Pull in master #4
Commits on Jan 7, 2021
-
[Don't review] Clean up type annotations in caffe2/torch/nn (#50079)
Summary: Pull Request resolved: #50079 Test Plan: Sandcastle tests Reviewed By: xush6528 Differential Revision: D25718694 fbshipit-source-id: f535fb879bcd4cb4ea715adfd90bbffa3fcc1150
-
Clean up some type annotations in android (#49944)
Summary: Pull Request resolved: #49944 Upgrades type annotations from Python2 to Python3 Test Plan: Sandcastle tests Reviewed By: xush6528 Differential Revision: D25717539 fbshipit-source-id: c621e2712e87eaed08cda48eb0fb224f6b0570c9
-
[Gradient Compression] Remove the extra comma after "bucket" in Power…
Commits on Jan 8, 2021
-
-
Fix SyncBatchNorm usage without stats tracking (#50126)
Summary: In `batch_norm_gather_stats_with_counts_cuda` use `input.scalar_type()` if `running_mean` is not defined In `SyncBatchNorm` forward function create count tensor with `torch.float32` type if `running_mean` is None Fix a few typos Pull Request resolved: #50126 Test Plan: ``` python -c "import torch;print(torch.batch_norm_gather_stats_with_counts( torch.randn(1, 3, 3, 3, device='cuda'), mean = torch.ones(2, 3, device='cuda'), invstd = torch.ones(2, 3, device='cuda'), running_mean = None, running_var = None , momentum = .1, eps = 1e-5, counts = torch.ones(2, device='cuda')))" ``` Fixes #49730 Reviewed By: ngimel Differential Revision: D25797930 Pulled By: malfet fbshipit-source-id: 22a91e3969b5e9bbb7969d9cc70b45013a42fe83
-
[PyTorch] Devirtualize TensorImpl::numel() with macro (#49766)
Summary: Pull Request resolved: #49766 Devirtualizing this seems like a decent performance improvement on internal benchmarks. The *reason* this is a performance improvement is twofold: 1) virtual calls are a bit slower than regular calls 2) virtual functions in `TensorImpl` can't be inlined Test Plan: internal benchmark Reviewed By: hlu1 Differential Revision: D25602321 fbshipit-source-id: d61556456ccfd7f10c6ebdc3a52263b438a2aef1
-
[PyTorch] validate that SparseTensorImpl::dim needn't be overridden (#…
…49767) Summary: Pull Request resolved: #49767 I'm told that the base implementation should work fine. Let's validate that in an intermediate diff before removing it. ghstack-source-id: 119528066 Test Plan: CI Reviewed By: ezyang, bhosmer Differential Revision: D25686830 fbshipit-source-id: f931394d3de6df7f6c5c68fe8ab711d90d3b12fd
-
[PyTorch] Devirtualize TensorImpl::dim() with macro (#49770)
Summary: Pull Request resolved: #49770 Seems like the performance cost of making this commonly-called method virtual isn't worth having use of undefined tensors crash a bit earlier (they'll still fail to dispatch). ghstack-source-id: 119528065 Test Plan: framework overhead benchmarks Reviewed By: ezyang Differential Revision: D25687465 fbshipit-source-id: 89aabce165a594be401979c04236114a6f527b59
-
Let RpcAgent::send() return JitFuture (#49906)
Summary: Pull Request resolved: #49906 This commit modifies RPC Message to inherit from `torch::CustomClassHolder`, and wraps a Message in an IValue in `RpcAgent::send()`. Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25719518 Pulled By: mrshenli fbshipit-source-id: 694e40021e49e396da1620a2f81226522341550b
-
Replace FutureMessage with ivalue::Future in distributed/autograd/uti…
-
Replace FutureMessage with ivalue::Future in RRefContext (#49960)
Summary: Pull Request resolved: #49960 Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25730530 Pulled By: mrshenli fbshipit-source-id: 5d54572c653592d79c40aed616266c87307a1ad8
-
Replace FutureMessage with ivalue::Future in RpcAgent retry logic (#4…
-
Completely remove FutureMessage from RRef Implementations (#50004)
Summary: Pull Request resolved: #50004 Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25750602 Pulled By: mrshenli fbshipit-source-id: 06854a77f4fb5cc4c34a1ede843301157ebf7309
-
Completely remove FutureMessage from RPC TorchScript implementations (#…
-
Completely remove FutureMessage from distributed autograd (#50020)
Summary: Pull Request resolved: #50020 Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25752968 Pulled By: mrshenli fbshipit-source-id: 138d37e204b6f9a584633cfc79fd44c8c9c00f41
-
Remove FutureMessage from sender ProcessGroupAgent (#50023)
Summary: Pull Request resolved: #50023 Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25753217 Pulled By: mrshenli fbshipit-source-id: 5a98473c17535c8f92043abe143064e7fca4413b
-
Remove FutureMessage from sender TensorPipeAgent (#50024)
Summary: Pull Request resolved: #50024 Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25753386 Pulled By: mrshenli fbshipit-source-id: fdca051b805762a2c88f965ceb3edf1c25d40a56
-
Completely remove FutureMessage from FaultyProcessGroupAgent (#50025)
Summary: Pull Request resolved: #50025 Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25753587 Pulled By: mrshenli fbshipit-source-id: a5d4106a10d1b0d3e4c406751795f19af8afd120
-
Remove FutureMessage from RPC request callback logic (#50026)
Summary: Pull Request resolved: #50026 Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25753588 Pulled By: mrshenli fbshipit-source-id: a6fcda7830901dd812fbf0489b001e6bd9673780
-
Completely Remove FutureMessage from RPC cpp tests (#50027)
Summary: Pull Request resolved: #50027 Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25753815 Pulled By: mrshenli fbshipit-source-id: 85b9b03fec52b4175288ac3a401285607744b451
-
Completely Remove FutureMessage from RPC agents (#50028)
Summary: Pull Request resolved: #50028 Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25753887 Pulled By: mrshenli fbshipit-source-id: 40718349c2def262a16aaa24c167c0b540cddcb1
-
Completely remove FutureMessage type (#50029)
Summary: Pull Request resolved: #50029 Test Plan: buck run mode/opt -c=python.package_style=inplace //caffe2/torch/fb/training_toolkit/examples:ctr_mbl_feed_april_2020 -- local-preset --flow-entitlement pytorch_ftw_gpu --secure-group oncall_pytorch_distributed Before: ``` ... I0107 11:03:10.434000 3831111 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|total_examples 14000.0 I0107 11:03:10.434000 3831111 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|window_qps 74.60101318359375 I0107 11:03:10.434000 3831111 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|lifetime_qps 74.60101318359375 ... I0107 11:05:12.132000 3831111 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|total_examples 20000.0 I0107 11:05:12.132000 3831111 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|window_qps 64.0 I0107 11:05:12.132000 3831111 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|lifetime_qps 64.64917755126953 ... ``` After: ``` ... I0107 11:53:03.858000 53693 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|total_examples 14000.0 I0107 11:53:03.858000 53693 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|window_qps 72.56404876708984 I0107 11:53:03.858000 53693 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|lifetime_qps 72.56404876708984 ... I0107 11:54:24.612000 53693 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|total_examples 20000.0 I0107 11:54:24.612000 53693 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|window_qps 73.07617950439453 I0107 11:54:24.612000 53693 print_publisher.py:23 master ] Publishing batch metrics: qps-qps|lifetime_qps 73.07617950439453 ... ``` Reviewed By: lw Differential Revision: D25774915 Pulled By: mrshenli fbshipit-source-id: 1128c3c2df9d76e36beaf171557da86e82043eb9
-
[PyTorch] Introduce packed SizesAndStrides abstraction (#47507)
Summary: Pull Request resolved: #47507 This introduces a new SizesAndStrides class as a helper for TensorImpl, in preparation for changing its representation. ghstack-source-id: 119313559 Test Plan: Added new automated tests as well. Run framework overhead benchmarks. Results seem to be neutral-ish. Reviewed By: ezyang Differential Revision: D24762557 fbshipit-source-id: 6cc0ede52d0a126549fb51eecef92af41c3e1a98
-
[PyTorch] Change representation of SizesAndStrides (#47508)
Summary: Pull Request resolved: #47508 This moves SizesAndStrides to a specialized representation that is 5 words smaller in the common case of tensor rank 5 or less. ghstack-source-id: 119313560 Test Plan: SizesAndStridesTest added in previous diff passes under ASAN + UBSAN. Run framework overhead benchmarks. Looks more or less neutral. Reviewed By: ezyang Differential Revision: D24772023 fbshipit-source-id: 0a75fd6c2daabb0769e2f803e80e2d6831871316
-
Disable cuDNN persistent RNN on sm_86 devices (#49534)
Summary: Excludes sm_86 GPU devices from using cuDNN persistent RNN. This is because there are some hard-to-detect edge cases that will throw exceptions with cudnn 8.0.5 on Nvidia A40 GPU. Pull Request resolved: #49534 Reviewed By: mruberry Differential Revision: D25632378 Pulled By: mrshenli fbshipit-source-id: cbe78236d85d4d0c2e4ca63a3fc2c4e2de662d9e
-
Address clang-tidy warnings in ProcessGroupNCCL (#50131)
Summary: Pull Request resolved: #50131 Noticed that in the internal diff for #49069 there was a clang-tidy warning to use emplace instead of push_back. This can save us a copy as it eliminates the unnecessary in-place construction ghstack-source-id: 119560979 Test Plan: CI Reviewed By: pritamdamania87 Differential Revision: D25800134 fbshipit-source-id: 243e57318f5d6e43de524d4e5409893febe6164c
-
Revert D25687465: [PyTorch] Devirtualize TensorImpl::dim() with macro
Test Plan: revert-hammer Differential Revision: D25687465 (4de6b27) Original commit changeset: 89aabce165a5 fbshipit-source-id: fa5def17209d1691e68b1245fa0873fd03e88eaa
-
Autograd engine, only enqueue task when it is fully initialized (#50164)
Summary: This solves a race condition where the worker thread might see a partially initialized graph_task Fixes #49652 I don't know how to reliably trigger the race so I didn't add any test. But the rocm build flakyness (it just happens to race more often on rocm builds) should disappear after this PR. Pull Request resolved: #50164 Reviewed By: zou3519 Differential Revision: D25824954 Pulled By: albanD fbshipit-source-id: 6a3391753cb2afd2ab415d3fb2071a837cc565bb
-
-
Update autograd related comments (#50166)
Summary: Remove outdated comment and update to use new paths. Pull Request resolved: #50166 Reviewed By: zou3519 Differential Revision: D25824942 Pulled By: albanD fbshipit-source-id: 7dc694891409e80e1804eddcdcc50cc21b60f822
-
Implement torch.linalg.svd (#45562)
Summary: This is related to #42666 . I am opening this PR to have the opportunity to discuss things. First, we need to consider the differences between `torch.svd` and `numpy.linalg.svd`: 1. `torch.svd` takes `some=True`, while `numpy.linalg.svd` takes `full_matrices=True`, which is effectively the opposite (and with the opposite default, too!) 2. `torch.svd` returns `(U, S, V)`, while `numpy.linalg.svd` returns `(U, S, VT)` (i.e., V transposed). 3. `torch.svd` always returns a 3-tuple; `numpy.linalg.svd` returns only `S` in case `compute_uv==False` 4. `numpy.linalg.svd` also takes an optional `hermitian=False` argument. I think that the plan is to eventually deprecate `torch.svd` in favor of `torch.linalg.svd`, so this PR does the following: 1. Rename/adapt the old `svd` C++ functions into `linalg_svd`: in particular, now `linalg_svd` takes `full_matrices` and returns `VT` 2. Re-implement the old C++ interface on top of the new (by negating `full_matrices` and transposing `VT`). 3. The C++ version of `linalg_svd` *always* returns a 3-tuple (we can't do anything else). So, there is a python wrapper which manually calls `torch._C._linalg.linalg_svd` to tweak the return value in case `compute_uv==False`. Currently, `linalg_svd_backward` is broken because it has not been adapted yet after the `V ==> VT` change, but before continuing and spending more time on it I wanted to make sure that the general approach is fine. Pull Request resolved: #45562 Reviewed By: H-Huang Differential Revision: D25803557 Pulled By: mruberry fbshipit-source-id: 4966f314a0ba2ee391bab5cda4563e16275ce91f
-
Add tensor.view(dtype) (#47951)
Summary: Fixes #42571 Note that this functionality is a subset of [`numpy.ndarray.view`](https://numpy.org/doc/stable/reference/generated/numpy.ndarray.view.html): - this only supports viewing a tensor as a dtype with the same number of bytes - this does not support viewing a tensor as a subclass of `torch.Tensor` Pull Request resolved: #47951 Reviewed By: ngimel Differential Revision: D25062301 Pulled By: mruberry fbshipit-source-id: 9fefaaef77f15d5b863ccd12d836932983794475
