
Versículo chave: "Consagre ao Senhor tudo o que você faz, e os seus planos serão bem-sucedidos." - Provérbios 16:3

Em engenharia de software, uma arquitetura de microsserviços (microservices) é uma abordagem arquitetônica e organizacional do desenvolvimento de software na qual o software consiste em pequenos ou um conjunto de serviços independentes e com escopo limitado a uma única função comercial que se comunicam usando APIs bem definidas. Esses serviços pertencem a pequenas equipes autossuficientes. Os microsserviços são uma coleção de unidades menores que sempre entregam e implementam aplicativos grandes e complexos.
Um serviço (service) é uma parte da nossa aplicação back-end isolada, contendo as regras de negócio, APIs e controle de dados.
Os microserviços representam uma mudança de paradigma na arquitetura de software, dividindo as aplicações em pequenos serviços implantáveis de forma independente. Essa abordagem oferece flexibilidade incomparável na escalabilidade e manutenção dos componentes do sistema, permitindo que as organizações desenvolvam e evoluam diferentes partes de suas aplicações de forma independente.
Com base em nossa discussão anterior sobre arquiteturas de 3 níveis, que podem ser implementadas usando abordagens monolíticas ou microserviços, exploramos os conceitos e insights essenciais dos microsserviços. Nosso objetivo é fornecer uma compreensão abrangente desse paradigma contemporâneo de design de sistemas, equipando você com conhecimentos cruciais para a arquitetura moderna de software e preparando para se destacar nas próximas entrevistas.
Os microsserviços surgiram como uma alternativa mais popular a SOA devido aos seus benefícios. Os microsserviços são mais compostos, permitindo que as equipes reutilizem a funcionalidade oferecida pelos pequenos pontos centrais de serviço. Os microsserviços são mais robustos e permitem um escalonamento vertical e horizontal mais dinâmico. Portanto, eles são um padrão de arquitetura orientado a serviços em que os aplicativos são construídos como uma coleção de várias unidades de serviço independentes menores.
Um microsserviço é um serviço web responsável por parte da lógica de domínio. Vários microsserviços são combinados para criar um aplicativo, e cada um representa uma funcionalidade para o domínio. Os microsserviços interagem uns com os outros por meio de APIs, como REST ou gRPC ou GraphQL, mas não têm conhecimento da atividade interna de outros serviços. Essa interação harmoniosa entre microsserviços é a arquitetura de microsserviços. Ele faz com que o software seja composto de múltiplos serviços de ligação solta que são independentes uns dos outros e implantados separadamente.
Podemos citar Martin Fowler e Adrian Cockcroft sobre aspectos-chave dos microserviços:
"O estilo arquitetônico de microserviços é uma abordagem para desenvolver uma única aplicação como um conjunto de pequenos serviços, cada um rodando em seu próprio processo e comunicando-se com mecanismos leves, frequentemente uma API de recursos HTTP. Esses serviços são construídos em torno das capacidades do negócio e podem ser implantados de forma independente por máquinas totalmente automatizadas. Há um mínimo necessário de gerenciamento centralizado desses serviços, que podem ser escritos em diferentes linguagens de programação e usar diferentes tecnologias de armazenamento de dados." - De Martin Fowler
"Microservices são arquiteturas orientadas a serviços frouxamente acopladas com contextos limitados." - De Adrian Cockcroft
Principais Aspectos dos Microserviços: A partir das definições perspicazes de Martin Fowler e Adrian Cockcroft, podemos resumir estes aspectos-chave de uma arquitetura de microsserviços:
Decompor a aplicação monolítica em pequenos serviços independentes. Isso permite que diferentes equipes de produto desenvolvam, testem e implantem serviços alinhados a capacidades específicas do negócio. Útil para grandes organizações desmontarem sistemas monolíticos e melhorarem a produtividade.
Serviços frouxamente acoplados que se comunicam via APIs. Componentes frontend/backend se comunicam via REST, enquanto as comunicações entre serviços usam RPC para solicitações/respostas eficientes.
Cuidadosamente projetados em torno de contextos delimitados. Cada serviço possui limites claros de módulo e lógica de domínio encapsulada para evitar acoplamento estreito entre os serviços.
Possibilita práticas eficazes de DevOps. É uma parte importante da metodologia de desenvolvimento de microserviços. Equipes pequenas e full-stack possuem totalmente serviços específicos de ponta a ponta. Conteinerização, automação e orquestração de contêineres são usadas para implantar microserviços de forma eficaz.
Escalável horizontalmente por design, resistente a falhas. Os serviços podem escalar de forma independente conforme necessário. Construído pensando na tolerância a falhas.
Governança descentralizada e flexibilidade. As equipes podem escolher a tecnologia que fizer sentido para seu serviço.
Requer monitoramento e instrumentação extensos devido a:
-
Crescimento dos serviços - À medida que os monólitos se decompõem em muitos serviços independentes, o número de componentes a serem monitorados cresce rapidamente.
-
Abstração de infraestrutura via containers/orquestradores - Plataformas de runtime como Kubernetes lidam com a infraestrutura. Portanto, o monitoramento deve acontecer no nível do código da aplicação usando sidecars para agregar logs, métricas e rastreamentos.
Arquitetura orientada a serviços (SOA) e estilos de arquitetura de microserviços são marcos importantes na evolução da arquitetura de software. O diagrama abaixo mostra a progressão dos principais estilos arquitetônicos.
A arquitetura orientada a serviços surgiu no final dos anos 1990 para ajudar a gerenciar a crescente complexidade dos sistemas de software corporativos. Nos anos 2000, a SOA ganhou mais atenção e adoção da indústria por empresas. No entanto, a SOA enfrentou desafios de complexidade na implementação.
Então, na década de 2010, surgiu a arquitetura de microserviços em resposta às limitações da SOA. Muitas grandes empresas de internet começaram a adotar microsserviços para dividir seus serviços em componentes menores. Os microserviços ganharam força com a evolução da computação em nuvem, já que contêineres e ferramentas de orquestração facilitaram o desenvolvimento, a implantação e o monitoramento dos microsserviços.

Vamos comparar as diferenças deles com mais detalhes. O diagrama abaixo lista algumas das diferenças.
O estilo arquitetônico SOA oferece serviços de granulação grosseira, tipicamente uma abordagem centralizada onde os serviços são agrupados por funções de negócio e compartilhados entre múltiplas aplicações. O estilo microsserviço oferece granularidade de serviços detalhada por meio de uma abordagem descentralizada onde pequenos serviços independentes executam funções específicas dentro de um contexto de aplicação.
Os métodos de comunicação também evoluem com o tempo. A SOA enfatiza protocolos de comunicação uniformes e interfaces padronizadas para que os serviços interajam. Microserviços tendem a usar protocolos e interfaces de comunicação diversos, frequentemente baseados em REST ou filas de mensagens.
A computação em nuvem evoluiu de Infraestrutura como Serviço (IaaS) para Plataforma como Serviço (PaaS) e depois PaaS baseada em contêineres. Portanto, aplicações baseadas em microserviços são implantadas em contêineres por padrão.
À medida que a arquitetura técnica muda, a estrutura organizacional a reflete (lei de Conway). Assim, com microserviços, a estrutura de equipes exige equipes de produto multifuncionais. Cada equipe foca em um domínio específico.
É uma abordagem de engenharia de software que se concentra na decomposição de um aplicativo em módulos de função única com interfaces bem definidas. Esses módulos podem ser implantados e operados de forma independente por pequenas equipes que possuem todo o ciclo de vida do serviço. O termo “micro” refere-se ao dimensionamento de um microsserviço que deve ser gerenciado por uma única equipe de desenvolvimento (5 a 10 desenvolvedores). Nesta metodologia, grandes aplicações são divididas nas menores unidades independentes.
Pensando de forma minimalista e conceitualmente limpa, um microserviço é essencialmente um endpoint (ou um conjunto de endpoints) especializado e desacoplado, responsável por um domínio de dados ou funcionalidade específica, e que pode ser orquestrado dentro de uma arquitetura maior. Estes pequenos independentes se comunicam entre si com as APIs bem definidas. Esta abordagem torna o software escalável, mais rápido de desenvolver e atualizar de forma rápida, eficiente e fácil.

A arquitetura de microsserviços é um padrão evoluído que mudou fundamentalmente a maneira como o código do lado do servidor é desenvolvido e gerenciado. Esse padrão de arquitetura envolve o design e o desenvolvimento do aplicativo como uma coleção de serviços fracamente acoplados que interagem em APIs leves e bem definidas para atender aos requisitos de negócios. O objetivo é ajudar as empresas de desenvolvimento de software a acelerar o processo de desenvolvimento, facilitando a entrega e o desenvolvimento contínuos.
Se falarmos sobre seu nível elementar, um microsserviço específico atua como um aplicativo em si mesmo que forma um aplicativo maior com outros microsserviços; Isso permite:

- Desenvolvimento mais fácil e rápido
- Manutenibilidade
- Escalabilidade
Essencialmente, isso permite que você gerencie e mantenha um aplicativo com mais eficiência. Há, no entanto, uma complexidade específica inerente a esse padrão, que pode ser mitigada com o uso de certas práticas recomendadas.
Todos sabemos que o design de microsserviços tem um impacto direto na resiliência da rede das arquiteturas modernas. Quando as empresas decidem criar usando microsserviços, é importante desenvolvê-los de forma eficiente e eficaz para que possam operar na rede, sem causar excesso de latência, consumo de largura de banda e perda de pacotes.
Então, discutiremos as práticas recomendadas básicas de microsserviços que você deve considerar se quiser obter um ecossistema de microsserviços eficiente e desprovido de complexidades arquitetônicas extremas.
Orientado por Modelo de Domínio Ao projetar a estrutura de caminhos de uma API RESTful, podemos nos referir ao modelo de domínio.
Escolha Métodos HTTP Adequados Definir alguns Métodos HTTP básicos pode simplificar o design da API. Por exemplo, o PATCH pode ser um problema para as equipes.
Implemente a Idempotência Adequadamente Projetar a idempotência antecipadamente pode melhorar a robustez de uma API. O método GET é idempotente, mas o POST precisa ser projetado corretamente para ser idempotente.
Escolha Códigos de Status HTTP Adequados Defina um número limitado de códigos de status HTTP para usar e simplificar o desenvolvimento de aplicações.
Versionamento Projetar o número de versão da API com antecedência pode simplificar o trabalho de atualização.
Caminhos Semânticos Usar caminhos semânticos facilita a compreensão das APIs, permitindo que os usuários encontrem as APIs corretas na documentação.
Processamento em lote Use batch/bulk como palavra-chave e coloque no final do caminho.
Linguagem de Consulta Projetar um conjunto de regras de consulta torna a API mais flexível. Por exemplo, paginação, ordenação, filtragem etc.
Adotar o princípio da responsabilidade única: O Princípio da Responsabilidade Única (SOLID) é o conceito de que qualquer objeto único em POO deve ser feito para uma função específica. Basicamente, faz parte dos princípios de programação apresentados por Robert Martin. Assim como no código, uma classe deve ter apenas um motivo para mudar, tornando o software mais sustentável, escalável e fácil de entender. Para adotar o SRP no desenvolvimento de software, você deve garantir que cada classe ou módulo tenha uma responsabilidade bem definida e que não esteja tentando fazer muitas coisas. Você também deve manter seus módulos desacoplados e usar interfaces claras e concisas para se comunicar entre eles. Para resumir isso, temos uma citação interessante:
"Reúna as coisas que mudam pelo mesmo motivo e separe as coisas que mudam por motivos diferentes." — O'Reilly
Podemos dizer que este é um dos melhores e mais essenciais princípios para construir um bom projeto de arquitetura, pois significa que um microsserviço, módulo, classe, subsistema ou função não deve ter vários motivos para mudar. Vamos entender este Princípio com um exemplo:
Um portal de comércio eletrônico pode ter uma arquitetura de microsserviços como esta:
Aqui, todos os serviços (por exemplo, Serviço de Listagem de Produtos, Serviço de Pedidos, Atendimento ao Cliente, Serviço de Pagamento, Serviço de Carrinho, Serviço de Lista de Desejos, etc.) têm responsabilidades únicas. Isso significa que é importante certificar-se de que você não está integrando um serviço com outro quando não for absolutamente necessário, pois torna a arquitetura mais complicada de manter e testar.
Construa equipes com responsabilidades claras: Para desenvolver a arquitetura de microsserviços, precisamos construir equipes que tenham responsabilidades claras. Isso pode ser feito de várias maneiras, como equipes baseadas em funções, equipes multifuncionais, etc. Nessa arquitetura, cada microsserviço funciona como um aplicativo independente. Portanto, cada equipe deve ser versátil o suficiente para lidar com suas operações.
Vamos entender isso com um exemplo: Uma organização pode ter equipes baseadas em funções, como desenvolvedores de UI/UX, desenvolvedores front-end, desenvolvedores back-end, administradores de banco de dados, QAs, desenvolvedores de middleware, etc., que trabalham isoladamente, mas interagem diariamente por meio de reuniões – pessoalmente ou usando várias ferramentas de comunicação como JIRA, Slack e assim por diante.
Quando pensamos em manutenção, às vezes pequenos bugs ou às vezes até grandes bugs também podem ocorrer no sistema. Portanto, o SCRUM pode ser uma solução possível. Ajuda cada membro da equipe a encurtar o tempo de inconsciência. Mas como as equipes são organizadas com base nas funções, a integração de uma atualização em um sprint pode se tornar uma tarefa complicada. Por exemplo, se os desenvolvedores de UI/UX não obtiverem nenhuma informação dos caras do servidor sobre as alterações em uma API, a nova API não será útil.
Então, qual é a solução?
Crie equipes multifuncionais com responsabilidades claras, para ajudar a orquestrar o trabalho entre as equipes: Uma equipe multifuncional responsável por toda a funcionalidade de microsserviços pode ser um grande benefício para o seu projeto. Essa equipe deve consistir em membros de todas as equipes baseadas em funções e é responsável por orquestrar as várias partes do aplicativo, ou seja, interface do usuário, desenvolvimento, banco de dados e até mesmo controle de qualidade.
Se houver duas versões do aplicativo, ou seja, web e mobile, os desenvolvedores de ambas as equipes devem estar presentes nessa equipe. O principal benefício desse tipo de equipe é que fica fácil resolver bugs, desenvolver novos recursos e implantá-los no ambiente de produção.
 |
 |
-
API Gateway: O gateway fornece um ponto de entrada unificado para aplicações clientes. Ele cuida do roteamento, filtragem e balanceamento de carga.
-
Registro de Serviços O registro de serviços contém os detalhes de todos os serviços. O gateway descobre o serviço usando o registro. Por exemplo, Cônsul, Eureka, Tratador de Zoológico, etc.
-
Camada de Serviço Cada microsserviço serve a uma função de negócio específica e pode rodar em múltiplas instâncias. Esses serviços podem ser construídos usando frameworks como Spring Boot, NestJS, etc.
-
Servidor de Autorização Usado para proteger os microserviços e gerenciar controle de identidade e acesso. Ferramentas como Keycloak, Azure AD e Okta podem ajudar aqui.
-
Bancos de dados de armazenamento de dados como PostgreSQL e MySQL podem armazenar dados de aplicação gerados pelos serviços.
-
Cache distribuído Cache é uma ótima abordagem para aumentar o desempenho da aplicação. As opções incluem soluções de cache como Redis, Couchbase, Memcached, etc.
-
Comunicação Assíncrona de Microserviços Usa plataformas como Kafka e RabbitMQ para suportar comunicação assíncrona entre microsserviços.
-
Microserviços de Visualização de Métricas podem ser configurados para publicar métricas no Prometheus e ferramentas como o Grafana podem ajudar a visualizar essas métricas.
-
Agregação e Visualização de Logs Gerados pelos serviços são agregados usando Logstash, armazenados no Elasticsearch e visualizados com Kibana.
Falando a sua palavra: o que mais você adicionaria à sua arquitetura de microserviços de produção?
 |
 |
Escolher o padrão certo de arquitetura de software é essencial para resolver problemas de forma eficiente.
-
Layered Architecture: Cada camada desempenha um papel distinto e claro dentro do contexto da aplicação. Ótimo para aplicações que precisam ser construídas rapidamente. Por outro lado, o código-fonte pode ficar desorganizado se as regras corretas não forem seguidas
-
Microservices Architecture: Divide um sistema grande em componentes menores e mais gerenciáveis. Sistemas construídos com arquitetura de microserviços são tolerantes a falhas. Além disso, cada componente pode ser escalado individualmente. Por outro lado, isso pode aumentar a complexidade da aplicação.
-
Event-Driven Architecture: se comunicam emitindo eventos que outros serviços podem ou não consumir. Esse estilo promove acoplamento frouxo entre os componentes. No entanto, testar componentes individuais torna-se desafiador
-
Client-Server Architecture: É composta por dois componentes principais - clientes e servidores se comunicando por meio de uma rede. Ótimo para serviços em tempo real. No entanto, servidores podem se tornar um ponto único de falha.
-
Plugin-based Architecture: Este padrão consiste em dois tipos de componentes - um sistema central e plugins. Os módulos de plugin são componentes independentes que fornecem uma funcionalidade especializada. Ótimo para aplicações que precisam ser expandidas com o tempo, como os IDEs. No entanto, mudar o núcleo é difícil.
-
Hexagonal Architecture: Este padrão cria uma camada de abstração que protege o núcleo de uma aplicação e a isola de integrações externas para melhor modularidade. Também conhecido como arquitetura de portas e adaptadores. Por outro lado, esse padrão pode levar a um aumento do tempo de desenvolvimento e da curva de aprendizado.
Use as ferramentas e estruturas certas: A essa altura, você provavelmente já projetou seus microsserviços para implantá-los de forma independente, agora você deve perceber o valor ideal desses microsserviços. E para fazer isso, você precisa automatizar o gerenciamento de compilação e implantação usando um bom conjunto de ferramentas de DevOps.
Frontend:
- Implementar layouts a partir do Figma com alta fidelidade.
- Garantir responsividade, acessibilidade, e boa performance.
- Dominar pelo menos um framework moderno (Angular ou React preferencialmente).
Backend:
- Escrever APIs eficientes, organizadas e seguras.
- Lidar com validações, erros e edge cases.
- Pensar em arquitetura de forma escalável e sustentável.
Geral:
- Escrever código limpo, modular e com boas práticas.
- Ter raciocínio lógico bem estruturado.
- Conseguir entender problemas e propor boas soluções.
Tecnologias que mais utilizamos:
Alto uso: JS/TS Stack
- TypeScript,
- NodeJS,
- Angular,
- MongoDB,
- SQL,
- Github Actions (CI/CD),
- Zod,
- Hono,
- Cloudflare Developer Platform
Médio uso: Microservices + Microfrontends
- React,
- Golang,
- Docker,
- Rust,
- Deno,
- Tauri,
- Biome,
- Storybook,
- Nx

Usar as ferramentas, estruturas e bibliotecas certas ajudará muito na implementação de uma arquitetura de microsserviços. Se você planeja fazer isso em Java, considere o Spring Boot Project. Escolher as ferramentas e estruturas certas leva muito tempo e esforço, então aqui está uma lista de ferramentas e tecnologias comprovadas para o trabalho:
 |
9 melhores práticas que você deve conhecer antes de construir microserviços:
Design para Falha Um sistema distribuído com microserviços vai falhar. Você deve projetar o sistema para tolerar falhas em múltiplos níveis, como infraestrutura, banco de dados e serviços individuais. Use disjuntores, anteparas ou métodos de degradação rigorosos para lidar com falhas.
Construa Pequenos Serviços Um microserviço não deve fazer várias coisas ao mesmo tempo. Um bom microserviço é projetado para fazer uma coisa bem.
Use protocolos leves para comunicação A comunicação é o núcleo de um sistema distribuído. Microserviços devem se comunicar entre si usando protocolos leves. As opções incluem REST, gRPC ou corretores de mensagens.
Implementar a descoberta de serviços Para se comunicar entre si, os microserviços precisam se descobrir pela rede. Implemente a descoberta de serviços usando ferramentas como Consul, Eureka ou Kubernetes Services
Propriedade dos Dados Em microserviços, os dados devem ser de propriedade e gerenciados pelos serviços individuais. O objetivo deve ser reduzir o acoplamento entre os serviços para que possam evoluir de forma independente.
Use padrões de resiliência Implemente padrões específicos de resiliência para melhorar a disponibilidade dos serviços. Exemplos: políticas de retentativas, cache e limitação de taxa.
Segurança em todos os níveis Em um sistema baseado em microserviços, a superfície de ataque é bastante grande. Você deve implementar segurança em todos os níveis do caminho de comunicação do serviço.
Registros centralizadossão importantes para identificar problemas em um sistema. Com múltiplos serviços, eles se tornam críticos.
Use técnicas de conteinerizaçãoPara implantar microserviços de forma isolada, utilize técnicas de conteinerização.
Ferramentas como Docker e Kubernetes podem ajudar nisso, pois são feitas para simplificar a escalabilidade e a implantação de um microsserviço.

A palavra é sua: que outras melhores práticas recomendaria?
- Jenkins e Bamboo para automação de implantação
- Docker para conteinerização
- Postman para teste de API
- Kubernetes para orquestração e implantação de contêineres
- Logstash para monitoramento
- DevSecOps para gerenciar todo o processo do ciclo de vida de desenvolvimento de software
- GitHub para gerenciamento de código-fonte e controle de versão
- Serviço de fila simples da Amazon para mensagens
- SonarQube para verificar a qualidade e segurança do código
- Ansible para gerenciar sua configuração
- Jira para rastreamento de problemas e gerenciamento de projetos
- Manter a comunicação assíncrona entre microsserviços

Dois tipos de comunicação ocorrem entre microsserviços: Síncrono e Assíncrono. Vamos entender isso com um exemplo: Para uma plataforma de comércio eletrônico, a comunicação síncrona significa que o usuário deverá "permanecer na linha" e avançar por uma série de etapas (selecionar itens, adicionar endereço de entrega, detalhes de pagamento, verificação do pedido), resultando na notificação do cliente "Obrigado pelo seu pedido! Estamos entregando na próxima semana".
Existem várias comunicações assíncronas que também ocorrem quando a notificação do cliente é processada e que fazem parte do estágio de "atendimento" do pedido, como: notificação de armazém, atualização de estoque, etc.
No caso de comunicação síncrona, um serviço torna-se dependente de outro serviço. Às vezes, torna-se um processo demorado concluir toda a tarefa usando a comunicação síncrona entre vários microsserviços.
Por outro lado, as comunicações assíncronas não dependem umas das outras. Assim, cada serviço pode levar seu tempo para concluir sua tarefa. Portanto, deve-se tentar maximizar a comunicação assíncrona entre microsserviços sempre que possível. Ele reduz a dependência e aumenta a eficiência geral de um aplicativo.
Você pode ver um exemplo disso abaixo:
Adote o modelo DevSecOps e proteja microserviços: A segurança é muito importante nessa arquitetura. À medida que a arquitetura de microserviços evoluiu no desenvolvimento de aplicações nativas em nuvem, as práticas DevSecOps são cada vez mais utilizadas para garantir integração contínua e entrega contínua com medidas de segurança reforçadas. Uma build de aplicação usando microserviços pode ser dividida nos seguintes tipos de código:
- Código de aplicação (lógica central)
- Código de serviço de aplicação (conexões de rede, estabelecimento de sessões, etc.)
- Infraestrutura (recursos de armazenamento de dados, rede, plataformas, etc.)
- Monitoramento (observabilidade contínua da aplicação)
DevSecOps consiste em três conceitos: desenvolvimento, segurança e operações, e provou ser um paradigma facilitador para tipos de código com primitivas como integração contínua, entrega contínua e pipelines de implantação contínua. Esses pipelines são fluxos de trabalho para usar o código-fonte dos desenvolvedores para desenvolver, testar, implantar e muitas outras operações que são suportadas por ferramentas automatizadas com mecanismos de feedback. Além disso, faz com que as equipes de desenvolvimento entreguem código melhor e mais seguro mais rapidamente. As práticas DevSecOps em arquitetura de microserviços oferecem inúmeros benefícios, tais como:
- Alta garantia de segurança
- Redução da vulnerabilidade do código
- Melhoria da qualidade do produto
- Aumento da produtividade
- Aumento da velocidade das operações
- Entregar softwares melhores e de maior qualidade mais rapidamente
O diagrama se encaixa principalmente em segurança de APIs, mas também toca diretamente em segurança de arquiteturas de microsserviços. Na prática, ele está exatamente na interseção dessas duas áreas:

Essa imagem representa um modelo de segurança e controle de acesso usando API keys em uma arquitetura de serviços, mostrando principalmente dois conceitos importantes de segurança: blast radius e isolamento de chaves.
A ideia central do diagrama é demonstrar como o uso de chaves diferentes para cada serviço reduz o impacto de uma possível falha de segurança. Em sistemas distribuídos modernos — especialmente arquiteturas de microserviços — aplicações se comunicam com vários serviços internos usando credenciais, como API keys, tokens ou certificados. Essas credenciais determinam o que cada serviço pode fazer dentro do sistema.
No lado esquerdo da imagem aparece a Application, que é o sistema cliente enviando requisições para diferentes serviços. Cada requisição inclui um header de autenticação com uma API key. Essas chaves representam diferentes níveis de privilégio: uma chave somente de leitura (read-only), uma chave de escrita (write key) e uma chave administrativa (admin key). Isso reflete um princípio de segurança chamado princípio do menor privilégio, no qual cada componente recebe apenas as permissões estritamente necessárias para executar sua função.
A parte central da imagem mostra três serviços diferentes — Service 1, Service 2 e Service 3 — que recebem requisições da aplicação. Cada serviço utiliza uma chave específica para acessar um Data Source (uma base de dados ou sistema de armazenamento). O ponto importante é que cada serviço possui um nível diferente de permissão sobre os dados: um pode apenas ler dados, outro pode modificá-los e outro pode realizar operações administrativas, como deploy ou atualização de estruturas.
A área destacada chamada Blast Radius representa o conceito de “raio de impacto” de um incidente de segurança. Em segurança de sistemas, blast radius significa até onde um comprometimento pode se espalhar dentro da arquitetura. Se um invasor conseguir roubar ou comprometer uma chave usada por um serviço, o dano causado dependerá das permissões dessa chave. Se o serviço tiver apenas acesso de leitura, o invasor poderá apenas consultar dados. Se tiver acesso de escrita ou administração, o impacto será muito maior.
Na parte direita da imagem aparece um cenário problemático chamado Same Key. Nesse caso, vários serviços compartilham a mesma chave de acesso para o banco de dados. Isso cria um risco enorme: se um único serviço for comprometido, o invasor automaticamente ganha acesso completo a todos os recursos protegidos por essa chave. Em outras palavras, o blast radius aumenta drasticamente, porque uma única credencial comprometida abre acesso a todo o sistema.
Por isso a imagem ilustra uma boa prática de segurança em arquiteturas modernas: cada serviço deve ter sua própria credencial com permissões específicas, em vez de compartilhar uma chave global. Esse modelo reduz o impacto de falhas, limita movimentos laterais dentro da infraestrutura e facilita auditoria e revogação de acesso.
Em resumo, o diagrama explica um conceito fundamental de segurança em sistemas distribuídos: dividir credenciais por serviço e por privilégio reduz o risco de comprometimento generalizado. Caso uma chave seja exposta ou roubada, o dano fica limitado apenas ao serviço específico que utilizava aquela credencial, em vez de afetar toda a plataforma.

Use um armazenamento de dados separado para cada microserviço: Uma prática importante é garantir que haja um banco de dados separado para armazenar dados sempre que possível, em vez de ter o mesmo banco de dados para múltiplos microserviços, como em uma arquitetura monolítica. No entanto, uma análise mais aprofundada pode indicar que um microserviço funciona apenas com um subconjunto de tabelas de banco de dados, enquanto, por outro lado, outro microserviço só funciona com um subconjunto totalmente novo de tabelas. E se ambos os subconjuntos de dados forem ortogonais, isso seria um caso para separar o banco de dados em serviços separados. Portanto, certifique-se de ter um armazenamento de dados separado para seus microserviços, a fim de reduzir a latência e melhorar a segurança. Isso já foi mencionado muitas vezes, mas é importante enfatizar que os microserviços devem depender o mínimo possível uns dos outros.
Um dos principais atributos da arquitetura de microserviços é que os dados de cada serviço são privados, como acontece, por exemplo, com o padrão Banco de Dados por Serviço.
Também podemos usar um servidor de banco de dados compartilhado que pode ser usado por múltiplos serviços com separação lógica de seus dados.
Implante cada microserviço separadamente Se você está implantando cada microserviço separadamente, certamente vai economizar muito tempo coordenando com várias equipes enquanto mantém ou atualiza os esforços. Além disso, se um ou mais microserviços tiverem os mesmos recursos, recomendamos que você use uma infraestrutura dedicada para isolar cada microserviço de falhas e evitar uma queda completa.
Alguns dos padrões mais comuns e populares para implantação de microserviços são:
- Múltiplas instâncias de serviço por host
- Instância de serviço por contêiner
- Instância de serviço único por host
- Instância de serviço por VM
- Orquestração de microserviços
A orquestração dos seus microserviços é um dos fatores mais influentes para alcançar sucesso tanto no processo quanto nas ferramentas. Você pode usar o Docker para rodar containers em uma VM, mas ele não oferece o mesmo nível de resiliência que uma plataforma de orquestração de containers oferece. Essa decisão pode muito bem afetar negativamente seu tempo de atividade ao tentar adotar uma arquitetura de microserviços.

Aqui estão algumas das plataformas de orquestração que já foram comprovadas: Essas plataformas podem ser úteis para gerenciar o provisionamento e implantação de contêineres, balanceamento de carga, escalabilidade, preocupações com comunicação em rede, etc.
- K8s (Kubernetes)
- AKS (Azure Kubernetes Services)
- ECS (Serviços de Contêineres Elásticos da Amazon)
- Azure Container Apps
Use um sistema de monitoramento eficaz: A arquitetura de microserviços ajuda você a realizar uma enorme escalabilidade de milhares de serviços modulares e oferece potencial para maior velocidade e métodos organizados de monitoramento. É importante, no entanto, revisar todos os seus microserviços e verificar regularmente se eles estão funcionando como desejado e utilizando eficientemente os recursos disponíveis. Dependendo dessas observações, você pode tomar as atitudes apropriadas caso as expectativas não estejam sendo atendidas.
Vamos analisar uma situação de exemplo e imaginar que você aplicou um padrão de arquitetura de microserviços que não tem capacidade para lidar com requisições, mas que ainda estão rodando. Por exemplo, se ele ficar sem conexões de banco de dados, o sistema de monitoramento deve ser capaz de gerar um alerta sempre que uma instância falhar e as requisições devem ser roteadas para instâncias de serviço em funcionamento.
Monitorar microserviços e manter essas estatísticas explicadas com precisão ajudará você a melhorar a tomada de decisões e manter seus microserviços disponíveis quando necessário.
Vamos dar uma olhada em alguns exemplos de ferramentas de monitoramento de microserviços.
-
AWS CloudWatch: um serviço de monitoramento, observabilidade e gerenciamento que coleta e visualiza logs em tempo real e fornece insights acionáveis para aplicações e recursos de infraestrutura da AWS, híbridos e locais.
-
Jaeger: software projetado para monitorar e solucionar problemas complexos em um ambiente de microserviços.
-
Datagod: uma plataforma de observabilidade, segurança e análise para aplicações em escala de nuvem que oferece uma solução abrangente para bancos de dados, serviços e ferramentas usando uma plataforma de análise de dados baseada em SaaS.
-
Graphite: como o nome sugere, é um software de código aberto que monitora e grava graficamente dados numéricos de séries temporais e fornece insights aprofundados sobre o sistema subjacente.
-
Prometheus: uma ferramenta de software livre e de código aberto que oferece soluções de monitoramento e modificação.

