Proportions Case Distribution
In designing the automatic case distribution, there were a number of policy objectives that the team sought to realize.
- Priority cases should be balanced among judges. No judge should request a distribution and receive all priority cases.
- Priority cases should be distributed quickly.
- Docket order should be respected. An appeal that has an earlier docket date should be distributed before one with a later docket date. A certain amount of allowance is made on the legacy docket, where some appeals are tied to judges. In this case, we'll want to maximize the docket efficiency, that is the extent to which we do not need to look too deep on the docket to find cases for a given judge.
- Nonpriority appeals on the Direct Review docket should receive a decision about 365 days after VA received the form starting the appeal.
- However, the Board should also start to work some Direct Review cases straight away, and not just wait for one year before starting to work the Direct Review docket. As a result, we want to ramp up to the 365 day timeline.
- The other dockets, legacy, Evidence Submission, and Hearing Request, should be balanced proportionately. That is the number of nonpriority cases distributed from each docket should be proportionate to the number of cases on each docket.
- Clearing the legacy backlog should be prioritized, but meeting the Direct Review timeliness goal is a higher priority.
How much of a given distribution should be priority cases? If we were to just always distribute a priority case if one was available, we would see that some judges would get far more priority cases than others, just by virtue of the timing of their request. Instead, we'll calculate an optimal number of cases for a given distribution that should be priority.
We start by counting all of the priority cases that are ready to be distributed on any docket. We then divide this number by the total batch size to get an target percentage, and then multiply by the individual judge's batch size (rounding up) to get the target number of priority cases that should be distributed.
We don't have to worry about which docket priority cases come from; all priority cases are treated the same. But for nonpriority cases, we must balance the four dockets, calculating the percentage of cases that we want to come from each docket.
Cases on the AMA Hearings Docket are grouped into several groups for determining if genpop or not genpop
- Not Genpop
- Tied to a judge
- If the case has a hearing held by a judge and the DistributionTask's
assigned_atdate is sooner thanhearing_case_affinity_daysdays ago
- If the case has a hearing held by a judge and the DistributionTask's
- Tied to a judge
- Genpop
- With no hearings
- With no held hearings
- With a held hearing not tied to a judge
- Tied to a judge but exceeding affinity threshold
- If the case has a hearing held by a judge and the DistributionTask's
assigned_atdate is later thanhearing_case_affinity_daysdays ago
- If the case has a hearing held by a judge and the DistributionTask's
Unlike the other dockets, cases on the Direct Review docket are distributed based on the Board's 365 day timeliness goal. We do this by giving each Direct Review case a target_decision_date at intake of 365 days after the receipt_date (this allows the Board the option of increasing the goal, while respecting the promises made to Veterans who are already in the door). We then get the minimum of 2 values to get the direct review proportion.
However, this proportion would remain at zero for nearly a year, waiting for cases to become due, and this is contrary to the Board's goal of beginning to work these cases immediately. So we will also calculate an interpolated minimum direct review proportion. We use the rate at which Direct Reviews are arriving to calculate a pacesetting proportion, or the proportion of nonpriority decision capacity that would need to go to the Direct Review docket in order to keep pace with what's arriving. We will then interpolate between 0 and the pacesetting proportion based on the age of the oldest Direct Review in the system. Finally, to accelerate the curve out, we multiply this interpolated figure by the interpolated direct review proportion adjustment. This gives us a curve out of the direct review proportion that would look something like the following:

The "jolt" in this chart shows when the calculation switched from using the interpolated minimum to using the standard due proportion.
- As of Sept. 2022, The interpolated minimum calculations are not used.
The direct review proportion is also subject to a maximum percentage value. It currently cannot exceed 80%. This percentage is the minimum of the maximum_direct_review_proportion lever and the due_direct_review_proportion. This prevents a complete halt to work on other dockets should demand for direct reviews approach the Board's capacity.
The other dockets are balanced proportionate to the number of cases on the docket. After the direct review proportion is deducted, the remaining proportions are divided among the other dockets according to their weight, the number of cases waiting.
The legacy docket has two exceptions to this rule.
- First, in addition to counting the cases on the docket, we also count the number of cases where the Agency of Original Jurisdiction has received a Notice of Disagreement but where the appeal has not yet reached the Form 9 stage. We count these cases at a 40% discount, reflecting the likelihood that they will come to the Board and providing a fuller picture of what is waiting.
- Second, the legacy docket is subject to a 90% minimum. This ensures that even as the legacy docket is winnowed, VA does not let up off the gas of finishing these older cases. Note that the sum of this minimum and the direct review maximum should not exceed 100%.
