Closed
Conversation
…ing time regression ### What changes were proposed in this pull request? After #28192, the job list page becomes very slow. For example, after the following operation, the UI loading can take >40 sec. ``` (1 to 1000).foreach(_ => sc.parallelize(1 to 10).collect) ``` This is caused by a [performance issue of `vis-timeline`](visjs/vis-timeline#379). The serious issue affects both branch-3.0 and branch-2.4 I tried a different version 4.21.0 from https://cdnjs.com/libraries/vis The infinite drawing issue seems also fixed if the zoom is disabled as default. ### Why are the changes needed? Fix the serious perf issue in web UI by falling back vis-timeline-graph2d to an ealier version. ### Does this PR introduce _any_ user-facing change? Yes, fix the UI perf regression ### How was this patch tested? Manual test Closes #28813 from gengliangwang/vis2.4. Authored-by: Gengliang Wang <gengliang.wang@databricks.com> Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
…n application summary is unavailable ### What changes were proposed in this pull request? <!-- Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue. If possible, please consider writing useful notes for better and faster reviews in your PR. See the examples below. 1. If you refactor some codes with changing classes, showing the class hierarchy will help reviewers. 2. If you fix some SQL features, you can provide some references of other DBMSes. 3. If there is design documentation, please add the link. 4. If there is a discussion in the mailing list, please add the link. --> This PR enriches the exception message when application summary is not available. #28444 covers the case when application information is not available but the case application summary is not available is not covered. ### Why are the changes needed? <!-- Please clarify why the changes are needed. For instance, 1. If you propose a new API, clarify the use case for a new API. 2. If you fix a bug, you can clarify why it is a bug. --> To complement #28444 . ### Does this PR introduce _any_ user-facing change? <!-- Note that it means *any* user-facing change including all aspects such as the documentation fix. If yes, please clarify the previous behavior and the change this PR proposes - provide the console output, description and/or an example to show the behavior difference if possible. If possible, please also clarify if this is a user-facing change compared to the released Spark versions or within the unreleased branches such as master. If no, write 'No'. --> Yes. Before this change, we can get the following error message when we access to `/jobs` if application summary is not available. <img width="707" alt="no-such-element-exception-error-message" src="https://user-images.githubusercontent.com/4736016/84562182-6aadf200-ad8d-11ea-8980-d63edde6fad6.png"> After this change, we can get the following error message. It's like #28444 does. <img width="1349" alt="enriched-errorm-message" src="https://user-images.githubusercontent.com/4736016/84562189-85806680-ad8d-11ea-8346-4da2ec11df2b.png"> ### How was this patch tested? <!-- If tests were added, say they were added here. Please make sure to add some test cases that check the changes thoroughly including negative and positive cases if possible. If it was tested in a way different from regular unit tests, please clarify how you tested step by step, ideally copy and paste-able, so that other reviewers can test and check, and descendants can verify in the future. If tests were not added, please describe why they were not added and/or why it was difficult to add. --> I checked with the following procedure. 1. Set breakpoint in the line of `kvstore.write(appSummary)` in `AppStatusListener#onStartApplicatin`. Only the thread reaching this line should be suspended. 2. Start spark-shell and wait few seconds. 3. Access to `/jobs` Closes #28820 from sarutak/fix-no-such-element. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit c2e5012) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
{kind=link}
### What changes were proposed in this pull request?
A unit test is added
Partition duplicate check added in `org.apache.spark.sql.execution.datasources.PartitioningUtils#validatePartitionColumn`
### Why are the changes needed?
When people write data with duplicate partition column, it will cause a `org.apache.spark.sql.AnalysisException: Found duplicate column ...` in loading data from the writted.
### Does this PR introduce _any_ user-facing change?
Yes.
It will prevent people from using duplicate partition columns to write data.
1. Before the PR:
It will look ok at `df.write.partitionBy("b", "b").csv("file:///tmp/output")`,
but get an exception when read:
`spark.read.csv("file:///tmp/output").show()`
org.apache.spark.sql.AnalysisException: Found duplicate column(s) in the partition schema: `b`;
2. After the PR:
`df.write.partitionBy("b", "b").csv("file:///tmp/output")` will trigger the exception:
org.apache.spark.sql.AnalysisException: Found duplicate column(s) b, b: `b`;
### How was this patch tested?
Unit test.
Closes #28814 from TJX2014/master-SPARK-31968.
Authored-by: TJX2014 <xiaoxingstack@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit a4ea599)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…tion is enabled ### What changes were proposed in this pull request? Added a Shutdown Hook in `executor.scala` which will ensure that executor's `stop()` method is always called. ### Why are the changes needed? In case executors are not going down gracefully, their `stop()` is not called. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Manually Closes #26901 from iRakson/SPARK-29152_2.4. Authored-by: iRakson <raksonrakesh@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…c allocation is enabled" This reverts commit 90e928c.