Outro ponto bastante importante, em um contexto de microsserviços, é sobre um domínio (domain) que refere-se a uma parte específica ou a um conjunto de funcionalidades de um sistema maior que é dividido em microsserviços, os domínios podem ser considerados como o núcleo de um microsserviço em uma arquitetura baseada nessa divisão. Em termos de design de microsserviços, a ideia é organizar serviços em torno de áreas específicas de funcionalidade ou de um contexto de negócios.
Essas áreas específicas são comumente referidas como domínios. Cada microsserviço é responsável por lidar com um domínio específico do negócio ou uma parte bem definida da aplicação. Os microsserviços são projetados para serem autônomos e independentes, e a ideia é que cada um deles se concentre em um domínio delimitado. Por exemplo, em um sistema de e-commerce, pode haver microsserviços separados para lidar com a gestão de produtos, carrinho de compras, processamento de pedidos, autenticação de usuários, etc.
Cada um desses microsserviços abordaria um domínio específico do sistema. Ao dividir um sistema em microsserviços baseados em domínios, há vantagens como:
-
Escalabilidade e Desempenho: Cada microsserviço pode ser escalado independentemente, focando nos domínios mais exigidos.
-
Manutenção e Evolução: Mudanças em um domínio específico podem ser feitas sem afetar outros microsserviços, facilitando a manutenção e evolução do sistema.
-
Desenvolvimento Ágil: Equipes podem se concentrar em microsserviços específicos, acelerando o desenvolvimento e permitindo que cada equipe tenha autonomia sobre o seu domínio.
A lógica de domínio é uma parte fundamental do desenvolvimento de software, onde reside a essência das regras de negócio e o comportamento específico de um determinado domínio ou área de conhecimento. Ela encapsula as regras, restrições e operações que governam o funcionamento e as relações dentro desse domínio. Lembrando que em um sistema de software, o domínio refere-se à área de negócio ou problema que o software está sendo desenvolvido para resolver. Por exemplo, em um sistema bancário, o domínio pode incluir conceitos como contas, transações, clientes, etc.
A lógica de domínio trata dessas entidades e das operações que podem ser realizadas sobre elas. Ela não está ligada diretamente à implementação técnica, como a interface do usuário ou o armazenamento de dados, mas sim à representação das regras e processos que definem o comportamento do sistema.
Por exemplo, no contexto de um sistema de reservas de voos, a lógica de domínio pode incluir regras sobre disponibilidade de assentos, restrições de datas, políticas de cancelamento e assim por diante.
A separação da lógica de domínio é um princípio fundamental no design de software, como na arquitetura em camadas ou no uso de padrões como o Modelo de Domínio, onde a lógica de domínio é isolada e mantida separada das outras partes do sistema. Isso facilita a manutenção, a compreensão e a evolução do software, uma vez que as mudanças no domínio podem ser feitas sem afetar desnecessariamente outras partes do sistema.
É possível implementar microsserviços em aplicativos desktop, web e móveis. A arquitetura de microsserviços é uma abordagem na qual um aplicativo é construído como um conjunto de serviços pequenos e independentes, cada um focado em realizar uma função específica. Para aplicativos desktop e móveis, os microsserviços podem ser implementados de maneira semelhante aos aplicativos web. Os serviços podem ser desenvolvidos separadamente e podem se comunicar por meio de APIs (Interfaces de Programação de Aplicativos), permitindo que diferentes partes do aplicativo interajam entre si de forma independente.
Você pode utilizar programação com sockets também em microsserviços, embora não seja a abordagem mais comum. A programação com sockets permite uma comunicação direta e bidirecional entre os serviços, o que pode ser vantajoso em algumas situações específicas. No entanto, é importante considerar os prós e contras dessa abordagem em comparação com os métodos mais comuns de comunicação entre microsserviços, como HTTP/REST, gRPC e mensageria. Você pode desenvolver um sistema de compartilhamento de arquivos P2P usando sockets em uma arquitetura de microsserviços que é uma abordagem viável e pode trazer várias vantagens em termos de escalabilidade, flexibilidade e manutenção, e é crucial garantir a robustez e a segurança do sistema. Implementar medidas de autenticação, autorização e criptografia de dados é essencial para proteger os dados dos usuários e manter a integridade do sistema. Além disso, monitorar e gerenciar a comunicação entre os peers é fundamental para assegurar a eficiência e a escalabilidade da rede P2P.
Por exemplo, em um aplicativo de e-commerce (sistema de vendas), pode haver um microsserviço para gerenciar o catálogo de produtos, outro para processar pagamentos, outro para gerenciar usuários e assim por diante. Cada um desses serviços pode ser desenvolvido separadamente e ser consumido pelo aplicativo desktop ou móvel por meio de chamadas de API. No entanto, é importante considerar alguns desafios ao implementar microsserviços em aplicativos desktop e móveis, como a latência da rede em dispositivos móveis, o consumo de recursos, a sincronização de dados offline e a segurança na comunicação entre os serviços. Com uma arquitetura bem planejada e estruturada, é viável implementar microsserviços em aplicativos desktop e móveis, aproveitando os benefícios de escalabilidade, manutenção simplificada e flexibilidade no desenvolvimento e atualização de diferentes partes do aplicativo.
A definição clara de limites de domínio é essencial para o sucesso dos microsserviços. Isso envolve identificar fronteiras bem definidas entre os diferentes domínios, para que cada microsserviço possa ser desenvolvido, mantido e escalado de forma independente. A comunicação entre os microsserviços geralmente é realizada através de APIs, independente do tipo arquitetural delas, permitindo que eles interajam uns com os outros para cumprir processos mais complexos ou fluxos de trabalho do sistema maior.
Nem sempre um domínio é diretamente equivalente a um microsserviço, embora essa seja uma maneira comum de organizar a arquitetura de microsserviços. Em muitos casos, um microsserviço pode abranger mais de um domínio, ou pode haver múltiplos microsserviços lidando com um único domínio. A ideia principal é que cada microsserviço seja especializado em uma área específica do negócio, mas a definição exata dos limites de um microsserviço pode variar dependendo do contexto e da complexidade do sistema.
Por exemplo, em um sistema de comércio eletrônico, pode haver um microsserviço responsável pela gestão de pedidos, que abrange vários domínios, como processamento de pagamentos, verificação de disponibilidade de produtos, gerenciamento de estoque, etc. Este microsserviço pode abranger múltiplos domínios, mas ainda está focado em uma área específica do negócio: o fluxo de pedidos.
Por outro lado, pode haver um domínio como o de autenticação e gerenciamento de usuários, que é abordado por vários microsserviços. Um microsserviço pode ser responsável pela autenticação, outro pelo gerenciamento de perfis de usuários e outro pelo controle de acesso.
A chave é encontrar um equilíbrio entre a granularidade dos microsserviços e a clareza das responsabilidades de cada um. A divisão deve permitir que os microsserviços sejam suficientemente independentes para serem desenvolvidos, implantados e mantidos de maneira ágil, mas também devem colaborar de forma eficiente para atender às necessidades do sistema como um todo.
A arquitetura de microsserviços, também conhecida como "microsserviços", é a abordagem de criação de aplicativos como uma série de serviços com implementação independente e desenvolvimento descentralizado e autônomo. Esses serviços são pouco integrados, implementáveis com independência e fáceis de manter. Enquanto o aplicativo monolítico, estrutura centralizada, é criado como unidade indivisível, os microsserviços dividem essa unidade em uma coleção de unidades independentes que contribuem para o todo. Os microsserviços são parte integral do DevOps, pois são a base para práticas de entrega contínua que permitem que equipes se adaptem com rapidez aos requisitos do usuário.
Uma arquitetura de microsserviços é um tipo de sistema distribuído, pois decompõe um aplicativo em componentes ou “serviços” diferentes. Por exemplo, uma arquitetura de microsserviços pode ter serviços que correspondem a recursos de negócios (pagamentos, usuários, produtos etc.) em que cada componente correspondente lida com a lógica empresarial para essa responsabilidade. O sistema vai ter várias cópias redundantes dos serviços para que não haja um ponto central de falha para um serviço.
Com a arquitetura de microsserviços, desenvolvedores podem se organizar em equipes menores especializadas em serviços diferentes, com pilhas distintas e implementações dissociadas. Por exemplo, o Jira é formado por diversos microsserviços, e cada um representa uma funcionalidade específica, como pesquisa de itens, visualização de informações sobre o item, comentários, transições de item e muito mais.
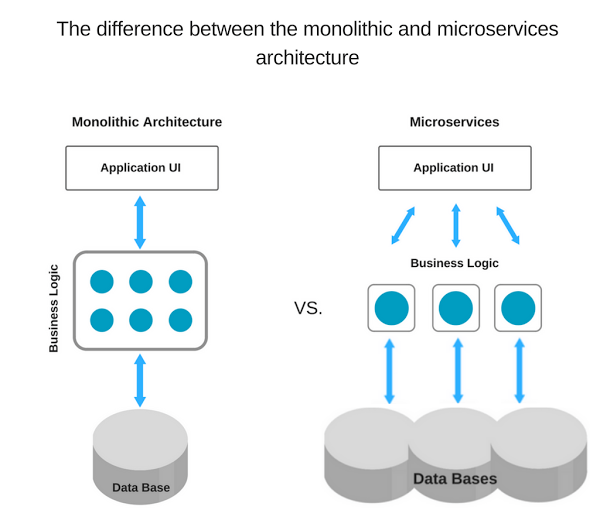
Então, baseado em um contexto histórico, uma forma de desenvolver uma aplicação é colocar todas as funcionalidades em um único "lugar". Ou seja, a aplicação roda em uma única instância (ou servidor) que possui todas as funcionalidades. Isso talvez seja a forma mais simples de criar uma aplicação (também a mais natural), mas quando a base de código cresce, alguns problemas podem aparecer. Por exemplo, qualquer atualização ou bug fix necessita parar todo o sistema, buildar o sistema todo e subir novamente. Isso pode ficar demorado e lento. Em geral, quanto maior a base de código, mais difícil será para manter ela mesmo com uma boa cobertura de testes e as desvantagens não param por ai. Outro problema é se alguma funcionalidade possuir um gargalo no desempenho o sistema todo será afetado. Não é raro de ver sistemas onde relatórios só devem ser gerados à noite para não afetar o desempenho de outras funcionalidades. Outro problema comum é com os ciclos de testes e builds demorados (falta de agilidade no desenvolvimento), problemas no monitoramento da aplicação ou falta de escalabilidade. Enfim, o sistema se torna um legado pesado, onde nenhum desenvolvedor gostaria de colocar a mão no fogo.
Então, a ideia é fugir desse tipo de arquitetura monolítica (com os padrões arquiteturais MVC, MVVP, PVC, MVP) monstruosa e dividir ela em pequenos pedaços. Cada pedaço possui uma funcionalidade bem definida e roda como se fosse um "mini sistema" isolado. Ou seja, em vez de termos uma única aplicação back-end enorme, teremos várias instâncias menores que dividem e coordenam o trabalho. Essas instâncias são chamadas de Microserviços (Microservices).
Agora fica mais fácil monitorar cada serviço específico, atualizá-lo ou escalá-lo pois a base de código é muito menor, e assim o deploy e o teste serão mais rápidos. Podemos agora achar soluções específicas para esse serviço sem precisar alterar os demais. Outra vantagem é que um desenvolvedor novo não precisa conhecer o sistema todo para alterar uma funcionalidade, basta ele focar na funcionalidade desse microsserviço.
Importante também é que um microsserviço seja acessível remotamente, normalmente usando o protocolo HTTP trocando mensagens JSON ou XML, mas nada impede que outro protocolo seja usado. Um microsserviço pode usar outros serviços para coordenar o trabalho.
Repare que isso é uma outra abordagem arquitetural bem diferente do monolítico e por isso também é chamado de arquitetura de microsserviços.
Por fim, uma arquitetura de Microserviços tem um grau de complexidade muito alta se comparada com uma arquitetura monolítica. Aliás, há aqueles profissionais que indicam partir para uma arquitetura monolítica primeiro e mudar para uma baseada em microsserviços depois, quando estritamente necessário.
Repare que a UI, ou seja nossa View ou aplicação front-end, fica dividida para cada microservice (nossas APIs) contendo as regras de negócio e acesso a camada de dados, e nossos microserviços ficam divididos ou se relacionando com os outros a fim de realizar uma tarefa necessária no nosso back-end e atuando em banco de dados próprios para os microsserviços específicos.
A arquitetura de microserviços ganhou popularidade por sua capacidade de melhorar a flexibilidade, testabilidade e escalabilidade dos sistemas de software.
Ao dividir uma aplicação monolítica em serviços menores e implantáveis de forma independente, os microserviços permitem que as equipes desenvolvam, implantem e escalem cada serviço de forma independente.
No entanto, a implementação da arquitetura de microserviços traz seus próprios desafios, tais como:
-
Consistência de Dados e Consistência Eventual: Em uma arquitetura de microserviços, os dados são frequentemente distribuídos por múltiplos nós, que podem estar localizados em diferentes data centers ou até mesmo em diferentes regiões geográficas. Em qualquer momento, podem existir discrepâncias no estado dos dados entre vários nós. Esse fenômeno é conhecido como consistência eventual.
-
Segurança: A arquitetura de microserviços introduz uma superfície de ataque maior para atores maliciosos em comparação com sistemas monolíticos. É fundamental estabelecer mecanismos de segurança adequados ao construir microsserviços. Padrões de design como o padrão API Gateway podem ajudar.
-
Escalabilidade e Desempenho do Banco de Dados: Os microserviços são conhecidos por sua escalabilidade. No entanto, embora seja relativamente fácil escalar a camada de aplicação adicionando mais instâncias, bancos de dados podem se tornar gargalos de desempenho se não forem projetados para escalabilidade. Padrões como Banco de Dados por Serviço e CQRS ajudam a resolver esse desafio.
Os padrões de design fornecem soluções comprovadas para problemas comuns encontrados em uma arquitetura de microserviços. Ao aplicar um padrão de design apropriado, esses problemas podem ser resolvidos de forma eficaz.
Vamos explorar os padrões de design de microserviços mais populares, junto com seus benefícios e desafios de adoção. Os microservices podem ser trabalhados com patterns (padrões) em seu desenvolvimento, tais como:
 |
-
API Gateway pattern: Esse padrão envolve ter um único ponto de entrada para todas as solicitações do cliente, que encaminha essas solicitações para o microsserviço apropriado. Isso simplifica a comunicação com os clientes e permite que o gateway lide com funções como autenticação, autorização e transformação de dados. É o ponto de entrada para acessar qualquer microserviço e podemos implementar aqui questões transversais como Segurança, Limite de Taxa e Balanceamento de Carga. Podemos usar o Spring Cloud Zuul ou o Spring Cloud Gateway para implementar isso.
-
Circuit Breaker pattern: Este padrão é utilizado para lidar com falhas em uma arquitetura de microsserviços. Quando um microsserviço falha ou deixa de responder, o disjuntor dispara e redireciona as solicitações para um serviço de fallback. Esse padrão é muito útil ao lidar com erros transitórios. Por exemplo, quando o serviço a chama o serviço b e o serviço b está indisponível (timeout), ele pode retornar um resultado de cache como resposta padrão ou um recurso de retenção para fazer uma solicitação a outro serviço auxiliar para obter o resultado e permitir que o serviço b recupere sem tentar fazer mais requisições para ele. Podemos usar Hystrix ou Resilient4J para implementar isso.
-
Retry pattern: Automaticamente tenta novamente as operações (requests) que falharam para prover as chances de sucesso.
-
Service Discovery: Permitir que os serviços se encontrem por meio de um nome em vez de um IP. Por que não propriedade intelectual? Porque o IP frequentemente muda em tempo de execução devido à frequência com que os containers são girados e destruídos. Podemos usar o serviço Spring Cloud Eureka ou Kubernetes para implementar isso.
-
Service Registry pattern: Este padrão é usado para rastrear todos os serviços em uma arquitetura de microsserviços. O registro atua como um diretório central para descoberta de serviço.
-
Mesh Service pattern: esse padrão envolve a adição de uma camada de infraestrutura entre microsserviços para lidar com preocupações transversais, como descoberta de serviço, balanceamento de carga e segurança.
-
Event-Driven Architecture pattern: esse padrão envolve o uso de eventos para comunicação entre microsserviços. Cada microsserviço pode publicar eventos e assinar eventos publicados por outros microsserviços. Esse padrão permite um acoplamento frouxo entre serviços, o que significa que os serviços não precisam se conhecer para se comunicar. O protocolo de comunicação geralmente ocorre por meio de eventos usando Mensagens Queue, como AMQP (RabbitMQ) ou Apache Kafka.
-
Saga pattern: Este padrão é usado para gerenciar transações que abrangem vários microsserviços. Envolve dividir a transação em etapas individuais menores e usar ações de compensação para desfazer as etapas concluídas se ocorrer um erro. Como sabemos, lidar com sistemas distribuídos é difícil, especialmente quando se trata de transações distribuídas; O commit de 2 fases era a melhor opção, mas devido à sua natureza de bloqueio pessimista, dificulta escalar, por isso os padrões Saga entram em cena. Existem maneiras de implementar o padrão Saga, que são Orquestração e Coreografia.
-
Bulkhead pattern: Este padrão é utilizado para isolar falhas em uma arquitetura de microsserviços. Cada microsserviço é colocado em um contêiner separado, portanto, se um microsserviço falhar, ele não afetará outros microsserviços. Esse padrão ajuda a lidar com a tolerância a falhas relacionada ao pool de threads, dividindo o pool de threads com base no número de serviços que precisavam ser chamados. Por exemplo, definimos um pool de 50 threads no serviço A e o serviço A fará requisições para os serviços B e C. Assim, o serviço A deve dividir o pool de 50 threads em 2 (25 para o serviço B, outros 25 para o serviço C), assim, se o serviço C não estiver disponível ou demorar mais para processar a solicitação, isso não afete a chamada do serviço B porque ele tem seu próprio pool de threads para realizar o trabalho. Podemos usar o Resilient4J para implementar isso.
-
Sidecar pattern: esse padrão envolve a implantação de um contêiner separado ao lado de cada microsserviço para lidar com preocupações transversais, como registro, monitoramento e segurança. Provavelmente um dos padrões mais legais de conhecer. Por quê? porque é uma forma de conectar serviços de negócios transversais como um sidecar ao serviço empresarial real. Normalmente, isso é feito implantando um serviço de sidecar no mesmo pod do serviço empresarial propriamente dito. Caso de uso: comunicação segura, entre serviço e serviço, implementação de logging ou métrica. Podemos usar o proxy do Envoy como sidecar.
-
CQRS pattern: Esse padrão envolve a separação dos modelos de leitura e gravação em uma arquitetura de microsserviços. O modelo de leitura é otimizado para consultar dados, enquanto o modelo de gravação é otimizado para atualizar dados. CQRS: poderíamos separar Command(write) e Query(read), o que significa que poderíamos projetar uma tabela de banco de dados otimizando para escrita e leitura de forma diferente para escalabilidade.
-
Strangler pattern: esse padrão envolve a substituição gradual de um aplicativo monolítico por microsserviços, adicionando gradualmente novos microsserviços e removendo a funcionalidade do monólito. Esta é uma forma de decompor uma aplicação monólita em microsserviços, extraindo gradualmente cada recurso do aplicativo monolítico em microsserviços individuais e permitindo que a aplicação monolítica chame esses novos microsserviços. Ao criar novos recursos, comece criando um novo microserviço em vez de criar esse novo recurso dentro do aplicativo monolito. A extração também pode incluir a criação de um novo banco de dados para esses novos serviços.
-
Shared Database pattern: esse padrão é praticamente uma base de dados compartilhada, ela é muito comum no processo pós migração de arquiteturas monolíticas para microsserviços. Onde os microsserviços vão sendo criados e vão ficando independentes, mas a base de dados ainda continua sendo compartilhada nesse serviço.
-
Database Per Service pattern: esse padrão é chamado de banco de dados por serviço, onde cada serviço geralmente possui seu próprio banco de dados, o que ajuda a evitar acoplamento entre serviços e permite que cada serviço escolha o banco de dados mais adequado às suas necessidades.
-
Test Automation pattern: Automatizar testes, incluindo testes de unidade, testes de integração e testes de aceitação, para garantir a qualidade e a confiabilidade dos microsserviços.
-
BFF pattern: Também conhecido como Backend para Frontend. Implementar microserviços para cada plataforma permite mais personalização/otimização com base em cada plataforma. Por exemplo, um aplicativo móvel pode não precisar de fotos ou vídeos de grande porte como aplicativos web, mas lembre-se de que o serviço pode ser redundante.
Ao desenvolver microsserviços, precisamos seguir as seguintes boas práticas:
-
Utilizar armazenamento de dados separado para cada microsserviço
-
Manter o código em um nível de maturidade semelhante
-
Realizar builds separados para cada microsserviço
-
Atribuir a cada microsserviço uma única responsabilidade
-
Implantar em contêineres
-
Projetar serviços sem estado
-
Adotar o design orientado a domínio (DDD)
-
Projetar micro front-ends
-
Orquestrar microsserviços
Lembre-se de que a escolha dos padrões arquiteturais depende dos requisitos específicos do projeto e das necessidades de negócios. Não existe uma única abordagem correta para a arquitetura de microsserviços, e você pode combinar vários desses padrões de acordo com suas necessidades. O importante é manter os princípios de isolamento, independência e coesão ao projetar e implementar microsserviços.
Exemplo: Microservices Communication - Implementando duas APIs e realizando comunicações síncronas e assíncronas via chamadas HTTP por meio de API REST e fila de mensagens com RabbitMQ. Por fim, iremos subir toda a aplicação no Docker com docker-compose, e iremos disponibilizar também no Heroku. Cada microsserviço vai cuidar de uma parte específica dentro do sistema.
Na prática, iremos simular um pequeno sistema de vendas:
- Teremos uma API isolada em Node.js para nos autenticar que através do nome do usuário e a senha ele vai gerar um token de acesso e nisso ele será usado em todas as aplicações e todos os endpoints,
- Outra API Node.js será responsável por registrar vendas,
- API em Spring responsável por cuidar do estoque de produtos.
- Toda vez que uma venda for realizada na aplicação de vendas em Node.js, será enviada uma mensagem da API de vendas para a API de produtos para que o estoque seja atualizado.
- Para a realização de cada venda, será necessário requisitar para a API de produtos os dados dos IDs dos produtos que constam no carrinho de compras.
- Ao receber uma mensagem de venda para atualizarmos o estoque, retornaremos uma mensagem para a aplicação de vendas informando se foi tudo ok ou não, para atualizá-la para
CANCELADAouCONCLUÍDA.
O conceito chave dessa aplicação é entender como funciona os microserviços, onde cada serviço cuida de uma parte pequena da aplicação, onde estamos descentralizando os serviços da API que seria de uma aplicação monolítica para uma aplicação em microsserviços.
O interessante é que vamos requisitar em uma comunicação síncrona por isso quando a gente tiver mensagem vai ser uma comunicação assíncrona a gente vai utilizar repetindo aquilo que vai ser isso a gente vai mandar uma mensagem a outra aplicação não vai escutar isso na hora a gente vai mandar para o repetir e vai ter. Isso vai cair numa fila.
Vai ter alguma outra aplicação que vai estar ouvindo essa fila em algum momento. Não precisa ser naquele exato instante que a gente publicou e quando ela ouvir ela vai processar essa mensagem.
Então beleza vamos supor que nossa aplicação caiu ela está fora por motivos de falta de alguma atualização gente que teve que dar um build lá em produção. Então a gente publicou uma mensagem e se ela estiver fora não vai impactar no nosso processamento da informação.
A aplicação vai estar fora a beleza mas em algum momento ela vai voltar a ficar operante e quando ela voltar a ficar operante ela vai processar essa mensagem e vai dar sequência no fluxo para realização de cada venda vai ser necessário requisitar então os produtos porque como a gente vendia só usar em dias a gente vai buscar todos os produtos informados no carrinho de compras e vai salvar eles da venda salvou a venda vai ficar com pendente.
A gente vai publicar a mensagem para pedir produtos e lá ele vai receber os produtos que a gente está tentando vender e a quantidade.
Então ele vai atualizar esse estoque caso vamos supor que a gente é formular o produto. Ele tem só lá no produto ele tem esse tipo dois itens só em estoque e a gente mandou fazer uma venda com cinco. A gente não vai conseguir atualizar essa venda para concluir ela vai ter que ser cancelada porque a gente não tem esse estoque disponível. Ou então vamos supor que a gente tem dois anos de estoque e a gente quer vender só um.
A gente vai embeleza a gente vai atualizar esse estoque para 1 e a gente vai finalizar essa venda a gente vai devolver uma mensagem para fazer uma nova publicação como concluída para a área de vendas.
Então assim a gente vai ter um método para publicar e para ele escutar mensagens um vice e um senador ou então publisher chegou subscrever tanto nas duas APIs de venda de produtos porque a gente vai implementar a lógica de ouvir as filas e de publicar nas filas tanto no Japão quanto no novo vocês conseguem ter uma noção de como faz em cada uma dessas tecnologias.
E essa aqui é uma imagem que eu criei um diagrama especificando como é que vai ser a nossa arquitetura aqui no quadrado principal e a aplicação em si. A aplicação de Java naqueles produtos é a aplicação de jazz que é de vendas. Elas vão se comunicar de maneira síncrona via chamadas HTTP através de uma API REST. E a gente vai ter uma token JWT protegendo essas chamadas.
Esse toque vai ser chamado por essa aplicação mas porque ele está num quadro de separado porque ela não vai ter interação alguma com essas aplicações. Ela só vai gerar em stock mas nada elas não vão se comunicar em momento algum nem envia via mensagem e nem envia chamada Oeste e também eu coloquei que servidor Red time que o que ele vai ser um serviço de mensageiro.
A gente vai subir um contêiner Docker. Então a gente faz com que Os dois que têm uma faixa de bidirecional por que ele vai enviar e escutar. Ele também vai enviar e vai escutar tanto a venda quanto produtos irão enviar ou escutar mensagens para esse servidor.
A gente vai ter um bom banco de dados em mongoDB para o próprio e de vendas.
A gente vai ter um banco de dados imposto de Goiás que ele próprio de produto e a gente vai ter um pouco das dados que SQL para pedir de autenticação. Esse último quadrado aqui em cima de toque com poucos a gente vai a gente tem todos os contêineres.
A gente tem um total de sete contêineres. A gente vai ter então dois contentes do posto de Goiás que é um para aplicação de autenticação e aplicação de produtos. Vamos repetir aqui porque são dois são dois deles então um do Acre também uma antena para aplicação de produtos ou uma aplicação de autenticação de vendas do Banco de Gutemberg.
E sempre o time caiu e a gente vai subir tudo isso com o Dakar pulso a ideia que a gente dê apenas um Docker Compose e ele consiga subir todo todas aqui e já ter o sistema pronto para gente utilizá-la. O utilizador vai fazendo chamadas pelo Postman coisas do tipo.
A arquitetura de microsserviços é a bala de prata? O diagrama abaixo mostra por que os jogos em tempo real e os aplicativos de negociação de baixa latência não devem usar a arquitetura de microsserviço.
Do Monólito aos Microserviços: Padrões de Transição Chave - Arquitetura monolítica é uma abordagem de desenvolvimento de software na qual toda a aplicação é construída como uma única base de código unificada. Muitas vezes, é a maneira mais simples de desenvolver e implantar software.
Para equipes ou projetos pequenos, monólitos oferecem simplicidade, desenvolvimento rápido e fácil implantação. No entanto, à medida que a aplicação cresce, essa simplicidade se torna uma faca de dois gumes, introduzindo vários desafios como:
Gargalos de Escalabilidade: Toda a aplicação é escalada como uma única unidade em um monólito. Se apenas uma parte da aplicação apresentar alta demanda (por exemplo, um módulo de relatório), toda a aplicação deve escalar, desperdiçando recursos em componentes menos exigentes.
-
Problemas de Manutenção: À medida que o código cresce, os monólitos se tornam mais difíceis de manter. As dependências entre diferentes partes da aplicação aumentam e cada alteração tem um raio de impacto maior.
-
Complexidade de Implantação: Em um sistema monolítico, uma pequena mudança em um módulo exige a reimplantação de toda a aplicação, mesmo que o restante do sistema permaneça inalterado.
-
Escolhas Limitadas de Tecnologia: Todas as partes de um monólito normalmente devem usar a mesma pilha tecnológica. Se a aplicação for escrita em Java, por exemplo, adicionar uma nova funcionalidade em Python ou usar uma biblioteca especializada torna-se impraticável.
-
Desafios de Resiliência: Uma falha em uma parte de um monólito pode derrubar toda a aplicação.
A arquitetura de microserviços aborda os desafios dos monólitos dividindo a aplicação em serviços menores e independentes. Cada serviço é responsável por uma funcionalidade específica e pode ser desenvolvido, implantado e escalonado de forma independente.
No entanto, a transição de uma arquitetura monolítica para microserviços é um processo complexo. Neste artigo, vamos analisar alguns padrões comprovados que podem ajudar a tornar a transição mais fácil.
Existem alguns recursos comuns a esses aplicativos, que os fazem escolher a arquitetura monolítica:
-
Esses aplicativos são muito sensíveis à latência. Para jogos em tempo real, a latência deve estar no nível de milissegundos; Para negociação de baixa latência, a latência deve estar no nível de microssegundos. Não podemos separar os serviços em processos diferentes porque a latência da rede é insuportável.
-
A arquitetura de microsserviços geralmente é sem estado e os estados são mantidos no banco de dados. Os jogos em tempo real e a negociação de baixa latência precisam armazenar os estados na memória para atualizações rápidas. Por exemplo, quando um personagem é ferido em um jogo, não queremos ver a atualização 3 segundos depois. Esse tipo de experiência do usuário pode matar um jogo.
-
Os jogos em tempo real e a negociação de baixa latência precisam se comunicar com o servidor em alta frequência, e as solicitações precisam ir para a mesma instância em execução. Portanto, conexões de soquete da web e roteamento fixo são necessários.
Portanto, a arquitetura de microsserviços é projetada para resolver problemas para determinados domínios. Precisamos pensar no "porquê" ao projetar aplicativos.
👉 Para você: você já se deparou com situações semelhantes no trabalho quando teve que escolher uma arquitetura diferente de microsserviço?
Quando falamos de aplicações monolíticas, dissemos que a comunicação em aplicações monolíticas é uma comunicação entre processos. Isso significa que ele está trabalhando em um único processo que invoca um para o outro usando chamadas de método. Basta criar uma classe e chamar o método dentro do módulo de destino. Todos executando o mesmo processo.
Essa comunicação é muito simples, mas ao mesmo tempo os componentes são altamente acoplados uns aos outros e difíceis de separar e escalar de forma independente.
Use um sistema de monitoramento eficaz: A arquitetura de microserviços ajuda você a realizar uma enorme escalabilidade de milhares de serviços modulares e oferece potencial para maior velocidade e métodos organizados de monitoramento. É importante, no entanto, revisar todos os seus microserviços e verificar regularmente se eles estão funcionando como desejado e utilizando eficientemente os recursos disponíveis. Dependendo dessas observações, você pode tomar as atitudes apropriadas caso as expectativas não estejam sendo atendidas.
Essa comunicação é muito simples, mas ao mesmo tempo os componentes são altamente acoplados uns aos outros e difíceis de separar e escalar de forma independente.
Construir software escalável exige que um engenheiro/arquiteto de software escolha a arquitetura certa, especialmente ao construir software/aplicações empresariais.
Arquitetura monolítica geralmente é a primeira escolha em mente para a maioria dos engenheiros porque é fácil e não precisa lidar com a complexidade do sistema distribuído, já que toda uma aplicação está no mesmo enorme código quando lida com entrega ágil de software; A aplicação monolith pode não ser a escolha certa porque, quando fazer pequenas alterações no código exige que implantemos uma aplicação inteira, o que pode ser demorado, outra coisa é que nem podemos escalar componentes/serviços individuais.
Se houver um erro em qualquer módulo/funcionalidade/serviço, isso pode afetar a disponibilidade de toda a aplicação e é por isso que a Microservice Architecture vem ao resgate.
Aqui estão os 10 padrões de microserviços que os engenheiros de software devem conhecer:
 |
 |
 |
 |
Em um mundo onde produtos digitais precisam escalar globalmente, responder instantaneamente e lidar com milhares de usuários simultâneos — a comunicação tradicional síncrona de solicitação e resposta atinge seus limites.
Sistemas distribuídos modernos exigem padrões de comunicação assíncronos que reduzam a dependência, aumentem a resiliência e permitam que as equipes distribuam recursos de forma independente.
 |
 |
Se você está construindo SaaS nativo da nuvem, microserviços de alto desempenho ou automação corporativa — esses três padrões são suas armas essenciais:
- 👉 Event Bus
- 👉 CQRS
- 👉 Saga
Component-based é uma abordagem de arquitetura de software onde os sistemas são construídos a partir de unidades modulares e reutilizáveis chamadas componentes. Cada componente é uma entidade funcional independente, encapsulando dados, lógica de negócio e comportamento, podendo ser desenvolvido, testado e mantido de forma isolada. O principal objetivo do component-based é promover reutilização, manutenção facilitada, escalabilidade e separação de preocupações. Em vez de criar sistemas como blocos monolíticos de código interdependente, o component-based permite montar aplicações como se fossem conjuntos de peças de Lego, onde cada peça realiza uma função específica e pode ser substituída ou atualizada sem impactar o todo, desde que sua interface permaneça a mesma.
Na prática, os componentes possuem interfaces bem definidas e comunicam-se entre si de forma controlada, muitas vezes por meio de eventos, injeção de dependência ou contratos formais de dados. Isso os torna altamente portáveis e adaptáveis a diferentes contextos. No front-end, esse conceito é amplamente adotado em frameworks como React, Angular e Vue, onde cada parte da interface — como botões, formulários ou tabelas — é um componente reutilizável. No back-end, esse paradigma também pode ser aplicado através de serviços encapsulados ou bibliotecas modulares que se integram em uma arquitetura maior. Em ambientes mais complexos, os componentes podem evoluir para microcomponentes ou micro frontends, refletindo a mesma filosofia de modularidade.
Além disso, o desenvolvimento baseado em componentes favorece a testabilidade e o versionamento granular, pois cada unidade pode ser testada isoladamente e evoluída de forma segura. Também incentiva a colaboração entre equipes, permitindo que diferentes grupos trabalhem em diferentes componentes sem conflitos, o que é crucial em projetos grandes e distribuídos. No entanto, adotar component-based exige disciplina em design, pois é necessário definir interfaces estáveis, evitar acoplamentos desnecessários e gerenciar bem a comunicação entre os módulos. Quando bem aplicado, o component-based resulta em sistemas mais flexíveis, organizados e fáceis de escalar, permitindo evoluções constantes sem comprometer a estrutura já existente.
Controller-Responder é um padrão arquitetural frequentemente utilizado em aplicações web que seguem a arquitetura MVC (Model-View-Controller), onde o objetivo é separar ainda mais as responsabilidades dentro do fluxo de uma requisição HTTP. Ele propõe que o Controller atue como um intermediador entre a lógica de aplicação e a entrega da resposta, enquanto o Responder seja responsável exclusivamente por construir e formatar a resposta que será enviada ao cliente, seja ela uma página HTML, um JSON, um XML ou qualquer outro tipo de representação. Esse padrão ajuda a reduzir o acoplamento entre lógica de controle e formatação de resposta, melhorando a organização, legibilidade e manutenção do código.
A principal ideia é que o Controller manipula o caso de uso: recebe a requisição, valida, chama os serviços ou casos de uso, obtém o resultado e, em vez de ele próprio montar a resposta final, delega essa tarefa ao Responder. O Responder, por sua vez, é especializado em transformar os dados de saída do domínio ou do caso de uso em uma resposta apropriada para o protocolo e formato desejado. Por exemplo, enquanto o Controller pode apenas saber que um usuário foi autenticado com sucesso, é o Responder quem decide como essa informação será apresentada, estruturando a resposta HTTP com os dados corretos, cabeçalhos, códigos de status e formatação.
Esse padrão é muito útil em sistemas que lidam com múltiplos formatos de resposta ou que exigem clareza entre as etapas da aplicação. Também contribui para testes mais precisos, pois separa a lógica de negócios (que pode ser testada em nível de controller e serviço) da apresentação (testada via responder). Em síntese, o Controller-Responder promove um controle mais claro e segmentado sobre o fluxo de uma requisição e permite que cada parte do sistema seja responsável por uma única coisa: o controller decide o que aconteceu, o responder decide como mostrar isso.
Broker (Pub/Sub) é um padrão arquitetural e também um conceito amplamente utilizado em sistemas distribuídos, onde sua principal função é atuar como um intermediário entre componentes que produzem dados (produtores) e componentes que consomem dados (consumidores).
Em vez de os produtores e consumidores se comunicarem diretamente, o broker recebe, organiza, encaminha ou até transforma as mensagens trocadas entre eles. Esse modelo é especialmente útil para desacoplar os elementos do sistema, garantindo que eles não dependam um do outro diretamente para operar, o que traz flexibilidade, escalabilidade e resiliência à arquitetura. Na prática, o broker funciona como uma central de mensagens ou eventos, um ponto de encontro onde os dados são enviados e de onde outros serviços podem consumi-los no tempo e da forma que preferirem.
Essa abordagem é muito comum em arquiteturas baseadas em eventos, como em sistemas que utilizam filas de mensagens (message queues) ou publicadores/assinantes (pub/sub). Um broker pode ser representado por tecnologias como RabbitMQ, Apache Kafka, ActiveMQ, Redis Streams ou MQTT, cada uma adequada a contextos e volumes diferentes. Por exemplo, num sistema de e-commerce, quando um pedido é realizado, o serviço de pedidos envia uma mensagem para o broker. Esse evento pode ser consumido simultaneamente por diferentes sistemas, como o de faturamento, o de estoque e o de envio, sem que o serviço de pedidos precise se preocupar em notificar cada um diretamente. O broker garante a entrega, o roteamento e, em alguns casos, até a persistência dessas mensagens, assegurando que nada se perca, mesmo em falhas temporárias dos consumidores.
Além disso, o uso de brokers contribui para a criação de sistemas assíncronos, o que melhora o desempenho e evita que um serviço precise esperar pela resposta de outro para continuar operando. Isso é essencial em ambientes de microserviços, onde os componentes são independentes e a comunicação entre eles precisa ser eficiente, confiável e tolerante a falhas. Em resumo, o broker é uma peça central que media a comunicação entre partes diferentes de um sistema, permitindo desacoplamento, tolerância a falhas e escalabilidade, além de tornar os sistemas mais organizados e preparados para lidar com alta carga de eventos e dados.
O MQTT é um protocolo de mensageria incrivelmente leve e simples, projetado especificamente para cenários onde a eficiência é crítica, como dispositivos IoT com recursos limitados, conexões de baixa largura de banda ou redes instáveis. Desenvolvido inicialmente pela IBM na década de 1990 para monitorar oleodutos via satélite, ele opera sobre TCP/IP e segue um modelo de publicação/assinatura extremamente elegante.
Sua arquitetura envolve três componentes principais: os publicadores que enviam mensagens, os assinantes que recebem mensagens de tópicos específicos, e o broker que atua como um corretor central, filtrando e distribuindo todas as mensagens. A beleza do MQTT está em sua simplicidade: os clientes não precisam saber uns dos outros, apenas se conectam ao broker e se comunicam através de tópicos hierárquicos como "casa/sala/temperatura". O protocolo oferece três níveis de qualidade de serviço que permitem equilibrar entre confiabilidade e overhead, desde o "fire and forget" até a confirmação de entrega completa, além de recursos importantes como a mensagem de última vontade que notifica outros clientes se um dispositivo se desconectar abruptamente.
Já o AMQP é um protocolo de camada de aplicação mais robusto e completo, projetado para ser um padrão aberto para sistemas de mensageria empresarial. Enquanto o MQTT é minimalista por design, o AMQP oferece um conjunto rico de recursos para cenários complexos de negócios. Sua arquitetura é mais sofisticada, baseada em um modelo de filas, exchanges e bindings que permitem roteamento flexível de mensagens através de diferentes padrões como publish/subscribe, ponto a ponto e request/reply.
As diferenças fundamentais entre eles começam com seus objetivos de design: MQTT foi criado para dispositivos embarcados e IoT, enquanto AMQP foi desenvolvido para sistemas empresariais como bancos e sistemas financeiros. Em termos de modelo de mensageria, MQTT usa publish/subscribe baseado em tópicos através de um broker central, enquanto AMQP oferece um modelo mais flexível com exchanges que roteiam mensagens para filas baseado em regras definidas por bindings. O tamanho do cabeçalho ilustra bem essa diferença filosófica - MQTT tem apenas 2 bytes de overhead por mensagem, enquanto AMQP tem overhead significativamente maior devido à sua riqueza de recursos.
Quando consideramos confiabilidade e garantias de entrega, MQTT oferece três níveis de QoS básicos, enquanto AMQP fornece garantias transacionais completas com confirmações e persistência robusta. Na descoberta de serviços, MQTT depende completamente do broker para roteamento baseado em tópicos, enquanto AMQP permite roteamento inteligente baseado em cabeçalhos de mensagem, parâmetros de rota e outras propriedades.
Essas diferenças se traduzem em casos de uso bastante distintos. O MQTT brilha em aplicações IoT como sensores remotos, dispositivos vestíveis, automação residencial e telemetria de veículos, onde a simplicidade e eficiência são prioritárias. O AMQP é ideal para sistemas empresariais como integração de sistemas legados, processamento de transações financeiras, orquestração de serviços em microsserviços e sistemas onde o roteamento complexo e as garantias de entrega são essenciais.
A escolha entre eles não é questão de qual é melhor, mas qual é mais apropriado para o contexto específico. MQTT oferece a elegância da simplicidade para dispositivos com restrições, enquanto AMQP fornece o poder e a flexibilidade para sistemas empresariais complexos que exigem roteamento sofisticado e garantias robustas de entrega.
O padrão Pub/Sub é um paradigma de comunicação assíncrona onde os emissores de mensagens, chamados de publicadores (Pub - publishers), não enviam dados diretamente para receptores específicos. Em vez disso, eles categorizam as mensagens em tópicos (ou channels), sem sequer conhecer a identidade ou a quantidade dos possíveis receptores. Os receptores, por sua vez, chamados de assinantes (Sub - subscribes), expressam interesse em um ou mais tópicos e recebem apenas as mensagens que são relevantes para eles, sem precisar saber de qual publicador vieram. Esse desacoplamento total entre publicador e assinante — tanto no tempo (não precisam estar ativos simultaneamente) quanto no espaço (não precisam se conhecer) — é a principal virtude do padrão, tornando-o ideal para sistemas escaláveis, dinâmicos e distribuídos.
A aplicação do Pub/Sub no MQTT é a sua razão de ser original. O protocolo foi concebido em torno desse modelo. No MQTT, o coração do sistema é o broker, um servidor central que gere todos os tópicos. Um publicador envia uma mensagem para o broker, especificando um tópico com estrutura hierárquica, como casa/sala/iluminacao. Os assinantes, para receberem essas mensagens, enviam ao broker uma mensagem SUBSCRIBE informando o tópico de interesse (é possível usar o caractere curinga # para assinar uma hierarquia inteira). A partir desse momento, o broker atua como um serviço de correio inteligente: toda vez que uma mensagem for publicada naquele tópico, ele a encaminhará a todos os assinantes inscritos. A implementação é simples e direta: basta que os dispositivos se conectem ao broker usando uma biblioteca cliente MQTT e comecem a publicar ou assinar nos tópicos desejados. A leveza do protocolo faz com que essa operação seja extremamente eficiente, mesmo para milhares de dispositivos conectados.
A aplicação no AMQP é igualmente poderosa, mas segue uma lógica mais rica e flexível. O AMQP implementa o Pub/Sub através de um de seus componentes de roteamento: a Exchange. Especificamente, a Fanout Exchange e a Topic Exchange são os mecanismos clássicos para esse padrão. Na Fanout Exchange, a regra é simples: toda mensagem que chega é replicada e enviada para todas as filas que estiverem vinculadas a ela, sem qualquer filtro. É o Pub/Sub mais puro e amplo. Já a Topic Exchange oferece um controle mais refinado: as mensagens são roteadas para filas específicas com base em uma chave de roteamento e em padrões de correspondência definidos no vínculo (o binding). Por exemplo, uma fila pode se vincular a uma exchange usando a chave sensor.temperatura.* e receberá todas as mensagens cuja chave de roteamento combine com esse padrão, como sensor.temperatura.cozinha e sensor.temperatura.quarto. Para aplicar o Pub/Sub no AMQP, o publicador envia a mensagem para uma Exchange do tipo Fanout ou Topic. Os assinantes, por sua vez, criam suas próprias filas (geralmente exclusivas e temporárias) e as vinculam a essa Exchange, com a chave de roteamento desejada. O broker (como o RabbitMQ) então se encarrega do roteamento inteligente.
A diferença fundamental na aplicação prática está na filosofia de uso. O MQTT, com seus tópicos hierárquicos e broker centralizado, é incrivelmente simples e intuitivo para cenários de IoT e telemetria, onde o foco é a disseminação eficiente de dados. O AMQP, com seu modelo baseado em Exchanges e Filas, oferece um controle muito mais granular sobre o fluxo de mensagens, permitindo padrões complexos de roteamento, persistência e garantias de entrega que são essenciais em sistemas empresariais. Em resumo, enquanto o MQTT oferece um "sistema de tópicos" pronto para uso, o AMQP fornece os "tijolos de construção" para que você mesmo monte seu próprio sistema de Pub/Sub com o nível de sofisticação exigido pela aplicação.
Space-based architecture é um estilo arquitetural voltado principalmente para aplicações altamente escaláveis e resilientes, especialmente aquelas que enfrentam cargas de trabalho imprevisíveis ou picos de acesso intensos. A ideia central do modelo space-based é eliminar gargalos comuns de acesso e processamento centralizado — como ocorre em bancos de dados relacionais tradicionais — distribuindo o estado da aplicação em memória através de múltiplos nós (clusters) que compartilham um "espaço de dados" (data grid), de onde vem o termo "space". Essa abordagem busca minimizar a contenção por recursos compartilhados, permitindo que os nós operem de forma mais autônoma, mantendo o estado da aplicação localmente, replicando-o conforme necessário.
No space-based, a aplicação é dividida em unidades chamadas de “processing units” (unidades de processamento), cada uma contendo a lógica de negócio, dados relevantes e, às vezes, o mecanismo de persistência local. Essas unidades são implantadas de forma redundante em diferentes servidores, e o sistema gerencia automaticamente o balanceamento de carga e a tolerância a falhas. Os dados e as tarefas de processamento são mantidos em um espaço distribuído em memória, como um cache altamente disponível, evitando assim o uso intensivo de banco de dados em tempo real. Isso é especialmente eficaz em sistemas como e-commerces durante Black Friday, sistemas bancários com transações simultâneas, ou qualquer cenário com grande volume de leitura e escrita concorrente.
Essa arquitetura é inspirada no conceito de tuple space (espaço de tuplas), popularizado pelo modelo Linda de programação paralela, onde elementos podem ser inseridos, buscados ou removidos de um espaço compartilhado, de forma assíncrona e desacoplada. Ao utilizar esse espaço como uma camada de abstração entre os componentes do sistema, o space-based promove o desacoplamento, a escalabilidade horizontal e a alta disponibilidade. A persistência eventual em bancos de dados pode ser usada para backup ou consistência de longo prazo, mas não interfere no desempenho em tempo real.
Em suma, space-based architecture é uma abordagem orientada à memória, com foco em escalabilidade e resiliência, onde os dados e processos circulam por um espaço distribuído e compartilhado entre os nós da aplicação. Ela é ideal para aplicações que não podem depender de uma única fonte de verdade centralizada e precisam operar sob alta concorrência e baixa latência.
Rule-based, ou sistema baseado em regras, é uma abordagem na qual o comportamento de um sistema é determinado por um conjunto explícito de regras lógicas e condicionais, geralmente escritas na forma de “se... então...” (if... then...). Esse tipo de sistema atua avaliando constantemente as regras definidas em sua base de conhecimento para tomar decisões, executar ações ou inferir novos dados a partir de informações fornecidas como entrada. É um paradigma fortemente utilizado em inteligência artificial simbólica, sistemas especialistas, motores de decisão e automações de negócios. Em vez de escrever um fluxo rígido de controle de programação, o desenvolvedor ou especialista define um conjunto de condições e consequências, e o motor de regras se encarrega de aplicar essas instruções de acordo com os dados e o contexto.
O grande diferencial de sistemas rule-based é a sua flexibilidade e facilidade de modificação. Como o comportamento é guiado por regras separadas da lógica de aplicação principal, é possível adaptar e expandir o sistema alterando ou adicionando novas regras, sem a necessidade de reescrever o código central. Essa característica os torna úteis em domínios onde o conhecimento muda com frequência ou onde especialistas não técnicos precisam alterar a lógica, como em sistemas jurídicos, financeiros, diagnósticos médicos ou motores de recomendação. Motores como Drools, no ecossistema Java, são exemplos típicos de implementação desse conceito, permitindo que o sistema reaja dinamicamente às entradas conforme as regras são disparadas.
No entanto, sistemas baseados em regras também apresentam desafios, principalmente à medida que a complexidade aumenta. Quando há muitas regras interdependentes, pode se tornar difícil prever os efeitos colaterais de uma nova regra ou compreender completamente o comportamento do sistema. Além disso, sistemas rule-based não lidam bem com incerteza ou ambiguidade, como modelos probabilísticos fariam. Mesmo assim, sua transparência e explicabilidade os tornam ideais para contextos em que decisões precisam ser justificáveis e auditáveis. Portanto, rule-based é uma abordagem lógica e determinística, onde o conhecimento do domínio é traduzido em regras explícitas e aplicadas sistematicamente para produzir decisões, diagnósticos ou ações.
Evolução da Arquitetura da API da Netflix: A arquitetura da API da Netflix passou por 4 estágios principais:
-
Monolith (monólito) é um estilo de arquitetura de software em que toda a aplicação é construída e executada como um único sistema unificado. Nesse modelo, todas as funcionalidades — como lógica de negócio, acesso a banco de dados, APIs e interface — ficam dentro do mesmo projeto ou processo executável. Isso significa que todos os módulos da aplicação são fortemente integrados e geralmente são implantados juntos. Esse tipo de arquitetura foi dominante durante muitos anos no desenvolvimento de software corporativo porque é mais simples de projetar inicialmente, facilita a depuração e reduz a complexidade operacional, já que existe apenas um serviço para executar, monitorar e atualizar. Porém, conforme o sistema cresce, o monólito pode se tornar difícil de manter, pois qualquer alteração exige recompilar e implantar toda a aplicação. Além disso, escalar apenas uma parte do sistema se torna complicado, já que normalmente é necessário escalar o sistema inteiro, mesmo que apenas um componente esteja sendo muito utilizado.
-
Direct access é um padrão arquitetural em que clientes — como aplicações web, aplicativos móveis ou outros serviços — acessam diretamente diferentes serviços ou bancos de dados sem passar por uma camada intermediária centralizada. Nesse modelo, cada cliente conhece os endpoints dos serviços de que precisa e se comunica diretamente com eles. A vantagem dessa abordagem é que ela elimina camadas intermediárias, reduzindo latência e simplificando a comunicação em sistemas menores. No entanto, em sistemas maiores essa abordagem pode gerar forte acoplamento entre clientes e serviços internos, pois qualquer mudança em um serviço pode exigir alterações em múltiplos clientes. Além disso, questões como autenticação, agregação de dados, transformação de respostas e controle de tráfego ficam distribuídas entre vários pontos da arquitetura, o que pode aumentar a complexidade do sistema à medida que ele cresce.
-
Gateway aggregation layer é uma arquitetura que introduz um componente intermediário chamado gateway ou API gateway entre os clientes e os serviços internos do sistema. Esse gateway atua como uma camada de entrada única para as requisições externas. Em vez de o cliente acessar vários serviços diretamente, ele envia a requisição ao gateway, que por sua vez consulta diferentes microserviços, agrega as respostas e retorna um único resultado ao cliente. Essa abordagem é muito útil em arquiteturas de microserviços, onde uma única funcionalidade da aplicação pode depender de vários serviços distintos. O gateway pode centralizar preocupações transversais como autenticação, controle de acesso, rate limiting, transformação de dados e cache. Além disso, ele simplifica o lado do cliente, pois o cliente não precisa conhecer a estrutura interna dos microserviços. Contudo, essa camada também pode se tornar um ponto crítico da arquitetura, já que concentra grande parte do tráfego e precisa ser altamente escalável e resiliente.
-
Federated gateway é uma evolução do conceito de gateway usada principalmente em arquiteturas baseadas em APIs distribuídas, especialmente quando diferentes equipes desenvolvem serviços independentes que expõem partes de um esquema de dados maior. Nesse modelo, o gateway não apenas agrega respostas de serviços distintos, mas também compõe dinamicamente um esquema unificado a partir de múltiplas APIs ou subserviços. Cada serviço é responsável por uma parte do domínio de dados, e o gateway federado combina essas partes para apresentar uma interface única para os clientes. Esse padrão é muito associado a arquiteturas baseadas em GraphQL federado, onde cada serviço define um subconjunto do esquema global e o gateway resolve consultas distribuídas automaticamente. A vantagem dessa abordagem é permitir que equipes desenvolvam e evoluam serviços de forma independente sem perder a visão de uma API unificada. Em sistemas grandes, isso melhora escalabilidade organizacional e modularidade da arquitetura, ao mesmo tempo em que mantém uma interface consistente para os consumidores da API.
Masterizando a Consistência de Dados entre Microserviços: Arquitetura de microserviços é um padrão de design de software onde uma aplicação é construída como uma coleção de pequenos serviços independentes, cada um responsável por uma função específica.
Esses serviços se comunicam entre si usando APIs (Interfaces de Programação de Aplicações) e operam de forma independente, permitindo maior flexibilidade, escalabilidade e facilidade de manutenção. Pense em um aplicativo de entrega de comida com os seguintes serviços:
- O serviço de pedidos gerencia os pedidos dos clientes.
- O serviço de pagamento cuida das transações.
- O serviço do restaurante atualiza a disponibilidade do cardápio.
- O serviço de entrega atribui e acompanha as entregas.
Cada serviço opera de forma independente, permitindo que as equipes os atualizem ou escalem separadamente.
No entanto, devido a essa separação, um grande desafio com os microserviços é manter a consistência dos dados. Em um sistema monolítico, todas as funcionalidades compartilham um único banco de dados, resultando em atualizações consistentes. Por outro lado, a arquitetura de microserviços defende que cada serviço deve gerenciar seu banco de dados. Embora essa seja uma boa prática, pode levar a alguns cenários como:
- Dados Duplicados ou Perdidos
- Atrasos na rede
- Questões de Concorrência
Compreender esses cenários é fundamental para construir aplicações robustas e escaláveis usando microsserviços. Neste artigo, vamos entender como a inconsistência de dados pode surgir em uma arquitetura de microserviços e as diversas estratégias para lidar com ela.




 |
 |
 |
- https://substack.com/redirect/8e94e755-da70-4871-a52c-c1f3bc65ab95?j=eyJ1IjoiMmRpcmZwIn0.DgQpD9vnxeDXnbOGqr5r4QICWGtxf2wFAnKNG8yY6Aw
- https://substack.com/redirect/55568165-cc89-4e78-a706-d535205faa44?j=eyJ1IjoiMmRpcmZwIn0.DgQpD9vnxeDXnbOGqr5r4QICWGtxf2wFAnKNG8yY6Aw
- https://substack.com/redirect/8ed69761-0f32-4dcf-b7f9-4f4f99574caa?j=eyJ1IjoiMmRpcmZwIn0.DgQpD9vnxeDXnbOGqr5r4QICWGtxf2wFAnKNG8yY6Aw
Um API Gateway é um componente essencial em arquiteturas modernas, especialmente em sistemas baseados em microserviços. Ele atua como um intermediário entre clientes e um conjunto de serviços backend, gerenciando todas as solicitações que entram no sistema. Sua principal função é receber, rotear, transformar e controlar as solicitações de API, além de retornar respostas apropriadas aos clientes.
Em uma arquitetura de microserviços, um gateway de API atua como um único ponto de entrada para as solicitações dos clientes. O gateway API é responsável pelo roteamento de requisições, composição e tradução de protocolos. Também oferece recursos adicionais como autenticação, autorização, cache e limitação de taxa.
Um gateway de API é um servidor que atua como um front-end de API, recebendo requisições de API, aplicando políticas de limitação e segurança, passando requisições para o serviço de back-end e, em seguida, retornando o resultado apropriado ao cliente.
Você está cansado de gerenciar vários pontos de entrada para seus microsserviços? O padrão API Gateway está aqui para salvar o dia! Atuando como um único ponto de entrada para todas as solicitações do cliente, o API Gateway simplifica o acesso aos seus microsserviços, oferecendo comunicação perfeita entre clientes e serviços.
Gateways de API são componentes essenciais em arquiteturas de software modernas, especialmente em sistemas baseados em microsserviços. Padrão de API gateway: seu balcão único para microsserviços.
Eles atuam como um único ponto de entrada para todas as requisições de API, fornecendo uma interface unificada para acessar diversos serviços e dados. Ao desacoplar aplicações clientes dos microserviços backend, os API Gateways simplificam o gerenciamento de APIs e melhoram o desempenho geral e a segurança do sistema.
Gateways de API ajudam a aprimorar a experiência do desenvolvedor enquanto constroem sistemas escaláveis e manuteníveis. As organizações podem alcançar melhor controle sobre seu cenário de APIs utilizando APIs Gateways.
À medida que a complexidade dos sistemas de software continua a crescer, os Gateways de API desempenharão um papel cada vez mais importante ao possibilitar uma comunicação e integração eficazes entre serviços e clientes.
Vamos falar sobre Padrões de Design da arquitetura de Microsserviços, que é o padrão de Agregação de Gateway (Gateway Aggregation Pattern). Como você sabe, aprendemos práticas e padrões e os adicionamos à nossa caixa de ferramentas de design. E usaremos esses padrões e práticas ao projetar a arquitetura de microsserviços.
Em sistemas distribuídos, sem um API Gateway, os clientes teriam que se comunicar diretamente com cada microserviço, o que aumentaria a complexidade, exigiria lógica adicional para lidar com autenticação, balanceamento de carga e agregação de dados, além de expor os serviços internos diretamente à internet. O API Gateway resolve esses problemas centralizando essas responsabilidades.
Você precisa aprender onde e quando aplicar o padrão de agregação de gateway na arquitetura de microsserviços com o design de um sistema de aplicativos de comércio eletrônico com os seguintes princípios KISS, YAGNI, SoC e SOLID.
O API Gateway é um servidor que lida com muitas funcionalidades em um único local para os clientes interagirem. Ele também funciona como um proxy reverso entre seus aplicativos cliente e a arquitetura de microsserviços de back-end.

O padrão de agregação de gateway é semelhante ao roteamento de gateway, mas além disso, oferece agregação de serviços. Basicamente, o padrão de agregação de gateway oferece o uso de um serviço de gateway que fornece para agregar várias solicitações internas a microsserviços internos com a exposição de uma única solicitação ao cliente.
Por que você deve se preocupar com o API Gateway? Primeiro, ajuda a agregar respostas de vários microsserviços, reduzindo o número de viagens de ida e volta entre clientes e serviços. Isso resulta em melhor desempenho e experiência do usuário. Em segundo lugar, ele permite que você implemente preocupações transversais, como autenticação, registro e limitação de taxa em um único local, promovendo consistência e reduzindo a redundância.
Imagine a conveniência de ter um hub central que cuida de todas essas responsabilidades! De acordo com um estudo da RapidAPI, 68% dos desenvolvedores que adotaram o API Gateway relataram segurança aprimorada e gerenciamento simplificado de seus microsserviços.
Algumas soluções populares do API Gateway incluem Amazon API Gateway, Kong e Azure API Management. Essas ferramentas fornecem uma variedade de recursos, como cache, limitação e monitoramento, para ajudá-lo a gerenciar seus microsserviços com eficiência.
O diagrama abaixo mostra os detalhes:
 |
 |
 |
 |
-
Passo 1 - O cliente envia uma requisição HTTP para o gateway da API.
-
Passo 2 - O gateway da API analisa e valida os atributos na requisição HTTP.
-
Passo 3 - O gateway API realiza verificações de lista de permissões/negações/listas de recusas.
-
Passo 4 - O gateway da API se comunica com um provedor de identidade para autenticação e autorização.
-
Passo 5 - As regras de limite de taxa são aplicadas ao pedido. Se o valor estiver acima do limite, o pedido é rejeitado.
-
Passos 6 e 7 - Agora que a solicitação passou pelas verificações básicas, o gateway da API encontra o serviço relevante para encaminhar por meio de correspondência de caminhos. O gateway da API encaminha a requisição para o serviço backend relevante por meio de correspondência de caminhos.
-
Passo 8 - O gateway da API transforma a solicitação no protocolo apropriado e a envia para microserviços de backend.
-
Passos 9-12: O gateway API pode lidar com erros corretamente e lida com falhas se o erro demorar mais para ser recuperado (quebra de circuito). Também pode aproveitar a pilha ELK (Elastic-Logstash-Kibana) para registro e monitoramento. Às vezes armazenamos dados em cache no gateway da API.
Passo 9: O gateway API lida com quaisquer erros que possam surgir durante o processamento de requisições para uma degradação gradual do serviço.
Passo 10: O gateway API implementa padrões de resiliência como freios de circuito para detectar falhas e evitar sobrecarga de serviços interconectados, evitando falhas em cascata.
Passo 11: O gateway API utiliza ferramentas de observabilidade como a pilha ELK (Elastic-Logstash-Kibana) para registro, monitoramento, rastreamento e depuração.
Passo 12: O gateway da API pode opcionalmente armazenar em cache respostas a solicitações comuns para melhorar a capacidade de resposta.
Além do roteamento de requisições, o gateway API também pode agregar respostas de microserviços em uma única resposta para o cliente.
O gateway API é diferente de um balanceador de carga. Embora ambos gerenciem tráfego de rede, o gateway API opera na camada de aplicação, principalmente lidando com requisições HTTP; o balanceador de carga opera principalmente na camada de transporte, lidando com protocolos TCP/UDP. O gateway da API oferece mais funções conforme ele vê a carga útil da requisição.
O gateway API difere de um balanceador de carga porque normalmente opera na camada de aplicação para lidar com requisições HTTP e entender cargas úteis de mensagens, enquanto balanceadores de carga tradicionais atuam na camada de transporte para lidar com conexões TCP/UDP sem olhar para os dados da aplicação.
No entanto, as linhas podem se confundir entre esses dois tipos de infraestrutura. Alguns balanceadores de carga avançados estão ganhando visibilidade na camada de aplicação e capacidades de roteamento semelhantes a gateways de API.
Mas, em geral, gateways de API focam em questões de nível de aplicação como segurança, roteamento, composição e resiliência com base na carga útil, enquanto balanceadores de carga tradicionais mapeiam as requisições para servidores backend principalmente com base em metadados em nível de transporte, como IP e números de porta.
Frequentemente temos gateways de API separados, adaptados para diferentes clientes e suas necessidades de experiência do usuário. O diagrama abaixo mostra uma arquitetura típica. Temos diferentes gateways de API para lidar com requisições de dispositivos móveis e aplicações web porque eles têm requisitos únicos para experiências de usuário. Além disso, separamos o WebSocket API Gateway porque ele tem requisitos diferentes de persistência de conexão e limitação de taxa em comparação com gateways HTTP.

Algumas tendências recentes de gateways de API:
Suporte a GraphQL. GraphQL é um sistema de tipos e uma linguagem de consulta para APIs. Muitos gateways de API agora oferecem integração com o GraphQL.
Integração com Service Mesh. Malhas de serviço como Istio e Linkerd são usadas para lidar com comunicações entre microsserviços. Gateways de API estão se integrando a eles para aprimorar as capacidades de gerenciamento de tráfego.
Integração com IA. Gateways de API estão se integrando com capacidades de IA para permitir roteamento de requisições mais inteligentes ou detecção de anomalias nos padrões de tráfego.
- Quais são as diferenças entre REST e RPC? REST (Transferência de Estado Representacional) e RPC (Chamada de Procedimento Remoto) são dois padrões arquitetônicos comuns usados para comunicações em sistemas distribuídos. REST é usado para comunicações cliente-servidor, e RPC é usado para comunicações servidor-servidor, como ilustrado no diagrama abaixo.

É essencialmente um intermediário entre o cliente e o servidor, gerenciando e otimizando o tráfego da API.

Funções-chave de um API Gateway:
- Roteamento de Requisições: Direciona as requisições de API recebidas para o serviço backend apropriado.
- Balanceamento de carga: Distribui requisições entre vários servidores para garantir que nenhum servidor único seja sobrecarregado.
- Segurança: Implementa medidas de segurança como autenticação, autorização e criptografia de dados.
- Limitação de Taxa e Limitação: Controla o número de solicitações que um cliente pode fazer dentro de um determinado período.
- Composição de APIs: Combina múltiplas requisições de API backend em uma única requisição frontend para otimizar o desempenho.
- Cache em cache: Armazena respostas temporariamente para reduzir a necessidade de processamento repetido.
Top 3 Casos de Uso de Gateways de API:
 |
 |
O gateway API fica entre os clientes e os serviços, fornecendo comunicações API entre eles.
-
O gateway API ajuda a construir um ecossistema. Os usuários podem usar um gateway de API para acessar um conjunto mais amplo de ferramentas. Os parceiros do ecossistema colaboram entre si para proporcionar melhores integrações aos usuários.
-
Gateway API constrói marketplace. API O marketplace API hospeda funcionalidades fundamentais para todos. Os desenvolvedores e empresas podem facilmente desenvolver ou inovar nesse ecossistema e vender APIs no marketplace.
-
Gateway de API oferece compatibilidade com múltiplas plataformas. Ao lidar com múltiplas plataformas, um gateway de API pode ajudar a trabalhar em várias arquiteturas complexas.
Propriedades do ACID em bancos de dados com exemplos
Você já ouviu falar do aplicativo de 12 fatores? O "12 Factor App" oferece um conjunto de melhores práticas para construir aplicações de software modernas. Seguir esses 12 princípios pode ajudar desenvolvedores e equipes a construir aplicações confiáveis, escaláveis e gerenciáveis.
No alternative text description for this image Aqui está uma breve visão geral de cada princípio:
Base de código: Tenha um lugar para guardar todo o seu código e gerencie usando controle de versões, como o Git.
Dependências: Liste tudo o que seu app precisa para funcionar corretamente e certifique-se de que seja fácil de instalar.
Configuração: Mantenha configurações importantes como credenciais de banco de dados separadas do seu código, para que você possa alterá-las sem precisar reescrever o código.
Serviços de Apoio: Use outros serviços (como bancos de dados ou processadores de pagamento) como componentes separados aos quais seu app se conecta.
Build, Release, Run: Faça uma distinção clara entre preparar seu app, lançá-lo e executá-lo em produção.
Processos: Projete seu aplicativo para que cada parte não dependa de um computador ou memória específica. É como fazer blocos de LEGO que se encaixam.
Vinculação de Portas: Permita que seu app seja acessível por uma porta de rede e certifique-se de que ele não armazene informações críticas em um único computador.
Concorrência: Faça seu app aguentar mais trabalho adicionando mais cópias da mesma coisa, como contratar mais funcionários para um restaurante movimentado.
Descartável: Seu app deve iniciar rapidamente e desligar de forma elegante, como desligar um interruptor de luz em vez de puxar o cabo de energia.
Paridade Dev/Prod: Certifique-se de que o que você usa para desenvolver seu app seja muito semelhante ao que você usa em produção, para evitar surpresas.
Registros: Mantenha um registro do que acontece no seu app para que você possa entender e corrigir problemas, como um diário para o seu software.
Processos administrativos: Execute tarefas especiais separadamente do seu app, como fazer manutenção em uma oficina em vez de no chão de fábrica.
A palavra é sua: onde você acha que esses princípios podem ter maior impacto na melhoria das práticas de desenvolvimento de software?
15 Projetos de Código Aberto que Mudaram o Mundo
Os 3 Principais Erros no Currículo que Custam o Emprego
O que o API gateway faz? O diagrama abaixo mostra os detalhes.
Passo 1 - O cliente envia uma requisição HTTP para o gateway da API.
Passo 2 - O gateway da API analisa e valida os atributos na requisição HTTP.
Passo 3 - O gateway API realiza verificações de lista de permissões/listas de recusas.
Passo 4 - O gateway da API se comunica com um provedor de identidade para autenticação e autorização.
Passo 5 - As regras de limite de taxa são aplicadas ao pedido. Se o valor estiver acima do limite, o pedido é rejeitado.
Passos 6 e 7 - Agora que a solicitação passou pelas verificações básicas, o gateway da API encontra o serviço relevante para encaminhar por meio de correspondência de caminhos.
Passo 8 - O gateway da API transforma a solicitação no protocolo apropriado e a envia para microserviços de backend.
Passos 9-12: O gateway API pode lidar com erros corretamente e lida com falhas se o erro demorar mais para ser recuperado (quebra de circuito). Também pode aproveitar a pilha ELK (Elastic-Logstash-Kibana) para registro e monitoramento. Às vezes armazenamos dados em cache no gateway da API.
Deixando a palavra para você:
- Qual é a diferença entre um balanceador de carga e um gateway de API?
- Precisamos usar diferentes gateways de API para PC, celular e navegador separadamente?
 |
 |
 |
 |
 |
Esse padrão deve ser usado se o aplicativo cliente tiver que invocar vários microsserviços de back-end diferentes para executar sua lógica. Vamos olhar para a imagem:
Se não pudermos colocar a caixa de agregação aqui, o cliente envia solicitações para cada serviço. Cada serviço processa a solicitação e envia a resposta de volta ao aplicativo (2,3,4,5,6).
Portanto, isso causará problemas de rede e latência. E não é bom gerenciar serviços de acesso direto do cliente e não é bom invocar a responsabilidade de serviço para o cliente.
Para resolver esses problemas, podemos usar um gateway para reduzir a conversa entre o cliente e os microsserviços internos. O gateway recebe solicitações de clientes e envia solicitações para os vários serviços de back-end e, em seguida, agrega os resultados e os envia de volta ao cliente solicitante.
Esse padrão pode reduzir o número de solicitações que o aplicativo faz aos serviços de back-end e melhorar o desempenho do aplicativo em redes de alta latência.
Veja a imagem 2 que a comunicação da interface do usuário e da MS é direta e parece difícil gerenciar as comunicações. Agora devemos nos concentrar nas comunicações de microsserviços com a aplicação do padrão API GW e a evolução dessas arquiteturas passo a passo.
Pode haver vários clientes que chamam as APIs do servidor, e o API Gateway é o componente que roteia solicitações para o microsserviço relevante e, em seguida, obtém a resposta e a envia ao cliente. Ele lida com todos os recursos transversais, como segurança, registro, cache, etc., em um único lugar, em vez de implementarmos essas funcionalidades em todos os microsserviços. Além disso, ele pode consolidar e agregar os dados na agregação de vários microsserviços usando um único endpoint para os clientes se comunicarem.
Antes da evolução da arquitetura de microsserviços, a maioria dos sistemas usava um padrão Monolith e podíamos até lidar com as preocupações transversais em um ou dois servidores. Mas com microsserviços, não podemos nos dar ao luxo de lidar com preocupações transversais em cada um dos microsserviços, o que tornará as coisas mais lentas com um volume de memória maior, degradando o desempenho do sistema.
As principais funcionalidades de um API Gateway incluem:
-
Roteamento de solicitações: Ele direciona solicitações para o serviço backend apropriado com base no caminho, método HTTP ou outros critérios.
-
Autenticação e autorização: Pode validar tokens de acesso, certificados ou outras credenciais antes de encaminhar solicitações aos serviços backend.
-
Transformação de dados: Permite manipular solicitações e respostas, como converter formatos (JSON para XML, por exemplo) ou adicionar/remover campos.
-
Agregação de respostas: Para solicitações que requerem dados de múltiplos serviços, o API Gateway pode consolidar essas respostas antes de retornar ao cliente.
-
Limitação de taxa e controle de acesso: Garante que o sistema não seja sobrecarregado, implementando políticas de limite de solicitações por usuário ou IP.
-
Monitoramento e métricas: Coleta dados de uso e desempenho para fornecer insights sobre o funcionamento das APIs.
-
Segurança e proteção: Oferece proteção contra ataques comuns, como DDoS e injeções maliciosas, ao atuar como uma camada de firewall para APIs.
Um exemplo prático é em uma aplicação de e-commerce: o API Gateway pode expor uma única API para os clientes acessarem, enquanto internamente roteia solicitações para microserviços como autenticação, catálogo de produtos, carrinho de compras e pagamentos.
Ferramentas populares para implementação de API Gateways incluem Kong, NGINX, AWS API Gateway, Apigee, Traefik e Istio (quando usado em conjunto com service meshes). Em resumo, o API Gateway é uma peça fundamental para simplificar a gestão, aumentar a segurança e otimizar a performance de APIs em arquiteturas modernas.
Vamos aprender a projetar a arquitetura de microsserviços usando padrões de design, princípios e as melhores práticas. Começaremos projetando microsserviços monolíticos a orientados a eventos passo a passo e juntos, usando os padrões e técnicas de design de arquitetura corretos. Você pode optar por mensageria, cache, balanceamento de carga, juntamente com arquiteturas de software como modulares, tudo isso pode ser customizável de acordo com a complexidade do seu sistema, verifique com atenção os requisitos e a complexidade.
Em resumo, o padrão API Gateway é um componente essencial de uma arquitetura de microsserviços bem-sucedida. Ao adotar esse padrão, você pode garantir comunicação simplificada, segurança aprimorada e gerenciamento simplificado de seus serviços. Você está pronto para desbloquear o verdadeiro potencial dos microsserviços com o padrão API Gateway? Bora pro código!
Os sistemas de software modernos raramente vivem isolados. A maioria dos aplicativos hoje é costurada a partir de dezenas, às vezes centenas, de serviços implantados de forma independente, cada um lidando com uma peça do quebra-cabeça. Isso ajuda a criar unidades menores de responsabilidade e acoplamento flexível. No entanto, a flexibilidade vem com um novo tipo de complexidade, especialmente em torno de como esses serviços se comunicam.
Em um monólito, a função em processo chama os componentes de costura. Em um mundo baseado em serviços, tudo fala pela rede. De repente, as preocupações que antes eram tratadas dentro do aplicativo, como novas tentativas, autenticação, limitação de taxa, criptografia e observabilidade, tornam-se preocupações distribuídas. E as preocupações distribuídas são mais difíceis de acertar.
Para gerenciar essa complexidade, as equipes de engenharia normalmente usam um dos dois padrões: o gateway de API ou o service mesh.
Ambos visam tornar a comunicação entre serviços mais gerenciável, segura e observável. Mas eles fazem isso de maneiras muito diferentes e por razões diferentes. A confusão geralmente começa quando essas ferramentas são tratadas como intercambiáveis ou quando suas funções são reduzidas a uma simples direção de tráfego: "Os gateways de API são para tráfego norte-sul, as malhas de serviço são para leste-oeste". Esse atalho simplifica demais ambos e prepara as equipes para uso indevido ou sobrecarga desnecessária.
Analisamos os gateways de API e o Service Mesh em detalhes, juntamente com suas principais diferenças e metas de uso:
Observe o diagrama abaixo: Essa imagem representa uma arquitetura de microsserviços com API Gateway um padrão bastante comum em sistemas distribuídos modernos, especialmente em plataformas de mobilidade (como Uber, 99, ou Lyft). Tecnicamente, o tipo exato é conhecido como API Gateway Pattern dentro do estilo Service-Oriented Microservices Architecture.
Veja a análise completa:
- Cada módulo hexagonal verde (Passenger Management, Driver Management, Trip Management, Billing, Payments, Notification) é um microsserviço independente, com sua própria REST API, banco de dados e domínio funcional.
- O API Gateway centraliza o acesso externo — ou seja, o app móvel e as interfaces web não se conectam diretamente a cada serviço, mas sim ao gateway, que roteia requisições, aplica autenticação, logging, rate limiting, etc.
- Os adapters externos (Stripe Adapter, Twilio Adapter, SendGrid Adapter) mostram integrações com serviços externos, aqui o padrão de integração é o adapter pattern, acoplado a serviços de pagamento, SMS e e-mail.
- Essa topologia também sugere o uso de Service Mesh (como Istio ou Linkerd), já que há comunicação cruzada direta entre microsserviços (REST API interna).
Conceitualmente, isso é uma arquitetura de microsserviços com gateway unificado e comunicação síncrona via REST, uma variação moderna do Backend for Frontend (BFF) quando há múltiplos front-ends (Passenger Web UI, Driver Web UI, Mobile App).
Se você fosse nomear essa arquitetura tecnicamente em um documento de design ou currículo, a forma mais correta seria:
Arquitetura de Microsserviços com API Gateway Pattern e integração externa via Adapters (REST-based Service Mesh).
Em termos práticos, é uma arquitetura distribuída e escalável, com alta coesão entre domínios (DDD) e baixo acoplamento entre serviços.
Essa arquitetura pode (e quase sempre deve) envolver Service Discovery, mesmo que isso não esteja explícito no diagrama. Explicando tecnicamente: o Service Discovery (como o que o Netflix OSS, Consul ou Eureka implementam) é um componente fundamental em sistemas de microsserviços dinâmicos, porque cada serviço pode estar em múltiplas instâncias, distribuídas em diferentes hosts, containers ou pods (em Kubernetes, por exemplo).
No diagrama, o API Gateway funciona como ponto de entrada, mas para conseguir rotear requisições corretamente, ele precisa saber onde cada serviço está rodando. É aí que entra o Service Discovery: ele mantém um catálogo de endpoints ativos e suas localizações (geralmente em formato de registros DNS dinâmicos ou endpoints HTTP).
A relação entre os dois é a seguinte:
- O API Gateway consulta o Service Discovery para saber onde estão os microsserviços que ele precisa chamar.
- Os microsserviços registram-se automaticamente no Service Discovery quando sobem (registro dinâmico) e removem-se quando caem (deregistro).
- Outros microsserviços também consultam o Service Discovery quando precisam se comunicar entre si.
Na prática, se o diagrama fosse expandido, veríamos o Service Discovery (como Consul, Eureka, etc.) entre o Gateway e os serviços, gerenciando o roteamento interno. Essa arquitetura não é apenas API Gateway Pattern, mas uma arquitetura de microsserviços com API Gateway e Service Discovery — o que a torna altamente resiliente e escalável.
Se fosse descrever com rigor de senior:
“Essa arquitetura implementa um modelo de microsserviços com API Gateway, comunicação síncrona via REST e resolução dinâmica de endpoints por meio de Service Discovery, garantindo balanceamento, disponibilidade e desacoplamento entre serviços.”
Por que precisamos usar um cadeado distribuído (distributed lock)? Um bloqueio distribuído é um mecanismo que garante a exclusão mútua em um sistema distribuído.
Principais 6 Casos de Uso para Bloqueios Distribuídos
-
Leader Election: Bloqueios distribuídos podem ser usados para garantir que apenas um nó se torne líder em qualquer momento.
-
Task Scheduling: Em um agendador de tarefas distribuído, bloqueios distribuídos garantem que uma tarefa agendada seja executada por apenas um nó de trabalho, evitando execução duplicada.
-
Resource Allocation: Ao gerenciar recursos compartilhados como sistemas de arquivos, sockets de rede ou dispositivos de hardware, locks distribuídos garantem que apenas um processo possa acessar o recurso por vez.
-
Microservices Coordination: Quando múltiplos microserviços precisam realizar operações coordenadas, como atualizar dados relacionados em diferentes bancos de dados, bloqueios distribuídos garantem que essas operações sejam realizadas de maneira controlada e ordenada.
-
Inventory Management: Em plataformas de comércio eletrônico, fechaduras distribuídas podem gerenciar atualizações de estoque para garantir que os níveis de estoque sejam mantidos corretamente quando vários usuários tentam comprar o mesmo item simultaneamente.
-
Session Management: Ao lidar com sessões de usuário em um ambiente distribuído, locks distribuídos podem garantir que uma sessão de usuário seja modificada apenas por um servidor por vez, evitando inconsistências.

