QueryUnfoldingBenchmark
Null hypothesis: "A non-nested query statement is faster than a nested query statement in term of execution time."
A nested query or subquery is a query that is resided inside a SELECT, INSERT, UPDATE, DELETE or JOIN statement, or inside another subquery. A subquery SELECT statement if executed independently will return a result set. Meaning a subquery SELECT statement can standalone and is not depended on the statement in which it is nested. Usually, virtual tables are used in building and working with subqueries and they are built on the fly. An example:
SELECT R.x, R.y FROM ( SELECT A.x FROM A UNION ALL SELECT B.x FROM B ) AS T1 JOIN R ON T1.x = R.x JOIN ( SELECT A.x FROM A UNION ALL SELECT B.x FROM B ) AS T2 ON R.y = T2.x
In the above example, the subqueries are constructed as union operations that are used later in the join operations. The statement above is equivalent to:
SELECT R.x, R.y FROM A JOIN R ON A.x = R.x JOIN A ON R.y = A.x UNION ALL SELECT R.x, R.y FROM B JOIN R ON B.x = R.x JOIN A ON R.y = A.x UNION ALL SELECT R.x, R.y FROM A JOIN R ON A.x = R.x JOIN B ON R.y = B.x UNION ALL SELECT R.x, R.y FROM B JOIN R ON B.x = R.x JOIN B ON R.y = B.x
The difference between both statements is that the latter is not nested but instead it forms as a sequence of union operators that merges several elementary join operations. We suggest this "expanded" version of query can be executed faster compared to the former one. This experiment tries to demonstrate such claim to be reasonably acceptable.
We conducted an empirical experiment by repetitively measuring the execution time of a query from its base construction to its most plain construction. We defined a base query as a nested join query that has the following construction:
(X ⋈ R) ⋈ Xwhere X is composed of multiple union operations. For example:
- One union operator
((A ∪ B) ⋈ R) ⋈ (A ∪ B)
- Two union operators
((A ∪ B ∪ C) ⋈ R) ⋈ (A ∪ B ∪ C)
- and so on.
- One union operator
((A ⋈ R) ⋈ A) ∪ ((B ⋈ R) ⋈ A) ∪ ((A ⋈ R) ⋈ B) ∪ ((B ⋈ R) ⋈ B)
- Two union operators
((A ⋈ R) ⋈ A) ∪ ((A ⋈ R) ⋈ B) ∪ ((A ⋈ R) ⋈ C) ∪ ((B ⋈ R) ⋈ A) ∪ ((B ⋈ R) ⋈ B) ∪ ((B ⋈ R) ⋈ C) ∪ ((C ⋈ R) ⋈ A) ∪ ((C ⋈ R) ⋈ B) ∪ ((C ⋈ R) ⋈ C)
- and so on.
- Database engine. Different database engines use different kinds of strategy in executing the query. We would like to observe which engine support our hypothesis. Currently, we are working on two DBMS, i.e., MySQL dan PostgreSQL.
We follow these two main steps in our experiment:
Before we conduct the experiment, we prepare the table schema and data. The goal is to create different execution environments in term of data volume and index sensitivity. We created a tool called DataCreatorClient to automate the execution.
The data preparation consists of 4 steps (see the image below):
- Reading configuration files for input parameters,

1) Reading configuration files. The tool provides a flexible way to prepare the data by having the parameters in an external file as shown below.
# Database settings database.url=obdalin.inf.unibz.it:3306 database.user=jsmith database.password=jsmith database.engine=InnoDB # Data settings name.concepts=A,B,C,D,E name.roles=R number.tuples=100000 number.constants=25000,50000,100000,200000,400000
In general, the configuration consists of two parts. The first part rules the database settings and the second part organizes the structure of the sample data. The first three lines in the database settings define the location, the username and the password to connect to the database server. The last line defines the storage engine for the database. Currently, this parameter is used only for MySQL database. There are two options for it, i.e., MyISAM and InnoDB.
Next, in the data settings, we define the tables and the data we are going to generate. There are six relations (or tables) namely A, B, C, D, E and R. The first 5 tables are called the concept table and it has only one attribute x. The last table (i.e., table R) is called the role table and it has two attributes x and y. The next two lines define the number of tuples and constants that will fill each table. Using the example above, the tool will generate 100,000 tuples with 5 variations in the data generation. For example, in the second variation, the tool randomly picks a number from 0 - 49999 and, therefore, there will be plenty of double duplications (Note: several different duplications may arise since this is a random picking).
There are several important notes for using this tool:
- Concept tables can have any names, although a single alphabetical letter is recommended for simplicity.
2) Creating database. For a single configuration file, the tool generates one database with a template name "Benchmark_tx_cy" with x and y correspond with the number of tuples and constants, respectively. So, using the configuration file above, the database will be named as "Benchmark_t1000_c500". The tool generates the database in a predefined DBMS mentioned in the execution arguments (explained later).