…e test completed ### What changes were proposed in this pull request? `SingleSessionSuite` not do `DROP TABLE IF EXISTS test_udtf` when test completed, then if we do mvn test `HiveThriftBinaryServerSuite`, the test case named `SPARK-11595 ADD JAR with input path having URL scheme` will FAILED because it want to re-create an exists table test_udtf. ### Why are the changes needed? test suite shouldn't rely on their execution order ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? Manual test,mvn test SingleSessionSuite and HiveThriftBinaryServerSuite in order Closes #28838 from LuciferYang/drop-test-table. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit d24d27f) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…ched task in barrier-mode ### What changes were proposed in this pull request? This PR changes the test to get an active executorId and set it as preferred location instead of setting a fixed preferred location. ### Why are the changes needed? The test is flaky. After checking the [log](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124086/artifact/core/), I find the root cause is: Two test cases from different test suites got submitted at the same time because of concurrent execution. In this particular case, the two test cases (from DistributedSuite and BarrierTaskContextSuite) both launch under local-cluster mode. The two applications are submitted at the SAME time so they have the same applications(app-20200615210132-0000). Thus, when the cluster of BarrierTaskContextSuite is launching executors, it failed to create the directory for the executor 0, because the path (/home/jenkins/workspace/work/app-app-20200615210132-0000/0) has been used by the cluster of DistributedSuite. Therefore, it has to launch executor 1 and 2 instead, that lead to non of the tasks can get preferred locality thus they got scheduled together and lead to the test failure. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? The test can not be reproduced locally. We can only know it's been fixed when it's no longer flaky on Jenkins. Closes #28851 from Ngone51/fix-spark-32000-24. Authored-by: yi.wu <yi.wu@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…orting column What changes were proposed in this pull request? issue link https://issues.apache.org/jira/browse/SPARK-31871 this PR link #28680 As sarutak suggested I open a new PR for branch-2.4 This issue is resolved the sorted list cannot display ICONS Before: Executors Page 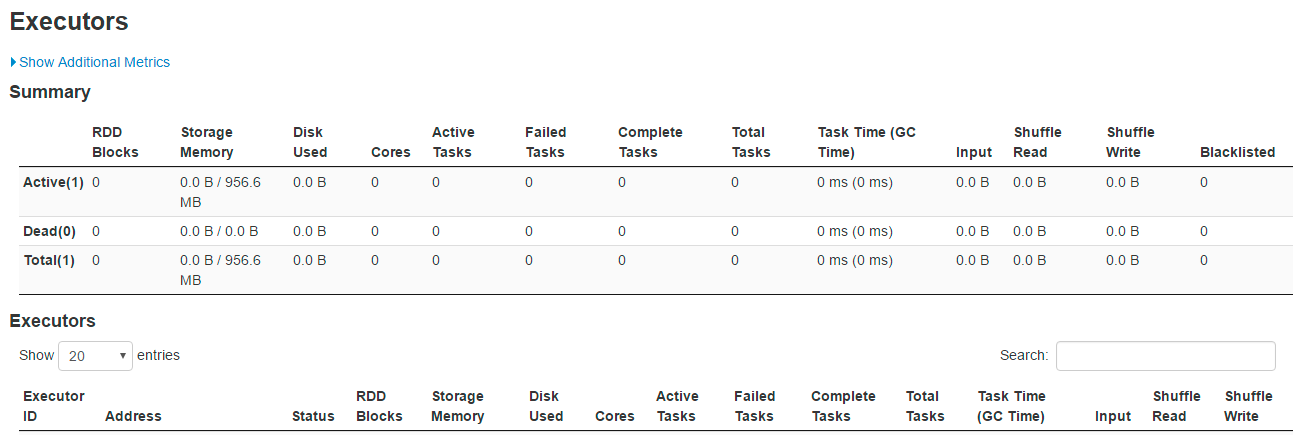 History Server Page 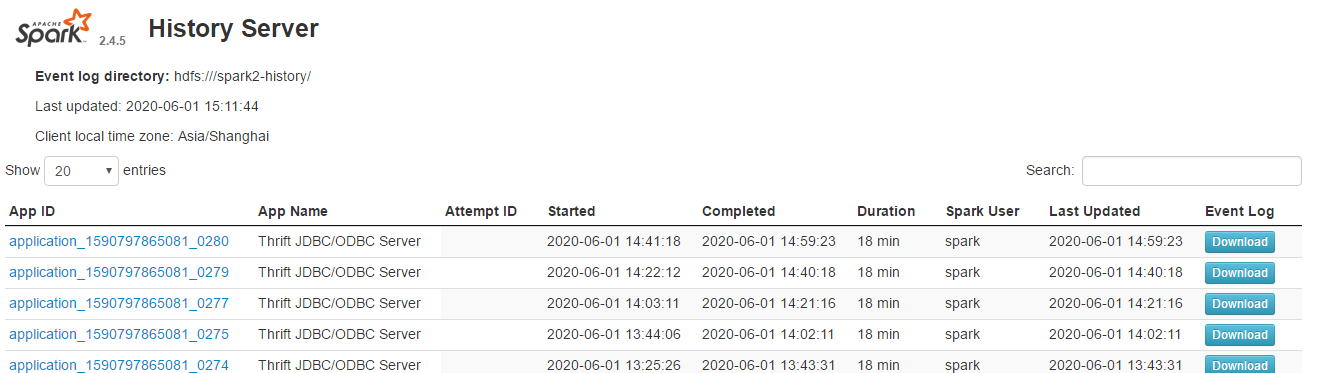 After: Executors Page 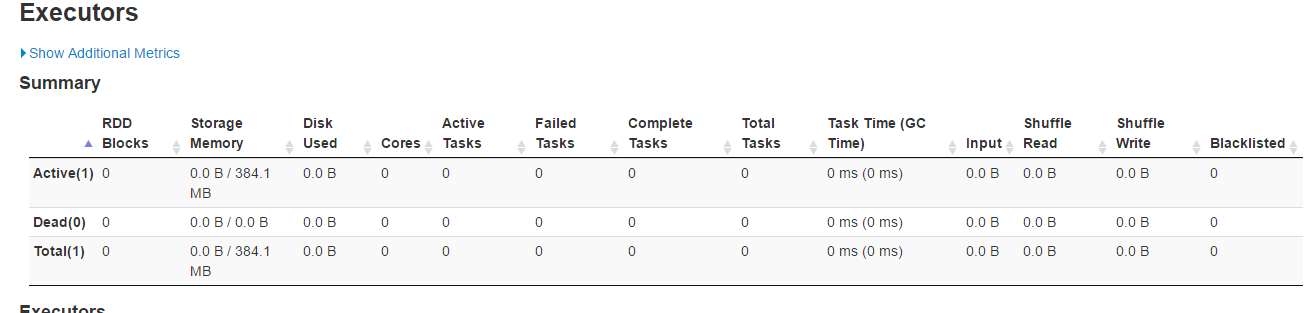 History Server Page 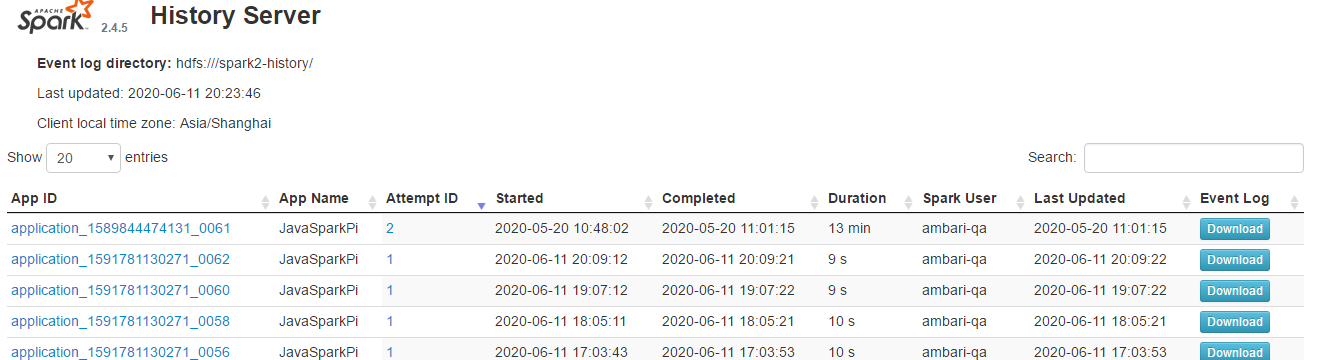 Why are the changes needed? The icon could not find the correct path Does this PR introduce any user-facing change? No. How was this patch tested? Fixed existing test. history server page: Closes #28799 from liucht-inspur/branch-2.4. Lead-authored-by: liucht <liucht@inspur.com> Co-authored-by: liucht-inspur <liucht@inspur.com> Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
…e are equal dates
### What changes were proposed in this pull request?
1. Add judge equal as bigger condition in `org.apache.spark.sql.catalyst.expressions.Sequence.TemporalSequenceImpl#eval`
2. Unit test for interval `day`, `month`, `year`
### Why are the changes needed?
Bug exists when sequence input get same equal start and end dates, which will occur `while loop` forever
### Does this PR introduce _any_ user-facing change?
Yes,
Before this PR, people will get a `java.lang.ArrayIndexOutOfBoundsException`, when eval as below:
`sql("select sequence(cast('2011-03-01' as date), cast('2011-03-01' as date), interval 1 year)").show(false)
`
### How was this patch tested?
Unit test.
Closes #28819 from TJX2014/master-SPARK-31980.
Authored-by: TJX2014 <xiaoxingstack@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit 177a380)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
… of range are equal dates" This reverts commit dee27ee.
