Recipes
- 1. Numbers
- 2. String Manipulation
- 3. Dates and Time
- 4. JSON
- 5. Fetch URLs and Web scraping
- 6. Duplicate patterns
- 7. Columns
- 8. Error Handling
- 9. Encoding Issues
- 10. Records and Rows
- 11. Clojure
- 12. Templating exporter
- 13. Reconciliation
- 14. Wikibase
Table of contents generated with markdown-toc
This page collects OpenRefine recipes, small workflows and code fragments that show you how to achieve specific things with OpenRefine.
Jython#working-with-phone-numbers-using-java-libraries-inside-python
For a string holding longitude/latitude information in the format XX degrees, XX minutes, XX.XX seconds the following can be used.
forNonBlank(value[0,2], v, v.toNumber(), 0) +
forNonBlank(value[2,4], v, v.toNumber()/60.0, 0) +
forNonBlank(value[4,6], v, v.toNumber()/3600.0, 0) +
forNonBlank(value[6,8], v, v.toNumber()/360000.0, 0)
Compute ISBN-10 check
digit:grel:sum(forRange(1,10,1,i,toNumber(value[i])**i))%11
Check computed value against check digit:
grel:if(value==10,'X',toString(round(value)))==cells['ISBN10'].value[10]
Convert ISBN-10 check digit to number ('X' == 10)
grel:if(toLowercase(value[10])=='x',10,toNumber(value[10]))
Take the first 9 digits and prepend 978: grel:'978'+value[0,9]
Compute the ISBN-13 check digit:
grel:((10-(sum(forRange(0,12,1,i,toNumber(value[i])*(1+(i%2*2)) )) %10)) %10).toString()[0]
Append the check digit to the 12-digit base: grel: value + ((10-(sum(forRange(0,12,1,i,toNumber(value[i])*(1+(i%2*2)) )) %10)) %10).toString()[0]
Or, do it all in one expression:
with('978'+value[0,9],v,v+((10-(sum(forRange(0,12,1,i,toNumber(v[i])*(1+(i%2*2)) )) %10)) %10).toString()[0] )
Here are some examples of possible types of common string manipulation operations that you might encounter and how they can be achieved with the GREL-Functions. See also GREL String Functions.
So if the cell was:
Doe, J; Smith, JD; Andersen SL
And you want your new cell to be:
Doe, J
You can use the GREL function 'split'. Because you want this in a new column, you need to use the 'Column->Add column based on this column' menu option. And use the GREL:
value.split(";")[0]
The first part (value.split(";")) will split the value into an array (list) using a semicolon as the character to split it up. The [0] directs OpenRefine to take the first item from the list created by the 'split' command. (and you can guess, using [1] instead would take the second value, [2] the third, etc.)
One way to do this is to use GREL's slice function.
value.slice(5, 7) + '/' + value.slice(8, 10) + '/' + value.slice(0, 4)
Another way to do this is to convert this to a Date data type, then convert back to a string with the specified format:
toString(toDate(value),"dd/MM/yyyy")
value.trim()
or if you have non-breaking spaces   on both ends then you might
try this instead:
split(escape(value,'xml')," ")[0]
If you don't know what kind of whitespace character is present, and they are not removed using 'trim' you can create a new column using:
value.escape("javascript")
This should reveal the types of whitespace that are in the original column, and allow you to target them for removal.
If you have a "name" column with values like "FOTHERINGTON-THOMAS", this will convert correctly to "Fotherington-Thomas" (more detailed explanation here
replace(toTitlecase(replace(value,"-",".")),".","-")
Replace will take a regular expression, e.g.
value.replace(/[%@#!]/,' ')
You can also use character classes to replace all punctuation characters with spaces
value.replace(/\p{Punct}/,' ')
If you ever do have to do multiple replaces, you can chain them together e.g.
value.replace('w','x').replace('y','z')
You can use
value.replace("someprefix_","")
basically replacing what you don't want with the empty string.
Note that "replace" replaces all instances of that first string in the cell value so see the next recipe for that case.
Here we can't replace "blah" with "" because it would change the second occurrence as well. So we can use this
value.partition("blah_")[2]
that will chop the value in an array of three strings
["","blah_","2342_blah_1232"]
and we get the 3rd value (remember that the arrays in OpenRefine, like
in most programming languages start from 0, so [2] is actually the
third value).
Sometimes the strings are more complicated and the only thing they have in common is a character separator. In that case, it's handy to use "split" and "join" together like this:
value.split(":")[1,3].join(":")
which "splits" the string around the ":" separating character in an array of 5 strings
["a","b","c","d","e"]
then you select only the range between the 2nd and 4th and you get
["b","c","d"]
then you join them together with the same separator character ":" and you get what you wanted "b:c:d".
Do not choose a string as a separator that might be present somewhere in your data. Consider using these uncommon UTF-8 strings via copy & paste:
- Unit Separator: ␟ (U+241F)
- Record Separator: ␞ (U+241E)
If you need to fill out a number with for example leading zeroes up to four characters try,
"0000"[0,4-value.length()] + value
This provides a string of zeroes from which we ask for the first 4-length(value) characters using the string slicing action of [start, offset].
To find Proper Names using the full Latin Character set you can use a
find() with some regex.
(the join() at the end is needed to pluck out the strings since
find() outputs an array)
value.find(/([A-Z]([a-z]|[\u00C0-\u00FF])+)\s([A-Z]([a-z]|[\u00C0-\u00FF])+)/).join(" | ")

value.replace(/(\p{IsAlphabetic})(?=\d)/,'$1 ')
- (\p{IsAlphabetic}) is any Unicode alphabetic character, wrapping it in parens makes it a "matching group"
- (?=\d) is a "lookahead". it basically means "followed by any digit"
- $1 means "first matching group", or the letter that was matched by the first bullet above. Adapted from this StackOverflow%20answer
Sometimes you have a need beyond just endsWith to find a varying
substring and want to know if that variable pattern is found at the end
of a string. You can add a Custom Text Facet and find this variable
pattern with regex delimited by / characters such as /.*(PR\d+)/
value.endsWith(get(value.match(/.*(PR\d+)/),0))
Here you have to wrap with get() in order to ask if it endsWith the
string version of the returned array from match. endsWith then
returns a boolean of True or False if the string ends with your regex
pattern, in this case, cells that end with reference numbers that begin
with PR followed by any number of decimal digits.
