Running Mid Term
SimMobility mid-term has three main components:
- preday
- withinday
- withinday pathset generation mode
- withinday normal simulation mode
- supply
All three components are part of the same SimMobility code base and can be executed from the same SimMobility mid-term binary file with the command below.
<SimMobility_Medium_executable> data/simulation.xml data/simrun_MidTerm.xml
where <SimMobility_Medium_executable> is the name of your executable, depending on the way you compiled (e.g., it can be ./Release/SimMobility_Medium, ./Debug/SimMobility_Medium or ./SimMobility_Medium).
Withinday normal simulation and supply are always executed together. Preday is executed separately by simply switching a configuration setting in simrun_MidTerm.xml. Steps to set-up and run simmobility are available [here] (https://github.com/smart-fm/simmobility-prod/wiki/Simmobility-Installation).
This document takes a closer look at running mid-term and explains the sequence of executions to be done to run one full cycle of preday, withinday+supply and feedback. The diagram below shows at a high level the sequence of executions to be done when running mid-term. It also shows the data transfers that take place after executing each component.
The execution sequence is shown with solid arrows and the data flow is shown in dotted arrows.
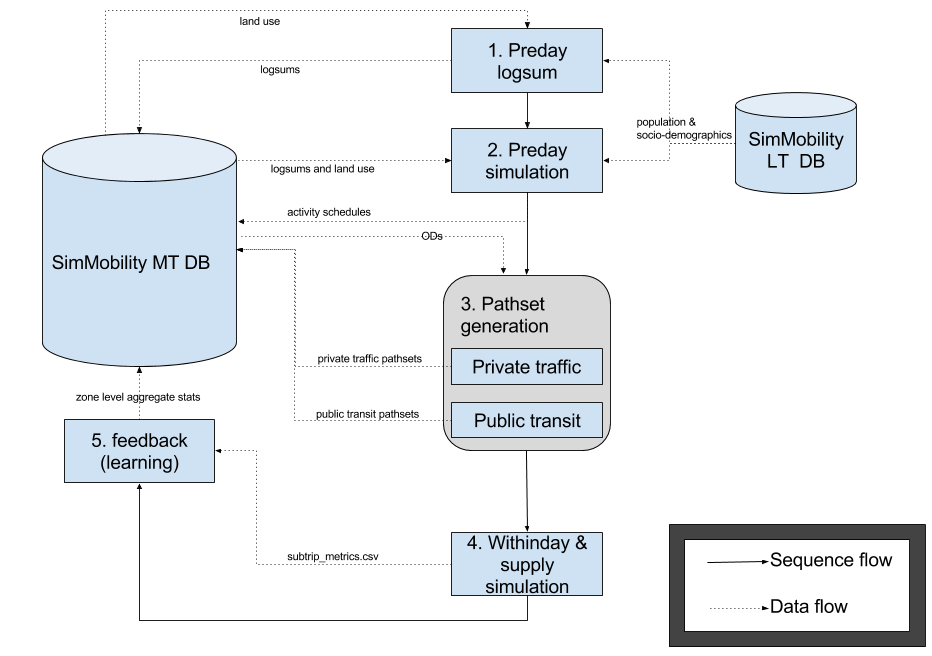
Each execution step is explained below along with corresponding config settings.
The choice (behavioral) models in preday are dependent on one another for [logsums] (https://github.com/smart-fm/simmobility-prod/wiki/Logsums). Logsums are required from tour mode and mode-destination models and day pattern models. Before running the preday to generate the activity schedules of each agent, we need to pre-compute logsums for those agents from these models. The logsums of an agent are later used to generate an activtiy schedule for the agent. Logsum computation is not required every time we run preday; it is required only if there are
- changes in population data or
- changes in the skim matrices and zone-to-zone travel times data or
- change of parameter values in models from which logsums are computed
To run preday in logsum computation mode, we need to set the following config settings.
In simulation.xml,
- Make sure the database information and credentials for the population database and mid-term database is available and note the corresponding ids.
In simrun_MidTerm.xml,
- change
mid_term_run_modeto "logsum" - provide the connection information and credentials for the population database in the
population_databaseelement. - in the
network_databaseelement under thesystemsection, provide connection information and credentials for the database with other required inputs like skim matrices, zonal data etc. - provide the name of the logsum table (along with schema name) in
logsum_tablexml tag. - Make sure that the logsum table exists in this database. The computed logsums will be output to this table.
