Drone Detection Progression 2026 04
작성일: 2026-04-24
드론 이미지 기반 포도송이(grape bunch) 탐지를 단계적으로 개선해 온 변천사 기록. 결과 숫자보다 "왜 그렇게 결정했고, 왜 좋아졌고/나빠졌는가" 에 포커스를 둔다.
이 문서는 다음 흐름의 결산 위치에 있다.
| 순서 | 문서 | 이 문서에서 무엇을 가져오나 |
|---|---|---|
| 1 | 포도밭 병해충 탐지 및 수확량 예측 | 프로젝트 전체 동기와 문제 정의 |
| 2 | 포도 탐지를 위한 데이터 수집 | 사용한 데이터셋의 출처와 구성 |
| 3 | YOLO Model Comparison Summary | YOLO 계열 baseline 비교의 출발점 |
| 4 | YOLO Baseline Top3 비교 요약 | baseline 시점에서의 model selection 근거 |
| 5 | Grounding DINO vs YOLO 비교 요약 | 다른 detector family와의 비교 |
| 6 | SAM3 vs Fine-tuned YOLO on Drone Imagery | foundation model 검증 |
| 7 | 이 문서 (Progression) | 위 흐름의 결산 + 다음 단계 의사결정 |
이 문서를 처음 보는 경우 위에서부터 1→7 순서로 읽으면 자연스럽다. 단계별 결정의 이유가 어떻게 누적되어 왔는지 알 수 있다.
| 항목 | 값 |
|---|---|
| 평가셋 | 드론 test split 29장, GT bbox 363개 |
| 주 metric | mAP50-95 (단일 IoU만으로는 박스 품질 차이를 못 잡음) |
| 현재 best | yolov8m + (open ∪ drone×100) mixed 학습, mAP50-95 = 0.286 (S2) |
| Stage A 결과 | yolo11m@1280 → mAP50-95 = 0.257 (−0.029, 빗나감) |
| Stage B2 결과 | yolo11m@1536 → mAP50-95 = 0.251 (−0.035, 빗나감) |
| 시사점 | "더 큰 모델/더 큰 입력" 축은 64장 train data에서는 효과 없음. 데이터 축으로 다음 시도 전환 |
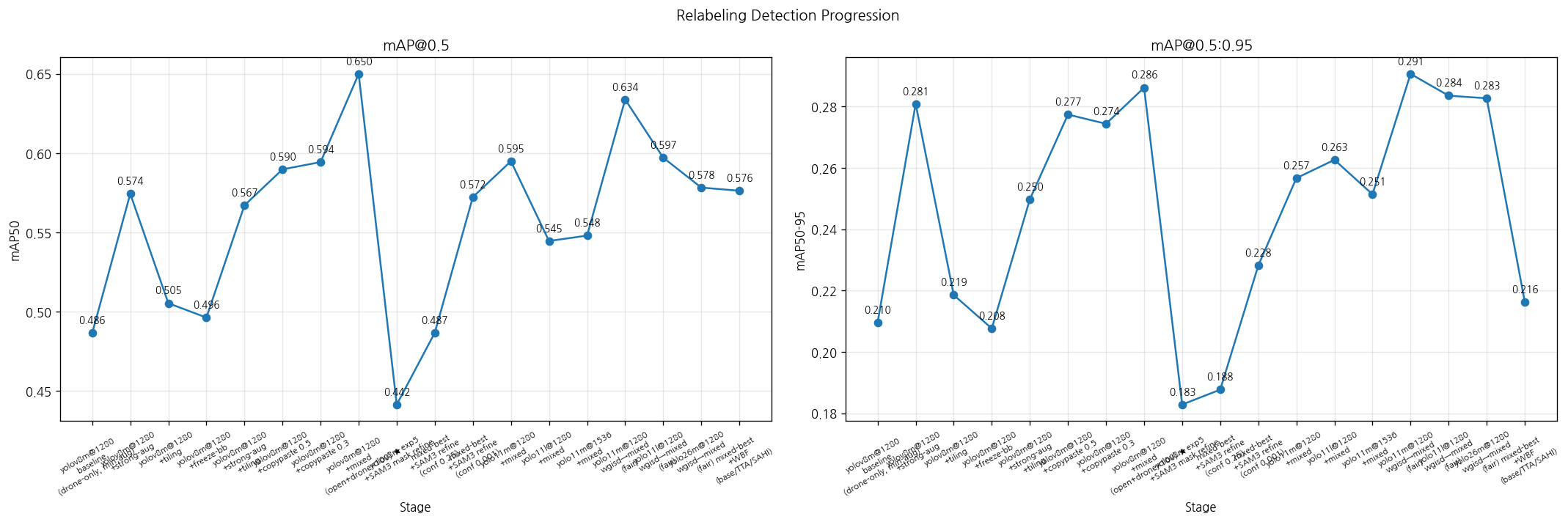 Stage별 mAP50 (좌) 및 mAP50-95 (우) 변천. S2 (mixed-best) 가 정점, A/B2는 빗나감
Stage별 mAP50 (좌) 및 mAP50-95 (우) 변천. S2 (mixed-best) 가 정점, A/B2는 빗나감
