exam16 5
ИДБ-18-07
Реферат к лекции 16. Технологии хранилищ данных
Выполнил: Выполнил: Павлов Андрей, ИДБ-18-07
Проверила Аминова Лиана ИДБ-18-07
Термин Big Data появился в 2008 году. Впервые его употребил редактор журнала Nature — Клиффорд Линч. Он рассказывал про взрывной рост объемов мировой информации и отмечал, что освоить их помогут новые инструменты и более развитые технологии.
Big Data буквально переводится на русский язык как «Большие данные». Этим термином определяют массивы информации, которые невозможно обработать или проанализировать при помощи традиционных методов с использованием человеческого труда и настольных компьютеров. Особенность Big Data еще и в том, что массив данных со временем продолжает экспоненциально расти, поэтому для оперативного анализа собранных материалов необходимы вычислительные мощности суперкомпьютеров. Соответственно, для обработки Big Data необходимы экономичные, инновационные методы обработки информации и предоставления выводов. Работа с Big Data помогает фирмам привлечь больше потенциальных клиентов и увеличить доходы, использовать ресурсы рационально и строить грамотную бизнес-стратегию.
| Традиционная аналитика | Big data аналитика |
|---|---|
| Постепенный анализ небольших пакетов данных | Обработка сразу всего массива доступных данных |
| Редакция и сортировка данных перед обработкой | Данные обрабатываются в их исходном виде |
| Старт с гипотезы и ее тестирования относительно данных | Поиск корреляций по всем данным до получения искомой информации |
| Данные собираются, обрабатываются, хранятся и лишь затем анализируются | Анализ и обработка больших данных в реальном времени, по мере поступления |
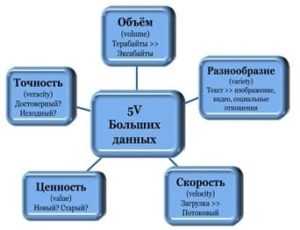
Существует так называемое правило 3V, которое служит характеристикой больших данных:
- Volume — измерение объема в физической величине, которая занимает определенное пространство на носителе. Приставка «Биг» означает получение информационного массива в размере более 150 Гб за день.
- Velocity — регулярное обновление в режиме реального времени за счет применения интеллектуальных технологий.
- Variety — абсолютная или частичная бессистемность, разнообразие.
С течением времени упомянутые выше признаки дополнили еще двумя факторами:
- Variability — способность изменяться в зависимости от внешних обстоятельств, неуправляемые всплески и спады поступающих потоков зачастую связаны с периодичностью;
- Value — изменчивость в зависимости от сложности может затруднить функционирование искусственного интеллекта. То есть сначала требуется определение степени значимости, а после этого идет этап структуризации.
Рис. 1. 5V – главные характеристики Big Data
Источниками больших данных могут быть:
- интернет — соцсети, блоги, СМИ, форумы, сайты, интернет вещей (Internet of Things, IoT);
- корпоративная информация – транзакции, архивы, базы данных и файловые хранилища;
- показания приборов — датчиков, сенсоров, регистраторов и пр.
Чтобы получить рабочую гипотезу о причинах возникновения конкретных ситуаций, в частности, как связаны отказы оборудования с условиями подачи напряжения, или спрогнозировать вероятность какой-либо ситуации, например, вероятность своевременного возврата кредита частным заемщиком, анализ больших объемов структурированной и неструктурированной информации выполняется в несколько этапов:
- чистка данных (data cleaning) – поиск и исправление ошибок в первичном наборе информации, например, ошибки ручного ввода (опечатки), некорректные значения с измерительных приборов из-за кратковременных сбоев и т.д.;
- генерация предикторов (feature engineering) – переменных для построения аналитических моделей, например, образование, стаж работы, пол и возраст потенциального заемщика;
- построение и обучение аналитической модели (model selection) для предсказания целевой (таргетной) переменной. Так проверяются гипотезы о зависимости таргетной переменной от предикторов. Например, сколько дней составляет просрочка по кредиту для заемщика со средним образованием и стажем работы менее 3-х месяцев.
