Designing Distributed Systems
Once upon a time, people wrote programs that ran on one machine and were also accessed from that machine. The world has changed.
Materials: https://github.com/brendandburns/designing-distributed-systems
- Distributed systems allow for apps to be always-available, and able to scale instantly
- DS are more reliable because there's no longer 1-2 single points of failure, but they are complicated to build and debug
- Distributed systems are "applications made up of many different components running on many different machines."
- The goal of containers:
- draw boundaries around resources (this needs 2 cores and 16 GB of memory)
- establish team ownership of the container
- separation of concerns/UNIX philosophy: do one thing and do it well
- A good place to start building DS is to have multiple containers on one node.
- A sidecar enhances the functionality of the app it sits next to. It either enhances or extends the app.
- Examples:
- topz sidecar: shows the output of the
topcommand in the browser - Transforming an old application from http to https; adding HTTPS to a legacy service
- istio: enabling MTLS, the envoy proxy
- topz sidecar: shows the output of the
- A sidecar is like a case for a computer. It only fits on a certain type of computer, and provides an extra layer of security. It doesn’t do much on it’s own, though.
- The Sidecar pattern in Kubernetes
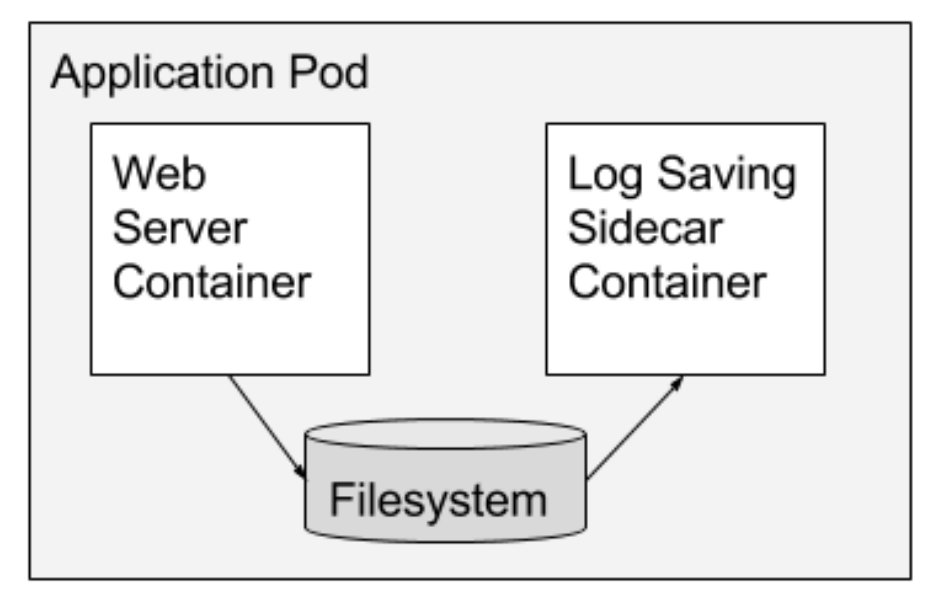
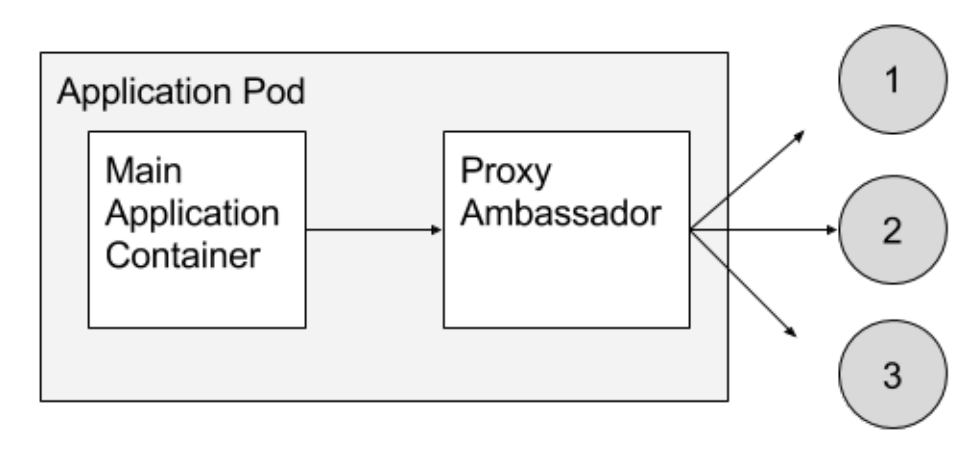
- The ambassador container handles interactions between the application container and everything else.
- Examples:
- Client-side sharding a service
- splitting up requests so that they go to different redis shards. The ambassador is twoemproxy.