| Stage | 한 줄 변경 사항 | mAP50 | mAP50-95 | 한 줄 평가 |
|---|---|---|---|---|
| S0 | yolov8m, 최소 aug | 0.486 | 0.210 | 출발선 |
| S1a | + 강한 aug (mosaic 0.5, mixup 0.1, hsv/회전/스케일 ↑) | 0.574 | 0.281 | aug 단독으로 +0.07, 가장 큰 단일 도약 |
| S1b | + 타일링만 | 0.505 | 0.219 | 단독은 효과 미미 |
| S1c | + freeze backbone | 0.496 | 0.208 | 오히려 하락 |
| S1d | + 강한 aug + 타일링 | 0.567 | 0.250 | aug 단독보다 못함 |
| S1e | + copy_paste 0.5 | 0.590 | 0.277 | aug와 비슷 |
| S1f | + copy_paste 0.3 | 0.594 | 0.274 | aug와 비슷 |
| S2 | + mixed (open ∪ drone×100) | 0.650 | 0.286 ⭐ | 현재 best, 데이터 합성 효과 |
| S2-aux | + SAM3 mask로 박스 refine | 다양 | ↓ | recall ↑이지만 mAP50-95 ↓ (라벨 스타일 충돌) |
| S2-aux | + base/TTA/SAHI/WBF 앙상블 | 0.576 | 0.216 | single 모델 미만 |
| A | 모델만 yolov8m → yolo11m | 0.595 | 0.257 | 빗나감 (이유는 아래 해석) |
| B1 | + yolo11m → yolo11l (capacity ↑) | — | — | 보류 (A/B2 결과 보고 결정) |
| B2 | + imgsz 1280 → 1536 (해상도 ↑) | 0.548 | 0.251 | 빗나감 (이유는 아래 해석) |
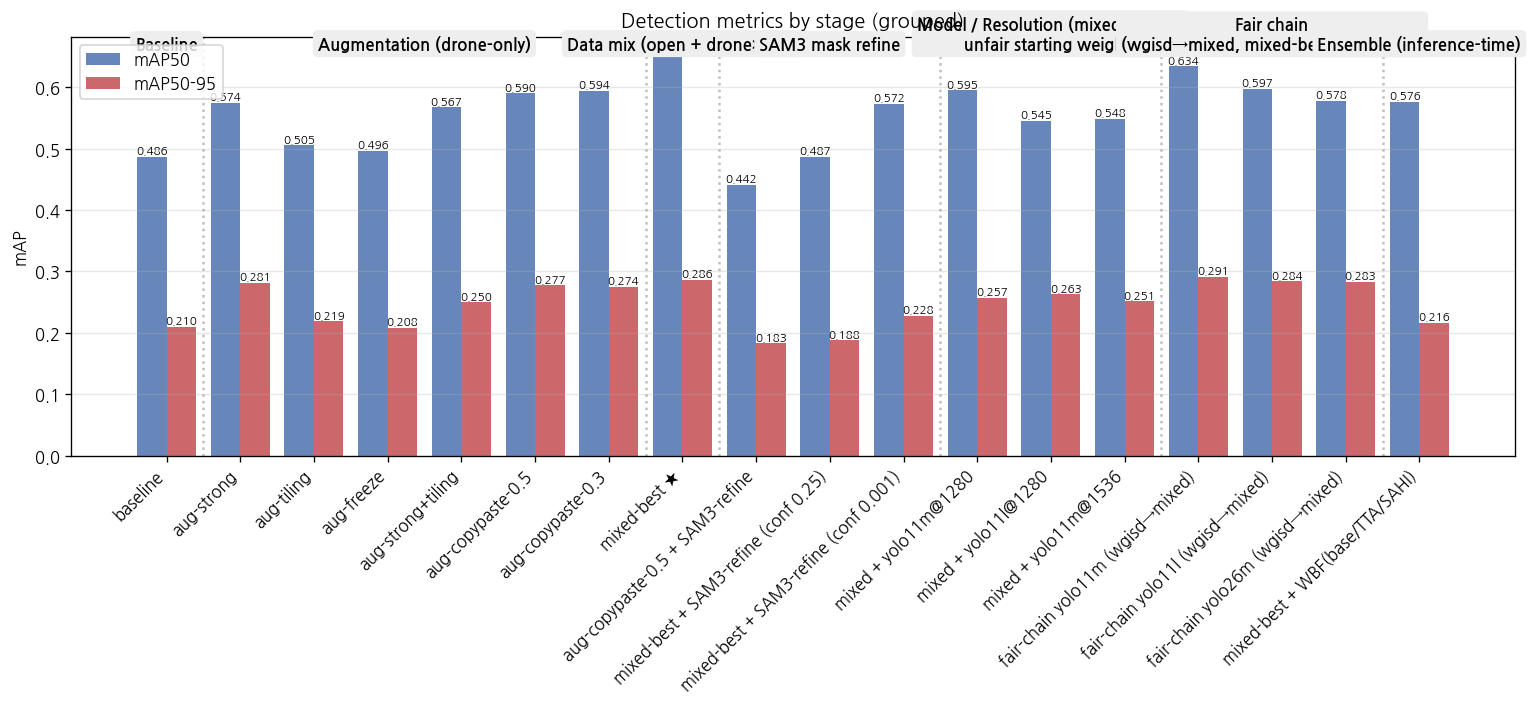 Baseline / Augmentation / Data mix / SAM3 refine / Model-Resolution / Ensemble 6 그룹별 mAP50, mAP50-95 비교
Baseline / Augmentation / Data mix / SAM3 refine / Model-Resolution / Ensemble 6 그룹별 mAP50, mAP50-95 비교
왜 시도했나? drone 데이터가 64장으로 작다. 모델이 이 적은 분포에 overfit 하지 않으려면 입력 다양성을 인위적으로 늘려야 한다.