… range are equal dates ### What changes were proposed in this pull request? 1. Add judge equal as bigger condition in `org.apache.spark.sql.catalyst.expressions.Sequence.TemporalSequenceImpl#eval` 2. Unit test for interval `day`, `month`, `year` Former PR to master is [https://github.com/apache/spark/pull/28819](url) Current PR change `stringToInterval => CalendarInterval.fromString` in order to compatible with branch-2.4 ### Why are the changes needed? Bug exists when sequence input get same equal start and end dates, which will occur `while loop` forever ### Does this PR introduce _any_ user-facing change? Yes, Before this PR, people will get a `java.lang.ArrayIndexOutOfBoundsException`, when eval as below: `sql("select sequence(cast('2011-03-01' as date), cast('2011-03-01' as date), interval 1 year)").show(false) ` ### How was this patch tested? Unit test. Closes #28877 from TJX2014/branch-2.4-SPARK-31980-compatible. Authored-by: TJX2014 <xiaoxingstack@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…timeoutChecker thread properly upon shutdown ### What changes were proposed in this pull request? This PR backports #28870 which ports https://issues.apache.org/jira/browse/HIVE-14817 for spark thrift server. ### Why are the changes needed? Port HIVE-14817 to fix related issues ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? passing Jenkins Closes #28888 from yaooqinn/SPARK-32034-24. Authored-by: Kent Yao <yaooqinn@hotmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…ial offset ### What changes were proposed in this pull request? Use `java.util.Optional.orElseGet` instead of `java.util.Optional.orElse` to fix unnecessary kafka offset fetch and misleading info log. In Java, `orElseGet` uses lazy evaluation while `orElse` always evaluate the expression. ### Why are the changes needed? Fix mislead initial offsets log and unnecessary kafka offset fetch ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Currently, no test for KafkaContinuousReader. Also it's hard to test log. Closes #28887 from warrenzhu25/SPARK-32044. Authored-by: Warren Zhu <zhonzh@microsoft.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…closure cleaning to support R 4.0.0+ ### What changes were proposed in this pull request? This PR proposes to ignore S4 generic methods under SparkR namespace in closure cleaning to support R 4.0.0+. Currently, when you run the codes that runs R native codes, it fails as below with R 4.0.0: ```r df <- createDataFrame(lapply(seq(100), function (e) list(value=e))) count(dapply(df, function(x) as.data.frame(x[x$value < 50,]), schema(df))) ``` ``` org.apache.spark.SparkException: R unexpectedly exited. R worker produced errors: Error in lapply(part, FUN) : attempt to bind a variable to R_UnboundValue ``` The root cause seems to be related to when an S4 generic method is manually included into the closure's environment via `SparkR:::cleanClosure`. For example, when an RRDD is created via `createDataFrame` with calling `lapply` to convert, `lapply` itself: https://github.com/apache/spark/blob/f53d8c63e80172295e2fbc805c0c391bdececcaa/R/pkg/R/RDD.R#L484 is added into the environment of the cleaned closure - because this is not an exposed namespace; however, this is broken in R 4.0.0+ for an unknown reason with an error message such as "attempt to bind a variable to R_UnboundValue". Actually, we don't need to add the `lapply` into the environment of the closure because it is not supposed to be called in worker side. In fact, there is no private generic methods supposed to be called in worker side in SparkR at all from my understanding. Therefore, this PR takes a simpler path to work around just by explicitly excluding the S4 generic methods under SparkR namespace to support R 4.0.0. in SparkR. ### Why are the changes needed? To support R 4.0.0+ with SparkR, and unblock the releases on CRAN. CRAN requires the tests pass with the latest R. ### Does this PR introduce _any_ user-facing change? Yes, it will support R 4.0.0 to end-users. ### How was this patch tested? Manually tested. Both CRAN and tests with R 4.0.1: ``` ══ testthat results ═══════════════════════════════════════════════════════════ [ OK: 13 | SKIPPED: 0 | WARNINGS: 0 | FAILED: 0 ] ✔ | OK F W S | Context ✔ | 11 | binary functions [2.5 s] ✔ | 4 | functions on binary files [2.1 s] ✔ | 2 | broadcast variables [0.5 s] ✔ | 5 | functions in client.R ✔ | 46 | test functions in sparkR.R [6.3 s] ✔ | 2 | include R packages [0.3 s] ✔ | 2 | JVM API [0.2 s] ✔ | 75 | MLlib classification algorithms, except for tree-based algorithms [86.3 s] ✔ | 70 | MLlib clustering algorithms [44.5 s] ✔ | 6 | MLlib frequent pattern mining [3.0 s] ✔ | 8 | MLlib recommendation algorithms [9.6 s] ✔ | 136 | MLlib regression algorithms, except for tree-based algorithms [76.0 s] ✔ | 8 | MLlib statistics algorithms [0.6 s] ✔ | 94 | MLlib tree-based algorithms [85.2 s] ✔ | 29 | parallelize() and collect() [0.5 s] ✔ | 428 | basic RDD functions [25.3 s] ✔ | 39 | SerDe functionality [2.2 s] ✔ | 20 | partitionBy, groupByKey, reduceByKey etc. [3.9 s] ✔ | 4 | functions in sparkR.R ✔ | 16 | SparkSQL Arrow optimization [19.2 s] ✔ | 6 | test show SparkDataFrame when eager execution is enabled. [1.1 s] ✔ | 1175 | SparkSQL functions [134.8 s] ✔ | 42 | Structured Streaming [478.2 s] ✔ | 16 | tests RDD function take() [1.1 s] ✔ | 14 | the textFile() function [2.9 s] ✔ | 46 | functions in utils.R [0.7 s] ✔ | 0 1 | Windows-specific tests ──────────────────────────────────────────────────────────────────────────────── test_Windows.R:22: skip: sparkJars tag in SparkContext Reason: This test is only for Windows, skipped ──────────────────────────────────────────────────────────────────────────────── ══ Results ═════════════════════════════════════════════════════════════════════ Duration: 987.3 s OK: 2304 Failed: 0 Warnings: 0 Skipped: 1 ... Status: OK + popd Tests passed. ``` Note that I tested to build SparkR in R 4.0.0, and run the tests with R 3.6.3. It all passed. See also [the comment in the JIRA](https://issues.apache.org/jira/browse/SPARK-31918?focusedCommentId=17142837&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-17142837). Closes #28907 from HyukjinKwon/SPARK-31918. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 11d2b07) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
Spark 3.0 accidentally dropped R < 3.5. It is built by R 3.6.3 which not support R < 3.5: ``` Error in readRDS(pfile) : cannot read workspace version 3 written by R 3.6.3; need R 3.5.0 or newer version. ``` In fact, with SPARK-31918, we will have to drop R < 3.5 entirely to support R 4.0.0. This is inevitable to release on CRAN because they require to make the tests pass with the latest R. To show the supported versions correctly, and support R 4.0.0 to unblock the releases. In fact, no because Spark 3.0.0 already does not work with R < 3.5. Compared to Spark 2.4, yes. R < 3.5 would not work. Jenkins should test it out. Closes #28908 from HyukjinKwon/SPARK-32073. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit b62e253) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…ct slicing in createDataFrame with Arrow
When you use floats are index of pandas, it creates a Spark DataFrame with a wrong results as below when Arrow is enabled:
```bash
./bin/pyspark --conf spark.sql.execution.arrow.pyspark.enabled=true
```
```python
>>> import pandas as pd
>>> spark.createDataFrame(pd.DataFrame({'a': [1,2,3]}, index=[2., 3., 4.])).show()
+---+
| a|
+---+
| 1|
| 1|
| 2|
+---+
```
This is because direct slicing uses the value as index when the index contains floats:
```python
>>> pd.DataFrame({'a': [1,2,3]}, index=[2., 3., 4.])[2:]
a
2.0 1
3.0 2
4.0 3
>>> pd.DataFrame({'a': [1,2,3]}, index=[2., 3., 4.]).iloc[2:]
a
4.0 3
>>> pd.DataFrame({'a': [1,2,3]}, index=[2, 3, 4])[2:]
a
4 3
```
This PR proposes to explicitly use `iloc` to positionally slide when we create a DataFrame from a pandas DataFrame with Arrow enabled.
FWIW, I was trying to investigate why direct slicing refers the index value or the positional index sometimes but I stopped investigating further after reading this https://pandas.pydata.org/pandas-docs/stable/getting_started/10min.html#selection
> While standard Python / Numpy expressions for selecting and setting are intuitive and come in handy for interactive work, for production code, we recommend the optimized pandas data access methods, `.at`, `.iat`, `.loc` and `.iloc`.
To create the correct Spark DataFrame from a pandas DataFrame without a data loss.
Yes, it is a bug fix.
```bash
./bin/pyspark --conf spark.sql.execution.arrow.pyspark.enabled=true
```
```python
import pandas as pd
spark.createDataFrame(pd.DataFrame({'a': [1,2,3]}, index=[2., 3., 4.])).show()
```
Before:
```
+---+
| a|
+---+
| 1|
| 1|
| 2|
+---+
```
After:
```
+---+
| a|
+---+
| 1|
| 2|
| 3|
+---+
```
Manually tested and unittest were added.
Closes #28928 from HyukjinKwon/SPARK-32098.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
(cherry picked from commit 1af19a7)
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
Bug fix for overflow case in `UTF8String.substringSQL`.
SQL query `SELECT SUBSTRING("abc", -1207959552, -1207959552)` incorrectly returns` "abc"` against expected output of `""`. For query `SUBSTRING("abc", -100, -100)`, we'll get the right output of `""`.
Yes, bug fix for the overflow case.
New UT.
Closes #28937 from xuanyuanking/SPARK-32115.