-
-
add type annotations to torch.nn.quantized.modules.conv (#49702)
Summary: closes gh-49700 No mypy issues were found in the first three entries deleted from `mypy.ini`: ``` [mypy-torch.nn.qat.modules.activations] ignore_errors = True [mypy-torch.nn.qat.modules.conv] ignore_errors = True [mypy-torch.nn.quantized.dynamic.modules.linear] ignore_errors = True ``` Pull Request resolved: #49702 Reviewed By: walterddr, zou3519 Differential Revision: D25767119 Pulled By: ezyang fbshipit-source-id: cb83e53549a299538e1b154cf8b79e3280f7392a
-
Stop using c10::scalar_to_tensor in float_power. (#50105)
Summary: Pull Request resolved: #50105 There should be no functional change here. A couple of reasons here: 1) This function is generally an anti-pattern (#49758) and it is good to minimize its usage in the code base. 2) pow itself has a fair amount of smarts like not broadcasting scalar/tensor combinations and we should defer to it. Test Plan: Imported from OSS Reviewed By: mruberry Differential Revision: D25786172 Pulled By: gchanan fbshipit-source-id: 89de03aa0b900ce011a62911224a5441f15e331a
-
-
[onnx] Do not deref nullptr in scalar type analysis (#50237)
Summary: Apply a little bit of defensive programming: `type->cast<TensorType>()` returns an optional pointer so dereferencing it can lead to a hard crash. Fixes SIGSEGV reported in #49959 Pull Request resolved: #50237 Reviewed By: walterddr Differential Revision: D25839675 Pulled By: malfet fbshipit-source-id: 403d6df5e2392dd6adc308b1de48057f2f9d77ab
-
Clean up some type annotations in test/jit (#50158)
Summary: Pull Request resolved: #50158 Upgrades type annotations from Python2 to Python3 Test Plan: Sandcastle tests Reviewed By: xush6528 Differential Revision: D25717504 fbshipit-source-id: 9a83c44db02ec79f353862255732873f6d7f885e
-
[numpy] torch.{all/any} : output dtype is always bool (#47878)
Summary: BC-breaking note: This PR changes the behavior of the any and all functions to always return a bool tensor. Previously these functions were only defined on bool and uint8 tensors, and when called on uint8 tensors they would also return a uint8 tensor. (When called on a bool tensor they would return a bool tensor.) PR summary: #44790 (comment) Fixes 2 and 3 Also Fixes #48352 Changes * Output dtype is always `bool` (consistent with numpy) **BC Breaking (Previously used to match the input dtype**) * Uses vectorized version for all dtypes on CPU * Enables test for complex * Update doc for `torch.all` and `torch.any` TODO * [x] Update docs * [x] Benchmark * [x] Raise issue on XLA Pull Request resolved: #47878 Reviewed By: albanD Differential Revision: D25714324 Pulled By: mruberry fbshipit-source-id: a87345f725297524242d69402dfe53060521ea5d
-
Convert string => raw strings so char classes can be represented in P…
…ython regex (#50239) Summary: Pull Request resolved: #50239 Convert regex strings that have character classes (e.g. \d, \s, \w, \b, etc) into raw strings so they won't be interpreted as escape characters. References: Python RegEx - https://www.w3schools.com/python/python_regex.asp Python Escape Chars - https://www.w3schools.com/python/gloss_python_escape_characters.asp Python Raw String - https://www.journaldev.com/23598/python-raw-string Python RegEx Docs - https://docs.python.org/3/library/re.html Python String Tester - https://www.w3schools.com/python/trypython.asp?filename=demo_string_escape Python Regex Tester - https://regex101.com/ Test Plan: To find occurrences of regex strings with the above issue in VS Code, search using the regex \bre\.[a-z]+\(['"], and under 'files to include', use /data/users/your_username/fbsource/fbcode/caffe2. Reviewed By: r-barnes Differential Revision: D25813302 fbshipit-source-id: df9e23c0a84c49175eaef399ca6d091bfbeed936
-
Dump state when hitting ambiguous_autogradother_kernel. (#50246)
Summary: Pull Request resolved: #50246 Test Plan: Imported from OSS Reviewed By: bhosmer Differential Revision: D25843205 Pulled By: ailzhang fbshipit-source-id: 66916ae477a4ae97e1695227fc6af78c4f328ea3
-
Apply clang-format to rpc cpp files (#50236)
Summary: Pull Request resolved: #50236 Test Plan: Imported from OSS Reviewed By: lw Differential Revision: D25847892 Pulled By: mrshenli fbshipit-source-id: b4af1221acfcaba8903c629869943abbf877e04e
-
Revert D25717504: Clean up some type annotations in test/jit
Test Plan: revert-hammer Differential Revision: D25717504 (a4f30d4) Original commit changeset: 9a83c44db02e fbshipit-source-id: e6e3a83bed22701d8125f5a293dfcd5093c1a2cd
-
-
Unused exception variables (#50181)
Summary: These unused variables were identified by [pyflakes](https://pypi.org/project/pyflakes/). They can be safely removed to simplify the code. Pull Request resolved: #50181 Reviewed By: gchanan Differential Revision: D25844270 fbshipit-source-id: 0e648ffe8c6db6daf56788a13ba89806923cbb76
-
Commits on Jan 9, 2021
-
Optimize Vulkan command buffer submission rate. (#49112)
Summary: Pull Request resolved: #49112 Differential Revision: D25729889 Test Plan: Imported from OSS Reviewed By: SS-JIA Pulled By: AshkanAliabadi fbshipit-source-id: c4ab470fdcf3f83745971986f3a44a3dff69287f
-
Support scripting classmethod called with object instances (#49967)
Summary: Currentlt classmethods are compiled the same way as methods - the first argument is self. Adding a fake statement to assign the first argument to the class. This is kind of hacky, but that's all it takes. Pull Request resolved: #49967 Reviewed By: gchanan Differential Revision: D25841378 Pulled By: ppwwyyxx fbshipit-source-id: 0f3657b4c9d5d2181d658f9bade9bafc72de33d8
-
Change CMake config to enable universal binary for Mac (#50243)
Summary: This PR is a step towards enabling cross compilation from x86_64 to arm64. The following has been added: 1. When cross compilation is detected, compile a local universal fatfile to use as protoc. 2. For the simple compile check in MiscCheck.cmake, make sure to compile the small snippet as a universal binary in order to run the check. **Test plan:** Kick off a minimal build on a mac intel machine with the macOS 11 SDK with this command: ``` CMAKE_OSX_ARCHITECTURES=arm64 USE_MKLDNN=OFF USE_QNNPACK=OFF USE_PYTORCH_QNNPACK=OFF BUILD_TEST=OFF USE_NNPACK=OFF python setup.py install ``` (If you run the above command before this change, or without macOS 11 SDK set up, it will fail.) Then check the platform of the built binaries using this command: ``` lipo -info build/lib/libfmt.a ``` Output: - Before this PR, running a regular build via `python setup.py install` (instead of using the flags listed above): ``` Non-fat file: build/lib/libfmt.a is architecture: x86_64 ``` - Using this PR: ``` Non-fat file: build/lib/libfmt.a is architecture: arm64 ``` Pull Request resolved: #50243 Reviewed By: malfet Differential Revision: D25849955 Pulled By: janeyx99 fbshipit-source-id: e9853709a7279916f66aa4c4e054dfecced3adb1
-
[fix] torch.cat: Don't resize out if it is already of the correct siz…
-
JIT: guard DifferentiableGraph node (#49433)
Summary: This adds guarding for DifferentiableGraph nodes in order to not depend on Also bailing out on required gradients for the CUDA fuser. Fixes #49299 I still need to look into a handful of failing tests, but maybe it can be a discussion basis. Pull Request resolved: #49433 Reviewed By: ngimel Differential Revision: D25681374 Pulled By: Krovatkin fbshipit-source-id: 8e7be53a335c845560436c0cceeb5e154c9cf296
-
Document single op replacement (#50116)
Summary: Pull Request resolved: #50116 Test Plan: Imported from OSS Reviewed By: jamesr66a Differential Revision: D25803457 Pulled By: ansley fbshipit-source-id: de2f3c0bd037859117dde55ba677fb5da34ab639
-
reuse consant from jit (#49916)
Summary: Pull Request resolved: #49916 Test Plan: 1. Build pytorch locally. `MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ USE_CUDA=0 DEBUG=1 MAX_JOBS=16 python setup.py develop` 2. Run `python save_lite.py` ``` import torch # ~/Documents/pytorch/data/dog.jpg model = torch.hub.load('pytorch/vision:v0.6.0', 'shufflenet_v2_x1_0', pretrained=True) model.eval() # sample execution (requires torchvision) from PIL import Image from torchvision import transforms import pathlib import tempfile import torch.utils.mobile_optimizer input_image = Image.open('~/Documents/pytorch/data/dog.jpg') preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(input_image) input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model # move the input and model to GPU for speed if available if torch.cuda.is_available(): input_batch = input_batch.to('cuda') model.to('cuda') with torch.no_grad(): output = model(input_batch) # Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes print(output[0]) # The output has unnormalized scores. To get probabilities, you can run a softmax on it. print(torch.nn.functional.softmax(output[0], dim=0)) traced = torch.jit.trace(model, input_batch) sum(p.numel() * p.element_size() for p in traced.parameters()) tf = pathlib.Path('~/Documents/pytorch/data/data/example_debug_map_with_tensorkey.ptl') torch.jit.save(traced, tf.name) print(pathlib.Path(tf.name).stat().st_size) traced._save_for_lite_interpreter(tf.name) print(pathlib.Path(tf.name).stat().st_size) print(tf.name) ``` 3. Run `python test_lite.py` ``` import torch from torch.jit.mobile import _load_for_lite_interpreter # sample execution (requires torchvision) from PIL import Image from torchvision import transforms input_image = Image.open('~/Documents/pytorch/data/dog.jpg') preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(input_image) input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model reload_lite_model = _load_for_lite_interpreter('~/Documents/pytorch/experiment/example_debug_map_with_tensorkey.ptl') with torch.no_grad(): output_lite = reload_lite_model(input_batch) # Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes print(output_lite[0]) # The output has unnormalized scores. To get probabilities, you can run a softmax on it. print(torch.nn.functional.softmax(output_lite[0], dim=0)) ``` 4. Compare the result with pytorch in master and pytorch built locally with this change, and see the same output. 5. The model size was 16.1 MB and becomes 12.9 with this change. Imported from OSS Reviewed By: kimishpatel, iseeyuan Differential Revision: D25731596 Pulled By: cccclai fbshipit-source-id: 9731ec1e0c1d5dc76cfa374d2ad3d5bb10990cf0
-
[codemod][fbcode/caffe2] Apply clang-format update fixes
Test Plan: Sandcastle and visual inspection. Reviewed By: igorsugak Differential Revision: D25849205 fbshipit-source-id: ef664c1ad4b3ee92d5c020a5511b4ef9837a09a0
Commits on Jan 10, 2021
-
-
Summary: This PR adds `torch.linalg.inv` for NumPy compatibility. `linalg_inv_out` uses in-place operations on provided `result` tensor. I modified `apply_inverse` to accept tensor of Int instead of std::vector, that way we can write a function similar to `linalg_inv_out` but removing the error checks and device memory synchronization. I fixed `lda` (leading dimension parameter which is max(1, n)) in many places to handle 0x0 matrices correctly. Zero batch dimensions are also working and tested. Ref #42666 Pull Request resolved: #48261 Reviewed By: gchanan Differential Revision: D25849590 Pulled By: mruberry fbshipit-source-id: cfee6f1daf7daccbe4612ec68f94db328f327651
-
Allow arbitrary docstrings to be inside torchscript interface methods (…
-
Automated submodule update: tensorpipe (#50267)
Summary: This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe). New submodule commit: pytorch/tensorpipe@03e0711 Pull Request resolved: #50267 Test Plan: Ensure that CI jobs succeed on GitHub before landing. Reviewed By: gchanan Differential Revision: D25848309 Pulled By: mrshenli fbshipit-source-id: c77adbad73c5b3b4b7d4e79953a797621dc11e5c
Commits on Jan 11, 2021
-
Use FileStore in TorchScript for store registry (#50248)
Summary: Pull Request resolved: #50248 make the FileStore path also use TorchScript when it's needed. Test Plan: wait for sandcastle. Reviewed By: zzzwen Differential Revision: D25842651 fbshipit-source-id: dec941e895a33ffde42c877afcaf64b5aecbe098
-
treat Parameter the same way as Tensor (#48963)