왜 가장 큰 도약이 일어났나? mosaic이 한 step에서 4장을 한 캔버스로 합치고 매번 다른 random seed가 적용되므로, 같은 이미지라도 모델이 보는 입력 텐서는 매번 다르다. 작은 데이터셋에서는 이런 합성 다양성이 진짜 데이터 추가와 비슷한 효과를 낸다.
왜 일부 변형은 효과가 없거나 음수였나?
| 변형 | 결과 | 왜? |
|---|---|---|
| 타일링 단독 (S1b) | 효과 미미 | 학습 시 random crop+scale로 비슷한 효과가 이미 발생 |
| freeze backbone (S1c) | 하락 | drone 도메인이 pretrained source와 충분히 달라서 backbone fine-tune 필요 |
| copy_paste (S1e/f) | aug와 비슷 | 객체 다양성보다 배경/맥락 다양성이 부족한 도메인 |
S1에서 augmentation만으로 mAP50-95가 0.281까지 올라왔지만 거기서 plateau. 모델이 보는 이미지 자체의 진짜 다양성이 부족하다는 한계가 보였다. drone train 64장은 augment를 아무리 강하게 해도 결국 64장 안의 변형일 뿐이다.
| 데이터셋 | 장 수 | 도메인 | 비고 |
|---|---|---|---|
| drone (재라벨링, 학습 대상 도메인) | 64 | 우리가 잘 하고 싶은 진짜 분포 | test 29장도 같은 도메인 |
| open dataset (외부, 같은 객체 클래스) | 7,341 | 다른 카메라/촬영 조건의 grape | 도메인 갭 있음 |
| 시나리오 | 학습 시 drone이 보일 빈도 | 문제 |
|---|---|---|
| drone만 (S1까지) | 100% | 다양성 한계, plateau |
| 단순 합치기 (drone 64 + open 7341) | 0.86% | drone 도메인이 학습에서 사실상 묻힘 |
| drone × N 복제 (oversample) | N에 따라 조정 가능 | dataloader가 같은 라인 여러 번 sampling |
drone을 그대로 합치면 7341장의 open이 압도적이라 모델이 "open 분포"를 학습한다. test는 drone 분포라 일반화 망함. 그래서 drone 비중을 인위적으로 올리는 oversample이 필요했다.
여러 비율이 가능했지만 100을 선택한 이유:
| 비율 | drone 비중 | 우려 |
|---|---|---|
| ×10 | 8% | 여전히 open이 dominant. drone이 묻힘 |
| ×50 | 30% | 적정 부근이지만 open 우위 |
| ×100 | 47% | 거의 1:1, balanced |
| ×200 | 64% | 같은 64장의 단순 반복 비중 ↑ → overfit 위험 ↑ |
| ×500 | 81% | 사실상 drone-only에 open 양념. S1으로 회귀 |
47% 부근이 직관적으로 자연스럽다. 모델이 두 도메인을 거의 균등하게 본다.
manifest의 같은 라인을 100번 적어놓으면 처음에는 "동일 이미지를 100번 학습? 의미 없는 메모리 복제 아닌가?" 싶다. 핵심은 dataloader가 매 sampling마다 random augmentation을 새로 적용한다는 점.
| 메커니즘 | 같은 64장이지만 매번 다르게 보이는 이유 |
|---|---|
| hsv / 회전 / 스케일 / flip | 매 step random seed가 다름 → 같은 이미지가 매번 다른 색/각도/크기 |
mosaic (mosaic=0.5) |
50% 확률로 base 1장 + 추가 3장이 한 캔버스로 합쳐짐. 추가 3장은 manifest 13,741에서 random sample → 조합이 사실상 무한 |
mixup (mixup=0.1) |
두 이미지를 alpha blend. 같은 base가 매번 다른 partner와 섞임 |
| random crop / shear | 한 이미지의 다른 부분이 잘려 보임 |
특히 mosaic이 결정적이다. drone 한 장을 base로 뽑았을 때 mosaic 슬롯의 다른 3장 중 일부는 open dataset에서 옴. 즉 매 mosaic 캔버스가 drone-open 혼합 패턴이 되고, 모델이 두 분포가 섞인 입력을 학습하게 된다.