An alternative form would be using Regex syntax to find the ending
pattern with $ , something like this, where if match() finds the Regex
subpattern it outputs the array, otherwise it outputs null, and we
then ask if the expression isNull() to get a boolean of true/false.
isNull("sometextPR12".match(/^.*(PR\d+)$/))
This uses smartSplit to find the last word [-1] and then wraps
partition to keep only the first phrase or part of the string
remaining with [0].
value.partition(smartSplit(value," ")[-1])[0]
Sometimes your content has no char separator because the separation is performed by alignment (in the case of non-delimited files) and padded to certain sizes. In that case, you can use
value.splitByLengths(6,4,2,5)
where those numbers are the length of the fields respectively.
Running this expression
forEach(value.split(" "), v, v + v.length()).join(";")
on the text
abc defg hi
yields
abc3;defg4;hi2
A similar trick can be used to compute, say, word length average
with(value.split(" "), a, sum(forEach(a, v, v.length())) / a.length())
Sometimes you get content that was extracted from web pages or XML documents and contain entities. These are very hard to deal with manually, mostly because there are tons of potential string values between "&" and ";". OpenRefine provides you a convenient command to do this in GREL
value.unescape("html")
Note the few entities are not part of HTML and are part of XML, so if you want to be safe, you can do
value.unescape("html").unescape("xml")
which will take care of them both.
Note that sometimes a string can get escaped several times: "AT&T" (yes, trust us, we've seen that in presumably good data sets). When you do a transform on such cells, make sure you check the "Re-transform until no change" checkbox. This causes the expression to get run on each cell's content until the output is the same as the input (or up to 10 times).
Example: you want to remove from a text all stopwords contained in a file on your desktop. In this case, use Jython.
with open(r"C:\Users\YOURUSERNAME\Desktop\stopwords.txt",'r') as f :
stopwords = [name.rstrip().lower() for name in f]
return " ".join([x for x in value.split(' ') if x.lower() not in stopwords])
Obviously, you can use the same method to extract words from cells only if they match those contained in a file. Here is another example with a list of words contained in the first column of a CSV.
import csv
import re
#remove punctuation from the value string
value = re.sub(ur'[^\w\d\s]+', '', value)
with open(r"C:\Users\Ettore\Desktop\countriesoftheworld.csv",'r') as f:
reader = csv.reader(f)
words_to_match = [col[0].strip().lower() for col in reader]
return ",".join([x for x in value.split(' ') if x.lower().strip() in words_to_match])You have a cell with joined image URL entries that you have downloaded
and named by a identifier + -Image-N.
"https://url/2a4d7bd5c8e04c.png",
"https://url/bbcfb4168a3.png", "https://url/03b9239f6c514ec.png",
"https://url/c02ae6689f1d4b14.png", "https://url/67438c.png"
You like to rename the list to "identifier-Image-N", "..", ".." so you
get this result
"identifier-Image-0.png","identifier-Image-1.png","identifier-Image-2.png","identifier-Image-3.png","identifier-Image-4.png"
You can do this with this expression:
join(forEachIndex(split(value,","),i,v,"\\"" +
cells\['Identifier'\].value + "-Image-" + i + "." +
split(v,".")\[length(split(v,"."))-1\]), ",")
GREL has many Date Functions that can work together.
For details see: GREL Date Functions
1. The diff function can be used for comparing dates:
diff(cells['end_date'].value, cells['begin_date'].value, "days")
Negative values should be errors.
2. You can also use this GREL form using a math operator "-" and
datePart():
cells['end_date'].value.datePart("time") - cells['begin_date'].value.datePart("time")
datePart ("time") expresses each date in milliseconds since January 1, 1970 (Unix Epoch).
For a string holding an Epoch time/Unix time (number of seconds that have elapsed since January 1, 1970 midnight UTC/GMT) convert into an ISO8601 string. This can be done using a Jython transformation:
import time; epochlong = int(float(value));
datetimestamp = time.strftime('%Y-%m-%dT%H:%M:%SZ',
time.localtime(epochlong)); return datetimestamp This creates a String. You can subsequently transform this string with
value.toDate() To convert it to an OpenRefine Date
value.toDate().datePart("time")
Date string value:
"2017-08-17 04:36:00"
Output:
1502944560
To convert duration's to minutes:
toNumber(value.substring(0,2))*60 + (toNumber(value.toDate().datePart('min')) + round((toNumber(value.toDate().datePart('s')))*0.01666666667)) + ' minutes'
Time string value:
"00:40:54.288"
Output:
41 minutes
forEach(value.parseJson().result,v,[v.score,v.name,v.mid])
then getting your 1st custom result:
forEach(value.parseJson().result,v,[v.score,v.name,v.mid])[0]
to get all instances from a JSON array called "keywords" having the same object string name of "text", combine with the forEach() function to iterate over the array:
forEach(value.parseJson().keywords,v,v.text).join(":::")
If you want to filter or apply some condition upon each element in a
JSON array, then you can use add if() with and() as necessary.
Example Data:
[{"place_id":"1369428","display_name":"Bīkāner, Bikaner, Rajasthan,
India","class":"place","type":"county"},
{"place_id":"187667935","display_name":"Bikaner, Rajasthan,
India","class":"boundary","type":"administrative"},
{"place_id":"15181811","display_name":"Bikaner, Bīkāner, Bikaner,
Rajasthan, 334001, India","class":"place","type":"city"}]What if you want to keep only the Json containing "class":"boundary" and "type":"administrative"?