https://medium.com/tinder/how-we-built-the-tinder-api-gateway-831c6ca5ceca
 |
 |
How Tinder’s API Gateway Handles A Billion Swipes Per Day:
Warning
Aviso: Os detalhes deste post foram derivados dos artigos compartilhados online pela equipe de engenharia do Tinder. Todo o crédito pelos detalhes técnicos vai para a equipe de engenharia do Tinder. Os links para os artigos e fontes originais estão presentes na seção de referências ao final do post. Tentamos analisar os detalhes e dar nossa opinião sobre eles. Se você encontrar alguma imprecisão ou omissão, por favor, deixe um comentário e faremos o possível para corrigi-las.
Gateways de API estão na linha de frente de qualquer aplicação em grande escala. Eles expõem os serviços ao mundo externo, garantem segurança e moldam como os clientes interagem com o backend. A maioria das equipes começa com soluções prontas para uso como AWS API Gateway, Apigee ou Kong. E para muitos casos de uso, essas ferramentas funcionam bem, mas em alguns momentos podem não ser suficientes.
O Tinder chegou a esse ponto por volta de 2020.
Ao longo dos anos, o Tinder cresceu para mais de 500 microserviços. Esses serviços se comunicam internamente via malha de serviços, mas APIs voltadas para o exterior, que lidam com tudo, desde recomendações até correspondências e pagamentos, precisavam de um ponto de entrada unificado, seguro e amigável para desenvolvedores. Gateways prontos a oferecer poder, mas não precisão. Eles impuseram restrições à configuração, introduziram complexidade na implantação e careciam de integração profunda com a pilha de nuvem do Tinder.
Também havia um problema de velocidade. Equipes de produto enviam atualizações frequentes para serviços backend e clientes móveis. O portal precisava acompanhar. Cada atraso na exposição de uma nova rota ou comportamento de ajuste na borda retardava a entrega de recursos.
Depois veio a preocupação maior: a segurança. O Tinder opera globalmente. Tráfego real de usuários chega de mais de 190 países. O mesmo vale para o tráfego ruim, incluindo bots, scrapers e tentativas de abuso. O portal se tornou um ponto crítico de estrangulamento. Ele precisava impor controles rigorosos, detectar anomalias e aplicar filtros protetores sem desacelerar o tráfego legítimo.
A equipe de engenharia precisava de mais do que um gateway de API. Era necessário um framework que pudesse escalar com a organização, integrar profundamente com ferramentas internas e permitir que as equipes avançassem rápido sem comprometer a segurança.
Foi aqui que nasceu o TAG (Tinder API Gateway).
Desafios antes do TAG: Antes do TAG, a lógica do gateway no Tinder era um mosaico de soluções de terceiros. Diferentes equipes de aplicação adotaram diferentes produtos de gateway de API, cada um com sua própria pilha tecnológica, modelo operacional e limitações. O que funcionava bem para um time virou um gargalo para outro.
Essa configuração fragmentada introduziu atrito real:
- Stacks tecnológicos incompatíveis dificultavam o compartilhamento de código ou configuração.
- Componentes reutilizáveis não podiam se propagar entre equipes, levando à duplicação e desvio.
- O comportamento do gerenciamento de sessões variava entre gateways, criando bugs sutis e experiências de usuário inconsistentes.
- A sobrecarga operacional aumentou. Cada portal tinha suas peculiaridades, ciclo de atualização e custo de manutenção.
- A velocidade de implantação diminuiu. As equipes passaram mais tempo aprendendo, depurando e contornando limitações do gateway do que enviando recursos.
Aqui está um vislumbre da complexidade do gerenciamento de sessões entre APIs no Tinder antes do TAG.

Ao mesmo tempo, recursos centrais simplesmente estavam ausentes ou difíceis de implementar em gateways existentes. Alguns exemplos foram os seguintes:
Não há uma maneira limpa de criar gateways por aplicação que pudessem escalar de forma independente.
Suporte limitado para fluxos de trabalho nativos do Kubernetes, que o Tinder já havia adotado em outros lugares.
Os formatos de configuração eram pesados ou inflexíveis, retardando as equipes que tentavam expor ou modificar rotas.
Construir middleware personalizado, como filtros para detecção de bots ou aplicação de esquema de requisições, era ou sem suporte ou difícil de manter.
Transformar pedidos e respostas na borda exigia escrever boilerplate ou adotar plugins frágeis.
Esses não eram casos extremos. Eram necessidades diárias em um produto de rápida escala global.
A necessidade era clara: uma estrutura interna única que permitisse a qualquer equipe do Tinder construir e operar um gateway de API seguro e de alto desempenho com atritos mínimos.
Limitações das Soluções Existentes: Antes de construir o TAG, a equipe avaliou várias soluções populares de gateway de API, incluindo AWS API Gateway, Apigee, Kong, Tyk, KrakenD e Express Gateway.
Cada uma dessas plataformas tinha seus pontos fortes, mas nenhuma se alinhava bem com as demandas operacionais e arquitetônicas do Tinder.
Várias questões centrais surgiram durante a avaliação:
Integração fraca com o Envoy, que serve como a espinha dorsal da malha interna de serviço do Tinder.
A sobrecarga de configuração era alta. Configurar até mesmo rotas ou transformações básicas envolvia arquivos de configuração detalhados, sistemas de plugins desconhecidos ou scripts personalizados.
Curvas de aprendizado íngremes retardaram o onboarding e a depuração. As equipes precisavam aprender o interior de cada gateway em vez de focar em entregar recursos.
O suporte ruim para as linguagens e ferramentas preferidas do Tinder significava mais código de colagem e menos reutilização. O atrito aumentou rapidamente.
A extensibilidade era limitada. Adicionar filtros personalizados ou middleware frequentemente significava forkar o gateway, escrever plugins não suportados ou lidar com hooks de ciclo de vida frágeis.
O que é TAG? TAG, abreviação de Tinder API Gateway, é um framework baseado em JVM construído sobre o Spring Cloud Gateway.
Não é um produto plug-and-play nem uma única instância de gateway compartilhada. É um kit de ferramentas para construir gateways. Cada equipe de aplicação pode usá-lo para criar sua própria instância de gateway de API, adaptada às suas rotas, filtros e necessidades de tráfego específicas. Veja o diagrama abaixo para referência:

No seu cerne, o TAG transforma a configuração em infraestrutura. As equipes definem suas rotas, regras de segurança e comportamento de middleware usando arquivos simples YAML ou JSON. O TAG cuida do resto ligando tudo nos bastidores usando o motor reativo da Spring.
Esse design desbloqueia três resultados críticos:
Fluxos de trabalho mais rápidos para desenvolvedores, já que a maioria das mudanças não exige código, apenas configuração.
Limites de segurança mais fortes, porque as equipes possuem e isolam suas instâncias de gateway.
Melhor reutilização, por meio de filtros compartilhados e padrões comuns de middleware.
Do ponto de vista do desenvolvedor, a experiência é a seguinte:
Defina rotas em um arquivo de configuração.
Aplique filtros embutidos como setPath, rewriteResponse ou addHeader.
Reutilize filtros globais para questões compartilhadas, como autenticação ou métricas.
Inclua filtros personalizados onde for necessário validação, transformação ou controle específico.
Fluxo de Boot do TAG: A maioria dos gateways de API sofre quando a configuração cresce. As rotas levam tempo para carregar. Filtros adicionam complexidade. Alguns sistemas até analisam a configuração em tempo real, introduzindo latência no momento da solicitação. O TAG evita isso completamente fazendo o trabalho pesado na inicialização.
Construído sobre o Spring Cloud Gateway, o TAG estende o ciclo de vida padrão com componentes personalizados que processam toda a configuração antes que o tráfego comece a fluir. O resultado é um motor de roteamento totalmente preparado, pronto desde a primeira solicitação.
Veja como funciona o boot flow:
O Gateway Watcher inicia o processo, sinalizando que é hora de carregar as definições de rota.
O Gateway Config Parser lê a configuração YAML específica do ambiente e valida a estrutura. Isso inclui caminhos de rota, predicados, filtros e vinculações de serviços backend.
O Gerenciador de Gateway monta um mapeamento dos IDs de rota para seus filtros associados (pré-construídos, personalizados e globais).
O Gateway Route Locator pega esse mapeamento e vincula os predicados de cada rota, filtrando-os para o motor interno de roteamento do Spring Cloud Gateway.
A tabela completa de roteamento é carregada na memória, então, quando o TAG começa a receber tráfego, não há necessidade de análise ou avaliação de configuração em tempo de execução.

Esse projeto garante que a lógica de roteamento seja executada com sobrecarga mínima. Todas as decisões já foram tomadas. Cada rota, predicado e filtro é compilado no grafo de tempo de execução.
A troca é simples e deliberada: se algo estiver configurado incorretamente, o gateway falha rapidamente na inicialização em vez de falhar lentamente durante o tráfego de produção. Ele impõe a correção cedo e protege o desempenho em tempo de execução.
Ciclo de Vida de Solicitação no TAG Quando uma solicitação atinge um gateway alimentado por TAG, ela passa por um pipeline bem definido de filtros, transformações e consultas antes de chegar ao backend. Esse fluxo é um caminho de execução consistente que dá controle às equipes em cada etapa.
Veja o diagrama abaixo:

Veja como o TAG lida com uma solicitação recebida do início ao fim:
Busca Reversa de IP Geo (RGIL) O primeiro passo é a geolocalização. O TAG aplica um filtro global que mapeia o endereço IP do cliente para um código de país ISO de três letras. Este teste leve alimenta:
Limitação de taxa específica por país
Banimento de pedidos geo-conscientes
Comportamento regional de características
O filtro roda antes de qualquer correspondência de rota, garantindo que até caminhos inválidos ou bloqueados possam ser parados antecipadamente.
Varredura de Solicitação e Resposta O TAG captura esquemas de requisição e resposta, não cargas completas. Isso acontece por meio de um filtro global e assíncrono que publica eventos na Amazon MSK (Kafka).
O fluxo de dados possibilita:
-
Geração automática de esquemas para documentação de API
-
Detecção de bots, baseada em padrões e formato de requisição
-
Ferramentas de detecção de anomalias que analisam a estrutura do tráfego em tempo real
-
O filtro funciona fora da thread principal, evitando impacto na latência da requisição.
Gerenciamento de Sessões: Um filtro global centralizado lida com a validação e atualizações das sessões, garantindo que a lógica da sessão permaneça consistente em todos os gateways e serviços.
Não há desvio por sessão por serviço ou lógica duplicada.
Correspondência de Predicados: Uma vez concluídos os filtros preliminares, o TAG corresponde ao caminho da requisição a uma rota configurada usando o mecanismo de predicados do Spring Cloud Gateway.
Se nenhuma correspondência for encontrada, o pedido é rejeitado antecipadamente.
Descoberta de Serviços (Service Discovery): Com a rota identificada, o TAG usa a malha de serviço do Envoy para resolver o serviço backend correto. Essa abordagem desacopla o roteamento de IPs fixos ou listas de serviço estáticas.
Pré-Filtros: Antes de encaminhar a solicitação, o TAG aplica quaisquer pré-filtros definidos para essa rota. Esses podem incluir:
Roteamento ponderado entre diferentes versões do backend.
Conversão de HTTP para gRPC, quando os clientes frontend falam HTTP, mas o backend fala gRPC.
Filtros personalizados, como cortar cabeçalhos ou validar campos de requisição.
Os pré-filtros rodam em uma sequência definida, determinada pela configuração.
Pós-Filtros: Após a resposta do serviço de backend, o TAG processa a saída por meio de filtros pós-post. Esses frequentemente incluem:
Registro ou enriquecimento de erros
Modificação de cabeçalhos ou mascaramento de campos sensíveis
Transformações de resposta para normalização de formas
Novamente, a ordem de execução é configurável.
Resposta Final Uma vez que todos os filtros pós-filtros estejam concluídos, a resposta final é enviada de volta ao cliente. Sem surpresas, sem efeitos colaterais.
Todo filtro (pré, pós, global ou personalizado) segue uma ordem de execução rigorosa. Desenvolvedores podem:
Insira lógica personalizada em qualquer etapa.
Compartilhe filtros entre rotas.
Defina a prioridade exata de execução.
Essa previsibilidade é o que torna o TAG sustentável sob carga.
Conclusão O TAG se tornou o framework padrão de gateway de API em todo o Tinder. Em vez de depender de uma única instância centralizada de gateway, cada equipe de aplicação implanta sua instância TAG com configurações específicas de cada aplicação. Esse modelo dá autonomia às equipes enquanto preserva a consistência em como as rotas são definidas, o tráfego é filtrado e a segurança é aplicada.
Cada instância de TAG escala de forma independente, facilitando a adaptação a mudanças nos padrões de tráfego, lançamentos de recursos ou prioridades de negócios. A TAG agora alimenta tanto o tráfego B2C quanto B2B, não só para o Tinder, mas também para outras marcas do Match Group como Hinge, OkCupid, PlentyOfFish e Ship.
Veja a visualização abaixo para essa capacidade.

O design do TAG desbloqueia várias vantagens de longo prazo:
A lógica de sessão e autenticação é padronizada, eliminando inconsistências entre equipes e serviços.
O suporte a plugins personalizados permite experimentação rápida e ajustes finos no comportamento na borda.
Sem lock-in de fornecedores, o Tinder controla seu caminho evolutivo sem esperar atualizações do roadmap de terceiros.
O Route-as-Config (RAC) permite que as equipes enviem mudanças mais rápido sem precisar escrever código ou esperar pelas equipes centrais.
Além do uso atual em produção, o TAG estabelece a base para futuras iniciativas que exigem visibilidade e controle na camada da API. A lição aqui não é que toda empresa precisa construir um gateway personalizado. A lição é que, em certa escala, flexibilidade, consistência e desempenho não podem ser resolvidos apenas com ferramentas prontas. O TAG funciona porque é profundamente moldado por como o Tinder constrói, implanta e defende seu software, sem comprometer a velocidade do desenvolvimento ou a clareza operacional.

O CQRS (Command-Query Responsibility Segregation) é um padrão arquitetural que separa as operações de escrita comandos (command) das operações de leitura consultas (query) em um sistema, atribuindo responsabilidades distintas para cada uma delas. Em vez de usar o mesmo modelo de dados e lógica para lidar tanto com as atualizações quanto com as consultas, o CQRS propõe que esses dois aspectos sejam tratados de maneira independente, o que permite otimizações específicas para cada cenário.
O CQRS - Command Query Responsibility Segregation (Segregação de Responsabilidade por Comando e Consulta) é um padrão que isola processos de leitura e atualização de armazenamento de dados. A implementação do CQRS na sua aplicação pode melhorar seu desempenho, escalabilidade e segurança. A flexibilidade obtida ao migrar para o CQRS permite que um sistema evolua de forma mais eficaz ao longo do tempo e impede que instruções de atualização desencadeem conflitos de fusão no nível do domínio.
CQRS, que significa Command Query Responsibility Segregation, é um padrão arquitetônico que separa as preocupações de leitura e gravação de dados.
Ela divide uma aplicação em duas partes distintas:
-
Lado de Comandos (Command): Responsável por gerenciar solicitações de criação, atualização e exclusão.
-
Lado da Consulta (Query): Responsável por lidar com requisições de leitura.
O padrão CQRS foi introduzido pela primeira vez por Greg Young, desenvolvedor e arquiteto de software, em 2010. Ele descreveu isso como uma forma de separar a responsabilidade de lidar com comandos (operações de escrita) do tratamento de consultas (operações de leitura) em um sistema.
As origens do CQRS podem ser rastreadas até o princípio de Separação Comando-Consulta (CQS), introduzido por Bertrand Meyer. O CQS afirma que todo método deve ser um comando que executa uma ação ou uma consulta que retorna dados, mas não ambos. O CQRS leva o princípio CQS além, aplicando-o em nível arquitetônico, separando as responsabilidades de comando e consulta em diferentes modelos, serviços ou até bancos de dados.
Desde sua introdução, o CQRS ganhou popularidade na comunidade de desenvolvimento de software, especialmente no contexto de arquiteturas de design orientado a domínio (DDD) e orientado a eventos.
Ele tem sido aplicado com sucesso em diversos domínios, como comércio eletrônico, sistemas financeiros e aplicações colaborativas, onde desempenho, escalabilidade e complexidade são preocupações críticas.
Vamos aprender sobre o CQRS em detalhes completos. Vamos cobrir os vários aspectos do padrão, junto com uma matriz de decisão sobre quando usá-lo. Modelos separados de consulta e atualização facilitam o design e a implementação. embora o código CQRS não possa ser gerado automaticamente a partir de um esquema de banco de dados usando técnicas de andaime, como ferramentas O/RM (embora você possa adicionar seu código personalizado sobre o código gerado).
Você pode dividir fisicamente os dados de leitura e gravação para maior isolamento. Nesse caso, o banco de dados de leitura pode utilizar seu próprio esquema de dados otimizado para consultas. Ele pode, por exemplo, armazenar uma visualização materializada dos dados para evitar junções complexas ou mapeamentos O/RM. Pode até empregar um tipo diferente de armazenamento de dados.
A escalabilidade de um sistema depende fortemente da camada de dados.
Não importa o quanto de esforço seja feito para escalar a API ou a camada de aplicação, ela é limitada pela escalabilidade da camada de dados. Além disso, escalar a camada de dados costuma ser a tarefa mais difícil durante o design da aplicação.
Escalar horizontalmente a camada de dados de uma aplicação, também conhecido como "escalonamento", envolve distribuir os dados e a carga entre múltiplos servidores ou nós.
Essa abordagem é particularmente eficaz para lidar com grandes volumes de dados e altas cargas de tráfego, mas também adiciona múltiplas ordens de complexidade. Como os dados são distribuídos, muitas questões relacionadas a transações e consistência que não aparecem em bancos de dados monolíticos tornam-se bastante comuns.
Existem várias técnicas disponíveis para escalar horizontalmente a camada de dados, cada uma com prós e contras, com nuances específicas que valem a pena considerar.
Vamos explorar as principais técnicas para escalar horizontalmente a camada de dados junto com exemplos. Além disso, vamos entender as vantagens e desvantagens de cada técnica para ter uma ideia melhor de quando usar uma abordagem específica em relação a outra.
Por exemplo, o banco de dados de escrita pode ser relacional, e o banco de dados de leitura pode ser um banco de dados de documentos.
 |
 |
Veja como funciona:
-
O cliente envia um comando para atualizar o estado do sistema. Um Gerenciador de Comandos valida e executa a lógica usando o Modelo de Domínio.
-
As alterações são salvas no Banco de Dados de Escrita e também podem ser salvas em um Armazenamento de Eventos. Eventos são emitidos para atualizar o Modelo de Leitura de forma assíncrona.
-
As projeções são armazenadas no Banco de Dados de Leitura. Esse banco de dados acaba sendo consistente com o Write Database.
-
No lado da consulta, o cliente envia uma consulta para recuperar os dados.
-
Um Gerenciador de Consultas busca dados do Banco de Dados de Leitura, que contém projeções pré-computadas.
-
Os resultados são retornados ao cliente sem atingir o modelo de escrita ou o banco de dados de escrita.
Principais Padrões de Consistência Eventual que Você Deve Conhecer

Consistência eventual é um modelo de consistência de dados que garante que as atualizações de um banco de dados distribuído sejam eventualmente refletidas em todos os nós. Técnicas como replicação assíncrona ajudam a alcançar consistência eventual.
No entanto, a consistência eventual também pode resultar em inconsistência nos dados. Aqui estão 4 padrões que podem ajudar você a projetar aplicações.
Padrão#1 - Serviços de Consistência Eventual baseados em eventos emitem eventos e outros serviços escutam esses eventos para atualizar suas instâncias no banco de dados. Isso faz com que os serviços sejam frouxamente acoplados, mas atrasa a consistência dos dados.
Padrão#2 - Sincronização em Segundo Plano Consistência Eventual Nesse padrão, um trabalho em segundo plano torna os dados entre bancos de dados consistentes. Isso resulta em uma consistência eventual mais lenta, já que o trabalho em segundo plano roda em um cronograma específico.
Padrão#3 - Saga de Consistência Eventual baseada em Saga é uma sequência de transações locais onde cada transação atualiza os dados com um único serviço. Ele é usado para gerenciar transações de longa duração que eventualmente se tornam consistentes.
Padrão#4 - Consistência Eventual baseada em CQRS Operações separadas de leitura e escrita em diferentes bancos de dados que eventualmente se tornam consistentes. Modelos de leitura e escrita podem ser otimizados para requisitos específicos.
A conversa é sua: Quais outros padrões de consistência eventual você já viu?
No contexto de comandos, o foco está em realizar mudanças no estado da aplicação. Essas operações geralmente envolvem regras de negócios que precisam ser validadas antes que os dados sejam modificados. Por outro lado, as consultas têm como objetivo apenas recuperar e exibir dados, sem causar impacto no estado do sistema. Essa separação pode resultar em um design mais simples e eficiente, pois permite que cada lado seja modelado e implementado de acordo com suas necessidades específicas.
O CQRS é um dos padrões importantes ao consultar entre microsserviços. Podemos usar o padrão de design CQRS para evitar consultas complexas para se livrar de junções ineficientes. CQRS significa Segregação de Responsabilidade de Comando e Consulta. Basicamente, esse padrão separa as operações de leitura e atualização de um banco de dados.
Normalmente, em aplicações monolíticas, na maioria das vezes temos 1 banco de dados e esse banco de dados deve responder tanto às operações de consulta quanto de atualização. Isso significa que um banco de dados está trabalhando para consultas de junção complexas e também executa operações CRUD. Mas se o aplicativo for mais complexo, essa consulta e as operações crud também serão uma situação não gerenciável.
No exemplo de leitura de banco de dados, se seu aplicativo exigiu alguma consulta que precisa unir mais de 10 tabelas, isso bloqueará o banco de dados devido à latência da computação da consulta. Além disso, se dermos um exemplo de gravação de banco de dados, ao realizar operações crud, precisaríamos fazer validações complexas e processar lógicas de negócios longas, portanto, isso causará o bloqueio das operações do banco de dados.
Além disso, o CQRS se integra bem a outras abordagens, como Event Sourcing, onde as mudanças de estado são representadas por eventos. Nesse caso, os comandos geram eventos que podem ser armazenados e usados para reconstruir o estado atual do sistema, enquanto as consultas podem acessar modelos de leitura otimizados que foram derivados desses eventos.
O CQRS é especialmente útil em sistemas complexos, onde as operações de leitura e escrita têm diferentes requisitos de desempenho, escalabilidade ou segurança. Ele também facilita a evolução do sistema, pois a separação de responsabilidades torna mais fácil introduzir novas funcionalidades ou modificar as existentes sem impacto significativo em outras partes do código. No entanto, sua implementação pode aumentar a complexidade inicial, e é importante avaliar se os benefícios justificam o esforço em projetos de menor escala ou simplicidade.
Aplicar estilos e padrões arquiteturais adequados em nossos componentes de software demonstram maturidade em sua base de construção. A decisão correta demanda esforço de maneira a prosperar, e sem dúvida, a escolha certa torna-se um grande ponto de partida para o sucesso de nossa aplicação, naturalmente facilitando adoção posterior de outros padrões/conceitos que estejam preparados para enfrentarmos as dificuldades relacionadas às aplicações distribuídas.
Independente do padrão de implementação adotado em nossas API’s/componentes, seja RESTful/CRUD/EDA (event-driven architecture), naturezas de comunicação síncronas/assíncronas, quando utilizada a Arquitetura de Microsserviços o padrão CQRS poderá agregar benefícios como veremos a seguir. Além disso, aplicado juntamente a outros conceitos complementares (Event Sourcing, DDD) atribuem a nossas aplicações um diferencial competitivo quando abraçamos os principais desafios pertencentes aos sistemas distribuídos.
Portanto, a leitura e a gravação do banco de dados têm abordagens diferentes para que possamos definir estratégias diferentes para lidar com essa operação. Para isso, o CQRS oferece o uso de princípios de "separação de preocupações" e banco de dados de leitura separado e o banco de dados de gravação com 2 bancos de dados. Dessa forma, podemos até usar diferentes bancos de dados para ler e gravar tipos de banco de dados, como usar no-sql para leitura e usar banco de dados relacional para operações crud.
Outra consideração é que devemos entender os comportamentos de caso de uso de nosso aplicativo, se nosso aplicativo estiver principalmente lendo casos de uso e não escrevendo tanto, podemos dizer que nosso aplicativo é um aplicativo de incentivo de leitura. Portanto, devemos projetar nossa arquitetura de acordo com nossos requisitos de leitura, concentrando-se em bancos de dados de leitura.
Portanto, podemos dizer que o CQRS separa leituras e gravações em diferentes bancos de dados, Comandos executa dados de atualização, Consultas executa dados de leitura.
Os comandos devem ser ações com operações baseadas em tarefas, como "adicionar item ao carrinho de compras" ou "pedido de check-out". Portanto, os comandos podem ser manipulados com sistemas de agentes de mensagens que fornecem comandos de processamento de maneira assíncrona.
Consultas nunca é modificar o banco de dados. As consultas sempre retornam os dados JSON com objetos DTO. Dessa forma, podemos isolar os Comandos e Consultas.
Para isolar Comandos e Consultas, suas melhores práticas para separar o banco de dados de leitura e gravação com 2 bancos de dados fisicamente. Dessa forma, se nosso aplicativo for de leitura intensiva, o que significa ler mais do que escrever, podemos definir um esquema de dados personalizado para otimizar as consultas.
O padrão de exibição materializado é um bom exemplo para implementar bancos de dados de leitura. Porque desta forma podemos evitar junções e mapeamentos complexos com dados pré-definidos e refinados para operações de consulta.
Por esse isolamento, podemos até usar diferentes bancos de dados para ler e gravar tipos de banco de dados, como usar banco de dados de documentos no-sql para leitura e usar banco de dados relacional para operações crud.
Exemplo: Arquitetura de banco de dados do Instagram - Isso é tão popular na arquitetura de microsserviços que também me permite dar um exemplo da arquitetura do Instagram. O Instagram basicamente usa dois sistemas de banco de dados, um é o banco de dados relacional PostgreSQL e o outro é o banco de dados no-sql - Cassandra.
Isso significa que o Instagram usa o banco de dados Cassandra no-sql para histórias de usuários que são dados de incentivo de leitura. E usando o banco de dados PostgreSQL relacional para atualização da biografia de informações do usuário. Este é um dos exemplos de abordagens do CRQS.
Como sincronizar bancos de dados com CQRS? Mas quando separamos os bancos de dados de leitura e gravação em 2 bancos de dados diferentes, a principal consideração é sincronizar esses dois bancos de dados de maneira adequada.
Portanto, devemos sincronizar esses 2 bancos de dados e manter a sincronização sempre.
Isso pode ser resolvido usando a Arquitetura Orientada a Eventos. De acordo com a Arquitetura Orientada a Eventos, quando algo é atualizado no banco de dados de gravação, ele publicará um evento de atualização com o uso de sistemas de agente de mensagens e isso consumirá pelo banco de dados de leitura e sincronizará os dados de acordo com as alterações mais recentes.
Mas essa solução cria um problema de consistência, porque, como implementamos a comunicação assíncrona com agentes de mensagens, os dados não seriam refletidos imediatamente.
Isso operará o princípio da "consistência eventual". O banco de dados de leitura eventualmente sincroniza com o banco de dados de gravação e pode levar algum tempo para atualizar o banco de dados de leitura no processo assíncrono. Discutiremos a consistência eventual nas próximas seções.
Portanto, se voltarmos aos nossos bancos de dados de leitura e gravação no padrão CQRS, ao iniciar seu design, você pode obter o banco de dados de leitura de réplicas do banco de dados de gravação. Dessa forma, podemos usar diferentes réplicas somente leitura com a aplicação do padrão de exibição materializado que pode aumentar significativamente o desempenho da consulta.
Além disso, quando separamos bancos de dados de leitura e gravação, isso significa que podemos escalá-los de forma independente. Isso significa que, se nosso aplicativo for de incentivo de leitura, quero dizer, se for muito mais consulta que grava, do que podemos escalar apenas lendo bancos de dados muito rápido.
O CQRS vem com comandos de separação e bancos de dados de consulta. Portanto, isso exigia sincronizar os dois bancos de dados com a oferta de arquiteturas orientadas a eventos. E com arquiteturas controladas por eventos, existem alguns novos padrões e práticas que devem ser considerados ao aplicar o CQRS.
O padrão de Fornecimento de Eventos é o primeiro padrão que devemos considerar para usar com o CQRS. Principalmente o CQRS está usando com "Padrão de Fornecimento de Eventos" em Arquiteturas Controladas por Eventos. Portanto, depois de aprendermos o CQRS, devemos aprender o "padrão de fornecimento de eventos", porque o CQRS e o "padrão de fornecimento de eventos" são as melhores práticas para usar os dois.
Projetar a arquitetura — CQRS, fornecimento de eventos, consistência eventual, exibição materializada
Vamos projetar nossa arquitetura de comércio eletrônico com a aplicação do padrão CQRS:
Agora podemos projetar nossos bancos de dados de microsserviços de pedidos
Vou dividir 2 bancos de dados para ordenar microsserviços 1 para o banco de dados de gravação para questões relacionais 2 para o banco de dados de leitura para consultar preocupações.
Então, quando o usuário criar ou atualizar um pedido, usarei o banco de dados de gravação relacional e, quando o pedido de consulta do usuário ou o histórico de pedidos, usarei o banco de dados de leitura no-sql. e torná-los consistentes ao sincronizar 2 bancos de dados com o uso do sistema de agente de mensagens com a aplicação do padrão de publicação/assinatura.
Agora podemos considerar a pilha de tecnologia desses bancos de dados, vou usar o SQL Server para o banco de dados de escrita relacional e o Cassandra para o banco de dados de leitura no-sql. É claro que usaremos o Kafka para sincronizar esses 2 bancos de dados com as trocas de tópicos pub / sub Kafka.
Portanto, devemos evoluir nossa arquitetura com a aplicação de outros padrões de dados de microsserviços para acomodar adaptações de negócios, tempo de lançamento no mercado mais rápido e lidar com solicitações maiores.
https://medium.com/@martinstm/cqrs-pattern-c-a6632693d3e1

