node의 key와 pointer를 순서대로 옮기고 neighbor의 right sibling을 가리키는 pointer를 node가 기리키고 있는 right sibling으로 변경해 줍니다.
이후 delete_entry 를 호출하여 node의 parent에서 k_prime 삭제를 진행합니다.
neighbor의 마지막 key 다음 위치에 k_prime을 삽입합니다.
neighbor의 마지막 key와 pointer 다음 위치에 node의 key와 pointer를 순서대로 옮긴 뒤 옮긴 pointer가 가리키고 있는 node들의 parent를 neighbor로 변경하여 줍니다.
이후 delete_entry 를 호출하여 node의 parent에서 k_prime 삭제를 진행합니다.
Case 1, 2에서 delete_entry 함수를 호출하면 4가지의 경우가 발생할 수 있습니다. 그 중 3가지는 deletion이 종료되게 되고, 1가지는 다시 위의 Coalesce를 발생 시킵니다.
deletion이 종료되는 3가지 경우
-
adjust_root함수 호출→ node의 parent가 root인 경우입니다. 여기서는
adjust_root함수 내부에서 root를 재조정한 뒤 deletion이 종료 됩니다 -
node의 parent의 num_keys가 min_keys보다 큰 경우
→ 이 경우는 tree가 modify될 필요가 없기 때문에 deletion이 종료 됩니다.
-
redistribute_nodes함수 호출→
redistribute_nodes함수 내부에서 재분배 후 deletion이 종료됩니다.
Coalesce가 다시 발생하는 1가지 경우
-
coalesce_nodes함수 호출→ 이 경우 node의 parent에서 k_prime을 삭제하면, parent의 num_keys와 parent 이웃의 num_keys가 capacity 이하로 떨어진다는 의미입니다. 따라서 위의 coalesce 과정이 반복됩니다.
기존의 b+ tree에서 사용되었던 node를 page라는 새로운 구조체로 변경하여 사용할 것 입니다.
page struct는 4096 bytes의 고정된 크기를 가지며, 4가지 종류의 페이지가 존재 합니다.
-
Header page
→ 8 bytes 크기의 Free page number, Root page number, Number of pages를 가지고 있습니다. 각각 첫번째 Free page number, Root page number, Page 개수를 의미합니다.
-
Free page
→ 8 bytes 크기의 Next free page number를 갖고 있습니다. 이는 자신의 다음 free page number를 의미합니다.
-
Internal page
→ 128 bytes 크기의 page header 1개, 16 bytes의 leaf record 248개를 가지고 있습니다.
-
Leaf page
→ 128 bytes 크기의 page header 1개, 128 bytes의 leaf record 31개를 가지고 있습니다.
Internal page와 Leaf page에는 각각 page header와 record가 존재합니다.
-
Page header
→ 128 bytes의 크기를 가지고 있습니다.
→ 8 bytes 크기의 Parent page number, Number of keys, 4 bytes의 is leaf 가 존재 합니다. 각각 자신의 parent page number, 가지고 있는 key의 개수, 자신이 leaf page인지 아닌지를 의미합니다.
→ Internal page의 경우 8 bytes 크기의 One more page number를 가지며, 이는 자신의 record가 모두 채워졌을 때 마지막 key보다 크거나 같은 key를 가지는 page의 page number를 가리키기 위함 입니다.
→ Leaf page의 경우 8 bytes 크기의 Right sibling page number를 가지며, 이는 자신의 오른쪽 형제의 page number를 의미합니다. 이렇게 사용하는 이유는 scan의 효율성을 높이기 위함 입니다.
-
Internal record
→ 8 bytes 크기의 key와 page number를 담고 있는 구조체 입니다.
-
Leaf record
→ 8 bytes 크기의 key와 120 bytes 크기의 value를 담고 있는 구조체 입니다.
각각의 page는 모두 4096 bytes의 크기를 가집니다.
4가지 종류의 page를 각각 struct로 구현 후 struct page_t 내부에서 union을 사용하여 4가지 page들을 page_t 타입으로 한번에 사용 할 것입니다.
internal page와 leaf page는 동일한 struct page로 구현 후 내부적으로 다른 부분만 union을 사용하여 둘을 page 타입으로 한번에 사용할 것입니다. 내부적으로 다른 부분이란 one_more_pagenum과 right_sibling_pagenum, internal record와 leaf record를 말합니다.
record의 경우 internal record와 leaf record의 struct를 각각 만들어서 사용할 것입니다.
요약 : 아래와 같은 코드로 page layout이 만들어 집니다.
/* struct which represents all kind of pages
* (header, free, internal, leaf)
*/
typedef struct page_t {
union {
// header page struct
headerPage h;
// free page struct
freePage f;
// struct for internal page and leaf page
page p;
};
} page_t;page가 자신의 page number에 맞는 Disk file 위치에 있도록 구성할 것입니다.
따라서 disk file의 시작 위치로 부터 Page size (4096) * page number 만큼 떨어진 위치에 page가 존재하게 구성하는 것입니다.
특별히 header page는 항상 disk file의 offset 0번 위치에서 시작하도록 구성 할 것입니다.
각각의 I/O는 Disk Manager APIs를 통해 수행 되며, File APIs 내부에서 page를 읽어 오거나, 읽어 온 page의 내용에 변경이 생기는 즉시 Disk Manager APIs 호출할 것입니다.
즉, page를 읽어 와서 page 내부 데이터를 봐야하는 경우, 읽어 온 page 내부 값을 변경하여 disk와 in-memory 상의 데이터가 같지 않은 경우 I/O를 수행 할 것입니다.
DB APIs는 user와 db간의 interaction을 위한 함수들을 설계할 것입니다.
int open_table(char* pathname);
int db_insert(int64_t key, char* value);
int db_delete(int64_t key);
int db_find(int64_t key, char* ret_val);위의 함수들을 통해서 file API를 호출하여 db에 접근 할 수 있도록 할 것 입니다.
DB_API 사용자의 명령을 받아오는 API 입니다.
File APIs는 file에 있는 db 내용을 담아 오기 위한 page에 대한 구조체가 정의되어 있으며, in-memory 상에서 DB APIs의 요청에 알맞는 작업을 수행하는 함수가 정의되어 있습니다.
또한 file에서 page로 값을 읽어 오거나, page에서 file로 값을 쓸 때와 같이 file과 page 간의 상호작용이 필요할 때 사용 되는 함수들이 설계될 것 입니다.
여기서 Disk Manager APIs를 호출하여 변경된 값을 쓰거나, 읽어야 할 값을 읽어 오는 작업을 수행합니다.
File API는 DB APIs의 요청을 받아 작업을 수행하고, 결과를 반영하기 위해 Disk Manager APIs를 호출하는 API 입니다.
Disk Manager APIs는 memory 상에서 수정된 정보들을 실제 disk에 써주는 작업을 하는 함수들을 설계할 것 입니다.
오직 Disk Manager APIs를 통해서만 disk에 접근 가능하도록 분리하기 위해서 입니다.
Disk Manager APIs는 File APIs로 부터 읽기 쓰기 작업을 요청 받아 disk에 직접 접근하여 작업을 진행하는 API 입니다.
따라서 User → DB APIs → File APIs → Disk Manager APIs → Disk의 구조로 top-down operation이 일어나게 끔 디자인 할 계획입니다.