The Grel formula is a bit complicated.
forEach(value.parseJson(),v,if(and(v.class=='boundary',v.type=="administrative"),v,null)).join("|")
And here is an equivalent in Python/Jython, a bit more readable:
import json
data = json.loads(value)
my_list = [] for el in data: if el['class'] == "boundary" and
el['type'] == 'administrative': my_list.append(el)
return "|".join(str(v) for v in my_list))Create a new column by fetching URLs based on a column with IP Addresses using an expression like:
"http://freegeoip.net/json/\"+value
There are many such services such as that one. Then parse the resulting json to create new columns with expressions such as:
value.parseJson().country_name
value.parseJson().latitude
value.parseJson().longitude
This clever hack from @atomotic shows how to use Python to get the location header field from a redirect response (in this case from the DOI API).
import httplib
conn = httplib.HTTPConnection("dx.doi.org")
doi = "/"+value
conn.request("HEAD", doi)
res = conn.getresponse()
return res.getheader('location')or in a single line version that you could paste into your Undo history
jython:import httplib\nconn = httplib.HTTPConnection(\"dx.doi.org\")\ndoi = \"/\"+value\nconn.request(\"HEAD\", doi)\nres = conn.getresponse()\nreturn res.getheader('location')"
Jython:
import httplib
import urlparse
url = urlparse.urlparse(value)
conn = httplib.HTTPConnection(url[1])
conn.request("HEAD", url[2])
res = conn.getresponse()
return res.statusClojure:
(.getResponseCode (.openConnection (java.net.URL. value)))Suppose you have XML or ATOM feed data in your cells that you may have gathered with the Add Column by Fetching URLs feature in Refine or some other source and you need to parse and strip certain tag elements such as:
<entry>
<title>San Francisco chronicle.</title>
<link href="http://chroniclingamerica.loc.gov/lccn/sn82003402/" />
<id>info:lccn/sn82003402</id>
<author><name>Library of Congress</name></author>
<updated>2010-09-03T00:01:07-04:00</updated>
</entry>
<entry>
<title>The San Francisco call.</title>
<link href="http://chroniclingamerica.loc.gov/lccn/sn85066387/" />
<id>info:lccn/sn85066387</id>
<author><name>Library of Congress</name></author>
<updated>2010-09-03T00:18:25-04:00</updated>
</entry>You can strip out the elements that you're interested in from any XML or ATOM feed and create an array of those elements values for further processing. In the above example, I only want the lccn id and title for all the entry records. This is useful when working with the http://chroniclingamerica.loc.gov API or any XML or ATOM feed.
forEach(value.split("<entry>"), v, v.partition("<id>info:lccn/")[2].partition("</id>")[0]+
","+v.partition("<title>")[2].partition("</title>")[0])
The above basically says that for each entry record (which creates an array), I want only the string partition between my id tags and title tags. The resulting output then looks something like:
[",Chronicling America Title Search Results",
"sn82003402,San Francisco chronicle.",
"sn85066387,The San Francisco call.",
"sn86091369,San Francisco Sunday examiner & chronicle.",
"sn82006825,The San Francisco examiner."]In Release 2.1+ there is now a Facet -> Customized Facets -> Duplicates Facet that can be applied on more than one column as needed. This easily applies for you a facetCount(value, 'value', 'Column') > 1 which shows ALL rows having more than 1 duplicate value in the column.
However, to ONLY remove subsequent instances of duplicates (any string), use this method:
- Sort (on the column that has duplicates or potentially)
- Reorder rows permanently (this option is in blue color SORT link in header)
- Edit cells -> Blank down
- Facet -> Customized Facets -> Facet by blank (click True)
- All -> Edit rows -> Remove all matching rows
The canonical recipe for stuff like this is to Move Column of interest to the beginning, Sort, Reorder Rows Permanently, Blank Down, <do stuff>, Fill Down. This effectively converts your rows to OpenRefine pseudo-"records" so that you can do further record based operations. GREL supports special record based commands.
A way to identify cells that contain duplicate words (i.e. the same word appearing more than once in the cell value) is to create a Custom Text Facet using the following GREL expression:
with(filter(value.split(/[^\p{L}\p{N}]/),a,a.length()>0),v,v.length()>v.uniques().length())
This will give an outcome of true if the same word appears more than once in the string, and false otherwise. This is calculated based on splitting the string into an array words using a regular expression that looks for any characters that aren’t in either the unicode Letter category \p{L} or the Unicode Number category \p{N}, filtering out any zero length words and then comparing the length of the array of words to the length of the array of unique words from the list).
The regular expression part of this GREL could be tweaked based on what should be counted as a 'word'
A way to identify cells that contain the same word repeated consecutively (i.e. the same word appears two or more times in a row within the cell value) is to create a Custom Text Facet using the following GREL expression:
filter(value.replace(/[^\p{L}\p{N}]/," ").ngram(2),n,n.split(" ").uniques().length()!=2).length()>0
This will give an outcome of true if there are consecutively repeated words anywhere in the string, and false otherwise.
The expression works by first replaces any non word characters with spaces using a regular expression that looks for any characters that aren’t in either the unicode Letter category \p{L} or the Unicode Number category \p{N}, and then splits the resulting string into pairs of words (word ngrams of length 2) and looks for any ngrams that do not contain two words if you split the ngram into a list of its constituent words and deduplicate the list. If the number of the ngrams that don't contain two words on de-duplication is more than zero there is at least one instance of a repeated consecutive word in the string.
The regular expression part of this GREL could be tweaked based on what should be counted as a 'word'
With strings that have duplicate words in them such as "Beef, Ground Beef", you may wish to see a count of the duplicates in each column's row. Using value.ngram(1) only separates the words but doesn't give a count. So, first, standardize spacing in the cell value or find good alternate separation chars to use on your particular pattern if needed, and perhaps clean up spaces with GREL transform of
value.replace(/\s+/,' ')
then using Jython, you can create a Custom Facet using something such as:
from sets import Set
# function to show count of Duplicates in a List returning an array
def countDuplicatesInList(dupedList):
uniqueSet = Set(item for item in dupedList)
return [(item, dupedList.count(item)) for item in uniqueSet]
v = countDuplicatesInList(value.split(" "))
for x in v[:]: # makes a slice copy of the entire list
if x[1]>1: # compares if the 2nd value in each mini list (x) is greater than 1, such as ["Beef", 2]
return xIn OpenRefine 3.2 and later these facets are available in the menu ("All" > "Facet"). For OpenRefine 3.1 and earlier use Facet > Custom text facet (from any column in the project)
rows:
filter(row.columnNames,cn,isNonBlank(cells[cn].value))
records:
filter(row.columnNames,cn,isNonBlank(if(row.record.fromRowIndex==row.index,row.record.cells[cn].value.join(""),null)))
filter(row.columnNames,cn,isBlank(cells[cn].value))
Starring or Flagging rows is a handy way of accumulating insights based on many different facets of messy data. Create a new column based on the Star, use:
if(row.starred, "yes", "no")
NOTE: There is also a VIB-BITS OpenRefine extension that automates
some of the GREL cross() functionality for ease of use with its "Add
column(s) from other projects..." function.