К основным методам сбора и анализа больших данных относят следующие:
- Data Mining – обучение ассоциативным правилам, классификация, кластерный и регрессионный анализ;
- краудсорсинг — категоризация и обогащение данных народными силами, т.е. с добровольной помощью сторонних лиц;
- смешение и интеграция разнородных данных, таких как, цифровая обработка сигналов и обработка естественного языка;
- машинное обучение (Machine Learning), включая искусственные нейронные сети, сетевой анализ, методы оптимизации и генетические алгоритмы;
- распознавание образов;
- прогнозная аналитика;
- имитационное моделирование;
- пространственный и статистический анализ;
- визуализация аналитических данных — рисунки, графики, диаграммы, таблицы.
Программно-аппаратные средства работы с Big Data предусматривают масштабируемость, параллельные вычисления и распределенность, т.к. непрерывное увеличение объема – это одна из главных характеристик больших данных. К основным технологиям относят нереляционные базы данных (NoSQL), модель обработки информации MapReduce, компоненты кластерной экосистемы Hadoop, языки программирования R и Python, а также специализированные продукты Apache (Spark, AirFlow, Kafka, HBase и др.)
Реферат к лекции 16. Технологии хранилищ данных
Выполнил: Утенкова Е.А., группа ИДБ-19-06
Проверил: Рыкалов А.П., группа ИДБ-19-06
Большие данные (англ. Big Data) – совокупность непрерывно увеличивающихся объемов информации одного контекста, но разных форматов представления, а также методов и средств для эффективной и быстрой обработки [1].
Проблемы, связанные с анализом данных, возникли в различных областях исследований задолго до появления самого термина. Но именно благодаря бурному развитию компьютерных технологий, появлению Интернета (в современном понимании этого термина) в конце 1980-х — начале 1990-х годов стало возможным собирать, хранить, передавать и обрабатывать большие объемы данных, анализ данных сформировался как самостоятельное научное направление.
Источников больших данных множество: интернет с социальными сетями, и информация с мобильных устройств (например, гео данные), и показания с измерительных устройств (счетчиков, датчиков и т.п.), и фото/видео информация из общественных мест, где используются системы наблюдения, транзакции в компаниях и т.д.
Чтобы работать с большими данными, нужно уметь их собирать — считывать. Их нужно где-то хранить — управлять потоками неструктурированных данных, состоящих из текстов, изображений, видео, объединять данные из разных источников, обеспечивать возможность доступа из приложений.
Хранение больших данных - это инфраструктура хранения, специально предназначенная для хранения, управления и извлечения огромных объемов данных или больших данных. Хранение больших данных позволяет хранить и сортировать большие данные таким образом, чтобы их можно было легко получать, использовать и обрабатывать приложениями и службами, работающими с большими данными. Хранение больших данных также может гибко масштабироваться по мере необходимости.
Типичная архитектура хранения больших данных состоит из избыточного и масштабируемого набора пулов хранения с прямым подключением (DAS), масштабируемого или кластерного сетевого хранилища (NAS) или инфраструктуры, основанной на формате объектного хранилища. Инфраструктура хранения связана с узлами вычислительных серверов, которые обеспечивают быструю обработку и извлечение больших объемов данных.
| Свойство | Описание |
|---|---|
| Объем | Количество данных — важный фактор. Располагая ими в больших количествах, Вам потребуется обрабатывать большие объемы неструктурированных данных низкой плотности. Ценность таких данных не всегда известна. Это могут быть данные каналов Twitter, данные посещаемости веб-страниц, а также данные мобильных приложений, сетевой трафик, данные датчиков. В некоторые организации могут поступать десятки терабайт данных, в другие — сотни петабайт. |
| Скорость | Скорость в данном контексте — это быстрота приема данных и, возможно, действий на их основе. Обычно высокоскоростные потоки данных поступают прямо в оперативную память, а не записываются на диск. Некоторые "умные" продукты с поддержкой Интернета работают в режиме реального или практически реального времени. Соответственно, такие данные требуют оценки и действий в реальном времени. |
| Разнообразие | Разнообразие означает, что доступные данные принадлежат к разным типам. Традиционные типы данных структурированы и могут быть сразу сохранены в реляционной базе данных. С появлением Big Data, данные стали поступать в неструктурированном виде. Такие неструктурированные и полуструктурированные типы данных как текст, аудио и видео, требуют дополнительной обработки для определения их значения и поддержки метаданных. |
Volume (объем) данных представляет собой количество данных, доступных для анализа с целью извлечения полезной информации. Ключевым для развития технологий обработки больших данных стал рост объемов данных вследствие интернет-активности. Например, на YouTube загружается 300 часов видео каждую минуту, а объем мобильного трафика достиг 6,2 млрд гигабайт в месяц.