Summary: Pull Request resolved: #48963 This PR makes the binding code treat `Parameter` the same way as `Tensor`, unlike all other `Tensor` subclasses. This does change the semantics of `THPVariable_CheckExact`, but it isn't used much and it seemed to make sense for the half dozen or so places that it is used. Test Plan: Existing unit tests. Benchmarks are in #48966 Reviewed By: ezyang Differential Revision: D25590733 Pulled By: robieta fbshipit-source-id: 060ecaded27b26e4b756898eabb9a94966fc9840
-
clean up imports for tensor.py (#48964)
Summary: Pull Request resolved: #48964 Stop importing overrides within methods now that the circular dependency is gone, and also organize the imports while I'm at it because they're a jumbled mess. Test Plan: Existing unit tests. Benchmarks are in #48966 Reviewed By: ngimel Differential Revision: D25590730 Pulled By: robieta fbshipit-source-id: 4fa929ce8ff548500f3e55d0475f3f22c1fccc04
-
move has_torch_function to C++, and make a special case object_has_to…
…rch_function (#48965) Summary: Pull Request resolved: #48965 This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API. Test Plan: Existing unit tests. Benchmarks are in #48966 Reviewed By: ezyang Differential Revision: D25590732 Pulled By: robieta fbshipit-source-id: 6bd74788f06cdd673f3a2db898143d18c577eb42
-
Treat has_torch_function and object_has_torch_function as static Fals…
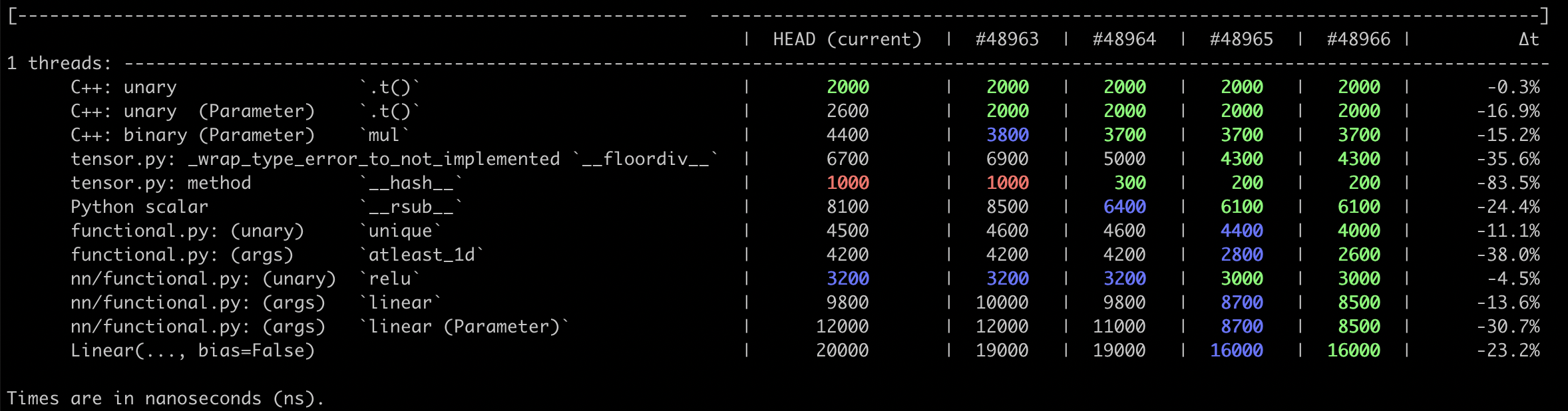
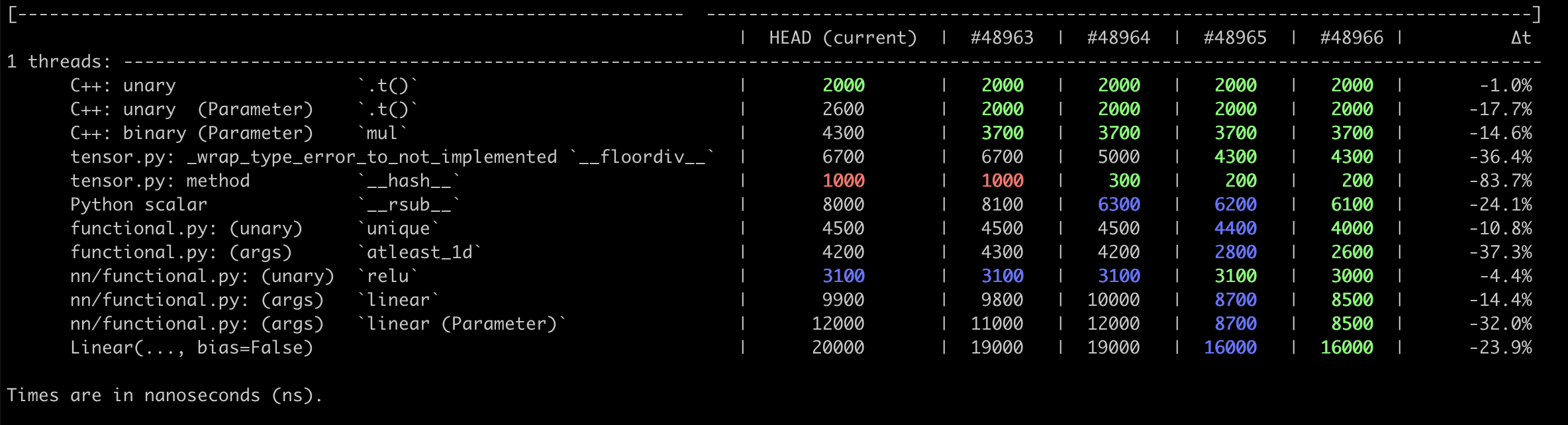
…e when scripting (#48966) Summary: Pull Request resolved: #48966 This PR lets us skip the `if not torch.jit.is_scripting():` guards on `functional` and `nn.functional` by directly registering `has_torch_function` and `object_has_torch_function` to the JIT as statically False. **Benchmarks** The benchmark script is kind of long. The reason is that it's testing all four PRs in the stack, plus threading and subprocessing so that the benchmark can utilize multiple cores while still collecting good numbers. Both wall times and instruction counts were collected. This stack changes dozens of operators / functions, but very mechanically such that there are only a handful of codepath changes. Each row is a slightly different code path (e.g. testing in Python, testing in the arg parser, different input types, etc.) <details> <summary> Test script </summary> ``` import argparse import multiprocessing import multiprocessing.dummy import os import pickle import queue import random import sys import subprocess import tempfile import time import torch from torch.utils.benchmark import Timer, Compare, Measurement NUM_CORES = multiprocessing.cpu_count() ENVS = { "ref": "HEAD (current)", "torch_fn_overhead_stack_0": "#48963", "torch_fn_overhead_stack_1": "#48964", "torch_fn_overhead_stack_2": "#48965", "torch_fn_overhead_stack_3": "#48966", } CALLGRIND_ENVS = tuple(ENVS.keys()) MIN_RUN_TIME = 3 REPLICATES = { "longer": 1_000, "long": 300, "short": 50, } CALLGRIND_NUMBER = { "overnight": 500_000, "long": 250_000, "short": 10_000, } CALLGRIND_TIMEOUT = { "overnight": 800, "long": 400, "short": 100, } SETUP = """ x = torch.ones((1, 1)) y = torch.ones((1, 1)) w_tensor = torch.ones((1, 1), requires_grad=True) linear = torch.nn.Linear(1, 1, bias=False) linear_w = linear.weight """ TASKS = { "C++: unary `.t()`": "w_tensor.t()", "C++: unary (Parameter) `.t()`": "linear_w.t()", "C++: binary (Parameter) `mul` ": "x + linear_w", "tensor.py: _wrap_type_error_to_not_implemented `__floordiv__`": "x // y", "tensor.py: method `__hash__`": "hash(x)", "Python scalar `__rsub__`": "1 - x", "functional.py: (unary) `unique`": "torch.functional.unique(x)", "functional.py: (args) `atleast_1d`": "torch.functional.atleast_1d((x, y))", "nn/functional.py: (unary) `relu`": "torch.nn.functional.relu(x)", "nn/functional.py: (args) `linear`": "torch.nn.functional.linear(x, w_tensor)", "nn/functional.py: (args) `linear (Parameter)`": "torch.nn.functional.linear(x, linear_w)", "Linear(..., bias=False)": "linear(x)", } def _worker_main(argv, fn): parser = argparse.ArgumentParser() parser.add_argument("--output_file", type=str) parser.add_argument("--single_task", type=int, default=None) parser.add_argument("--length", type=str) args = parser.parse_args(argv) single_task = args.single_task conda_prefix = os.getenv("CONDA_PREFIX") assert torch.__file__.startswith(conda_prefix) env = os.path.split(conda_prefix)[1] assert env in ENVS results = [] for i, (k, stmt) in enumerate(TASKS.items()): if single_task is not None and single_task != i: continue timer = Timer( stmt=stmt, setup=SETUP, sub_label=k, description=ENVS[env], ) results.append(fn(timer, args.length)) with open(args.output_file, "wb") as f: pickle.dump(results, f) def worker_main(argv): _worker_main( argv, lambda timer, _: timer.blocked_autorange(min_run_time=MIN_RUN_TIME) ) def callgrind_worker_main(argv): _worker_main( argv, lambda timer, length: timer.collect_callgrind(number=CALLGRIND_NUMBER[length], collect_baseline=False)) def main(argv): parser = argparse.ArgumentParser() parser.add_argument("--long", action="store_true") parser.add_argument("--longer", action="store_true") args = parser.parse_args(argv) if args.longer: length = "longer" elif args.long: length = "long" else: length = "short" replicates = REPLICATES[length] num_workers = int(NUM_CORES // 2) tasks = list(ENVS.keys()) * replicates random.shuffle(tasks) task_queue = queue.Queue() for _ in range(replicates): envs = list(ENVS.keys()) random.shuffle(envs) for e in envs: task_queue.put((e, None)) callgrind_task_queue = queue.Queue() for e in CALLGRIND_ENVS: for i, _ in enumerate(TASKS): callgrind_task_queue.put((e, i)) results = [] callgrind_results = [] def map_fn(worker_id): # Adjacent cores often share cache and maxing out a machine can distort # timings so we space them out. callgrind_cores = f"{worker_id * 2}-{worker_id * 2 + 1}" time_cores = str(worker_id * 2) _, output_file = tempfile.mkstemp(suffix=".pkl") try: loop_tasks = ( # Callgrind is long running, and then the workers can help with # timing after they finish collecting counts. (callgrind_task_queue, callgrind_results, "callgrind_worker", callgrind_cores, CALLGRIND_TIMEOUT[length]), (task_queue, results, "worker", time_cores, None)) for queue_i, results_i, mode_i, cores, timeout in loop_tasks: while True: try: env, task_i = queue_i.get_nowait() except queue.Empty: break remaining_attempts = 3 while True: try: subprocess.run( " ".join([ "source", "activate", env, "&&", "taskset", "--cpu-list", cores, "python", os.path.abspath(__file__), "--mode", mode_i, "--length", length, "--output_file", output_file ] + ([] if task_i is None else ["--single_task", str(task_i)])), shell=True, check=True, timeout=timeout, ) break except subprocess.TimeoutExpired: # Sometimes Valgrind will hang if there are too many # concurrent runs. remaining_attempts -= 1 if not remaining_attempts: print("Too many failed attempts.") raise print(f"Timeout after {timeout} sec. Retrying.") # We don't need a lock, as the GIL is enough. with open(output_file, "rb") as f: results_i.extend(pickle.load(f)) finally: os.remove(output_file) with multiprocessing.dummy.Pool(num_workers) as pool: st, st_estimate, eta, n_total = time.time(), None, "", len(tasks) * len(TASKS) map_job = pool.map_async(map_fn, range(num_workers)) while not map_job.ready(): n_complete = len(results) if n_complete and len(callgrind_results): if st_estimate is None: st_estimate = time.time() else: sec_per_element = (time.time() - st_estimate) / n_complete n_remaining = n_total - n_complete eta = f"ETA: {n_remaining * sec_per_element:.0f} sec" print( f"\r{n_complete} / {n_total} " f"({len(callgrind_results)} / {len(CALLGRIND_ENVS) * len(TASKS)}) " f"{eta}".ljust(40), end="") sys.stdout.flush() time.sleep(2) total_time = int(time.time() - st) print(f"\nTotal time: {int(total_time // 60)} min, {total_time % 60} sec") desc_to_ind = {k: i for i, k in enumerate(ENVS.values())} results.sort(key=lambda r: desc_to_ind[r.description]) # TODO: Compare should be richer and more modular. compare = Compare(results) compare.trim_significant_figures() compare.colorize(rowwise=True) # Manually add master vs. overall relative delta t. merged_results = { (r.description, r.sub_label): r for r in Measurement.merge(results) } cmp_lines = str(compare).splitlines(False) print(cmp_lines[0][:-1] + "-" * 15 + "]") print(f"{cmp_lines[1]} |{'':>10}\u0394t") print(cmp_lines[2] + "-" * 15) for l, t in zip(cmp_lines[3:3 + len(TASKS)], TASKS.keys()): assert l.strip().startswith(t) t0 = merged_results[(ENVS["ref"], t)].median t1 = merged_results[(ENVS["torch_fn_overhead_stack_3"], t)].median print(f"{l} |{'':>5}{(t1 / t0 - 1) * 100:>6.1f}%") print("\n".join(cmp_lines[3 + len(TASKS):])) counts_dict = { (r.task_spec.description, r.task_spec.sub_label): r.counts(denoise=True) for r in callgrind_results } def rel_diff(x, x0): return f"{(x / x0 - 1) * 100:>6.1f}%" task_pad = max(len(t) for t in TASKS) print(f"\n\nInstruction % change (relative to `{CALLGRIND_ENVS[0]}`)") print(" " * (task_pad + 8) + (" " * 7).join([ENVS[env] for env in CALLGRIND_ENVS[1:]])) for t in TASKS: values = [counts_dict[(ENVS[env], t)] for env in CALLGRIND_ENVS] print(t.ljust(task_pad + 3) + " ".join([ rel_diff(v, values[0]).rjust(len(ENVS[env]) + 5) for v, env in zip(values[1:], CALLGRIND_ENVS[1:])])) print("\033[4m" + " Instructions per invocation".ljust(task_pad + 3) + " ".join([ f"{v // CALLGRIND_NUMBER[length]:.0f}".rjust(len(ENVS[env]) + 5) for v, env in zip(values[1:], CALLGRIND_ENVS[1:])]) + "\033[0m") print() import pdb pdb.set_trace() if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--mode", type=str, choices=("main", "worker", "callgrind_worker"), default="main") args, remaining = parser.parse_known_args() if args.mode == "main": main(remaining) elif args.mode == "callgrind_worker": callgrind_worker_main(remaining) else: worker_main(remaining) ``` </details> **Wall time** <img width="1178" alt="Screen Shot 2020-12-12 at 12 28 13 PM" src="https://user-images.githubusercontent.com/13089297/101994419-284f6a00-3c77-11eb-8dc8-4f69a890302e.png"> <details> <summary> Longer run (`python test.py --long`) is basically identical. </summary> <img width="1184" alt="Screen Shot 2020-12-12 at 5 02 47 PM" src="https://user-images.githubusercontent.com/13089297/102000425-2350e180-3c9c-11eb-999e-a95b37e9ef54.png"> </details> **Callgrind** <img width="936" alt="Screen Shot 2020-12-12 at 12 28 54 PM" src="https://user-images.githubusercontent.com/13089297/101994421-2e454b00-3c77-11eb-9cd3-8cde550f536e.png"> Test Plan: existing unit tests. Reviewed By: ezyang Differential Revision: D25590731 Pulled By: robieta fbshipit-source-id: fe05305ff22b0e34ced44b60f2e9f07907a099dd
-
Use Unicode friendly API in fused kernel related code (#49781)
-
svd_backward: more memory and computationally efficient. (#50109)
Summary: As per title. CC IvanYashchuk (unfortunately I cannot add you as a reviewer for some reason). Pull Request resolved: #50109 Reviewed By: gchanan Differential Revision: D25828536 Pulled By: albanD fbshipit-source-id: 3791c3dd4f5c2a2917eac62e6527ecd1edcb400d
-
Run mypy over test/test_utils.py (#50278)
Summary: _resubmission of gh-49654, which was reverted due to a cross-merge conflict_ This caught one incorrect annotation in `cpp_extension.load`. xref gh-16574. Pull Request resolved: #50278 Reviewed By: walterddr Differential Revision: D25865278 Pulled By: ezyang fbshipit-source-id: 25489191628af5cf9468136db36f5a0f72d9d54d
-
Vulkan convolution touchups. (#50329)
Summary: Pull Request resolved: #50329 Test Plan: Imported from OSS Reviewed By: SS-JIA Differential Revision: D25869147 Pulled By: AshkanAliabadi fbshipit-source-id: b8f393330b68912506fdaefaf62a455dc192e36c
-
Format RPC files with clang-format (#50367)
Summary: Pull Request resolved: #50367 This had already been done by mrshenli on Friday (#50236, D25847892 (f9f758e)) but over the weekend Facebook's internal clang-format version got updated and this changed the format, hence we need to re-apply it. Note that this update also affected the JIT files, which are the other module enrolled in clang-format (see 8530c65, D25849205 (8530c65)). ghstack-source-id: 119656866 Test Plan: Shouldn't include functional changes. In any case, there's CI. Reviewed By: mrshenli Differential Revision: D25867720 fbshipit-source-id: 3723abc6c35831d7a8ac31f74baf24c963c98b9d
-
Move scalar_to_tensor_default_dtype out of ScalarOps.h because it's o…
-
[aten] embedding_bag_byte_rowwise_offsets_out (#49561)