3) Creating tables. The tables are generated and named using the name.concept and name.roles parameters as shown above.
4) Generating random data. This final step involves generating, inserting and indexing the data as well as analyzing the table for improving the query performance. The process iterates if the tool finds another configuration files in the target directory.
Next, we are going to discuss the performance measurement which is the main theme of this experiment.
We created another tool called BenchmarkClient to automate the measurement. The tool produces a CSV file that stores all the execution parameters and results for later analysis.
The performance measurement consists of 4 steps (see the image below):
- Reading configuration files for input parameters,

1) Reading configuration files. Similar to our previous tool, the execution of this tool relies on an external configuration file as shown below.
# Database settings database.maps=32:db_t10000_c5000,33:db_t10000_c10000 database.url=obdalin.inf.unibz.it:5432 database.user=postgres database.password=obdaps83 # Experiment settings number.joins=2,4 number.concepts=1,3 number.iterations=5 number.sample.queries=10 timeout=5 count.tuples=false use.union.all=false use.select.count=true
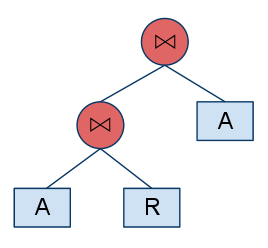
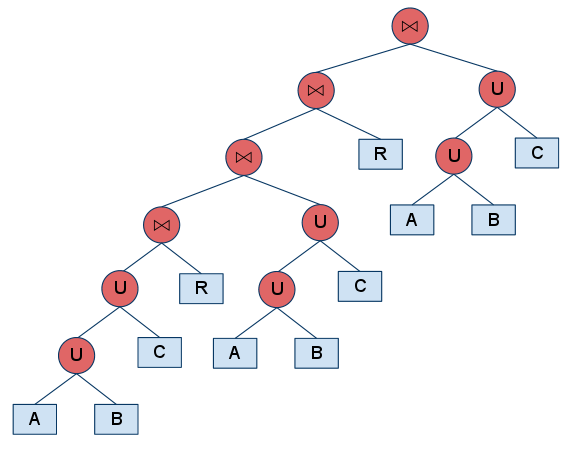
In general, the configuration consists of two parts. The first part is the database settings in which we define the database names, the server address, the username and the password. Note that the format for defining the database is <db_id>:<db_name>. The second part is the experiment setting. The first two lines define the type of query tree we are going to use based on the number of joins and concepts. If you define multiple numbers in these parameters, the tool will create a complete combination. Using the example above, the tool will generate 4 different trees, i.e., {2, 1}, {2, 3}, {4, 1}, {4, 3}. The table below demonstrates the generated trees:
| Configuration {n joins, m concepts} | Query Tree (JAVA code) | Illustration |
|---|---|---|
| {2, 1} | RelationalAlgebraTreeCreator.create(2, 1) |
|
| {2, 3} | RelationalAlgebraTreeCreator.create(2, 3) |

|
| {4, 1} | RelationalAlgebraTreeCreator.create(4, 1) |

|
| {4, 3} | RelationalAlgebraTreeCreator.create(4, 3) |
|
The next line is the number of iterations for a single experiment, i.e., in this case we defined it as 5 times. The number.selected.queries suggests the number of queries we are going to execute. During the unfolding process, the number of expanded queries can be numerous. By using this setting, user can limit the number of queries to be executed. Put "number.selected.queries=-1" if users wish to execute all the queries. Then, we have the amount of timeout (in seconds) to limit the execution time. Users can tell whether the tool should do the tuple counting or not. Users can try a variation of using the operator UNION ALL or UNION in the query generation. And lastly, users can choose whether to add SELECT COUNT(*) command when executing the query or not.
2) Unfolding the query. Our experiment observes also the performance of other equivalent queries along the tree expansions. Our tool API provides a method to iterate the unfolding from its initial stage to the final expansion. And for each iteration, users can obtain the query tree and generate the appropriate query string. The unfolding operation takes an input of a binary tree (i.e., it represents the construction of relational algebra) and uses procedures of left/right rotation and copy subtree to create the expansion.
3) Executing the query. The query string generated from the unfolding is then executed to a database engine in which it returns the tuples. We expect the number of tuples for different expansions to be the same as they are equivalent. We also measure the execution time for each query for benchmarking.
4) Storing the statistics. Finally, the tool saves all the information, including the parameters, the execution time, returned tuples, error message (if any) to a CSV file. Users can import this data to a database for later analysis.
These whole steps are repeated until the tool read all the configuration files.
General usage
usage: java -classpath sqlnfbench-1.1.jar:. inf.unibz.it.benchmark.data.DataCreatorClient [OPTIONS] PROPERTIES_DIR
The sample data generator.