NOTE: If you don't get matches when using cross(), then you might need to first do a few things, such as
- trim() your key column before doing cross()
- Deduplicate values in your key column if necessary
OK, with that out the way, let's show you an example of how to use the cross() function. Consider 2 projects with the following data:
My Address Book
| friend | address |
|---|---|
| john | 120 Main St. |
| mary | 50 Broadway Ave. |
| anne | 17 Morning Crescent |
Christmas Gifts
| gift | recipient |
|---|---|
| lamp | mary |
| clock | john |
Now in the project "Christmas Gifts", we want to add a column containing
the addresses of the recipients, which are in the project "My Address
Book". So we can invoke the command Add column based on this column on
the "recipient" column in "Christmas Gifts" and enter this expression:
cell.cross("My Address Book", "friend")[0].cells["address"].value
When that command is applied, the result is
Christmas Gifts
| gift | recipient | address |
|---|---|---|
| lamp | mary | 50 Broadway Ave. |
| clock | john | 120 Main St. |
In case the cross() function finds multiple matching rows, you can combine cross() with the forEach() function to iterate over the array and the forNonBlank() function to prevent errors caused by null values present in the looked up column, e.g.
forEach(cell.cross("My Address Book", "friend"),r,forNonBlank(r.cells["address"].value,v,v,"")).join("|")
- To perform a cross or lookup between 2 columns (B and C) in the same
project, you can create a new column "match" based on the expression
using
forEach(), retrieve the value in A when they match, and thenjoin()the produced arrays, as in this example:
Original:
A B C
098 11079851 11079851
110 11089385 25853201
118 11089385 22412115
798 11079851 22412115
GREL (from column B using "add column based on this column"):
forEach(cross(cell,"my_project","C"),v,v.cells["A"].value).join(',')
Result:
A B match C
098 11079851 098 11079851
110 11089385 25853201
118 11089385 22412115
798 11079851 098 22412115
Also note that felixlohmeier has written a nice enhanced cross function that can do a cross with repeating values in the same cell (i.e. comma delimiter list). https://gist.github.com/felixlohmeier/a5a893190e4aa8e26091664908d04e20
Note: As of OpenRefine 3.5 you can indicate the current project with an empty string. Thus cell.cross("", "C") is the same as cell.cross("my_project","C") when the project's name is "my_project". This is not only less typing but makes it easier to reuse such GREL expressions across projects.
Self-crossing can also be useful for finding data in a previous row. (See note below. There is a much more succinct way to do this. This description is left in for explanatory purposes.)
With the same Original table above, you can add a column named idx with
the GREL expression row.index and a second named idx-1 based on this
with the expression row.index - 1, which will produce a table like this:
A B C idx idx-1
098 11079851 11079851 0 -1
110 11089385 25853201 1 0
118 11089385 22412115 2 1
798 11079851 22412115 3 2
Now you can say subtract the previous row's C column from the current
row's C column by crossing the idx-1 row with the idx row as
follows:
with(cross(cell,"","idx"), prevRow, cells.C.value - prevRow.cells.C.value)
To produce the following:
A B C idx idx-1 diff
098 11079851 11079851 0 -1 null
110 11089385 25853201 1 0 14773350
118 11089385 22412115 2 1 -3441086
798 11079851 22412115 3 2 0
Note: that this uses indices in the full unfaceted project. So that even if you have filtered view, it will find the previous row from the unfaceted project.
Note: As of OpenRefine 3.5, there is a more succinct way to do a self-cross to find the previous row. Instead of having to explicitly extract the row into a column to cross against it, you can simply do cross(rowIndex - 1). Here we're not using the cross to match against values of the current cell but rather selecting the "target row" indicated by the calculated index rowIndex - 1. I.e. the row whose index is one less than the current row.
You'd need to use the 'cells' variable:
cells["col1"].value + ", " + cells["col2"].value
In OpenRefine 3.0 and later this will work even where some cells contain
a null value. For OpenRefine 2.8 and earlier, this will fail for any
rows which contain any cell with a null value. To fix, create a facet
of blank cells with "Text Facet" ⇒ "Customized Facets" ⇒ "Facet by
Blank". Then use "Edit Cells" ⇒ "Transform ..." and enter a string with
a space: ' '.
To merge all values across a row, you can use 'row.columnNames' (which retrieves all the column names in the project) with the 'cells' variable:
forEach(row.columnNames,cn,cells[cn].value).join("|")
In OpenRefine 2.8 and before if there are 'null' cells in the row, the
row will still merge, but where the cells were null you will get the
phrase "Cannot retrieve field from null|". In OpenRefine 3.0 and later
any null cells will return null which will translate to an empty
string when the join() command is used.
If there are empty strings ("") in any cell in the row, these will be
merged as empty strings - in OpenRefine 3.0 and later this means that
cells containing null and cells containing empty strings will both
result in empty strings when merging columns using this technique.
Obviously, you can use filter(), [] or slice() to select which
column to merge. Example : merge all columns except the column ID :
forEach(filter(row.columnNames, v, v!="ID"),cn,cells[cn].value).join("|")
Or : merge all columns except the first one :
forEach(row.columnNames.slice(1),cn,cells[cn].value).join("|")
Another example using .match() (Thanks to Stephens Owen for the
"lenght()>0" trick)
forEach(filter(row.columnNames, v, v.match(/(colname1|colname2|colname3|colname4|colname5)/).length()>0),cn,cells[cn].value).join("|")
Sometimes the cells in a column are not uniform, but your expression has to be flexible enough to handle them all. One case of nonuniformity is that the strings in the cells are not all of the same lengths, e.g., 3 cells in a column might contain
200810
20090312
2010
This means that this formula
value[0,4] + "-" + value[4,6] + "-" + value[6,8]
only works on the second cell. To catch the other cases, use the forNonBlank control:
value[0,4] + forNonBlank(value[4,6], v, "-" + v, "") + forNonBlank(value[6,8], v, "-" + v, "")
This new expression transforms those cells to
2008-10
2009-03-12
2010
What forNonBlank does is test its first argument and decides what to do based on whether that is blank (null or empty string) or not. If it's not blank, bind that value to the variable name in the second argument (v) and evaluates the third argument ("-" + v). Otherwise, it evaluates the fourth argument ("").