Summary: Pull Request resolved: #49561 Out variant for embedding_bag_byte_rowwise_offsets Test Plan: ```MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 numactl -m 0 -C 3 ./buck-out/opt/gen/caffe2/caffe2/fb/predictor/ptvsc2_predictor_bench --scripted_model=/data/users/ansha/tmp/adindexer/merge/traced_merge_dper_fixes.pt --p t_inputs=/data/users/ansha/tmp/adindexer/merge/container_precomputation_bs1.pt --iters=30000 --warmup_iters=10000 --num_threads=1 --pred_net=/data/users/ansha/tmp/adindexer/precomputation_merge_net.pb --c2_inp uts=/data/users/ansha/tmp/adindexer/merge/c2_inputs_precomputation_bs1.pb --c2_sigrid_transforms_opt=1 --c2_use_memonger=1 --c2_apply_nomnigraph_passes --c2_weights=/data/users/ansha/tmp/adindexer/merge/c2_weig hts_precomputation.pb --pt_enable_static_runtime --pt_cleanup_activations=true --pt_enable_out_variant=true --compare_results --do_profile``` Check embedding_bag_byte_rowwise_offsets_out is called in perf Before: 0.081438 After: 0.0783725 Reviewed By: supriyar, hlu1 Differential Revision: D25620718 fbshipit-source-id: 83d5d0dd2e1f60c46e6727f73d5d8b52661b6767
-
[quant][graphmode][fx] Scope support for call_method in QuantizationT…
…racer (#50173) Summary: Pull Request resolved: #50173 Previously we did not set the qconfig for call_method node correctly since it requires us to know the scope (module path of the module whose forward graph contains the node) of the node. This PR modifies the QuantizationTracer to record the scope information and build a map from call_method Node to module path, which will be used when we construct qconfig_map Test Plan: python test/test_quantization.py TestQuantizeFx.test_qconfig_for_call_method Imported from OSS Reviewed By: vkuzo Differential Revision: D25818132 fbshipit-source-id: ee9c5830f324d24d7cf67e5cd2bf1f6e0e46add8
-
[FX} Implement wrap() by patching module globals during symtrace (#50182
) Summary: Pull Request resolved: #50182 Test Plan: Imported from OSS Reviewed By: pbelevich Differential Revision: D25819730 Pulled By: jamesr66a fbshipit-source-id: 274f4799ad589887ecf3b94f5c24ecbe1bc14b1b
-
[FX] Make graph target printouts more user-friendly (#50296)
Summary: Pull Request resolved: #50296 Test Plan: Imported from OSS Reviewed By: pbelevich Differential Revision: D25855288 Pulled By: jamesr66a fbshipit-source-id: dd725980fc492526861c2ec234050fbdb814caa8
-
[JIT] Ensure offset is a multiple of 4 to fix "Philox" RNG in jitted …
…kernels (#50169) Summary: Immediately-upstreamable part of #50148. This PR fixes what I'm fairly sure is a subtle bug with custom `Philox` class usage in jitted kernels. `Philox` [constructors in kernels](https://github.com/pytorch/pytorch/blob/68a6e4637903dba279c60daae5cff24e191ff9b4/torch/csrc/jit/codegen/cuda/codegen.cpp#L102) take the cuda rng generator's current offset. The Philox constructor then carries out [`offset/4`](https://github.com/pytorch/pytorch/blob/74c055b24065d0202aecdf4bc837d3698d1639e1/torch/csrc/jit/codegen/cuda/runtime/random_numbers.cu#L13) (a uint64_t division) to compute its internal offset in its virtual Philox bitstream of 128-bit chunks. In other words, it assumes the incoming offset is a multiple of 4. But (in current code) that's not guaranteed. For example, the increments used by [these eager kernels](https://github.com/pytorch/pytorch/blob/74c055b24065d0202aecdf4bc837d3698d1639e1/aten/src/ATen/native/cuda/Distributions.cu#L171-L216) could easily make offset not divisible by 4. I figured the easiest fix was to round all incoming increments up to the nearest multiple of 4 in CUDAGeneratorImpl itself. Another option would be to round the current offset up to the next multiple of 4 at the jit point of use. But that would be a jit-specific offset jump, so jit rng kernels wouldn't have a prayer of being bitwise accurate with eager rng kernels that used non-multiple-of-4 offsets. Restricting the offset to multiples of 4 for everyone at least gives jit rng the chance to match eager rng. (Of course, there are still many other ways the numerics could diverge, like if a jit kernel launches a different number of threads than an eager kernel, or assigns threads to data elements differently.) Pull Request resolved: #50169 Reviewed By: mruberry Differential Revision: D25857934 Pulled By: ngimel fbshipit-source-id: 43a75e2d0c8565651b0f12a5694c744fd86ece99
-
[quant][graphmode][fx] Support preserved_attributes in prepare_fx (#5…
-
Implement optimization bisect (#49031)
Summary: Pull Request resolved: #49031 Test Plan: Imported from OSS Reviewed By: nikithamalgifb Differential Revision: D25691790 Pulled By: tugsbayasgalan fbshipit-source-id: a9c4ff1142f8a234a4ef5b1045fae842c82c18bf
-
Fix elu backward operation for negative alpha (#49272)
Summary: Fixes #47671 Pull Request resolved: #49272 Test Plan: ``` x = torch.tensor([-2, -1, 0, 1, 2], dtype=torch.float32, requires_grad=True) y = torch.nn.functional.elu_(x.clone(), alpha=-2) grads = torch.tensor(torch.ones_like(y)) y.backward(grads) ``` ``` RuntimeError: In-place elu backward calculation is triggered with a negative slope which is not supported. This is caused by calling in-place forward function with a negative slope, please call out-of-place version instead. ``` Reviewed By: albanD Differential Revision: D25569839 Pulled By: H-Huang fbshipit-source-id: e3c6c0c2c810261566c10c0cc184fd81b280c650
-
Update op replacement tutorial (#50377)
Summary: Pull Request resolved: #50377 Test Plan: Imported from OSS Reviewed By: jamesr66a Differential Revision: D25870409 Pulled By: ansley fbshipit-source-id: b873b89c2e62b57cd5d816f81361c8ff31be2948
-
Add docstring for Proxy (#50145)
Summary: Pull Request resolved: #50145 Test Plan: Imported from OSS Reviewed By: pbelevich Differential Revision: D25854281 Pulled By: ansley fbshipit-source-id: d7af6fd6747728ef04e86fbcdeb87cb0508e1fd8
-
[JIT] Print better error when class attribute IValue conversion fails (…
…#50255) Summary: Pull Request resolved: #50255 **Summary** TorchScript classes are copied attribute-by-attribute from a py::object into a `jit::Object` in `toIValue`, which is called when copying objects from Python into TorchScript. However, if an attribute of the class cannot be converted, the error thrown is a standard pybind error that is hard to act on. This commit adds code to `toIValue` to convert each attribute to an `IValue` inside a try-catch block, throwing a `cast_error` containing the name of the attribute and the target type if the conversion fails. **Test Plan** This commit adds a unit test to `test_class_type.py` based on the code in the issue that commit fixes. **Fixes** This commit fixes #46341. Test Plan: Imported from OSS Reviewed By: pbelevich, tugsbayasgalan Differential Revision: D25854183 Pulled By: SplitInfinity fbshipit-source-id: 69d6e49cce9144af4236b8639d8010a20b7030c0
-
[JIT] Update clang-format hashes (#50399)
Summary: Pull Request resolved: #50399 **Summary** This commit updates the expected hashes of the `clang-format` binaries downloaded from S3. These binaries themselves have been updated due to having been updated inside fbcode. **Test Plan** Uploaded new binaries to S3, deleted `.clang-format-bin` and ran `clang_format_all.py`. Test Plan: Imported from OSS Reviewed By: seemethere Differential Revision: D25875184 Pulled By: SplitInfinity fbshipit-source-id: da483735de1b5f1dab7b070f91848ec5741f00b1
-
.circleci: Remove CUDA 9.2 binary build jobs (#50388)
Summary: Now that we support CUDA 11 we can remove support for CUDA 9.2 Signed-off-by: Eli Uriegas <eliuriegas@fb.com> Fixes #{issue number} Pull Request resolved: #50388 Reviewed By: zhangguanheng66 Differential Revision: D25872955 Pulled By: seemethere fbshipit-source-id: 1c10bcc8f4abbc1af1b3180b4cf4a9ea9c7104f9 -
Add link to tutorial in Timer doc (#50374)
Summary: Because I have a hard time finding this tutorial every time I need it. So I'm sure other people have the same issue :D Pull Request resolved: #50374 Reviewed By: zhangguanheng66 Differential Revision: D25872173 Pulled By: albanD fbshipit-source-id: f34f719606e58487baf03c73dcbd255017601a09
-
-
Raise warning during validation when arg_constraints not defined (#50302
) Summary: After we merged #48743, we noticed that some existing code that subclasses `torch.Distribution` started throwing `NotImplemenedError` since the constraints required for validation checks were not implemented. ```sh File "torch/distributions/distribution.py", line 40, in __init__ for param, constraint in self.arg_constraints.items(): File "torch/distributions/distribution.py", line 92, in arg_constraints raise NotImplementedError ``` This PR throws a UserWarning for such cases instead and gives a better warning message. cc. Balandat Pull Request resolved: #50302 Reviewed By: Balandat, xuzhao9 Differential Revision: D25857315 Pulled By: neerajprad fbshipit-source-id: 0ff9f81aad97a0a184735b1fe3a5d42025c8bcdf
-
[fix] Indexing.cu: Move call to C10_CUDA_KERNEL_LAUNCH_CHECK to make …
…it reachable (#49283) Summary: Fixes Compiler Warning: ``` aten/src/ATen/native/cuda/Indexing.cu(233): warning: loop is not reachable aten/src/ATen/native/cuda/Indexing.cu(233): warning: loop is not reachable aten/src/ATen/native/cuda/Indexing.cu(233): warning: loop is not reachable ``` Pull Request resolved: #49283 Reviewed By: zhangguanheng66 Differential Revision: D25874613 Pulled By: ngimel fbshipit-source-id: 6e384e89533c1d80f241b7b98fda239c357d1a2c
{kind=link}
{kind=link}
{kind=link}
Commits on Jan 12, 2021
-
Automated submodule update: tensorpipe (#50369)
Summary: This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe). New submodule commit: pytorch/tensorpipe@bc5ac93 Pull Request resolved: #50369 Test Plan: Ensure that CI jobs succeed on GitHub before landing. Reviewed By: mrshenli Differential Revision: D25867976 Pulled By: lw fbshipit-source-id: 5274aa424e3215b200dcb2c02f342270241dd77d
-
[GPU] Calculate strides for metal tensors (#50309)
Summary: Pull Request resolved: #50309 Previously, in order to unblock the dogfooding, we did some hacks to calculate the strides for the output tensor. Now it's time to fix that. ghstack-source-id: 119673688 Test Plan: 1. Sandcastle CI 2. Person segmentation results Reviewed By: AshkanAliabadi Differential Revision: D25821766 fbshipit-source-id: 8c067f55a232b7f102a64b9035ef54c72ebab4d4
-
Stop using an unnecessary scalar_to_tensor(..., device) call. (#50114)
Summary: Pull Request resolved: #50114 In this case, the function only dispatches on cpu anyway. Test Plan: Imported from OSS Reviewed By: mruberry Differential Revision: D25790155 Pulled By: gchanan fbshipit-source-id: 799dc9a3a38328a531ced9e85ad2b4655533e86a
-
Ensure DDP + Pipe works with find_unused_parameters. (#49908)
Summary: Pull Request resolved: #49908 As described in #49891, DDP + Pipe doesn't work with find_unused_parameters. This PR adds a simple fix to enable this functionality. This only currently works for Pipe within a single host and needs to be re-worked once we support cross host Pipe. ghstack-source-id: 119573413 Test Plan: 1) unit tests added. 2) waitforbuildbot Reviewed By: rohan-varma Differential Revision: D25719922 fbshipit-source-id: 948bcc758d96f6b3c591182f1ec631830db1b15c
-
-
[GPU] Fix the broken strides value for 2d transpose (#50310)
Summary: Pull Request resolved: #50310 Swapping the stride value is OK if the output tensor's storage stays in-contiguous. However, when we copy the result back to CPU, we expect to see a contiguous tensor. ``` >>> x = torch.rand(2,3) >>> x.stride() (3, 1) >>> y = x.t() >>> y.stride() (1, 3) >>> z = y.contiguous() >>> z.stride() (2, 1) ``` ghstack-source-id: 119692581 Test Plan: Sandcastle CI Reviewed By: AshkanAliabadi Differential Revision: D25823665 fbshipit-source-id: 61667c03d1d4dd8692b76444676cc393f808cec8
-
[GPU] Clean up the operator tests (#50311)
Summary: Pull Request resolved: #50311 Code clean up ghstack-source-id: 119693032 Test Plan: Sandcastle Reviewed By: husthyc Differential Revision: D25823635 fbshipit-source-id: 5205ebd8a5331c0d1825face034cca10e8b3b535
-
Pytorch Distributed RPC Reinforcement Learning Benchmark (Throughput …
…and Latency) (#46901) Summary: A Pytorch Distributed RPC benchmark measuring Agent and Observer Throughput and Latency for Reinforcement Learning Pull Request resolved: #46901 Reviewed By: mrshenli Differential Revision: D25869514 Pulled By: osandoval-fb fbshipit-source-id: c3b36b21541d227aafd506eaa8f4e5f10da77c78
-
Minor Fix: Double ";" typo in transformerlayer.h (#50300)
