Parallel Framework
SimMobility features a robust, relatively novel approach to massive scalability that is designed to take advantage of the processing power of modern hardware. The majority of computations performed by SimMobility are done by Agents in their update() functions. Agents with a similar update frequency are grouped into the same WorkGroup, wherein they are distributed among a number of Workers. This structure enables a number of optimizations in parallel processing, discussed later.
The diagram below depicts the idea of WorkGroups, Workers and agents within the workers.

Agents can generally remain ignorant of the Worker they are assigned to. They can communicate with other Agents on any other Worker thread through the use of Shared<> variables or the message bus, which are described in detail later.
As mentioned previously, SimMobility achieves parallelism by packing Agents into Worker threads and then running through each Worker's list of agents in parallel. An agent is added to a Worker automatically based on its startTime, and is removed and deleted if it returns UpdateStatus::RS_DONE at the end of its update tick. Agents can also move between Workers in the same WorkGroup using mechanisms which are relatively straightforward.
To enforce time synchronization, each worker, after processing all its agents for the given time step, waits for all other threads to complete. No worker can proceed to the next time step before all workers have finished for the current time step. After all workers finish the processing of a time step, they can start together the processing of the next.
Given this design, the main concern with Workers is communication. Specifically: how do Agents on different Workers communicate with each other in an error-free, repeatable and performant way?
The typical intuition to use locking (mutex-based) communication has some potential pitfalls. First, it limits the repeatability of the simulation. If Agents [0..100] are reading a value that Agent 50 is updating during that time tick, then both the update order of the Agents and the inherent parallelism of the system will ensure that not every Agent sees the updated value. This can introduce a large amount of nondeterminism into the system without any practical way of dealing with it. Second, locking can lead to poor performance on many-cored systems, especially in traffic simulation with its high degree of inter-agent data dependency. As the number of discrete processing units on a system increases, this becomes more of a problem.
SimMobility solves this problem in three ways:
- buffered variables
- messaging system
- events
Instead of locking, SimMobility uses buffering to handle inter-agent communication wherever feasible. A typical shared variable is defined for an agent using the syntax Shared<int> x;. Shared variables must only be updated (using x.set(<value>)) by one agent in one time tick, but can be read by any number of Agents simultaneously (using x.get()). After each time tick, all Shared variables are set to the value that they were assigned in .set() of that time tick. Thus, if one of these variables is updated during a certain time step, every read operation on it will return the non-updated value. The updated value will be available only starting from the next time step, i.e., after the .set() function of the current time step has run. In other words, Shared<> variables are always one time tick delayed, but they introduce no additional cost in terms of synchronization.
Note, also, that an Agent's Shared<> variables must be announced to the system in the function Agent::buildSubscriptionList(); see the code and inline comments for more explanation. Agents can modify the subscription list using the variables toAdd and toRemove inside the class UpdateStatus (which is returned by Agent::update()).
WorkGroups can exist at different granularities. For example, the “Person” work group (for Drivers, Pedestrians, and other general Agents) can tick every 100ms, while the “Signal” work group ticks every 1s. In terms of interacting time granularities, the Shared<> variables inside the Signal class are updated 100ms after they are set ― not 1s later. This allows Drivers to interact with Signals at the highest time resolution,
without adding needless busy-waiting on the part of the Signal. Note that, due to the way interacting time granularities work, two Signals will see each others' Shared<> variables update at a 1s interval, even though the update effectively happens after only 100ms.
In some cases, immediate interaction between agents may not be necessary. The messages can be asynchronous without any impacts. SimMobility has an in-built asynchronous messaging system that can help in such scenarios. All agents are registered as message handlers. Therefore, any agent can send any notification with a message payload to any other agent irrespective of which worker they belong to.
The messaging system, known as the Message Bus, works closely with the worker threads. Each worker consists of an input queue and an output queue. The diagram below shows the components of the message bus.
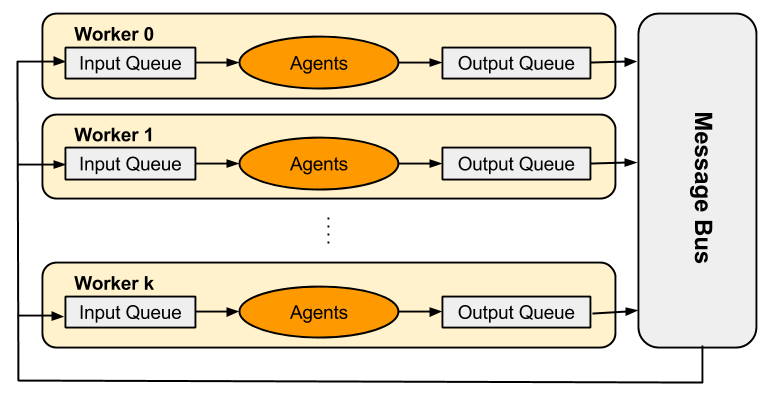
When an agent sends a message to another agent, the message is dropped in the output queue of the sender's worker right away. At the end of the time step, before proceeding to the next time step, the message bus kicks in to collect all messages from the output queue of every worker and dispatches the message to the input queue of the receiver's worker. Later in the subsequent time step, every worker does a thread-local dispatch of the message to the receiver agent. It is guaranteed that if a message was sent in the current time step, the recipient agent will receive the message before it updates for the next time step.