While OpenRefine offers a convenient way to fix encoding issues with the "reinterpret" GREL command, it also helps you find where these problems could be since they can be hidden if most of the content has been properly decoded.
To do this, there is a special numeric facet called "Unicode charcode Facet" that generates a distribution of which Unicode characters are used in a particular column. That distribution will allow you to spot outliers, meaning characters that are used infrequently and that might suggest encoding issues. You can use that char distribution facet to 'scan' and inspect the values for yourself and then fix their encoding with the 'reinterpret' GREL function.
Boris Villazón -> Boris Villazon
See Jython use case Extending-Jython-with-pypi-modules
Sometimes content is aggregated from various sources and somewhere improperly decoded. This results in strings that contain 'garbled' content in the form of weird spurious characters. Fixing that is normally a very tedious and time-consuming process, but OpenRefine contains a handy GREL command specifically for that
value.reinterpret("utf-8")
that does exactly that.
As a tip, if you see two weird characters where you think there should be one, try reinterpreting with "utf-8" which normally solves it. Other encoding values that are useful to try are "latin-1" (for European content), "Big5" (for Chinese content"), etc. You can get a list of all the supported encodings here. Re-encoding can also be done outside of OpenRefine with text tools such as PSPad, Notepad++, etc.
Another useful numeric facet is the "Text Length Facet" which builds a distribution of lengths of the strings contained in a particular column. Here too spotting outliers, meaning strings that are too big or too small, might be an indication of a problem.
This is the "Replacement Character - used to replace an incoming
character whose value is unknown or unrepresentable." These will show if
there are encoding issues with your data. Because the data is actually
changed at import time, this may not be recoverable without
re-importing, but you can try reinterpreting as above. Also there may be
non-breaking spaces   Unicode(160). You can inspect with
unicode(value) and replace with regular spaces Unicode(32).
You can also try this quick fix to remove non-breaking spaces on both ends of your string:
split(escape(value,'xml')," ")[0]
