Vineyard Wildlife RPi Runtime Comparison
학습된 YOLO11n 모델을 라즈베리파이 4에서 돌리려고 했을 때 가장 먼저 부딪힌 질문은 "무엇으로 추론하지?" 였습니다.
데스크톱에서는 그냥 PyTorch로 돌리면 끝나지만, ARM CPU-only 환경에서는 백엔드마다 속도·정확도·생태계 성숙도가 천차만별이었습니다. 이 문서는 RPi 4에서 직접 측정한 백엔드 비교를 정리합니다.
| 백엔드 | RPi 4 가능 여부 | 이유 |
|---|---|---|
torch CPU .pt
|
가능 | ultralytics 기본 백엔드, 가장 단순 |
| onnxruntime CPU FP32 | 가능 | ARM NEON 활용, ARM 생태계 표준 |
| ncnn FP16 | 가능 | Tencent의 ARM-최적화 추론 런타임 |
| onnxruntime CPU INT8 | 가능 | 양자화 후 속도 향상 기대 |
| TensorRT | 불가 | NVIDIA GPU 전용, RPi와 무관 |
| TFLite INT8 | 불가 | tflite-runtime이 RPi Python 3.13 wheel 미제공 |
| OpenVINO | 후보에서 제외 | Intel CPU 가속용 라이브러리, ARM에서 큰 이득 없음 |
ARM에서 진짜 후보는 torch / onnxruntime / ncnn 3개로 좁혀졌습니다.
- 디바이스: Raspberry Pi 4 Model B, Cortex-A72 4코어 @ 1.8GHz, 4GB RAM
- OS: Raspberry Pi OS 64-bit
- Python: 3.13
- 모델: yolo11n multi-class (5종)
- test split 전체 이미지 기준 mAP / 단일 이미지 추론 시간
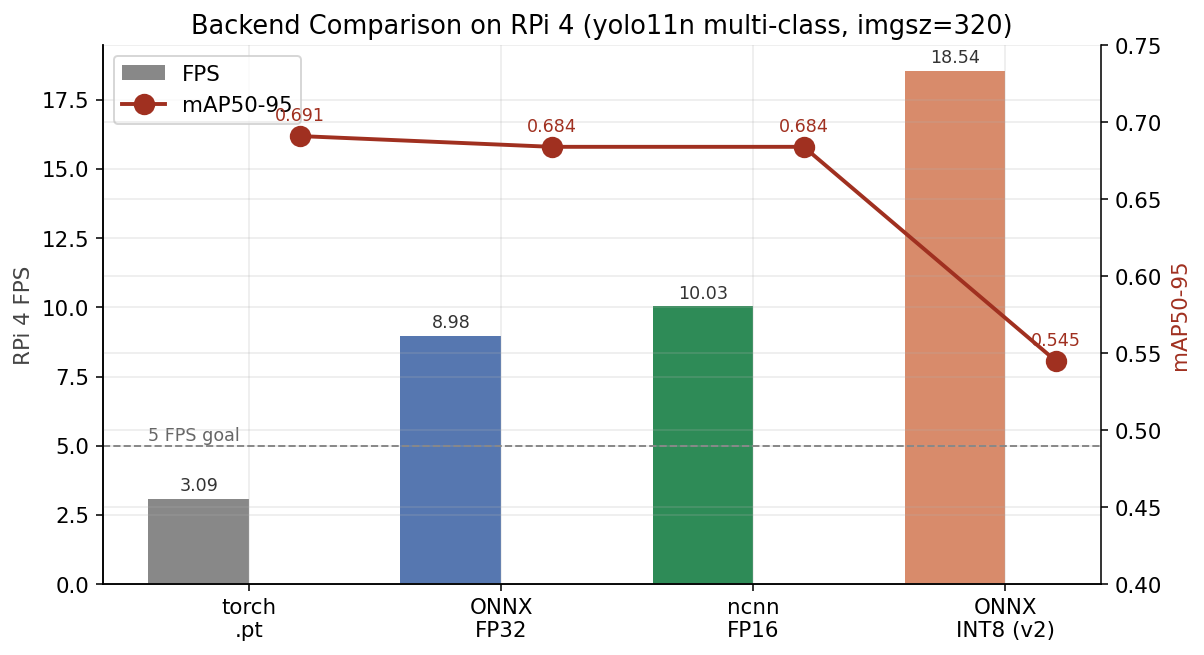
| 백엔드 | FPS | mAP50-95 | 모델 크기 | 비고 |
|---|---|---|---|---|
torch CPU .pt
|
3.09 | 0.691 | 5.4 MB | 베이스라인 |
| onnxruntime CPU FP32 | 8.98 | 0.684 | 10.6 MB | torch 대비 약 2.9× |
| ncnn FP16 | 10.03 | 0.684 | 5.1 MB | torch 대비 약 3.2×, 가장 작음 |
| onnxruntime CPU INT8 | 18.54 | 0.473 | 약 3 MB | 정확도 -31%p로 망가짐 |
| 백엔드 | FPS | mAP50-95 | 비고 |