Please, refer to this page.
In the parallel computing terminology, a barrier (Sec 3.5 of [Fujimoto]) is a point in the computation at which all the workers must wait. Only after all the workers have arrived to that point, they can proceed all together. In other words, a barrier is a synchronization point.
The diagram below shows the workers and barriers that work together in each time step of the simulation.

NOTE
- Boxes in orange color execute in parallel
- Boxes in purple color execute serially
- Barriers operate across work groups. Workers from all work groups wait at each barrier until all other workers have finished executing till that point.
There are four barriers in each time step to force the workers to synchronize.
- Frame tick barrier: Majority of computations take place before the this barrier. Every worker goes through its own list of agents and allows them to update for that time step.
- Flip buffers barrier: The buffered variables are flipped in this barrier. Staging of new agents for simulation and un-staging of finished agents from the simulation also takes place in this barrier.
- Distribute messages barrier: All asynchronous messages are collected from the output queues of each worker and distributed to appropriate input queue of the target workers managing the message recipients. This barrier is also used for any post-processing that needs to take place in the main thread after all agents have been processed. Examples of such post-processing tasks are the update of spatial index tracking agent locations in each time step in short-term and virtual queue processing in mid-term supply.
- Macro tick barrier: It is possible to set-up work groups to operate at a larger time resolution. The macro-tick barrier helps to synchronize the frequency of the macro-ticks.
After the last barrier for the current time step, the simulation repeats the same sequence of execution through the barriers for the subsequent time step. The workers go through this cycle indefinitely as long as the simulation is active. The main thread serves as the timekeeper and keeps the simulation active for precisely the duration of the configured simulation run-time.
For debug reasons, it may be useful running SimMobility with only one core, to have all the operations accomplished in a simple order, which is simple to check.
If you want to remove parallelism, put to 1 the following values:
-
<preday>/<threads>indata/simrun_MidTerm.xml -
<workers>/<person>, fieldcountand<preday>/<threads>indata/simrun_MidTerm.xml -
<pathset>/<thread_pool>indata/pathset_config.xml - In
medium/main_impl.ccin theperformMain()you should set something like:
WorkGroupManager wgMgr;
wgMgr.setSingleThreadMode(false);
and recompile again
In Short Term:
- in
data/simrun_ShortTerm.xmlworkers/person and io threads - In
short/main_impl.ccin theperformMain()you should set something like:
WorkGroupManager wgMgr;
wgMgr.setSingleThreadMode(false);
and recompile again
(WORK IN PROGRESS)
We consider a message a specific type of event with a single listener only. We consider the execution of a portion of code an event as well. Therefore, in what follows, even if we only explicitly mention events, we also implicitly refer to messages and execution of routines.
Events are constrained by relations of type "directly depends on". For example, if the Uber controller sends a command message to a driver and the driver replies with an ack, then ack directly depends on command. The action boarding performed by the bus directly depends on the set of events arrival issued by the passenger arriving at the bus stop.
We now extend the definition of "depends on" to a broader "depends on" relation in a recursive way. If A directly depends on B, we say also that A depends on B. If A depends on C, which, in turn, depends on B, we also say that A depends on B.
A and B are independent if it is not true that A depends on B.
If an action or an event E to be performed or issued at tick t depend on a certain event E', E' must have been processed before E.
The order in which independent events or messages are issued must not change the execution of the simulation. Whether two independent events A,B are issued in the order A,B or in the order B,A, the result of the simulation must not change.
The classic definition of causality is the following
A discrete event simulation [...] obeys the local causality constraint if and only if each [processor] processes events in non-decreasing timestamp order. From [1], Sec.3.1.
If we were sure that the frame ticks are very short, then the classic definition would be enough. Having very short frame ticks is computationally expensive and reduces the benefits of parallelization, as too often we would find processors blocked at the barriers waiting for the others to complete. Therefore, we want to allow long frame ticks. Let us consider two events A and B, where A depends on B. Therefore, we want to be sure that B is executed after A. In order to be sure of that, if we are only constrained to the causality constraint above, the timestamp of B must be greater than the timestamp of A. Indeed, if A and B had the same timestamp, nothing prevents B from being processed before A, as, even in this case, the non-decreasing timestamp order would not be violated. Therefore, we need some stronger concept of causality, which goes beyond the timestamp order and also embeds the semantic dependencies between events:
A discrete event simulation [...] obeys the hyper causality constraint if and only if each [processor] processes events in non-decreasing timestamp order and, if two events A and B have the same timestamp, but A depends on B, then B is processed before A.
