03_architecture
The overall goal of the MOSIM project is to realistically simulate complex human motions in the context of different use-cases. In academia and on the market, up to now, only isolated digital human simulation approaches are available. For instance, individual tools can already address the simulation of setup paths or ergonomic validation. However a comprehensive simulation of manual assembly scenarios comprising heterogeneous activities is not possible yet. Nonetheless, given the available tools and motion synthesis approaches, most of the requested simulation capabilities are already available. A major hurdle for combining the available technologies is the lacking availability of source code and expertise and uneconomically high porting effort. To allow the open and efficient utilization of these technologies and tools for a comprehensive simulation and benchmarking, the MOSIM projects targets to provide an open standard for connecting heterogeneous digital human simulation approaches in a common framework. In particular, the efforts for incorporation and implementation should be minimized, whereas the major programming languages and platforms shall be supported. Ultimately, the MOSIM framework enables the end-user to combine the best motion synthesis approaches available. Given the MOSIM framework, a new value chain comprising different roles is generated. In particular, vendors of simulation software can sell comprehensive simulation environments. Moreover, a new business for selling digital human simulation approaches in a modular way is created. For exchanging simulation functionality in a different domain than motions, a widely used solution named Functional Mock-up Interface (FMI) is already available. The proposed MOSIM framework is strongly inspired by the FMI approach. The Functional Mock-up Interface is a standard that supports the exchange of dynamic simulation models as well as its co-simulation while being tool independent. This standard is based on a combination of xml-files and compiled C-code [1]. An instance of an FMI component is called a Functional Mock-up Unit (FMU). By using the FMI standard, it is possible to perform a simulation of different FMUs, containing appropriate solvers, whereas only the simulation results of the FMUs are exchanged after defined time steps. This approach is called FMI for co-simulation [2]. The concept of modular motion units as derived in the MOSIM project, which is also referred as Motion Model Interface (MMI) approach, builds upon the idea of the FMI concept to further extend the standard to simulate human motion. Orchestrating various sub-simulations as intended by the FMI or MMI approach requires a superior instance managing the distributed sub-systems. In general, this orchestration process is named co-simulation, whereas the co-simulator updates the components and incorporates the results. Recently, in literature various co-simulation approaches for the FMI standard have been proposed ([3] [4] [5]), however, these systems predominantly focus on signal flow modeling mainly in the mechatronic domain. Since the co-simulation of digital human simulation systems has entirely different requirements, these solutions cannot be directly used. To implement the aforementioned aspects, a standardized framework satisfying the heterogeneous requirements of the digital human simulation approaches, co-simulation, behavior modeling and use-cases is required. The document is structured as follows: Section 2 proposes the overall concept of the MOSIM framework, depicting the main concepts and components. In section 3, the proposed technical architecture is presented in detail. In particular, in section 3.1 the main technical framework and the components are revisited. Section 3.2 focuses and the description of the respective formats and data structures by means of class diagrams. Section 3.3 explains the overall process and workflow of the framework. Section 4 gives a conclusion and summary of the presented framework. Moreover, in the appendix additional example files are provided.
Strongly inspired by the FMI approach, a new concept for combining heterogeneous digital human simulation approach is developed in the MOSIM project. Based on the FMI approach, a concept for exchanging character animation systems is introduced in [6], [7]. With the FMI standard, complex systems like industrial machines can be simulated using specialized approaches such as solvers of pneumatic cylinders or kinematic models. The respective sub-simulations are embedded within standardized modules (FMUs) [2]. A co-simulator sequences several of these co-simulations. This component communicates with the FMUs at discrete points in time and incorporates the computed results of all heterogeneous approaches in a common simulation. Transferring this concept to the domain of character animation, so called Motion Model Interfaces (MMIs) and their implementations called Motion Model Units (MMUs) are presented which allow incorporating diverse character animation approaches into a common framework. Figure 1 shows the main idea of the novel MOSIM approach. In the following, the overall framework is also referred as MMI framework.