NOTE To access and use the Non-breaking space character itself such
as   or \u00A0 or [160] in GREL expressions on Windows systems
type on the numeric keypad: ALT 2 5 5 ,which will still display as a
regular space in the expression window, but will actually be a
non-breaking space character. Example: value.replaceChars(" ", " ")
If you want to find rows that have a certain number of blank cells, including 'all blank' or 'no blanks' you can create a custom facet:
Facet->Custom text facet (from any column in the project)
use the GREL:
filter(row.columnNames,cn,isBlank(cells[cn].value)).length().toString()
This will give a facet with the number of blank (null or empty strings) cells in each row. If you want to limit by a particular number you can enhance the GREL with a check for a specific length:
Rows with more than one blank cell (true/false facet)
(filter(row.columnNames,cn,isBlank(cells[cn].value)).length()>1).toString()
Rows with exactly one blank cell (true/false facet)
(filter(row.columnNames,cn,isBlank(cells[cn].value)).length()==1).toString()
Rows with less than two blank cells (true/false facet)
(filter(row.columnNames,cn,isBlank(cells[cn].value)).length()<2).toString()
Rows with blank cells in all columns (true/false facet)
(filter(row.columnNames,cn,isNonBlank(cells[cn].value)).length()==0).toString()
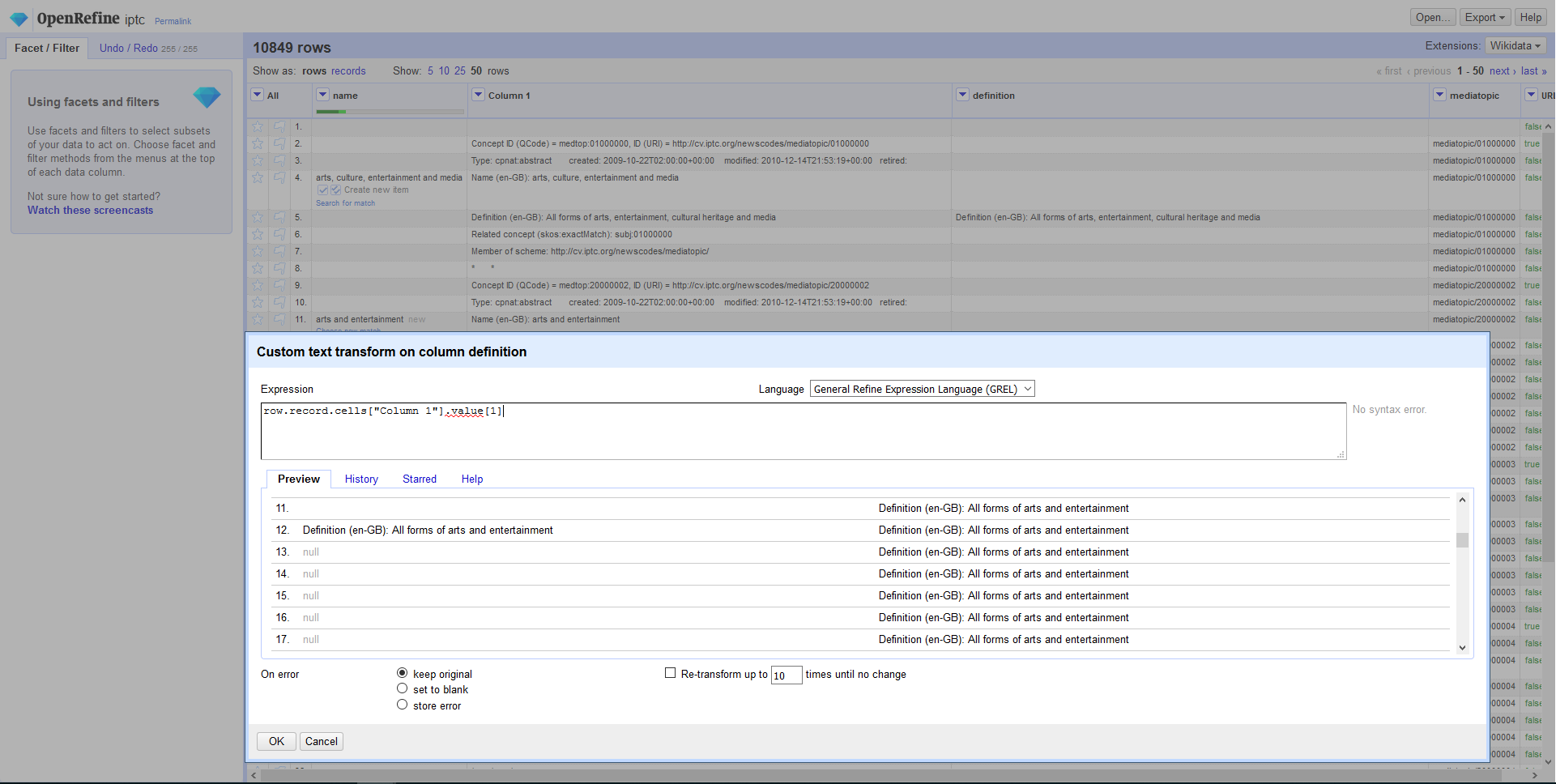
Often times you might need to do a Fill Up command (instead of Fill Down). Or your data has a column with lots of rows in a column for an individual record, and you want to select or get some of those rows. You can do this by selecting only the rows from the Record row array that you need.
This gets only the 2nd row of the Record array
row.record.cells["Column 1"].value[1]
(right click "view image") https://user-images.githubusercontent.com/986438/43036011-86980efc-8cbe-11e8-8493-e8a1fd934e8f.PNG
{kind=link}
If you want to get multiple rows then just use Array slicing
This gets the 1st through 4th row of the Record array
row.record.cells["Column 1"].value[0,3]
This gets the 2nd through 4th row of the Record array
row.record.cells["Column 1"].value[1,3]
(right click "view image") https://user-images.githubusercontent.com/986438/43036041-4c394b76-8cbf-11e8-9c81-39607714d64e.PNG
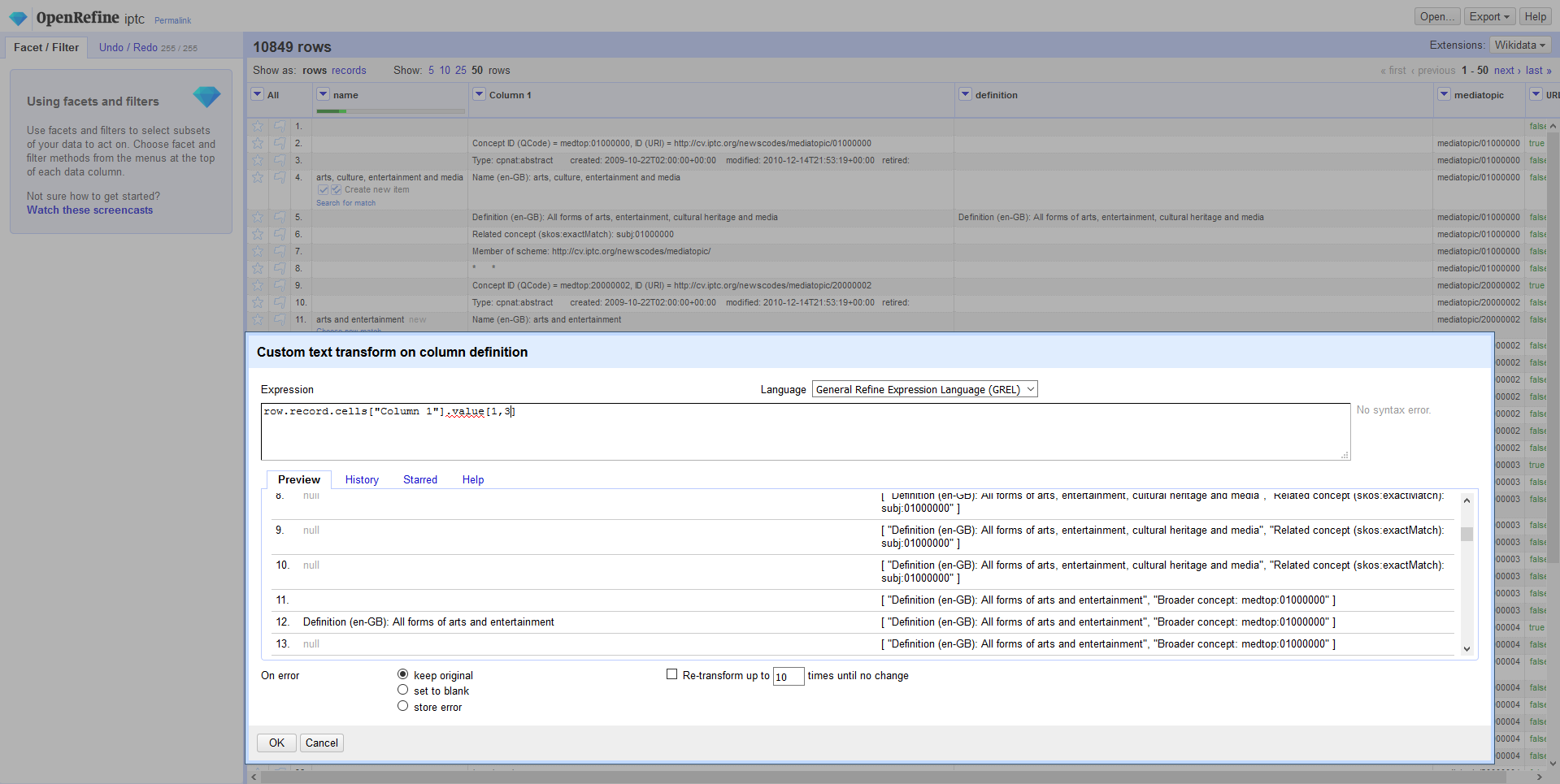{kind=link}
1. Add a new column based on the Name col:
Name > Edit column > Add column based on this column...