-D <mysql, pgsql, db2> Specify the database system.
-O <csv, db> Specify the output recording mechanism.
-P <key=value,...> Define the parameters for the output writer.Generating data for MySQL server
- CSV Output:
java -classpath sqlnfbench-1.1.jar:. inf.unibz.it.benchmark.data.DataCreatorClient
-Dmysql
-Ocsv
-PdbOut=mysql-db.csv
conf/database/mysql/innodb/- Database Output:
java -classpath sqlnfbench-1.1.jar:. inf.unibz.it.benchmark.data.DataCreatorClient
-Dmysql
-Odb
-PdbConfig=obdalin.inf.unibz.it:5432;Benchmark;jsmith;jsmith
conf/database/mysql/innodb/Generating data for PostgreSQL server
- CSV Output:
java -classpath sqlnfbench-1.1.jar:. inf.unibz.it.benchmark.data.DataCreatorClient
-Dpgsql
-Ocsv
-PdbOut=pgsql-db.csv
conf/database/pgsql/- Database Output:
java -classpath sqlnfbench-1.1.jar:. inf.unibz.it.benchmark.data.DataCreatorClient
-Dpgsql
-Odb
-PdbConfig=obdalin.inf.unibz.it:5432;Benchmark;jsmith;jsmith
conf/database/pgsql/Generating data for DB2 server
- CSV Output:
java -classpath sqlnfbench-1.1.jar:db2cc.jar:db2cc4.jar:. inf.unibz.it.benchmark.data.DataCreatorClient
-Ddb2
-Ocsv
-PdbOut=db2-db.csv
conf/database/db2/- Database Output:
java -classpath sqlnfbench-1.1.jar:db2cc.jar:db2cc4.jar:. inf.unibz.it.benchmark.data.DataCreatorClient
-Ddb2
-Odb
-PdbConfig=obdalin.inf.unibz.it:5432;Benchmark;jsmith;jsmith
conf/database/db2/General usage
usage: java -classpath sqlnfbench-1.1.jar:. inf.unibz.it.benchmark.BenchmarkClient [OPTIONS] PROPERTIES_FILE
CNF-DNF Benchmark tool.
-T Specify the test type, i.e., 'direct', 'semantic', 'alphanum', 'integer'.
-D Specify the database system, i.e., 'mysql', 'pgsql', 'db2'.
-O Specify the output recording mechanism, i.e., 'csv', 'db'.
-P <key=value,...> Define the parameters for the output writer.Measuring performance for MySQL server
- CSV Output:
java -classpath sqlnfbench-1.1.jar:. inf.unibz.it.benchmark.BenchmarkClient
-Tdirect
-Dmysql
-Ocsv
-PtestOut=mysql-test.csv,resultOut=mysql-result.csv
conf/observation/mysql_innodb.properties- Database Output:
java -classpath sqlnfbench-1.1.jar:. inf.unibz.it.benchmark.BenchmarkClient
-Tdirect
-Dmysql
-Odb
-PdbConfig=obdalin.inf.unibz.it:5432;Benchmark;jsmith;jsmith
conf/observation/mysql_innodb.propertiesMeasuring performance for PostgreSQL server
- CSV Output:
java -classpath sqlnfbench-1.1.jar:. inf.unibz.it.benchmark.BenchmarkClient
-Tdirect
-Dpgsql
-Ocsv
-PtestOut=pgsql-test.csv,resultOut=pgsql-result.csv
conf/observation/pgsql.properties- Database Output:
java -classpath sqlnfbench-1.1.jar:. inf.unibz.it.benchmark.BenchmarkClient
-Tdirect
-Dpgsql
-Odb
-PdbConfig=obdalin.inf.unibz.it:5432;Benchmark;jsmith;jsmith
conf/observation/pgsql.propertiesMeasuring performance for DB2 server
- CSV Output:
java -classpath sqlnfbench-1.1.jar:db2cc.jar:db2cc4.jar:. inf.unibz.it.benchmark.BenchmarkClient
-Tdirect
-Ddb2
-Ocsv
-PtestOut=db2-test.csv,resultOut=db2-result.csv
conf/observation/db2.properties- Database Output:
java -classpath sqlnfbench-1.1.jar:db2cc.jar:db2cc4.jar:. inf.unibz.it.benchmark.BenchmarkClient
-Tdirect
-Ddb2
-Odb
-PdbConfig=obdalin.inf.unibz.it:5432;Benchmark;jsmith;jsmith
conf/observation/db2.propertiesWe execute our experiment in a machine with the following specifications:
| Number of processors | 3 |
|---|---|
| CPU model | Intel(R) Xeon(R) X5650 |
| CPU speed | 2.67GHz |
| Cache size | 12288 KB |
| Memory size | 8 GB |