O padrão Saga (Saga Pattern) foi originalmente proposto pelos cientistas da computação Hector Gracia Molina e Kenneth Salem, é uma abordagem para gerenciar transações distribuídas em uma arquitetura de microsserviços. Em sistemas distribuídos, uma transação (transaction) pode envolver múltiplos microsserviços, o que torna o uso de transações tradicionais (como as que utilizam o protocolo de commit em duas fases) impraticável devido à complexidade e ao impacto na performance.
O padrão Saga oferece uma maneira de garantir a consistência dos dados e a execução das transações em tais sistemas. O padrão Saga é frequentemente associado ao conceito de Long-Running Transactions (LRTs). SAGA pode ser descrito como uma sequência de transações que podem ser intercaladas com outras transações.
Em aplicações empresariais, quase toda requisição é executada dentro de uma transação de banco de dados.
Desenvolvedores frequentemente utilizam frameworks e bibliotecas com mecanismos declarativos para simplificar o gerenciamento de transações.
O framework Spring, por exemplo, usa uma anotação especial para organizar que invocações de métodos sejam executadas automaticamente dentro de uma transação. Essa anotação simplifica a escrita da lógica de negócios transacional, facilitando o gerenciamento de transações em uma aplicação monolítica que acessa um único banco de dados.
No entanto, embora o gerenciamento de transações seja relativamente simples em uma aplicação monolítica que acessa um único banco de dados, ele se torna mais complexo em cenários envolvendo múltiplos bancos de dados e corredores de mensagens.
Por exemplo, em uma arquitetura de microserviços, as transações empresariais abrangem múltiplos serviços, cada um com seu banco de dados. Essa complexidade torna a abordagem tradicional de transação impraticável. Em vez disso, aplicações baseadas em microserviços devem adotar mecanismos alternativos para gerenciar as transações de forma eficaz.
Vamos entender por que aplicações baseadas em microserviços exigem uma abordagem mais sofisticada para a gestão de transações, como o uso do padrão Saga. Também entenderemos as diferentes abordagens para implementar o padrão Saga em uma aplicação.
Warning
Problema: Microserviços têm suas próprias vantagens e desvantagens. Uma dessas desvantagens é gerenciar transações distribuídas. Digamos que sua transação abrange 4 microserviços diferentes. Como garantir que sua transação seja confirmada com sucesso com todas as 4 tarefas ou fracasse se alguma das tarefas não for concluída (as concluídas forem revertidas)? O Spring Boot fornece a @Transactional de anotação para gerenciar transações. Mas isso funciona apenas dentro de um único método e dentro de um único projeto.
Tip
Solução: Existe um padrão de design que resolve o problema com transações distribuídas em microserviços e ele surgiu exatamente porque o modelo clássico de transações distribuídas — o famoso Two-Phase Commit (2PC) — simplesmente não escala bem nem combina com os princípios de microserviços. O padrão que resolve esse problema de forma pragmática é o Saga Pattern, e ele parte de uma mudança mental importante: em vez de tentar garantir atomicidade global forte, ele assume que falhas vão acontecer e modela explicitamente como o sistema deve se recuperar delas.
O Spring Boot fornece a @Transactional de anotação para gerenciar transações. Mas isso funciona apenas dentro de um único método e dentro de um único projeto.
Nos aprofundamos no intrincado mundo das transações distribuídas através das lentes do padrão SAGA, uma estratégia fundamental para gerenciar a consistência de dados em arquiteturas de microsserviços descentralizadas. Com o brilho dos microsserviços, o SAGA é quase a solução ideal quando se trata de transações distribuídas, entender como lidar efetivamente com transações que abrangem vários serviços torna-se crucial. Esta discussão visa não apenas esclarecer os princípios fundamentais dos SAGAs, mas também fornecer insights práticos sobre sua aplicação estratégica, garantindo interações robustas e sem erros dentro de seus serviços.
Uma compreensão fundamental dos microsserviços é essencial para compreender totalmente as nuances das SAGAs. Recomenda-se que os leitores tenham familiaridade com os vários mecanismos de comunicação empregados em arquiteturas de microsserviços. Para aqueles que buscam aprofundar seus conhecimentos, convido você a ler meu post detalhado no blog, "Um Guia para Estilos de Comunicação na Arquitetura de Microsserviços", que oferece uma análise aprofundada sobre esse assunto.
Da arquitetura monolítica à arquitetura de microsserviços, quase todas as solicitações tratadas por um aplicativo empresarial são executadas em uma transação de banco de dados. Os desenvolvedores de aplicativos corporativos usam estruturas e bibliotecas que simplificam o gerenciamento de transações. Algumas estruturas e bibliotecas fornecem uma API programática para iniciar, confirmar e reverter transações explicitamente. Outras estruturas, como a estrutura Spring, fornecem um mecanismo declarativo.
O Spring fornece uma anotação @Transactional que organiza as invocações de método a serem executadas automaticamente em uma transação. Como resultado, é simples escrever lógica de negócios transacional.
Warning
Deixei nosso backend Java 50x mais rápido substituindo essa anotação, veja como uma anotação aparentemente inocente da primavera estava silenciosamente matando o desempenho abaixo.
Nosso backend era lento. Não é "esperar um arquivo para baixar". Quero dizer, vovó atravessando a rua com um andaril. Cada pedido se arrastava como se tivesse acabado de correr uma maratona de chinelos.
O uso da CPU estava suspeitosamente alto, os logs GC pareciam um ECG, e os tempos de resposta... Bem, digamos que os usuários não ficaram satisfeitos.
Eu já tinha feito a dança de sempre: perfilar, otimizar consultas, ajustar as bandeiras da JVM, rezar para os deuses do GC. Nada funcionou...
E então — durante mais uma sessão de perfil — encontrei o culpado. Não era uma consulta de banco de dados. Não foi uma grande serialização em JSON. Nem era um código ruim. Era o @Transactional, sim, aquela inocente anotação da primavera.
A Cena do Crime: @Transactional é como fita adesiva. Fácil de colocar. Mantém tudo unido. Mas comece a usá-la em todos os lugares, e de repente você já construiu toda a casa com fita adesiva. E fita adesiva não é aço.
Nossa equipe havia espalhado todos os métodos de serviço @Transactional
Porque, sabe, "só por precaução." Como colocar um impermeável no deserto—suado, desnecessário e, eventualmente, com cheiro ruim.
O problema? Todo @Transactional abre um proxy, intercepta chamadas, inicia uma transação (mesmo para operações somente leitura) e funciona bem com o PlatformTransactionManager subjacente.
Isso não é de graça, na verdade, quando seu app está lidando com milhares de solicitações por segundo, esse "gratuito" começa a parecer uma assinatura premium da Netflix que você nunca quis.
O Momento Ahá-Ha: Durante o perfil, percebi que 40% do tempo de execução estava sendo consumido pela sobrecarga de transações — para métodos que nem sequer modificavam o banco de dados.
Imagine pagar um pedágio toda vez que passar pela ponte sem nem atravessá-la.
Então decidi tentar algo radical: remover dos métodos somente leitura @Transactional.
O Substituto: Em vez de bater cegamente em todos os lugares, eu: @Transactional
-
Marcou apenas operações de escrita como
@Transactional -
Para operações com muita leitura, removi completamente ou usei:
@Transactional(readOnly = true)- Melhor ainda, para alguns caminhos críticos de desempenho, abandonei completamente o gerenciamento de transações do Spring e deixei os métodos do repositório cuidarem do que precisavam.
Os Resultados: O impacto? Como trocar uma bicicleta por um trem-bala.
- 50 vezes mais rápido para alguns endpoints.
- A carga do processador foi reduzida pela metade.
- A atividade do GC caiu quase para nada.
- Os usuários pararam de me enviar "o site está fora do ar?" Mensagens no Slack.
Tudo porque substituí (ou removi) uma anotação.
A Realidade: Agora, antes de correr e sair para uma onda de deletes, lembre-se: grep -r "@Transactional"
- Transações são críticas para a integridade dos dados.
- Se você está modificando dados, precisa deles.
- Transações somente leitura ainda podem ser úteis para garantir alguma consistência.
Mas, por favor pelo amor do código limpo pare de colocá-los em todos os métodos "só por precaução." Isso é como usar capacete para dormir porque "nunca se sabe."
O Aprendizado: O código mais rápido é o que não roda. Cada anotação tem um custo. é poderoso, mas não é gratuito @Transactional
Da próxima vez que seu backend parecer lento, não olhe apenas para seu banco de dados ou rede. Confira suas anotações.
O problema pode ser uma linha de código que exige silenciosamente cada solicitação.
Ou, para ser mais preciso, o gerenciamento de transações é simples em um aplicativo monolítico que acessa um único banco de dados. O gerenciamento de transações é mais desafiador em um aplicativo monolítico complexo que usa vários bancos de dados e agentes de mensagens.
E em uma arquitetura de microsserviços, as transações abrangem vários serviços, cada um com seu próprio banco de dados.
Nessa situação, o aplicativo deve usar um mecanismo mais elaborado para gerenciar transações. Como você aprenderá nesta postagem do blog, a abordagem tradicional de usar transações distribuídas não é uma opção viável para aplicativos modernos. Em vez disso, um aplicativo baseado em microsserviços deve usar sagas.
A necessidade de transações distribuídas em uma arquitetura de microsserviços. Imagine que você é um desenvolvedor encarregado de implementar uma operação do sistema, essa operação deve: createOrder()
- Verificar se um consumidor (cliente) pode fazer um pedido
- Verifique os detalhes do pedido
- Autorizar o cartão de crédito do consumidor
- Crie um pedido no banco de dados.
É relativamente simples implementar essa operação em um aplicativo monolítico, todos os dados necessários para validar o pedido são prontamente acessíveis no monolítico. Além disso, você pode usar uma transação ACID para garantir a consistência dos dados.
Por outro lado, implementar a mesma operação em uma arquitetura de microsserviço é muito mais complicado. Nos microsserviços, os dados necessários estão espalhados por vários serviços, a operação acessa dados em vários serviços, conforme mostrado na Figura a seguir createOrder()
Explorando a integração de vários serviços em uma arquitetura de microsserviços
Ele lê dados do Atendimento ao consumidor e atualiza dados no Serviço de pedidos, Serviço de cozinha e Serviço de contabilidade. Como cada serviço tem seu próprio banco de dados, você precisa usar um mecanismo para manter a consistência dos dados nesses bancos de dados.
O problema com transações distribuídas: A abordagem tradicional para manter a consistência dos dados em vários serviços, bancos de dados ou agentes de mensagens é usar transações distribuídas. O padrão de fato para gerenciamento de transações distribuídas é o Modelo de Processamento de Transações Distribuídas (DTP) X / Open, XA usa confirmação de duas fases (2PC) para garantir que todos os participantes de uma transação se comprometam ou revertam.
Uma pilha de tecnologia compatível com XA consiste em bancos de dados e agentes de mensagens compatíveis com XA, drivers de banco de dados, APIs de mensagens e um mecanismo de comunicação entre processos que propaga o ID de transação global XA. A maioria dos bancos de dados SQL é compatível com XA, assim como alguns agentes de mensagens.
Por mais simples que pareça, há uma variedade de problemas com transações distribuídas heterogêneas. Um problema é que muitas tecnologias modernas, incluindo bancos de dados NoSQL, como MongoDB e Cassandra, não os suportam. Além disso, as transações distribuídas não são suportadas por agentes de mensagens modernos, como RabbitMQ e Apache Kafka.
Como resultado, se você insistir em usar transações distribuídas, estará limitado às tecnologias que podem suportar esse tipo de transação.
Outro problema com as transações distribuídas é que elas são uma forma de IPC (comunicação entre processos) síncrona, o que reduz a disponibilidade. Para que uma transação distribuída seja confirmada, todos os serviços participantes devem estar disponíveis. A disponibilidade é o produto da disponibilidade de todos os participantes da transação. Se uma transação distribuída envolver dois serviços com 99,5% de disponibilidade, a disponibilidade geral será de 99%, o que é significativamente menor. Cada serviço adicional envolvido em uma transação distribuída reduz ainda mais a disponibilidade.
Superficialmente, as transações distribuídas são atraentes. Do ponto de vista de um desenvolvedor, eles têm o mesmo modelo de programação que as transações locais. Mas devido aos problemas mencionados até agora, as transações distribuídas não são uma tecnologia viável para aplicativos modernos.
Usando o padrão SAGA para manter a consistência dos dados: SAGAs são mecanismos para manter a consistência dos dados em uma arquitetura de microsserviço sem precisar usar transações distribuídas. Você define um SAGA para cada comando do sistema que precisa atualizar dados em vários serviços. Um SAGA é uma sequência de transações locais. Cada transação local atualiza dados em um único serviço usando as estruturas e bibliotecas de transações ACID familiares.
A operação do sistema inicia a primeira etapa do SAGA. A conclusão de uma transação local aciona a execução da próxima transação local.
Posteriormente, você verá como a coordenação das etapas é implementada usando mensagens assíncronas. Um benefício importante do sistema de mensagens assíncrono é que ele garante que todas as etapas de um SAGA sejam executadas, mesmo que um ou mais participantes da saga estejam temporariamente indisponíveis.
Os SAGAs diferem das transações ACID de algumas maneiras importantes. Eles não têm a propriedade de isolamento das transações ACID.
UM EXEMPLO DE SAGA: A SAGA 'CREATEOrder', a saga de exemplo usada em toda esta postagem do blog é o , que é mostrado na figura a seguir. O Serviço de Pedidos implementa a operação usando esta SAGA. A primeira transação local da SAGA é iniciada pela solicitação externa para criar um pedido. As outras cinco transações locais são acionadas pela conclusão da anterior. Create Order SAGAcreateOrder()
Esta saga consiste nas seguintes transações locais:
- Serviço de pedido — Crie um pedido em um
state.APPROVAL_PENDING - Atendimento ao consumidor — Verifique se o consumidor pode fazer um pedido.
- Serviço de cozinha — Valide os detalhes do pedido e crie um tíquete no
.CREATE_PENDING - Serviço de contabilidade — Autorize o cartão de crédito do consumidor.
- Serviço de cozinha — Altere o estado do Ticket para
.AWAITING_ACCEPTANCE - Serviço de pedido — Altere o estado do pedido para
.APPROVED
Um serviço publica uma mensagem quando uma transação local é concluída. Essa mensagem aciona a próxima etapa do SAGA, não apenas o uso de mensagens garante que os participantes do SAGA estejam fracamente acoplados, mas também garante que um SAGA seja concluído. Isso ocorre porque, se o destinatário de uma mensagem estiver temporariamente indisponível, o agente de mensagens armazenará a mensagem em buffer até que ela possa ser entregue.
Os SAGAs usam transações de compensação para reverter as alterações. Um grande recurso das transações ACID tradicionais é que a lógica de negócios pode reverter facilmente uma transação se detectar uma violação de uma regra de negócios. Ele executa uma instrução ROLL-BACK e o banco de dados desfaz todas as alterações feitas até o momento. Infelizmente, os SAGAs não podem ser revertidos automaticamente, porque cada etapa confirma suas alterações no banco de dados local.
Isso significa, por exemplo, que se a autorização do cartão de crédito falhar na quarta etapa do Create Order SAGA, o aplicativo deverá desfazer explicitamente as alterações feitas pelas três primeiras etapas. Você deve escrever o que é conhecido como transações de compensação.
O SAGA executa as operações de compensação na ordem inversa das operações a termo:
Cn ... C1. A mecânica de sequenciar o não é diferente de sequenciar o .- A conclusão de
C(i)deve desencadear a execução deC(i-1).C(i)sT(i)s
Considere, por exemplo, a SAGA Create Order. Esta SAGA pode falhar por vários motivos:
- As informações do consumidor são inválidas ou o consumidor não tem permissão para criar pedidos.
- As informações do restaurante são inválidas ou o restaurante não pode aceitar pedidos.
- A autorização do cartão de crédito do consumidor falha.
Se uma transação local falhar, o mecanismo de coordenação da saga deve executar transações de compensação que rejeitem a Ordem e, possivelmente, o Ticket.
A tabela a seguir mostra as transações de compensação para cada etapa da SAGA Criar Ordem. É importante observar que nem todas as etapas precisam de transações de compensação. As etapas somente leitura, como verifyConsumerDetails(), não precisam de transações de compensação. Nem passos como esse são seguidos por passos que sempre são bem-sucedidos.authorizeCreditCard()
Para ver como as transações compensadoras são usadas, imagine um cenário em que a autorização do cartão de crédito do consumidor falha. Nesse cenário, o SAGA executa as seguintes transações locais:
- Serviço de pedido — Crie um pedido em um
state.APPROVAL_PENDING - Atendimento ao consumidor — Verifique se o consumidor pode fazer um pedido.
- Serviço de cozinha — Valide os detalhes do pedido e crie um tíquete no
state.CREATE_PENDING - Serviço de contabilidade — Autorize o cartão de crédito do consumidor, que falha.
- Serviço de cozinha — Altere o estado do Ticket para
.CREATE_REJECTED - Serviço de pedido — Altere o estado do pedido para
.REJECTED - A quinta e a sexta etapas são transações compensatórias que desfazem as atualizações feitas pelo Kitchen Service e pelo Order Service, respectivamente.
- A lógica de coordenação de um SAGA é responsável por sequenciar a execução de transações a termo e de compensação. Vejamos como isso funciona.
Coordenação de SAGAs: A implementação de um SAGA consiste em uma lógica que coordena as etapas da saga. Quando um SAGA é iniciado por um comando do sistema, a lógica de coordenação deve selecionar e informar ao primeiro participante do SAGA para executar uma transação local. Uma vez concluída essa transação, a coordenação de sequenciamento da SAGA seleciona e invoca o próximo participante da saga.
Esse processo continua até que a SAGA tenha executado todas as etapas.
Se alguma transação local falhar, o SAGA deverá executar as transações de compensação na ordem inversa. Existem algumas maneiras diferentes de estruturar a lógica de coordenação de uma saga:
-
Coreografia — Distribua a tomada de decisão e o sequenciamento entre os participantes da saga. Eles se comunicam principalmente por meio da troca de eventos.
-
Orquestração — Centralize a lógica de coordenação de um SAGA em uma classe de orquestrador do SAGA. Um orquestrador do SAGA envia mensagens de comando aos participantes do SAGA informando quais operações executar. Vejamos cada opção.
SAGAs baseados em coreografias: Uma maneira de implementar um SAGA é usando coreografia. Ao usar a coreografia, não há um coordenador central dizendo aos participantes da SAGA o que fazer. Em vez disso, os participantes da SAGA se inscrevem nos eventos uns dos outros e respondem de acordo.
Vamos implementar a SAGA usando COREOGRAFIAcreateOrder
A figura a seguir mostra o design da versão baseada em coreografia do Create Order SAGA. Os participantes se comunicam por meio da troca de eventos. Cada participante, começando com o Serviço de Pedidos, atualiza seu banco de dados e publica um evento que aciona o próximo participante.
O caminho FELIZ por esta SAGA é o seguinte:
- O Serviço de Pedidos cria um Pedido no estado e publica um
event.APPROVAL_PENDINGOrderCreated - O Serviço ao consumidor consome o evento, verifica se o consumidor pode fazer o pedido e publica um
event.OrderCreatedConsumerVerified - O Kitchen Service consome o evento, valida o pedido, cria um ticket em um estado e publica o
event.OrderCreatedCREATE_PENDINGTicketCreated - O Serviço de Contabilidade consome o evento e cria um em um
state.OrderCreateCreditCardAuthorizationPENDING - O Serviço de Contabilidade consome os eventos and, cobra o cartão de crédito do consumidor e publica o
event.TicketCreatedConsumerVerifiedCreditCardAuthorized - O Kitchen Service consome o evento
CreditCardAuthorizede altera o estado do Ticket para.AWAITING_ACCEPTANCE - O serviço de pedido recebe os eventos, altera o estado do pedido para e publica um
event.CreditCardAuthorizedAPPROVEDOrderApproved - A SAGA Criar Ordem também deve lidar com o cenário em que um participante da SAGA rejeita a Ordem e publica algum tipo de evento de falha.
Por exemplo, a autorização do cartão de crédito do consumidor pode falhar. O SAGA deve executar as transações de compensação para desfazer o que já foi feito.
A figura a seguir mostra o fluxo de eventos quando o não é possível autorizar o cartão de crédito do consumidor AccountingService
A sequência de eventos é a seguinte:
- O Serviço de Pedidos cria um Pedido no estado e publica um
event.APPROVAL_PENDINGOrderCreated - O Serviço ao consumidor consome o evento, verifica se o consumidor pode fazer o pedido e publica um
event.OrderCreatedConsumerVerified - O Kitchen Service consome o evento, valida o pedido, cria um ticket em um estado e publica o
event.OrderCreatedCREATE_PENDINGTicketCreated - O Serviço de Contabilidade consome o evento e cria um em um
state.OrderCreatedCreditCardAuthorizationPENDING - O Serviço de Contabilidade consome os eventos and, cobra o cartão de crédito do consumidor e publica um
event.TicketCreatedConsumerVerifiedCreditCardAuthorizationFailed - O Serviço de Cozinha consome o evento e altera o estado do Ticket para
.CreditCardAuthorizationFailedREJECTED - O Serviço de Pedidos consome o evento e altera o estado do Pedido para
.CreditCardAuthorizationFailedREJECTED
Como você pode ver, os participantes de SAGAs baseados em coreografia interagem usando publicar/assinar. Vamos dar uma olhada em algumas questões que você precisará considerar ao implementar a comunicação baseada em publicação/assinatura para seus SAGAs.
Comunicação confiável baseada em eventos: Existem algumas questões relacionadas à comunicação entre serviços que você deve considerar ao implementar SAGAs baseados em coreografia:
-
A primeira questão é garantir que um participante do SAGA atualize seu banco de dados e publique um evento como parte de uma transação de banco de dados. Cada etapa de uma SAGA baseada em coreografia atualiza o banco de dados e publica um evento. Por exemplo, na SAGA Criar pedido, o Serviço de cozinha recebe um evento Verificado pelo consumidor, cria um Ticket e publica um evento Ticket Created. É essencial que a atualização do banco de dados e a publicação do evento aconteçam atomicamente. Consequentemente, para se comunicar de forma confiável, os participantes da SAGA devem usar mensagens transacionais
-
A segunda questão que você precisa considerar é garantir que um participante da saga seja capaz de mapear cada evento que recebe para seus próprios dados. Por exemplo, quando o Order Service recebe um evento, ele deve ser capaz de pesquisar o Order correspondente. A solução é que um participante do SAGA publique eventos contendo um, que são dados que permitem que outros participantes executem o mapeamento. Por exemplo, os participantes da Saga Criar Pedido podem usar o orderId como um ID de correlação que é passado de um participante para o outro. O Serviço de Contabilidade publica um evento que contém o
orderIddoevent.CreditCardAuthorized*correlationId*CreditCardAuthorizedTicketCreated
Benefícios e desvantagens dos SAGAs baseados em coreografia - Os SAGAs baseados em coreografia têm vários benefícios:
- Simplicidade — Os serviços publicam eventos quando criam, atualizam ou excluem objetos de negócios.
- Acoplamento fraco — Os participantes se inscrevem em eventos e não têm conhecimento direto uns dos outros.
E há algumas desvantagens:
- Mais difícil de entender — Ao contrário da orquestração, não há um único lugar no código que defina o SAGA. Em vez disso, a coreografia distribui a implementação do SAGA entre os serviços. Consequentemente, às vezes é difícil para um desenvolvedor entender como um determinado SAGA funciona.
- Dependências cíclicas entre os serviços — Os participantes do SAGA assinam os eventos uns dos outros, o que geralmente cria dependências cíclicas. Por exemplo, se você examinar cuidadosamente os diagramas anteriores, verá que há dependências cíclicas, como .
- Embora isso não seja necessariamente um problema, as dependências cíclicas são consideradas um cheiro de
design.Order Service → Accounting Service → Order Service - Risco de acoplamento estreito — Cada participante do SAGA precisa se inscrever em todos os eventos que os afetam. Por exemplo, o Serviço de Contabilidade deve se inscrever em todos os eventos que fazem com que o cartão de crédito do consumidor seja cobrado ou reembolsado. Como resultado, há o risco de que ele precise ser atualizado em sintonia com o ciclo de vida do pedido implementado pelo Serviço de pedido.
Sagas baseadas em orquestração. A orquestração é outra maneira de implementar SAGAs. Ao usar a orquestração, você define uma classe de orquestrador cuja única responsabilidade é dizer aos participantes do SAGA o que fazer. O orquestrador SAGA se comunica com os participantes usando interação no estilo de resposta assíncrona/comando.
Para executar uma etapa do SAGA, ele envia uma mensagem de comando a um participante informando qual operação executar. Depois que o participante do SAGA tiver executado a operação, ele enviará uma mensagem de resposta ao orquestrador. Em seguida, o orquestrador processa a mensagem e determina qual etapa do SAGA deve ser executada em seguida.
Vamos implementar a SAGA usando ORCHESTRATIONcreateOrder
A figura a seguir mostra o design da versão baseada em orquestração da SAGA Criar Ordem. O SAGA é orquestrado pela classe CreateOrderSaga, que invoca os participantes do SAGA usando solicitação/resposta assíncrona. Essa classe acompanha o processo e envia mensagens de comando aos participantes do SAGA, como Serviço de Cozinha e Serviço ao Consumidor.
A classe lê mensagens de resposta de seu canal de resposta e, em seguida, determina a próxima etapa, se houver, na saga CreateOrderSaga
O serviço de pedidos primeiro cria um orquestrador SAGA Order e Create Order Depois disso, o fluxo para o caminho feliz é o seguinte:
- O orquestrador SAGA envia um comando para o Serviço do Consumidor.Verify Consumer
- O Serviço de Atendimento ao Consumidor responde com uma mensagem.Consumer Verified
- O orquestrador SAGA envia um comando para o Serviço de Cozinha.Create Ticket
- O Serviço de Cozinha responde com uma mensagem.Ticket Created
- O orquestrador SAGA envia uma mensagem para o Serviço de Contabilidade.Authorize Card
- O Serviço de Contabilidade responde com uma mensagem.Card Authorized
- O orquestrador do SAGA envia um comando para o Serviço de Cozinha.Approve Ticket
- O orquestrador da saga envia um comando para o Serviço de Pedidos.Approve Order
- Observe que, na etapa final, o orquestrador SAGA envia uma mensagem de comando para o Serviço de pedidos, mesmo que seja um componente do Serviço de pedidos. Em princípio, a Saga Criar Pedido poderia aprovar o Pedido atualizando-o diretamente. Mas, para ser consistente, a SAGA trata o Order Service como apenas mais um participante.
Eu entendo que os SAGAs podem ser complexos, mas para aplicações práticas, este exemplo reflete um fluxo de trabalho típico. Meu objetivo é fornecer um cenário realista nesta postagem do blog para melhorar a compreensão das implementações do mundo real.
Orquestração SAGA e mensagens transacionais: Cada etapa de um SAGA baseado em orquestração consiste em um serviço atualizando um banco de dados e publicando uma mensagem. Por exemplo, o Serviço de pedidos persiste um orquestrador de pedidos e um orquestrador Criar saga de pedidos e envia uma mensagem para o primeiro participante do SAGA.
Um participante do SAGA, como o Kitchen Service, lida com uma mensagem de comando atualizando seu banco de dados e enviando uma mensagem de resposta. O Serviço de Pedidos processa a mensagem de resposta do participante atualizando o estado do orquestrador do SAGA e enviando uma mensagem de comando para o próximo participante do SAGA.
Um serviço deve usar mensagens transacionais para atualizar atomicamente o banco de dados e publicar mensagens.
Vantagens e desvantagens dos SAGAs baseados em orquestração Os SAGAs baseados em orquestração têm vários benefícios:
-
Dependências mais simples — Um benefício da orquestração é que ela não introduz dependências cíclicas. O orquestrador do SAGA invoca os participantes do SAGA, mas os participantes não invocam o orquestrador. Como resultado, o orquestrador depende dos participantes, mas não vice-versa e, portanto, não há dependências cíclicas.
-
Acoplamento de perda — Cada serviço implementa uma API que é invocada pelo orquestrador, portanto, não precisa saber sobre os eventos publicados pelos participantes do SAGA.
-
Melhora a separação de preocupações e simplifica a lógica de negócios — A lógica de coordenação do SAGA está localizada no orquestrador do SAGA. Os objetos de domínio são mais simples e não têm conhecimento dos SAGAs dos quais participam. Por exemplo, ao usar orquestração, a classe Order não tem conhecimento de nenhum dos SAGAs, portanto, tem um modelo de máquina de estado mais simples. Durante a execução da SAGA Create Order, ela faz a transição direta do estado para o estado. A classe Order não tem nenhum estado intermediário correspondente às etapas do SAGA. Como resultado, o negócio é muito mais simples.APPROVAL_PENDINGAPPROVED
-
A orquestração também tem uma desvantagem: o risco de centralizar muita lógica de negócios no orquestrador. Isso resulta em um design em que o orquestrador inteligente informa aos serviços burros quais operações fazer. Felizmente, você pode evitar esse problema projetando orquestradores que são os únicos responsáveis pelo sequenciamento e não contêm nenhuma outra lógica de negócios.
Lidando com a falta de isolamento: O in ACID significa isolamento. A propriedade de isolamento das transações ACID garante que o resultado da execução simultânea de várias transações seja o mesmo como se elas fossem executadas em alguma ordem serial.I
O banco de dados fornece a ilusão de que cada transação ACID tem acesso exclusivo aos dados. O isolamento facilita muito a escrita de lógica de negócios que é executada simultaneamente.
O desafio de usar SAGAs é que eles não têm a propriedade de isolamento das transações ACID. Isso ocorre porque as atualizações feitas por cada uma das transações locais de uma SAGA são imediatamente visíveis para outras SAGAs assim que a transação é confirmada.
Esse comportamento pode causar dois problemas:
Primeiro, outros SAGAs podem alterar os dados acessados pelo SAGA enquanto ele está em execução. Os outros SAGAs podem ler seus dados antes que o SAGA conclua suas atualizações e, consequentemente, podem ser expostos a dados inconsistentes.
Você pode, de fato, considerar uma SAGA como ACD:
- Atomicidade — A implementação do SAGA garante que todas as transações sejam executadas ou que todas as alterações sejam desfeitas.
- Consistência — A integridade referencial dentro de um serviço é tratada por bancos de dados locais. A integridade referencial entre os serviços é tratada pelos serviços.
- Durabilidade — Manipulado por bancos de dados locais.
Essa falta de isolamento potencialmente causa o que a literatura de banco de dados chama de anomalias.
An é quando uma transação lê ou grava dados de uma forma que não faria se as transações fossem executadas uma de cada vez. Quando ocorre uma anomalia, o resultado da execução simultânea de SAGAs é diferente do que se fossem executadas em série.anomaly
A seguir, discutimos um conjunto de estratégias de design SAGA que lidam com a falta de isolamento, essas estratégias são conhecidas como Algumas contramedidas implementam isolamento no nível do aplicativo. Outras contramedidas reduzem o risco comercial da falta de isolamento.countermeasures
Usando contramedidas, você pode escrever uma lógica de negócios baseada em SAGA que funcione corretamente.
Visão geral das anomalias A falta de isolamento pode causar as três anomalias a seguir:
Atualizações perdidas — Uma SAGA substitui sem ler as alterações feitas por outra saga. Leituras sujas — Uma transação ou uma SAGA lê as atualizações feitas por uma saga que ainda não concluiu essas atualizações. Leituras difusas/não repetíveis — Duas etapas diferentes de um SAGA leem os mesmos dados e obtêm resultados diferentes porque outro SAGA fez atualizações. Todas as três anomalias podem ocorrer, mas as duas primeiras são as mais comuns e as mais desafiadoras. Vamos dar uma olhada nesses dois tipos de anomalia, começando com atualizações perdidas.
ATUALIZAÇÕES PERDIDAS Uma anomalia de atualização perdida ocorre quando um SAGA substitui uma atualização feita por outro SAGA.
Considere, por exemplo, o seguinte cenário:
A primeira etapa da SAGA Criar Pedido cria um Pedido. Enquanto essa SAGA estiver em execução, a SAGA Cancelar Ordem cancelará a Ordem. A etapa final da SAGA Criar Pedido aprova o Pedido. Nesse cenário, a Saga Criar Pedido ignora a atualização feita pela Saga Cancelar Pedido e a substitui. Como resultado, o aplicativo enviará um pedido que o cliente cancelou.
LEITURAS SUJAS Uma leitura suja ocorre quando um SAGA lê dados que estão no meio de serem atualizados por outro SAGA.
Considere, por exemplo, uma versão do aplicativo em que os consumidores têm um limite de crédito. Neste aplicativo, um SAGA que cancela um pedido consiste nas seguintes transações:
Atendimento ao consumidor — Aumente o crédito disponível. Serviço de pedido — Altere o estado do pedido para cancelar. Serviço de entrega — Cancele a entrega. Vamos imaginar um cenário que intercala a execução das SAGAs Cancelar Pedido e Criar Pedido, e a SAGA Cancelar Pedido é revertida porque é tarde demais para cancelar a entrega. É possível que a sequência de transações que invocam o Serviço do Consumidor seja a seguinte:
Cancelar pedido SAGA — Aumente o crédito disponível. Criar SAGA de Pedidos — Reduza o crédito disponível. Cancelar SAGA do pedido — Uma transação de compensação que reduz o crédito disponível. Nesse cenário, o Create Order SAGA faz uma leitura suja do crédito disponível que permite ao consumidor fazer um pedido que exceda seu limite de crédito. É provável que este seja um risco inaceitável para o negócio.
Vejamos como evitar que esse e outros tipos de anomalias afetem um aplicativo.
Contramedidas para lidar com a falta de isolamento O modelo de transação SAGA é ACD e sua falta de isolamento pode resultar em anomalias que fazem com que os aplicativos se comportem mal. É responsabilidade do desenvolvedor escrever SAGAs de uma forma que evite as anomalias ou minimize seu impacto nos negócios. Isso pode parecer uma tarefa assustadora, mas você já viu um exemplo de estratégia que evita anomalias. O uso de estados por uma Ordem, como , é um exemplo de uma dessas estratégias. As SAGAs que atualizam Pedidos, como a SAGA Criar Pedido, começam definindo o estado de um Pedido como . O estado informa a outras transações que a Ordem está sendo atualizada por uma SAGA e deve agir de acordo._PENDINGAPPROVAL_PENDING_PENDING*_PENDING
O uso de estados por uma ordem é um exemplo do que o artigo de 1998 "Propriedades ACID semânticas em multidatabases usando chamadas de procedimento remoto e propagações de atualização" de Lars Frank e Torben U. Zahle chama de contramedida de bloqueio semântico. O artigo descreve como lidar com a falta de isolamento de transações em arquiteturas de vários bancos de dados que não usam transações distribuídas. Muitas de suas ideias são úteis ao projetar SAGAs. Ele descreve um conjunto de contramedidas para lidar com anomalias causadas pela falta de isolamento que evitam uma ou mais anomalias ou minimizam seu impacto nos negócios. As contramedidas descritas por este artigo são as seguintes:*_PENDING
Bloqueio semântico — Um bloqueio no nível do aplicativo. Atualizações comutativas — Projete as operações de atualização para serem executáveis em qualquer ordem. Visão pessimista — Reordene as etapas de uma saga para minimizar o risco comercial. Valor de releitura — Evite gravações sujas relendo os dados para verificar se eles não foram alterados antes de substituí-los. Arquivo de versão — Registre as atualizações em um registro para que possam ser reordenadas. Por valor — Use o risco comercial de cada solicitação para selecionar dinamicamente o mecanismo de simultaneidade. A estrutura de uma SAGA O artigo de contramedidas mencionado na última seção define um modelo útil para a estrutura de um SAGA. Nesse modelo, mostrado na figura abaixo, um SAGA consiste em três tipos de transações:
Transações compensáveis — Transações que podem ser revertidas usando uma transação de compensação. Transação de pivô — O ponto de ir / não ir em uma saga. Se a transação dinâmica for confirmada, a saga será executada até a conclusão. Uma transação dinâmica pode ser uma transação que não é compensável nem repetível. Como alternativa, pode ser a última transação compensável ou a primeira transação repassível. Transações com pedido — Transações que seguem a transação dinâmica e têm garantia de sucesso.
na ordem de criação SAGA:
As etapas são transações compensáveis.createOrder(), verifyConsumerDetails(), and createTicket() As transações têm transações de compensação que desfazem suas atualizações.createOrder() and createTicket() A transação é somente leitura, portanto, não precisa de uma transação de compensação.verifyConsumerDetails() A transação é a transação pivô desta SAGA. Se o cartão de crédito do consumidor puder ser autorizado, esta SAGA tem garantia de conclusão.authorizeCreditCard() As etapas e são transações que podem ser repetidas que seguem a transação dinâmica.approveTicket()approveOrder() A distinção entre transações compensáveis e transações passíveis de recuperação é especialmente importante. Como você verá, cada tipo de transação desempenha um papel diferente nas contramedidas.
Vejamos agora cada contramedida, começando com a contramedida de bloqueio semântico.
CONTRAMEDIDA: BLOQUEIO SEMÂNTICO Adiciona um bloqueio à linha que estamos criando ou atualizando para que ela possa ser bloqueada de outros consumidores.
Ao usar a contramedida de bloqueio semântico, a transação compensável de um SAGA define um sinalizador em qualquer registro que ele cria ou atualiza.
O sinalizador indica que o registro não é e pode ser alterado.committed
O sinalizador pode ser um bloqueio que impede que outras transações acessem o registro ou um aviso que indica que outras transações devem tratar esse registro com suspeita. É compensado por uma transação recuperável - a SAGA está sendo concluída com sucesso - ou por uma transação de compensação: a saga está sendo revertida.
O campo é um ótimo exemplo de bloqueio semântico. Os estados, como e , implementam um bloqueio semântico. Eles dizem a outros SAGAs que acessam um Pedido que um SAGA está em processo de atualização do Pedido.Order.state*_PENDINGAPPROVAL_PENDINGREVISION_PENDING
Por exemplo, a primeira etapa da SAGA Criar Ordem, que é uma transação compensável, cria uma Ordem em um estado. A etapa final da SAGA Criar pedido, que é uma transação que pode ser corrigida, altera o campo para . Uma transação de compensação altera o campo para .APPROVAL_PENDINGAPPROVEDREJECTED
Gerenciar o bloqueio é apenas metade do problema. Você também precisa decidir caso a caso como uma SAGA deve lidar com um registro que foi bloqueado. Considere, por exemplo, o comando do sistema. Um cliente pode invocar essa operação para cancelar um pedido que está no state.cancelOrder()APPROVAL_PENDING
Existem algumas maneiras diferentes de lidar com esse cenário.
Uma opção é que o comando do sistema falhe e diga ao cliente para tentar novamente mais tarde. O principal benefício dessa abordagem é que ela é simples de implementar. A desvantagem, no entanto, é que isso torna o cliente mais complexo porque precisa implementar a lógica de repetição.cancelOrder() Outra opção é bloquear até que o bloqueio seja liberado.cancelOrder() CONTRAMEDIDA: ATUALIZAÇÕES COMUTATIVAS Projete o SAGA para que possa ser executado em qualquer ordem ~ um exemplo seria um aumento e diminuição de uma conta blanace.
Uma contramedida simples é projetar as operações de atualização para serem comutativas. As operações são se puderem ser executadas em qualquer ordem. As contas e as operações de uma conta são comutativas (se você ignorar os cheques a descoberto). Essa contramedida é útil porque elimina atualizações perdidas.commutativedebit()credit()
Considere, por exemplo, um cenário em que um SAGA precisa ser revertido depois que uma transação compensável debitou (ou creditou) uma conta. A transação de compensação pode simplesmente creditar (ou debitar) a conta para desfazer a atualização. Não há possibilidade de sobrescrever atualizações feitas por outros SAGAs.
CONTRAMEDIDA: VISÃO PESSIMISTA Ele reordena as etapas de um SAGA para minimizar o risco de negócios devido a uma leitura suja.
Considere, por exemplo, o cenário usado anteriormente para descrever a anomalia de leitura suja. Nesse cenário, a SAGA Criar Pedido realizou uma leitura suja do crédito disponível e criou um pedido que excedeu o limite de crédito ao consumidor. Para reduzir o risco de isso acontecer, esta contramedida reordenaria o:Cancel Order SAGA
Serviço de pedido — Altere o estado do pedido para cancelado. Serviço de entrega — Cancele a entrega. Atendimento ao cliente — Aumente o crédito disponível. Nesta versão reordenada do SAGA, o crédito disponível é aumentado em uma transação reutilizável, o que elimina a possibilidade de uma leitura suja.
CONTRAMEDIDA: VALOR DE RELEITURA Um SAGA que usa essa contramedida relê um registro antes de atualizá-lo, verifica se ele não foi alterado e, em seguida, atualiza o registro. Se o registro foi alterado, a saga é abortada e possivelmente reiniciada.
A contramedida de valor de releitura evita atualizações perdidas.
Um SAGA que usa essa contramedida relê um registro antes de atualizá-lo, verifica se ele não foi alterado e, em seguida, atualiza o registro. Se o registro tiver sido alterado, o SAGA será interrompido e possivelmente reiniciado. Essa contramedida é uma forma do padrão Bloqueio Offline Otimista.
Eles podem usar essa contramedida para lidar com o cenário em que o Pedido é cancelado enquanto está em processo de aprovação. A transação que aprova o pedido verifica se o pedido não foi alterado desde que foi criado anteriormente na SAGA. Se não for alterada, a transação aprova o pedido. Mas se a Ordem foi cancelada, a transação aborta a SAGA, o que faz com que suas transações compensadoras sejam executadas.Create Order SAGA
CONTRAMEDIDA: ARQUIVO DE VERSÃO Ele registra as operações que são executadas em um registro para que possa executá-las em uma ordem.
A contramedida é assim chamada porque registra as operações executadas em um registro para que ele possa reordená-las. É uma maneira de transformar operações não comutativas em operações comutativas.version file
Para ver como essa contramedida funciona, considere um cenário em que o executa simultaneamente com um . A menos que as sagas usem a contramedida de bloqueio semântico, é possível que o cancele a autorização do cartão de crédito do consumidor antes que a Saga Criar Pedido autorize o cartão.Create Order SAGACancel Order SAGACancel Order SAGA
Uma maneira de o Serviço de Contabilidade lidar com essas solicitações fora de ordem é registrar as operações à medida que elas chegam e executá-las na ordem correta. Nesse cenário, ele registraria primeiro a solicitação de Cancelamento de Autorização. Então, quando o Serviço de Contabilidade receber a solicitação de Autorização de Cartão subsequente, ele perceberá que já recebeu a solicitação de Autorização de Cancelamento e ignorará a autorização do cartão de crédito.
CONTRAMEDIDA: POR VALOR É uma estratégia para selecionar mecanismos de simultaneidade com base no risco comercial. usa as propriedades de cada solicitação para decidir entre usar sagas e transações distribuídas
A contramedida final é a contramedida. É uma estratégia para selecionar mecanismos de simultaneidade com base no risco comercial. Um aplicativo que usa essa contramedida usa as propriedades de cada solicitação para decidir entre usar SAGAs e transações distribuídas. Ele executa solicitações de baixo risco usando SAGAs, talvez aplicando as contramedidas descritas na seção anterior. Mas executa solicitações de alto risco envolvendo, por exemplo, grandes quantias de dinheiro, usando transações distribuídas.by value
Essa estratégia permite que um aplicativo faça concessões dinamicamente sobre risco de negócios, disponibilidade e escalabilidade.
É provável que você precise usar uma ou mais dessas contramedidas ao implementar SAGAs em seu aplicativo.
Long-Running Transactions (LRTs) são transações que se estendem por um longo período e envolvem múltiplas operações distribuídas, possivelmente em diferentes serviços ou sistemas. Elas não podem ser tratadas com as técnicas tradicionais de transações ACID (Atomicidade, Consistência, Isolamento, Durabilidade) devido à natureza distribuída e à necessidade de alto desempenho e disponibilidade.
Características do Padrão Saga:
-
Sequência de Passos: Uma Saga é composta por uma sequência de transações locais, cada uma executada por um serviço diferente. Cada transação local é atômica e independente, mas juntas elas formam uma unidade lógica de trabalho.
-
Compensação: Caso alguma transação dentro da Saga falhe, é necessário desfazer (ou compensar) as transações que já foram concluídas para manter a consistência do sistema. Isso é feito através de transações de compensação, que são essencialmente o inverso das operações realizadas.
-
Coordenação: A coordenação das transações dentro de uma Saga pode ser feita de duas maneiras: Coreografia ou Orquestração.
Coordenação de Sagas: Na coreografia (Choreography), não há um coordenador central. Cada serviço sabe o que fazer após completar sua transação local e publica um evento que desencadeia a próxima etapa.
- Vantagens:
- Alta descentralização e independência entre serviços.
- Evita o ponto único de falha.
- Desvantagens:
- Pode ser difícil de gerenciar e depurar devido à complexidade e falta de visibilidade central.
- Pode levar a dependências cíclicas e aumento do acoplamento entre serviços.
Exemplo de Coreografia:
- Serviço A realiza sua transação e publica um evento.
- Serviço B escuta o evento do Serviço A, realiza sua transação e publica um novo evento.
- Serviço C escuta o evento do Serviço B e realiza sua transação, e assim por diante.
Na orquestração (orchestration), um serviço central (o orquestrador) coordena a execução das transações da Saga. O orquestrador chama cada serviço em sequência e gerencia as compensações em caso de falhas.
-
Vantagens:
- Visibilidade central e controle do fluxo da transação.
- Simplicidade na gestão e depuração das transações.
-
Desvantagens:
- Introduz um ponto único de falha e potencial gargalo no sistema.
- Reduz a independência dos serviços.
Exemplo de Orquestração:
- O Orquestrador inicia a transação chamando o Serviço A.
- Após a conclusão do Serviço A, o Orquestrador chama o Serviço B.
- Após a conclusão do Serviço B, o Orquestrador chama o Serviço C, e assim por diante.
- Se o Serviço B falhar, o Orquestrador chama as transações de compensação necessárias para desfazer as operações dos serviços anteriores.
Exemplos de Aplicação do Padrão Saga:
-
Processamento de Pedidos em E-commerce:
- Passos:
- Serviço de criação de pedido cria um pedido.
- Serviço de pagamento processa o pagamento.
- Serviço de inventário reserva os produtos.
- Serviço de envio organiza a entrega.
- Compensação: Se o serviço de envio falhar, desfaz-se a reserva no inventário, o pagamento é revertido, e o pedido é cancelado.
- Passos:
-
Cadastro de Novo Usuário:
- Passos:
- Serviço de autenticação cria as credenciais do usuário.
- Serviço de perfil cria o perfil do usuário.
- Serviço de notificações envia um e-mail de boas-vindas.
- Compensação: Se o serviço de perfil falhar, as credenciais são removidas.
- Passos:
Se você estiver trabalhando em um microsserviço Java ou se preparando para uma entrevista de desenvolvedor Java em que as habilidades de microsserviço são necessárias, você deve se preparar sobre o padrão SAGA.
SAGA é um padrão de microsserviço essencial que visa resolver o problema de transações de longa duração na arquitetura de microsserviços. É também uma das perguntas populares da entrevista de microsserviço, frequentemente feita a desenvolvedores experientes.
Como a arquitetura de microsserviço divide seu aplicativo em vários aplicativos pequenos, uma única solicitação também é dividida em várias solicitações e há uma chance de que algumas partes das solicitações sejam bem-sucedidas e algumas partes falhem, nesse caso, é difícil manter a consistência dos dados.
Se você estiver lidando com dados reais, como fazer um pedido na Amazon, deverá lidar com esse cenário normalmente para que, se o pagamento falhar, o estoque volte ao seu estado original e o pedido não seja enviado.
Neste artigo, vou explicar O que é o padrão SAGA? O que ele faz, qual problema ele resolve, bem como prós e contras do padrão SAGA em uma arquitetura de microsserviço.
A propósito, se você está se preparando para entrevistas com desenvolvedores Java, também pode ver meus artigos anteriores, como 25 perguntas avançadas sobre Java, 25 perguntas sobre Spring Framework, 20 consultas SQL de entrevistas, 50 perguntas sobre microsserviços, 60 perguntas sobre estrutura de dados em árvore, 15 perguntas sobre design de sistema e 35 perguntas sobre Core Java.
E, se você gosta das minhas postagens, considere assinar meu boletim informativo, é GRATUITO e você não postará nenhuma das minhas postagens
O que é o padrão de design da SAGA? Que problema resolve? O padrão SAGA (ou Saga) é um padrão de design de microsserviço para gerenciar a consistência de dados em sistemas distribuídos.
Ele fornece uma maneira de lidar com transações de longa duração compostas por várias etapas, em que cada etapa é uma operação de banco de dados separada. A ideia principal é capturar todas as etapas da transação em um banco de dados para que, em caso de falha, o sistema possa reverter a transação ao seu estado inicial.
O padrão SAGA resolve o problema de manter a consistência dos dados em um sistema distribuído, onde é difícil garantir que todas as operações em uma transação sejam executadas atomicamente, especialmente em caso de falhas.
Um dos exemplos populares do padrão SAGA é uma transação de comércio eletrônico, como fazer um pedido na Amazon ou Flipkart, onde um pedido é feito, o pagamento é deduzido da conta do cliente e os itens são reservados no estoque. Se alguma dessas etapas falhar, as etapas anteriores serão revertidas para garantir a consistência. Por exemplo, se o pagamento falhar, a reserva de itens é cancelada.
O padrão SAGA resolve o problema de manter a consistência em uma transação envolvendo várias etapas que podem ou não ser bem-sucedidas.
Aqui está outro diagrama de arquitetura de microsserviço para demonstrar como o padrão SAGA funciona:
Prós e contras do padrão de design SAGA na arquitetura de microsserviços Sempre que aprendemos um padrão, devemos aprender seus prós e contras, pois isso nos ajuda a entender melhor os padrões e também nos ajuda a decidir quando usá-los em seu aplicativo:
Aqui estão algumas vantagens e desvantagens do padrão SAGA no Microsserviço:
Vantagens: Aqui estão algumas vantagens de usar o padrão SAGA Design na arquitetura de microsserviços:
- É fácil implementar transações complexas em vários microsserviços.
- Lida com falhas normalmente e garante a consistência dos dados.
- Aumenta a resiliência e a robustez do sistema.
- Evita inconsistências de dados e atualizações perdidas.
- Fornece um processo claro e bem definido para compensar transações.
Desvantagens: Aqui estão algumas desvantagens de usar o padrão SAGA Design na arquitetura de microsserviços:
- É difícil de implementar e manter, também é difícil de monitorar e depurar
- Você terá a sobrecarga de armazenar e gerenciar o estado das sagas.
- Ele também vem com sobrecarga de desempenho devido à necessidade de gerenciar transações em vários microsserviços.
- Seu aplicativo também sofrerá com o aumento da latência devido à necessidade de várias viagens de ida e volta entre microsserviços.
- Não há padronização na implementação de sagas em diferentes microsserviços. Seria melhor se frameworks como Spring Cloud ou Quarks suportassem nativamente esse padrão no futuro.
Como implementar o padrão SAGA em uma arquitetura de microsserviço? O padrão SAGA pode ser implementado em uma arquitetura de microsserviços, dividindo uma transação de negócios complexa em várias etapas ou serviços menores e independentes.
- Cada etapa se comunicaria com seu microsserviço correspondente para concluir uma parte da transação.
- Se alguma etapa falhar, o sistema iniciará uma transação de compensação para desfazer as etapas anteriores.
- A coordenação dessas etapas pode ser obtida usando um banco de dados, fila de mensagens ou serviço de coordenação para armazenar o estado da transação e disparar transações de compensação.
Dessa forma, o sistema pode garantir a consistência eventual e lidar com falhas normalmente.
Se você está se perguntando se algum framework Java Microservice pode fornecer suporte para o padrão SAGA? Então, infelizmente, não há uma estrutura de microsserviço específica que forneça suporte direto para o padrão SAGA.
No entanto, você pode implementar o SAGA Pattern usando bibliotecas e estruturas como Apache Camel ou Spring integration, juntamente com tecnologias como Apache Kafka, fornecimento de eventos e arquitetura orientada a mensagens.
Material de preparação para entrevistas Java e Spring - Antes de qualquer entrevista com desenvolvedores Java e Spring, eu sempre costumo ler os recursos abaixo:
Important
Entrevista Grokking the Java. Eu pessoalmente comprei esses livros para acelerar minha preparação.
Atualmente, os sistemas são frequentemente distribuídos. Isso reflete a necessidade de extensibilidade, escalabilidade e resiliência. Engenheiros e arquitetos estão explorando mais estilos de arquitetura para alcançar esses objetivos. Microsserviços é uma opção. CQRS é outra. EDA também.
Em CQRS, precisamos de sincronização de consistência entre o modelo de leitura e o de escrita, usando um barramento de eventos e implementando um padrão de projeto observador. EDA busca a assincronia e a consistência eventual entre os componentes de um sistema. Em CQRS, precisamos implementar o padrão de coreografia SAGA para garantir a consistência eventual entre os modelos de leitura e escrita. Com EDA, é necessário fornecer um meio para que os componentes se comuniquem entre si. Quando um evento ocorre em um componente, ele é publicado para que outros componentes possam reagir a ele. Esse é o padrão de projeto observador.
Como Halo no Xbox Escalou para 10+ Milhões de Jogadores Usando o Padrão Saga?
Warning
Aviso: Os detalhes deste post foram derivados dos artigos/vídeos compartilhados online pela equipe de engenharia do Halo. Todo o crédito pelos detalhes técnicos vai para a equipe de engenharia do Halo/343. Os links para os artigos e vídeos originais estão presentes na seção de referências ao final do post. Tentamos analisar os detalhes e dar nossa opinião sobre eles. Se você encontrar alguma imprecisão ou omissão, por favor, deixe um comentário e faremos o possível para corrigi-las.
No mundo atual de aplicações em larga escala, seja em jogos, redes sociais ou compras online, construir sistemas confiáveis é uma tarefa difícil. À medida que as aplicações crescem, elas frequentemente passam do uso de um único banco de dados centralizado para serem distribuídas por muitos serviços menores e sistemas de armazenamento. Essa mudança, embora necessária para lidar com mais usuários e dados, traz um conjunto totalmente novo de desafios, especialmente em relação à consistência e ao manejo das transações.
Em sistemas tradicionais, se quiséssemos atualizar múltiplos dados (por exemplo, salvar um novo pedido de cliente e reduzir o estoque), poderíamos facilmente contar com uma transação. Uma transação garantiria que todas as atualizações tenham sucesso juntas ou que nenhuma delas aconteça.
No entanto, em sistemas distribuídos, não existe mais apenas um banco de dados para se comunicar. Podemos ter serviços diferentes, cada um gerenciando seus dados em locais distintos. Cada um pode estar rodando em servidores diferentes, provedores de nuvem ou até mesmo continentes diferentes. De repente, conseguir que todos concordem ao mesmo tempo fica muito mais difícil. Falhas de rede, falhas de serviço e inconsistências agora são situações do dia a dia.
Isso cria um grande problema: como mantemos um comportamento correto e confiável quando não podemos mais depender de transações tradicionais? Se estamos reservando uma viagem, não queremos acabar com reserva de hotel e sem voo. Se estamos atualizando as estatísticas de um jogador em um jogo, não podemos nos dar ao luxo de que algumas estatísticas sejam atualizadas e outras desapareçam.
Os engenheiros precisam encontrar novas formas de coordenar operações entre múltiplos sistemas independentes para enfrentar essas questões. Um padrão poderoso para resolver esse problema é o Padrão Saga, uma técnica originalmente proposta no final dos anos 1980, mas cada vez mais relevante hoje. Neste artigo, vamos analisar como a equipe de engenharia do Halo da 343 Game Studio (agora Halo Studios) usou o padrão Saga para melhorar a experiência do jogador.
Transações ACID: Quando engenheiros projetam sistemas que armazenam e atualizam dados, frequentemente dependem de um conjunto de garantias chamadas propriedades ACID. Essas propriedades garantem que, quando algo muda no sistema, como salvar uma compra ou atualizar as estatísticas de um jogador, isso aconteça de forma segura e previsível.

Aqui está uma rápida análise de cada propriedade.
-
Atomicidade: Atomicidade significa "tudo ou nada". Ou cada etapa de uma transação acontece com sucesso, ou nada disso acontece. Se algo der errado no meio do caminho, o sistema cancela tudo para não ficar preso com um trabalho pela metade. Por exemplo, ou reserve um voo e um hotel juntos, ou nenhum dos dois.
-
Consistência: A consistência garante que os dados do sistema se movam de um estado válido para outro estado válido. Após o término de uma transação, os dados ainda devem seguir todas as regras e restrições que devem seguir. Por exemplo, após comprar um ingresso, o sistema não deve mostrar disponibilidade negativa de assentos. As regras sobre o que é válido são sempre respeitadas.
-
Isolamento: O isolamento garante que as transações não interfiram umas nas outras mesmo que ocorram ao mesmo tempo. Deveria parecer que cada transação acontece uma após a outra, mesmo quando acontecem em paralelo. Por exemplo, se duas pessoas estiverem tentando comprar o último bilhete ao mesmo tempo, apenas uma transação é bem-sucedida.
-
Durabilidade: Durabilidade significa que, uma vez que uma transação é comprometida, ela é permanente. Mesmo que o sistema trave logo depois, o resultado permanece seguro e não será perdido. Por exemplo, se um usuário comprou um ingresso e o aplicativo trava imediatamente depois, o ingresso ainda está reservado e não está perdido no sistema.
Modelo de Banco de Dados Único: Em arquiteturas de sistemas antigas, a forma típica de construir aplicações era ter um único banco de dados SQL grande que atuava como a fonte central de verdade.

Cada parte do aplicativo, seja um jogo como Halo, um site de comércio eletrônico ou um aplicativo bancário, enviaria todos os seus dados para um único lugar.
Veja como funcionava:
Aplicações (como servidores de jogos ou sites) se comunicariam com um serviço sem estado.
Esse serviço sem estado então se comunicaria diretamente com o único banco de dados SQL.
O banco de dados armazenaria tudo: estatísticas dos jogadores, progresso do jogo, inventário, transações financeiras, tudo em um único local centralizado e consistente.
Algumas vantagens do modelo de banco de dados único eram fortes garantias impostas pelas propriedades ACID, simplicidade de desenvolvimento e escalabilidade vertical.
Crise de Escalabilidade de Halo 4 Durante o desenvolvimento de Halo 4, a equipe de engenharia enfrentou desafios de escala sem precedentes que não haviam sido encontrados em títulos anteriores da franquia.
Halo 4 experimentou um nível de engajamento avassalador:
Mais de 1,5 bilhão de jogos foram disputados.
Mais de 11,6 milhões de jogadores únicos se conectaram e competiram online.
Cada partida gerava dados detalhados de telemetria para cada jogador: abates, assistências, mortes, uso de armas, medalhas e várias outras estatísticas relacionadas ao jogo. Essas informações precisavam ser ingeridas, processadas, armazenadas e tornadas acessíveis em múltiplos serviços, tanto para feedback em tempo real no próprio jogo quanto para plataformas externas de análise como o Halo Waypoint.
A complexidade aumentava ainda mais porque uma única partida podia envolver de 1 a 32 jogadores. Para cada sessão de jogo, as estatísticas precisavam ser atualizadas de forma confiável em vários registros de jogadores simultaneamente, preservando a precisão e consistência dos dados.
Inadequação de um Banco de Dados SQL Único Antes de Halo 4, os primeiros capítulos da série dependiam fortemente de um modelo centralizado de banco de dados.
Uma única instância grande do SQL Server operava como fonte canônica da verdade. Os serviços de aplicação interagiriam com esse banco de dados centralizado para ler e escrever todos os dados de jogabilidade, jogadores e partidas, dependendo das garantias embutidas do ACID para garantir a integridade dos dados.
No entanto, a escala exigida por Halo 4 rapidamente revelou limitações sérias nesse modelo:
Limites de Escalonamento Vertical: Embora o banco de dados centralizado pudesse ser escalado verticalmente (adicionando hardware mais potente), havia limites físicos e operacionais inerentes. Além de um certo limite, nenhuma quantidade de memória, potência da CPU ou otimização de armazenamento poderia compensar o volume crescente de leituras e gravações concorrentes.
Ponto único de falha: Depender de uma única instância de banco de dados apresentou um risco operacional crítico. Qualquer tempo de inatividade, corrupção de dados ou saturação de recursos nesse caso pode derrubar serviços essenciais para toda a base de jogadores.
Questões de Contenção e Bloqueios: Com milhões de usuários interagindo simultaneamente com o banco de dados, a disputa por bloqueios e índices tornou-se um gargalo.
Complexidade Operacional da Particionação: O sistema centralizado original não foi projetado para cargas de trabalho particionadas. Introduzir retroativamente sharding ou particionamento em uma estrutura SQL monolítica exigiria grandes reescritas e procedimentos operacionais complexos, criando riscos de inconsistência e instabilidade de serviço.
Descompasso com a Arquitetura Cloud-native: O backend do Halo 4 migrou para a infraestrutura em nuvem do Azure, especificamente usando o Azure Table Storage. Azure Table Storage é um sistema NoSQL que depende inerentemente de armazenamento particionado e oferece consistência eventual. O antigo modelo de consistência transacional em um único banco de dados não se alinhava com esse ambiente particionado e distribuído.
Diante desses desafios, a equipe de engenharia reconheceu que continuar confiando em um banco de dados SQL monolítico limitaria a escalabilidade e exporia o sistema a níveis inaceitáveis de risco e tempo de inatividade. Uma transição para uma arquitetura distribuída era necessária.
O Padrão Saga teve origem em um artigo de pesquisa publicado em 1987 por Hector Garcia-Molina e Kenneth Salem na Universidade de Princeton. A pesquisa abordou um problema crítico: como lidar com transações de longa duração em sistemas de banco de dados.
Na época, as transações tradicionais eram projetadas para serem operações de curta duração, bloqueando recursos por um período mínimo para manter as garantias do ACID. No entanto, algumas operações, como gerar um extrato bancário complexo, processar grandes conjuntos de dados históricos ou conciliar fluxos de trabalho financeiros em múltiplas etapas, exigem manter bloqueios por períodos prolongados. Essas transações de longa duração criaram gargalos ao imobilizar recursos, reduzir a concorrência do sistema e aumentar o risco de falha.
O Padrão Saga resolve essas questões das seguintes maneiras:
-
Uma única operação lógica é dividida em uma sequência de subtransações menores.
-
Cada subtransação é executada de forma independente e faz commit imediatamente com suas alterações.
-
Se todas as subtransações forem bem-sucedidas, a Saga como um todo é considerada bem-sucedida.
-
Se alguma subtransação falhar, as transações compensatórias são executadas em ordem inversa para desfazer as alterações das subtransações previamente concluídas.
Veja o diagrama abaixo que mostra um exemplo desse padrão:

Os principais pontos técnicos sobre as Sagas são os seguintes:
-
Subtransações devem ser independentes: A execução bem-sucedida de uma subtransação não deve depender diretamente do resultado de outra. Essa independência permite uma melhor concorrência e evita falhas em cascata.
-
Transações compensatórias são necessárias: Para cada subtransação, uma ação compensatória correspondente deve ser definida. Essas transações compensatórias "desfazem" semanticamente o efeito de suas operações associadas. No entanto, o sistema pode nem sempre conseguir retornar ao estado anterior exato; em vez disso, visa uma recuperação semanticamente consistente.
-
A atomicidade é enfraquecida: Diferente das transações tradicionais, onde atualizações parciais nunca são visíveis, em uma Saga, estados intermediários são visíveis para outras partes do sistema. Resultados parciais podem existir temporariamente até que a sequência completa seja concluída ou até que uma falha desencadeie o rollback por compensação.
-
A consistência é preservada por meio da lógica de negócios: em vez de depender de garantias transacionais em nível de banco de dados, as Sagas mantêm consistência em nível de aplicação garantindo que, após todas as subtransações e compensações, o sistema permaneça em um estado válido e coerente.
-
O gerenciamento de falhas está incorporado: as Sagas tratam falhas como parte esperada da operação do sistema. O padrão oferece uma forma estruturada de lidar com erros e manter a resiliência sem assumir confiabilidade perfeita.
Modelos de Execução Saga: Os principais aspectos do modelo de execução do Saga são os seguintes:
Execução de Banco de Dados Único: Quando o Saga Pattern foi introduzido pela primeira vez, ele foi projetado para operar dentro de um único sistema de banco de dados. Nesse ambiente, executar uma saga requer dois componentes principais:
1 - Coordenador de Execução de Sagas (SEC) O Coordenador de Execução Saga é um processo que orquestra a execução de todas as subtransações na sequência correta. É responsável por:
- Iniciando a saga
- Executando cada subtransação uma após a outra
- Monitorando o sucesso ou fracasso de cada subtransação
- Acionando transações compensatórias caso algo dê errado
A SEC garante que a saga progredia corretamente, sem necessidade de coordenação distribuída, pois tudo está acontecendo dentro do mesmo sistema de banco de dados.

2 - Saga Log O Diário da Saga funciona como um registro duradouro de tudo o que acontece durante a execução de uma saga. Todo evento importante, iniciando uma saga, iniciando uma subtransação, completando uma subtransação, iniciando uma transação compensatória, concluindo uma transação compensatória, encerrando uma saga, é escrito no log.
O Saga Log garante que, mesmo que a SEC trave durante a execução, o sistema pode se recuperar ao reproduzir os eventos registrados no log. Isso proporciona durabilidade e recuperação sem depender do tradicional bloqueio de transações em toda a saga.
Manuseio de Falhas Lidar com falhas em uma saga de banco de dados único depende de uma estratégia chamada recuperação reversa.
Isso significa que, se qualquer subtransação falhar durante a execução da saga, o sistema deve reverter executando transações compensatórias para todas as subtransações que já foram concluídas com sucesso.
Veja como o processo funciona:
Detecção de Falha: A SEC detecta que uma subtransação falhou porque a operação do banco de dados retorna um erro ou viola uma regra de negócio.
Registro do Aborto: A SEC grava um evento de abortar no Saga Log, marcando que o caminho de execução direta foi abandonado.
Compensações iniciais: A SEC lê o Saga Log para determinar quais subtransações foram concluídas. Em seguida, começa a executar as transações compensatórias correspondentes na ordem inversa.
Completando o Rollback: Cada transação compensatória é registrada no Saga Log à medida que começa e se conclui.
Após todas as compensações necessárias serem aplicadas com sucesso, a saga é formalmente marcada como abortada no registro.
Serviço de Estatísticas de Halo 4 Aqui estão os componentes-chave de como Halo usou o Padrão Saga:
Arquitetura de Serviços: O serviço de estatísticas de Halo 4 foi criado para lidar com grandes volumes de dados de jogadores gerados durante e após cada jogo. A arquitetura utilizava uma combinação de armazenamento baseado em nuvem e modelos de programação baseados em atores para gerenciar essa complexidade de forma eficaz.

A arquitetura de serviço incluía os seguintes componentes principais:
Azure Table Storage: Todos os dados persistentes do jogador eram armazenados no Azure Table Storage, um armazenamento de chave-valor NoSQL. Os dados de cada jogador eram atribuídos a uma partição separada, permitindo leituras e gravações altamente paralelas sem um único gargalo centralizado.
Modelo de Ator de Orleans: A equipe adotou o framework Orleans da Microsoft, que é baseado no modelo de ator. Atores (chamados de "grãos" em Orleans) representavam diferentes unidades lógicas no sistema.
Game Grains cuidava da agregação das estatísticas de uma sessão de jogo.
Os Grãos dos Jogadores eram responsáveis por persistir as estatísticas de cada jogador. No sistema backend de Halo 4, um Player Grain é uma unidade lógica que representa os dados e o comportamento de um único jogador dentro da aplicação do lado do servidor.
Azure Service Bus: O Azure Service Bus era usado como uma fila de mensagens e um log distribuído e duradouro. Quando um novo jogo é concluído, uma mensagem contendo a carga útil de estatísticas é publicada no Service Bus. Isso serviu como o início de uma saga.
Serviços de Frontend Sem Estado: Esses serviços aceitavam estatísticas brutas dos clientes Xbox, as publicavam no Service Bus e acionavam os pipelines de processamento da saga.
A separação em grãos de jogo e de jogadores, combinada com armazenamento distribuído em nuvem, forneceu uma base escalável capaz de processar milhares de jogos simultâneos e milhões de atualizações simultâneas de jogadores.
Aplicação da Saga A equipe aplicou o Padrão Saga para gerenciar as atualizações complexas necessárias para as estatísticas dos jogadores em múltiplas partições.
A sequência típica era:
Agregação: Após o término de uma sessão de jogo, o Game Grain agregava estatísticas dos jogadores participantes.
Iniciação da Saga: Uma mensagem foi registrada no Azure Service Bus indicando o início de uma saga para atualizar estatísticas daquele jogo.
Subsolicitações para os Grãos do Jogador: Para cada jogador no jogo (até 32), o Grão do Jogo enviava solicitações individuais de atualização para seus Graãos de Jogador correspondentes. Cada Grão de Jogador então atualizava as estatísticas de seu jogador no Azure Table Storage.
Registro do Progresso: Atualizações bem-sucedidas e quaisquer erros eram registrados pelo sistema de mensagens durável, garantindo que nenhum estado fosse perdido mesmo que um processo travasse.
Conclusão ou Falha: Se todas as atualizações dos jogadores tivessem sucesso, a saga era considerada concluída. Se alguma atualização do jogador falhasse (por exemplo, devido a um problema temporário de armazenamento no Azure), a saga não seria revertida, mas passaria para uma fase de recuperação para frente.
Por meio dessa estrutura, a equipe podia garantir que as atualizações fossem processadas independentemente por jogador, sem depender das transações tradicionais ACID em todas as partições dos jogadores.

Estratégia de Recuperação Avançada Em vez de usar a recuperação retroativa tradicional (reverter subtransações completas), a equipe de Halo 4 implementou a recuperação avançada para suas sagas estatísticas.
As principais razões para escolher a recuperação para frente são as seguintes:
Experiência do Usuário: Jogadores que tiveram suas estatísticas atualizadas com sucesso não devem ver essas estatísticas desaparecerem de repente caso ocorra um retrocesso. Reverter dados visíveis e processados com sucesso criaria uma experiência confusa e ruim.
Eficiência Operacional: Retentar apenas as atualizações falhadas do jogador foi mais eficiente do que desfazer escritas bem-sucedidas e reiniciar todo o processamento do jogo.
Veja como funciona a recuperação para frente:
Se um Player Grain não atualizasse suas estatísticas (por exemplo, devido à indisponibilidade da partição de armazenamento ou esgotamento de cotas), o sistema registrava a falha, mas não desfazia nenhuma atualização bem-sucedida já concluída para outros jogadores.
A atualização falhada foi colocada na fila para uma tentativa novamente usando uma estratégia de recuo. Isso permitia tempo para resolver problemas temporários sem sobrecarregar o sistema de armazenamento com tentativas agressivas.
Atualizações retentadas eram necessárias para serem idempotentes. Ou seja, repetir a operação de atualização não resultaria em estatísticas duplicadas ou corrupção. Isso foi alcançado confiando em operações de banco de dados que aplicavam com segurança mudanças incrementais ou sobrescreviam campos conforme necessário.
Retentativas bem-sucedidas eventualmente traziam todos os recordes dos jogadores para um estado consistente, mesmo que levasse minutos ou horas após o término da sessão original do jogo.
Ao usar recuperação direta e projetar para idempotência, o backend do Halo 4 conseguiu alcançar alta disponibilidade.
Conclusão À medida que os sistemas crescem para suportar milhões de usuários, modelos tradicionais de banco de dados que dependem de transações centralizadas e fortes garantias ACID começam a falhar.
A experiência da equipe de engenharia de Halo 4 destacou a necessidade urgente de uma nova abordagem: uma que pudesse lidar com uma escala enorme, tolerar falhas com elegância e ainda manter consistência entre os repositórios de dados distribuídos.
O Padrão Saga ofereceu uma solução elegante e prática para esses desafios. Ao decompor operações de longa duração em sequências de subtransações e ações compensatórias, a equipe conseguiu construir um sistema que priorizava disponibilidade, resiliência e correção operacional sem depender de locks distribuídos caros ou protocolos rígidos de coordenação.
As lições aprendidas com esse sistema se aplicam amplamente, não apenas à infraestrutura de jogos, mas a qualquer domínio onde operações distribuídas devem manter confiabilidade em larga escala.