Call the column 'index' (or similar).
In expression, type: ""
This creates a new but empty column.
2. Move the new 'index' column to be the first column in the project:
index > Edit column > Move column to beginning
3. Edit the cell in the first row of the 'index' column to have some value in it. It could be anything, e.g. 'first'.
4. Change to 'Record' mode by clicking 'Show as: records' link (top left of the project).
This should create you a single record based on the index column only having a value in the first row.
If this doesn't work, then use 'Fill down' and then 'Blank down' on the Index column, and you should find this forces the shift to a single record.
5. Modify the cells in the 'Age' column so empty cells have a placeholder value in them - this is to make sure the next step (which ignores empty cells) works correctly.
Age > Edit cells > Transform
In the Expression box type:
if(isBlank(value),"null",value)
6. Move the values in the Age column down one cell
Age > Edit cells > Transform
In expression type:
row.record.cells["Age"].value[rowIndex-1]
The row.record.cells["Age"].value part of this creates an array of
values using all the values in the Age column - because they are now all
part of the same Record (which is what steps 1-5 achieved). You can then
extract the value from the row above using 'rowIndex' which gives you a
row number.
Note that the first row in the project will get the value from the last row in the project using this expression. If this is 'null' you don't need to worry about this.
7. Remove the dummy values in the Age column
Age > Edit cells > Transform
In expression type:
if(value=="null","",value)
8. Remove the index column
index > Edit column > Remove this column
9. Make sure you are back in Row mode by clicking 'Show as: rows' link
-
Getting the value of a cell. ( Same as simply
value. )(.-value (.-cell cell)) -
Get a different cell in the row (indexed by number, which is 1 in this case)
(.getCellValue (.-row row) 1) -
Get a different cell in the row by column name
(.-value (.-cell (.getField cells "ColumnName" (new java.util.Properties))))
Given a column that contains Roman numbers, you can convert them using the following Clojure snippet
| Column 1 | output |
|---|---|
| vii | 7 |
| v | 5 |
| xix | 19 |
| iv | 4 |
(defn ro2ar [r]
(->> (reverse (.toUpperCase r))
(map {\M 1000 \D 500 \C 100 \L 50 \X 10 \V 5 \I 1})
(partition-by identity)
(map (partial apply +))
(reduce #(if (< %1 %2) (+ %1 %2) (- %1 %2)))))
(ro2ar value)Clojure supports Java interoperability and provides several syntax forms to use a builtin Java class and it's fields and methods.
#_ Provide the builtin class separated by slash / and then the field or method
(Integer/parseInt "1")
(Integer/parseInt value)
#_ Can't remember what PI is from your high school Math class?
(StrictMath/PI)
#_ Import a Java class and use it in a Clojure function
(import [org.apache.commons.codec.digest DigestUtils])
(defn md5-hash [input]
(DigestUtils/md5Hex input))
(md5-hash "hello world!") Use Clojure as your expression language and use one of these expressions (consult java URL or URI docs for other methods besides just the .getHost() method.
(.getHost(java.net.URL. http://www.example.com/index/search/q=%22OpenRefine%22))
(.getHost(java.net.URI. value))
(.getPath (java.net.URI. value))
(.getQuery (java.net.URI. value))
(.toURI (java.net.URL. value))
(uri? (.toURI (java.net.URL. value)))
Sometimes when doing reconciliation you want to perform some calculation on the reconciliation candidates. This is probably easiest by splitting out the candidates into their own cells. Say you had a single reconciled cell like so:
item
MyItem(*)
(Here (*) represents reconciled with candidates.) We'll describe splitting those candidates shortly,
but it's often helpful to add a column with the original row indices first by adding a column with the
GREL expression row.index so that your table now looks like this:
item idx
MyItem(*) 1
Next you can gather up all the candidates and their scores by adding a column with the following GREL expression:
forEach(cell.recon.candidates,cand,join([cand.id,cand.name],";")).join(",")
So that your table now looks like this:
item idx cand
MyItem(*) 1 Q6;32.6,Q974;80.6,Q1111;64.3
Now you use Edit cells -> split multi-valued cells with the , separator to make the table
item idx cand
MyItem(*) 1 Q6;32.6
Q974;80.6
Q1111;64.3
And then Edit column -> split into several columns with the ; separator to make
item idx cand 1 cand 2
MyItem(*) 1 Q6 32.6
Q974 80.6
Q1111 64.3
Then it's often helpful to fill down both the item and idx columns like so:
item idx cand 1 cand 2
MyItem(*) 1 Q6 32.6
MyItem(*) 1 Q974 80.6
MyItem(*) 1 Q1111 64.3
It's probably worth changing those column names, but now you have the candidates each
in their own cells. The cand 1 column can be reconciled by identifier (using
Reconcile -> Use values as identifiers).
Note: Here we're using the idx column to store the row index of the original row and not merely the current row. This serves a slightly different purpose than the example above.
At this point you could use Edit column ->
Add column from reconciled values to pull more information about the candidate.
For the Wikibase reconciliation service, extending
with SPARQL: Len to pull in the entry's label may be helpful.
Another example might be pulling geographic coordinates to do a distance calculation.