Authored-by: Yuanjian Li <xyliyuanjian@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit 6484c14)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…istory summary page This is simply a backport of #28867 to branch-2.4 Closes #28949 from srowen/SPARK-32028.2. Authored-by: Zhen Li <zhli@microsoft.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…US operations fix error exception messages during exceptions on Union and set operations Union and set operations can only be performed on tables with the compatible column types,while when we have more than two column, the exception messages will have wrong column index. Steps to reproduce: ``` drop table if exists test1; drop table if exists test2; drop table if exists test3; create table if not exists test1(id int, age int, name timestamp); create table if not exists test2(id int, age timestamp, name timestamp); create table if not exists test3(id int, age int, name int); insert into test1 select 1,2,'2020-01-01 01:01:01'; insert into test2 select 1,'2020-01-01 01:01:01','2020-01-01 01:01:01'; insert into test3 select 1,3,4; ``` Query1: ```sql select * from test1 except select * from test2; ``` Result1: ``` Error: org.apache.spark.sql.AnalysisException: Except can only be performed on tables with the compatible column types. timestamp <> int at the second column of the second table;; 'Except false :- Project [id#620, age#621, name#622] : +- SubqueryAlias `default`.`test1` : +- HiveTableRelation `default`.`test1`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#620, age#621, name#622] +- Project [id#623, age#624, name#625] +- SubqueryAlias `default`.`test2` +- HiveTableRelation `default`.`test2`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#623, age#624, name#625] (state=,code=0) ``` Query2: ```sql select * from test1 except select * from test3; ``` Result2: ``` Error: org.apache.spark.sql.AnalysisException: Except can only be performed on tables with the compatible column types int <> timestamp at the 2th column of the second table; ``` the above query1 has the right exception message the above query2 have the wrong errors information, it may need to change to the following ``` Error: org.apache.spark.sql.AnalysisException: Except can only be performed on tables with the compatible column types. int <> timestamp at the third column of the second table ``` NO unit test Closes #28951 from GuoPhilipse/32131-correct-error-messages. Lead-authored-by: GuoPhilipse <46367746+GuoPhilipse@users.noreply.github.com> Co-authored-by: GuoPhilipse <guofei_ok@126.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 02f3b80) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…kerFiile This PR proposes to upgrade R version to 4.0.2 in the release docker image. As of SPARK-31918, we should make a release with R 4.0.0+ which works with R 3.5+ too. To unblock releases on CRAN. No, dev-only. Manually tested via scripts under `dev/create-release`, manually attaching to the container and checking the R version. Closes #28922 from HyukjinKwon/SPARK-32089. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… effective in data source options ### What changes were proposed in this pull request? backport #28948 This is a followup of #28760 to fix the remaining issues: 1. should consider data source options when refreshing cache by path at the end of `InsertIntoHadoopFsRelationCommand` 2. should consider data source options when inferring schema for file source 3. should consider data source options when getting the qualified path in file source v2. ### Why are the changes needed? We didn't catch these issues in #28760, because the test case is to check error when initializing the file system. If we initialize the file system multiple times during a simple read/write action, the test case actually only test the first time. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? rewrite the test to make sure the entire data source read/write action can succeed. Closes #28973 from cloud-fan/pick. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request? For queries like `t1d in (SELECT t2d FROM t2 ORDER BY t2c LIMIT 2)`, the result can be non-deterministic as the result of the subquery may output different results (it's not sorted by `t2d` and it has shuffle). This PR makes the test more robust by sorting the output column. ### Why are the changes needed? avoid flaky test ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? N/A Closes #28976 from cloud-fan/small. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit f834156) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…Java for "other" type uses a wrong variable ### What changes were proposed in this pull request? This PR fixes an inconsistency in `EvaluatePython.makeFromJava`, which creates a type conversion function for some Java/Scala types. `other` is a type but it should actually pass `obj`: ```scala case other => (obj: Any) => nullSafeConvert(other)(PartialFunction.empty) ``` This does not change the output because it always returns `null` for unsupported datatypes. ### Why are the changes needed? To make the codes coherent, and consistent. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? No behaviour change. Closes #29029 from sarutak/fix-makeFromJava. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 371b35d) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…erverDiskManager initializing ### What changes were proposed in this pull request? Update ApplicationStoreInfo.size to real size during HistoryServerDiskManager initializing. ### Why are the changes needed? This PR is for fixing bug [32024](https://issues.apache.org/jira/browse/SPARK-32024). We found after history server restart, below error would randomly happen: "java.lang.IllegalStateException: Disk usage tracker went negative (now = -***, delta = -***)" from `HistoryServerDiskManager`.  **Cause**: Reading data from level db would trigger table file compaction, which may also trigger size of level db directory changes. This size change may not be recorded in LevelDB (`ApplicationStoreInfo` in `listing`). When service restarts, `currentUsage` is calculated from real directory size, but `ApplicationStoreInfo` are loaded from leveldb, then `currentUsage` may be less then sum of `ApplicationStoreInfo.size`. In `makeRoom()` function, `ApplicationStoreInfo.size` is used to update usage. Then `currentUsage` becomes negative after several round of `release()` and `lease()` (`makeRoom()`). **Reproduce**: we can reproduce this issue in dev environment by reducing config value of "spark.history.retainedApplications" and "spark.history.store.maxDiskUsage" to some small values. Here are steps: 1. start history server, load some applications and access some pages (maybe "stages" page to trigger leveldb compaction). 2. restart HS, and refresh pages. I also added an UT to simulate this case in `HistoryServerDiskManagerSuite`. **Benefit**: this change would help improve history server reliability. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Add unit test and manually tested it. Closes #28859 from zhli1142015/update-ApplicationStoreInfo.size-during-disk-manager-initialize. Authored-by: Zhen Li <zhli@microsoft.com> Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com> (cherry picked from commit 8e7fc04) Signed-off-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com>