Um Service mesh (malha de serviço) é uma camada de infraestrutura configurável e de baixa latência projetada para lidar com um alto volume de comunicação entre processos baseada na rede entre serviços de infraestrutura de aplicativos usando interfaces de programação de aplicativos (APIs).
Em um service mesh, cada instância do serviço é pareada com uma instância de um servidor de proxy reverso, chamando service proxy, sidecar proxy ou sidecar. A instância do serviço e o proxy sidecar compartilham um container, e o container é gerenciado por uma ferramenta de orquestração de containers como Kubernetes, Nomad, Docker Swarm ou DC/OS. O proxy de serviço é responsável pela comunicação com outras instâncias de serviço e podem suportar capacidades como descoberta de (instância de) serviço, balanceamento de carga, autenticação e autorização, comunicação segura e outras.
Serviços de malha, como Istio, Linkerd e Consul, são implementados como uma camada de infraestrutura entre os microsserviços, facilitando a comunicação e oferecendo um conjunto de funcionalidades padronizadas para lidar com os desafios complexos inerentes a ambientes distribuídos e baseados em microsserviços.
A malha de serviço geralmente é implementada fornecendo uma instância de proxy, chamada sidecar , para cada instância de serviço. Os Sidecars lidam com comunicações, monitoramentos e preocupações relacionadas à segurança entre serviços na verdade, qualquer coisa que possa ser abstraída dos serviços individuais. Dessa forma, os desenvolvedores podem lidar com desenvolvimento, suporte e manutenção do código do aplicativo nos serviços; as equipes de operações podem manter a malha de serviço e executar o aplicativo.
Uma malha de serviços garante que a comunicação entre serviços de infraestrutura de aplicativos em contêiner e muitas vezes efêmeros seja rápida, confiável e segura. A malha fornece recursos críticos, incluindo descoberta de serviços, balanceamento de carga, criptografia, observabilidade, rastreabilidade, autenticação e autorização e suporte para o padrão de circuit braker (disjuntor).
Aqui vou dar ênfase em um service mesh especifico o grande Istio mas existem outros, como o Consul da Hashicorp que vale a pena olhar.
Podemos pensar em um service mesh como um campo de força inteligente e programável que envolve cada microserviço em uma arquitetura distribuída. Vamos explorar essa metáfora em detalhes, porque ela capta perfeitamente a essência do conceito. Imagine que cada microserviço é uma espaçonave ou uma base em um campo de batalha. Sozinha, ela é vulnerável. O service mesh é o campo de força (force field) que a envolve, mas não é um escudo estático e burro. É um sistema de defesa ativo, inteligente e com consciência situacional.
Basicamente, são uma arquitetura de rede utilizada em ambientes de microsserviços para gerenciar a comunicação entre esses serviços de forma mais segura, confiável e controlada.
A principal função dos serviços de malha é oferecer um conjunto de capacidades para facilitar e controlar a comunicação entre os microsserviços em uma aplicação distribuída. Alguns dos principais objetivos e funcionalidades incluem:
-
Descoberta de Serviços: Ajudam os microsserviços a descobrirem e se comunicarem entre si, independentemente de onde estão hospedados na rede.
-
Roteamento e Balanceamento de Carga: Direcionam o tráfego entre os serviços de maneira inteligente, distribuindo as requisições de forma equilibrada para garantir um desempenho otimizado e evitar sobrecargas em um único serviço.
-
Segurança na Comunicação: Implementam medidas de segurança, como criptografia de ponta a ponta e autenticação, para garantir a confidencialidade e integridade dos dados durante a comunicação entre os serviços.
-
Monitoramento e Observabilidade: Oferecem ferramentas para monitorar o tráfego entre os serviços, coletando métricas e informações que podem ser utilizadas para análise, solução de problemas e otimização da rede.
-
Controle de Tráfego e Políticas de Acesso: Permitem definir políticas de acesso, regras de autorização, limites de tráfego e outras políticas para controlar o comportamento da rede.


O Envoy é um proxy L7 (camada de aplicação) de alto desempenho, open source, projetado para arquiteturas modernas baseadas em microsserviços e ambientes cloud-native. Ele foi criado originalmente pela Lyft para resolver problemas de comunicação entre serviços distribuídos e hoje é um dos componentes centrais de muitas plataformas modernas, sendo amplamente adotado em conjunto com service meshes como o Istio.
Em arquiteturas de microsserviços, dezenas ou centenas de serviços precisam se comunicar entre si de forma confiável, segura e observável. Essa comunicação envolve descoberta de serviços, balanceamento de carga, retries automáticos, controle de timeout, circuit breaking, autenticação mTLS, métricas, tracing distribuído e muito mais. Implementar tudo isso dentro de cada serviço seria complexo e repetitivo. O Envoy resolve esse problema atuando como um proxy intermediário que gerencia toda a comunicação de rede entre serviços.
Ele pode funcionar como sidecar proxy, ou seja, rodando ao lado de cada microsserviço dentro de um container ou pod, interceptando todo o tráfego de entrada e saída. Nesse modelo, o serviço não precisa saber nada sobre balanceamento, segurança ou telemetria — o Envoy assume essas responsabilidades. Isso é a base do conceito de service mesh, onde a malha de comunicação é abstraída da lógica de negócio.
O Envoy opera principalmente na camada 7 (HTTP/HTTPS, gRPC), mas também suporta camada 4 (TCP). Ele entende protocolos modernos, consegue fazer roteamento inteligente baseado em headers, versionamento de API, A/B testing e canary releases. Por exemplo, é possível direcionar 5% do tráfego para uma nova versão de um serviço e monitorar o comportamento antes de liberar totalmente.
Outro ponto forte é a observabilidade. O Envoy gera métricas detalhadas, logs estruturados e integra facilmente com sistemas de tracing distribuído. Isso permite entender latência entre serviços, identificar gargalos e diagnosticar falhas com precisão em sistemas altamente distribuídos.
Em termos de resiliência, ele implementa padrões como circuit breaker (para evitar efeito cascata quando um serviço falha), retries automáticos configuráveis e rate limiting. Isso aumenta significativamente a estabilidade do sistema sob carga ou falhas parciais.
Arquiteturalmente, o Envoy é altamente performático, escrito em C++, com modelo assíncrono e orientado a eventos, capaz de lidar com milhares de conexões simultâneas com baixa latência. Ele também suporta configuração dinâmica via APIs (xDS), permitindo que sua configuração seja atualizada em tempo real sem reiniciar o proxy.
Em resumo, o Envoy é uma peça fundamental na infraestrutura moderna de microsserviços. Ele abstrai complexidade de rede, centraliza políticas de segurança e tráfego, melhora observabilidade e aumenta resiliência, permitindo que desenvolvedores foquem na lógica de negócio enquanto a comunicação distribuída é tratada de forma padronizada e escalável.
Qual é a jornada de uma mensagem do Slack? Em um artigo técnico recente, o Slack explica como funciona sua estrutura de mensagens em tempo real. Aqui está meu resumo curto:

Como há muitos canais, o Channel Server (CS) usa hashing consistente para alocar milhões de canais a muitos servidores de canais.
As mensagens do Slack são entregues via WebApp e Admin Server para o Channel Server correto.
Por meio do Gate Server e do Envoy (um proxy), o Channel Server enviará mensagens para os receptores de mensagens.
Receptores de mensagens usam WebSocket, que é um mecanismo de mensagens bidirecional, permitindo receber atualizações em tempo real.
Uma mensagem do Slack passa por cinco servidores importantes:
-
WebApp: defina a API que um cliente Slack poderia usar
-
Servidor de Administração (AS): encontre o Servidor de Canal correto usando o ID do canal
-
Servidor de Canal (CS): manter o histórico do canal de mensagens
-
Servidor Gateway (GS): implantado em cada região geográfica. Manter a assinatura do canal WebSocket
-
Envoy: proxy de serviço para aplicações nativas em nuvem
Agora é com você: Os servidores de canal podem cair. Como eles usam hashing consistente, como poderiam se recuperar?
Embora a tendência do setor seja dividir seu aplicativo monolítico em microsserviços para segregar dados, código e interface, não é uma tarefa fácil de fazer. Especialmente se você não tiver nenhuma experiência no desenvolvimento de microsserviços e não estiver familiarizado com as práticas recomendadas e os padrões e princípios essenciais de design de microsserviços.
Gostando de Padrões de Design Orientados a Objetos, os Padrões de Microsserviços também são soluções testadas e comprovadas para problemas comuns que as pessoas encontraram ao desenvolver, implantar e dimensionar seus Microsserviços.
Por exemplo, o padrão SAGA resolve o problema de falhas de transação distribuída e o gateway de API facilita o código do lado do cliente e também atua como um controlador frontal e balanceador de carga para muitos de seus microsserviços, tornando-os mais fáceis de manter.
Você está lutando para acompanhar seu número crescente de microsserviços? Não se preocupe mais! O padrão Service Discovery (descoberta de serviço) está aqui para ajudá-lo a navegar no mundo complexo dos microsserviços com facilidade. Esse padrão permite que os serviços se encontrem dinamicamente, garantindo uma comunicação suave e reduzindo a necessidade de configuração manual. Padrão de descoberta de serviço: navegando no labirinto de microsserviços com facilidade
Por que o Service Discovery é crucial para sua arquitetura de microsserviços? À medida que seu sistema é dimensionado, o gerenciamento dos locais de serviço em constante mudança torna-se cada vez mais desafiador. Com o Service Discovery, os serviços podem se registrar e descobrir uns aos outros automaticamente, promovendo agilidade e flexibilidade em seu sistema.
Dê uma olhada nos Padrões de Design de Microsserviços da Grokking para dominar esses padrões de design de microsserviços para projetar sistemas escalonáveis, resilientes e mais gerenciáveis.
A descoberta de serviço pode ser obtida por meio de duas abordagens principais: descoberta do lado do cliente e descoberta do lado do servidor. A descoberta do lado do cliente envolve o cliente consultando um registro de serviço para encontrar o local do serviço de destino, enquanto a descoberta do lado do servidor depende de um balanceador de carga para rotear solicitações para o serviço apropriado. Ferramentas como Netflix Eureka, Consul e Kubernetes oferecem soluções integradas de descoberta de serviços para atender às suas necessidades específicas.
O diagrama abaixo é uma arquitetura de microsserviços baseada em Service Registry com Load Balancer, também conhecida como Service Discovery com Client-Side e/ou Server-Side Load Balancing. Vou detalhar:
-
Service Instances (A, B, C): cada serviço é independente, com sua própria API REST. Esses são os microsserviços reais.
-
Registry Client: cada instância de serviço se registra no Service Registry para que outras partes do sistema saibam onde encontrá-la.
-
Service Registry: é o componente central que mantém o mapeamento de quais instâncias estão ativas e seus endereços (IP + porta). Pode ser algo como Eureka, Consul ou Zookeeper.
-
Load Balancer: faz o balanceamento de requisições entre as instâncias disponíveis do serviço. Dependendo da implementação, pode ser Server-Side (o load balancer sabe das instâncias) ou Client-Side (o cliente consulta o registry e decide qual instância chamar).
-
Request Flow: quando uma requisição chega, ela passa pelo load balancer, que consulta o Service Registry para descobrir quais instâncias estão ativas e encaminha a requisição de forma balanceada.
Resumo do tipo de arquitetura: Arquitetura de microsserviços com Service Discovery e Load Balancing
Características principais:
- Desacoplamento total entre clientes e serviços.
- Descoberta dinâmica de serviços (não precisa de endereços fixos).
- Balanceamento de carga automático.
- Alta escalabilidade e resiliência.
 |
Em poucas palavras, o padrão de descoberta de serviço desempenha um papel fundamental na manutenção de uma arquitetura de microsserviços robusta e adaptável. Ao implementar esse padrão, você pode gerenciar e dimensionar facilmente seus serviços sem suar a camisa. Você está preparado para conquistar o labirinto de microsserviços com o Service Discovery?
Comunicação entre serviços em aplicações monolíticas: Em uma arquitetura monolítica, todos os componentes e módulos do aplicativo são totalmente integrados em uma única base de código e são executados no mesmo processo ou na mesma máquina. Como todos os componentes fazem parte do mesmo aplicativo, normalmente não há necessidade de comunicação entre serviços ou chamadas remotas para funções internas de negócios. A comunicação entre os componentes é obtida por meio de chamadas de método no nível da linguagem ou chamadas de função simples na mesma base de código
// Monolithic application with internal method calls
public class MonolithicApp {
public void performBusinessLogic() {
// Call a method within the same application
ComponentA.doSomething();
ComponentB.processData();
}
}
class ComponentA {
public static void doSomething() {
// Business logic for Component A
}
}
class ComponentB {
public static void processData() {
// Business logic for Component B
}
}Neste exemplo monolítico, a classe chama diretamente métodos dentro e . Como todos os componentes fazem parte do mesmo aplicativo, não há necessidade de comunicação de rede e as chamadas de método são diretas.MonolithicAppComponentAComponentB

A EDA - Event-driven architecture (arquitetura de orientação a eventos) é um paradigma de design de software em que os componentes de um sistema são projetados para responder a eventos e mensagens, em vez de se comunicarem diretamente uns com os outros através de chamadas de função ou métodos. Um evento (event) pode ser definido como uma mudança significativa do seu estado. Nessa arquitetura, os sistemas são construídos em torno da ideia de eventos. Os componentes do sistema podem produzir, consumir ou reagir a eventos. Quando um evento ocorre, os componentes interessados são notificados para tomar ações apropriadas.
Essa arquitetura é comumente usada em sistemas de streaming em tempo real, como aplicativos de monitoramento e processamento de dados em tempo real. Nessa arquitetura, os eventos são usados como meio de comunicação entre os diferentes componentes ou módulos do sistema. Esses eventos podem ser gerados por ações de usuários, sensores, outros sistemas, ou até mesmo pelo próprio sistema. Se você está cansado de lidar com a complexidade e a inflexibilidade das arquiteturas tradicionais de solicitação-resposta, talvez seja hora de considerar a arquitetura orientada a eventos.
A arquitetura orientada a eventos é um padrão de design poderoso que pode fornecer muitos benefícios para sistemas modernos. Ao permitir que os componentes se comuniquem de forma assíncrona por meio de eventos, a arquitetura orientada a eventos pode permitir sistemas mais flexíveis, escaláveis e resilientes que podem lidar com as demandas de dados em tempo real e ambientes distribuídos.
A arquitetura de microsserviços promove o desenvolvimento de serviços independentes. No entanto, esses serviços ainda precisam se comunicar entre si para funcionar como um sistema coeso.
Conseguir a comunicação correta entre os microserviços costuma ser um desafio. Existem duas razões principais para isso:
-
Quando os microserviços se comunicam por meio de uma rede, enfrentam desafios inerentes associados à comunicação entre processos.
-
Desenvolvedores frequentemente escolhem um padrão de comunicação sem considerar cuidadosamente as necessidades específicas do problema. Isso pode levar a desempenho e escalabilidade subótimos.
A arquitetura orientada a eventos (EDA) é uma abordagem de design de software que enfatiza a produção, detecção, consumo e reação a eventos. Nessa arquitetura, eventos são mudanças de estado ou atualizações dentro de um sistema.
A EDA é particularmente benéfica no desenvolvimento moderno de software porque pode desacoplar serviços, melhorar a escalabilidade e melhorar a capacidade de resposta.
Ao permitir que os sistemas reajam a eventos de forma assíncrona, a EDA suporta processamento em tempo real e possibilita que os sistemas lidam com grandes volumes de dados de forma eficiente. Essa abordagem é útil em sistemas distribuídos e arquiteturas de microserviços, onde diferentes componentes devem operar de forma independente, porém coesa.
A importância da EDA no cenário atual de software não pode ser subestimada. Oferece vantagens significativas, tais como:
-
Tolerância a falhas melhorada porque os sistemas podem continuar operando mesmo que alguns componentes falhem.
-
Melhor utilização dos recursos ao permitir que os serviços escalem de forma independente com base na demanda.
-
Suporta fluxos de trabalho dinâmicos e flexíveis, permitindo que as empresas se adaptem rapidamente às mudanças nos requisitos e às condições do mercado.
Vamos explorar vários padrões usados na arquitetura orientada a eventos. Ao examinar esses padrões, o objetivo é reunir insights sobre como eles podem ser aplicados para construir sistemas robustos, escaláveis e responsivos. Exploramos vários padrões de comunicação para microserviços e discutimos seus pontos fortes, fracos e casos de uso ideais.
Mas primeiro, vamos analisar os principais desafios associados à comunicação entre microserviços.
Os microsserviços orientados a eventos são um padrão de design para a criação de sistemas de software escalonáveis e resilientes. Em vez da arquitetura monolítica tradicional, em que todos os componentes são fortemente acoplados e executados em uma sequência predefinida, os microsserviços orientados a eventos desacoplam componentes individuais e permitem que eles se comuniquem e colaborem por meio da troca de eventos.
Em uma arquitetura de microsserviços orientada a eventos, cada microsserviço é projetado para ser pequeno, modular e independente, e se concentra em uma funcionalidade ou funcionalidade de negócios específica. Esses microsserviços se comunicam entre si por meio de um sistema de mensagens, como o Apache Kafka, que atua como um hub central para a troca de eventos. Isso permite que os microsserviços sejam acoplados de forma flexível e permite que sejam desenvolvidos, implantados e dimensionados independentemente uns dos outros.
Um dos benefícios do uso de microsserviços orientados a eventos é que ele permite a criação de sistemas altamente escaláveis e resilientes. Porque cada microsserviço é
A arquitetura orientada a eventos facilita o manuseio de processos demorados, funcionalidades complexas e longo tempo de espera para os usuários processarem as solicitações. De plataformas de mídia social a sistemas de processamento de pagamentos, a arquitetura orientada a eventos está alimentando alguns dos aplicativos mais bem-sucedidos do mercado.
Você pode estar familiarizado com a arquitetura tradicional de solicitação-resposta (um cliente, normalmente um navegador da Web, envia uma solicitação de um recurso para um servidor e o servidor envia de volta uma resposta correspondente ao recurso), na qual os componentes se comunicam entre si fazendo solicitações explícitas e recebendo respostas. Os componentes são fracamente acoplados nesta arquitetura.
Em um sistema orientado a eventos, os componentes se comunicam entre si produzindo e consumindo eventos. Isso permite sistemas mais flexíveis e escaláveis, pois os componentes não precisam esperar por solicitações ou respostas explícitas.
 |
 |
Os termos Event-Based e Event-Driven frequentemente são usados de maneira intercambiável, mas tecnicamente podem ter nuances diferentes dependendo do contexto em que são aplicados. No entanto, para a maioria das aplicações práticas e discussões sobre arquitetura de microsserviços, eles se referem ao mesmo padrão arquitetural.
Um exemplo de arquitetura orientada a eventos é o sistema de processamento de pagamentos usado por comerciantes online. Quando um cliente faz uma compra, um evento é gerado e enviado para o sistema de processamento de pagamentos. O sistema de processamento de pagamentos processa o pagamento e envia um evento de confirmação de volta ao sistema do comerciante, que atualiza o status do pedido.
Vamos tentar entendê-lo de uma maneira mais simples com um exemplo. Digamos que você tenha um sistema que permite enviar vídeos para a plataforma deles. O sistema precisa lidar com as seguintes tarefas:
- Aceitar upload de vídeo do cliente
- Inspecionando o vídeo em busca de violações.
- Transcodificando o vídeo. (convertendo vídeo para outros formatos como MPEG, HLS etc, que oferece a melhor experiência de transmissão com base no seu dispositivo e largura de banda de rede.)
- Gerando uma miniatura.
- Codificando áudio para o vídeo.
- Adicione marcas d'água, se houver.
- Adicione metadados desse vídeo ao banco de dados.
- Carregando o vídeo para a nuvem ou para cdn.
- e muitos mais.
Em uma arquitetura tradicional de solicitação-resposta, essas tarefas podem ser implementadas da seguinte maneira:
- O usuário carrega um vídeo na plataforma.
- A plataforma envia uma solicitação ao sistema de processamento de vídeo para processar o vídeo.
- O sistema de processamento de vídeo primeiro passa o vídeo para a lista de verificação de inspeção e isso validará se o vídeo está violando algum direito ou algo assim.
- Em seguida, o vídeo será passado pelo serviço de transcodificação no qual o vídeo será convertido para diferentes formatos e tamanhos.
- O vídeo será usado para criar a miniatura.
- Em seguida, precisamos passar o vídeo pelo serviço de codificação de áudio para codificar o áudio.
- Depois que a codificação de áudio for concluída, precisamos adicionar uma sobreposição de imagem em cima do vídeo.
- Em seguida, precisamos enviar o vídeo para a nuvem para melhor acessibilidade para o usuário. idealmente CDN.
- Feito tudo isso, precisamos atualizar o banco de dados para os metadados e o conteúdo relacionado à imagem.
- Em seguida, poderemos retornar a resposta ao usuário dizendo que o upload do vídeo é um sucesso ou algo assim.
Nesse cenário, o site está fortemente acoplado ao sistema de processamento de vídeo e o sistema de processamento de vídeo está fortemente acoplado aos outros serviços responsáveis por lidar com operações como codificação, compactação, marca d'água etc. Se algum desses componentes falhar, todo o sistema poderá ser afetado. Além disso, se o sistema tiver um alto volume de uploads de vídeo, o sistema de processamento de vídeo poderá se tornar um gargalo.
Esse tipo de arquitetura é comumente usado em muitos sistemas, mas pode ser menos flexível e escalável do que outras arquiteturas, como a arquitetura orientada a eventos.
Em uma arquitetura orientada a eventos, os componentes se comunicam entre si de forma assíncrona por meio de eventos, em vez de solicitações e respostas explícitas.
Agora, vamos considerar como esse cenário pode ser implementado usando a arquitetura orientada a eventos:
- O usuário carrega um vídeo na plataforma.
- A plataforma gera um evento de "upload de vídeo" e o envia para o sistema orientado a eventos.
- O sistema orientado a eventos encaminha o evento para o componente de inspeção de vídeo, que verificará se o vídeo não está violando nenhum direito. Assim que a inspeção de vídeo for concluída, ela gerará um evento de "processamento de vídeo".
- O sistema orientado a eventos roteia o "processamento de vídeo" para os componentes de transcodificação, miniatura, codificação de áudio, compactação e marca d'água.
- Como esses componentes são fracamente acoplados, eles podem funcionar de maneira assíncrona.
- Cada um desses componentes é dissociado um do outro, pois se comunicam por meio de eventos em vez de solicitações ou respostas diretas.
- O usuário pode enviar o vídeo e continuar com seus outros trabalhos, pois não precisa esperar que o servidor processe todas essas coisas. Esses processos estão sendo tratados de forma assíncrona.
- Assim que todos os componentes forem concluídos com suas respectivas manipulações para o vídeo, podemos notificar o usuário.
Apresentando o agente de mensagens, eventos de pull de componentes do agente de mensagens, os componentes são desacoplados.
Nessa arquitetura orientada a eventos, o site é desacoplado do componente de processamento de vídeo e o componente de processamento de vídeo é desacoplado dos outros componentes. Isso permite mais flexibilidade e facilita a modificação ou substituição de componentes individuais sem afetar o sistema geral.
Introduzimos um agente de mensagens, o vídeo que precisa ser processado é enviado para o agente de mensagens, outros componentes funcionam como um consumidor que consome eventos desse agente de mensagens.
À medida que os componentes se comunicam de forma assíncrona por meio de eventos, o sistema pode escalar horizontalmente adicionando mais instâncias de um componente para lidar com um volume maior de pedidos.
Benefícios da arquitetura orientada a eventos:
-
Acoplamento flexível: os componentes em um sistema orientado a eventos são desacoplados uns dos outros, pois se comunicam por meio de eventos em vez de solicitações ou respostas diretas. Isso facilita a modificação ou substituição de componentes individuais sem afetar o sistema geral.
-
Escalabilidade: como os componentes em um sistema orientado a eventos não precisam esperar por solicitações ou respostas explícitas, o sistema pode escalar horizontalmente adicionando mais instâncias de um componente para lidar com um volume maior de eventos.
-
Resiliência: em um sistema orientado a eventos, se um componente falhar, os eventos podem ser armazenados em buffer e repetidos assim que o componente for restaurado, permitindo que o sistema se recupere de falhas com mais facilidade.
Aqui estão alguns exemplos de arquitetura orientada a eventos no mundo real:
-
Processamento de pagamentos: Quando um cliente faz uma compra em um comerciante online, um evento é gerado e enviado para o sistema de processamento de pagamentos. O sistema de processamento de pagamentos processa o pagamento e envia um evento de confirmação de volta ao sistema do comerciante, que atualiza o status do pedido.
-
Plataforma de mídia social: os eventos são gerados sempre que um usuário publica uma mensagem, curte uma postagem ou executa qualquer outra ação em uma plataforma de mídia social. Esses eventos são usados para atualizar os feeds e notificações de outros usuários em tempo real.
-
Gerenciamento de estoque: em um ambiente de depósito ou varejo, os eventos podem ser gerados sempre que um item é adicionado ou removido do estoque. Esses eventos podem disparar atualizações no sistema de gerenciamento de estoque e acionar o reabastecimento ou reabastecimento conforme necessário.
Aqui estão algumas coisas importantes a serem lembradas ao projetar uma arquitetura orientada a eventos:
-
Identifique as fontes de eventos: A primeira etapa na criação de uma arquitetura orientada a eventos é identificar as fontes de eventos em seu sistema. Podem ser fontes externas, como ações do usuário ou leituras de sensores, ou fontes internas, como a conclusão de uma tarefa em segundo plano.
-
Defina os eventos: Em seguida, você deve definir os eventos que serão usados para se comunicar entre os componentes do seu sistema. Isso inclui a estrutura e o conteúdo dos eventos, bem como o formato em que eles serão transmitidos (e.g. JSON mensagens por HTTP).
-
Escolha um mecanismo de entrega de eventos: há várias opções para entregar eventos em um sistema controlado por eventos, incluindo filas de mensagens, sistemas de publicação/assinatura e barramentos de eventos. Você deve escolher o mecanismo de entrega que melhor se adapta às necessidades do seu sistema, considerando fatores como confiabilidade, escalabilidade e desempenho.
-
Projete os consumidores de eventos: os consumidores de eventos são os componentes do sistema que reagem a eventos. Você deve projetar esses componentes para serem o mais desacoplados possível das origens dos eventos e para lidar com eventos de forma assíncrona.
-
Implementar novas tentativas e tratamento de erros: Em um sistema orientado a eventos, é importante implementar novas tentativas e tratamento de erros para garantir que os eventos sejam entregues de forma confiável e que o sistema possa se recuperar de falhas. Isso pode incluir eventos de buffer e repetição da entrega em caso de falha ou implementação de transações de compensação para desfazer os efeitos de eventos com falha.
-
Teste e monitore a arquitetura orientada a eventos: Como em qualquer sistema, é importante testar e monitorar minuciosamente uma arquitetura orientada a eventos para garantir que ela esteja funcionando conforme o esperado e para identificar e resolver quaisquer problemas que surjam.
A arquitetura orientada a eventos pode oferecer muitos benefícios, mas tem suas desvantagens. Aqui estão algumas desvantagens potenciais a serem consideradas:
-
Complexidade: Os sistemas orientados a eventos podem ser mais complexos do que as arquiteturas tradicionais de solicitação-resposta, pois envolvem comunicação assíncrona e podem envolver vários componentes trabalhando juntos para produzir e consumir eventos. Isso pode tornar mais desafiador projetar, implementar e depurar sistemas orientados a eventos.
-
Dependência de serviços de terceiros: os sistemas orientados a eventos podem depender de serviços de terceiros, como filas de mensagens ou barramentos de eventos, para transmitir eventos entre componentes. Isso pode introduzir dependências adicionais e possíveis pontos de falha.
-
Dificuldade em testar e depurar: como os sistemas orientados a eventos envolvem comunicação assíncrona e podem envolver vários componentes trabalhando juntos, eles podem ser mais difíceis de testar e depurar do que os sistemas tradicionais de solicitação-resposta.
-
Ordenação de eventos: em alguns casos, pode ser importante manter a ordem na qual os eventos são gerados e consumidos. Isso pode ser mais desafiador em um sistema controlado por eventos, pois os eventos podem ser transmitidos e consumidos de forma assíncrona.
-
Falta de garantias transacionais: Em um sistema orientado a eventos, pode não haver o mesmo nível de garantias transacionais que em um sistema tradicional de solicitação-resposta. Isso pode tornar mais difícil garantir a consistência e a integridade dos dados no sistema.
Dito isto, os benefícios da arquitetura orientada a eventos muitas vezes podem superar essas desvantagens, especialmente em sistemas que exigem alta escalabilidade, resiliência ou flexibilidade.
Exemplo 2: Quando um consumidor adquire um imóvel, o estado dele se modifica de "à venda" para "vendido".
A arquitetura desse sistema pode tratar essa mudança de estado como um evento cuja ocorrência pode ser divulgada para outros aplicativos dentro da sua arquitetura.
De uma perspectiva formal, o que é produzido, publicado, propagado, detectado ou consumido é uma mensagem (geralmente assíncrona), chamada de notificação de evento, e não o próprio evento, que é a mudança de estado que acionou a emissão da mensagem. Isso se deve às arquiteturas orientadas a eventos, muitas vezes sendo projetadas sobre arquiteturas orientadas a mensagens, nas quais tal padrão de comunicação requer que uma das entradas seja somente texto (a mensagem), para diferenciar como cada comunicação deve ser tratada.
Um sistema de mensagens é um dos mecanismos mais comumente usados para troca de informações entre aplicações.
Ao escolher seu mecanismo de integração de aplicações, é importante ter em mente os princípios orientadores discutidos anteriormente.
No caso de bancos de dados compartilhados, por exemplo, alterações feitas por um aplicativo podem afetar diretamente outros aplicativos que estão usando as mesmas tabelas de banco de dados. Ambas as aplicações são fortemente acopladas.
-
Você pode querer evitar isso nos casos em que tenha regras adicionais a serem aplicadas antes de aceitar as alterações no outro aplicativo.
-
Da mesma forma, você deve pensar sobre todos esses princípios orientadores antes de finalizar formas de integração entre suas aplicações.
Um sistema de mensagens atua como um componente de integração entre vários aplicativos. Um sistema orientado a eventos normalmente consiste em:
-
Emissores (ou agentes): Os emissores têm a responsabilidade de detectar, reunir e transferir eventos. Um emissor de evento não conhece os consumidores, nem mesmo sabe se existe ou não um consumidor e, caso exista, não sabe como o evento será utilizado ou processado.
-
Consumidores (ou coletores): Os coletores têm a responsabilidade de aplicar uma reação assim que um evento seja apresentado. A reação pode ou não ser totalmente fornecida pelo próprio coletor. Por exemplo, o coletor pode ter apenas a responsabilidade de filtrar, transformar e encaminhar o evento para outro componente ou pode fornecer uma reação independente a tal evento.
-
Canais de eventos: Os canais de eventos são transmitidos dos emissores para consumidores. A implementação física dos canais pode ser baseada em componentes tradicionais, como middleware orientado à mensagem ou comunicação ponto a ponto.
Em um projeto de um sistema de integração entre aplicações, alguns fatores/princípios devem ser colocados em mente, tais como: fracamente acoplado, definições de interfaces comuns, latência e confiabilidade. Vamos compreender cada um deles a seguir:
- FRACAMENTE ACOPLADO: A interação entre as aplicações deve garantir uma dependência mínima entre elas. Isso garante que qualquer modificação em uma aplicação não irá afetar a outra. É diferente dos sistemas fortemente acoplados, nos quais uma aplicação é codificada com especificações predefinidas da outra aplicação, e qualquer mudança pode quebrar ou mudar suas funcionalidades com outras aplicações dependentes.
Um sistema de mensagens atua como um componente de integração entre vários aplicativos. Tal integração invoca diferentes comportamentos das aplicações com base nas trocas de informações entre eles. Esse comportamento pode ser aplicado pelo projeto e pela implementação de aplicativos e sistemas que transmitem eventos entre componentes de software e serviços fracamente acoplados.
-
PADRÕES DE INTERFACES COMUNS: Deve garantir um formato de dados comum acordado para troca de mensagens entre aplicativos. Isso não apenas ajuda a estabelecer padrões de troca de mensagens entre aplicativos, mas também garante que algumas das melhores práticas de troca de informações possam ser aplicadas facilmente. Por exemplo, você pode escolher usar o formato de dados Avro (muito usado em Big Data) para trocar mensagens. Isso pode ser definido como seu padrão de interface comum para troca de informações.
-
LATÊNCIA: É o tempo que as mensagens levam para passar entre o remetente e o receptor. A maioria dos aplicativos deseja atingir uma baixa latência como um requisito crítico. Mesmo em um modo de comunicação assíncrono, a alta latência não é desejável, pois um atraso significativo no recebimento de mensagens pode causar perdas significativas para qualquer organização.
-
CONFIABILIDADE: Garante que a indisponibilidade temporária dos aplicativos não afete as aplicações dependentes que precisam trocar informações. Em geral, quando o aplicativo de origem envia uma mensagem para o aplicativo remoto, este pode estar lento ou não disponível devido a alguma falha. A comunicação de mensagens assíncronas e confiáveis garante que a fonte da aplicação continue o seu trabalho, e garante que o aplicativo remoto retomará sua tarefa mais tarde. Uma vez compreendidas essas premissas iniciais, exploraremos alguns conceitos básicos de controle de mensageria.
-
FILA DE MENSAGENS: Estruturas que também são referenciadas como canais. De uma forma bem simples, podemos definir como conectores que enviam/recebem mensagens entre as aplicações de forma oportuna e confiável.
Em ciência da computação, uma fila de mensagens (MQ - Messaging Queue) é um componente de engenharia de software usado para a comunicação entre processos ou threads dum mesmo processo. O componente usa uma fila de mensagens.
Filas de mensagens provêm um protocolo de comunicação assíncrona, de forma que o remetente e o destinatário da mensagem não precisam interagir ao mesmo tempo. As mensagens são enfileiradas e armazenadas até que o destinatário as processe. A maioria das filas de mensagens definem limites ao tamanho dos dados que podem ser transmitidos numa única mensagem. Aquelas que não possuem tal limite são chamadas caixas de mensagens.
Faz sentido usar as filas de mensagens quando os interlocutores estão ligados através de redes de grande escala, em países diferentes, para as quais a probabilidade de desconexão não é desprezível.
-
MENSAGENS (PACOTES DE DADOS): Uma mensagem é um pacote de dados que é transmitido por uma rede para uma fila de mensagens.
- O aplicativo remetente divide os dados em pacotes de dados menores e os envolve como uma mensagem com informações de protocolo e cabeçalho.
- Em seguida, ele o envia para a fila de mensagens.
- De maneira semelhante, um aplicativo receptor recebe uma mensagem e extrai os dados do invólucro para processá-los posteriormente.
-
REMETENTE (PRODUTOR): Os aplicativos do remetente ou produtor são as fontes de dados que precisam ser enviados a um determinado destino. Eles estabelecem conexões com pontos de extremidade da fila de mensagens e enviam dados em pacotes de mensagens menores, que seguem padrões de interface comuns. Dependendo do tipo de sistema em uso, os aplicativos remetentes podem decidir enviar dados um a um ou em lote.
-
DESTINATÁRIO (CONSUMIDOR): São os destinatários das mensagens enviadas pelo aplicativo remetente.
- Eles extraem ou recebem, por meio de uma conexão persistente, dados de filas de mensagens.
- Em seguida, extraem dados desses pacotes de mensagens e os usam para processamento posterior.
-
PROTOCOLOS DE TRANSMISSÃO DE DADOS: Determinam as regras para controle das trocas de mensagens entre aplicativos. Diferentes sistemas de filas usam diferentes protocolos de transmissão de dados. Alguns exemplos de tais protocolos de transmissão de dados são:
-
AMQP (Advance Message Queuing Protocol) é um protocolo de rede de código aberto projetado para a troca eficiente e confiável de mensagens entre aplicativos ou sistemas distribuídos. Ele é especialmente útil em cenários em que é necessária uma comunicação assíncrona e a transferência de mensagens entre componentes de software.
-
STOMP (Streaming Text Oriented Message Protocol) é um protocolo de mensagens voltado para a comunicação entre clientes e servidores de mensagens (message brokers). Ele é projetado para ser simples e orientado a texto, facilitando a implementação e a interoperabilidade entre diferentes sistemas.
-
MQTT (Message Queue Telemetry Protocol) é um protocolo de mensagens leve e eficiente projetado para comunicação entre dispositivos em redes de Internet das Coisas (IoT) e em ambientes de redes de sensores. Ele foi desenvolvido para ser simples, econômico em termos de largura de banda e adequado para dispositivos com recursos limitados, como sensores, microcontroladores e outros dispositivos IoT.
-
HTTP (Hypertext Transfer Protocol)
-
-
MODO DE TRANSFERÊNCIA: O modo de transferência em um sistema de mensagens pode ser entendido como a maneira pela qual os dados são transferidos de uma aplicação de origem para a aplicação receptora. Exemplo: Modos síncrono, assíncrono e em lote.
Event-Based Architecture é frequentemente usada como sinônimo de Event-Driven Architecture. Quando alguém se refere a uma arquitetura baseada em eventos, geralmente está falando de um sistema onde os eventos desempenham um papel central na comunicação e no controle do fluxo de trabalho, com características semelhantes às descritas na EDA.
As diferenças sutis, se houverem, se for necessário fazer uma distinção técnica entre Event-Based e Event-Driven, pode-se considerar:
-
Event-Based pode ser uma descrição mais ampla que inclui qualquer sistema que use eventos como parte de sua lógica, sem necessariamente seguir todos os princípios de uma arquitetura Event-Driven, como desacoplamento rigoroso e comunicação assíncrona.
-
Event-Driven implica um conjunto mais específico de princípios e práticas que promovem a reatividade, a escalabilidade e o desacoplamento através do uso de eventos.
https://medium.com/@vinciabhinav7/common-problems-in-message-queues-with-solutions-f0703c0bd5af
A arquitetura orientada por eventos do McDonald demonstra uma implementação bem-sucedida de uma plataforma global de processamento de eventos em grande escala. O sistema lida de forma eficaz com diversos casos de uso, desde rastreamento de pedidos móveis até comunicações de marketing, mantendo alta confiabilidade e desempenho.
Os principais fatores de sucesso incluem a implementação robusta do AWS MSK, gerenciamento eficaz de esquemas e mecanismos abrangentes de tratamento de erros. A abordagem de sharding baseada em domínio da arquitetura e as capacidades de auto-escalonamento têm se mostrado cruciais para lidar com volumes crescentes de eventos.
Algumas boas práticas estabelecidas por meio desta implementação incluem:
- Um uso padronizado de SDK em diferentes linguagens de programação.
- Gerenciamento centralizado de esquemas.
- Manejo robusto de erros com tópicos sem saída.
- Otimização de desempenho por meio do cache de esquemas.
Olhando para o futuro, a plataforma do McDonald's está posicionada para evoluir com melhorias planejadas incluindo:
- Suporte formal para especificação de eventos.
- Transição para MSK serverless.
- Implementação do autoescalonamento de partições.
- Ferramentas e experiência aprimoradas para desenvolvedores.
Essas melhorias fortalecerão ainda mais as capacidades da plataforma, mantendo seus princípios centrais de design de escalabilidade, confiabilidade e simplicidade.
Warning
Aviso legal: Os detalhes deste post foram derivados do Blog Técnico do McDonald's. Todo o crédito pelos detalhes técnicos vai para a equipe de engenharia do McDonald's. Os links para os artigos originais estão presentes na seção de referências ao final do post. Tentamos analisar os detalhes e dar nossa opinião sobre eles. Se você encontrar alguma imprecisão ou omissão, por favor, deixe um comentário e faremos o possível para corrigi-las.
Ao longo dos anos, o McDonald's passou por uma transformação digital significativa para aprimorar a experiência dos clientes, fortalecer sua marca e otimizar operações como um todo.
No cerne dessa transformação está uma infraestrutura tecnológica robusta que unifica processos em diversos canais e pontos de contato em suas operações globais.
A necessidade de processamento unificado de eventos surgiu do extenso ecossistema digital do McDonald's, onde os eventos são utilizados em toda a pilha tecnológica. Havia três tipos principais de processamento:
- Operações assíncronas
- Processamento transacional
- Tratamento analítico de dados
Os eventos foram usados em vários casos de uso, como acompanhamento do progresso dos pedidos móveis e envio de comunicações de marketing aos clientes (promoções e promoções).
Somado à escala das operações do McDonald's, o sistema precisava de uma arquitetura capaz de suportar:
- Requisitos globais de implantação
- Processamento de eventos em tempo real
- Integração entre canais
- Processamento de transações de alto volume
Vamos analisar a jornada do McDonald no desenvolvimento de uma plataforma unificada que permite arquiteturas em tempo real orientadas a eventos.
Objetivos de Design da Plataforma: A plataforma unificada orientada a eventos da McDonald's foi construída com princípios fundamentais específicos para apoiar suas operações globais e serviços voltados ao cliente.
Cada objetivo de projeto foi cuidadosamente considerado para garantir a robustez e eficiência da plataforma. Vamos analisar os objetivos com um pouco mais de detalhes.

Escalabilidade: A plataforma precisava da capacidade de escalonar automaticamente para acomodar a demanda. Para esse fim, eles o projetaram para lidar com volumes crescentes de eventos por meio de sharding baseado em domínio em múltiplos clusters MSK. Essa abordagem permite escalabilidade horizontal e utilização eficiente dos recursos à medida que o volume de transações aumenta.
Alta Disponibilidade: A plataforma precisava ser capaz de suportar falhas em componentes. A resiliência do sistema é alcançada por meio de componentes redundantes e mecanismos de failover. A arquitetura inclui um armazenamento de eventos em standby que mantém a continuidade operacional quando o serviço principal MSK apresenta problemas.
Desempenho: O objetivo era entregar eventos em tempo real, com a capacidade de lidar com cargas de trabalho altamente concorrentes. A entrega de eventos em tempo real é facilitada por meio de caminhos de processamento otimizados e mecanismos de cache de esquemas. O sistema mantém baixa latência enquanto lida com cenários de alta taxa em diferentes regiões geográficas.
Segurança: Os dados precisavam seguir as diretrizes de segurança dos dados.
A plataforma implementa medidas abrangentes de segurança, incluindo:
- Camadas de autenticação para integrações com parceiros externos
- Gateways de eventos seguros
- Adesão a protocolos rigorosos de segurança de dados
Confiabilidade: A plataforma deve ser confiável com controles para evitar perder qualquer evento. A prevenção de perdas de eventos é alcançada por meio de:
- Gerenciamento de tópicos sem correspondência
- Mecanismos robustos de tratamento de erros
- Garantias de entrega confiável
- Procedimentos automatizados de recuperação
Consistência: A plataforma deve manter consistência em torno de padrões importantes relacionados ao manejo de erros, resiliência, evolução de esquemas e monitoramento. A padronização é mantida usando:
- SDKs personalizados para diferentes linguagens de programação
- Padrões unificados de implementação
- Registro centralizado de esquemas
- Gestão consistente de contratos de eventos
Simplicidade: A plataforma deve reduzir a complexidade operacional para que as equipes possam construir sobre a plataforma com facilidade.
A complexidade operacional é minimizada com:
- Gerenciamento automatizado de cluster
- Ferramentas de desenvolvimento simplificadas
- Interfaces administrativas simplificadas
- Padrões claros de implementação
Componentes Chave da Arquitetura: O diagrama abaixo mostra a arquitetura de alto nível da arquitetura orientada a eventos do McDonald's.

Os principais componentes da arquitetura são os seguintes:
Event Broker: O componente central da plataforma é o AWS Managed Streaming for Kafka (MSK), que lida com o seguinte:
- Gestão da comunicação entre produtores e consumidores.
- Organização e gestão de temas.
- Distribuição de eventos pela plataforma.
Registro de Esquemas Um registro de esquemas é um componente crítico que mantém a qualidade dos dados ao armazenar todos os esquemas de eventos.
Isso possibilita a validação de esquemas tanto para produtores quanto para consumidores. Também permite que os consumidores determinem qual esquema seguir para o processamento de mensagens.
Loja de Eventos de Reserva Esse componente ajuda a evitar a perda de mensagens caso o MSK não esteja disponível.
Ele realiza as seguintes funções:
Funciona como um mecanismo de recuo quando Kafka está indisponível.
Armazena temporariamente eventos que não puderam ser publicados para Kafka.
Funciona com a função AWS Lambda para tentar republicar eventos no Kafka assim que eles estão disponíveis.
SDKs personalizados A equipe de engenharia do McDonald's criou bibliotecas específicas de linguagem para produtores e consumidores.
Aqui estão os recursos suportados por esses SDKs:
Interfaces padronizadas tanto para produtores quanto para consumidores.
Capacidades integradas de validação de esquemas.
Mecanismos automatizados de tratamento de erros e retentativas.
Abstração de operações complexas de plataforma.
Portal de Eventos A arquitetura baseada em eventos do McDonald's é necessária para suportar eventos gerados internamente e eventos produzidos por aplicações parceiras externas.
O gateway de eventos serve como interface para integrações externas por meio de:
Fornecimento de endpoints HTTP para parceiros externos.
Converter requisições HTTP para eventos Kafka.
Implementando camadas de autenticação e autorização.
Serviços Públicos de Apoio São ferramentas administrativas que oferecem capacidades como:
Gestão de tópicos sem saída
Tratamento de erros para eventos que falham
Interfaces administrativas para monitoramento de eventos
Capacidades de gerenciamento de cluster
Fluxo de Processamento de Eventos O sistema de processamento de eventos do McDonald's segue um fluxo sofisticado que garante a integridade dos dados e o processamento eficiente.
O diagrama abaixo mostra o fluxo geral de processamento.

Vamos analisar isso com mais detalhes, dividindo o fluxo em dois grandes temas – criação de eventos e recepção de eventos.
Criação e Compartilhamento de Eventos O primeiro passo é criar um blueprint (esquema) para cada tipo de evento e armazená-lo em uma biblioteca central, também conhecida como registro de esquemas.
Aplicativos que querem criar eventos usam uma ferramenta especial (producer SDK) para isso.
Quando um app inicia, ele salva uma cópia do blueprint do evento para acesso rápido.
A ferramenta verifica se o evento corresponde ao blueprint antes de enviá-lo.
Se tudo parecer bem, o evento é enviado para o fórum principal, que é o tema principal.
Se houver algum problema com o evento ou um erro corrigível, ele é enviado para uma área separada (tópico dead-letter) para aquele app.
Se o sistema de mensagens (MSK) estiver fora do ar, o evento é salvo em um banco de dados de backup (DynamoDB).
Recepção do Evento Aplicativos que querem receber eventos usam o SDK de consumidor. Este SDK também verifica se os eventos recebidos correspondem aos seus projetos.
Quando um evento é recebido com sucesso, a aplicação o marca como "lido" e segue para o próximo.
Eventos na área problemática (tópico sem saída) podem ser corrigidos depois e enviados de volta para o fórum principal.
Eventos de empresas parceiras ("Outer Events") chegam pelo portal de eventos, como mencionado anteriormente.
Técnicas para Desafios-Chave A equipe de engenharia do McDonald's também utilizou algumas técnicas interessantes para resolver desafios comuns associados à instalação.
Vamos analisar alguns importantes:
Governança de Dados Garantir a precisão dos dados é crucial quando diferentes sistemas compartilham informações. Se os dados forem confiáveis, isso torna o projeto e a construção desses sistemas muito mais simples.
MSK e Schema Registry ajudam a manter a integridade dos dados ao impor "contratos de dados" entre sistemas.
Um esquema é como um blueprint que define quais informações devem estar presentes em cada mensagem e em qual formato. Ele especifica os campos de dados obrigatórios e opcionais e seus tipos (por exemplo, texto, número, data). Cada mensagem é verificada em tempo real contra esse projeto. Se uma mensagem não corresponder ao esquema, ela é enviada para uma área separada para ser corrigida.
Veja como os esquemas funcionam:
Quando um sistema inicia, ele salva uma lista de esquemas conhecidos para consulta rápida.
Esquemas podem ser atualizados para incluir mais campos ou alterar tipos de dados.
Quando um sistema envia uma mensagem, ele inclui um número de versão para indicar qual esquema foi usado.
O sistema receptor usa esse número de versão para processar a mensagem com o esquema correto.
Essa abordagem lida com mensagens com diferentes esquemas sem interrupção e permite atualizações e rollbacks fáceis.
Veja o diagrama abaixo para referência:

O uso de um registro de esquema para validar contratos de dados garante que o fluxo de informações entre os sistemas seja preciso e consistente. Isso economiza tempo e esforço no design e operação dos sistemas que dependem desses dados, especialmente para fins analíticos.
Cluster Autoscaling MSK é um sistema de mensagens que ajuda diferentes partes de uma aplicação a se comunicarem entre si. Ele usa corretores para armazenar e gerenciar as mensagens.
À medida que a quantidade de dados cresce, o MSK aumenta automaticamente o espaço de armazenamento para cada corretor. No entanto, eles precisavam de uma forma de adicionar mais corretores ao sistema quando os existentes ficassem sobrecarregados.
Para resolver esse problema, eles criaram uma função Autoscaler. Veja o diagrama abaixo:

Pense nessa função como um cão de guarda que monitora o quanto cada corretor está trabalhando. Quando a carga de trabalho de um corretor (medida pela utilização da CPU) ultrapassa um certo nível, a função Autoscaler entra em ação e faz duas coisas:
Ele adiciona um novo corretor ao sistema MSK para ajudar a lidar com o aumento da carga de trabalho.
Ela aciona uma função lambda para redistribuir os dados de forma uniforme entre todos os corretores, incluindo o novo.
Dessa forma, o sistema MSK pode se adaptar automaticamente para lidar com mais dados e tráfego, sem a necessidade de adicionar corretores ou mover dados manualmente.
Sharding baseado em domínio Para garantir que o sistema de mensagens possa lidar com muitos dados e minimizar o risco de falhas, eles dividem os eventos em grupos separados de acordo com seu domínio.

Cada grupo possui seu próprio cluster dedicado MSK. Isso é como ter salas de correspondência separadas para diferentes departamentos em uma grande empresa. O domínio de um evento determina a qual cluster e tema ele pertence. Por exemplo, eventos relacionados a perfis de usuário podem ir para um cluster, enquanto eventos relacionados a pedidos de produtos podem ir para outro.
Aplicações que precisam receber eventos podem optar por obtê-los de qualquer um desses tópicos baseados em domínio. Isso melhora a flexibilidade e ajuda a distribuir a carga de trabalho pelo sistema.
Para garantir que a plataforma esteja sempre disponível e possa atender usuários globalmente, ela está configurada para funcionar em várias regiões. Em cada região, há uma configuração de alta disponibilidade. Isso significa que, se uma parte do sistema falhar, outra parte pode assumir o controle de forma contínua, garantindo um serviço ininterrupto.