Summary: Fix double ";" typo in transformerlayer.h Pull Request resolved: #50300 Reviewed By: zhangguanheng66 Differential Revision: D25857236 Pulled By: glaringlee fbshipit-source-id: b9b21cfb3ddbff493f6d1c616abe21c5cfb9bce0
-
Fix warning when running scripts/build_ios.sh (#49457)
Summary: * Fixes `cmake implicitly converting 'string' to 'STRING' type` * Fixes `clang: warning: argument unused during compilation: '-mfpu=neon-fp16' [-Wunused-command-line-argument]` Pull Request resolved: #49457 Reviewed By: zhangguanheng66 Differential Revision: D25871014 Pulled By: malfet fbshipit-source-id: fa0c181ae7a1b8668e47f5ac6abd27a1c735ffce
-
[MacOS] Add unit tests for Metal ops (#50312)
Summary: Pull Request resolved: #50312 Integrate the operator tests to the MacOS playground app, so that we can run them on Sandcastle ghstack-source-id: 119693035 Test Plan: - `buck test pp-macos` - Sandcastle tests Reviewed By: AshkanAliabadi Differential Revision: D25778981 fbshipit-source-id: 8b5770dfddba0ca19f662894757b2dff66df87e6
-
[PyTorch] List::operator[] can return const ref for Tensor & string (#…
…50083) Summary: Pull Request resolved: #50083 This should supercede D21966183 (a371652) (#39763) and D22830381 (b44a10c) as the way to get fast access to the contents of a `torch::List`. ghstack-source-id: 119675495 Reviewed By: smessmer Differential Revision: D25776232 fbshipit-source-id: 81b4d649105ac9e08fc2c6563806f883809872f4
-
Fix PyTorch NEON compilation with gcc-7 (#50389)
Summary: Apply sebpop patch to correctly inform optimizing compiler about side-effect of missing neon restrictions Allow vec256_float_neon to be used even if compiled by gcc-7 Fixes #47098 Pull Request resolved: #50389 Reviewed By: walterddr Differential Revision: D25872875 Pulled By: malfet fbshipit-source-id: 1fc5dfe68fbdbbb9bfa79ce4be2666257877e85f
-
warn user once for possible unnecessary find_unused_params (#50133)
Summary: Pull Request resolved: #50133 `find_unused_parameters=True` is only needed when the model has unused parameters that are not known at model definition time or differ due to control flow. Unfortunately, many DDP users pass this flag in as `True` even when they do not need it, sometimes as a precaution to mitigate possible errors that may be raised (such as the error we raise with not using all outputs).While this is a larger issue to be fixed in DDP, it would also be useful to warn once if we did not detect unused parameters. The downside of this is that in the case of flow control models where the first iteration doesn't have unused params but the rest do, this would be a false warning. However, I think the warning's value exceeds this downside. ghstack-source-id: 119707101 Test Plan: CI Reviewed By: pritamdamania87 Differential Revision: D25411118 fbshipit-source-id: 9f4a18ad8f45e364eae79b575cb1a9eaea45a86c
-
[doc] fix doc formatting for
torch.randpermand `torch.repeat_inter… -
Migrate some torch.fft tests to use OpInfos (#48428)
Summary: Pull Request resolved: #48428 Test Plan: Imported from OSS Reviewed By: ngimel Differential Revision: D25868666 Pulled By: mruberry fbshipit-source-id: ca6d0c4e44f4c220675dc264a405d960d4b31771
-
Cleanup unnecessary SpectralFuncInfo logic (#48712)
Summary: Pull Request resolved: #48712 Test Plan: Imported from OSS Reviewed By: ngimel Differential Revision: D25868675 Pulled By: mruberry fbshipit-source-id: 90b32b27d9a3d79c3754c4a1c0747dbe0f140192
-
test_ops: Only run complex gradcheck when complex is supported (#49018)
Summary: Pull Request resolved: #49018 Test Plan: Imported from OSS Reviewed By: ngimel Differential Revision: D25868683 Pulled By: mruberry fbshipit-source-id: d8c4d89c11939fc7d81db8190ac6b9b551e4cbf5
-
remove redundant tests from tensor_op_tests (#50096)
Summary: All these Unary operators have been an entry in OpInfo DB. Pull Request resolved: #50096 Reviewed By: zhangguanheng66 Differential Revision: D25870048 Pulled By: mruberry fbshipit-source-id: b64e06d5b9ab5a03a202cda8c22fdb7e4ae8adf8
-
Fix Error with torch.flip() for cuda tensors when dims=() (#50325)
Summary: Fixes #49982 The method flip_check_errors was being called in cuda file which had a condition to throw an exception for when dims size is <=0 changed that to <0 and added seperate condition for when equal to zero to return from the method... the return was needed because after this point the method was performing check expecting a non-zero size dims ... Also removed the comment/condition written to point to the issue mruberry kshitij12345 please review this once Pull Request resolved: #50325 Reviewed By: zhangguanheng66 Differential Revision: D25869559 Pulled By: mruberry fbshipit-source-id: a831df9f602c60cadcf9f886ae001ad08b137481
-
Summary: This PR adds `torch.linalg.pinv`. Changes compared to the original `torch.pinverse`: * New kwarg "hermitian": with `hermitian=True` eigendecomposition is used instead of singular value decomposition. * `rcond` argument can now be a `Tensor` of appropriate shape to apply matrix-wise clipping of singular values. * Added `out=` variant (allocates temporary and makes a copy for now) Ref. #42666 Pull Request resolved: #48399 Reviewed By: zhangguanheng66 Differential Revision: D25869572 Pulled By: mruberry fbshipit-source-id: 0f330a91d24ba4e4375f648a448b27594e00dead
-
add type annotations to torch.nn.modules.normalization (#49035)
Summary: Fixes #49034 Pull Request resolved: #49035 Test Plan: Imported from GitHub, without a `Test Plan:` line. Force rebased to deal with merge conflicts Reviewed By: zhangguanheng66 Differential Revision: D25767065 Pulled By: walterddr fbshipit-source-id: ffb904e449f137825824e3f43f3775a55e9b011b
-
Disable complex dispatch on min/max functions (#50347)
Summary: Fixes #50064 **PROBLEM:** In issue #36377, min/max functions were disabled for complex inputs (via dtype checks). However, min/max kernels are still being compiled and dispatched for complex. **FIX:** The aforementioned dispatch has been disabled & we now rely on errors produced by dispatch macro to not run those ops on complex, instead of doing redundant dtype checks. Pull Request resolved: #50347 Reviewed By: zhangguanheng66 Differential Revision: D25870385 Pulled By: anjali411 fbshipit-source-id: 921541d421c509b7a945ac75f53718cd44e77df1
-
Enable fast pass tensor_fill for single element complex tensors (#50383)
Summary: Pull Request resolved: #50383 Test Plan: Imported from OSS Reviewed By: heitorschueroff Differential Revision: D25879881 Pulled By: anjali411 fbshipit-source-id: a254cff48ea9a6a38f7ee206815a04c31a9bcab0
-
Add new patterns for ConcatAddMulReplaceNaNClip (#50249)
Summary: Pull Request resolved: #50249 Add a few new patterns for `ConcatAddMulReplaceNanClip` Reviewed By: houseroad Differential Revision: D25843126 fbshipit-source-id: d4987c716cf085f2198234651a2214591d8aacc0
-
[PyTorch] Devirtualize TensorImpl::sizes() with macro (#50176)
Summary: Pull Request resolved: #50176 UndefinedTensorImpl was the only type that overrode this, and IIUC we don't need to do it. ghstack-source-id: 119609531 Test Plan: CI, internal benchmarks Reviewed By: ezyang Differential Revision: D25817370 fbshipit-source-id: 985a99dcea2e0daee3ca3fc315445b978f3bf680
-
[JIT] Frozen Graph Conv-BN fusion (#50074)
Summary: Pull Request resolved: #50074 Adds Conv-BN fusion for models that have been frozen. I haven't explicitly tested perf yet but it should be equivalent to the results from Chillee's PR [here](https://github.com/pytorch/pytorch/pull/476570) and [here](#47657 (comment)). Click on the PR for details but it's a good speed up. In a later PR in the stack I plan on making this optimization on by default as part of `torch.jit.freeze`. I will also in a later PR add a peephole so that there is not conv->batchnorm2d doesn't generate a conditional checking # dims. Zino was working on freezing and left the team, so not really sure who should be reviewing this, but I dont care too much so long as I get a review � Test Plan: Imported from OSS Reviewed By: tugsbayasgalan Differential Revision: D25856261 Pulled By: eellison fbshipit-source-id: da58c4ad97506a09a5c3a15e41aa92bdd7e9a197
-
[JIT] Add Frozen Conv-> Add/Sub/Mul/Div fusion (#50075)
Summary: Pull Request resolved: #50075 Adds Conv - Add/Sub/Mul/Div fusion for frozen models. This helps cover models like torchvision maskrcnn, which use a hand-rolled batchnorm implementation: https://github.com/pytorch/vision/blob/90645ccd0e774ad76200245e32222a23d09f2312/torchvision/ops/misc.py#L45. I haven't tested results yet but I would expect a somewhat similar speed up as conv-bn fusion (maybe a little less). Test Plan: Imported from OSS Reviewed By: tugsbayasgalan Differential Revision: D25856265 Pulled By: eellison fbshipit-source-id: 2c36fb831a841936fe4446ed440185f59110bf68
-
[JIT] Factor out peephole to own test file (#50220)
Summary: Pull Request resolved: #50220 Test Plan: Imported from OSS Reviewed By: tugsbayasgalan Differential Revision: D25856263 Pulled By: eellison fbshipit-source-id: f3d918d860e64e788e0bb9b9cb85125660f834c6
-
Peephole Optimize out conv(x).dim(), which prevents BN fusion (#50221)
Summary: Pull Request resolved: #50221 Test Plan: Imported from OSS Reviewed By: tugsbayasgalan Differential Revision: D25856266 Pulled By: eellison fbshipit-source-id: ef7054b3d4ebc59a0dd129116d29273be33fe12c
-
Add Post Freezing Optimizations, turn on by default in torch.jit.free…
…ze (#50222) Summary: Pull Request resolved: #50222 This PR adds a pass which runs a set of optimizations to be done after freezing. Currently this encompasses Conv-BN folding, Conv->Add/Sub/Mul/Div folding and i'm also planning on adding dropout removal. I would like some feedback on the API. torch.jit.freeze is technically in \~prototype\~ phase so we have some leeway around making changes. I think in the majority of cases, the user is going to want to freeze their model, and then run in inference. I would prefer if the optimization was opt-out instead of opt-in. All internal/framework use cases of freezing all use `freeze_module`, not the python API, so this shouldn't break anything. I have separated out the optimization pass as a separate API to make things potentially modular, even though I suspect that is an unlikely case. In a future PR i would like to add a `torch::jit::freeze` which follows the same api as `torch.jit.freeze` intended for C++ use, and runs the optimizations. Test Plan: Imported from OSS Reviewed By: tugsbayasgalan Differential Revision: D25856264 Pulled By: eellison fbshipit-source-id: 56be1f12cfc459b4c4421d4dfdedff8b9ac77112
-
-
[vmap] Add batching rules for comparisons ops (#50364)
Summary: Related to #49562 This PR adds batching rules for the below comparison ops. - torch.eq - torch.gt - torch.ge - torch.le - torch.lt - torch.ne Pull Request resolved: #50364 Reviewed By: anjali411 Differential Revision: D25885359 Pulled By: zou3519 fbshipit-source-id: 58874f24f8d525d8fac9062186b1c9970618ff55
-
Check CUDA kernel launches in caffe2/caffe2/utils/math (#50238)
Summary: Pull Request resolved: #50238 Added `C10_CUDA_KERNEL_LAUNCH_CHECK();` after all kernel launches in caffe2/caffe2/utils/math Test Plan: ``` buck build //caffe2/caffe2 ``` {F356531214} files in caffe2/caffe2/utils/math no longer show up when running ``` python3 caffe2/torch/testing/check_kernel_launches.py ``` Reviewed By: r-barnes Differential Revision: D25773299 fbshipit-source-id: 28d67b4b9f57f1fa1e8699e43e9202bad4d42c5f
-
Clean up some type annotations in test/jit/...../test_class_type.py (#…
-
Stop moving scalars to GPU for one computation in leaky_rrelu_backwar…
…d. (#50115) Summary: Pull Request resolved: #50115 There is no way this is performant and we are trying to minimize the usage of scalar_to_tensor(..., device) since it is an anti-pattern, see #49758. Test Plan: Imported from OSS Reviewed By: mruberry Differential Revision: D25790331 Pulled By: gchanan fbshipit-source-id: 89d6f016dfd76197541b0fd8da4a462876dbf844
-
fixing autodiff to support Optional[Tensor] on inputs (#49430)
Summary: This PR fixes two local issue for me: 1. Assert failure when passing `None` to `Optional[Tensor]` input that requires gradient in autodiff 2. Wrong vjp mapping on inputs when `requires_grad` flag changes on inputs stack. This PR is to support autodiff on layer_norm. Pull Request resolved: #49430 Reviewed By: izdeby Differential Revision: D25886211 Pulled By: eellison fbshipit-source-id: 075af35a4a9c0b911838f25146f859897f9a07a7
-
[package] better error message when unpickling a mocked obj (#50159)