비유하면: 64장의 카드 + 7341장의 다른 카드가 한 덱에 있고, 매 라운드 4장을 콜라주로 합쳐 보여줌. drone 카드가 100번 들어있어 자주 base로 뽑히지만, 매 라운드의 시각 자극은 매번 unique.
| 지표 | 결과 |
|---|---|
| mAP50-95 | 0.281 → 0.286 (+0.005) |
| mAP50 | 0.574 → 0.650 (+0.076, 큰 도약) |
| 학습 안정성 | val_loss 분산이 눈에 띄게 줄어듦 |
| overfit 신호 | drone-only 학습 대비 약화 |
큰 도약은 mAP50에서 일어났고, mAP50-95 도약은 작았다. 이게 의미하는 것: open data 추가는 어떤 송이가 송이인지를 더 잘 알게 해주지만 (mAP50), 박스 위치 정확도(strict IoU)는 drone 라벨 품질이 더 결정적이다.
| 한계 | 설명 |
|---|---|
| Information ceiling | 64장 원본의 진짜 정보(다른 시기/각도/품종)는 늘어나지 않음. augment는 변형만 만듦 |
| ×N의 sweet spot | ×100이 직관적이지만 ×50/×200 비교를 명시적으로 한 적은 없음 |
| Test 분포가 train과 매우 다르면 | drone 64장과 test 29장이 같은 도메인이라 효과를 봤음. 더 다른 분포면 효과 작음 |
→ "drone × 50/×200 ablation"을 다음 시도 후보에 넣어둠.
왜 시도했나? YOLO 박스는 약간 loose하다. SAM3로 정확한 mask를 만들고 그 mask의 tight한 bounding rectangle로 박스를 다시 만들면 IoU가 올라갈 거라 기대.
왜 빗나갔나?
| 사실 | 결과 |
|---|---|
| SAM3 mask 품질 자체는 양호 (IoU 0.85) | OK |
| GT 박스가 사람이 그린 loose한 박스 | 문제 발생 |
| SAM3 tight 박스 ↔ GT loose 박스 매칭 시 IoU 손실 | recall ↑, mAP50-95 ↓ |
일반화할 수 있는 교훈:
후처리로 박스 정밀도를 올리는 건 GT 라벨 스타일과 호환될 때만 의미가 있다. GT가 loose하면 예측도 loose해야 점수가 잘 나온다. 이건 metric의 한계지 모델 품질의 한계가 아니다.
구성: S2 best 모델 1개를 base / TTA / SAHI 세 가지로 추론 후 Weighted Boxes Fusion.
왜 빗나갔나?
| 앙상블 효과 조건 | 우리 시도의 문제 |
|---|---|
| 서로 다른 결정 경계의 모델들 | 같은 모델의 inference variant는 결정 경계가 거의 같음 |
| TTA = 약간 다른 view, 같은 모델 | 추가 정보 거의 없음 |
| SAHI = sliced inference | 큰 객체에서 손해, 작은 객체에 약간 ↑ |
일반화할 수 있는 교훈:
앙상블을 시도하려면 서로 다른 architecture, 또는 적어도 다른 training schedule로 학습된 여러 모델이 있어야 한다. 같은 모델 inference variant 합치기는 효과가 작다.
왜 시도했나? yolo11은 신형 architecture 블록 (C3k2, C2PSA)을 도입. 동일 데이터/aug에서 모델만 바꿔서 architecture 효과를 측정.
결과: mAP50-95 0.286 → 0.257. 빗나감.
왜 빗나갔나? — training log를 보면 단서가 보임
| epoch | mAP50-95 | 관찰 |
|---|---|---|
| 1 | 0.310 ⭐ | 이 시점이 최고 |
| 2 | 0.248 | 급락 |
| 3 | 0.212 | 더 떨어짐 |
| ... | ... | 회복 시도 |
| 14 | 0.263 | 일부 회복 |
| 18 | 0.271 | early-stop 발동 |
이게 시사하는 것:
wgisd-pretrained weights에 이미 충분한 일반화가 있었고, mixed dataset으로 fine-tune이 모델을 다른 분포로 끌고 가버린 형태. 즉 "mixed data로 fine-tune이 항상 좋다"는 가정이 yolo11m에는 적용되지 않음.
왜 yolov8m에는 적용되고 yolo11m에는 안 됐나? (가설들)
| 가설 | 설명 |
|---|---|
| 1. learning rate 차이 | hyperparam이 yolov8m 기준. yolo11m에는 더 보수적인 schedule 필요 가능 |
| 2. patience 너무 짧음 | epoch 18 stop. 더 멀리 갔으면 회복했을지 확신 불가 |
| 3. architecture가 도메인에 약함 | C3k2/C2PSA가 일반 객체에 강해도, 1280px 드론의 작은 송이에는 다를 수 있음 |
다음 시도 (B1, B2)에서 검증할 것:
- B1 yolo11l: 더 큰 모델이면 회복하나? → capacity 부족이 원인이었는지 검증
- B2 imgsz 1536: 해상도가 결정적 축이면 yolo11m@1536 > yolo11m@1280 일 것
왜 시도했나? drone bbox 분포 분석 결과 norm area median 0.0016 (1280px 기준 ~50×80px). 작은 송이가 다수다. 입력 해상도를 ↑하면 작은 송이 detection이 회복될 거라 기대.