Trade-offs de Engenharia: Consistência Eventual (Eventual Consistency) na Prática
Imagine um aplicativo de carona que mostra a localização do motorista com alguns segundos de atraso. Agora, imagine se o app inteiro se recusasse a mostrar qualquer coisa até que todos os serviços de backend concordassem com a localização atual perfeita. Sem movimento, sem atualizações, apenas uma roda girando.
É isso que aconteceria se a consistência forte fosse sempre preferida em um sistema distribuído.
Aplicações modernas (feeds sociais, mercados, plataformas logísticas) não rodam mais em um único banco de dados ou backend monolítico. Eles rodam em sistemas distribuídos orientados por eventos. Os serviços publicam e reagem aos eventos. Os dados fluem de forma assíncrona, e os componentes são atualizados de forma independente. Esse desacoplamento desbloqueia flexibilidade, escalabilidade e resiliência. No entanto, isso também significa que a consistência não é mais imediata ou garantida.
É aí que a consistência eventual se torna importante.
Alguns exemplos são os seguintes:
Um sistema de pagamento pode marcar uma transação como pendente até que múltiplos serviços downstream confirmem isso.
Um serviço de feed pode renderizar postagens enquanto um trabalho em segundo plano as desduplica ou reordena depois.
Um sistema de armazém pode vender temporariamente um produto em excesso e depois emitir uma correção à medida que as atualizações de estoque sincronizam entre as regiões.
Esses não são bugs, mas trade-offs.
A consistência eventual permite que cada componente faça seu trabalho de forma independente, depois se reconcilie. Ele prioriza a disponibilidade e a resposta em vez de acordo imediato.
Este artigo explora o que significa construir com consistência eventual em um mundo movido por eventos. Ele explica como lidar com eventos fora de ordem e como projetar sistemas que possam lidar com atrasos.
Como a Netflix Construiu um Contador Distribuído? Como a Netflix Construiu um Contador Distribuído para Bilhões de Interações de Usuários?
Um Contador Distribuído (Distributed Counter) é um sistema onde a responsabilidade de contar eventos é distribuída entre múltiplos servidores ou nós em uma rede. A Netflix precisa monitorar e medir múltiplas interações dos usuários para tomar decisões em tempo real e otimizar sua infraestrutura. O contador distribuído da Netflix é uma aula magistral para design de sistemas de aprendizagem.
Warning
Aviso: Os detalhes deste post foram retirados do Netflix Tech Blog. Todo o crédito pelos detalhes técnicos vai para a equipe de engenharia da Netflix. Os links para os artigos originais estão presentes na seção de referências ao final do post. Tentamos analisar os detalhes e dar nossa opinião sobre eles. Se você encontrar alguma imprecisão ou omissão, por favor, deixe um comentário e faremos o possível para corrigi-las.
A Netflix opera em uma escala incrível, com milhões de usuários interagindo com sua plataforma a cada segundo.
Para proporcionar uma ótima experiência ao usuário, a Netflix precisa acompanhar e medir essas interações — por exemplo, contando quantos usuários estão assistindo a um novo programa ou clicando em recursos específicos. Esses números ajudam a Netflix a tomar decisões em tempo real sobre como melhorar a experiência do usuário, otimizar sua infraestrutura e realizar experimentos como testes A/B.
No entanto, contar em uma escala tão grande não é simples. Imagine tentar contar milhões de eventos acontecendo simultaneamente no mundo todo, garantindo que os resultados sejam rápidos, precisos e econômicos.
É aí que entra a Contra-Abstração Distribuída.
Esse sistema foi projetado para lidar com a contagem de uma forma que atenda aos exigentes requisitos da Netflix:
- Baixa latência: As contagens precisam ser atualizadas e estar disponíveis em milissegundos.
- Alta Produtividade: O sistema deve lidar com milhares de atualizações por segundo sem gargalos.
- Eficiência de Custos: Gerenciar um sistema em grande escala não deve ser uma grande estima.
Vamos analisar como a Netflix construiu uma Contra-Abstração Distribuída e os desafios que enfrentou:

Por essa razão, eles construíram uma Contra-Abstração Distribuída.
A Abstração Contrária Distribuída da Netflix opera em quatro camadas principais, garantindo alto desempenho, escalabilidade e consistência eventual.
-
Usuários da Camada da API do Clienteinteragem com o sistema enviando requisições AddCount, GetCount ou ClearCount. O Netflix Data Gateway processa e roteia essas solicitações de forma eficiente.
-
Os eventos de Registro de Eventos e Armazenamento de Séries Temporais são armazenados na Abstração de Séries Temporais da Netflix para maior escalabilidade. Cada evento é marcado com um ID de Evento para garantir a idempotência. Para evitar contenção no banco de dados, eventos são agrupados em partições temporais conhecidas como buckets. Os dados são armazenados em Cassandra.
-
Filas de Rollup Pipeline ou Agregação coletam alterações de eventos e as processam em lotes. A agregação ocorre em janelas de tempo imutáveis, garantindo cálculos de rollup precisos. Os dados são armazenados na Cassandra Rollup Store para eventual consistência.
-
Otimização de Leitura (Cache e Gerenciamento de Consultas) Valores agregados de contadores são armazenados em cache no EVCache para leituras ultrarrápidas. Se um valor de cache estiver desatualizado, uma atualização de rollup em segundo plano o atualiza. Esse modelo permite que a Netflix processe 75K requisições por segundo com latência de um dígito de milissegundos.
Por que a necessidade de um contador distribuído? A Netflix precisa contar milhões de eventos a cada segundo em sua plataforma global. Esses eventos podem ser qualquer coisa: o número de vezes que um recurso é usado, com que frequência um programa é clicado, ou até métricas detalhadas de experimentos como testes A/B
O desafio é que essas necessidades de contagem não são tamanho único.
Algumas situações exigem resultados rápidos e aproximados, enquanto outras exigem contagens precisas e duradouras. É aí que o Distributed Counter Abstraction da Netflix se destaca, oferecendo flexibilidade para atender a essas necessidades diversas.
Existem duas grandes categorias de contagem:
Contagem de Melhor Esforço: Esse tipo de contagem é usado quando a velocidade é mais importante que a precisão. As contagens não precisam ser perfeitamente precisas, e não ficam armazenadas por muito tempo. Funciona bem para cenários como testes A/B, onde contagens aproximadas são suficientes para comparar o desempenho de dois grupos.
Contagem Eventualmente Consistente: Este tipo é usado quando precisão e durabilidade são críticas. Embora possa levar um pouco mais de tempo para obter a contagem final, isso garante que os resultados sejam corretos e preservados. Isso é ideal para métricas que precisam ser registradas com precisão ao longo do tempo, como faturamento, conformidade regulatória ou relatórios críticos de uso.
Analisaremos ambas as categorias com mais detalhes em uma seção futura.
No entanto, ambas as categorias compartilham alguns requisitos-chave que são os seguintes:
Alta Disponibilidade: O sistema deve estar sempre funcionando, mesmo durante falhas ou alta demanda. A Netflix não pode se dar ao luxo de perder tempo na contagem, já que essas métricas frequentemente influenciam decisões críticas.
Alta Taxa de Rendimento: O sistema deve lidar com milhões de operações de contagem por segundo. Isso significa que precisa processar eficientemente um enorme volume de dados recebidos, sem gargalos.
Escalabilidade: A Netflix opera globalmente, então o sistema de contagem deve escalar horizontalmente em várias regiões e lidar com picos de uso, como durante o lançamento de um novo programa.
A tabela abaixo mostra esses requisitos com mais detalhes:

O Design da API de Contraabstração A abstração Contador Distribuído foi projetada como um sistema altamente configurável e amigável para o usuário.
A abstração fornece uma API simples, porém poderosa, permitindo que os clientes interajam consistentemente com contadores. As principais operações da API são as seguintes:
1 - Adicionar Contagem/Adicionar E Conseguir Contagem O objetivo desse ponto final é incrementar ou decrementar um contador em um valor especificado.
O cliente especifica o namespace (por exemplo, "user_metrics"), o nome do contador (por exemplo, "views_counter") e o delta (um valor positivo ou negativo para ajustar a contagem). A API retorna a contagem atualizada imediatamente após aplicar o delta.
Veja o exemplo abaixo:
{
"namespace": "user_metrics",
"counter_name": "views_counter",
"delta": 5,
"idempotency_token": {
"token": "unique_event_id",
"generation_time": "2025-01-28T14:48:00Z"
}
}Aqui, o token de idempotência garante que requisições repetidas (devido a tentativas) não resultem em contagem dupla.
2 - GetCount Esse endpoint ajuda a recuperar o valor atual de um contador.
O cliente especifica o namespace e o nome do contador, e o sistema busca o valor. Aqui está um exemplo de solicitação de API:
{
"namespace": "user_metrics",
"counter_name": "views_counter"
}Essa operação é otimizada para velocidade, retornando contagens um pouco desgastadas em algumas configurações para manter o desempenho.
3 - Contagem Limpa Esse ponto final ajuda a resetar o valor de um contador para zero.
Semelhante a outras requisições, o cliente fornece o namespace e o nome do contador. Essa operação também suporta tokens de idempotência para garantir tentativas seguras.
Técnicas de contagem A abstração do Contador Distribuído suporta vários tipos de contadores para atender aos diversos requisitos de contagem da Netflix. Cada abordagem equilibra os trade-offs entre velocidade, precisão, durabilidade e custo de infraestrutura.
Aqui está uma análise detalhada das principais estratégias de contagem:
Melhor Esforço Regional Esta é uma abordagem leve de contagem, otimizada para velocidade e baixo custo de infraestrutura. Ele fornece contagens rápidas, mas aproximadas.
Ele é construído sobre o EVCache, a solução de cache distribuído da Netflix baseada em Memcached. As contagens são armazenadas como pares-chave-valor em um cache com latência mínima e alta taxa de transferência. TTL (Time-To-Live) garante que os contadores não ocupem o cache indefinidamente.
O contador de melhor esforço é ideal para experimentos de curta duração, como testes A/B, onde contagens precisas não são críticas. As vantagens desse tipo de contador são as seguintes:
Extremamente rápido, com latência de milissegundos.
Econômico devido aos clusters multi-tenant compartilhados.
No entanto, também existem desvantagens nessa abordagem:
Sem replicação entre regiões para contadores.
Falta idempotência, tornando as tentativas inseguras.
Não posso garantir consistência entre nós.
Eventualmente Contador Global Consistente Para cenários onde precisão e durabilidade são cruciais, existem várias abordagens disponíveis sob o modelo eventualmente consistente. Esses fatores garantem que os contadores convergam para valores precisos ao longo do tempo, embora alguns atrasos sejam aceitáveis.
1 - Fileira única por contador É uma abordagem direta onde cada contador é representado por uma única linha em um datastore replicado globalmente.
Veja a tabela abaixo, por exemplo:

Apesar de sua simplicidade, essa abordagem apresenta algumas desvantagens, tais como:
Vulnerável à perda de dados se uma instância falhar antes de esvaziar suas contagens.
É difícil sincronizar resets de contadores entre instâncias.
Falta idempotência, o que complica as tentativas.
2 - Agregação por Instância Essa abordagem agrega contagens na memória em instâncias individuais e, periodicamente, escreve os valores agregados em um repositório durável. Esse processo é conhecido como flushing. Introduzir jitter suficiente no processo de flush ajuda a reduzir a contenção.
Veja o diagrama abaixo para referência:

A principal vantagem dessa abordagem é que reduz a contenção ao limitar as atualizações para a loja durevole. No entanto, também apresenta alguns desafios, como:
Vulnerável à perda de dados se uma instância falhar antes de esvaziar suas contagens.
É difícil sincronizar resets de contadores entre instâncias.
Falta idempotência.
3 - Caudas Duráveis Essa abordagem registra eventos contrários a um sistema de fila durável como o Apache Kafka. Os eventos são processados em lotes para agregação. Veja como funciona:
Eventos contadores são gravados em partições Kafka específicas com base em um hash da chave contadora.
Os consumidores leem partições, agregam eventos e armazenam os resultados em um armazenamento durado.
Veja o diagrama abaixo:

Essa abordagem é confiável e tolerante a falhas devido aos troncos duráveis. Além disso, a idempotência é mais fácil de implementar, prevenindo contagem excessiva durante as tentativas.
No entanto, pode causar atrasos se os consumidores ficarem atrasados. Rebalancear partições como contadores ou aumentos de throughput pode ser complexo.
4 - Registro de Eventos de Incrementos Essa abordagem registra cada incremento individual (ou decremento) como um evento com metadados como tempo de evento e event_id. O event_id pode incluir a fonte de onde a operação se originou.
Veja o diagrama abaixo:

A combinação de event_time e event_id também pode servir como chave de idempotência para a escrita.
No entanto, essa abordagem também apresenta várias desdesvantagens:
Alto custo de armazenamento devido à necessidade de manter cada incremento.
Desempenho de leitura degradado, pois exige escanear todos os eventos em busca de um contador.
Partições amplas em bancos de dados como o Cassandra podem desacelerar consultas.
Abordagem Híbrida da Netflix As necessidades de contagem da Netflix são vastas e diversas, exigindo uma solução que equilibre velocidade, precisão, durabilidade e escalabilidade.
Para atender a essas demandas, a Netflix desenvolveu uma abordagem híbrida que combina os pontos fortes das várias técnicas de contagem que discutimos até agora. Essa abordagem utiliza registro de eventos, agregação em segundo plano e cache para criar um sistema que seja escalável e eficiente, mantendo também a consistência eventual.
Vamos entender a abordagem com mais detalhes:
1 - Registrar eventos na abstração de séries temporais No cerne da solução da Netflix está o TimeSeries Abstraction, um serviço de alto desempenho projetado para gerenciar dados temporais.
A Netflix utiliza esse sistema para registrar cada evento contador como um registro individual, permitindo rastreamento preciso e escalabilidade.
Cada evento contador é registrado com metadados, incluindo:
-
event_time: O momento em que o evento aconteceu. -
event_id: Um identificador único para o evento para garantir idempotência. -
event_item_key: Especifica o contador a ser atualizado.
Os eventos são organizados em baldes de tempo (por exemplo, por minuto ou hora) para evitar partições amplas no banco de dados. IDs de eventos únicos impedem a contagem duplicada, mesmo que ocorram tentativas repetidas.
2 - Processos de agregação para contadores de alta cardinalidade Para evitar a ineficiência de buscar e recalcular contagens de eventos brutos em cada leitura, a Netflix emprega um processo de agregação em segundo plano. Esse sistema consolida continuamente os eventos em contagens resumidas, reduzindo armazenamento e sobrecarga de leitura.
A agregação ocorre dentro de janelas de tempo definidas para garantir a consistência dos dados. Uma janela imutável é usada, ou seja, apenas eventos finalizados (não sujeitos a atualizações adicionais) são agregados.
O Último Timestamp de Rolagem acompanha a última vez que um contador foi agregado. Ele garante que o sistema processe apenas novos eventos desde o rollup anterior.
Veja como funciona o processo de agregação:
O processo de agrupamento coleta todos os eventos de um contador dentro da janela de agregação. Ele resume a contagem total e atualiza a loja de rollup.
Contagens agregadas são armazenadas em um sistema durável como o Cassandra para persistência. Agregações futuras se baseiam nesse ponto de verificação, reduzindo os custos de computação.
Os rollups são acionados durante escritas e leituras. Para gravações, ela é acionada quando um evento leve notifica o sistema sobre as alterações. Durante as leituras, quando um usuário busca um contador, os rollups são acionados se a contagem estiver obsoleta.
Veja o diagrama abaixo para o processo do caminho de escrita:

Em seguida, temos o diagrama abaixo que mostra o processo read ou getCount:

A agregação reduz a necessidade de processar repetidamente eventos brutos, melhorando o desempenho da leitura. Ao usar janelas imutáveis, a Netflix garante que as contagens sejam precisas dentro de um prazo razoável.
3 - Cache para leituras otimizadas Embora o processo de agregação garanta que as contagens sejam eventualmente consistentes, o cache é usado para melhorar ainda mais o desempenho dos contadores acessados com frequência. A Netflix integra o EVCache (uma solução de cache distribuída) para armazenar contagens acumuladas.
O cache contém a última contagem agregada e o carimbo de tempo correspondente do último rollup. Quando um contador é lido, o valor em cache é retornado imediatamente, fornecendo uma resposta quase em tempo real. Um rollup em segundo plano é acionado para garantir que o cache permaneça atualizado.
Contagens em cache permitem que os usuários recuperem valores em milissegundos, mesmo que estejam um pouco desatualizados. Além disso, o cache minimiza consultas diretas ao datastore subjacente, economizando custos de infraestrutura.
Principais benefícios da abordagem híbrida A abordagem híbrida traz vários benefícios, tais como:
Combinando Precisão e Desempenho: Ele registra cada evento para uma contagem precisa quando necessário. Agrega eventos em segundo plano para manter alto desempenho de leitura.
Escala com Alta Cardinalidade: Lida com milhões de contadores de forma eficiente usando bucketing de tempo e evento. Isso garante uma distribuição equilibrada da carga de trabalho entre os sistemas de armazenamento e processamento.
Garante confiabilidade: Utiliza tokens de idempotência para lidar com retentativas com segurança. Além disso, ele emprega armazenamento persistente (por exemplo, Cassandra) e caches para tolerância a falhas.
Equilibra Trade-Offs: Sacrifica um pouco de imediatismo para a consistência eventual nas contagens globais. Também introduz pequenos atrasos na agregação para manter a precisão dentro de janelas imutáveis.
Escalonando o Pipeline de Rollup Para gerenciar milhões de contadores ao redor do mundo mantendo alto desempenho, a Netflix utiliza um Pipeline de Rollup. Este é um sistema sofisticado que processa eventos de contagem de forma eficiente, os agrega em segundo plano e escala para lidar com cargas de trabalho massivas.

Existem três partes principais desse pipeline de rollup:
1 - Eventos e Filas de Rolagem Quando um contador é atualizado (via uma operação AddCount, ClearCount ou GetCount), o sistema gera um evento de rollup leve.
Esse evento notifica o Rollup Pipeline que o contador requer agregação. O evento de rollup em si não inclui os dados brutos, mas apenas identifica o contador que precisa ser processado.
Veja como funcionam as filas de rolo:
Cada instância do Servidor de Rollup mantém filas em memória que recebem eventos de rollup. Essas filas permitem o processamento paralelo de tarefas de agregação, possibilitando que o sistema gerencie cargas de trabalho de alta produtividade.
Uma função de hash rápida e não criptográfica (por exemplo, XXHash) garante que contadores relacionados sejam roteados consistentemente para a mesma fila. Isso minimiza o trabalho duplicado e melhora a eficiência.
Múltiplos eventos para o mesmo marcador são consolidados em um Conjunto, então cada marcador é rolado apenas uma vez dentro de uma janela de rollup.
A Netflix optou por filas de enrolamento em memória para simplificar o provisionamento e reduzir custos. Esse design é mais fácil de implementar em comparação com um sistema de fila totalmente durável.
No entanto, também existem alguns riscos potenciais.
Se um servidor de rollup travar antes de processar todos os eventos, esses eventos são perdidos. Isso é mitigado para contadores acessados com frequência, pois operações subsequentes desencadeiam novos rollups.
Durante implantações ou escalabilidades, pode haver breves sobreposições onde servidores antigos e novos estão ativos. No entanto, isso é gerenciado com segurança porque agregações ocorrem dentro de janelas imutáveis.
Quando as cargas de trabalho aumentam, a Netflix escala o Pipeline de Rollup aumentando o número de filas de rollup e reimplantando os servidores de rollup com configurações atualizadas.
O processo é contínuo, com servidores antigos desligando graciosamente após esvaziar seus eventos. Durante as implantações, tanto os servidores de rollup antigos quanto os novos podem lidar brevemente com os mesmos contadores. Isso evita o tempo de inatividade, mas introduz uma leve variabilidade nas contagens, que é eventualmente resolvida à medida que as contagens convergem.
2 - Agrupamento Dinâmico e Contrapressão Para otimizar o desempenho, o Rollup Pipeline processa contadores em lotes, em vez de individualmente.
O tamanho de cada lote se ajusta dinamicamente com base na carga do sistema e na cardinalidade do contador. Isso impede que o sistema sobrecarregue o armazenamento de dados subjacente (por exemplo, Cassandra). Dentro de um lote, o pipeline consulta a Abstração de Séries Temporais em paralelo para agregar eventos de múltiplos contadores simultaneamente.
Veja o diagrama abaixo:

O sistema monitora o desempenho de cada lote e usa essas informações para controlar a taxa de processamento. Após processar um lote, o pipeline pausa antes de iniciar o próximo, dependendo da rapidez com que o lote anterior é concluído. Esse mecanismo adaptativo garante que o sistema não sobrecarregue o backend de armazenamento durante o alto tráfego.
3 - Lidar com a Convergência para contadores de baixa e alta cardinalidade Contadores de baixa cardinalidade são frequentemente acessados, mas têm menos instâncias únicas. O gasoduto mantém eles em circulação contínua para garantir que permaneçam atualizados.
Por outro lado, contadores de alta cardinalidade possuem muitas instâncias únicas (como métricas por usuário) e podem não ser acessados com frequência. Para evitar uso excessivo de memória, o pipeline usa o último carimbo de tempo de gravação para determinar quando um contador precisa ser reenfileirado. Isso garante que a agregação continue até que todas as atualizações sejam processadas.
Veja o diagrama abaixo:

Configuração Centralizada do Plano de Controle No coração da Abstração Contrária Distribuída da Netflix está seu plano de controle, um sistema centralizado que gerencia a configuração, a implantação e a complexidade operacional nas camadas de abstração.
Veja o diagrama abaixo:

O plano de controle permite que a Netflix ajuste todos os aspectos do serviço de contagem, garantindo que ele atenda às necessidades de diversos casos de uso sem necessidade de intervenção manual ou reengenharia.
1 - Função do Plano de Controle O Plano de Controle serve como um centro de gerenciamento para todas as configurações relacionadas à Abstração de Contadores Distribuídos. É responsável por:
Configurando os mecanismos de persistência para contadores.
Ajustar configurações para casos de uso específicos, como contadores de alta ou baixa cardinalidade.
Implementando estratégias para retenção de dados, cache e durabilidade.
Essa gestão centralizada garante que as equipes da Netflix possam focar em seus casos de uso sem se preocupar com as complexidades subjacentes da contagem distribuída.
2 - Configuração de Mecanismos Persistentes O Plano de Controle permite a configuração de camadas de persistência para armazenar dados de contadores.
A Netflix usa uma combinação de EVCache (para cache) e Cassandra (para armazenamento durável). O plano de controle coordena a interação deles.
EVCache é usado para acesso rápido e de baixa latência aos contadores. O plano de controle especifica parâmetros como tamanho do cache e políticas de expiração.
{
"id": "CACHE",
"physical_storage": {
"type": "EVCACHE",
"cluster": "evcache_dgw_counter_tier1"
}
}O Cassandra é usado como o principal armazenamento de dados para armazenamento durável e de longo prazo de contadores e seus rollups.
Os parâmetros configuráveis para isso incluem:
- Configurações de espaço de chaves, como o número de partições.
- Particionamento de tempo para contadores (por exemplo, dividir dados em baldes de tempo gerenciáveis).
- Políticas de retenção para evitar o uso excessivo de armazenamento.
Veja a configuração de exemplo abaixo:
{
"id": "COUNTER_ROLLUP",
"physical_storage": {
"type": "CASSANDRA",
"cluster": "cass_dgw_counter_uc1",
"dataset": "my_dataset"
}
}3 - Suporte a Diferentes Estratégias de Cardinalidade Os contadores podem variar muito em cardinalidade, ou seja, no número de contadores únicos sendo gerenciados.
Contadores de baixa cardinalidade são métricas globais como "total de visualizações" para um programa. Tais contadores são frequentemente acessados e exigem processamento contínuo de rolamento. Isso requer intervalos de tempo menores para agregação e TTLs mais curtos para valores em cache para garantir a novidade.
Contadores de alta cardinalidade incluem métricas por usuário como "visualizações por usuário". Esses contadores são acessados com menos frequência, mas exigem o manuseio eficiente de um grande número de chaves únicas. Eles envolvem buckets de tempo maiores para reduzir a sobrecarga do banco de dados e particionamento eficiente para distribuir a carga entre os nós de armazenamento.
4 - Apólices de Retenção e Ciclo de Vida As políticas de retenção garantem que os dados contadores não cresçam descontroladamente, reduzindo custos enquanto mantêm a relevância histórica.
Por exemplo, eventos contadores brutos são armazenados temporariamente (como 7 dias) antes de serem deletados ou arquivados. Os rollups agregados são mantidos por mais tempo, pois ocupam menos espaço e são úteis para métricas de longo prazo.
Além disso, o plano de controle garante que os contadores expirem após sua vida útil pretendida, evitando que consumam recursos desnecessários.
5 - Suporte Multi-Inquilino O Plano de Controle da Netflix foi projetado para suportar um ambiente multi-inquilino onde diferentes equipes ou aplicações podem operar seus contadores de forma independente:
Cada namespace é isolado, permitindo que as configurações variem conforme o caso de uso.
Por exemplo, o espaço de nomes user_metrics pode priorizar cache de baixa latência para dashboards em tempo real. Além disso, o namespace billing_metrics pode focar na durabilidade e precisão para relatórios financeiros.
Conclusão A contagem distribuída é um problema complexo, mas a abordagem da Netflix demonstra como um design e engenharia cuidadosos podem superar esses desafios.
Ao combinar abstrações poderosas como TimeSeries e Data Gateway Control Plane com técnicas inovadoras como rollup pipelines e batching dinâmico, a Netflix oferece um sistema de contagem rápido, confiável e econômico.
O sistema processa 75.000 requisições contadoras por segundo globalmente, mantendo uma latência de um dígito de milissegundo para endpoints da API. Esse desempenho incrível é alcançado por meio de escolhas cuidadosas de design, incluindo lotamento dinâmico, cache com EVCache e processos eficientes de agregação.

Os princípios por trás da Distributed Counter Abstraction da Netflix vão muito além da plataforma. Qualquer sistema em grande escala que exija métricas em tempo real, rastreamento distribuído de eventos ou consistência global pode se beneficiar de uma arquitetura semelhante
Event Sourcing é um padrão de arquitetura em que o estado de uma aplicação não é armazenado diretamente em estruturas de dados tradicionais, como tabelas com os dados finais atualizados, mas sim reconstruído a partir de uma sequência de eventos que descrevem tudo o que aconteceu com aquele dado ao longo do tempo. Em vez de gravar apenas o estado atual de uma entidade, cada mudança de estado é registrada como um evento imutável e persistido de forma sequencial.
Você já pensou em implementar event sourcing? Pode ser aplicado de forma eficaz em aplicações do mundo real? Como ele se integra com outros padrões e abordagens, como Design Orientado por Domínio (DDD) ou Arquitetura Orientada a Eventos (EDA)? Se você tem curiosidade sobre essas perguntas, continue lendo; Vou compartilhar minhas percepções depois de mergulhar nesse padrão (incluindo código! Meu Deus!).
Reconstruindo o estado anterior com eventos sequenciais e imutáveis: Com esse padrão de arquitetura as mudanças de "ESTADO" de uma aplicação são armazenadas como uma sequência de eventos IMUTÁVEIS. Em vez de armazenar apenas o estado final dos dados, todas as alterações (eventos) que ocorreram para chegar a esse estado são armazenadas. Isso permite que você reconstrua qualquer estado anterior do sistema simplesmente reaplicando a sequência de eventos.
Um exemplo prático: A Conta Bancária, como pessoa pragmática, acho mais fácil entender conceitos teóricos usando exemplos do mundo real. Neste artigo, explicarei minha exploração do event sourcing usando um subdomínio de Conta Bancária em uma empresa financeira imaginária, um banco.
Por exemplo, em vez de simplesmente atualizar o saldo de uma conta bancária, o sistema registraria eventos como “depósito de 100”, “saque de 50”, “transferência de 200 recebida”, e assim por diante. O estado atual da conta pode ser reconstruído a qualquer momento aplicando essa sequência de eventos na ordem em que ocorreram.
Essa abordagem tem diversas vantagens. Ela garante uma trilha auditável de tudo que aconteceu no sistema, o que é extremamente útil para rastreabilidade, debugging e conformidade. Além disso, permite flexibilidade para construir diferentes projeções ou visualizações dos dados, já que os eventos podem ser reprocessados para gerar outras formas de representar o estado. Também facilita integrações com outras partes do sistema que queiram reagir a eventos, alimentando notificações, logs ou sincronizações com outras bases. Em sistemas altamente distribuídos, especialmente quando usados em conjunto com o padrão CQRS (Command Query Responsibility Segregation), o Event Sourcing se encaixa muito bem, pois separa claramente o que muda os dados (comandos e eventos) do que apenas os consulta (queries e projeções).
Por outro lado, Event Sourcing também traz complexidades. Como os eventos são imutáveis, qualquer mudança de lógica de negócio pode demandar a reinterpretação ou migração de eventos antigos, o que exige cuidado com versionamento de eventos. Além disso, reconstruir o estado de entidades pode se tornar custoso com muitos eventos, exigindo uso de snapshots intermediários. Apesar disso, em sistemas onde a rastreabilidade, auditabilidade e reatividade são prioridades, o Event Sourcing oferece um modelo poderoso e alinhado com a natureza temporal dos dados. Ele muda a forma de pensar o estado: não como algo fixo e mutável, mas como uma consequência acumulada de tudo que já aconteceu.
Como incorporamos o Event Sourcing nos sistemas? Event sourcing muda o paradigma de programação de estados persistentes para eventos persistentes. O armazenamento de eventos é a fonte da verdade.
 |
 |
Embora exista uma certa complexidade, também há grandes benefícios e um leque tecnologico.
O diagrama abaixo mostra uma comparação entre o design de um sistema CRUD tradicional e o design de um sistema de Event Sourcing. Usamos um serviço de pedidos como exemplo:
 |
Vamos ver três exemplos:
-
New York Times - O site do jornal armazena todos os artigos, imagens e assinaturas desde 1851 em uma loja de eventos. Os dados brutos são então desnormalizados em diferentes visões e alimentados em diferentes nós do ElasticSearch para buscas em sites.
-
CDC (Captura de Dados de Alteração) - Um conector CDC extrai dados das tabelas e os transforma em eventos. Esses eventos são empurrados para Kafka e outros sumidoiros consomem eventos de Kafka.
-
Conector de Microsserviço - Também podemos usar o paradigma de event sourcing para transmitir eventos entre microserviços. Por exemplo, o serviço de carrinho de compras gera vários eventos para adicionar ou remover itens do carrinho. O corretor Kafka atua como a loja de eventos, e outros serviços, incluindo o serviço de fraude, o serviço de faturamento e o serviço de e-mail, consomem eventos da loja de eventos. Como os eventos são a fonte da verdade, cada serviço pode determinar o modelo de domínio por conta própria.
O paradigma de Event Sourcing é usado para projetar um sistema com determinismo. Isso altera a filosofia dos projetos de sistemas tradicionais.
Como isso funciona? Em vez de registrar os estados da ordem no banco de dados, o design de event sourcing mantém os eventos que levam às mudanças de estado no armazenamento de eventos. O armazenamento de eventos é um log apenas de anexos. Os eventos devem ser sequenciados com números incrementais para garantir sua ordenação. Os estados da ordem podem ser reconstruídos a partir dos eventos e mantidos no OrderView. Se o OrderView estiver fora do ar, sempre podemos confiar no armazenamento de eventos, que é a fonte de verdade, para recuperar os estados da ordem.
Vejamos os passos detalhados:

Sem Event Sourcing:
- Passos 1 e 2: Bob quer comprar um produto. O pedido é criado e inserido no banco de dados.
- Passos 3 e 4: Bob quer alterar a quantidade de 5 para 6. O pedido é modificado com um novo estado.
Com Event Sourcing:
- Passos 1 e 2: Bob quer comprar um produto. Um evento
NewOrderEventé criado, sequenciado e armazenado no repositório de eventos comeventID=321. - Etapas 3 e 4: Bob deseja alterar a quantidade de 5 para 6. Um evento
ModifyOrderEventé criado, sequenciado e persistido no repositório de eventos comeventID=322. - Etapa 5: A visualização do pedido é reconstruída a partir dos eventos do pedido, mostrando o estado mais recente de um pedido.
Vamos analisar os passos detalhados.
Sourcing Não Evento:
- Passos 1 e 2: Bob quer comprar um produto. A ordem é criada e inserida no banco de dados.
- Passos 3 e 4: Bob quer mudar a quantidade de 5 para 6. A ordem é modificada com um novo estado.
Sourcing de Eventos:
- Passos 1 e 2: Bob quer comprar um produto. Um NewOrderEvent é criado, sequenciado e armazenado no armazenamento de eventos com eventID=321.
- Passos 3 e 4: Bob quer mudar a quantidade de 5 para 6. Um ModifyOrderEvent é criado, sequenciado e mantido no armazenamento de eventos com eventID=322.
- Passo 5: A visualização de ordem é reconstruída a partir dos eventos de ordem, mostrando o estado mais recente de um pedido.
A palavra é sua: qual tipo de sistema é adequado para design de event sourcing? Você já usou esse paradigma em seu trabalho?
A maioria dos aplicativos opera com dados, e o método comum é o programa manter os dados em seu estado atual, atualizando-os quando os usuários interagem com eles. Na arquitetura clássica de criar, ler, atualizar e excluir (CRUD), por exemplo, uma operação típica de dados é receber dados do armazenamento, fazer algumas alterações neles e então atualizar o estado atual dos dados com os novos valores — muitas vezes utilizando transações que travam os dados.
O design de Event Sourcing define um método para lidar com atividades de dados que são acionadas por uma série de eventos, cada um dos quais é registrado em um armazenamento apenas de anexação. O código da aplicação entrega uma série de eventos para o armazenamento de eventos, onde eles são mantidos em manuse, que devem descrever cada ação que ocorreu nos dados. Cada evento descreve uma coleção de mudanças de dados (por exemplo, "AddedItemToOrder").
Os eventos são salvos em um armazenamento de eventos, que serve como sistema de registro (a fonte oficial de dados) para o estado atual dos dados. Esses eventos geralmente são publicados pelo varejista para que os consumidores estejam cientes e possam lidar com eles, se necessário. Os consumidores podem, por exemplo, iniciar tarefas que aplicam as operações dos eventos a outros sistemas, ou podem executar qualquer outra ação associada necessária para concluir o processo. Vale notar que o código da aplicação que gera os eventos é separado dos sistemas que os subscrevem.

Um event-bus é um mecanismo de comunicação baseado em eventos que funciona como um canal central por onde diferentes partes de um sistema enviam e recebem mensagens sem depender diretamente umas das outras. Em vez de um componente chamar o outro de forma direta, criando acoplamento e dependências rígidas, tudo passa pelo barramento: um serviço “publica” um evento e qualquer outro serviço interessado “ouve” esse evento e reage a ele. Isso produz um fluxo muito mais solto, assíncrono e escalável, porque nada precisa saber quem vai consumir a informação; basta emitir o acontecimento e deixar o barramento cuidar da distribuição.
A função essencial do event-bus é organizar essa comunicação assíncrona. Ele recebe eventos — que podem representar mudanças de estado, ações do usuário, comunicação entre microsserviços ou notificações internas — e encaminha tudo para os assinantes corretos. Em sistemas distribuídos, isso significa que um backend pode emitir um evento de “pedido criado”, por exemplo, e vários serviços podem reagir de formas diferentes: um calcula frete, outro atualiza estoque, outro envia e-mail. Nada disso exige que esses serviços se conheçam diretamente, porque o event-bus faz o papel de conector invisível entre todos eles.
Um Event-bus, ou barramento de eventos, é um padrão de arquitetura de software usado para facilitar a comunicação assíncrona entre diferentes partes de um sistema distribuído. Ele permite que os componentes do sistema comuniquem-se entre si sem ter conhecimento direto uns dos outros.
Basicamente, um Event-bus atua como um intermediário entre os vários componentes de um sistema, permitindo que eles publiquem eventos (mensagens, notificações, atualizações etc.) e se inscrevam para receber eventos específicos que são relevantes para eles.
Existem dois tipos principais de Event-bus:
-
Event-bus baseado em mensagens: Neste tipo, os componentes enviam e recebem mensagens assíncronas através de um barramento centralizado. Cada componente pode ser um produtor (enviando eventos) ou um consumidor (recebendo eventos). Exemplos populares incluem Apache Kafka, RabbitMQ e ActiveMQ.
-
Event-bus baseado em publish/subscribe (publicar/inscrever-se): Aqui, os componentes publicam eventos em "tópicos" específicos e outros componentes se inscrevem nos tópicos relevantes para receber esses eventos. Quando um evento é publicado em um tópico, todos os assinantes desse tópico recebem o evento. Exemplos incluem o uso de sistemas de mensagens como MQTT ou tecnologias como Redis Pub/Sub.
O Event-bus é amplamente utilizado em arquiteturas de microsserviços, sistemas distribuídos e ambientes orientados a eventos, pois oferece flexibilidade, escalabilidade e desacopla os componentes do sistema, permitindo que eles evoluam independentemente.
Ao adotar um Event-bus, é essencial planejar cuidadosamente os eventos que serão enviados e recebidos, garantir a confiabilidade na entrega de mensagens e considerar a escalabilidade e o desempenho do sistema como um todo.
Esse padrão é muito usado em arquiteturas orientadas a eventos, tanto em front-ends modernos quanto em plataformas de mensageria robustas. No contexto de aplicações JavaScript, por exemplo, um event-bus interno organiza a comunicação entre componentes sem que eles precisem se referenciar diretamente. Já no universo de microservices, o event-bus costuma ser implementado por ferramentas como RabbitMQ, Kafka, NATS ou SNS/SQS na AWS, que lidam com volume alto, tolerância a falhas, filas persistentes e distribuição confiável.
O event-bus não serve apenas para transportar mensagens; ele também cria uma forma mais saudável de estruturar a arquitetura, reduzindo acoplamento, aumentando testabilidade e facilitando evolução do sistema. Quando tudo gira em torno de eventos, o software passa a ser mais rastreável, auditar o comportamento fica simples, e é possível introduzir novas funcionalidades observando apenas os eventos existentes, sem tocar no código dos serviços que já funcionam. Em essência, o event-bus é o coração silencioso de sistemas modernos baseados em reatividade e comunicação assíncrona, garantindo fluidez, escalabilidade e clareza no fluxo de informações.
Um event-bus não é um microsserviço em si, mas é um padrão arquitetural amplamente usado em microsserviços. Ou seja, ele não é um “tipo de microsserviço”, mas um mecanismo que serve como base para arquiteturas orientadas a eventos dentro de um ecossistema distribuído.
Quando falamos de microsserviços, existem alguns padrões clássicos: API Gateway, Saga, CQRS, Event Sourcing, Backend for Frontend, Sidecar, entre outros. O event-bus se encaixa nessa família como um padrão de mensageria e comunicação assíncrona, funcionando como a “infraestrutura” que permite que os microsserviços troquem informações sem ficarem acoplados.
Em microsserviços, o event-bus ajuda a resolver problemas como dependência direta entre serviços, necessidade de sincronização e dificuldade de escalar fluxos de comunicação. Ele atua como o mediador central por onde todos os eventos passam, garantindo que cada serviço possa emitir informações e reagir apenas ao que lhe interessa. Isso torna a arquitetura mais tolerante a falhas, mais observável e mais fácil de evoluir.
Em resumo, o event-bus faz parte dos padrões fundamentais que sustentam uma arquitetura moderna de microsserviços, mas ele mesmo não é um serviço; é a espinha dorsal de comunicação assíncrona que permite que todo o ecossistema funcione com independência e baixo acoplamento.

Quando comecei a trabalhar com microsserviços, levei a regra comum de "dois serviços não devem compartilhar uma fonte de dados" um pouco literalmente.
Eu vi isso grampeado em todos os lugares da internet: "não compartilharás um banco de dados entre dois serviços", e definitivamente fazia sentido. Um serviço deve possuir seus dados e manter a liberdade de alterar seu esquema como quiser, sem alterar sua API externa.
Mas há uma sutileza importante aqui que eu não entendi até muito mais tarde. Para aplicar essa regra corretamente, temos que distinguir entre compartilhar uma fonte de dados e compartilhar dados.
Por que compartilhar uma fonte de dados é ruim: Um exemplo: o serviço Produtos deve ser o proprietário da tabela e de todos os registros nela. Eles expõem esses dados a outras equipes por meio de uma API, uma consulta GraphQL e a criação desses registros por meio de uma mutation.products products createProduct
O serviço de Produtos tem propriedade sobre a fonte de verdade dos produtos, e nenhuma outra equipe deve entrar em contato diretamente com isso, nunca. Se eles quiserem dados fora dele, eles devem solicitar ao serviço de Produtos por meio do contrato (API) ao qual aderem. Sob nenhuma circunstância você deve permitir acesso direto ao banco de dados ou perderá a liberdade de fazer alterações em seu esquema. Aprendi isso da maneira mais difícil.
Compartilhar dados está OK. O fato é que os serviços precisam de dados que pertencem a outros serviços.
Por exemplo, um serviço de Viagem (Trip service) precisará de acesso a passageiros (do Serviço de Passageiros) e motoristas (do Serviço de Motorista) para fornecer visões gerais de viagens.
O serviço de viagem solicita a cada serviço respectivo seus dados, de forma síncrona, para atender à solicitação original request (). Podemos ter certeza de que os dados são atualizados e o cliente solicitante terá uma visão fortemente consistente dos dados (alguns de vocês podem ver para onde estou indo neste momento ;). getTrips
Esse modelo síncrono de solicitação/resposta para transmitir dados entre microsserviços é um modelo mental muito natural para equipes que começam em microsserviços, pelo menos na minha experiência. Você precisa de alguns dados, sabe onde obtê-los, pede ao serviço proprietário e ele fornece os dados para você, sob demanda.
Além disso, fornecer dados novos e fortemente consistentes foi um acéfalo para as equipes em que eu estava. Dados fortemente consistentes significam dados atualizados, os dados "mais recentes" absolutos, direto da fonte (da verdade). Para mim, naquela época, servir qualquer coisa que não fosse dados consistentes era inaceitável. Como você poderia servir outra coisa além de dados atualizados? Qualquer outra coisa seria uma mentira!
Aplicamos esses padrões como dogma porque não víamos outra maneira e, acima de tudo, parecia natural.
Sincronicidade e consistência forte não escalam. Arquiteturas que dependem muito de solicitações síncronas e consistência forte não são bem dimensionadas. Às vezes, simplesmente não é viável, ou estritamente necessário, sempre ir direto à fonte para suas necessidades de dados.
O exemplo de serviço Trips acima parece legal no início, mas raramente os sistemas permanecem tão simples. Novos serviços nascem e exigirão dados dos serviços existentes. Aderir ao padrão de solicitação síncrona, com o tempo, fará com que você acabe com uma teia emaranhada de solicitações entre serviços. Aqui está um cenário:
Exemplo de fluxo com solicitações síncronas:
- Um usuário concluiu um desafio, executa uma mutação no serviço
ChallengecompleteChallenge - Depois de armazenar a conclusão, o serviço Desafio informa o serviço
Leaderboard, para que ele possa atualizar oleaderboard - O serviço
Leaderboardsolicita ao serviço de usuário nomes de exibição e avatares do usuário para criar o novo estado do placar - O serviço de Classificação vê que há um novo líder no novo estado da tabela de classificação e permite que o serviço de Notificação saiba para que ele possa notificar os participantes de que há um novo líder!
- O serviço de notificação solicita ao serviço do usuário os endereços de e-mail atualizados dos usuários nesse placar específico, para que ele possa enviar e-mails
O serviço ao usuário é claramente um ponto de discórdia aqui: todos dependem de uma forma ou de outra dele. Imagine que este serviço esteja fora do ar: ele também desativará a maioria dos outros serviços. Não apenas isso, mas você terá que manter este servidor aprimorado o tempo todo com mais réplicas e um banco de dados de alto desempenho para acompanhar a demanda.
Além disso, cada salto nessa cadeia de solicitações adiciona latência a toda a solicitação. Cada salto tem o potencial de adicionar uma quantidade exponencial de latência porque cada serviço na cadeia de dependências pode disparar mais de uma solicitação para suas próprias dependências. Antes que você perceba, você atingiu níveis insuportáveis de latência.
Por fim, cada dependência adicional na cadeia de solicitações aumenta a probabilidade de falha de toda a cadeia de solicitações. Em uma cadeia de solicitações envolvendo cinco serviços com um SLA de 99,9% (~9h de tempo de inatividade anual), o SLA composto se torna 99,5%. São quase 2 dias de inatividade por ano!
Podemos evitar todas essas desvantagens fazendo uma pergunta: os serviços realmente precisam de dados atualizados?
O serviço de notificação (etapa 5) provavelmente faz. Se um usuário alterar seu endereço e o serviço de notificação não souber, correrá o risco de enviar um e-mail para o endereço errado e não receber a notificação para o usuário pretendido.
O serviço Leaderboard, por outro lado, provavelmente não precisa de nomes de exibição e avatares atualizados para construir a tabela de classificação - não é grande coisa se os usuários virem avatares ou nomes de exibição obsoletos.
Como você pode ver, os serviços têm diferentes necessidades de consistência de dados. Existem compensações que podemos usar como alavanca para aplicar diferentes métodos de compartilhamento de dados e construir um sistema distribuído mais robusto.
Insira a consistência eventual. Foi nesse ponto da minha carreira que descobri que os serviços podem manter uma cópia dos dados de outros serviços, localmente em suas próprias tabelas de banco de dados. Ele vem com a responsabilidade de reter esses dados por meio de eventos ou pesquisas.
Incluído neste pacote está o fato de que os dados podem ficar obsoletos por algum tempo, mas que eventualmente serão atualizados, o que significa que os dados são eventualmente consistentes. Não podemos garantir que os dados não estejam obsoletos, mas podemos garantir que eventualmente nos atualizaremos.
O momento em que "clicou" para mim foi quando pensei nisso da perspectiva de um serviço de back-end que depende de uma API meteorológica pública para dados meteorológicos. Em vez de recuperar dados meteorológicos de Pristina ou Berlim toda vez que um usuário dessas respectivas cidades precisa de dados meteorológicos, eu os armazeno em cache (talvez várias vezes ao dia) materializando-os em uma tabela local e servindo dados em cache para esses usuários. Fiz a troca em favor da consistência eventual porque não é crucial para meus usuários ver os dados mais recentes, tudo bem se estiverem algumas horas obsoletos.
Voltando ao exemplo do Desafio: podemos cortar muitas dependências síncronas para o serviço do usuário apenas mantendo uma cópia local dos usuários nos serviços:
- O serviço de placar pode manter uma cópia local dos usuários e evitar a necessidade de fazer solicitações ao serviço do usuário. Ninguém realmente se importa se os dados são um pouco antigos, não é um empecilho se alguém vir um avatar um pouco antigo.
- O serviço de desafio pode fazer o mesmo; digamos que se ele expôs uma consulta e precisou de nomes de exibição e avatares de usuário para mostrar os participantes atuais do desafio - ele também pode fornecer esses dados eventualmente consistentes de sua própria tabela de usuários materializados.getChallengeDetails
- O serviço de notificação, embora um pouco mais sensível, também pode utilizar o compartilhamento de dados para remover sua dependência do serviço Usuários. Ele pode materializar os usuários localmente e manter um estado atualizado de melhor esforço ouvindo os eventos atualizados pelo usuário para garantir que ele tenha os e-mails mais atualizados.
Embora não tenhamos falado muito sobre como os serviços compartilham esses dados (um tópico para outra hora), uma arquitetura de exemplo final usaria uma combinação de fornecimento de eventos e armazenamento em cache. Aqui está uma prévia de como seria esse tipo de arquitetura:
Exemplo de arquitetura com dois métodos principais de compartilhamento de dados entre serviços: fornecimento de eventos e cache
Se você quiser mais exemplos, dê uma olhada em Como compartilhar dados entre microsserviços em alta escala por Shiran Metsuyanim, engenheiro da Fiverr. É um ótimo post que mostra como manter a robustez ao adicionar um novo serviço. Ele começa estabelecendo as restrições e, em seguida, discutindo as compensações entre soluções síncronas, assíncronas e híbridas.
Conclusão, eu queria transmitir esse ponto aos desenvolvedores que, como eu há alguns anos, estão presos no sentido literal de "não compartilhe dados", mas devem perceber que isso só se aplica a não compartilhar a fonte da verdade. Manter uma cópia dos dados de um serviço no domínio de outro serviço é perfeitamente aceitável e abrange o espírito de consistência eventual.
Simplesmente, quando sua API publica mensagens de evento, ela não as envia diretamente. Em vez disso, as mensagens são mantidas em uma tabela de banco de dados. Depois disso, um trabalho publica eventos no sistema do agente de mensagens em intervalos de tempo predefinidos.
Basicamente, o padrão de caixa de saída (Outbox Pattern) fornece a publicação de eventos de forma confiável. A ideia dessa abordagem é ter uma tabela "Caixa de saída" no banco de dados do microsserviço.
Nesse método, os eventos de domínio não são gravados diretamente em um barramento de eventos. Em vez disso, ele é gravado em uma tabela na função "caixa de saída" do serviço que armazena o evento em seu próprio banco de dados.
No entanto, o ponto crítico aqui é que a transação executada antes do evento e o evento gravado na tabela da caixa de saída fazem parte da mesma transação.
Por exemplo, quando um novo produto é adicionado ao sistema, o processo de adicionar o produto e gravar o evento ProductCreated na tabela da caixa de saída é feito na mesma transação, garantindo que o evento seja salvo no banco de dados.
A segunda etapa é receber esses eventos gravados na tabela de caixa de saída por um serviço independente e gravá-los no barramento de eventos.
Como você pode ver na imagem acima, o serviço Order executa suas operações de caso de uso e atualiza sua própria tabela e, em vez de publicar um evento, ele escreve outra tabela com esse registro de evento e esse evento é lido de outro serviço e publica um evento.
Por que usamos este padrão de caixa de saída? Se você estiver trabalhando com dados críticos que precisam ser consistentes e precisos para capturar todas as solicitações, é bom usar o padrão Caixa de saída. Se no seu caso, a atualização do banco de dados e o envio da mensagem devem ser atômicos para garantir a consistência dos dados, é bom usar o padrão de caixa de saída.
Por exemplo, as transações de venda de pedidos, já está claro o quão importantes são esses dados. Porque eles são sobre negócios financeiros. Assim, os cálculos devem estar 100% corretos. Para poder acessar essa precisão, devemos ter certeza de que nosso sistema não está perdendo nenhuma mensagem de evento. Portanto, o padrão de caixa de saída deve ser aplicado neste tipo de casos.
Portanto, devemos evoluir nossa arquitetura com a aplicação de outros padrões de dados de microsserviços para acomodar adaptações de negócios, tempo de lançamento no mercado mais rápido e lidar com solicitações maiores.
O streaming é um dos padrões (patterns) usados em arquiteturas de microservices. É particularmente útil para cenários onde os dados precisam ser processados em tempo real ou quase real, permitindo uma comunicação eficiente e contínua entre serviços. O streaming é um padrão fundamental em arquiteturas de microservices, especialmente útil para casos que exigem processamento de dados em tempo real, baixa latência e alta escalabilidade. Ao utilizar sistemas de mensageria e plataformas de streaming de eventos, é possível construir sistemas reativos, escaláveis e resilientes, capazes de lidar com grandes volumes de dados e alta taxa de eventos de maneira eficiente.
Padrões de Streaming em Microservices:
-
Event Streaming: Serviços produzem eventos que são transmitidos para outros serviços em tempo real. Isso é frequentemente implementado usando sistemas de mensageria ou de streaming de eventos como Apache Kafka, RabbitMQ, ou Amazon Kinesis. Casos de Uso: Monitoramento em tempo real, análise de dados em tempo real, atualização de caches distribuídos, etc.
-
Data Streaming: Dados são continuamente transmitidos entre serviços. Pode envolver a transmissão de grandes volumes de dados de forma eficiente, dividindo-os em pequenos chunks. Casos de Uso: Streaming de mídia (vídeo, áudio), sincronização de bases de dados, processamento contínuo de dados de sensores IoT.
Vantagens do Streaming em Microservices:
- Baixa Latência: Permite a comunicação em tempo real, essencial para aplicações que exigem respostas rápidas.
- Escalabilidade: Facilita a escalabilidade horizontal, permitindo que diferentes partes do sistema processem fluxos de dados em paralelo.
- Desacoplamento: Promove o desacoplamento entre serviços, onde produtores e consumidores de eventos/dados não precisam estar diretamente conectados.
Ferramentas Comuns para Streaming:
- Apache Kafka: Uma plataforma distribuída de streaming de eventos que permite a publicação e assinatura de fluxos de registros, armazenamento de fluxos de registros de maneira tolerante a falhas e processamento de fluxos de registros em tempo real.
- RabbitMQ: Um broker de mensagens que suporta a transmissão de mensagens de forma confiável entre produtores e consumidores.
- Amazon Kinesis: Uma plataforma gerenciada para streaming de dados em tempo real na AWS.
- Apache Flink e Apache Spark Streaming: Ferramentas para processamento de fluxos de dados em tempo real, permitindo a análise e transformação de dados em movimento.
Exemplos de Padrões de Streaming em Microservices:
-
Log Aggregation: Coletar logs de diferentes serviços e transmiti-los para um serviço central para armazenamento e análise. Ferramenta Comum: Apache Kafka.
-
Event Sourcing: Armazenar o estado do sistema como uma sequência de eventos. Cada mudança no estado gera um novo evento que é transmitido. Ferramenta Comum: Event Store, Apache Kafka.
-
CQRS (Command Query Responsibility Segregation) com Streaming: Usar um modelo separado para comandos (escrita) e consultas (leitura), onde as mudanças são propagadas através de eventos transmitidos para diferentes modelos de leitura. Ferramenta Comum: Apache Kafka, RabbitMQ.
-
Real-Time Analytics: Processamento contínuo de dados para gerar insights e análises em tempo real. Ferramenta Comum: Apache Flink, Apache Spark Streaming.
Os padrões de design são soluções reutilizáveis para problemas comuns no design de software. Eles fornecem uma abordagem estruturada para resolver desafios arquitetônicos sem reinventar a roda a cada vez.
O padrão sidecar é um desses padrões de design que ganhou destaque na engenharia de software moderna. Em sua essência, o padrão sidecar combina um processo ou serviço secundário (o "sidecar") com um aplicativo primário para lidar com tarefas complementares. Essas tarefas incluem registro em log, monitoramento, proxy, segurança ou gerenciamento de configuração. O sidecar é executado junto com o aplicativo principal, compartilhando o mesmo host ou contêiner, mas permanece lógica e operacionalmente independente.
O padrão sidecar pode ser comparado a uma motocicleta com um sidecar. A motocicleta (o serviço principal) é o principal motorista, responsável pela funcionalidade principal, como transportar uma pessoa. O sidecar (o serviço auxiliar) transporta ferramentas ou passageiros adicionais, auxiliando o veículo principal sem interferir em sua operação.
Da mesma forma, em sistemas de software, o sidecar estende os recursos do aplicativo principal sem ser fortemente acoplado a ele.
Serviços de monitoramento, registro, configuração e rede são frequentemente exigidos por aplicações e serviços. Essas tarefas extras podem ser realizadas como componentes ou serviços distintos.
Um serviço de sidecar nem sempre faz parte da aplicação, mas está vinculado a ele. Ele segue o aplicativo principal para onde quer que vá. Sidecars são procedimentos ou serviços que são oferecidos junto com a aplicação principal. O sidecar de uma motocicleta é acoplado a uma motocicleta, e cada motocicleta pode ter seu próprio sidecar. Um serviço de sidecar, da mesma forma, reflete o destino de sua aplicação principal. Uma instância sidecar é implantada e hospedada junto com cada instância da aplicação.
Eles podem ser executados no mesmo processo que a aplicação se estiverem fortemente integrados, fazendo uso ótimo dos recursos compartilhados. Isso, no entanto, implica que eles não estão devidamente separados, e uma falha em um desses componentes pode afetar outros componentes ou toda a aplicação. Além disso, normalmente devem ser escritos no mesmo idioma do programa principal. Como resultado, o componente e a aplicação dependem muito um do outro.