{kind=link}
…ld's nullability together ### What changes were proposed in this pull request? Backport #28992 to 2.4 Fix nullability of `GetArrayStructFields`. It should consider both the original array's `containsNull` and the inner field's nullability. ### Why are the changes needed? Fix a correctness issue. ### Does this PR introduce _any_ user-facing change? Yes. See the added test. ### How was this patch tested? a new UT and end-to-end test Closes #29019 from cloud-fan/port. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…hen statements ### What changes were proposed in this pull request? This patch fixes the test failure due to the missing when statements for destination path. Note that it didn't fail on master branch, because 245aee9 got rid of size call in destination path, but still good to not depend on 245aee9. ### Why are the changes needed? The build against branch-3.0 / branch-2.4 starts to fail after merging SPARK-32024 (#28859) and this patch will fix it. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Ran modified UT against master / branch-3.0 / branch-2.4. Closes #29046 from HeartSaVioR/QUICKFIX-SPARK-32024. Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan.opensource@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 161cf2a) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…t, & Sessions tokens ### What changes were proposed in this pull request? I resolved some of the inconsistencies of AWS env variables. They're fixed in the documentation as well as in the examples. I grep-ed through the repo to try & find any more instances but nothing popped up. ### Why are the changes needed? As previously mentioned, there is a JIRA request, SPARK-32035, which encapsulates all the issues. But, in summary, the naming of items was inconsistent. ### Does this PR introduce _any_ user-facing change? Correct names: AWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEY AWS_SESSION_TOKEN These are the same that AWS uses in their libraries. However, looking through the Spark documentation and comments, I see that these are not denoted correctly across the board: docs/cloud-integration.md 106:1. `spark-submit` reads the `AWS_ACCESS_KEY`, `AWS_SECRET_KEY` <-- both different 107:and `AWS_SESSION_TOKEN` environment variables and sets the associated authentication options docs/streaming-kinesis-integration.md 232:- Set up the environment variables `AWS_ACCESS_KEY_ID` and `AWS_SECRET_KEY` with your AWS credentials. <-- secret key different external/kinesis-asl/src/main/python/examples/streaming/kinesis_wordcount_asl.py 34: $ export AWS_ACCESS_KEY_ID=<your-access-key> 35: $ export AWS_SECRET_KEY=<your-secret-key> <-- different 48: Environment Variables - AWS_ACCESS_KEY_ID and AWS_SECRET_KEY <-- secret key different core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala 438: val keyId = System.getenv("AWS_ACCESS_KEY_ID") 439: val accessKey = System.getenv("AWS_SECRET_ACCESS_KEY") 448: val sessionToken = System.getenv("AWS_SESSION_TOKEN") external/kinesis-asl/src/main/scala/org/apache/spark/examples/streaming/KinesisWordCountASL.scala 53: * $ export AWS_ACCESS_KEY_ID=<your-access-key> 54: * $ export AWS_SECRET_KEY=<your-secret-key> <-- different 65: * Environment Variables - AWS_ACCESS_KEY_ID and AWS_SECRET_KEY <-- secret key different external/kinesis-asl/src/main/java/org/apache/spark/examples/streaming/JavaKinesisWordCountASL.java 59: * $ export AWS_ACCESS_KEY_ID=[your-access-key] 60: * $ export AWS_SECRET_KEY=<your-secret-key> <-- different 71: * Environment Variables - AWS_ACCESS_KEY_ID and AWS_SECRET_KEY <-- secret key different These were all fixed to match names listed under the "correct names" heading. ### How was this patch tested? I built the documentation using jekyll and verified that the changes were present & accurate. Closes #29058 from Moovlin/SPARK-32035. Authored-by: moovlin <richjoerger@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 9331a5c) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
… class name in ScalaUDF
This PR proposes to use `Utils.getSimpleName(function)` instead of `function.getClass.getSimpleName` to get the class name.
For some functions(see the demo below), using `function.getClass.getSimpleName` can hit "Malformed class name" error.
Yes. For the demo,
```scala
object MalformedClassObject extends Serializable {
class MalformedNonPrimitiveFunction extends (String => Int) with Serializable {
override def apply(v1: String): Int = v1.toInt / 0
}
}
OuterScopes.addOuterScope(MalformedClassObject)
val f = new MalformedClassObject.MalformedNonPrimitiveFunction()
Seq("20").toDF("col").select(udf(f).apply(Column("col"))).collect()
```
Before this PR, user can only see the error about "Malformed class name":
```scala
An exception or error caused a run to abort: Malformed class name
java.lang.InternalError: Malformed class name
at java.lang.Class.getSimpleName(Class.java:1330)
at org.apache.spark.sql.catalyst.expressions.ScalaUDF.udfErrorMessage$lzycompute(ScalaUDF.scala:1157)
at org.apache.spark.sql.catalyst.expressions.ScalaUDF.udfErrorMessage(ScalaUDF.scala:1155)
at org.apache.spark.sql.catalyst.expressions.ScalaUDF.doGenCode(ScalaUDF.scala:1077)
at org.apache.spark.sql.catalyst.expressions.Expression.$anonfun$genCode$3(Expression.scala:147)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.catalyst.expressions.Expression.genCode(Expression.scala:142)
at org.apache.spark.sql.catalyst.expressions.Alias.genCode(namedExpressions.scala:160)
at org.apache.spark.sql.execution.ProjectExec.$anonfun$doConsume$1(basicPhysicalOperators.scala:69)
...