설정 변경:
| 항목 | Stage A | Stage B2 |
|---|---|---|
| 모델 | yolo11m | yolo11m (동일) |
| 데이터/aug | mixed (open ∪ drone×100) | 동일 |
| imgsz | 1280 | 1536 (↑) |
| BATCH | 8 | 4 (해상도↑로 메모리↑) |
| patience | 10 | 15 (Stage A 회고 반영, 더 길게) |
| epochs | 50 | 50 |
결과: mAP50-95 0.286 (S2 best) → 0.251. 또 빗나감. Stage A보다 더 떨어짐.
training log 관찰:
| epoch | mAP50-95 (val) | 해석 |
|---|---|---|
| 1 | 0.269 | 시작 |
| 5 | 0.301 | warmup 후 도달 |
| 10 | 0.303 ⭐ | val 최고점 |
| 13 | 0.303 | plateau |
| 25 | 0.280 (early-stop) | 하강 후 stop |
val 기준으로는 epoch 10 부근이 best였는데, test split 평가에서는 0.251. 이건 두 split 사이 분포가 다르거나, val 18장이 너무 적어 selection이 noisy하다는 신호.
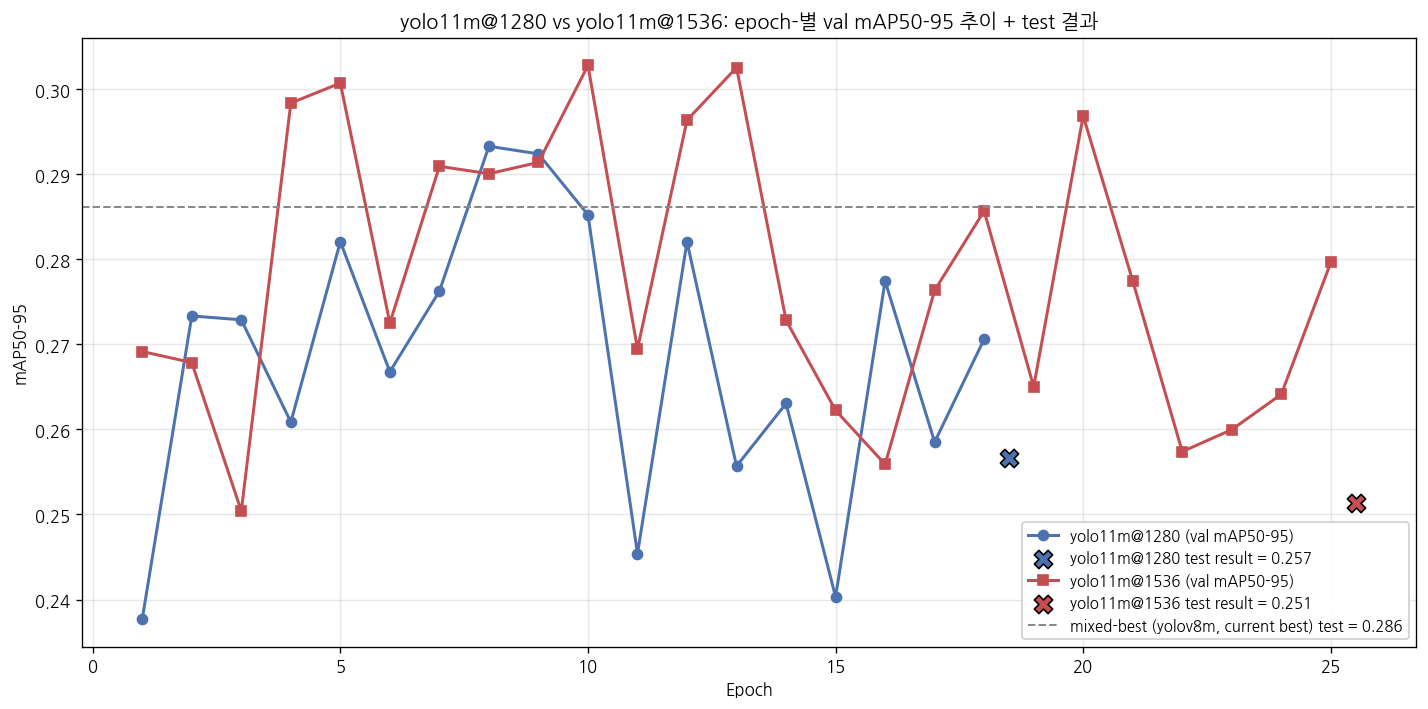 A (yolo11m@1280) 와 B2 (yolo11m@1536) 의 val mAP50-95 추이. 회색 점선 = mixed-best (S2) test 기준점. val 정점이 test에서 재현 안 됨
A (yolo11m@1280) 와 B2 (yolo11m@1536) 의 val mAP50-95 추이. 회색 점선 = mixed-best (S2) test 기준점. val 정점이 test에서 재현 안 됨
왜 빗나갔나? — 단순 "해상도 ↑"가 답이 아닌 이유
| 가설 | 근거 |
|---|---|
| 1. train/test 분포 미스매치 | val 18장에서 best였던 weights가 test 29장에서는 underperform. 두 split이 동질적이지 않음 |
| 2. 데이터 부족 + 큰 입력 | drone train 64장만 있는데 입력 해상도↑ → 모델이 과한 detail에 fit하면서 일반화 떨어짐 |
| 3. mosaic 효과 약화 | imgsz↑ + BATCH↓ (8→4) → 한 step에서 모델이 보는 이미지 수↓ → mosaic의 다양성 효과↓ |
| 4. Recall 급락 | P 0.668 → 0.718 (↑), R 0.493 → 0.399 (↓). 모델이 confident할 때만 예측 → 놓치는 송이↑ |
가장 의심스러운 건 3, 4번 조합. 해상도가 크면 한 송이가 더 많은 픽셀로 보여 confident detection은 늘지만, batch가 줄어 학습 다양성이 떨어지면서 robust한 recall은 떨어지는 trade-off.