Summary: Pull Request resolved: #50159 Test Plan: Imported from OSS Reviewed By: tugsbayasgalan Differential Revision: D25809551 Pulled By: suo fbshipit-source-id: 130587e650271cf158f5f5d9e688c622c9006631
-
Automated submodule update: tensorpipe (#50441)
Summary: This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe). New submodule commit: pytorch/tensorpipe@ac98f40 Pull Request resolved: #50441 Test Plan: Ensure that CI jobs succeed on GitHub before landing. Reviewed By: mrshenli Differential Revision: D25888666 fbshipit-source-id: fd447f81462f476c62aed0e43830a710f60187e1
-
[quant][bug] Fixing the mapping getter to return a copy (#50297)
Summary: Pull Request resolved: #50297 Current implementation has a potential bug: if a user modifies the quantization mappings returned by the getters, the changes will propagate. For example, the bug will manifest itself if the user does the following: ``` my_mapping = get_default_static_quant_module_mappings() my_mapping[nn.Linear] = UserLinearImplementation model_A = convert(model_A, mapping=my_mapping) default_mapping = get_default_static_quant_module_mappings() model_B = convert(model_B, mapping=default_mapping) ``` In that case the `model_B` will be quantized with with the modified mapping. Test Plan: Imported from OSS Reviewed By: vkuzo Differential Revision: D25855753 Pulled By: z-a-f fbshipit-source-id: 0149a0c07a965024ba7d1084e89157a9c8fa1192
-
[quant][refactor] Minor refactor of some typos (#50304)
Summary: Pull Request resolved: #50304 Does not include any functional changes -- purely for fixing minor typos in the `fuser_method_mappings.py` Test Plan: Imported from OSS Reviewed By: jerryzh168 Differential Revision: D25857248 Pulled By: z-a-f fbshipit-source-id: 3f9b864b18bda8096e7cd52922dc21be64278887
-
[te] Create TargetMachine only once with correct options to fix perf (#…
…50406) Summary: Pull Request resolved: #50406 We were creating different TMs in PytorchLLVMJIT and LLVMCodeGen; the one in LLVMCodeGen had the right target-specific options to generate fast AVX2 code (with FMAs, vbroadcastss, etc.), and that's what was showing up in the debug output, but the LLVMJIT TM was the one that actually generated runtime code, and it was slow. ghstack-source-id: 119700110 Test Plan: ``` buck run mode/opt //caffe2/benchmarks/fb/tensorexpr:tensorexpr_bench ``` With this diff NNC is getting at least somewhat (5%) close to Pytorch with MKL, for at least this one small-ish test case" ``` Run on (24 X 2394.67 MHz CPU s) 2021-01-11 15:57:27 ---------------------------------------------------------------------------------------------------- Benchmark Time CPU Iterations UserCounters... ---------------------------------------------------------------------------------------------------- Gemm/Torch/128/128/128 65302 ns 65289 ns 10734 GFLOPS=64.2423G/s Gemm/TensorExprTile4x16VecUnroll/128/128/128 68602 ns 68599 ns 10256 GFLOPS=61.1421G/s ``` Reviewed By: bwasti Differential Revision: D25877605 fbshipit-source-id: cd293bac94d025511f348eab5c9b8b16bf6505ec
-
Commits on Jan 13, 2021
-
Create subgraph rewriter (#49540)
Summary: Pull Request resolved: #49540 Test Plan: Imported from OSS Reviewed By: pbelevich Differential Revision: D25869707 Pulled By: ansley fbshipit-source-id: 93d3889f7ae2ecc5e8cdd7f4fb6b0446dbb3cb31
-
Type annotations in test/jit (#50293)
Summary: Pull Request resolved: #50293 Switching to type annotations for improved safety and import tracking. Test Plan: Sandcastle tests Reviewed By: xush6528 Differential Revision: D25853949 fbshipit-source-id: fb873587bb521a0a55021ee4d34d1b05ea8f000d
-
[Pytorch Mobile] Remove caching (in code) of interned strings (#50390)
Summary: Pull Request resolved: #50390 Currently, there is a massive switch/case statement that is generated in the `InternedStrings::string()` method to speed up Symbol -> string conversion without taking a lock (mutex). The relative call rate of this on mobile is insignificant, so unlikely to have any material impact on runtime even if the lookups happen under a lock. Plus, parallelism is almost absent on mobile, which is where locks/mutexes cause the most problem (taking a mutex without contention is usually very fast and just adds a memory barrier iirc). The only impact that caching interned strings has is avoiding taking a lock when interned strings are looked up. They are not looked up very often during training, and based on basic testing, they don't seem to be looked up much during inference either. During training, the following strings were looked up at test startup: ``` prim::profile prim::profile_ivalue prim::profile_optional prim::FusionGroup prim::TypeCheck prim::FallbackGraph prim::ChunkSizes prim::ConstantChunk prim::tolist prim::FusedConcat prim::DifferentiableGraph prim::MMBatchSide prim::TensorExprGroup ``` Command used to trigger training: `buck test fbsource//xplat/papaya/client/executor/torch/store/transform/feature/test:test` During inference, the only symbol that was looked up was `tolist`. ghstack-source-id: 119679831 Test Plan: See the summary above + sandcastle tests. ### Size test: fbios ``` D25861786-V1 (https://www.internalfb.com/intern/diff/D25861786/?dest_number=119641372) fbios: Succeeded Change in Download Size for arm64 + 3x assets variation: -13.9 KiB Change in Uncompressed Size for arm64 + 3x assets variation: -41.7 KiB Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:747386759232352@base/bsb:747386759232352@diff/ ``` ### Size test: igios ``` D25861786-V1 (https://www.internalfb.com/intern/diff/D25861786/?dest_number=119641372) igios: Succeeded Change in Download Size for arm64 + 3x assets variation: -16.6 KiB Change in Uncompressed Size for arm64 + 3x assets variation: -42.0 KiB Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:213166470538954@base/bsb:213166470538954@diff/ ``` Reviewed By: iseeyuan Differential Revision: D25861786 fbshipit-source-id: 34a55d693edc41537300f628877a64723694f8f0
-
Caffe2 Concat operator benchmark (#50449)
Summary: Pull Request resolved: #50449 Port caffe2 operator benchmark from torch.cat to caffe2 concat to measure the difference in performance. previous diff abandoned to rerun github CI tests. D25738076 Test Plan: Tested on devbig by running both pt and c2 benchmarks. Compiled with mode/opt Inputs: ``` size, number of inputs, cat dimension, device ---------------------------------------------------- (1, 1, 1), N: 2, dim: 0, device: cpu (512, 512, 2), N: 2, dim: 1, device: cpu (128, 1024, 2), N: 2, dim: 1, device: cpu (1024, 1024, 2), N: 2, dim: 0, device: cpu (1025, 1023, 2), N: 2, dim: 1, device: cpu (1024, 1024, 2), N: 2, dim: 2, device: cpu [<function <lambda> at 0x7f922718e8c0>, 111, 65], N: 5, dim: 0, device: cpu [96, <function <lambda> at 0x7f9226dad710>, 64], N: 5, dim: 1, device: cpu [128, 64, <function <lambda> at 0x7f91a3625ef0>], N: 5, dim: 2, device: cpu [<function <lambda> at 0x7f91a3625f80>, 32, 64], N: 50, dim: 0, device: cpu [32, <function <lambda> at 0x7f91a3621050>, 64], N: 50, dim: 1, device: cpu [33, 65, <function <lambda> at 0x7f91a36210e0>], N: 50, dim: 2, device: cpu (64, 32, 4, 16, 32), N: 2, dim: 2, device: cpu (16, 32, 4, 16, 32), N: 8, dim: 2, device: cpu (9, 31, 5, 15, 33), N: 17, dim: 4, device: cpu [<function <lambda> at 0x7f91a3621170>], N: 100, dim: 0, device: cpu [<function <lambda> at 0x7f91a3621200>], N: 1000, dim: 0, device: cpu [<function <lambda> at 0x7f91a3621290>], N: 2000, dim: 0, device: cpu [<function <lambda> at 0x7f91a3621320>], N: 3000, dim: 0, device: cpu ``` ``` pytorch: MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 buck-out/gen/caffe2/benchmarks/operator_benchmark/pt/cat_test.par --tag_filter=all caffe2: MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 buck-out/gen/caffe2/benchmarks/operator_benchmark/c2/concat_test.par --tag_filter=all ``` ``` Metric: Forward Execution Time (us) pytorch | caffe2 -------------------------------- 4.066 | 0.312 351.507 | 584.033 184.649 | 292.157 9482.895 | 6845.112 9558.988 | 6847.511 13730.016 | 14118.505 6324.371 | 4840.883 4613.497 | 3702.213 7504.718 | 7889.751 9882.978 | 7364.350 10087.076 | 7483.178 16849.556 | 18092.295 19181.075 | 13363.742 19296.508 | 13466.863 34157.449 | 56320.073 176.483 | 267.106 322.247 | 352.782 480.064 | 460.214 607.381 | 476.908 ``` Reviewed By: hlu1 Differential Revision: D25890595 fbshipit-source-id: f53e125c0680bc2ebf722d1da5ec964bec585fdd
-
[StaticRuntime][ATen] Add out variant for narrow_copy (#49502)
Summary: Pull Request resolved: #49502 It broke the OSS CI the last time I landed it, mostly cuda tests and python bindings. Similar to permute_out, add the out variant of `aten::narrow` (slice in c2) which does an actual copy. `aten::narrow` creates a view, however, an copy is incurred when we call `input.contiguous` in the ops that follow `aten::narrow`, in `concat_add_mul_replacenan_clip`, `casted_batch_one_hot_lengths`, and `batch_box_cox`. {F351263599} Test Plan: Unit test: ``` buck test //caffe2/aten:math_kernel_test buck test //caffe2/test:sparse -- test_narrow ``` Benchmark with the adindexer model: ``` bs = 1 is neutral Before: I1214 21:32:51.919239 3285258 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.0886948. Iters per second: 11274.6 After: I1214 21:32:52.492352 3285277 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.0888019. Iters per second: 11261 bs = 20 shows more gains probably because the tensors are bigger and therefore the cost of copying is higher Before: I1214 21:20:19.702445 3227229 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.527563. Iters per second: 1895.51 After: I1214 21:20:20.370173 3227307 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.508734. Iters per second: 1965.67 ``` Reviewed By: ajyu Differential Revision: D25596290 fbshipit-source-id: da2f5a78a763895f2518c6298778ccc4d569462c
-
Change watchdog timeout logging from INFO to ERROR. (#50455)
Summary: Pull Request resolved: #50455 Certain systems only print logging messages for ERROR/WARN and the error message that the watchdog is timing out a particular operation is pretty important. As a result, changing its level to ERROR instead of INFO. ghstack-source-id: 119761029 Test Plan: waitforbuildbot Reviewed By: rohan-varma Differential Revision: D25894795 fbshipit-source-id: 259b16c13f6cdf9cb1956602d15784b92aa53f17
-
Add torch.cuda.can_device_access_peer (#50446)
Summary: And unrelying torch._C._cuda_canDeviceAccessPeer, which is a wrapper around cudaDeviceCanAccessPeer Pull Request resolved: #50446 Reviewed By: mrshenli Differential Revision: D25890405 Pulled By: malfet fbshipit-source-id: ef09405f115bbe73ba301d608d56cd8f8453201b
-
Fix
fmodtype promotion (#48278)Summary: Pull Request resolved: #48278 Remove various lines from tests due to no type promotion introduced from #47323 ## BC-breaking Note: In order to make `fmod` operator have type promotion, we have to introduce BC breaking. ### 1.7.1: In the case where the second argument is a python number, the result is casted to the dtype of the first argument. ```python >>> torch.fmod(x, 1.2) tensor([0, 0, 0, 0, 0], dtype=torch.int32) ``` ### Prior PR: Check the BC-breaking note of #47323 ### This PR: In the case where the second argument is a python number, the dtype of result is determined by type promotion of both inputs. ```python >>> torch.fmod(x, 1.2) tensor([1.0000, 0.8000, 0.6000, 0.4000, 0.2000]) ``` Test Plan: Imported from OSS Reviewed By: mruberry Differential Revision: D25869137 Pulled By: ejguan fbshipit-source-id: bce763926731e095b75daf2e934bff7c03ff0832
-
Fix remainder type promotion (#48668)
Summary: Pull Request resolved: #48668 Combine tests for `fmod` and `remainder`. ## BC-breaking Note: In order to make `remainder` operator have type promotion, we have to introduce BC breaking. ### 1.7.1: In the case where the second argument is a python number, the result is casted to the dtype of the first argument. ```python >>> torch.remainder(x, 1.2) tensor([0, 0, 0, 0, 0], dtype=torch.int32) ``` ### This PR: In the case where the second argument is a python number, the dtype of result is determined by type promotion of both inputs. ```python >>> torch.remainder(x, 1.2) tensor([1.0000, 0.8000, 0.6000, 0.4000, 0.2000]) ``` Test Plan: Imported from OSS Reviewed By: mruberry Differential Revision: D25869136 Pulled By: ejguan fbshipit-source-id: 8e5e87eec605a15060f715952de140f25644008c
-
[PyTorch] Gate tls_local_dispatch_key_set inlining off for Android (#…