```
After this PR, user can see the real root cause of the udf failure:
```scala
org.apache.spark.SparkException: Failed to execute user defined function(UDFSuite$MalformedClassObject$MalformedNonPrimitiveFunction: (string) => int)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:753)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:340)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:898)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:898)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:464)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:467)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.ArithmeticException: / by zero
at org.apache.spark.sql.UDFSuite$MalformedClassObject$MalformedNonPrimitiveFunction.apply(UDFSuite.scala:677)
at org.apache.spark.sql.UDFSuite$MalformedClassObject$MalformedNonPrimitiveFunction.apply(UDFSuite.scala:676)
... 17 more
```
Added a test.
Closes #29050 from Ngone51/fix-malformed-udf.
Authored-by: yi.wu <yi.wu@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit 0c9196e)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request? This PR changes `true` to `True` in the python code. ### Why are the changes needed? The previous example is a syntax error. ### Does this PR introduce _any_ user-facing change? Yes, but this is doc-only typo fix. ### How was this patch tested? Manually run the example. Closes #29073 from ChuliangXiao/patch-1. Authored-by: Chuliang Xiao <ChuliangX@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit c56c84a) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…e with no partitions
### What changes were proposed in this pull request?
This PR proposes to just simply by-pass the case when the number of array size is negative, when it collects data from Spark DataFrame with no partitions for `toPandas` with Arrow optimization enabled.
```python
spark.sparkContext.emptyRDD().toDF("col1 int").toPandas()
```
In the master and branch-3.0, this was fixed together at ecaa495 but it's legitimately not ported back.
### Why are the changes needed?
To make empty Spark DataFrame able to be a pandas DataFrame.
### Does this PR introduce _any_ user-facing change?
Yes,
```python
spark.sparkContext.emptyRDD().toDF("col1 int").toPandas()
```
**Before:**
```
...
Caused by: java.lang.NegativeArraySizeException
at org.apache.spark.sql.Dataset$$anonfun$collectAsArrowToPython$1$$anonfun$apply$17.apply(Dataset.scala:3293)
at org.apache.spark.sql.Dataset$$anonfun$collectAsArrowToPython$1$$anonfun$apply$17.apply(Dataset.scala:3287)
at org.apache.spark.sql.Dataset$$anonfun$52.apply(Dataset.scala:3370)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:80)
...
```
**After:**
```
Empty DataFrame
Columns: [col1]
Index: []
```
### How was this patch tested?
Manually tested and unittest were added.
Closes #29098 from HyukjinKwon/SPARK-32300.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
…BT download in branch 2.4 and 3.0 ### What changes were proposed in this pull request? Move SBT download URL from `https://dl.bintray.com/typesafe` to `https://scala.jfrog.io/artifactory`. ### Why are the changes needed? As [bintray is sunsetting](https://jfrog.com/blog/into-the-sunset-bintray-jcenter-gocenter-and-chartcenter/), we should migrate SBT download location away from it. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Tested manually and it is working, while previously it was failing because SBT 0.13.17 can't be found: ``` Attempting to fetch sbt Our attempt to download sbt locally to build/sbt-launch-0.13.17.jar failed. Please install sbt manually from http://www.scala-sbt.org/ ``` Closes #32352 from sunchao/SPARK-35233. Authored-by: Chao Sun <sunchao@apple.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
…ubmit This change is to use repos.spark-packages.org instead of Bintray as the repository service for spark-packages. The change is needed because Bintray will no longer be available from May 1st. This should be transparent for users who use SparkSubmit. Tested running spark-shell with --packages manually. Closes #32346 from bozhang2820/replace-bintray. Authored-by: Bo Zhang <bo.zhang@databricks.com> Signed-off-by: hyukjinkwon <gurwls223@apache.org> (cherry picked from commit f738fe0) Signed-off-by: hyukjinkwon <gurwls223@apache.org>
…mber of parameters ### What changes were proposed in this pull request? This patch fixes `Invoke` expression when the target object has more than one method with the given method name. This is 2.4 backport of #32404. ### Why are the changes needed? `Invoke` will find out the method on the target object with given method name. If there are more than one method with the name, currently it is undeterministic which method will be used. We should add the condition of parameter number when finding the method. ### Does this PR introduce _any_ user-facing change? Yes, fixed a bug when using `Invoke` on a object where more than one method with the given method name. ### How was this patch tested? Unit test. Closes #32412 from viirya/SPARK-35278-2.4. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
Closes #32414 from viirya/prepare-rc4. Authored-by: Liang-Chi Hsieh <viirya@apache.org> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
…argument classes match ### What changes were proposed in this pull request? This patch proposes to make StaticInvoke able to find method with given method name even the parameter types do not exactly match to argument classes. ### Why are the changes needed? Unlike `Invoke`, `StaticInvoke` only tries to get the method with exact argument classes. If the calling method's parameter types are not exactly matched with the argument classes, `StaticInvoke` cannot find the method. `StaticInvoke` should be able to find the method under the cases too. ### Does this PR introduce _any_ user-facing change? Yes. `StaticInvoke` can find a method even the argument classes are not exactly matched. ### How was this patch tested? Unit test. Closes #32413 from viirya/static-invoke. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit 33fbf56) Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
20 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Hi, could anyone can tell me that if Spark will have a 2.5.0 version in future?