|---|---|---|---|
torch CPU .pt
|
약 0.7 | 0.792 | 너무 느림 |
| onnxruntime CPU FP32 | 약 2.0 | 0.787 | — |
| ncnn FP16 | 2.34 | 0.787 | 가장 빠름 |
| onnxruntime CPU INT8 | 약 5.x | 0.000 | detection 0건, 완전 실패 |
ncnn은 ARM NEON 최적화 + 모바일 비전 사용 사례에 맞게 설계된 라이브러리라 우리 환경에 정확히 맞았습니다. 정확도 손실은 0%인데 속도는 torch 대비 3배 이상.
onnxruntime도 ARM NEON을 쓰지만, ncnn 쪽이 모바일/임베디드 케이스에 더 튜닝되어 있는 것으로 보였습니다. 다만 onnxruntime은 디버깅·생태계가 더 풍부해서, ncnn에 문제가 생기면 fallback으로 좋은 위치입니다.
INT8 결과는 따로 INT8 양자화 진단에 정리했습니다. 짧게는: 큰 imgsz에서 onnxruntime ARM EP의 INT8 처리 한계로 정확도가 무너집니다.
TFLite는 RPi Python 3.13 wheel이 없고, OpenVINO는 Intel 전용이라 ARM에서 의미가 없었습니다. 가능성 후보로 보였지만 실제로는 빠르게 제거됐습니다.
처음에는 RPi에서 직접 ONNX → ncnn 변환과 INT8 calibration을 돌렸습니다. 그런데 calibration 도중 OOM 의심 재부팅이 발생했고, ONNX·ncnn은 portable 포맷이라 어디서 변환하든 결과가 동일 하다는 점이 보였습니다.
현재는:
- Dev 머신 (64GB RAM, GPU 2장): 학습 + ONNX 변환 + INT8 calibration
- RPi 4: 추론 실행만
이 분리가 안정성·속도 모두에서 압도적으로 나았습니다.
모델 정확도 향상보다 백엔드 선택의 영향이 더 컸습니다. torch에서 ncnn으로 바꾼 것만으로 FPS가 3배.
같은 모델·같은 디바이스인데 백엔드만 바꿔도 FPS와 정확도가 다르고, 어떤 옵션은 큰 imgsz에서 아예 망가집니다. 백엔드별 실측이 의사결정의 출발점.
양자화·변환의 OOM·발열·재부팅 위험은 엣지에서 감수할 이유가 없습니다. portable한 산출물의 장점을 적극 활용하는 게 자연스럽습니다.
- INT8 양자화 진단 — INT8이 왜 망가졌는지
- 야생동물 5종 multi-class 학습 변천사 — 비교에 사용한 모델의 학습 과정
- 카메라 실시간 검출 MVP — ncnn FP16 320을 실제 카메라에 붙인 결과