-
[doc] Add note about
torch.flipreturning new tensor and not view. (#… -
Summary: The failure is: ``` ______________________________________________________________________________________________________ TestCommonCUDA.test_variant_consistency_jit_fft_rfft_cuda_float64 _______________________________________________________________________________________________________ ../.local/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py:889: in wrapper method(*args, **kwargs) ../.local/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py:889: in wrapper method(*args, **kwargs) ../.local/lib/python3.9/site-packages/torch/testing/_internal/common_device_type.py:267: in instantiated_test if op is not None and op.should_skip(generic_cls.__name__, name, _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ self = <torch.testing._internal.common_methods_invocations.SpectralFuncInfo object at 0x7f7375f9b550>, cls_name = 'TestCommon', test_name = 'test_variant_consistency_jit', device_type = 'cuda', dtype = torch.float64 def should_skip(self, cls_name, test_name, device_type, dtype): > for si in self.skips: E TypeError: 'NoneType' object is not iterable ../.local/lib/python3.9/site-packages/torch/testing/_internal/common_methods_invocations.py:186: TypeError ``` Pull Request resolved: #50435 Reviewed By: izdeby Differential Revision: D25886650 Pulled By: mruberry fbshipit-source-id: 722a45247dc79be86858306cd1b51b0a63df8b37 -
[AutoAccept][Codemod][FBSourceClangFormatLinter] Daily `arc lint --ta…
…ke CLANGFORMAT` Reviewed By: zertosh Differential Revision: D25896704 fbshipit-source-id: c6b112db889aaf31996929829e4989f9562964da
-
Fix TORCH_LIBRARIES variables when do static build (#49458)
Summary: Fixes #21737 With this fix, TORCH_LIBRARIES variable can provide all nessesary static libraries build from pytorch repo. User program (if do static build) now can just link with ${TORCH_LIBRARIES} + MKL + cuda runtime. Pull Request resolved: #49458 Reviewed By: mrshenli Differential Revision: D25895354 Pulled By: malfet fbshipit-source-id: 8ff47d14ae1f90036522654d4354256ed5151e5c
-
Enables build with oneDNN (MKL-DNN) on AArch64 (#50400)
Summary: Since version 1.6, oneDNN has provided limited support for AArch64 builds. This minor change is to detect an AArch64 CPU and permit the use of `USE_MKLDNN` in that case. Build flags for oneDNN are also modified accordingly. Note: oneDNN on AArch64, by default, will use oneDNN's reference C++ kernels. These are not optimised for AArch64, but oneDNN v1.7 onwards provides support for a limited set of primitives based Arm Compute Library. See: oneapi-src/oneDNN#795 and: oneapi-src/oneDNN#820 for more details. Support for ACL-based oneDNN primitives in PyTorch will require some further modification, Fixes #{issue number} Pull Request resolved: #50400 Reviewed By: izdeby Differential Revision: D25886589 Pulled By: malfet fbshipit-source-id: 2c81277a28ad4528c2d2211381e7c6692d952bc1
-
MAINT: char class regex simplify (#50294)
Summary: * remove some cases of single characters in character classes--these can incur the overhead of a character class with none of the benefits of a multi-character character class * for more details, see Chapter 6 of: Friedl, Jeffrey. Mastering Regular Expressions. 3rd ed., O’Reilly Media, 2009. Pull Request resolved: #50294 Reviewed By: zhangguanheng66 Differential Revision: D25870912 Pulled By: malfet fbshipit-source-id: 9be5be9ed11fd49876213f0be8121b24739f1c13
-
Summary: Pull Request resolved: #50393 Exponential Moving Average Usage: add ema_options in adagrad optimizer. For details, plz refer to the test workflow setting. if ema_end == -1, it means ema will never end. Test Plan: buck test caffe2/caffe2/fb/optimizers:ema_op_optimizer_test buck test caffe2/caffe2/fb/optimizers:ema_op_test f240459719 Differential Revision: D25416056 fbshipit-source-id: a25e676a364969e3be2bc47750011c812fc3a62f
-
Clean up some type annotations in benchmarks/fastrnns (#49946)
Summary: Pull Request resolved: #49946 Upgrades type annotations from Python2 to Python3 Test Plan: Sandcastle tests Reviewed By: xush6528 Differential Revision: D25717510 fbshipit-source-id: 4f6431d140e3032b4ca55587f9602aa0ea38c671
-
Clean up some type annotations in caffe2/test (#49943)
Summary: Pull Request resolved: #49943 Upgrades type annotations from Python2 to Python3 Test Plan: Sandcastle tests Reviewed By: xush6528 Differential Revision: D25717534 fbshipit-source-id: 5aedea4db07efca126ffb6daee79617c30a67146
-
[BE] replace unittest.main with run_tests (#50451)
Summary: fix #50448. This replaces all `test/*.py` files with run_tests(). This PR does not address test files in the subdirectories because they seems unrelated. Pull Request resolved: #50451 Reviewed By: janeyx99 Differential Revision: D25899924 Pulled By: walterddr fbshipit-source-id: f7c861f0096624b2791ad6ef6a16b1c4895cce71
-
Update loss module doc (#48596)
Summary: Fixes #{issue number} Pull Request resolved: #48596 Reviewed By: izdeby Differential Revision: D25889748 Pulled By: zou3519 fbshipit-source-id: 9f6e77ba2af4030c8b9ae4afcea6d002a4dae423 -
Fix TestOpInfoCUDA.test_unsupported_dtypes_addmm_cuda_bfloat16 on amp…
…ere (#50440) Summary: The `TestOpInfoCUDA.test_unsupported_dtypes_addmm_cuda_bfloat16` in `test_ops.py` is failing on ampere. This is because addmm is supported on Ampere, but the test is asserting that it is not supported. Pull Request resolved: #50440 Reviewed By: mrshenli Differential Revision: D25893326 Pulled By: ngimel fbshipit-source-id: afeec25fdd76e7336d84eb53ea36319ade1ab421
-
[te] Benchmark comparing fused overhead to unfused (#50305)
Summary: Pull Request resolved: #50305 That's it ghstack-source-id: 119631533 Test Plan: ``` buck run //caffe2/benchmarks/cpp/tensorexpr:tensorexpr_bench -- --benchmark_filter=Overhead ``` ``` Run on (24 X 2394.67 MHz CPU s) 2021-01-08 16:06:17 ------------------------------------------------------- Benchmark Time CPU Iterations ------------------------------------------------------- FusedOverhead 2157 ns 2157 ns 311314 UnfusedOverhead 2443 ns 2443 ns 311221 ``` Reviewed By: ZolotukhinM Differential Revision: D25856891 fbshipit-source-id: 0e99515ec2e769a04929157d46903759c03182a3
-
[te] Optimize allocation of kernel outputs (#50318)
Summary: Pull Request resolved: #50318 We can skip the dispatcher and go to the device-specific `at::native::empty_strided` implementation. Also, unpacking the TensorOptions struct at kernel launch time actually takes a bit of work, since the optionals are encoded in a bitfield. Do this upfront and use the optionals directly at runtime. ghstack-source-id: 119735738 Test Plan: Before: ``` ------------------------------------------------------- Benchmark Time CPU Iterations ------------------------------------------------------- FusedOverhead 2143 ns 2142 ns 332946 UnfusedOverhead 2277 ns 2276 ns 315130 ``` After: ``` ------------------------------------------------------- Benchmark Time CPU Iterations ------------------------------------------------------- FusedOverhead 2175 ns 2173 ns 321877 UnfusedOverhead 2394 ns 2394 ns 307360 ``` (The noise in the baseline makes this really hard to read, it seemed to be about 3-5% faster in my local testing) Reviewed By: eellison Differential Revision: D25859132 fbshipit-source-id: 8753289339e365f78c790bee076026cd649b8509
-
Summary: Pull Request resolved: #49972 From ``` ./python/libcst/libcst codemod remove_unused_imports.RemoveUnusedImportsWithGlean --no-format caffe2/ ``` Test Plan: Standard sandcastle tests Reviewed By: xush6528 Differential Revision: D25727352 fbshipit-source-id: 6b90717e161aeb1da8df30e67d586101d35d7d5f
-
Exclude test/generated_type_hints_smoketest.py from flake8 (#50497)
Summary: Similar to #48201, this PR excludes a file that is auto-generated by [`test/test_type_hints.py`](https://github.com/pytorch/pytorch/blob/5834438090a1b3206347e30968e48f44251a53a1/test/test_type_hints.py#L109-L111), which doesn't happen to be run before the Flake8 check is done in CI. Also, because the `exclude` list in `.flake8` has gotten fairly long, this PR splits it across multiple lines. Pull Request resolved: #50497 Test Plan: Run this in your shell: ```sh python test/test_type_hints.py TestTypeHints.test_doc_examples flake8 ``` - _Before:_ `flake8` prints [these 169 false positives](https://pastebin.com/qPJY24g8) and returns exit code 1 - _After:_ `flake8` prints no output and returns exit code 0 Reviewed By: mrshenli Differential Revision: D25903177 Pulled By: samestep fbshipit-source-id: 21f757ac8bfa626bb56ece2ecc55668912b71234
-
Remove a blacklist reference (#50477)
Summary: Pull Request resolved: #50477 See task for context Test Plan: Sandcastle+OSS tests Reviewed By: xush6528 Differential Revision: D25893906 fbshipit-source-id: c9b86d0292aa751597d75e8d1b53f99b99c924b9
-
[ONNX] ONNX dev branch merge 01-06-2021 (#50163)
Summary: [ONNX] ONNX dev branch merge 01-06-2021 - [ONNX] Support onnx if/loop sequence output in opset 13 - (#49270) - Symbolic function for torch.square (#49446) - [ONNX] Add checks in ONNXSetDynamicInputShape (#49783) … - [ONNX] Enable export af aten::__derive_index (#49514) … - [ONNX] Update symbolic for unfold (#49378) … - [ONNX] Update the sequence of initializers in exported graph so that it is as same as inputs. (#49798) - [ONNX] Enable opset 13 ops (#49612) … - [ONNX] Improve error message for supported model input types in ONNX export API. (#50119) - [ONNX] Add a post-pass for If folding (#49410) Pull Request resolved: #50163 Reviewed By: pbelevich Differential Revision: D25821059 Pulled By: SplitInfinity fbshipit-source-id: 9f511a93d9d5812d0ab0a49d61ed0fa5f8066948
-
[FX] Make FX stability warning reference beta (#50394)
Summary: Pull Request resolved: #50394 Test Plan: Imported from OSS Reviewed By: Chillee Differential Revision: D25874188 Pulled By: jamesr66a fbshipit-source-id: 4fc4e72fec1f3fab770d870fe78cd4ad0f1d6888
-
[FX] Update docstring code/graph printout (#50396)
Summary: Pull Request resolved: #50396 Test Plan: Imported from OSS Reviewed By: Chillee Differential Revision: D25874253 Pulled By: jamesr66a fbshipit-source-id: 6217eadbcbe823db14df25070eef411e184c2273
-
[PyTorch] Reapply D25687465: Devirtualize TensorImpl::dim() with macro (
#50290) Summary: Pull Request resolved: #50290 This was reverted because it landed after D24772023 (b73c018), which changed the implementation of `dim()`, without rebasing on top of it, and thus broke the build. ghstack-source-id: 119608505 Test Plan: CI Reviewed By: ezyang Differential Revision: D25852810 fbshipit-source-id: 9735a095d539a3a6dc530b7b3bb758d4872d05a8
-
[PyTorch] Make TensorImpl::empty_tensor_restride non-virtual (#50301)
Summary: Pull Request resolved: #50301 I'm not sure why this is virtual. We don't seem to override it anywhere, and GitHub code search doesn't turn up anything either. ghstack-source-id: 119622058 Test Plan: CI Reviewed By: ezyang Differential Revision: D25856434 fbshipit-source-id: a95a8d738b109b34f2aadf8db5d4b733d679344f
-
[PyTorch] Make SROpFunctor a raw function pointer (#50395)
Summary: Pull Request resolved: #50395 There's no need for these to be `std::function`. ghstack-source-id: 119684828 Test Plan: CI Reviewed By: hlu1 Differential Revision: D25874187 fbshipit-source-id: e9fa3fbc0dca1219ed13904ca704670ce24f7cc3
Commits on Jan 14, 2021
-
[PyTorch][codemod] Replace immediately-dereferenced expect calls w/ex…
…pectRef (#50228) Summary: Pull Request resolved: #50228 `fastmod -m 'expect(<((at|c10)::)?\w+Type>\(\)\s*)->' 'expectRef${1}.'` Presuming it builds, this is a safe change: the result of `expect()` wasn't being saved anywhere, so we didn't need it, so we can take a reference instead of a new `shared_ptr`. ghstack-source-id: 119782961 Test Plan: CI Reviewed By: SplitInfinity Differential Revision: D25837374 fbshipit-source-id: 86757b70b1520e3dbaa141001e7976400cdd3b08
-
[package] mangle imported module names (#50049)
Summary: Pull Request resolved: #50049 Rationale and implementation immortalized in a big comment in `torch/package/mangling.md`. This change also allows imported modules to be TorchScripted Test Plan: Imported from OSS Reviewed By: pbelevich Differential Revision: D25758625 Pulled By: suo fbshipit-source-id: 77a99dd2024c76716cfa6e59c3855ed590efda8b
-
Fix fastrnn benchmark regression introduced by 49946 (#50517)
-
Assemble technical overview of FX (#50291)