| 시도 | 변경 축 | mAP50-95 변화 | 결론 |
|---|---|---|---|
| Stage A | 모델 architecture (yolov8m → yolo11m) | -0.029 | 신형이 우리 도메인에 약함 |
| Stage B2 | 입력 해상도 (1280 → 1536) | -0.035 | 해상도↑가 효과 없음 |
| 공통 | — | — | 모델/입력 축은 막혔다 |
현재 가설: drone 64장의 정보량이 진짜 ceiling. 모델/해상도 같은 "표현력 ↑" 축은 데이터가 받쳐주지 않으면 오히려 overfit/noise. 의미 있는 다음 도약은:
- 데이터 측면: drone 데이터를 더 라벨링 (현실적이지만 비용 큼) 또는 oversample 비율 sweep (×50/×200)
- 라벨 형식: OBB(rotated detection)로 박스 정보를 더 활용
- 학습 schedule: epochs↑ + patience↑로 yolo11m이 더 멀리 가는지 확인 (가능성 낮음)
Stage B1 (yolo11l) 재평가:
A/B2 패턴이 "더 큰 모델/해상도 = 음수"라면, B1 (yolo11l, 더 큰 모델)도 같은 결과 가능성 높음. 하지만 변천사 완성 + 가설의 명확한 반증을 위해 한 번은 돌릴 가치 있음. 음수 결과도 데이터다.
| # | 결정 | 왜 좋았나 |
|---|---|---|
| 1 | 결과물 인벤토리 먼저 | "재학습 필요한 것"과 "이미 결과 있는 것"을 분리해 시간 절약 |
| 2 | 한 번에 한 축만 변경 | Stage A/B1/B2가 model arch / capacity / resolution 직교라 결과 해석 깔끔 |
| 3 | 변천사 자동 수집 스크립트 | 손으로 표 옮기지 않고 코드가 모든 metric 자동 수집 |
| 4 | 안전 영역에서 시작해 부하 점진 증가 | OOM/시스템 다운의 손실 >> 보수적 시작의 비용 |
| # | 결정 | 무엇이 잘못됐나 |
|---|---|---|
| 1 | batch를 한 번에 16까지 키움 | 시스템 한계점 초과 → 학습 도중 시스템 다운. 8 → 12 → 16 단계적이 맞았음 |
| 2 | yolo11m에 yolov8m과 같은 patience 사용 | 새 모델은 다른 학습 곡선. patience를 더 길게 두고 곡선 보고 결정했어야 (B2에서는 patience=15로 반영) |
| 3 | S2-aux SAM3 refine 결과 분석에 시간을 덜 썼음 | "라벨 스타일 호환성" 문제를 더 빨리 알았다면 비슷한 후처리 시도 반복 안 해도 됐음 |
| 4 | A/B2 모두 "더 키우기" 축이라 과적합 위험 동시에 부담 | 모델 capacity↑(A)와 입력 해상도↑(B2)가 둘 다 train data 64장이 받쳐주지 않으면 효과 없음. 한쪽이 빗나간 시점에 다른 쪽 가설을 재검토했어야 |
다음에 비슷한 종류의 detection 실험을 처음부터 설계한다면 — 자기 자신을 위한 체크리스트로 정리.
| # | 항목 | 안 하면 발생하는 일 |
|---|---|---|
| 1 | 인벤토리 먼저 | 이미 있는 결과 다시 돌려서 시간 낭비 |
| 2 | base/control 정하기 | 이후 비교가 의미 없어짐 |
| 3 | 변경 축은 한 번에 하나만 | 효과의 원인 분리 불가 |
| 4 | 결과 정리는 코드로 자동화 | 손으로 옮기다 누락 발생 |
| 5 | 자원 보수적 시작 → 실측 후 키움 | 한계 못 본 채 큰 부하 → 시스템 다운 |
| 6 | 죽지 않을 범위에서 빠르게 | 학습 1회 손실 >> 보수적 시작 비용 |
| 7 | 각 단계 한 줄 해석 남김 | 변천사가 데이터 모음으로 전락 |
| 8 | 실패한 시도도 기록 | 다음에 같은 시도 반복 |
| 후보 | 변경 축 | 가설 | 우선순위 |
|---|---|---|---|
| yolo11l (B1) | capacity ↑ | 더 큰 모델로 추가 capacity 활용 | 중간 (A/B2가 음수였지만 변천사 완성을 위해 한 번은 돌려봄) |
|
|
|||
| drone oversample ×50 / ×200 | data sampling 비율 | A/B2 음수 결과 → 데이터 축이 더 효과적일 가능성. ×100이 최적인지 ablation | 높음 (다음 우선) |
| drone 데이터 추가 라벨링 | data 절대량 ↑ | 64장 → 128장 등. 정보 ceiling 자체를 올림 | 높음 (현실적이면) |
| OBB (rotated) | 라벨 형식 | 송이의 63%가 세로 길쭉, OBB tight fit | 중간 (라벨 변환 비용) |
| epochs 100 + patience 20 | 학습 시간 ↑ | yolo11m이 더 멀리 가면 회복할까 | 낮음 (B2의 patience=15에서도 회복 못 함, 가능성 작음) |
| RT-DETR | architecture family | CNN과 다른 inductive bias로 일반화 검증 | 낮음 (model 축이 막힌 상황에서 추가 model 시도 우선순위↓) |
위 "다음 시도 후보"의 데이터 축 (oversample sweep, fair chain w/ wgisd 사전학습) 모두 진행한 결과 → detection axis 전부 plateau 확정 (mAP50-95 ≈ 0.286 ± 0.008, noise 수준). 미세 튜닝 시도 종료.