- Ensure that the FeatureToggle
:acd_distribute_allis disabled as that will overwrite the Proportions based distribution algorithm with "By Docket Date Distribution".
When a judge requests the distribution, we distribute cases according to the following steps:
- We distribute legacy cases that are tied to a judge. As many as available, up to the limit of the batch size. If priority_acd is enabled.
- We distribute priority AMA hearing cases that are tied to a judge. Again, as many as available.
- We distribute nonpriority legacy cases that are tied to a judge. We'll distribute as many as available, but they must be within the legacy docket range.
- We distribute nonpriority AMA hearing cases that are tied to a judge. As many as available.
- At this point, we may have distributed some priority appeals. We'll deduct those appeals from the priority target to get the number of additional priority appeals that we should distribute. We ask each docket for its priority appeals that have been waiting the longest, and distribute the oldest ones up to the priority remaining number, irrespective of docket.
- We have also potentially distributed some nonpriority appeals from the legacy and AMA hearing dockets. We'll deduct these cases from the docket proportions.
- Now we're ready to distribute the remaining nonpriority cases from each of the dockets according to the updated docket proportions. As some of these proportions may be small, we do this by means of stochastic allocation.
- If when we try to distribute cases from a given docket, we find that it has no cases that are ready to distribute, we'll reallocate those cases among the other dockets according to the docket proportions and try again until we've found a number of cases equal to the batch size.
In an effort to get priority cases to judges without waiting for them to request cases, every Monday morning, aPushPriorityAppealsToJudgesJob is run to push ready priority cases to judges that can receive them. Judges can receive this push if they have an active judge team in caseflow and they hav not been removed from the job. DVCs are in charge of keeping this list of judges up to date and can add and remove judges from this job from the Team Management page.
To ensure some judges are not distributed more than others, we first distribute all priority cases that are tied to a judge (non-genpop) to that respective judge. We then look at the number of cases all eligible judges have received in the last month (including the ones just distributed), calculate a target number for each judge that would get us as close to even as possible, and distribute the remaining ready priority genpop appeals based on that calculation. The board is in charge of manually handling any cases that cannot be distributed due to the associated judge being unable to receive cases (they have left the board, they are no longer a judge, they are on vacation, etc).
- Distribute Legacy Docket Cases tied to a judge
- Distribute AMA Hearing Docket Cases that are not genpop
- Distribute AOD or CAVC Remand cases that are genpop to a judge until the push priority target is hit for the judge.
- Sorting of these cases is by the
assigned_atdate of their DistributionTask for AMA andbfdlooutfor Legacy - push priority target = look at the number of cases all eligible judges have received in the last month (including the ones just distributed), calculate a target number for each judge that would get us as close to even as possible
- Sorting of these cases is by the
Starting with sprint PI9.S4, Team Echo began to consolidate the "levers" that control distribution in one json file. Previously, the levers were defined as constants throughout the codebase.
- As of Q1 2024 (03/01/2024), these levers and more can now be found within the Case Distribution Admin UI, a new a centralized location to be able to view values and descriptions of the levers used in the case-distribution algorithm. In addition to this, Administrative users of the Case Distro Algorithm Control team are able to replace existing values for the case-distribution variables.
The list below contains consolidated levers in use. The values that you see are example values only. (current as of 9/13/2022.)
| Lever | Description | Value |
|---|---|---|
alternative_batch_size |
If the judge does not have their own team, for example if they are a DVC, they receive a set number of cases known as an alternative batch size | 15 |
batch_size_per_attorney |
When a judge requests a distribution of cases, they will receive a certain number of cases (batch size) in their queue. It is a multiple of the number of attorneys on the judge's team (3 x the number of attorneys) | 3 |
cavc_affinity_days |
How many days a case should stick with the judge who authored a decision which came back from CAVC (see CASEFLOW-1936) | 21 |
days_before_goal_due_for_distribution |
Used to determine when a Direct Review Docket case is ready for distribution, when ignored cases are ready for distribution immediately | ignored |
direct_docket_time_goal |
Direct review timeliness goal | 365 |
hearing_case_affinity_days |
How long an AMA Hearing Case is tied to the judge that held the hearing | 0 |
maximum_direct_review_proportion |
0.07 | |
minimum_legacy_proportion |
0.9 | |
nod_adjustment |
When counting the total number of appeals on the legacy docket for purposes of docket balancing, we include NOD-stage appeals at a discount reflecting the likelihood that they will advance to a Form 9. | 0.4 |
request_more_cases_minimum |
When requesting more cases VLJs must have less than or equal to this value of cases remaining | 8 |
- The sum of
minimum_legacy_proportionandmaximum_direct_review_proportioncannot exceed 1. - A note about
nod_adjustment: When counting the total number of appeals on the legacy docket for purposes of docket balancing, we include NOD-stage appeals at a discount reflecting the likelihood that they will advance to a Form 9. - Direct review distribution due date is calculated as (
direct_docket_time_goal-days_before_goal_due_for_distribution).