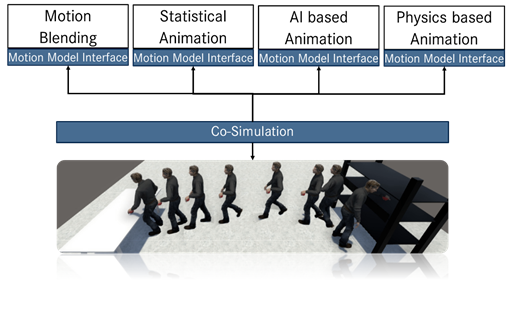
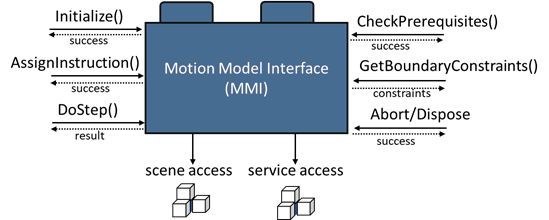
The proposed MMUs are an essential part of this modular concept and provide the basic interface for encapsulating different character animation systems and technologies (see Figure 1 top). These units contain the actual animation approach, being implemented in the required platform and programming language. For instance, an actual MMU can comprise a data-driven algorithm implemented in Python, as well as model-based approaches realized in C++. By utilizing a common interface, and inter-process communication, the MMUs can be accessed independent of the platform. Thus, the communication and workflow are only driven by the functionality provided by the interface and not by the specific environments. Figure 2 gives an overview of the provided key functionality of the interface. The individual MMUs are responsible for generating specific kinds of motion (e.g. locomotion behavior or grasp modeling). Each MMU provides the functionality to set the intended motion instruction, as well as evaluating prerequisites and getting boundary constraints for executing the motion. Moreover, the MMUs comprise a DoStep routine that is executed for each frame to be simulated. In this context, the actual posture at the given frame is computed by the specific technology. For each frame, the MMU provides output parameters describing the generated posture, its constraints, as well as intended scene manipulations and events. Since most motion generation approaches strongly rely on spatial information of the environment and the digital human representation, the communication with the scene is an important aspect for realizing such an encapsulation. Thus, each MMU can access the information provided by the scene through a defined interface (see Figure 2 scene access). In this way, the actual scene representation can be embedded in diverse target environments. Considering the concurrency between different MMUs, manipulations of the scene, which are intended by the MMUs, are not directly written back to the scene; instead, these are provided as an output of the simulation step and are furthermore processed by a superior instance. Even though the MMU implementations of different motion types such as grasping or walking might be different in terms of the underlying technique and algorithms, frequently, the MMUs utilize similar functionalities such as computing inverse kinematics or planning a path. For this reason, each MMU can additionally access a set of predefined services such as inverse kinematics, retargeting and path planning (see Figure 2 service access).
Relevant Interface Definitions: *
Having distinct MMUs comprising specific simulation approaches, the separately generated postures must be merged and further processed to obtain natural motions. Therefore, a co-simulator is required, which orchestrates the actual execution of the MMUs. In this context, the component merges and overlaps the motions, while considering the constraints of the postures. Figure 3 provides an overview of the general input and output of a co-simulation. Generally, the input of the co-simulation is a list of different tasks (e.g., walk to, grasp object) with temporal dependencies. The output of the co-simulation is a feasible motion representing the specified tasks.

Since the scope of the framework is to incorporate strongly heterogeneous character animation systems, the individual MMUs might comprise entirely different skeleton structures and anthropometries. To utilize these heterogeneous results in a common platform, a retargeting to a global reference skeleton is required for each MMU. Moreover, since two consecutive MMUs might start/end with a different posture (e.g., MMU1 ends with t-Pose, MMU2 starts with idle pose), the transition between the respective units must be explicitly modeled. Another essential aspect of the co-simulation is to preserve the constraints and characteristics of the original motions/ postures (e.g., Grasp MMU1 requires the hand to be at a specific location). One possibility to handle the different MMUs is to sequentially execute them. However, examining humanoid motion, it can be encountered that most of the performed motions are commonly executed in parallel. Therefore, one important task of the co-simulation is to overlap and merge different motions generated by the MMUs. In [8], a first concept of a co-simulation for digital human simulation was presented. Within the MOSIM project, different concepts and variations of possible co-simulation approaches will be investigated. The co-simulation interface proposed in this document forms the base for the future implementations and investigations.