- set the value for
threadsas per requirement. Preday is highly parallel. The more threads we specify, the faster it runs. However, number of threads must be limited by the user to the number of available CPU cores in the target computer. - set the path to the lua scripts and the names of the scripts to use in
model_scriptsunder thepredaysection
After setting the above configurations, the mid-term binary can be executed to compute logsums. The output of this is the logsum rows written to the logsum table specified above. Note that the table is truncated by the binary before any logsums are written to it. After the execution finishes, there will be a record with all logsum values in the logsum table for each agent in population.
Preday simulation mode takes the population, socio-demographics, zonal data, skim matrices and pre-computed logsums as input and generates the day activity schedule. The configuration settings for running preday simulation is listed below.
In simulation.xml,
- Make sure the database information and credentials for the population database and mid-term database is available and note the corresponding ids.
In simrun_MidTerm.xml,
- change
mid_term_run_modeto "activityschedule" - provide the connection information and credentials for the population database in the
population_databaseelement. - in the
network_databaseelement under thesystemsection, provide connection information and credentials for the database with other required inputs like skim matrices, zonal data etc. - set the value for
threadsas per requirement. Preday is highly parallel. The more threads we specify, the faster it runs. However, number of threads must be limited by the user to the number of available CPU cores in the target computer. - provide the name of the logsum table (along with schema name) in
logsum_tableelement. Logsums will be read from this table. - set the path to the lua scripts and the names of the scripts to use in
model_scriptsunder thepredaysection - provide the name of the das table in the
activity_schedule_tabletag. The generated activity_schedule will be pushed to this table using thepublic.load_das()stored procedure which is called automatically. The load_das() stored procedure is explained here.
After setting the above configurations, the binary can be executed to generate the activity schedule for each individual in the population. The activity schedules are written to activity_schedule csv file. This file is in the same format as the database table.
After obtaining the activity schedules in the csv file, we need to upload this into the simmobility database so that withinday and supply can use it to simulate the trips and activities of the agents.
NOTE FOR CAR SHARING: There are a couple of modes namely "Car Sharing 2" (driver plus one passenger) and "Car Sharing 3" (driver plus two or more passengers) predicted by preday as travel modes for some trips of agents. However, we do not know which agent would be the driver and who would be the passengers sharing the car. Withinday and supply is coded to create cars only for those trips with "Car" as the mode. In order to get the number of cars on the network (approximately) correct, we switch the travel mode of random one-half of trips with "Car sharing 2" mode and random one-third of "Car Sharing 3" mode to "Car" in the activity schedule. The remaining "Car Sharing *" rides are teleported from the corresponding origin to the destination with a delay equivalent to the travel time along the shortest path.
We have a postgresql function, namely public.load_das, which helps us to load the Day Activity Schedule into the a table that will be created (or overridden if existent) into the database. Make sure that this table is the one that will be read during your simulation. Remember that you will specify the table from which the withinday simulation will read Day Activity Schedule indirectly through the the tag <config>/<db_proc_groups>/<proc_map>/<mapping> (in the file simrun_MidTerm.xml) whose name is day_activity_schedule. You will find there the name of the procedure used to retrieve the activity schedule. Access the database you are using and look for that procedure, under the public schema. In the from-part of the query, you should find the name of the table from which the Day Activity Schedule will be retrieved in the within simulation.
In detail, the function load_das(<csv_file>,<das_table_name>)
- creates the Day Activity Schedule table called
demand.<table_name> - imports the supplied
<csv_file>into the table - creates necessary indexes on the table or better query performance
- renames "Car_Sharing_2" to "Car Sharing 2" and "Car_Sharing_3" to "Car Sharing 3"
- switches random half of "Car Sharing 2" mode to "Car"
- switches random one-third of "Car Sharing 3" mode to "Car"
NOTE:
- The
activity_schedulecsv needs to be in the same computer where the database is hosted. If preday was run by connecting to a remote database server, we need to copy the csv to the database server and provide the file path on that server as the first argument. - If there is already a table with the same name
demand.<das_table_name>, it will be dropped before creating a new table. Please, double check the name before running this function. - The table created will have the structure explained here.
Example
The function can be executed as follows from the psql prompt or pgAdmin.
select * from load_das('/full/path/to/file/filename', 'das_example');When the run mode is Preday full mode runs the two preday modes and pushes the generated activity schedule to the database. The configuration settings for running preday simulation is listed below.
In simulation.xml,
- Make sure the database information and credentials for the population database and mid-term database is available and note the corresponding ids.