Circuit breaker, ou disjuntor em português, é um padrão de design utilizado em sistemas distribuídos, principalmente em arquiteturas baseadas em microserviços, para lidar com falhas temporárias e evitar sobrecargas em serviços instáveis ou fora do ar. A ideia central é inspirada nos disjuntores elétricos: quando um circuito apresenta falha ou sobrecarga, o disjuntor desarma para impedir danos maiores; da mesma forma, em software, o circuit breaker monitora chamadas remotas e, ao detectar uma quantidade excessiva de falhas consecutivas, ele "abre" o circuito, interrompendo temporariamente as tentativas de comunicação com o serviço problemático. Padrão de disjuntor: proteja seus microsserviços contra falhas em cascata.
Inspirando-se nos disjuntores elétricos, em sistemas de software, objetos disjuntores funcionam de forma semelhante, interrompendo automaticamente o fluxo de solicitações quando anomalias são detectadas. Ele está situado entre o atendimento e o serviço de chamada. O disjuntor 'desliga' quando o interlocutor não está disponível. Esse mecanismo não só previne danos adicionais, mas também permite que o tempo de falha se recupere.
Enquanto o circuito está aberto, as tentativas de acesso ao serviço são bloqueadas de imediato, evitando que a aplicação continue enviando requisições inúteis que só iriam falhar e consumir recursos preciosos. Após um intervalo de tempo pré-definido (geralmente chamado de timeout), o circuito entra em estado de teste (half-open), permitindo algumas chamadas para verificar se o serviço voltou ao normal. Se as tentativas forem bem-sucedidas, o circuito é fechado e o serviço volta a receber tráfego normalmente. Se falhar novamente, o circuito permanece aberto, protegendo o sistema de novos colapsos.
Esse padrão é fundamental para manter a resiliência e a estabilidade de sistemas que dependem de muitos serviços externos ou internos, especialmente em contextos onde a indisponibilidade de um componente pode provocar efeito cascata, travando partes críticas da aplicação. O circuit breaker ajuda a degradar o sistema de forma controlada, oferecendo respostas rápidas de fallback ao invés de deixar os usuários esperando por tempo de resposta indefinido.
Na arquitetura de microserviços, comunicar-se por meio de chamadas remotas de procedimentos e dependências de API a jusante introduz uma camada de complexidade onde erros transitórios podem ocorrer devido a problemas de rede ou o serviço pode falhar por qualquer motivo, como interrupção de rede, sobrecarga do sistema, travamento, etc.
Nessa situação, é muito importante desconectar os componentes/serviços que estão falhando e não solicitar mais informações sabendo que estão falhando no momento, permitindo que o sistema se recupere. Um componente de disjuntor pode facilmente desconectar serviços que falharam a jusante.
- O fracasso que não ficou contido: Começou, como essas coisas costumam acontecer, com um gráfico um pouco estranho. Um serviço a jusante foi mais lento que o normal — não foi para baixo, apenas lento. Nenhum alerta disparado. As taxas de erro estavam boas. Mas em poucos minutos, os painéis de serviços não relacionados começaram a ficar âmbar, depois vermelhos. Latências aumentaram lentamente. Piscinas de fios preenchidas. Tentativas se acumulavam sobre chamadas já lentas. De repente, o problema não era mais aquele serviço — era tudo.
O que tornava tudo doloroso em retrospecto era o quão previsível era. Nada exótico falhou. Sem falha no data center. Apenas uma dependência sendo lenta, permitida continuar prejudicando seus chamadores. Este artigo não é sobre prevenir falhas completamente. É sobre contê-los. Disjuntores não são uma solução mágica. Eles são uma forma de impedir que uma interação ruim arraste uma plataforma inteira para baixo.

- Como as falhas em cascata realmente acontecem: A maioria das falhas em cascata não é misteriosa. Eles são mecânicos.
Imagine uma cadeia simples: Serviço A → Serviço B → Serviço C
O serviço C desacelera — talvez um problema no banco de dados, talvez pressão do GC. O serviço B chama C sincronizadamente, espera
Important
O livro de Michael Nygard, Release It!, popularizou o padrão Circuit Breaker, que pode impedir que um aplicativo tente executar continuamente uma ação que provavelmente falhará, permitindo que ele prossiga sem esperar a correção do problema ou gastar ciclos de CPU para determinar a duração da falha. “Release It! – Second Edition”, do Michael T. Nygard, é um dos livros mais importantes sobre como projetar, construir e operar sistemas realmente prontos para produção. O tema central não é apenas código, mas como softwares se comportam no mundo real, onde falhas acontecem, tráfego cresce inesperadamente, dependências externas quebram e a infraestrutura reage de formas imprevisíveis.
O padrão de disjuntor também permite que a aplicação determine se o problema foi resolvido ou não. Se o problema parecer resolvido, o programa pode tentar realizar a operação.
O padrão Disjuntor serve a um propósito distinto do padrão Retry. O padrão Retry permite que uma aplicação tente novamente uma operação na esperança de que ela tenha sucesso na próxima vez.
O design do Disjuntor proíbe que uma aplicação realize uma atividade de risco. Uma aplicação pode usar o padrão Retry para acionar uma ação através de um disjuntor e combinar esses dois padrões. A lógica de retentativa, por outro lado, deve estar alerta para quaisquer exceções fornecidas pelo disjuntor e deve cessar as tentativas repetidas se o disjuntor indicar que a falha não é temporária.
Ferramentas como Hystrix (da Netflix), Resilience4j, Polly (para .NET) e algumas implementações no Spring Cloud oferecem suporte a esse padrão, muitas vezes combinando com retries, timeouts e mecanismos de fallback para formar uma estratégia robusta de tolerância a falhas. Em suma, o circuit breaker permite que aplicações sobrevivam em ambientes imprevisíveis, garantindo que uma falha localizada não se torne um problema sistêmico.
Você está preocupado com o efeito cascata de falhas em sua arquitetura de microsserviços? Conheça o padrão de disjuntor - sua proteção definitiva contra falhas em cascata. Esse padrão monitora falhas e impede que as solicitações cheguem a um serviço com falha, dando tempo para se recuperar e protegendo todo o sistema contra colapso.
Por que você deve implementar o padrão de disjuntor? Em um ecossistema de microsserviços, um único serviço com defeito pode causar um efeito dominó, interrompendo outros serviços que dependem dele. Ao usar disjuntores, você pode isolar o serviço defeituoso e evitar mais danos, garantindo a resiliência e a estabilidade do seu sistema.
Os disjuntores podem ser facilmente implementados usando bibliotecas como Netflix, Hystrix e Resilience4j. Essas bibliotecas oferecem uma variedade de recursos, como métodos de fallback e monitoramento, para ajudá-lo a gerenciar e se recuperar de falhas com eficiência.
Em essência, o padrão de disjuntor é essencial para a criação de microsserviços resilientes e tolerantes a falhas. Ao incorporar esse padrão em sua arquitetura, você pode efetivamente proteger seu sistema contra os efeitos adversos de falhas de serviço. Você está pronto para fortalecer seus microsserviços com o padrão de disjuntor?

Onion Architecture é um padrão de design de software e foi introduzido por Jeffrey Palermo em 2008 como uma alternativa para abordar algumas das limitações e problemas de outras arquiteturas tradicionais, como a arquitetura em camadas. A Onion Architecture promove uma maior separação de preocupações e independência das dependências externas, como frameworks e bibliotecas.
A Onion Architecture é um poderoso padrão de design que promove a separação de preocupações e a independência de tecnologia, facilitando a criação de sistemas mais flexíveis, testáveis e manuteníveis. Ela é especialmente útil em ambientes de desenvolvimento complexos e de rápida mudança, onde a capacidade de adaptar e evoluir o sistema é crucial.
A arquitetura Onion pode ser utilizada em uma arquitetura de microsserviços. Na verdade, muitos dos princípios da Onion Architecture se alinham bem com os objetivos e práticas de desenvolvimento de microsserviços. A Onion Architecture pode ser uma abordagem eficaz para estruturar microsserviços, promovendo um design desacoplado, testável e fácil de manter. Ao aplicar os princípios da Onion Architecture, cada microsserviço pode ser desenvolvido de forma independente, mantendo a lógica de negócios centralizada e livre de dependências externas desnecessárias.
Principais Conceitos da Onion Architecture:
-
Camadas Concêntricas: A arquitetura é visualizada como um conjunto de camadas concêntricas, onde cada camada depende apenas das camadas mais internas, nunca das camadas externas. As dependências fluem para dentro, não para fora.
-
Domínio no Centro: O núcleo da arquitetura é o domínio. Isso inclui as entidades de negócio e as regras de negócio. O domínio é completamente independente de detalhes externos como bancos de dados, interfaces de usuário ou serviços.
-
Independência de Tecnologia: Detalhes de implementação, como frameworks de persistência, interfaces de usuário e outros serviços externos, são mantidos nas camadas mais externas, permitindo que a lógica de negócio permaneça livre de dependências técnicas.
Estrutura da Onion Architecture:
-
Camada de Domínio (Core):
- Entidades: Classes que representam o modelo de domínio e encapsulam as regras de negócio.
- Serviços de Domínio: Serviços que contêm lógica de negócio que não pertence a nenhuma entidade específica.
-
Camada de Aplicação: Casos de Uso: Contém a lógica de aplicação que orquestra o uso das entidades de domínio para atender a um caso de uso específico. Não contém lógica de negócio em si, mas coordena operações entre diferentes partes do domínio.
-
Camada de Interface (Application Interfaces): Interfaces: Define contratos (interfaces) para serviços externos, como repositórios de dados, serviços de mensagem, etc. As implementações dessas interfaces ficam em uma camada ainda mais externa.
-
Camada de Infraestrutura: Implementações: Contém as implementações reais das interfaces definidas na camada de aplicação. Isso inclui detalhes específicos de tecnologia, como acesso a banco de dados, serviços de mensageria, etc.
Benefícios da Onion Architecture:
-
Desacoplamento: Permite que a lógica de negócio seja desacoplada de detalhes técnicos e frameworks, tornando o sistema mais flexível e testável.
-
Testabilidade: As camadas internas (domínio e aplicação) podem ser testadas isoladamente sem a necessidade de dependências externas, facilitando a escrita de testes unitários.
-
Manutenibilidade: Com uma separação clara de responsabilidades, a manutenção do código se torna mais fácil, pois as mudanças em uma camada (por exemplo, detalhes de acesso a dados) não afetam outras camadas (como a lógica de negócio).
Comparação com Outras Arquiteturas:
-
Arquitetura em Camadas (Layered Architecture): Embora a arquitetura em camadas também tenha uma separação de preocupações, ela não impõe a mesma direção de dependência. Em uma arquitetura em camadas tradicional, a camada de apresentação pode ter dependências diretas na camada de persistência, o que não é o caso na Onion Architecture.
-
Arquitetura Hexagonal (Ports and Adapters): Muito semelhante à Onion Architecture, a arquitetura hexagonal também promove a separação de lógica de negócio das dependências externas. A principal diferença é na terminologia e na ênfase no uso de "portas" e "adaptadores" para representar interfaces e implementações externas.
Exemplo de Implementação: Suponha um sistema de gerenciamento de pedidos:
-
Domínio:
- Entidade Pedido: Representa um pedido com propriedades como ID, lista de itens, status, etc.
- Serviço de Domínio PedidoService: Contém lógica de negócio, como criação de pedidos, cancelamento, etc.
-
Aplicação:
- Caso de Uso CriarPedidoUseCase: Orquestra a criação de um pedido, utilizando as entidades e serviços do domínio.
-
Interfaces:
- PedidoRepository: Interface para persistência de pedidos.
- NotificacaoService: Interface para envio de notificações.
-
Infraestrutura:
- PedidoRepositoryImpl: Implementação do repositório utilizando um banco de dados específico.
- NotificacaoServiceImpl: Implementação do serviço de notificação utilizando um serviço de e-mail externo.

O DDD - Domain-Driven Design (Projeto Orientado a Domínio) é uma abordagem de desenvolvimento de software que se concentra em entender o domínio do negócio e modelar o software em torno desses conceitos e regras de negócio. É um tipo de modelagem de software e um design de software orientado a objetos (OOP) que procura reforçar conceitos e boas práticas relacionadas à OOP e surgiu como uma resposta às dificuldades enfrentadas por desenvolvedores ao lidarem com sistemas complexos, especialmente em domínios de negócio onde a lógica e os requisitos mudam frequentemente.
Isso vem em contrapartida com o uso comum do Data-Driven Design (Projeto Orientado a Dados), que a maioria dos desenvolvedores usa sem mesmo ter consciência disso. O design orientado por domínio (DDD) é uma abordagem importante de design de software, focada em modelar software para corresponder a um domínio de acordo com a contribuição dos especialistas desse domínio. A DDD é contra a ideia de ter um modelo unificado único; em vez disso, divide um grande sistema em contextos limitados, cada um com seu próprio modelo.
Sem levar em conta o DDD, as técnicas de modelagem de domínio são métodos utilizados na engenharia de software para compreender e representar o domínio de um problema específico.
O domínio (domain) refere-se à área de conhecimento, contexto ou setor de negócios em que o software está sendo desenvolvido. A modelagem de domínio tem como objetivo capturar os conceitos, regras e relacionamentos do domínio em um formato compreensível e utilizável pelos desenvolvedores. Então, o DDD (Domain-Driven Design) é uma abordagem para o desenvolvimento de software que combina conceitos de design de software e técnicas de modelagem de domínio.
Não é considerado um design pattern específico, mas sim uma abordagem geral para projetar e estruturar sistemas de software. Domain-Driven Design (DDD) é um método de design de software em que os desenvolvedores constroem modelos para entender os requisitos de negócios de um domínio. Esses modelos servem como base conceitual para o desenvolvimento de software.
O termo foi cunhado por Eric Evans em seu livro de mesmo nome, publicado em 2003. No entanto, a definição mais simples que encontrei foi ao ler o livro Fundamentals of Software Architecture de Neal Ford e Mark Richards:
O design orientado a domínio (DDD) é uma técnica de modelagem que permite a decomposição organizada de domínios de problemas complexos. - Neal Ford e Mark Richards. Fundamentos da Arquitetura de Software. 2020.
Eric Evans cunhou o termo Domain-Driven Design (DDD) como parte do título de seu livro de 2004, Domain-Driven Design: Tackling Complexity in the Heart of Software.
Important
Foi popularizado por Eric Evans em seu livro Domain-Driven Design: Tackling Complexity in the Heart of Software, publicado em 2003. Esse livro não é leve, especialmente se você ainda está no início da jornada. Ele exige uma certa base em desenvolvimento orientado a objetos (OOP), arquitetura de software e experiência prática com projetos reais. Geralmente, ele é mais proveitoso depois que você já trabalhou em sistemas mais complexos ou com arquitetura em camadas. O Design Orientado por Domínio (DDD) ganhou atenção significativa no desenvolvimento de software por seu potencial de enfrentar desafios complexos de software, especialmente nas áreas de refatoração de sistemas, reimplementação e adoção. Utilizando o conhecimento do domínio, o DDD visa resolver problemas de negócios complexos de forma eficaz.
Embora o design orientado a domínio (DDD) exista desde 2004, o conceito não foi capaz de se espalhar excessivamente em todo esse tempo. Nos últimos anos, no entanto, o termo experimentou uma segunda primavera. Onde o desenvolvimento de software não é um fim em si mesmo. Em vez disso, o software é desenvolvido para resolver problemas técnicos do mundo real. Isso requer tecnologia, mas esse não é o foco, é apenas um meio para um fim. O foco real está no assunto, o domínio (domain)! Portanto, uma boa compreensão disso é essencial para um desenvolvimento bem-sucedido e direcionado.
Sob design orientado por domínio, a estrutura e a linguagem do código de software (nomes de classes, métodos de classe, variáveis de classe) devem corresponder ao domínio de negócio. Por exemplo: se o software processa solicitações de empréstimo, pode ter classes como "solicitação de empréstimo", "clientes" e métodos como "aceitar oferta" e "retirar".
DDD só funciona plenamente quando anda alinhado com design de software, design de sistemas e arquitetura, não porque eles sejam a mesma coisa, mas porque o DDD sozinho não consegue se sustentar sem uma estrutura técnica que dê corpo às suas ideias. O ponto central é que o Domain-Driven Design é uma abordagem profundamente conceitual: ele organiza o pensamento sobre o domínio, define limites claros, introduz linguagens específicas, identifica contextos independentes e estabelece modelos consistentes.
Só que tudo isso precisa inevitavelmente se materializar em código, fluxos, integrações, decisões de infraestrutura, modularização e comunicação entre serviços. Se esse materializar não acompanha a lógica do domínio, o DDD implode, ou vira apenas documentação bonita.
O objetivo do DDD é, em primeiro lugar, adquirir conhecimento sobre o problema para identificar a solução. Em seguida, concordaremos com os vários componentes desta solução para implementá-la. Esse objetivo é alcançado por meio dos padrões fundamentais do DDD: padrões estratégicos e táticos. Os padrões estratégicos respondem à pergunta: "Por que estamos construindo este software e quais são seus componentes?". Por outro lado, os padrões táticos dão a resposta à pergunta: "Como esses componentes são implementados?"
Portanto, o design orientado por domínio baseia-se nos seguintes objetivos:
- Colocando o foco principal do projeto no domínio central e na camada de lógica de domínio;
- Basear projetos complexos em um modelo do domínio;
- Iniciando uma colaboração criativa entre especialistas técnicos e especialistas do domínio para refinar iterativamente um modelo conceitual que aborde problemas específicos do domínio.
 |
 |
 |
 |
Design Orientado por Domínio Defensores do design orientado por domínio que impulsionam o design de softwares por meio da modelagem de domínio.
Linguagem unificada é um dos conceitos-chave do design orientado por domínio. Um modelo de domínio é uma ponte entre os domínios de negócios.
Business Entities: O uso de modelos pode ajudar a expressar conceitos e conhecimentos de negócios e a orientar o desenvolvimento futuro de softwares, como bancos de dados, APIs, etc.
Model Boundaries: Limites frouxos entre conjuntos de modelos de domínio são usados para modelar correlações de negócios.
Aggregation: Um Agregado é um agrupamento de objetos relacionados (entidades e objetos de valor) que são tratados como uma única unidade para fins de alterações de dados.
Entities vs. Value Objects: de Valor Além de raízes agregadas e entidades, existem alguns modelos que parecem descartáveis, eles não possuem seu próprio ID para identificá-los, mas são mais parte de alguma entidade que expressa uma coleção de vários campos.
Operational Modeling: Operacional No design orientado por domínio, para manipular esses modelos, há vários objetos que atuam como "operadores".
Camadas da arquitetura: Para organizar melhor os diversos objetos em um projeto, precisamos simplificar a complexidade de projetos complexos ao sobrepê-los como uma rede de computadores.
Construa o modelo de domínio Muitos métodos foram inventados para extrair modelos de domínio a partir do conhecimento de negócios.
Important
Em seu livro Clean Architecture: A Craftsman's Guide to Software Structure and Design, Uncle Bob chama uma arquitetura que informa ao leitor sobre o sistema, não as estruturas usadas no sistema, de "Arquitetura Gritante". Em A Arquitetura Limpa: O Guia do Artesão para Estrutura e Design de Software, Martin vai além de um simples catálogo de opções. Com base em mais de meio século de experiência em diversos ambientes de software, ele oferece orientações sobre as escolhas cruciais e explica por que são essenciais para o sucesso. Como esperado de Uncle Bob, o livro apresenta soluções simples e diretas para os desafios reais enfrentados pelos desenvolvedores, desafios que podem determinar o êxito ou o fracasso de seus projetos.
Então, faz sentido para mim pensar em design de software como design gritante quando fala alto e claro sobre o domínio do problema. Geralmente, o ativo mais crítico no design de uma solução é adquirir conhecimento sobre os problemas que estamos tentando resolver, o processo que queremos automatizar ou as dificuldades que queremos facilitar. Então, para nos aproximarmos da solução, tínhamos que já estar próximos do problema.
Falaremos sobre a maneira de se aproximar do problema e da solução: o caminho do Domain-Driven Design (DDD) em direção a um design gritante, o design que informa ao leitor sobre o domínio do negócio, não sobre os frameworks usados.
Warning
Quando não usar DDD? Às vezes só é necessário um CRUD (entrega de um produto funcional)! DDD não é uma solução para tudo. A maioria dos sistemas possui uma boa parte composta por cadastros básicos (CRUD) e não seria adequado usar DDD para isso. A engenharia de domínios tem sido criticada por focar demais em "engenharia para reutilização" ou "engenharia com reutilização" de recursos genéricos de software, em vez de se concentrar em "engenharia para uso", de modo que a visão de mundo, linguagem ou contexto de um indivíduo seja integrado ao design do software. Um CRUD é praticamente o estágio MVP funcional, voltado a registrar, atualizar e consultar informações, geralmente com baixo acoplamento conceitual e alto acoplamento técnico. Você descreve tabelas, cria endpoints, faz o básico para o sistema existir. Ele resolve o problema imediato, mas não escala bem quando as regras começam a se multiplicar, quando várias áreas de negócio influenciam o mesmo fluxo ou quando múltiplos times precisam trabalhar em partes diferentes da solução sem se bloquear. Então, depende da complexidade do projeto e das regras de negócio.
Tip
Já o DDD é “nível engenharia” (entrega de um produto sustentável, capaz de sobreviver à complexidade, a mudanças constantes, a regras de negócio extensivas e a um ciclo de vida longo), porque exige que o desenvolvedor deixe de pensar apenas como codificador e passe a operar como analista de domínio, arquiteto e estrategista ao mesmo tempo. É necessário entender profundamente o negócio, descobrir limites contextuais, refinar invariantes, identificar agregados, modelar comportamentos, conversar com especialistas e traduzir tudo isso para uma arquitetura mais sólida, isolada e resiliente, geralmente integrada com abordagens como Clean Architecture, Hexagonal, Onion, EDA, CQRS, Event Sourcing e microsserviços.
Você aplica DDD quando a complexidade do domínio começa a crescer a ponto de inviabilizar soluções lineares ou meramente CRUD. Ele se torna realmente vantajoso quando você precisa que o software represente fielmente regras de negócio dinâmicas, mutáveis e distribuídas, principalmente em arquiteturas mais sofisticadas como microsserviços, BFF, EDA, Hexagonal, Clean Architecture, Onion ou Tomato. Nessas abordagens, há múltiplos contextos, integrações, fluxos assíncronos, eventos, fronteiras claras e times diferentes trabalhando sobre partes distintas do sistema; tudo isso exige linguagem ubíqua, modelagem explícita, separação de responsabilidades e decisões guiadas pelo domínio. Em sistemas simples, centralizados ou puramente transacionais, DDD vira peso morto, mas em cenários complexos ele traz clareza, previsibilidade e alinhamento entre tecnologia e negócio, evitando entropia arquitetural e facilitando evolução contínua.
Por isso, ele é usado quando a aplicação deixa de ser “só um sistema” e passa a ser um ecossistema vivo, com equipe, visão de produto, múltiplos contextos e evolução contínua. É literalmente a fronteira entre “programação” e “engenharia de software aplicada ao domínio”.
No entanto, críticos do design orientado por domínio argumentam que os desenvolvedores normalmente precisam implementar uma grande quantidade de isolamento e encapsulamento para manter o modelo como uma construção pura e útil. Embora o design orientado por domínio ofereça benefícios como manutenção, a Microsoft o recomenda apenas para domínios complexos onde o modelo oferece benefícios claros na formulação de uma compreensão comum do domínio.
A exigência de construir um entendimento profissional também se aplica aos desenvolvedores. Uma boa compreensão do assunto (domínio) surge da comunicação regular e de uma linguagem comum, o que representa um desafio, principalmente em equipes interdisciplinares: Afinal, cada disciplina tem sua linguagem técnica, por isso os mal-entendidos são inevitáveis.

Num Code Review, o time não está apenas olhando se o código “funciona”, mas se ele está legível, sustentável e alinhado ao domínio. É aí que DDD se torna um guia. Por exemplo, quando você define entidades e value objects, o revisor consegue avaliar se você está representando o domínio corretamente ou se misturou regras de negócio com detalhes de infraestrutura. Se você trabalha com bounded contexts, o code review ajuda a garantir que cada módulo está respeitando suas fronteiras e não está acoplando responsabilidades que deveriam estar separadas. E quando se usa a linguagem ubíqua, qualquer pessoa envolvida no projeto pode bater o olho no código e identificar termos familiares do negócio, reduzindo ambiguidades.
A ideia central é trazer o domínio (o sujeito, a razão) à tona...O DDD acaba aparecendo muito em code reviews (revisões de código) porque ele não é só um conjunto de padrões técnicos, mas uma maneira de organizar o raciocínio e o design do sistema a partir do domínio de negócio. Diferente de TDD e BDD, que são mais voltados ao como testar e como validar comportamento, o DDD toca no como estruturar o código para refletir a realidade do problema que a aplicação resolve.
Isso muda o tom da revisão: em vez de ser só “esse método está mal nomeado” ou “esse if pode virar um switch”, passa a ser “essa entidade realmente pertence a este contexto?” ou “essa regra deveria estar no domínio ou no serviço de aplicação?”. São discussões de mais alto nível, que evitam dívida técnica e fortalecem a coerência do sistema. Por isso, times que adotam DDD costumam ter code reviews mais ricos, que não param na forma, mas questionam se a essência do código está fiel ao problema que ele resolve.
O DDD (Domain-Driven Design) entra no fluxo do desenvolvimento de produto antes do MVP, como um alicerce. Ele não é um artefato de entrega como MVP, UAT ou Release, mas sim uma abordagem de modelagem que orienta como o software deve ser desenhado para refletir o domínio do problema.
Se você pensar em sequência, o fluxo ficaria assim: Engenharia de domínio + Engenharia de requisitos + MVP - Minimum Product Viable + Design orientado por domínio + Design Evolutivo + Arquitetura de aplicações

-
DDD – Domain-Driven Design: Aqui você faz a imersão no domínio de negócio, conversa com especialistas e stakeholders, descobre a linguagem ubíqua e modela o sistema em termos que façam sentido para o negócio. É nessa etapa que surgem conceitos como entidades, agregados, bounded contexts e eventos de domínio. O objetivo é garantir que a estrutura do software nasça aderente à realidade que ele pretende resolver.
-
MVP – Minimum Viable Product: Uma vez que o domínio esteja bem modelado, você constrói o MVP. Esse MVP já se beneficia do DDD, porque mesmo sendo mínimo, ele está fundamentado em um design que respeita a linguagem e as regras do negócio. Isso evita que o MVP vire um “protótipo descartável” e aumenta a chance de evoluir para produto de verdade.
-
QA interno → UAT → Release → Continuous Delivery: Depois disso, o fluxo segue normalmente como te expliquei antes.
Então, se o MVP é o “primeiro produto que entrega valor real”, o DDD é o mapa que garante que esse valor seja o certo, modelando desde o início com consistência e visão de futuro. Sem o DDD, corre-se o risco de o MVP ser feito de qualquer jeito e depois ser difícil ou custoso de evoluir.
Um conceito fundamental para tudo isso é a Engenharia de domínio que é todo o processo de reutilização do conhecimento de domínio na produção de novos sistemas de software. É um conceito-chave no reuso sistemático de software e na engenharia de linhas de produtos. Uma ideia-chave na reutilização sistemática de software é o domínio. A maioria das organizações atua em apenas alguns domínios. Eles constroem repetidamente sistemas semelhantes dentro de um determinado domínio, com variações para atender a diferentes necessidades dos clientes. Em vez de construir cada nova variante do zero, economias significativas podem ser alcançadas reutilizando partes de sistemas anteriores no domínio para construir novos.
O processo de identificar domínios, delimitá-los e descobrir semelhanças e variáveis entre os sistemas do domínio é chamado de análise de domínio. Essas informações são capturadas em modelos usados na fase de implementação do domínio para criar artefatos como componentes reutilizáveis, uma linguagem específica de domínio ou geradores de aplicações que podem ser usados para construir novos sistemas no domínio.
Na engenharia de linhas de produtos, conforme definido por ISO26550:2015, a Engenharia de Domínios é complementada pela Engenharia de Aplicações, que cuida do ciclo de vida dos produtos individuais derivados da linha de produtos.
A engenharia de domínio é projetada para melhorar a qualidade dos produtos de software desenvolvidos por meio do reaproveitamento de artefatos de software. A engenharia de domínios mostra que a maioria dos sistemas de software desenvolvidos não são sistemas novos, mas sim variantes de outros sistemas dentro do mesmo campo. Como resultado, por meio do uso da engenharia de domínio, as empresas podem maximizar lucros e reduzir o tempo de lançamento no mercado utilizando conceitos e implementações de sistemas de software anteriores e aplicando-os ao sistema-alvo. A redução de custos é evidente mesmo durante a fase de implementação. Um estudo mostrou que o uso de linguagens específicas de domínio permitiu que o tamanho do código, tanto em número de métodos quanto em número de símbolos, fosse reduzido em mais de 50%, e o número total de linhas de código fosse reduzido em quase 75%.
A engenharia de domínios foca em capturar o conhecimento adquirido durante o processo de engenharia de software. Ao desenvolver artefatos reutilizáveis, os componentes podem ser reutilizados em novos sistemas de software a baixo custo e alta qualidade. Como isso se aplica a todas as fases do ciclo de desenvolvimento de software, a engenharia de domínios também foca nas três fases principais: análise, design e implementação, paralelamente à engenharia de aplicações. Isso produz não apenas um conjunto de componentes de implementação de software relevantes para o domínio, mas também requisitos e projetos reutilizáveis e configuráveis.
Dado o crescimento dos dados na Web e da Internet das Coisas, uma abordagem de engenharia de domínios está se tornando relevante para outras disciplinas também. O surgimento de cadeias profundas de serviços Web destaca que o conceito de serviço é relativo. Serviços web desenvolvidos e operados por uma organização podem ser utilizados como parte de uma plataforma por outra organização. Como os serviços podem ser usados em diferentes contextos e, portanto, requerem configurações distintas, o projeto de famílias de serviços pode se beneficiar de uma abordagem de engenharia de domínio.
A engenharia de domínios, assim como a engenharia de aplicações, consiste em três fases principais: análise, projeto e implementação. No entanto, enquanto a engenharia de software foca em um único sistema, a engenharia de domínios foca em uma família de sistemas. Um bom modelo de domínio serve como referência para resolver ambiguidades mais adiante no processo, um repositório de conhecimento sobre as características e definição do domínio, e uma especificação para desenvolvedores de produtos que fazem parte do domínio.
A análise de domínio é usada para definir o domínio, coletar informações sobre o domínio e produzir um modelo de domínio. Por meio do uso de modelos de características (inicialmente concebidos como parte do método de análise de domínio orientada a características), a análise de domínio visa identificar os pontos comuns em um domínio e os pontos variáveis dentro do domínio. Por meio do uso da análise de domínio, é possível o desenvolvimento de requisitos e arquiteturas configuráveis, em vez de configurações estáticas que seriam produzidas por uma abordagem tradicional de engenharia de aplicação.
A análise de domínio é significativamente diferente da engenharia de requisitos e, como tal, abordagens tradicionais para derivar requisitos são ineficazes para o desenvolvimento de requisitos configuráveis, como estariam presentes em um modelo de domínio. Para aplicar a engenharia de domínio de forma eficaz, o reuso deve ser considerado nas fases iniciais do ciclo de vida do desenvolvimento de software. Por meio da seleção de recursos dos modelos desenvolvidos, a reutilização da tecnologia é realizada muito cedo e pode ser aplicada adequadamente durante todo o processo de desenvolvimento.
A análise de domínio é derivada principalmente de artefatos produzidos a partir de experiências passadas no domínio. Sistemas existentes, seus artefatos (como documentos de projeto, documentos de requisitos e manuais do usuário), padrões e clientes são todas fontes potenciais de entrada para análise de domínio. No entanto, ao contrário da engenharia de requisitos, a análise de domínio não consiste apenas na coleta e formalização de informações; Existe também um componente criativo. Durante o processo de análise de domínio, os engenheiros buscam ampliar o conhecimento do domínio além do que já é conhecido e categorizar o domínio em semelhanças e diferenças para aumentar a reconfigurabilidade.
A análise de domínio produz principalmente um modelo de domínio, representando as propriedades comuns e variáveis dos sistemas dentro do domínio. O modelo de domínio auxilia na criação de arquiteturas e componentes de maneira configurável, atuando como uma base sobre a qual projetar esses componentes. Um modelo de domínio eficaz não inclui apenas as características variáveis e consistentes de um domínio, mas também define o vocabulário usado no domínio e define conceitos, ideias e fenômenos dentro do sistema.
Modelos de características decompõem conceitos em suas características necessárias e opcionais para produzir um conjunto totalmente formalizado de requisitos configuráveis.
O design de domínio toma o modelo de domínio produzido durante a fase de análise de domínio e visa produzir uma arquitetura genérica à qual todos os sistemas dentro do domínio possam se conformar. Da mesma forma que a engenharia de aplicações utiliza os requisitos funcionais e não funcionais para produzir um projeto, a fase de projeto de domínio da engenharia de domínios toma os requisitos configuráveis desenvolvidos durante a fase de análise de domínio e produz uma solução configurável e padronizada para a família de sistemas. O design de domínios visa produzir padrões arquitetônicos que resolvam um problema comum entre os sistemas dentro do domínio, apesar das diferentes configurações de requisitos. Além do desenvolvimento de padrões durante o projeto de domínio, os engenheiros também devem tomar cuidado para identificar o escopo do padrão e o nível em que o contexto é relevante para o padrão. A limitação do contexto é crucial: contexto excessivo resulta em o padrão não ser aplicável a muitos sistemas, e contexto insuficiente resulta em um padrão insuficientemente poderoso para ser útil. Um padrão útil deve ser frequentemente recorrente e de alta qualidade.
O objetivo do design de domínio é satisfazer o maior número possível de requisitos de domínio, mantendo a flexibilidade oferecida pelo modelo de características desenvolvido. A arquitetura deve ser suficientemente flexível para satisfazer todos os sistemas dentro do domínio, ao mesmo tempo em que rígida o bastante para fornecer uma estrutura sólida sobre a qual basear a solução.
Implementação de domínio é a criação de um processo e de ferramentas para gerar eficientemente um programa personalizado no domínio.
Um domínio bem modelado só tem efeito se o design de software respeita a coesão do modelo, preserva invariantes, mantém consistência interna e evita que detalhes técnicos vazem para áreas onde não deveriam. Se o design de software decide misturar responsabilidades, criar acoplamentos arbitrários, espalhar regras por camadas que não conversam com o domínio ou ignorar o Ubiquitous Language, então o DDD perde força, porque o código deixa de refletir as estruturas conceituais. O resultado é um sistema que só “parece DDD no papel”, mas opera como um monólito acoplado, com entidades sem significado e casos de uso sem fronteiras.

Ao mesmo tempo, DDD também depende do design de sistemas, porque os Bounded Contexts (Contextos limitados), para existirem de verdade, precisam de fronteiras técnicas: precisam ser isolados, ter seus próprios modelos, seus próprios fluxos de dados, sua própria vida. É o design de sistemas (System design) que decide como esses contextos conversam, se por eventos, filas, APIs, contratos assíncronos ou mensagens. O DDD diz “esses dois contextos são independentes e têm linguagens diferentes”; o design de sistemas transforma essa independência em topologia real e se ele falha nisso, os contextos se fundem, o sistema fica acoplado e a proposta de modularidade do DDD desaparece.
E por fim, a arquitetura de software é o alicerce onde o DDD se apoia. É ela que escolhe padrões como microservices, monólito modular, event-driven, CQRS, event sourcing, hexagonal ou clean architecture, que definem como as partes se organizam, como as dependências fluem, como proteções ao domínio são criadas. A arquitetura é o meio técnico que permite que o domínio respire. Quando a arquitetura é mal desenhada, a equipe tenta aplicar DDD sobre um terreno instável, e o domínio acaba se adaptando aos problemas arquiteturais em vez de a arquitetura se adaptar ao domínio. DDD, nesse cenário, vira ornamento.
Então, sim: DDD precisa andar alinhado com design de software, design de sistemas e arquitetura. O DDD é a visão conceitual, estratégica e semântica; o design de software é a expressão detalhada e tática; o design de sistemas é a topologia operacional; e a arquitetura é a fundação estrutural. Quando esses quatro caminham juntos, o domínio guia o software, o sistema é coerente, a linguagem é compartilhada, os limites são respeitados, e a complexidade fica organizada. Quando andam separados, o DDD deixa de ser um modelo vivo e vira apenas teoria sem impacto real no código e no comportamento do sistema.
O design orientado por domínio articula uma série de conceitos e práticas de alto nível. De importância primordial é o domínio do software, a área de estudo à qual o usuário aplica um programa. Os desenvolvedores de software constroem um modelo de domínio: um sistema de abstrações que descreve aspectos selecionados de um domínio e pode ser usado para resolver problemas relacionados a esse domínio.
Esses aspectos do design orientado por domínio visam fomentar uma linguagem comum compartilhada por especialistas em domínio, usuários e desenvolvedores — a linguagem onipresente. A linguagem onipresente é usada no modelo de domínio e para descrever os requisitos do sistema. A linguagem onipresente é um dos pilares do DDD junto com o design estratégico e o design tático. No design orientado por domínio, a camada de domínio é uma das camadas comuns em uma arquitetura multicamadas orientada a objetos.
Os conceitos e práticas do DDD são dividos em camadas de domínio: Quando você diz que os conceitos e práticas do Domain-Driven Design são divididos em camadas, você está tocando em uma das características mais marcantes do DDD, mas que muitas vezes é mal compreendida. DDD não é exatamente uma “arquitetura em camadas”, mas ele influenciou fortemente arquiteturas que usam camadas de maneira disciplinada. O ponto central é que DDD organiza o software em torno do domínio, e essa organização naturalmente cria zonas distintas de responsabilidade, que acabam se parecendo com camadas lógicas, mesmo que o padrão em si não force isso.
Na prática, quando falamos de camadas em DDD, normalmente estamos falando do conjunto de estruturas conceituais que separa o coração do domínio (onde vivem as regras de negócio puras) das partes infraestruturais, externas ou acopladas a tecnologia. O domínio fica isolado, limpo, autocontido, enquanto o resto da aplicação orbita em volta dele, servindo-o, protegendo-o e garantindo que ele se mantenha expressivo e imutável diante das mudanças tecnológicas.

Os padrões estratégicos lidam com a obtenção de uma visão geral do domínio de negócios, o que inclui decompô-lo em regras de negócios.
Estritamente falando, as regras de negócios são regras ou procedimentos que fazem ou economizam o dinheiro da empresa. — Tio Bob, Arquitetura Limpa: Guia de um Artesão para Estrutura e Design de Software

Em outras palavras, as regras de negócios são os recursos funcionais que requerem desenvolvimento. No entanto, existem diferentes tipos de regras de negócios. Existem urgentes e importantes. Ainda assim, outros não são urgentes, mas são importantes. Coletar e reagrupar essas regras de forma significativa ajuda a decompor a complexidade do domínio de negócios em subdomínios: subdomínios principais, genéricos e de suporte.
O subdomínio principal contém as regras de negócios que oferecem vantagem competitiva e destacam a diferença entre as empresas que trabalham no mesmo domínio de negócios. Ele incorpora uma lógica de negócios altamente complexa e volátil. Portanto, ele deve estar aberto a mudanças na lógica de negócios, o que pode envolver a adição de novos requisitos, a atualização dos antigos ou até mesmo a remoção de alguns deles. Em seguida, ele deve ser cuidadosamente implementado internamente para permitir que essas alterações ocorram de forma eficiente sem causar muitos problemas em todo o software.
A conclusão das regras de negócios do subdomínio principal requer outras regras de negócios que não envolvem lógica altamente complexa nem volátil. Em vez disso, eles apenas apoiam os negócios da empresa sem invocar nenhuma vantagem competitiva, pois estão resolvendo um problema muito óbvio. Eles são desenvolvidos internamente e podem ser terceirizados. Aqui, falamos sobre o subdomínio de suporte. No entanto, o subdomínio genérico consiste em regras de negócios relacionadas a um problema já resolvido para que ele possa ser comprado ou adotado.
Ao destilar o domínio de negócios em busca de subdomínios, devemos falar a mesma língua para nos entendermos. Devemos, portanto, usar o mesmo termo para nos referirmos a um determinado objeto, comportamento ou campo. Na terminologia do DDD, é chamada de linguagem onipresente. Aqui, estamos evocando um dos ingredientes indispensáveis para construir uma solução de software: comunicação eficaz entre as diferentes partes interessadas do projeto, incluindo desenvolvedores, especialistas de domínio, analistas de negócios, gerentes de projeto, gerentes de marketing, etc.
Como desenvolvedores de software, devemos garantir que nossas suposições estejam alinhadas com o conhecimento dos especialistas do domínio. Alberto Brandolini, que é um consultor versátil na área de Tecnologia da Informação, disse uma vez:
Não é o conhecimento dos especialistas de domínio que vai para a produção, são as suposições dos desenvolvedores que vão para a produção. — Alberto Brandolini
Ele é um especialista em DDD que criou o EventStorming, uma metodologia colaborativa envolvendo todas as partes interessadas do projeto para compartilhar conhecimento sobre o domínio do problema. Ele os reuniu com post-its e canetas coloridas diante de um quadro branco para iniciar uma sessão de análise de conhecimento. Essas metodologias ajudam a encontrar limites para separar regras de negócios consistentes e reagrupá-las por contexto. Na terminologia do DDD, esses grupos são chamados de Contextos Limitados, cada um contendo regras de negócios consistentes.
Como reconhecemos regras de negócios consistentes? Regras de negócios consistentes falam uma linguagem onipresente consistente. Quando chamamos de conceito "um" usando um vocabulário diferente e começamos a tratá-lo de um ponto de vista diferente, podemos estar falando de duas responsabilidades comerciais diferentes que exigem segregação de contexto. Além disso, regras de negócios consistentes geralmente mudam pelo mesmo motivo, portanto, mantê-las juntas é melhor.
Cada contexto limitado incorpora determinados recursos de domínio para cumprir uma única responsabilidade e pode ser empacotado de forma independente. Dessa forma, nosso software será fatiado verticalmente e empacotado por recurso. Além disso, essas fatias verticais devem se comunicar para processar um fluxo de trabalho de negócios específico. Portanto, nossos contextos limitados precisam colaborar; Enquanto isso, devemos proteger a consistência das regras de negócios. Devemos escolher o tipo de comunicação que melhor se adapta aos requisitos do negócio, nem mais, nem menos.
A maneira como os contextos limitados devem se comunicar também afeta a maneira como as equipes devem se organizar e colaborar. Duas formas de comunicação são possíveis: cooperação ou comunicação cliente-fornecedor.
Como cooperamos em diferentes contextos delimitados? A cooperação é possível através de parcerias. Nesse tipo de relacionamento, as equipes são parceiras na solução de problemas que surgem durante a integração de contextos limitados; Eles devem, portanto, sincronizar com frequência para detectar pontos de bloqueio, a fim de garantir a integridade do software.
Outra maneira de cooperar entre contextos limitados é ter um kernel compartilhado. As equipes criam um modelo compartilhado que deve ser consistente em todos os contextos limitados que o utilizam. O uso desse padrão deve ser justificado pelo custo da duplicação, que é maior do que o custo da coordenação.
E quanto à relação Cliente-Fornecedor? No tipo de comunicação Cliente-Fornecedor, tínhamos dois lados. O lado do fornecedor é chamado de "upstream", enquanto os clientes são conhecidos como "downstream". O fornecedor é aquele que presta um serviço aos seus clientes. No entanto, os clientes podem interagir de forma diferente com esse serviço, dependendo do padrão de serviço conformista, anticorrupção ou de host aberto.
Conformista significa que o downstream estará em conformidade com o modelo upstream. No entanto, o downstream não estará em conformidade com o modelo upstream na camada anticorrupção. Em vez disso, ele o personalizará para se adequar ao seu modelo por meio de uma camada anticorrupção para proteger seu modelo contra corrupção e conceitos irrelevantes que podem prejudicar a consistência do contexto limitado. Outra maneira de proteger o downstream é seguir o padrão de serviço de host aberto. Nesse padrão, o fornecedor exporá um serviço que esteja em conformidade com seus clientes. Em outras palavras, o upstream pode ter versões diferentes de uma linguagem publicada para estar em conformidade com seu modelo downstream correspondente.
Após essa longa jornada de obtenção do conhecimento essencial, decomposição do domínio de negócios em subdomínios, delimitação de contextos e desenho das relações entre eles, traçamos um mapa de contexto. É uma representação visual que fornece insights, em primeiro lugar, sobre o design de alto nível, incluindo nossos subdomínios, contextos limitados, bem como o modelo que eles implementarão, em segundo lugar, sobre os padrões de comunicação que devem ser usados entre os contextos limitados e, finalmente, sobre a organização e colaboração das equipes.
O DDD nos permite planejar uma arquitetura de microsserviços decompondo o sistema maior em unidades independentes, compreendendo as responsabilidades de cada uma e identificando seus relacionamentos, ele não é um design pattern específico, mas sim uma importante abordagem de design de software, com foco na modelagem de software para corresponder a um domínio de acordo com as informações dos especialistas desse domínio. O Domain-Driven Design (DDD) surgiu como uma metodologia revolucionária para a modelagem de software, desenvolvida com o intuito de refinar e otimizar a correspondência entre o design do software e o domínio do software e o domínio do problema que ele busca resolver.
Os microsserviços são a forma mais escalável de desenvolver software. Mas você precisa de um bom design que permita que as equipes de desenvolvedores trabalhem de forma autônoma e implementem sem atrapalhar umas às outras, caso contrário, você perderá os benefícios de escalabilidade. O DDD ajuda a delimitar responsabilidades claras entre os serviços, o que permite que equipes atuem de forma independente e coordenada.
No entanto, suas raízes vêm de práticas e ideias que estavam sendo discutidas na indústria desde os anos 1990. Durante esse período, muitas empresas estavam adotando metodologias ágeis e enfrentando problemas ao construir sistemas que não apenas funcionassem, mas que também fossem fáceis de entender, modificar e expandir. Um dos grandes desafios era a chamada "lacuna semântica" entre os especialistas de domínio (pessoas que entendem o negócio) e os desenvolvedores (que implementam soluções técnicas). Essa lacuna frequentemente levava a softwares que funcionavam de forma errada ou que eram difíceis de adaptar a mudanças nos requisitos.
A ideia inicial do DDD é voltar à uma modelagem OO mais pura, por assim dizer. Devemos esquecer de como os dados são persistidos e nos preocupar em como representar melhor as necessidades de negócio em classes e comportamentos (métodos). Isso significa que em DDD um Cliente pode não ter um setter para os seus atributos comuns, mas pode ter métodos com lógica de negócio que neste domínio de negócio pertencem ao cliente, como void associarNovoCartao(Cartao) ou Conta recuperarInformacoesConta(). Em resumo, as classes modeladas e os seus métodos deveriam representar o negócio da empresa, usando inclusive a mesma nomenclatura. A persistência dos dados é colocada em segundo plano, sendo apenas uma camada complementar.
O DDD nasceu da necessidade de aproximar esses dois mundos. Eric Evans observou que o software bem-sucedido em contextos complexos era construído em torno de um modelo de domínio que capturava com precisão o conhecimento do negócio. Ele também percebeu que os sistemas mais sustentáveis utilizavam linguagens comuns entre especialistas e desenvolvedores, além de técnicas para isolar a complexidade e tornar o código mais alinhado com as regras do domínio.
Com a evolução do desenvolvimento de softwares e no aumento da complexidade dos requisitos da aplicação, é extremamente relevante definirmos uma comunicação clara entre as várias partes envolvidas em um projeto de software. É bastante comum haver conflitos entre os termos técnicos utilizados pelas diferentes áreas, seja entre analistas de negócios, desenvolvedores, especialistas financeiros ou de vendas. Nada mais natural haja visto que as equipes estão cada vez mais multidisciplinares. Para auxiliar em uma comunicação fluida, os conceitos do DDD — Domain Driven Design, propõem como um dos seus pilares a definição de uma Linguagem Ubíqua.
O DDD formalizou essas práticas ao introduzir conceitos como Ubiquitous Language (Linguagem Ubíqua), o cerne do DDD, que promove a criação de uma linguagem compartilhada entre todas as partes interessadas, e Bounded Contexts (Contextos Limitados), que ajudam a dividir sistemas grandes e complexos em partes menores e mais compreensíveis. Além disso, o DDD trouxe atenção para padrões arquiteturais que dão suporte ao domínio, como Entidades (Entity), Agregados (), Repositórios () e Serviços de Domínio (), estabelecendo um design centrado na lógica de negócios em vez de nas tecnologias subjacentes.
Para que possamos iniciar uma compreensão acerca de Linguagem Ubíqua (Ubiquitous Language), podemos nos valer da análise semântica do termo ubíquo: u-bí-quo (latim ubiquus, -a, -um), adjetivo:
- Que está ao mesmo tempo em toda a parte. =
ONIPRESENTE - Que tem dom da ubiquidade. =
ONIPRESENTE - Que está difundido em todo o lado. =
GERAL, UNIVERSAL.
De forma conceitual, a linguagem ubíqua é o conjunto de termos e inter-relações que fornecem a semântica da comunicação do domínio, que reflete a visão do negócio. E de forma prática, ao se trabalhar com DDD, entende-se como comunicação de mesma linguagem, em um único modelo, de forma que todos os envolvidos no projeto tenham a mesma compreensão acerca dos termos utilizados. Linguagem ubíqua pode parecer um termo complexo de se compreender, mas outro termo também utilizado para identificar este tipo de comunicação, nos auxilia em uma melhor compreensão: Linguagem Onipresente.
Linguagem Onipresente é essencialmente os termos, palavras e definições utilizadas por todo o domínio do projeto. É o idioma utilizado no cotidiano da empresa, as terminologias da realidade do negócio. Quando um projeto não respeita a linguagem do domínio diversos problemas de comunicação surgem, dificultando o desenvolvimento, implantação e sustentação da solução.
Quando termos utilizados no projeto vão sendo traduzidos, de acordo com o uso em cada departamento, a comunicação se torna anêmica e a assimilação do conhecimento disperso. Em seu livro Domain Driven Design — Atacando as Complexidades no Coração do Software, Eric Evans descreve de maneira clara esta problemática:
O custo de toda a tradução, além do risco de entendimento errado, é simplesmente muito alto. Um projeto precisa de uma linguagem em comum que seja mais robusta que o mínimo denominador comum.
A Linguagem Onipresente (ubiquitous language) não está limitada a diagramas em UML (Unified Modeling Languages, ou Linguagem de Modelagem Unificada), mas principalmente, define em seu vocabulário nome das classes e operações de destaque. Inclui regras para implantar um dicionário uniforme e explícito para o modelo, para que o mesmo possa ser utilizado com o máximo de eficiência possível.
O Diagram as code (Diagrama como código) é uma abordagem de criação de diagramas que utiliza código, em vez de ferramentas gráficas, para desenhar e manter diagramas. Essa abordagem permite que os diagramas sejam criados e atualizados utilizando linguagens de programação ou marcadores, em vez de ferramentas de desenho gráfico. A prática de "Diagram as code" (Diagrama como código) pode auxiliar no Domain-Driven Design (DDD), pois é uma prática útil no DDD que ajuda a manter a documentação atualizada, facilita a colaboração, fornece controle de versão e permite a geração automática de diagramas. Vantagens do "Diagram as code" no DDD:
- Melhor documentação: Com o "Diagram as code", você pode manter a documentação do seu modelo de domínio atualizada e sincronizada com o código. Isso ajuda a garantir que a documentação seja precisa e refletida nas mudanças no código.
- Modelagem colaborativa: O "Diagram as code" permite que os membros da equipe colaborativamente trabalhem no modelo de domínio, tornando mais fácil para os desenvolvedores, especialistas em domínio e outros stakeholders discutirem e refinarem o modelo.
- Versão e controle: Com o "Diagram as code", você pode usar sistemas de controle de versão (como Git) para rastrear as alterações no modelo de domínio. Isso ajuda a garantir que todas as alterações sejam documentadas e possam ser revertidas se necessário.
- Geração automática de diagramas: Muitas ferramentas de "Diagram as code" permitem que você gere diagramas automaticamente a partir do código. Isso pode economizar tempo e reduzir a chance de erros manuais.
- Integração com o ciclo de desenvolvimento: O "Diagram as code" pode ser integrado ao ciclo de desenvolvimento de software, permitindo que os desenvolvedores trabalhem no modelo de domínio em paralelo com o desenvolvimento do código.
As ferramentas permitem que você crie diagramas como código, utilizando sintaxes específicas para desenhar os diagramas. Em seguida, elas geram imagens ou diagramas a partir do código. Algumas ferramentas populares para "Diagram as code" incluem:
- Mermaid
- PlantUML
- Graphviz
- C4 (abordagem de modelagem de software)
Normalmente os especialistas de um domínio, diretores, administradores, analistas, técnicos, possuem pouca familiaridade com o jargão técnico utilizado no desenvolvimento de software, mas utilizam os jargões próprios de sua área de atuação. A partir desta realidade, os especialistas de um domínio descrevem superficialmente o que necessitam, fazendo com que desenvolvedores criem abstrações que sustentem o design da aplicação. Com isso, uma compreensão uniforme vai se deteriorando exponencialmente.
Como solução a esta dispersão na comunicação, devemos usar a linguagem baseada no modelo de forma exaustiva até que a comunicação seja fluida e compreensível entre os diversos setores envolvidos no projeto. Para que possamos alcançar esta fluência, os especialistas do domínio devem vetar termos ou estruturas que não transmitam uma compreensão clara acerca das funcionalidades envolvidas; os desenvolvedores devem se empenhar no cuidado com ambiguidades ou inconsistências que possam corromper o modelo proposto. Ou seja, é um esforço conjunto entre todos os envolvidos, mas, é essencialmente necessário que ocorra.
Como identificar os especialistas de domínio? Especialistas de domínio são os profissionais envolvidos no dia a dia da operação, nos mais diferentes setores, ou seja, são os “conhecedores” do negócio (stakeholders). Normalmente estes especialistas são analistas, técnicos, engenheiros, podendo ser todo aquele que possui a compreensão acerca do fluxo de operação da empresa. Os especialistas de domínio detém o conhecimento sobre as necessidades e requisitos necessários para o processamento das atividades organizacionais.
Em essência, o DDD surgiu para enfrentar a complexidade inerente ao desenvolvimento de software em domínios desafiadores, permitindo que os sistemas sejam projetados de forma que o código seja uma expressão direta das regras e processos do negócio. Com o tempo, o DDD ganhou popularidade e passou a ser usado em diversos contextos, especialmente em sistemas corporativos onde o domínio de negócio é complexo e sujeito a constantes mudanças.
Para o sucesso de um projeto de software, o DDD sugere que tanto especialistas de domínio quanto desenvolvedores devem falar a mesma língua.
A figura acima, ilustra a existência de termos que só os especialistas de domínio conhecem e apresentam expressões somente de caráter tecnológico, os quais são de uso apenas do time de desenvolvimento. Contudo, é necessário que exista um conjunto de termos que devem ser de conhecimento universal, no que se refere ao domínio da aplicação, formando a Linguagem Ubíqua do sistema. A definição de uma linguagem onipresente objetiva principalmente dois propósitos:
-
Possibilitar uma comunicação fluida entre os membros de equipes multidisciplinares; Nomear elementos do código da aplicação, como classes, métodos, variáveis, funções, módulos, tabelas de bancos de dados, rotas de APIs, etc.
-
Ademais a padronização na comunicação propõe elucidar o significado dos termos, de um forma simples, objetiva e compreensível para facilitar os relacionamentos e associações entre todos módulos necessários.
Qualquer pessoa técnica contribuindo para o modelo deve programar, pelo menos tocar no código, independente do papel desempenhado no projeto. Um responsável por mudar o código deve sempre aprender a expressar o modelo através do código. Todo desenvolvedor deve estar envolvido na discussão sobre o modelo e ter contato com os especialistas do domínio. (EVANS, 2016).
Em seu livro Implementando Domain Driven Design, Vaughn Vernon, pontua que um especialista de domínio tem uma forte influência sobre a linguagem utilizada, devido ao maior conhecimento acerca do negócio, que no final é o contexto imperativo de todo projeto. Estes especialistas tendem a ser influenciados pelos padrões da indústria, contudo, uma linguagem universal deve ser centrada em como o próprio negócio pensa e opera. Ou seja, cada empresa possui seu próprio domínio acerca da execução de seus processos.
Não entenda Linguagem Ubíqua como um conjunto de jargões de negócios sendo impostos ao time de desenvolvimento, e nem mesmo uma sobreposição de termos técnicos sobre o contexto de negócio, mas sim, uma linguagem real que é criada por toda a equipe e que é propagada por toda a corporação.
Compreende-se que haverá discordâncias em relação aos termos utilizados e que estão na mente dos especialistas, mas, a partir do uso aberto da linguagem, a evolução é natural e consolidada por este processo de maturação da comunicação.
O DDD enfatiza a compreensão profunda do domínio do problema e o uso de uma linguagem ubíqua compartilhada entre as equipes de desenvolvimento e especialistas do domínio. Ele propõe a organização do código em torno do domínio do problema, separando-o dos detalhes técnicos e infraestrutura.
Embora o DDD não seja um design pattern em si, ele pode ser combinado com vários design patterns e princípios de design, como Agregado, Repositório, Especificação, Event Sourcing, entre outros. O DDD fornece diretrizes e conceitos para ajudar na criação de uma arquitetura de software robusta e flexível.
Portanto, podemos dizer que o DDD é uma abordagem de design e uma metodologia de modelagem que pode ser aplicada em diferentes arquiteturas de software, como arquitetura em camadas, arquitetura hexagonal, arquitetura de microsserviços, entre outras. Ele fornece princípios e práticas para projetar e estruturar o código em torno do domínio do problema, visando um modelo de domínio rico, desacoplamento e flexibilidade.
É uma abordagem mais ampla para o design de software que abrange vários conceitos e técnicas. DDD enfatiza a modelagem do domínio, a colaboração entre especialistas do domínio e desenvolvedores, e a criação de um código baseado em um entendimento profundo do domínio do problema.
O DDD deve ajudar na modelagem das classes mais importantes e mais centrais do sistema de forma e diminuir a complexidade e ajudar na manutenção das mesmas, afinal este é o objetivo dos princípios de orientação a objetos.
Important
Outro ponto é sobre nós desenvolvedores estarmos compartilhando dados com outros sistemas, as rotinas de integração que recebem ou disponibilizam dados para outros sistemas não devem ser "inteligentes". Muitos desenvolvedores acabam modelando suas classes de negócios tentando resolver as questões internas do sistema e, ao mesmo tempo, pensando em como essas classes serão expostas para outros sistemas. Padrões como DTO (Data Transfer Object) que usam objetos "burros" são mais adequados para isso.
Portanto, o DDD não tenta resolver todos os problemas de todas as camadas de um sistema. Seu foco é na modelagem das entidades principais de negócio usando a linguagem adequada daquele domínio para facilitar a manutenção, extensão e entendimento. Particularmente, eu não seguiria à risca o padrão, até porque existem inúmeros padrões e variações de modelagem OO. Estude os princípios por detrás desses padrões, pois eles são geralmente parecidos e veja o que funciona melhor para cada projeto.
A maioria dos softwares não quebra por causa de erros de sintaxe ou lógica if-else falha.
Ele quebra porque as equipes perdem o alinhamento com o problema de negócios que deveriam resolver. Os sistemas se emaranham com suposições técnicas que envelhecem mal. Os recursos são implementados sem considerações de design adequadas. E com o tempo, cada novo requisito cria mais problemas que continuam se acumulando.
Muitas vezes, isso não é um problema de ferramentas. É um problema de modelagem.
O DDD (Design Controlado por Domínio) tenta resolver esse problema de frente. Em sua essência, o DDD é uma maneira de projetar software que mantém o domínio de negócios, não o esquema de banco de dados ou a estrutura mais recente, no centro da tomada de decisões. Ele insiste que os engenheiros colaborem profundamente com especialistas de domínio durante o ciclo de vida do projeto, não apenas para reunir requisitos uma vez e desaparecer nos tickets do Jira. Ele fornece às equipes o vocabulário, os padrões e os limites para modelar sistemas complexos sem serem enterrados na complexidade acidental.
Claro, o DDD não é uma bala de prata. Ele não gera código e não conserta magicamente um monólito legado. Mas oferece algo mais valioso a longo prazo: clareza sobre o que o sistema deve fazer e onde pode mudar.
Essa abordagem se torna especialmente valiosa quando:
- O domínio não é trivial e continua evoluindo. Pense em finanças, saúde, logística ou mercados gigantes.
- Várias equipes estão trabalhando em partes sobrepostas do sistema.
- O código precisa refletir o comportamento do mundo real, não construções técnicas abstratas.
O DDD não se importa se a arquitetura é monolítica ou baseada em microsserviços. O que importa é se o modelo reflete as regras e a linguagem do mundo real do domínio e se esse modelo pode evoluir com segurança à medida que o domínio muda.
Exploramos as ideias centrais do DDD (como Contextos Limitados, Agregados e Linguagem Ubíqua) e explicamos como eles funcionam juntos na prática. Também veremos como o DDD se encaixa nos sistemas do mundo real, onde ele brilha e onde pode falhar.
Essa divisão natural acaba sendo organizada em três grandes agrupamentos: uma camada de domínio, uma camada de aplicação e uma camada de infraestrutura. Mas, novamente, isso não é um dogma do DDD, é apenas a forma como as ideias do DDD funcionam melhor em arquiteturas limpas e separadas:
 |
 |
 |
No contexto do DDD, existem design patterns específicos que são frequentemente utilizados para ajudar a implementar os conceitos e princípios do DDD. Alguns desses padrões incluem:
-
Agregado: Se refere a um padrão de design que agrupa um conjunto de objetos relacionados em uma única unidade coesa. O Agregado é uma das principais construções utilizadas para modelar e organizar o domínio em DDD;
-
Repositório: Fornece uma interface para acessar coleções de objetos agregados, permitindo que o domínio permaneça livre de preocupações com persistência. Ele atua como uma camada intermediária entre o domínio e a fonte de dados (como bancos de dados).
-
Serviço de Domínio: Representa operações ou ações do domínio que não pertencem naturalmente a uma única entidade ou value object. Encapsula lógica de negócio que depende de múltiplos objetos.
-
Value Object: Objetos que não possuem identidade própria e são definidos apenas por seus atributos. São imutáveis e usados para representar conceitos como dinheiro, coordenadas ou medidas.
-
Entidade: Objetos do domínio que possuem identidade própria (geralmente um ID) e um ciclo de vida distinto. Diferente de value objects, entidades podem mudar seus atributos ao longo do tempo.
-
Factory: Padrão responsável por encapsular a lógica de criação complexa de objetos, especialmente agregados. Evita a poluição do construtor com lógica de montagem de objetos.
-
Especificação: Define regras de negócio reutilizáveis e combináveis para verificar se um objeto atende a determinados critérios. É útil para separação de responsabilidades e clareza das regras de domínio.
-
Event Sourcing: Técnica onde o estado do sistema é determinado por uma sequência de eventos (ao invés de snapshots de dados). Permite reconstruir o estado do sistema e ter um histórico detalhado das mudanças.
-
Injeção de Dependência (DI - Dependency Injection): Técnica que permite desacoplar componentes do sistema, facilitando testes, manutenção e extensibilidade. No DDD, é comum para injetar repositórios, serviços de domínio e unidades de trabalho nos agregados e serviços de aplicação.
Esses padrões, juntamente com outros conceitos e técnicas, podem ser aplicados para construir uma arquitetura que segue os princípios do DDD. O DDD, portanto, não é um design pattern em si, mas uma abordagem que pode ser implementada usando diversos padrões de design específicos.
O coração é sempre o domínio: entidades, objetos-valor, agregados, repositórios como contratos e os serviços de domínio quando algo não cabe numa entidade específica. Aqui não existe conhecimento técnico como banco de dados, HTTP, mensageria ou UI. É o código que sobrevive quando se troca tudo ao redor. É onde o vocabulário ubíquo vive, onde o modelo mental da empresa vira código executável. É a camada mais estável e a mais valiosa de todas:
Quando você fala dessas “camadas do domínio”: entidades, objetos-valor, agregados, repositórios e serviços de domínio, na verdade você está descrevendo os blocos estruturais internos do próprio Domain Model, isto é, os elementos que compõem o núcleo do DDD. Eles não são camadas no sentido arquitetural, mas sim componentes conceituais do modelo, cada um representando um papel distinto dentro da lógica de negócio. E essa distinção é crucial, porque o domínio só fica expressivo e coerente quando cada peça é usada para aquilo que foi criada.
O design orientado por domínio reconhece múltiplos tipos de modelos. Por exemplo, uma entidade é um objeto definido não por seus atributos, mas por sua identidade. Por exemplo, a maioria das companhias aéreas atribui um número único aos assentos de cada voo: essa é a identidade do assento. Em contraste, um objeto valor é um objeto imutável que contém atributos, mas não possui identidade conceitual. Quando as pessoas trocam cartões de visita, por exemplo, elas se importam apenas com as informações do cartão (seus atributos), em vez de tentar distinguir entre cada cartão único.