Relevant Interface Definitions: *
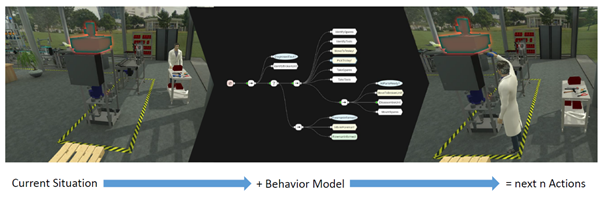
In order for the co-simulator to be able to merge different motions, in the first place, it requires a sequence of instructions or MMUs to be executed as input. Which motions or granular tasks an avatar has to execute depends on two factors: on the one hand on the task definition to be simulated and on the other hand on the current state of the avatar and/or the simulated environment. Depending on these factors, there must be a mechanism that considers both together and then reasons which granular task to execute. In the MOSIM project, the Behavior Modeling & Execution unit is responsible for this reasoning task. It acts on a semantic level in which higher-level actions or behaviors are executed and thus serves as a mediator between the co-simulator and the holistic scenario to be simulated. Task descriptions defined purely as sequences have the restriction that alternative activities cannot be represented. If a dynamic environment is to be considered in which not only the avatar to be simulated interacts with the environment, but also other autonomous entities are contained or if there are different ways to perform such higher-level actions, an approach is required which allows mapping of alternative context-dependent activities. In order for an entity to be able to make decisions independently and to be able to carry out context-dependent actions, a kind of knowledge representation is required in addition to a behavior model, via which it can determine the current entity state. In addition to the current state of the simulated character and its environment, constraints for the selection or execution of given MMUs or actions must also be available for the Behavior Modeling & Execution unit. After a context-dependent action has been executed, its result is also required. This result is received either via an update of the scene state or from the co-simulator if the passed sequence fails. Furthermore, it must be easy for a developer to model a behavior or to adapt it to a considered task description to be able to run through different scenarios as quickly and intuitively as possible. The Behavior Tree (BT) paradigm is a graphical programing language, which combines Decision Trees with Finite State Machines and has its roots in the gaming industry. BTs are also used extensively in robotics to realize autonomous and goal-driven entities that decide reactively which actions are to be performed depending on their current situation. Figure 4 shows for example a Reasoning Cycle with a BT controlled and simulated worker. In the first step, the current situation of the worker is perceived and then evaluated with a BT. The next action is derived and executed, resulting in a new situation.
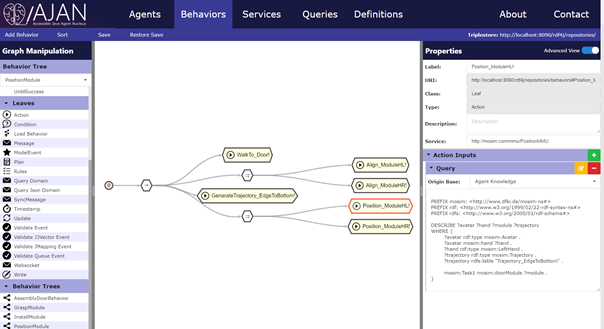
The BT paradigm is often used in combination with a blackboard that stores the current entity state. BTs can also be event-based or executed with a game tick and are suitable for describing parallel actions, fulfilling a primary criterion for selecting a behavioral model in MOSIM. However, they only carry out the actions that are valid in the current situation. A generation of a list with possible future actions, as required by the co-simulator, is not yet possible with common implementations and would have to be developed in MOSIM. In the MOSIM project BTs are supposed to be used as an executable behavior model. The agent system AJAN developed at DFKI, was suggested as a possible implementation of the Behavior Modeling & Execution unit. In [9] and [10] the framework was used for the control of simulated workers in an assembly line production. AJAN is a multi-agent system, which is implemented as a web service and uses BTs extended with SPARQL queries and RDF-Triple Stores as knowledge base. Furthermore, it is equipped with a graphical editor (see Figure 5) to model and manage agents with such BTs.
Relevant Interface Definitions: *