Velocity (скорость) обработки данных — это скорость потока создания, хранения, анализа и визуализации данных. Быстрота изменений приводит к необходимости обработки большого количества данных за короткий промежуток времени. Так, Google обрабатывает 40 тысяч поисковых запросов в секунду — то есть 3,5 млрд запросов в день.
Variety (разнообразие) данных заставляет анализировать данные разных типов из различных предметных областей. Кроме того, большие данные включают в себя не только структурированные, но полуструктурированные и неструктурированные данные — и последних большинство. К большим данным относятся аудио- и видеофайлы, изображения, данные постов в социальных сетях и другие текстовые форматы, данные о переходе по ссылкам, машинные данные, данные датчиков.
ГОСТ выделяет еще одну, четвертую ключевую характеристику:
Variability (вариативность) данных — это изменения в скорости передачи данных, их формате и (или) структуре, семантике и (или) качестве, которые влияют на работу с данными. Вариативность приводит к необходимости реорганизации архитектур, интерфейсов, методов обработки, влияет на интеграцию, слияние, хранение, применимость и использование данных.
Иногда к первым четырем V добавляются еще шесть дополнительных признаков: veracity (достоверность), visualization (визуализация), validity (валидность), vulnerability (уязвимость), volatility (волатильность) и value (ценность).
Появление платформ на основе открытого кода, таких как Hadoop и позднее Spark, сыграло значительную роль в распространении больших данных, так как эти инструменты упрощают обработку больших данных и снижают стоимость хранения. За прошедшие годы объемы больших данных возросли на порядки. Огромные объемы данных появляются в результате деятельности пользователей — но теперь не только их.
С появлением Интернета вещей (IoT) все большее число устройств получает подключение к Интернету, что позволяет собирать данные о моделях действий пользователей и работе продуктов. А когда появились технологии машинного обучения, объем данных вырос еще больше.
Большие данные имеют долгую историю развития, однако их потенциал еще далеко не раскрыт. Облачные вычисления раздвинули границы применения больших данных еще шире. Облачные технологии обеспечивают по-настоящему гибкие возможности масштабирования, что позволяет разработчикам развертывать кластеры для тестирования выборочных данных по требованию. Кроме того, также все более значимыми становятся графовые базы данных, позволяющие отображать громадные объемы данных так, чтобы анализировать их можно было быстро и всеобъемлюще. [2]
Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, не справлялась с возникшими проблемами. Главная причина – концепция усреднения по выборке, приводящая к операциям над фиктивными величинами (например, температура пациентов по больнице, средняя высоты дома на улице). Методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining) и для «грубого» разведочного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing, OLAP).
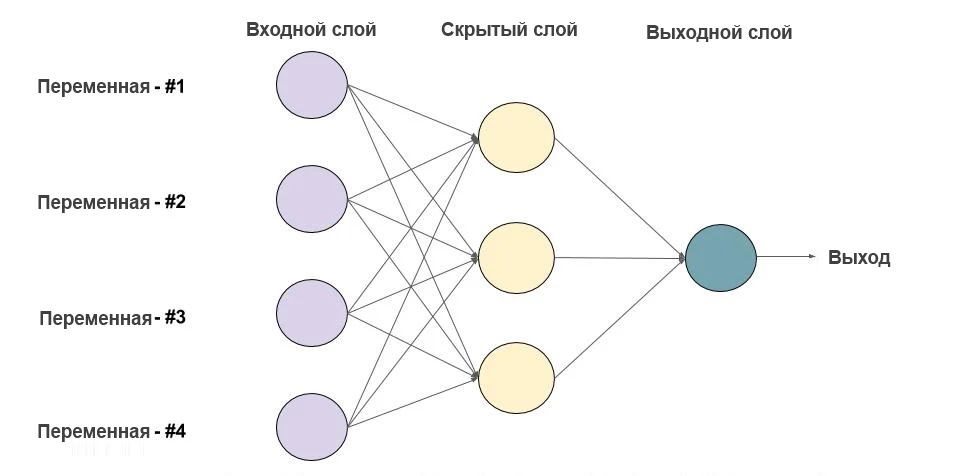
Этот метод анализ данных содержит в своей основе способность аналитической системы самостоятельно обучаться в процессе решения различных задач. Т.е. программе задается алгоритм, который позволяет ей учиться выявлять определенные закономерности. Сферы применения такого метода достаточно разнообразны — например, с помощью машинного обучения проводятся маркетинговые исследования, социальные сети предлагают подборку постов, происходит разработка медицинских программ.