대신 새 axis (segmentation → 면적 → 무게 회귀) 로 전환해 수확량 예측 파이프라인 구축으로 넘어감.
| 모델 | mAP50-95 | mixed-best 대비 |
|---|---|---|
| yolov8m mixed-best (이 문서 S2) | 0.286 | baseline |
| yolo11m fair-chain (wgisd→mixed) | 0.291 | +0.005 (noise) |
| yolo11l fair-chain | 0.284 | −0.002 |
| yolo26m fair-chain | 0.283 | −0.003 |
→ 4 모델 모두 0.286 ± 0.008 안에 수렴. architecture / capacity axis는 도약 가능성 없음 공식 확인.
| 주제 | 위치 |
|---|---|
| 수확량 예측 파이프라인 구축 (segmentation, GSD, 합성, end-to-end) | 드론 포도 수확량 예측 — 파이프라인 (2026-05) |
후속 문서 핵심 내용:
- Detection plateau 후 axis 전환 의사결정
- YOLO + SAM3 mask 파이프라인 + 4단계 overlap 후처리
- 기둥/와이어 reference로 GSD calibration
- 합성 vineyard 데이터 (copy-paste vs diffusion 비교)
- 도메인별 detector winner 차이 (드론 top-down vs 측면 시점)
| 주제 | 위치 |
|---|---|
| 전체 프로젝트 컨텍스트 | 포도밭 병해충 탐지 및 수확량 예측 |