We should evaluate whether to use mutex or any other shared memory data structure, because it may slow down the execution (in case many processors have to wait each other to write on the same datastructure). Moreover, if we use shared memory, we cannot run in the cloud or in many machines environment.
Looking at the picture in this previous section, some actions of tick t of an entity may happen before the messages for tick t are dispatched. This violates the "dispatch first, process after" principle.
See issue 592.
When an entity A SendInstantaneousMessage to an entity B, it directly calls B->HandleMessage(). This allows to future developers to violate, possibly inadvertently, the "independence from the creation time" principle. Suppose, for example, that a traveller can send a book message to a driver, which switches her to a booked state, in which no other traveller can book her. Suppose now that two travellers T1 and T2 send a book message to the same driver. The two book messages are independent. Now, it may happen, depending on which processor each entity is processed in and the occupancy of those processors, that the book message from T1 is created before the one from T2. In this case, T1 books the driver and T2 fails to do so. Or it may happen the opposite.

During the process agents phase, each agent issuing events places them in an output queue. Each event is scheduled for a certain frame tick. In the message distribution phase of a tick t, all the events scheduled for time t are taken from the output queues and placed in the input queues of the intended destination entities. Events are categorized in types. Suppose an event of type B depends on an event of type A (A->B). Before an entity can process an event B, it has to be sure it has received all the events of type A for that frame tick. To enforce this, we can use different ages or explicit notification.
In each frame tick we perform a loop through the different phases. We call each iteration of the loop a age. Each type of message is tied to a specific age. For example, the message command may be tied to age 1 and message ack may be tied to age 2, etc. In the 1st iteration of the loop, only messages and events tied to the 1st age are consumed, in the 2nd iteration the 2nd age, etc. An entity is authorized to consume messages only at the right age. If we are at age 2 and an entity is trying to consume messages of a type tied to age 1 or 3, an exception is raised.
If we are at frame tick t at a age s, a message or event can only be scheduled i) for frame tick > t or ii) for the same frame tick, but in this case for a age > s.
We have to know in advance what is the maximum number S of ages to which the message types are tied. For example, if we have a message type tied to age 1, another message type tied to 1 as well, another tied to age 2 and other two message types tied to age 3, then S=3. The value of S is hardcoded (or it may be computed by SimMobility introspecting itself and understanding all the messages that are going to be used). At each frame tick, S ages will be performed. The developer should not worry too much to write a correct value of S. In most of the cases, the default value will work and if, for some reason, we are keeping an incorrect value of S, it means that in the simulation we will be sending messages tied to a age greater then S, and an exception will be raised in the simulation, such that the developer will be notify, thus no risking to run inconsistent simulations.
Suppose an action depends on events or messages of certain types, each tied to a certain age. Suppose that the latest of this age is s. Then we force that action to occur only at age s and not before. To enforce it, we raise an issue whenever, during a certain age, we try to access a queue of messages f type tied to some future age.
Observe that the concept of age is similar to the age Sec.3.9.1 or priority numbers of Sec.3.9.2 of [1], with the difference that we make it stronger and we force each type of category to be tied to a pre-defined age. In this way, we are able to enforce the causality dependence between events, messages and actions happening in the same frame tick.
This design satisfy the hyper causality constraint.
To recap, we are supposing that A->B, i.e., events of type B depends of events of type A. The processing entity En knows exactly all the other entities En' that can issue events of type A to it. Therefore, before processing any event of type B, En wait to receive a notification from all the other entities En' saying "I am done with issuing messages of type A". The problem is the overhead for sending all these explicit notifications. Moreover, the list of the notifications already received must be handled via a mutex. Moreover, each entity should know, for each type of messages, from which other entities it should wait for notification
Travellers issue events of type ArrivedAtBusStop to notify their presence. This type of event is tied to age 1. When the bus boards, it checks the list of arrivedAtBusStop events and boards those travellers. Observe that no traveller can arrive at the same frame tick after the bus finishes boarding. In fact, when the bus starts boarding, it checks the list of ArrivedAtBusStop, at a certain age >=1. Given that there cannot be ArrivedAtBusStop events scheduled for ages > 1, we are sure that there cannot be travellers arriving after the boarding.
We tie the command messages to age 1 and the ack messages to age 2.
[Fujimoto] Fujimoto, R. M. (2000). Parallel and distributed simulation systems. https://doi.org/10.1109/WSC.2001.977259