Нейросеть используют для распознавания визуальных образов. Нейронные сети — это математические модели, отображенные программным кодом. Такие модели работают по принципу нейронной сети живого существа: получение информации — ее обработка и передача — выдача результата.
Нейросеть способна проделать работу за несколько десятков людей. Ее используют для развлечений, прогнозирования, обеспечения безопасности, медицинской диагностики и т. д. Т.е. в различных социальных и профессиональных областях.
В основу современной технологии Data Mining (discovery-driven data mining) положена концепция шаблонов (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборке и виде распределений значений анализируемых показателей [3].
Важное положение Data Mining – нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные регулярности в данных, составляющие так называемые «скрытые знания». К обществу пришло понимание, что «сырые данные» содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие, ценные знания.
Другими словами, методика прогнозирования. Имея достаточный объем соответствующей информации, можно составить прогноз и ответить на вопрос «Как будут развиваться события?». Принцип предиктивной аналитики таков: сначала нужно исследовать данные за прошлый период; выявить закономерности или факторы, которые стали причиной результата; далее с помощью нейросети или математических вычислений создать модель, которая сможет производить прогнозирование.

Суть метода заключается в сборе данных, их изучении на основе конкретных параметров и получении результата, выраженного, как правило, в процентах. У этого метода есть слабое звено — неточность данных в маленьких выборках. Поэтому для получения максимально точных результатов необходимо собирать большой объем исходных данных.
Для получения статистических показателей используют:
- корреляционный анализ для определения взаимозависимости показателей;
- процентное соотношение итогов анализа;
- динамические ряды для оценки интенсивности изменений определенных условий в конкретный интервал времени;
- определение среднего показателя.
Имитационное моделирование отличается от методики прогнозирования тем, что берутся в учет факторы, чье влияние на результат затруднительно отследить в реальных условиях. Т.е. выстраиваются модели с учетом гипотетических, а не реальных данных, и затем эти модели исследуют в виртуальной реальности.
Метод имитационных моделей применяют для анализа влияния разных обстоятельств на итоговый показатель. Например, в сфере продаж таким образом исследуют воздействие изменения цены, наличия предложений со скидками, количества продавцов и прочих условий. Различные вариации изменений помогают определить наиболее эффективную модель маркетинговой стратегии для внедрения в практику. Для такого рода моделирования необходимо использовать большое число возможных факторов, чтобы снизить риски недостоверности результатов.
Для удобства оценки результатов анализа применяют визуализацию данных. Для реализации этого метода, при условии работы с большими данными, используют виртуальную реальность и «большие экраны». Основной плюс визуализации в том, что такой формат данных воспринимается лучше, чем текстовый, ведь до 90 % всей информации человек усваивает с помощью зрения.
В подавляющем большинстве случаев Big Data получают из различных источников, соответственно, данные имеют разнородный формат. Загружать такие данные в одну базу бессмысленно, так как их параметры не имеют взаимного соотношения. Именно в таких случаях применяют смешение и интеграцию, то есть приводят все данные к единому виду.
Для использования информации из различных источников применяют следующие методы:
- сведение данных в единый формат посредством конвертации документов, перевода текста в цифры, распознавание текста;
- информацию для одного объекта дополняют данными из разных источников;
- из лишней информации отфильтровывают и удаляют ту, которая недоступна для анализа.
После того как процесс интеграции завершен, следует анализ и обработка данных. В качестве примера метода интеграции и смешения данных можно рассмотреть: магазин, который ведет торговлю в нескольких направлениях — оффлайн-продажи, маркетплейс и одна из соцсетей. Чтобы провести полноценную оценку продаж и спроса, нужно собрать данные: о заказах через маркетплейс, товарные чеки оффлайн-продаж, заказы через соцсеть, остатки товара на складе и так далее. [4]