In simrun_MidTerm.xml,
- change
mid_term_run_modeto "predayfull" - provide the connection information and credentials for the population database in the
population_databaseelement. - in the
network_databaseelement under thesystemsection, provide connection information and credentials for the database with other required inputs like skim matrices, zonal data etc. - set the value for
threadsas per requirement. Preday is highly parallel. The more threads we specify, the faster it runs. However, number of threads must be limited by the user to the number of available CPU cores in the target computer. - provide the name of the logsum table (along with schema name) in
logsum_tableelement. Logsums will be written into and read from this table. - set the path to the lua scripts and the names of the scripts to use in
model_scriptsunder thepredaysection - provide the name of the das table in the
activity_schedule_tabletag. The generated activity_schedule will be pushed to this table using thepublic.load_das()stored procedure which is called automatically.
When new activity schedules are in place, we need to make sure that we have pathsets for all public transit and private traffic OD pairs in the activity schedule. If we have ODs for which pathsets are not available, we need to perform pathset generation for those ODs, with the withinday pathset generation mode.
As mentioned earlier, withinday normal simulation and supply are always executed together. The supply is responsible for tracking the state of the simulated network throughout the simulation and withinday simulation is responsible for allowing agents to take decisions like route-choice, mode choice, departure time choice etc. The following configuration settings need to be taken care of before running withinday simulations.
In simulation.xml,
- make sure the database information and credentials for the population database and simmobility database is available and note the corresponding ids.
- set appropriate simulation run-time in
total_runtimeelement under simulation section - set appropriate simulation start time in
start_timeelement under simulation section
NOTE
- The run time must be specified in seconds or minutes.
- The run-time and the start time must be specified such that the simulation does not cross 12 mid-night. The time-stamps used internally in the code are not designed with a date component. This implies, for example, within a simulation 1AM is considered to be always before 10PM. If we run a 24 hour simulation starting from 6PM, 1AM comes after 10PM which may lead to inconsistencies in the code and possibly lead to a crash of the simulation.
- If we load the entire activity schedule table in one shot, agent objects may be created much earlier than needed. These agent objects occupy free memory and do nothing till their start time is reached. This can cause problems in computers with limited memory. To avoid this, we load activity schedules on an hourly basis. At the start of each hour, the activity schedules for all agents whose first trip is in that hour are loaded. However there is a known side-effect to this strategy. For example, if we specify the run-time as 1440 minutes (24 hours) and the start time as "00:00:00" (12 mid-night), at the end of the simulation, the program loads the activity schedules for agents starting their day between 12AM to 1AM again before ending the simulation at 12AM. To evade this waste of time and resources to load agents who are never going to be simulated, we may specify the runtime as 1439 minutes (1 minute less than 24 hours).
In simrun_MidTerm.xml,
- change
mid_term_run_modeto "withinday" - validate the postgreSQL function names specified in the proc_map you want to use
- provide the connection information and credentials for the population database in the
population_databaseelement under thesystemsection - in the
network_databaseelement under thesystemsection, provide connection information and credentials for the database with the network data, pathsets and other inputs. Specify the proc_map that you want to use in the same element. All postgreSQL functions in the specified proc_map should be available in the specified database. - set the required number of worker threads in the
persontag underworkers. This is the number of threads that will manage person agents in the withinday simulation. - set the path to the lua scripts and the names of the scripts to use in
model_scriptsundersupplysection
NOTE
- There are a whole bunch of other configurations available in simrun_MidTerm.xml which are explained in detail here
The mid-term binary can be executed after the above configurations are set. A few output files are produced from supply. They are explained in detail here.
Step-by-step guide to run SimMobility-MT
There are a couple of internal supply to withinday feedbacks after every 24 hour run of withinday and supply. The travel times of links and statistics pertinent to PT modes are fed back into respective database tables to guide route choices in subsequent withinday simulations. The link travel time feedback helps in the route choice selection by nudging the agents to choose faster routes based on the result of the previous iteration. This feedback can be enabled using the link_travel_time tag in simrun_Midterm.xml More detailed explanation on this is available here
After running the withinday and supply, its travel time outputs are aggregated into zonal level and are used to update travel times and costs in the skim matrices. These updated skim matrices are then used by preday to generate the activity schedules for another day. This feedback can be enabled using the subtrip_metrics in simrun_Midterm.xml
We have a python program named - TravelTimeAggregator.py which is responsible for this feedback. This script takes the subtrip_metrics.csv file (output from supply) as input and updates the specified skim matrices and zone-to-zone travel times tables. The database connection information and table names can be configured easily in the first few lines of the python program.
The program resides under the scripts directory of the simmobility code base and can be executed from a terminal as follows.
python TravelTimeAggregator.py subtrip_metrics.csv
This completes one full cycle of mid-term. The subsequent cycle can be started from preday.
Setting the run mode to "midtermfull", completes one full cycle of mid term. It involves:
- Running Preday Logsum
- Running Preday Simulation
- Running Supply/Withinday