- https://github.com/brendandburns/designing-distributed-systems/tree/master/ambassadors
- Service Brokering
- Request splitting
- Circuit-breaking
- Istio does this for a lot of things. Canary builds, blue/green deployments, service discovery
- Client-side sharding a service
- Istio does this for a lot of things. Canary builds, blue/green deployments, service discovery
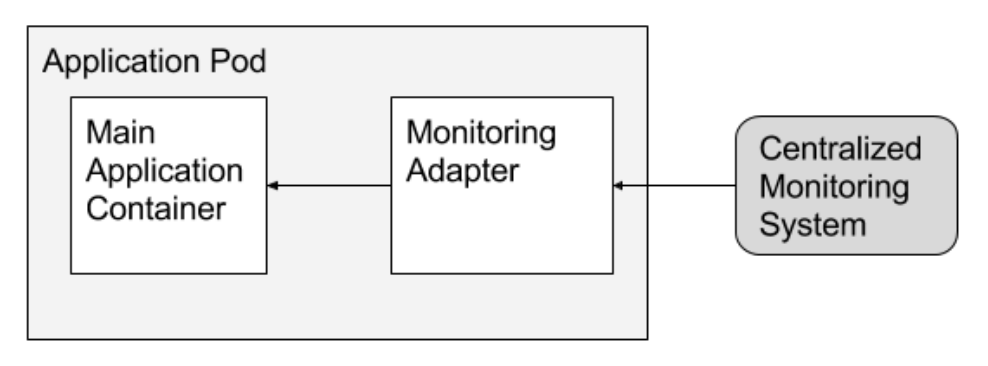
- The adapter container makes changes to the main container’s output so it is standardized. Usually used for monitoring and logging purposes.
- Examples:
- An adapter is like a trash compactor. It takes a variety of inputs, but the output is always the same size and shape.
- In order to have a highly-available service (99.9% availability), you must have at least two replicas
- Horizontal scaling means that new replicas are created as more requests are sent to the service. The replicas as the same size and shape as the originals.
- Load balancing enables service replicas, and horizontal scaling
- A readiness probe lets a load balancer know when an app is ready to serve requests
- You will need to include a special URL that the readiness probe can touch
- A service can be alive, but not ready.
- When you need to map a user's request to a specific machine (there may be caching)
-
Generally speaking, this session tracking is performed by hashing the source and destination IP addresses and using that key to identify the server that should service the requests. So long as the source and destination IP addresses remain constant, all requests are sent to the same replica.
- A caching web proxy is a server that saves already-requested responses and sends them to users so that the server doesn't handle all those requests
- Actions depend on cache hits, cache misses and cache backfills
- In the book, Varnish is the open-source project used to demonstrate web caching
- Benefits of an HTTP reverse proxy:
- Rate limiting
- Varnish has a
throttleplugin - http response code
429means too many requests -
X-RateLimit-Remainingcan be put in a header, and tells the developer how many requests they have remaining
- Varnish has a
- SSL Termination
- SSL enables HTTPS. Termination means switching from HTTPS to HTTP.
- nginx can do this, varnish cannot
- in the example, nginx does SSL termination, hands requests to varnish which does its reverse-proxy thing
- Rate limiting
- How do you scale the process of assignment?
- If you want highly-available services, you must have a distributed system that assigns ownership
- The easiest way is to establish ownership is by only having one instance, AKA a singleton. A singleton in Kubernetes has pretty good uptime because the container will be restarted if killed, and it will be moved to another machine if the node fails.
Two ways of applying master elections:
- Distributed Consensus Algorithms: Paxos and RAFT
- Use a key-value store that already has a DCA. Examples: etcd, Zookeeper and consul.
- "compare-and-swap operation for a particular key" (not sure what that means)
- Locks are a way to establish temporary ownership
- The most straight-forward lock is the mutual exclusion lock (Mutex)
-
A lock allows only one thread to enter the part that's locked and the lock is not shared with any other processes.
-
A mutex is the same as a lock but it can be system wide (shared by multiple processes).
- In a distributed system, you can lock a key-value store with a mutex.
- Steps:
- Acquire the lock
- (if needed) If the lock doesn't exist, claim a lock.
- When you're done, unlock
- In a distributed system, the process could fail while holding a lock. If there's no way to unlock, you're in trouble. The solution is TTL functionality to locks.
- In etcd: "Keys in etcd can be set to expire after a specified number of seconds. You can do this by setting a TTL (time to live) on the key when sending a PUT request:"
curl http://127.0.0.1:2379/v2/keys/foo -XPUT -d value=bar -d ttl=5 - TTL = Time to Live
- You need to ensure that only one lock holder is allowed at a time.
- Long-term ownership requires a renewable lock
- Leases in etcd:
How does this work when rolling K8s master nodes?
Steps:
- Create a Custom Resource Definition for the etcd operator
- Create a service account, role and role-binding
- Create the etcd operator deployment
- Create the etcd cluster custom resource
- Install the etcd client