Dentro do domínio, as entidades representam conceitos que têm identidade persistente ao longo do tempo, mesmo que seus atributos mudem. Elas capturam comportamentos essenciais ligados a um identificador único, como um Cliente, um Pedido ou um Veículo. Já os objetos-valor são as estruturas que descrevem características imutáveis, conceituais, que não têm identidade própria, mas têm significado. Eles existem para impedir que o domínio fique cheio de tipos primitivos sem sentido, substituindo-os por tipos ricos, como Email, CPF, Placa, Endereço ou Dinheiro. Essa relação entre entidades e objetos-valor sustenta a expressividade do vocabulário ubíquo dentro do código.
Modelos também podem definir eventos (algo que aconteceu no passado). Um evento de domínio é um evento pelo qual especialistas de domínio se importam. Modelos podem ser ligados por uma entidade raiz para se tornarem um agregado. Objetos fora do agregado podem conter referências à raiz, mas não a qualquer outro objeto do agregado. A raiz agregada verifica a consistência das mudanças no agregado. Os motoristas, por exemplo, não precisam controlar individualmente cada roda de um carro: eles simplesmente dirigem o carro. Nesse contexto, um carro é um conjunto de vários outros objetos (o motor, os freios, os faróis, etc.).
Quando o sistema cresce e você percebe que certas entidades começam a formar agrupamentos naturais de regras e invariantes, entra o conceito de agregado. Ele funciona como um limite de consistência: um conjunto de entidades e objetos-valor que sempre deve ser manipulado de forma coerente. O agregado garante que você não mexa em partes internas que não deveriam ser alteradas isoladamente e que toda modificação passe por uma única entidade-raiz. Essa raiz é quem expõe métodos públicos e controla as regras internas do agregado, protegendo sua integridade lógica.
No design orientado por domínio, a criação de um objeto frequentemente é separada do próprio objeto.
Um repositório, por exemplo, é um objeto com métodos para recuperar objetos de domínio de um armazenamento de dados (por exemplo, um banco de dados). De forma semelhante, uma fábrica é um objeto com métodos para criar diretamente objetos de domínio. Já os repositórios são contratos dentro do domínio — e isso é importante: contratos, não implementações. Eles definem as operações necessárias para persistir e recuperar agregados, mas não sabem nada sobre banco de dados, ORM, SQL ou infraestrutura. Eles expressam apenas a intenção: “preciso obter esse agregado”, “preciso persistir esse agregado”. A tecnologia que faz isso acontecer vive fora do domínio. O repositório é o ponto de contato mais importante entre o núcleo do domínio e o resto da aplicação, porque permite que o domínio permaneça independente e limpo.

Por fim, os serviços de domínio (Domain service) são como espaços auxiliares dentro do modelo. Eles só existem quando uma regra de negócio não pertence naturalmente a nenhuma entidade ou objeto-valor. São operações puramente de domínio, mas sem estado próprio, que coordenam comportamentos entre objetos.
Muitas vezes representam cálculos, validações complexas, políticas ou decisões de negócio que não cabem dentro de um único agregado. O fato de eles existirem mostra maturidade na modelagem, porque impede que entidades se tornem “deuses” com responsabilidades demais.
Esse diagrama junta vários conceitos de DDD, microsserviços, Domain Services, CQRS e Event-Driven Architecture, e por isso parece mais abstrato do que realmente é.
O contextual service não tem relação com application context no sentido técnico de frameworks, mas sim com o contexto de domínio definido pelo DDD. Ele representa um serviço que atua dentro do bounded context, carregando as regras de negócio específicas daquele domínio. É um tipo de componente que não é simplesmente uma service class de aplicação, mas uma unidade que encapsula conhecimento do domínio e age conforme as regras internas do contexto. Ele existe para isolar o significado, o vocabulário e as invariantes daquele pedaço do sistema, de modo que aquilo que faz sentido dentro daquele contexto não vaze para outro. Ou seja, é um serviço que só funciona dentro do contexto semântico onde ele pertence e é por isso que ele é “contextual”, porque depende do significado local daquele domínio, e não de uma API genérica ou do framework.
Já o managed state transition event aparece quando o domínio possui algum tipo de estado que muda com o tempo e essas mudanças têm significado de negócio. Quando um agregado ou entidade passa de um estado para outro, essa transição pode gerar um evento que registra essa mudança para que outras partes do sistema possam reagir. O termo “managed” indica que esse estado é controlado e validado pelo próprio domínio, obedecendo invariantes, regras e consistência interna. Portanto, esse tipo de evento é originado quando o domínio aceita, valida e confirma uma mudança de estado, e então emite um evento que pode acionar comportamento assíncrono, projeções, atualizações ou integrações. Não é apenas um evento técnico, mas sim a expressão de uma transformação relevante dentro da lógica da operação.
O business event, por sua vez, é o evento de mais alto nível, aquele que traduz uma ocorrência de valor para o negócio. É diferente do managed state transition event porque ele não diz apenas que um agregado mudou seu estado interno, mas que algo significativo aconteceu dentro da empresa, algo que outros serviços, contextos e até sistemas externos precisam saber. Esse tipo de evento é emitido quando o domínio reconhece que ocorreu um fato com relevância semântica, como “Pagamento Confirmado”, “Pedido Cancelado”, “Cliente Registrado”. Ele se torna um ponto de integração entre bounded contexts e é geralmente publicado em sistemas de mensageria ou barramento de eventos, servindo de gatilho para fluxos, reações automáticas ou pipelines de consumo. Em termos de EDA e CQRS, é o que permite que projeções atualizem read models, ou que outros microserviços sincronizem decisões e comportamentos sem acoplamento direto.
Assim, o diagrama articula três camadas de significado. O contextual service executa lógica de domínio situada no contexto adequado. O managed state transition event registra a mudança interna e valida dentro do domínio. E o business event expõe para o ecossistema aquele fato relevante que deve ser consumido por outros componentes, dando vida à característica distribuída de microservices com DDD e CQRS.
Quando parte da funcionalidade de um programa não pertence conceitualmente a nenhum objeto, ela normalmente é expressa como um serviço.
Existem diferentes tipos de eventos no DDD, e as opiniões sobre sua classificação podem variar. Segundo Yan Cui, existem duas categorias-chave de eventos:
-
Eventos de domínio significam ocorrências importantes dentro de um domínio de negócios específico. Esses eventos são restritos a um contexto limitado e são vitais para preservar a lógica de negócios. Normalmente, eventos de domínio têm cargas úteis mais leves, contendo apenas as informações necessárias para o processamento. Isso ocorre porque os ouvintes de eventos geralmente estão dentro do mesmo serviço, onde seus requisitos são mais claramente compreendidos.
-
Por outro lado, eventos de integração servem para comunicar mudanças entre diferentes contextos limitados. Eles são cruciais para garantir a consistência dos dados em todo o sistema. Eventos de integração tendem a ter cargas úteis mais complexas com atributos adicionais, pois as necessidades dos ouvintes potenciais podem variar significativamente. Isso frequentemente leva a uma abordagem mais completa da comunicação, resultando em excesso de comunicação para garantir que todas as informações relevantes sejam compartilhadas de forma eficaz.
O que você chamou de “camadas” é, portanto, o conjunto de padrões que estruturam o modelo de domínio internamente. Eles servem para que o núcleo do sistema represente a realidade de negócio de forma organizada, expressiva e coerente. Cada um desempenha um papel específico e todos se combinam para formar o coração do DDD. Esses elementos não vivem separados por fronteiras técnicas — eles convivem dentro do mesmo contexto, mas com funções bem definidas. E é exatamente essa organização interna que permite ao domínio permanecer sólido mesmo quando todo o resto do sistema muda.
Ao redor do domínio está a camada de aplicação, que não contém regras de negócio, mas coordena casos de uso. Ela funciona como um orquestrador, chamando o domínio e o que está fora dele para cumprir um fluxo. Esse nível também permanece relativamente estável, mas já conhece elementos mais concretos, como serviços de email, notificações ou repositórios que serão implementados no mundo técnico. Essa camada é a ponte entre a intenção de negócio e a execução tecnológica.
Por fim, a infraestrutura é a camada que toca na realidade: banco de dados, HTTP, mensageria, arquivos, serviços externos, ORM, drivers, tudo que é acoplado à tecnologia. Aqui ficam as implementações concretas dos contratos definidos nas camadas superiores. A infraestrutura depende do domínio, mas o domínio nunca depende dela — essa é a inversão fundamental que mantém a modelagem limpa. Quando se aplica arquitetura hexagonal ou Onion Architecture, o domínio fica no centro e a infraestrutura fica nas bordas, o que reforça a mesma ideia.
Então, quando se fala que DDD tem camadas, a verdade é que ele inspira a criação de camadas porque a modelagem orientada ao domínio exige separação clara entre regras de negócio e tecnologia. É por isso que tantos times que aplicam DDD acabam automaticamente usando Clean Architecture, Hexagonal Architecture ou Onion Architecture: essas estruturas preservam o modelo de domínio e permitem que ele evolua sem ser destruído por detalhes técnicos.
DDD não existe sem essa separação. Ele até poderia ser aplicado em uma bagunça de código monolítico distribuído, mas não funcionaria. O poder do DDD acontece justamente quando o domínio é posto no centro e protegido por camadas que impedem que a tecnologia engula as regras de negócio. Essa divisão natural acaba sendo percebida como “camadas do DDD”, apesar de tecnicamente elas pertencerem mais a estilos arquiteturais compatíveis com DDD do que ao DDD em si.

O AOP - Aspect-Oriented Programming pode fortalecer muito as boas práticas de DDD, TDD e BDD, e essa conexão faz bastante sentido quando entendemos o papel de cada um desses paradigmas dentro de uma arquitetura limpa e organizada. A orientação a aspectos não substitui nenhum deles, mas funciona como uma espécie de tecido estrutural que mantém o código limpo, modular e fiel aos princípios que essas abordagens defendem.
O DDD se beneficia especialmente porque a regra número um do design orientado ao domínio é manter o domínio puro, expressivo e livre de detalhes técnicos acoplados. O AOP ajuda justamente a retirar do domínio tudo aquilo que não é domínio: logs, transações, auditorias, repetição de validações estruturais, políticas de segurança, métricas e qualquer outra funcionalidade transversal. Ao deslocar essas responsabilidades para aspectos, o modelo de domínio permanece limpo e orientado exclusivamente à lógica do negócio, sem anotações excessivas, sem serviços utilitários misturados e sem ruídos que atrapalhem a clareza conceitual do código. Isso deixa o domínio mais próximo da linguagem ubíqua, mais fácil de evoluir e mais coerente com o propósito principal do DDD, que é representar conhecimento e regras do negócio de forma elegante e sustentável.
No caso do TDD, o AOP traz uma contribuição igualmente importante. Quando usamos TDD, queremos testar a lógica de forma isolada, sem que camadas externas interfiram no comportamento esperado. Se o código estiver poluído com logs, tratamentos repetitivos ou preocupações técnicas envolvendo transações ou autenticação, o ato de testar se torna mais difícil, mais lento e mais sujeito a falhas colaterais. O AOP limpa esse cenário ao remover grande parte desse ruído estrutural, permitindo que você escreva testes focados apenas na lógica essencial. Além disso, como os aspectos podem ser desativados ou simulados durante os testes, você consegue um ambiente de testes mais controlado, determinístico e alinhado com o espírito do TDD, que exige ciclos rápidos, previsíveis e com feedback imediato sobre a execução da regra de negócio.
Sobre o BDD, o AOP também se encaixa de maneira natural, porque o BDD exige clareza comportamental e foco na história do usuário ou no comportamento esperado de uma funcionalidade. Quando você descreve um comportamento no formato Given-When-Then, espera que o código reflita essa lógica de forma limpa, sem camadas técnicas misturadas. O AOP impede que esses comportamentos de alto nível fiquem escondidos ou embrulhados por detalhes de infraestrutura, preservando a naturalidade da leitura tanto no código quanto nos testes comportamentais. Isso torna os cenários mais fiéis à linguagem de negócio, diminui ruídos e deixa as tratativas técnicas centralizadas fora do fluxo principal. Em outras palavras, o BDD ganha em clareza, o TDD ganha em eficácia e o DDD ganha em pureza — tudo porque o AOP protege a regra de negócio de interferências externas.
Assim, quando você coloca tudo isso junto, percebe que AOP não é um acessório técnico, mas uma ferramenta arquitetural que sustenta a separação de responsabilidades, reduz acoplamento e melhora a manutenção do sistema como um todo. Ele permite que o domínio seja domínio, que os testes sejam testes e que o comportamento da aplicação seja descrito de maneira simples e coerente. O AOP acaba se tornando um verdadeiro aliado para sistemas que queiram adotar DDD, TDD e BDD de forma madura, escalável e profissional, principalmente em ambientes como o ecossistema Java/Kotlin, onde essa abordagem é amplamente consolidada através de frameworks como o Spring.
 |
 |
Acoplamento e Coesão: Os Dois Princípios para uma Arquitetura Eficaz - Todo grande sistema que sai do controle começa da mesma forma: pequeno, funcional e aparentemente simples. No entanto, à medida que o sistema evolui, as coisas saem do controle.
Uma funcionalidade é adicionada aqui, uma função auxiliar é comprimida ali, e uma dependência "temporária" para alguma tarefa urgente que nunca é removida. Meses depois, a depuração exige passar por cinco camadas de indireção, e tocar em um módulo pode quebrar todo o sistema.
Nos bastidores desse lento colapso, duas forças invisíveis frequentemente brincam de cabo de guerra: acoplamento e coesão.
A maioria dos desenvolvedores ouve esses termos pela primeira vez em livros didáticos ou postagens de blog, frequentemente agrupados em uma lista de verificação de "bom design".
- Alta coesão: bom.
- Acoplamento solto: também é bom.
Mas além dos conceitos, o significado prático muitas vezes se perde. Como é o acasalamento? Quando a coesão se quebra em equipes reais? E por que alguns projetos parecem fáceis de mudar, enquanto outros oferecem desafios a cada pull request?
Acoplamento e coesão não são diretrizes abstratas. São realidades práticas de engenharia que definem o quão fácil o código pode evoluir, quão confiante as equipes podem implantar e quão doloroso se torna incorporar um novo colega ou corrigir um bug sob pressão.
Neste artigo, tentaremos entender o acoplamento e a coesão de forma mais realista e como eles podem se manifestar em diferentes estilos e padrões arquitetônicos.
DDD - Segregação de Responsabilidade de Consulta de Comando (CQRS) os comandos são complexos, as consultas são simples, anteriormente, examinamos as Entidades DDD, que têm estado, e Eventos, onde o estado muda. Para reduzir a complexidade, podemos ser específicos sobre o que tem estado e encapsular onde ele muda. Os eventos são códigos de alto nível, situados no meio da Onion Architecture. Veremos como os comandos de nível inferior vinculam a interface do usuário ou a API a eventos para permitir que os usuários alterem o estado.
 |
 |
Os eventos de domínio existem no centro de domínio de alto nível de um diagrama Onion Architecture, coberto por Robert C. Martin em Clean Architecture. A camada externa da cebola contém detalhes de baixo nível, entradas e saídas, como armazenamento, interfaces de usuário e APIs. Os comandos estão em algum lugar no meio, vinculando as entradas ao domínio de nível superior para que os usuários possam acionar os eventos para alterar o estado.
 |
 |
Para que um usuário interaja com um sistema e para que ele seja útil, precisamos ser capazes de fazer duas coisas. A primeira é exibir informações para o usuário.

O Clean Architecture (CA) é a diretriz de arquitetura de sistemas proposta por Robert C. Martin (Uncle Bob) derivada de muitas diretrizes arquitetônicas como Hexagonal Architecture e Onion Architecture, entre outras. Eric Evans introduziu o conceito de Domain-Driven Design (DDD). Ele escreveu sobre isso em seu livro Domain-driven Design em 2004 (também conhecido como "The Big Blue Book"). O Design Orientado a Domínio é uma abordagem para o desenvolvimento de software que centra o desenvolvimento na programação de um modelo de domínio com uma rica compreensão dos processos e regras de um domínio.
| Hexagonal Architecture + DDD | Hexagonal Architecture + Clean Architecture + DDD |
 |
 |
Comecei com minha equipe a adotar o Domain-Driven Design (DDD) em nosso trabalho, e nossa missão era tirar o máximo proveito do DDD e do CA, se possível. À medida que a adoção cresce, estamos cada vez mais perto do negócio e do domínio que estamos abordando; começamos a falar a linguagem onipresente do domínio.
 |
 |
Note
Não existe tal arquitetura que sirva para todos. Toda arquitetura ou padrão de desenvolvimento de software tem prós e contras; Baseie sua decisão no projeto, no escopo e na equipe. Vamos descrever o caminho que tomamos.
Exemplo: DDD + Hexagonal Architecture - GalleryManager

Nos concentraremos em como estruturamos o código de acordo com DDD e Clean Architecture, para que o código também fale a linguagem onipresente do domínio com mais facilidade:
Primeiro, dividimos o sistema em partes independentes menores em torno dos subdomínios de negócios por meio de algumas iterações (ferramentas estratégicas de DDD, como tempestade de eventos, narrativa e muito mais). Idealmente, essas partes devem ser implantáveis de forma independente (microsserviços), mas nem sempre é esse o caso. Muitas vezes, podemos ter um código legado que não podemos alterar facilmente, então temos que mantê-lo por um tempo. Nesses casos, temos esses subdomínios em um único projeto (monólito), com cada subdomínio em uma pasta ou pacote separado.
Estrutura de código de contexto limitado (Bounded Contexts): Depois de dividir o domínio extenso em partes menores, também chamadas de subdomínios. Em seguida, tentamos resolver cada subdomínio; Um "contexto limitado" implementará um subdomínio. Cada contexto limitado pode ser um microsserviço separado ou um pacote separado que encapsula esse contexto limitado dentro de um serviço atual. Então, vamos falar sobre essa parte agora, como projetamos cada contexto limitado, quantas camadas de alto nível temos e como elas se comunicariam juntas.
Exemplos de contextos limitados em um sistema de comércio eletrônico
├───wallet
├───orderManagement
├───shipping
├───..
Comando vs. Consulta (CQRS): A primeira camada que temos em cada contexto limitado são comandos e consultas. O que eles significam?
Todo caso de uso em um sistema pode ser considerado um Comando ou Consulta, onde um Comando é qualquer caso de uso que altera o estado atual do sistema, enquanto uma Consulta é qualquer caso de uso que busca o estado atual SEM mudar o estado atual. Como esses dois têm preocupações diferentes, decidimos usar o padrão CQRS (Command Query Responsibility Segregation)
Então, temos pastas de nível muito alto; Cada uma contém o restante das camadas, que discutiremos mais adiante nesta página para isolar essas duas preocupações.
├───shipping
| ├───commands
| ├───queriesCamadas de Arquitetura: Ter camadas claras em nosso código onde cada camada tem responsabilidade clara torna adequado para nós identificar a direção da dependência, testar facilmente o código, trabalhar em paralelo sem esperar uns pelos outros, e muito mais.
Concordamos em ter as seguintes camadas
- Camada de domínio
- Camada de Aplicação
- Camada de Infraestrutura
├───shipping
├───commands
├───application
├───domain
├───infrastructure
├───queries
├───application
├───infrastructureVocê provavelmente percebeu que a subpasta de consultas não tem camada de domínio! A seção a seguir explicará os motivos por isso.
Camada de domínio: A camada de domínio é a parte central de um contexto limitado, contendo o domínio central e todos os invariantes de negócios e a lógica para esse contexto limitado. Não deve depender de nenhuma camada ou biblioteca ou framework de terceiros. Em vez disso, todas as camadas dependem disso. O conteúdo típico nessa camada é o seguinte.
├───shipping
├───commands
├───domain
├───models
├───Shipment
├───Order
├───ShippingCompany
├───OrderStatus
├───Receiver
├───services
├───ShippingService
├───events
├───ShipmentCreated
├───ShipmentDelievered
├───contracts
├───ShipmentRepo
├───OrderRepo
├───ShippingCompanyProviderComponentes do Domínio: Resumindo, temos modelos de domínio, serviços de domínio, eventos e contratos. Existem principalmente três tipos de modelos de domínio que envolvem a lógica de negócios:
- AggregateRoot,
- Entidade, e
- Objeto de valor.
E qualquer código que não se encaixe em nenhum desses modelos deve ir para um serviço de domínio. Também temos os eventos produzidos pelo AggregateRoots sempre que algo muda no modelo. E, por fim, os contratos/interfaces para qualquer domínio de implementação de infraestrutura que possam precisar.
Camada de aplicação: Essa camada fina atua como uma API que expõe as funcionalidades do contexto limitado por meio de casos de uso.
É o cliente direto do modelo de domínio, responsável pela coordenação de tarefas (orquestração) dos fluxos de casos de uso. Além disso, ao usar um banco de dados ACID, a camada de aplicação controla as transações, garantindo que a aplicação persista atômicamente as transições de estado do modelo.
Note
Nota: É um erro considerar o caso de uso da Aplicação igual ao dos Serviços de Domínio. Eles não são. O contraste deve ser marcante. Devemos nos esforçar para colocar toda a lógica de domínio de negócios no modelo de domínio, seja em Agregados, Objetos de Valor ou Serviços de Domínio. Mantenha os Serviços de Aplicação enxutos, usando-os apenas para coordenar tarefas no modelo. (Vaughn Vernon)
Uma camada típica de aplicação consiste em duas pastas, conforme segue:
├───shipping
| ├───commands
| ├───application
| ├───usecases
| ├───CreateShipment
| ├───OrderConfirmedEventHandler
| ├───models
| ├───CreateShipmentRequest
| ├───OrderConfirmedEvent
| ├───queries
| ├───application
| ├───usecases
| ├───ListShipments
| ├───models
| ├───ListShipmentsQueryImplementamos uma classe separada por caso de uso; Cada classe contém um único método chamado executar algo como padrão de comando
Existem três tipos de casos de uso:
- Solicitar para fazer algo (
CriarEnvio,AtualizarStatusEnvio) - Consultar algo (
GetShipments) - Manipulador de Eventos (
OrderReceivedEventHandler)
Camada de infraestrutura: O trabalho da infraestrutura é fornecer capacidades técnicas para outras partes da nossa aplicação. Ele contém qualquer implementação de banco de dados, IOs ou rede, como MongoDB, Postgres, serviços analíticos, controladores, acesso ao sistema de arquivos ou cache de memória.
É útil manter uma mentalidade de Princípio da Inversão de Dependência. Então, onde quer que as camadas de aplicação ou domínio precisem de detalhes de infraestrutura, dependemos de interfaces. Então, quando um caso de uso de aplicação consulta um repositório, ele dependerá apenas da interface do modelo de domínio, mas usando a implementação da infraestrutura.
Um diagrama simples para ilustrar como isso funciona é o seguinte.

O Serviço de Aplicação depende da interface do Repositório do modelo de domínio, mas utiliza a classe de implementação da infraestrutura. Os pacotes abrangem amplas responsabilidades.
├───shipping
| ├───commands
| ├───infrastructure
| ├───controllers
| ├───services
| ├───repositories
| ├───..
Repositórios: Repositórios são classes ou componentes que encapsulam a lógica necessária para acessar fontes de dados. Eles centralizam funcionalidades comuns de acesso a dados, proporcionando melhor manutenção e desacoplando a infraestrutura ou tecnologia usada para acessar bancos de dados a partir da camada do modelo de domínio.
Para cada agregado ou raiz agregada, você deve criar uma classe de repositório.
Criamos uma classe de repositório para cada agregado ou raiz agregada, já que a raiz agregada não permite acesso direto às suas entidades filhas para impor variantes agregadas. Precisamos puxar todo o agregado do banco de dados, realizar ações e salvá-lo.
Dito isso, tenha cuidado ao projetar seu agregado para evitar penalidades de desempenho. Por exemplo, não projete uma raiz agregada contendo uma lista de entidades que aumenta ao longo do tempo. Você precisará extrair uma parte significativa dos dados toda vez que operar com esse agregado. Como resultado, você pode acabar com uma operação muito lenta e, pior ainda, OutOfMemory!.
Algo como uma raiz agregada de carteira com uma lista de transações é um exemplo de um design ruim desse tipo; A transação de uma carteira aumenta com o tempo. Existem múltiplas soluções para esses casos; Uma delas é usar event sourcing.
O último ponto a mencionar aqui é que o repositório esconde diferentes fontes de dados usadas da camada de domínio para que possa usar MongoDB e Redis sem alterações na interface.
Controladores:
- Nos esforçamos para ter um único controlador por API. Por exemplo,
GetUserControllereSaveUserController. Um controlador único por API mantém os controladores menores e diretos ao ponto. - Um controlador recebe a solicitação, a mapeia para o modelo de Aplicação, chama o caso de uso apropriado da aplicação e mapeia o resultado para a entidade de resposta desejada.
Como é um fluxo completo? Os dois diagramas a seguir explicam a implementação de cada fluxo típico.
| Fluxo Típico de Comando: | Fluxo típico de consulta: |
 |
 |
Novamente, não existe uma arquitetura que sirva para todos. Toda arquitetura ou padrão de desenvolvimento de software tem prós e contras; Baseie sua decisão no projeto, no escopo e na equipe.
Padrões de Arquitetura de Integração Empresarial - Redações sobre arquitetura

A perspectiva: Sistemas de TI interagem e, portanto, se integram pelos mesmos motivos que as pessoas.
- Quando precisamos de informações de outras pessoas para o nosso trabalho
- Quando precisamos de alguém para fazer algo por nós
- Quando queremos socializar com alguém
Os exemplos correspondentes de TI são uma chamada de API para uma consulta, uma operação e um cheeping de keep-alive/checagem de saúde (com IA, pode surgir uma verdadeira socialização entre sistemas de TI). Eles também são os tipos de interação mais comuns para os menos comuns.
A empresa se preocupa com a interação entre sistemas tecnológicos e os humanos envolvidos nos processos de negócios. Estes últimos podem ser clientes, funcionários e parceiros. Nem tudo pode ser automatizado, e há humanos nas extremidades ou dentro de sequências de eventos, e precisamos torná-los igualmente parte da solução.
A integração de sistemas é cara e frequentemente o ponto de falha. Assim como nas pessoas, os seguintes princípios tornam a interação entre os sistemas rápida, eficiente e espaçosa.
- A especialização de responsabilidades (coesão)
- A falta de importância de saber como algo funciona ou fornece informação (acoplamento frouxo)
- Uma comunalidade de linguagem (protocolos padronizados)
Como pensar em integração: Integração não é apenas HTTP, REST e algum FTP ou SQLNet antigo em segundo plano. É uma área arquitetônica e disciplina interessante e complexa. Não existe uma única forma de encarar isso. Eu vejo isso sob seis pontos de vista que nos permitem criar requisitos sólidos de arquitetura de integração, declarações de problemas e soluções.
Esses pontos de vista de integração, dos mais amplos aos mais detalhados, são
Escopo da integração empresarial → Hierarquia de padrões de integração empresarial → Padrões de integração de aplicações → Integração horizontal das camadas dos sistemas → integração sem estado versus com estado → Segurança da integração
(Usaremos terminologia arquitetonicamente relevante do Design Orientado por Domínio, especialmente os termos específicos de DDD para camadas — UI, Aplicação, Domínio e Infraestrutura. Outros termos DDD estão em itálico. Por favor, consulte meus artigos sobre Arquitetura Orientada por Domínio Parte I e II.)
Uma vez que você entenda a integração sob os pontos de vista abaixo, poderá definir e resolver problemas de integração de forma holística, eficiente e eficaz.
Ponto de Vista 1: O escopo da integração empresarial: É útil começar com uma visão de onde as interações estão acontecendo, pois isso influencia sua natureza e soluções.
Intra-Domínio: Integrações dentro de um domínio de negócios são as mais comuns. Eles conectam sistemas relacionados com arquitetura e modelos de design semelhantes (assumindo o Domain Driven Design). Isso permite mapas de contexto mais simples entre contextos limitados e integrações mais diretas, com menos preocupações de capacidade e escalabilidade: por exemplo, integração entre um sistema de Gestão de Estoque e um Sistema de Compras.
Interdomínio: As integrações entre domínios de negócio são menores, mas apresentam mais desafios. A Linguagem Ubíqua provavelmente diferirá em cada domínio, e a carga útil de dados e os objetos de resposta frequentemente precisam ser transformados nas interações. A infraestrutura também pode ser separada um pouco ou muito, introduzindo a necessidade de várias funções de suporte (veja ponto de vista #2 abaixo) para uma integração bem-sucedida, por exemplo, integração entre um Sistema de Gerenciamento de Pedidos no domínio de vendas com um Sistema de Gerenciamento de Relacionamento com o Cliente no domínio de atendimento ao cliente.
Inter-Empresas: A integração entre empresas parceiras em cenários B2B e B2B2C está aumentando exponencialmente com os serviços modernos de web e digitais. Felizmente, os padrões de integração de serviços e serviços em nuvem acompanharam as arquiteturas emergentes da web, mobile e digital, atendendo às necessidades de serviços integrados confiáveis, rápidos e rápidos em escala, seguros e ágeis, desenvolvendo serviços integrados que abrangem de duas a dezenas de empresas em ecossistemas como eCommerce, logística, viagens, automotivo, manufatura, companhia aérea, bancos e serviços financeiros.
A imagem abaixo ilustra esse ponto de vista:

Diretrizes: Considere cada tipo de integração acima separadamente por suas características e os cinco pontos de vista abaixo para personalizar as arquiteturas de integração.
Ponto de Vista 2: Hierarquia dos padrões de integração empresarial - Hierarquia de funções de negócio
-
BPM — A gestão de processos de negócios coordena pessoas, sistemas, informações e coisas para produzir resultados de negócios para os domínios e subdomínios da empresa. Exemplos são design de produto, fabricação, marketing, aquisição de clientes, vendas, etc. A arquitetura BPM automatiza a integração dinâmica dos processos de negócios na máxima medida possível para fornecer resultados bem definidos, repetíveis, eficientes e confiáveis.
-
Fluxo de trabalho — Um fluxo de trabalho é uma sequência definida de tarefas realizadas por sistemas e humanos trabalhando juntos para entregar uma tarefa de negócio. Pode ser considerado um subconjunto de um processo de negócios. Um exemplo é o fluxo de aprovação de um empréstimo empresarial. A arquitetura de workflow integra sistemas de TI e humanos para a iniciação, roteamento, suporte analítico à decisão, etapas manuais, tarefas automatizadas, coordenação e monitoramento dos fluxos de trabalho.
-
Integração de sistemas — Em um cenário de TI bem projetado, a funcionalidade é dividida em sistemas coesos que mapeiam capacidades de domínio e subdomínio de negócio. Esses sistemas devem trabalhar juntos para entregar resultados úteis para fluxos de trabalho e processos de negócios. A integração de sistemas automatiza a cooperação dinâmica deles. (Leia este artigo para saber mais sobre os tipos de sistemas que precisam ser integrados → Uma Abstração Prática de Sistemas de TI Funcionais.)
-
Integração de componentes — Todos os sistemas de TI são segregados internamente em componentes e subcomponentes coesos e fracamente acoplados. Esses são integrados usando padrões padrão (veja ponto de vista #4 abaixo) para entregar as funções externamente úteis do sistema.
A imagem abaixo ilustra esse enquadramento:

Hierarquia técnica de funções: A integração é cara e deve ser o mais simples possível. O quão difícil e propenso a problemas será depende da maturidade dos sistemas de TI (ou seja, aplicações). Quando sistemas/serviços cliente e servidor se comunicam como parte de um processo de negócio, algumas ou todas as seguintes funções podem ser necessárias.
- Retentando — o servidor não responde na primeira tentativa
- Mensagens — o servidor não pode ser contatado diretamente
- Gerenciamento de carga (fila, balanceamento, pooling de conexão) — o servidor pode responder a um número limitado de solicitações por unidade de tempo
- Publicar-assinar — o servidor possui informações que um ou mais consumidores podem obter enquanto estão atualizadas
- Transformação de objetos — o cliente e o servidor trabalham com pacotes de dados suficientes, porém diferentes.
- Transformação de protocolo — cliente e servidor não usam o mesmo protocolo de comunicação
- Conversão sincronizada — o cliente espera uma resposta online enquanto o servidor é projetado para uma resposta offline ou espera uma resposta offline enquanto o servidor é projetado para uma resposta online.
- Fusão de funções ou dados — o cliente deve ser atendido a partir de uma combinação de mais de uma operação ou repositório de informações.
- Roteamento — o servidor correto deve ser alcançado com base em regras
- Orquestração — uma sequência de operações deve ser realizada para responder ao cliente, e a lógica está em um único lugar. (Coreografia é um conceito relacionado, onde a lógica de ação e sequência são distribuídas nos serviços participantes; no entanto, sua capacidade funcional é limitada, e geralmente há um orquestrador centralizado de algum tipo, mesmo que seja apenas um conjunto de regras de referência passivo.)
- Gerenciamento de versões — diferentes clientes precisam de versões diferentes da mesma operação
- Segurança (veja ponto de vista #6 abaixo) — o cliente e o servidor precisam ser protegidos de uma ou mais maneiras
Quanto mais dessas necessidades os sistemas cliente e servidor atendem internamente, menos o arquiteto de integração precisa fornecê-las externamente. Em outras palavras, a arquitetura da aplicação e da informação influenciam significativamente a complexidade e o custo da arquitetura de integração para construir e operar.
Normalmente, haverá algumas funções de integração externas que precisamos atender. Mas quanto mais direta e simples a integração, melhor.
Padrões e plataformas de soluções de integração intermediária: Os padrões de solução de integração externa são os seguintes, em ordem crescente de escopo. Tecnicamente, eles não são padrões arquitetônicos, e alguns se sobrepõem funcionalmente. Então, compreenda as diferenças deles e use os termos com cuidado.
-
RPC — uma chamada de procedimento remoto (RPC) é quando um programa de computador faz com que um procedimento (sub-rotina) seja executado em um espaço de endereçamento diferente (comumente em outro computador em uma rede compartilhada), codificado como se fosse uma chamada de procedimento comum (local), para simplificar a programação e não precisar lidar com detalhes de rede, protocolo e sistema operacional, etc.
-
Integração intra-app — interações entre as camadas de UI, aplicação, domínio e repositório de um sistema (termos DDD; ou UI, lógica de negócio e camadas de banco de dados em terminologia mais antiga), por exemplo, entre a interface e a camada de lógica de negócios (usando protocolos HTTP(s)) e entre a lógica de negócio e a camada de banco de dados (usando TNS/TTC sobre protocolos TCP/IP para o Oracle DB).
-
API de Leitura (DAL) — uma API de leitura ou Camada de Acesso a Dados é uma camada comum de integração em Fontes de Dados Operacionais (ODS), Bancos de Dados de Sistemas de Informação de Gestão (MIS DBs) e camadas de negócios de BI acessadas por transações de leitura OLTP e OLAP.
-
API — Uma Interface de Programação de Aplicações é uma interface de software para comunicação entre sistemas de TI. Uma API geralmente suporta múltiplas operações. O projeto é guiado pela padronização das assinaturas de funções e protocolos de rede, e um documento de especificação da API é publicado. APIs frequentemente possuem várias versões disponíveis para diferentes clientes. A descoberta dinâmica e a vinculação de APIs e operações por clientes durante a execução também podem ser suportadas.
-
API GW — um API Gateway realiza uma combinação de padrões arquitetônicos como fachada, adaptador, mediador e (reverso) proxy. Ele recebe chamadas de clientes e as roteia para os serviços que estão por detrás dele, enquanto fornece funções como roteamento, limitação de taxa, transformação de protocolo, agregação, segurança, versionamento, logs, etc.
-
Sistemas de Mensagens — o padrão de integração de mensagens permite que os sistemas sejam acoplados de forma fraca por meio da comunicação assíncrona, tornando a comunicação mais confiável porque os dois sistemas não precisam funcionar simultaneamente. O sistema de mensagens é responsável por transferir dados de um sistema para outro, para que possam focar nas informações que precisam compartilhar e não gerenciar a interação ativamente. É como um serviço de cartas postal.
-
Sistemas de Fila (de Mensagens) — o padrão de fila estende o padrão de comunicação assíncrona da Mensagem, fornecendo um pipeline onde múltiplas mensagens podem ser armazenadas sequencialmente por sistemas clientes ou servidores até que sejam consumidas, geralmente em um sistema de Primeiro Entrado, Primeiro a Sair (FIFO), ou se tornem obsoletas. Mensagens de solicitação são colocadas em filas pelos sistemas clientes e captadas e atendidas com mensagens em filas de resposta pelos sistemas de serviço. Filas aumentam a confiabilidade e o throughput líquido e reduzem a perda de dados. Esse acoplamento frouxo permite o desenvolvimento independente e ágil dos sistemas. Gerenciar as filas e seu conteúdo, envelhecimento, escalonamento, registro, etc., são funções fornecidas pela plataforma de fila de mensagens. É como fazer fila para comprar um ingresso para um filme.
-
Sistemas de Publicação-Assinatura — o padrão de publicação é um padrão de comunicação assíncrono e fracamente acoplado para que um sistema de serviço disponibilize informações ou funções às quais clientes interessados possam se inscrever. É como publicar jornais e assinar por leitores interessados.
-
ESBs — Um Barramento de Serviços Empresariais combina múltiplas funções de integração, como mensagens, fila, publicação-assinatura, roteamento, transformação de protocolo, transformação de objetos, etc., em uma única plataforma de software. Elas são uma das plataformas EAI mais comuns (veja abaixo).
-
Plataformas EAI — de modo geral, as plataformas de Integração de Aplicações Empresariais podem fornecer todas as 12 funções de integração abordadas na seção de Hierarquia de Funções Técnicas acima e os tipos de solução 2 a 9 acima.
-
Gerentes de Fluxo de Trabalho — Plataformas de fluxo de trabalho integram os sistemas e as pessoas para a iniciação, roteamento, suporte à decisão, ações manuais, tarefas automatizadas, coordenação e monitoramento da sequência de etapas realizadas por sistemas e humanos juntos para uma tarefa de negócio.
-
Gerentes de Processos de Negócios — Plataformas BPM automatizam a integração dinâmica dos processos de negócios para fornecer resultados bem definidos, repetíveis, eficientes e confiáveis. Eles geralmente cobrem serviços de descoberta, análise e otimização.
Diretrizes: O que é necessário para a integração surge organicamente da arquitetura de aplicações e informações e dos processos e fluxos de trabalho de negócios que eles atendem. Mas, às vezes, há uma decisão a ser tomada se devemos refatorar aplicações para melhor integração ou usar uma plataforma externa.
O teste de tornasol mostrado abaixo nos ajuda a identificar a necessidade de apoio externo. Se a pontuação for baixa, é recomendável refatorar as candidaturas.

Ponto de Vista 3: Padrões de integração de aplicativos: Desde o início, os padrões de design de aplicações incluíram padrões de integração. Alguns desses fatores estão alinhados com o pensamento arquitetônico; Podemos nos adaptar e adotá-los. O livro 'Gang of Four' sobre Padrões de Design de Aplicações aborda os seguintes temas arquitetonicamente relevantes, que são brevemente descrevidos. Como arquiteto de aplicações e integração, aprenda e use esses padrões.
-
Facade — Fornece uma interface unificada para um conjunto de interfaces em um subsistema. A Facade define uma interface de nível superior que torna o subsistema mais fácil de usar. Por exemplo, uma fachada de API para Order reúne as interfaces de múltiplos subsistemas subjacentes, como ManageStock, CheckPayment, FulfilOrder, etc.
-
Adapter — Converte a interface de uma classe em outra interface que os clientes esperam. O adaptador permite que classes trabalhem juntas que, de outra forma, não poderiam por causa de interfaces incompatíveis. Em termos arquitetônicos, pense em sistema, aplicação, componente ou subcomponente em vez de classe. Por exemplo, um PaymentGWAdapter preenche um campo de tipo cliente obrigatório exigido por uma interface de sistema de pagamento com um valor padrão para um cliente que não o fornece.
-
Proxy — Fornece um substituto ou substituto para outro objeto controlar o acesso a ele. Funcionalmente, eles podem ser ainda divididos em Proxy Remoto (representação local de uma API remota), Proxy Virtual (fornece cache e acesso backend sob demanda), Proxy de Proteção (acesso de controle baseado em funções e regras) e Proxy Auxiliar (fornece serviços adicionais como contagem, registro, etc.). Por exemplo, uma CDN (rede de entrega de conteúdo) usa um proxy reverso para segurança, balanceamento de carga e escalabilidade.
-
**Observ