| 데이터셋 출처와 구성 | 포도 탐지를 위한 데이터 수집 |
| 이전 YOLO 계열 baseline 비교 흐름 | YOLO Model Comparison Summary |
| YOLO baseline 모델 selection 근거 | YOLO Baseline Top3 비교 요약 |
| 다른 detector family와의 비교 | Grounding DINO vs YOLO Top3 비교 요약 |
| SAM3 vs YOLO 정량 비교 (S2-aux SAM3 refine 단락의 출발점) | SAM3 vs Fine-tuned YOLO on Drone Imagery |
| 후속 — 수확량 예측 파이프라인 | Drone Yield Prediction Pipeline 2026-05 |
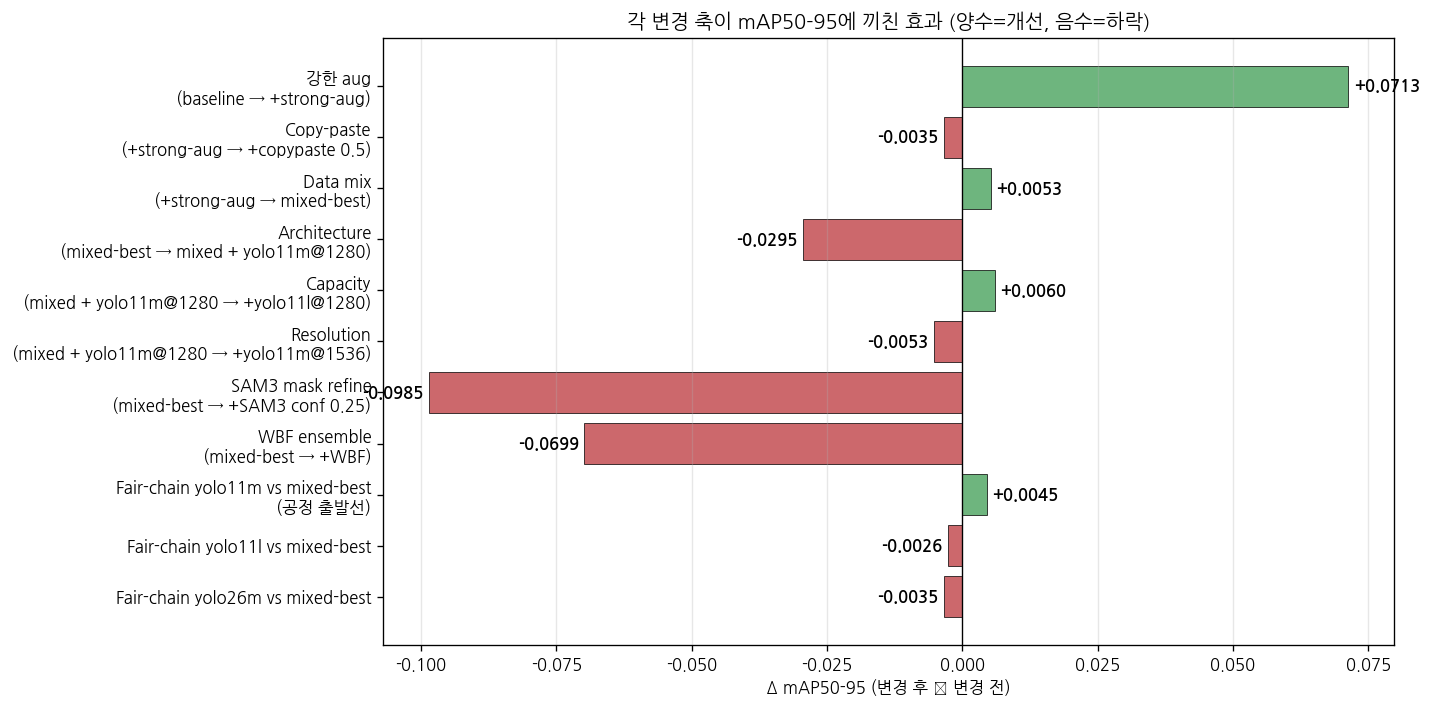 양수 = 개선, 음수 = 하락. 강한 aug (+0.07) 이 가장 큰 단일 도약, SAM3 mask refine 과 architecture/resolution↑ 변경은 모두 음수
양수 = 개선, 음수 = 하락. 강한 aug (+0.07) 이 가장 큰 단일 도약, SAM3 mask refine 과 architecture/resolution↑ 변경은 모두 음수
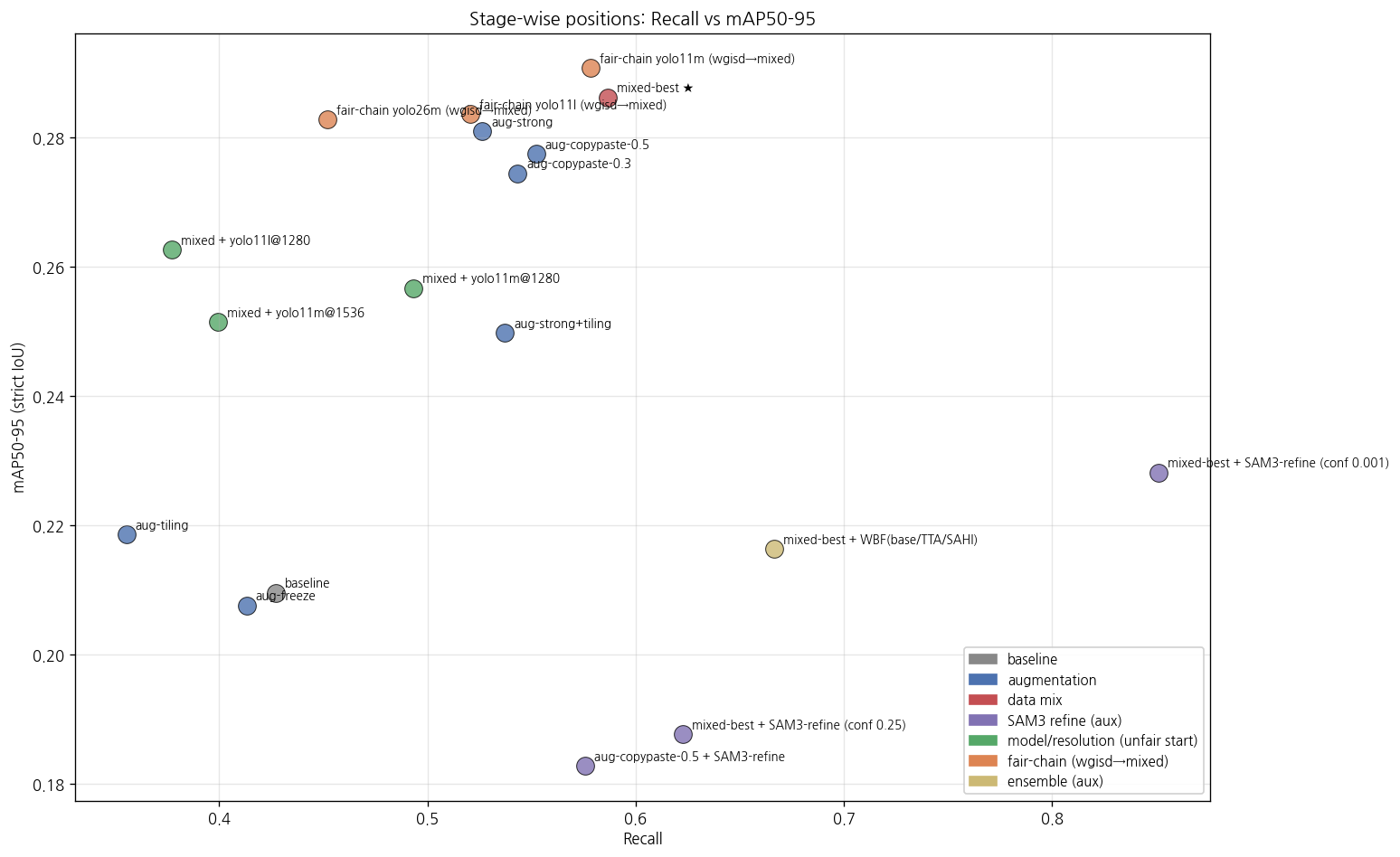 그룹별 색상으로 각 Stage 위치 표시. mixed-best (data mix) 가 우측 상단 (high R, high mAP)
그룹별 색상으로 각 Stage 위치 표시. mixed-best (data mix) 가 우측 상단 (high R, high mAP)