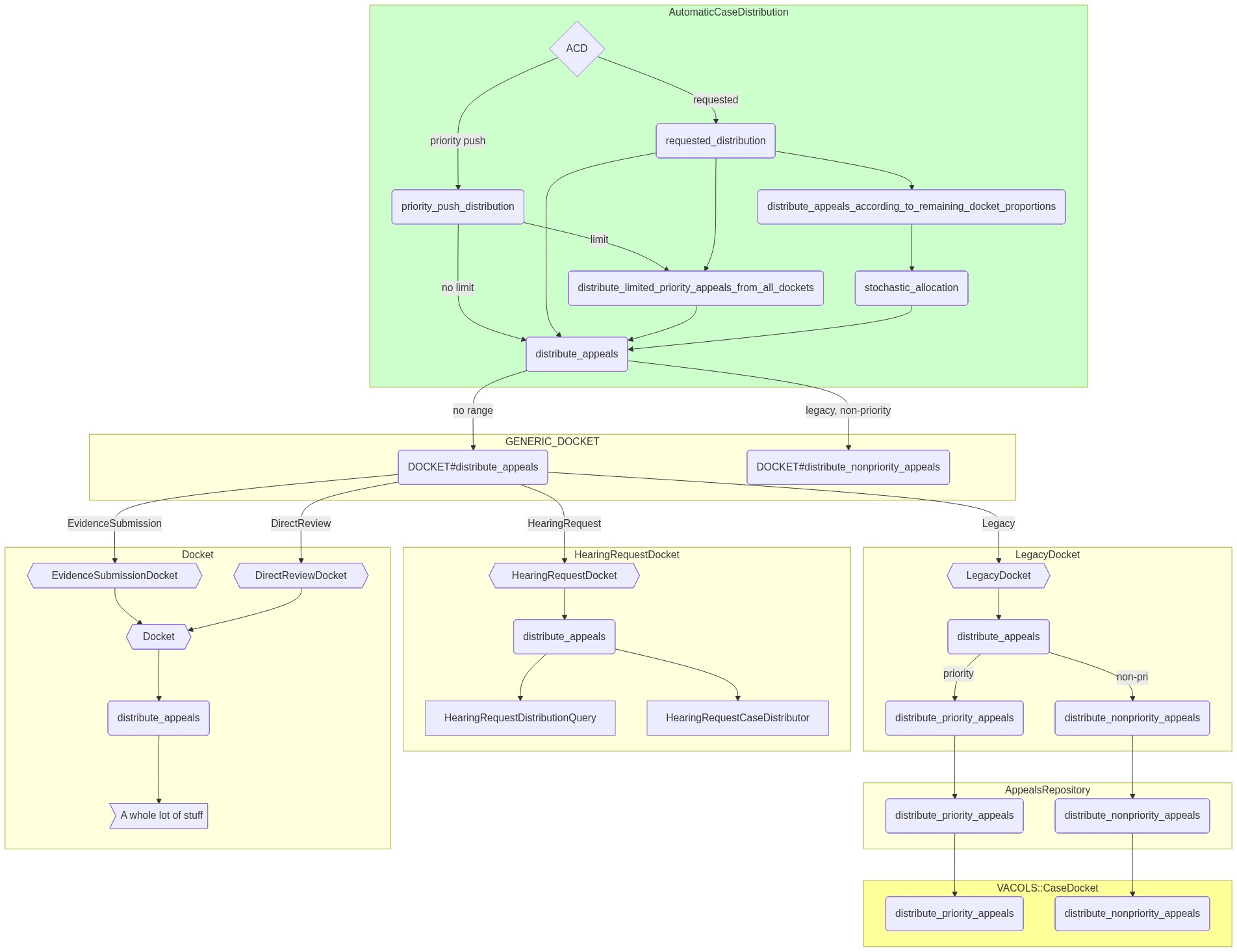
This is a slightly incomplete diagram of the path code takes. Understanding that there are four different dockets, all of which implement a distribute_appeals method, will help. The logic of distribution varies with Docket, but all present a similar interface. Also note that AutomaticCaseDistribution is never instantiated directly, but is instead included into a few classes.
 (
(Some of the requirements were documented by the original design team in this Github issue