Now you can choose which value you want to reconcile by flagging the row. So you'll have something like the following:
item idx cand 1 cand 2
MyItem(*) 1 Q6 32.6
F MyItem(*) 1 Q974 80.6
MyItem(*) 1 Q1111 64.3
Finally, you can find which items have candidates chosen by using the following GREL expression:
if( row.index == cells.idx.value,
with( cell.cross('','idx'), cross,
with( filter(cross,r,r.flagged), flagged,
if( length(flagged) > 0,
forEach(flagged,r,r.cells['cand 1'].value).join(';'),
false
)
)
),
null
)
Here we used the idx column we created above for this self-cross. Now you
have the following:
item idx cand 1 cand 2 selected
MyItem(*) 1 Q6 32.6 Q974
F MyItem(*) 1 Q974 80.6
MyItem(*) 1 Q1111 64.3
This is probably more clear when there is more than one reconciled item. Say we had the following:
item idx cand 1 cand 2 selected
MyItem(*) 1 Q6 32.6 Q974
F MyItem(*) 1 Q974 80.6
MyItem(*) 1 Q1111 64.3
MyItem(*) 2 Q98 3.2 false
YourItem(*) 2 Q19 53.0
YourItem(*) 2 Q366 11.7
YourItem(*) 2 Q293 93.2
YourItem(*) 2 Q1 66.3
YourItem(*) 2 Q4 93.2
Now using the selected facet to filter out null values and removing the
idx, cand 1 and cand 2 columns, you get back the
original table with an extra column.
item selected
MyItem(*) Q974
YourItem(*) false
Note you could simply use the Flag for the facet, but then unflagged
rows will contain a mix of reconciled values with no candidates chosen and
reconciled values with unchosen candidates. Moreover, you don't preserve
other columns from the original table. Note also that the selected column
contains a ; separated list of selected columns in case you flag more
than one per item.
Bulk upload images to Wikimedia Commons with OpenRefine 3.7+
You can use GREL to populate templated Wikitext with descriptive metadata, which will then display a formatted table on the image's Commons page.
The main structure of the instruction looks like this:
"== {{int:filedesc}} ==\n" +
"{{Information\n" +
*Your field instructions go here!*
"}}\n" +
"=={{int:license-header}}==\n" +
"{{cc-by-4.0}}\n" +
*Your category instructions go here!*
All the \n bits make sure there’s a linebreak instead of it all running on, and the + symbols connect the individual instructions into one big transformation that happens at once.
If using another template, put the name where the example says Information. The following examples are for a customised template for specimen images.
For each template field you want to populate, include a section that looks like this:
if(isBlank(cells.qualifiedName.value), "", "|qualifiedName=" + cells.qualifiedName.value + "\n") +
Here, each field checks if the record has data for it. If not, it knows to leave it out, but if there is data, it’ll pull it into the right part of the Wikitext column. qualifiedName is the label for both the column in the OpenRefine project and the field in the template.
For each category you want to add to all your images, include a section like this:
[[Category:Botany in Te Papa]]\n" +
But if there are categories you only want to include on some records, add the category name to its own column and do this instead:
if(isBlank(cells.categoryScientificName.value), "", "[[Category:" + cells.categoryScientificName.value + "]]\n") +
Like the field data, this only adds the category to the Wikitext if you’ve got a value to fill it in.
A full GREL instruction for a custom template might look like this:
"== {{int:filedesc}} ==\n" +
"{{TePapaColl\n" +
"|description=" + cells.description.value + "\n" +
"|date=" + cells.date.value + "\n" +
"|author=" + cells.author.value + "\n" +
"|source=" + cells.source.value + "\n" +
if(isBlank(cells.title.value), "", "|title=" + cells.title.value + "\n") +
if(isBlank(cells.mātaurangaMāori.value), "", "|MātaurangaMāori=" + cells.mātaurangaMāori.value + "\n") +
if(isBlank(cells.placeCreated.value), "", "|placeCreated=" + cells.placeCreated.value + "\n") +
if(isBlank(cells.madeOf.value), "", "|madeOf=" + cells.madeOf.value + "\n") +
if(isBlank(cells.depicts.value), "", "|depicts=" + cells.depicts.value + "\n") +
if(isBlank(cells.basisOfRecord.value), "", "|basisOfRecord=" + cells.basisOfRecord.value + "\n") +
if(isBlank(cells.vernacularName.value), "", "|vernacularName=" + cells.vernacularName.value + "\n") +
if(isBlank(cells.qualifiedName.value), "", "|qualifiedName=" + cells.qualifiedName.value + "\n") +
if(isBlank(cells.typeStatus.value), "", "|typeStatus=" + cells.typeStatus.value + "\n") +
if(isBlank(cells.identifiedBy.value), "", "|identifiedBy=" + cells.identifiedBy.value + "\n") +
if(isBlank(cells.genusVernacularName.value), "", "|genusVernacularName=" + cells.genusVernacularName.value + "\n") +
if(isBlank(cells.family.value), "", "|family=" + cells.family.value + "\n") +
if(isBlank(cells.dateCollected.value), "", "|dateCollected=" + cells.dateCollected.value + "\n") +
if(isBlank(cells.recordedBy.value), "", "|recordedBy=" + cells.recordedBy.value + "\n") +
if(isBlank(cells.country.value), "", "|country=" + cells.country.value + "\n") +
if(isBlank(cells.stateProvince.value), "", "|stateProvince=" + cells.stateProvince.value + "\n") +
if(isBlank(cells.catalogueRestrictions.value), if(isBlank(cells.preciseLocality.value), "", "|preciseLocality=" + cells.preciseLocality.value + "\n"), "") +
if(isBlank(cells.elevation.value), "", "|elevation=" + cells.elevation.value + "\n") +
if(isBlank(cells.depth.value), "", "|depth=" + cells.depth.value + "\n") +
if(isBlank(cells.institutionCode.value), "", "|institutionCode=" + cells.institutionCode.value + "\n") +
if(isBlank(cells.institution.value), "", "|institution=" + cells.institution.value + "\n") +
if(isBlank(cells.identifier.value), "", "|identifier=" + cells.identifier.value + "\n") +
if(isBlank(cells.creditLine.value), "", "|creditLine=" + cells.creditLine.value + "\n") +
"}}\n" +
"=={{int:license-header}}==\n" +
"{{cc-by-4.0}}\n" +
"[[Category:Botany in Te Papa Tongarewa]]\n" +
"[[Category:Uploaded by Te Papa staff]]\n" +
"[[Category:Herbarium specimens]]\n" +
if(isBlank(cells.categoryScientificName.value), "", "[[Category:" + cells.categoryScientificName.value + "]]\n") +
if(isBlank(cells.typeStatus.value), "", "[[Category:Museum of New Zealand Te Papa Tongarewa type specimens]]\n")