Summary: Pull Request resolved: #50291 Test Plan: Imported from OSS Reviewed By: pbelevich, SplitInfinity Differential Revision: D25908444 Pulled By: ansley fbshipit-source-id: 9860143a0b6aacbed3207228183829c18d10bfdb
-
[tools] Update clang-format linux hash (#50520)
Summary: Pull Request resolved: #50520 **Summary** The new version of `clang-format` for linux64 that was uploaded to S3 earlier this week was dynamically linked to fbcode's custom platform. A new binary has been uploaded that statically links against `libgcc` and `libstdc++`, which seems to have fixed this issue. Ideally, all libraries would be statically linked. **Test Plan** `clang-format` workflow passes on this PR and output shows that it successfully downloaded, verified and ran. ``` Created directory /home/runner/work/pytorch/pytorch/.clang-format-bin for clang-format binary Downloading clang-format to /home/runner/work/pytorch/pytorch/.clang-format-bin Reference Hash: 9073602de1c4e1748f2feea5a0782417b20e3043 Actual Hash: 9073602de1c4e1748f2feea5a0782417b20e3043 Using clang-format located at /home/runner/work/pytorch/pytorch/.clang-format-bin/clang-format no modified files to format ``` Test Plan: Imported from OSS Reviewed By: pbelevich Differential Revision: D25908868 Pulled By: SplitInfinity fbshipit-source-id: 5667fc5546e5ed0bbf9f36570935d245eb26629b
-
HalfCauchy should ValueError if _validate_args (#50403)
Summary: **Expected**: When I run `torch.distributions.HalfCauchy(torch.tensor(1.0), validate_args=True).log_prob(-1)`, I expect a `ValueErro` because that is the behavior of other distributions (e.g. Beta, Bernoulli). **Actual**: No run-time error is thrown, but a `-inf` log prob is returned. Fixes #50404 --- This change is [<img src="https://reviewable.io/review_button.svg" height="34" align="absmiddle" alt="Reviewable"/>](https://reviewable.io/reviews/pytorch/pytorch/50403) Pull Request resolved: #50403 Reviewed By: mrshenli Differential Revision: D25907131 Pulled By: neerajprad fbshipit-source-id: ceb63537e5850809c8b32cf9db0c99043f381edf
-
Structured kernel definition for upsample_nearest2d (#50189)
Summary: See the structured kernel definition [RFC](pytorch/rfcs#9) for context. Pull Request resolved: #50189 Reviewed By: mrshenli Differential Revision: D25903846 Pulled By: soulitzer fbshipit-source-id: 0059fda9b7d86f596ca35d830562dd4b859293a0
-
Revert D25859132: [te] Optimize allocation of kernel outputs
Test Plan: revert-hammer Differential Revision: D25859132 (62f676f) Original commit changeset: 8753289339e3 fbshipit-source-id: 580069c7fa7565643d3204f3740e64ac94c4db39
-
Revert D25856891: [te] Benchmark comparing fused overhead to unfused
Test Plan: revert-hammer Differential Revision: D25856891 (36ae3fe) Original commit changeset: 0e99515ec2e7 fbshipit-source-id: 2d2f07f79986ca7815b9eae63e734db76bdfc0c8
-
cleaned up ModuleAttributeError (#50298)
Summary: Fixes #49726 Just cleaned up the unnecessary `ModuleAttributeError` BC-breaking note: `ModuleAttributeError` was added in the previous unsuccessful [PR](#49879) and removed here. If a user catches `ModuleAttributeError` specifically, this will no longer work. They should catch `AttributeError` instead. Pull Request resolved: #50298 Reviewed By: mrshenli Differential Revision: D25907620 Pulled By: jbschlosser fbshipit-source-id: cdfa6b1ea76ff080cd243287c10a9d749a3f3d0a
-
Revert D25717510: Clean up some type annotations in benchmarks/fastrnns
Test Plan: revert-hammer Differential Revision: D25717510 (7d0eecc) Original commit changeset: 4f6431d140e3 fbshipit-source-id: 2bcc19cd434047f3857e0d7e804d34f72e566c30
-
Reorder torch.distributed.rpc.init_rpc docstring arguments (#50419)
Summary: Pull Request resolved: #50419 Test Plan: Imported from OSS Reviewed By: glaringlee Differential Revision: D25911561 Pulled By: pbelevich fbshipit-source-id: 62c9a5c3f5ec5eddcbd149821ebdf484ff392158
-
[BE] fix subprocess wrapped test cases reported as failure (#50515)
-
Add batched grad testing to gradcheck, turn it on in test_autograd (#…
…49120) Summary: Pull Request resolved: #49120 This adds a `check_batched_grad=False` option to gradcheck and gradgradcheck. It defaults to False because gradcheck is a public API and I don't want to break any existing non-pytorch users of gradcheck. This: - runs grad twice with two grad outputs, a & b - runs a vmapped grad with torch.stack([a, b]) - compares the results of the above against each other. Furthermore: - `check_batched_grad=True` is set to be the default for gradcheck/gradgradcheck inside of test_autograd.py. This is done by reassigning to the gradcheck object inside test_autograd - I manually added `check_batched_grad=False` to gradcheck instances that don't support batched grad. - I added a denylist for operations that don't support batched grad. Question: - Should we have a testing only gradcheck (e.g., torch.testing.gradcheck) that has different defaults from our public API, torch.autograd.gradcheck? Future: - The future plan for this is to repeat the above for test_nn.py (the autogenerated test will require a denylist) - Finally, we can repeat the above for all pytorch test files that use gradcheck. Test Plan: - run tests Reviewed By: albanD Differential Revision: D25563542 Pulled By: zou3519 fbshipit-source-id: 125dea554abefcef0cb7b487d5400cd50b77c52c
-
Revert D25903846: [pytorch][PR] Structured kernel definition for upsa…
…mple_nearest2d Test Plan: revert-hammer Differential Revision: D25903846 (19a8e68) Original commit changeset: 0059fda9b7d8 fbshipit-source-id: b4a7948088c0329a3605c32b64ed77e060e63fca
-
Drop unused imports from caffe2/quantization (#50493)
Summary: Pull Request resolved: #50493 Pull Request resolved: #49974 From ``` ./python/libcst/libcst codemod remove_unused_imports.RemoveUnusedImportsWithGlean --no-format caffe2/ ``` Test Plan: Sandcastle Tests Reviewed By: xush6528 Differential Revision: D25902417 fbshipit-source-id: aeebafce2c4fb649cdce5cf4fd4c5b3ee19923c0
-
Back out "reuse consant from jit" (#50521)
Summary: Pull Request resolved: #50521 Original commit changeset: 9731ec1e0c1d Test Plan: - run `arc focus2 -b pp-ios //xplat/arfx/tracking/segmentation:segmentationApple -a ModelRunner --force-with-bad-commit ` - build via Xcode, run it on an iOS device - Click "Person Segmentation" - Crash observed without the diff patched, and the segmentation image is able to be loaded with this diff patched Reviewed By: husthyc Differential Revision: D25908493 fbshipit-source-id: eef072a8a3434b932cfd0646ee78159f72be5536
-
Link to mypy wiki page from CONTRIBUTING.md (#50540)
Summary: Addresses one of the documentation points in #50513 by making it easier to find our `mypy` wiki page. Also updates the `CONTRIBUTING.md` table of contents and removes some trailing whitespace. Pull Request resolved: #50540 Reviewed By: janeyx99 Differential Revision: D25912366 Pulled By: samestep fbshipit-source-id: b305f974700a9d9ebedc0c2cb75c92e72d84882a
-
enable CPU tests back (#50490)
Summary: Pull Request resolved: #50490 Right now CPU tests are skipped because it always failed in checking 'torch.cuda.device_count() < int(self.world_size)', enable CPU tests back by checking device count only when cuda is available Test Plan: unit tests, CPU tests are not skipped with this diff Reviewed By: rohan-varma Differential Revision: D25901980 fbshipit-source-id: e6e8afe217604c5f5b3784096509240703813d94
-
Validate args in HalfCauchy and HalfNormal (#50492)
Summary: Fixes #50404 Complementary to #50403 This also fixes `HalfCauchy.cdf()`, `HalfNormal.log_prob()`, `HalfNormal.cdf()` and ensures validation is not done twice. cc feynmanliang Pull Request resolved: #50492 Reviewed By: mrshenli Differential Revision: D25909541 Pulled By: neerajprad fbshipit-source-id: 35859633bf5c4fd20995182c599cbcaeb863cf29
-
[quant] update embedding module to not store qweight (#50418)
Summary: Pull Request resolved: #50418 previously we were storing the quantized weight as a module attribute, whcih was resulting in the weight getting stored as part of the model. We don't need this since we already store the unpacked weights as part of the model. Test Plan: Before ``` Archive: tmp.pt Length Method Size Cmpr Date Time CRC-32 Name -------- ------ ------- ---- ---------- ----- -------- ---- 586 Stored 586 0% 00-00-1980 00:00 5fefdda0 tmp/extra/producer_info.json 1588700 Stored 1588700 0% 00-00-1980 00:00 04e0da4c tmp/data/0 63548 Stored 63548 0% 00-00-1980 00:00 0ceb1f45 tmp/data/1 63548 Stored 63548 0% 00-00-1980 00:00 517bc3ab tmp/data/2 1588700 Stored 1588700 0% 00-00-1980 00:00 dbe88c73 tmp/data/3 63548 Stored 63548 0% 00-00-1980 00:00 d8dc47c4 tmp/data/4 63548 Stored 63548 0% 00-00-1980 00:00 b9e0c20f tmp/data/5 1071 Stored 1071 0% 00-00-1980 00:00 10dc9350 tmp/data.pkl 327 Defl:N 203 38% 00-00-1980 00:00 dfddb661 tmp/code/__torch__/___torch_mangle_0.py 185 Stored 185 0% 00-00-1980 00:00 308f580b tmp/code/__torch__/___torch_mangle_0.py.debug_pkl 1730 Defl:N 515 70% 00-00-1980 00:00 aa11f799 tmp/code/__torch__/torch/nn/quantized/modules/embedding_ops.py 1468 Defl:N 636 57% 00-00-1980 00:00 779609a6 tmp/code/__torch__/torch/nn/quantized/modules/embedding_ops.py.debug_pkl 0 Stored 0 0% 00-00-1980 00:00 00000000 tmp/code/__torch__/torch/classes/quantized.py 6 Stored 6 0% 00-00-1980 00:00 816d0907 tmp/code/__torch__/torch/classes/quantized.py.debug_pkl 4 Stored 4 0% 00-00-1980 00:00 57092f6d tmp/constants.pkl 2 Stored 2 0% 00-00-1980 00:00 55679ed1 tmp/version -------- ------- --- ------- 3436971 3434800 0% 16 files ``` After ``` Archive: tmp.pt Length Method Size Cmpr Date Time CRC-32 Name -------- ------ ------- ---- ---------- ----- -------- ---- 1588700 Stored 1588700 0% 00-00-1980 00:00 a4da6981 tmp/data/0 63548 Stored 63548 0% 00-00-1980 00:00 74d9b607 tmp/data/1 63548 Stored 63548 0% 00-00-1980 00:00 e346a0c2 tmp/data/2 952 Stored 952 0% 00-00-1980 00:00 eff8706e tmp/data.pkl 375 Defl:N 227 40% 00-00-1980 00:00 96c77b68 tmp/code/__torch__/quantization/test_quantize/___torch_mangle_23.py 228 Defl:N 162 29% 00-00-1980 00:00 6a378113 tmp/code/__torch__/quantization/test_quantize/___torch_mangle_23.py.debug_pkl 1711 Defl:N 509 70% 00-00-1980 00:00 66d8fd61 tmp/code/__torch__/torch/nn/quantized/modules/embedding_ops.py 1473 Defl:N 634 57% 00-00-1980 00:00 beb2323b tmp/code/__torch__/torch/nn/quantized/modules/embedding_ops.py.debug_pkl 0 Stored 0 0% 00-00-1980 00:00 00000000 tmp/code/__torch__/torch/classes/quantized.py 6 Stored 6 0% 00-00-1980 00:00 816d0907 tmp/code/__torch__/torch/classes/quantized.py.debug_pkl 4 Stored 4 0% 00-00-1980 00:00 57092f6d tmp/constants.pkl 2 Stored 2 0% 00-00-1980 00:00 55679ed1 tmp/version -------- ------- --- ------- 1720547 1718292 0% 12 files ``` Imported from OSS Reviewed By: jerryzh168 Differential Revision: D25879879 fbshipit-source-id: e09427a60d4c44dd1a190575e75f3ed9cde6358f
-
Enable GPU-to-GPU comm in TensorPipeAgent (#44418)
Summary: Pull Request resolved: #44418 This commit uses TensorPipe's cuda_ipc channel to conduct cross-process same-machine GPU-to-GPU communication. On the sender side, `TensorPipeAgent` grabs a stream to each device used by the message, let these streams wait for current streams, and passes the streams to TensorPipe `CudaBuffer`. On the receiver side, it also grabs a stream for each device used in the message, and uses these streams to receive tensors and run user functions. After that, these streams are then used for sending the response back to the sender. When receiving the response, the sender will grab a new set of streams and use them for TensorPipe's `CudaBuffer`. If device maps are provided, `TensorPipeAgent::send` will return a derived class of `CUDAFuture`, which is specifically tailored for RPC Messages. TODOs: 1. Enable sending CUDA RPC to the same process. 2. Add a custom CUDA stream pool. 3. When TensorPipe addressed the error for `cudaPointerGetAttributes()`, remove `cuda:0` context initialization code in `backend_registry.py`. 4. When TensorPipe can detect availability of peer access, enable all tests on platforms without peer access. Differential Revision: D23626207 Test Plan: Imported from OSS Reviewed By: lw Pulled By: mrshenli fbshipit-source-id: d30e89e8a98bc44b8d237807b84e78475c2763f0
-
Reapply D25856891: [te] Benchmark comparing fused overhead to unfused (…
…#50543) Summary: Pull Request resolved: #50543 Original commit changeset: 2d2f07f79986 Was part of a stack that got reverted. This is just a benchmark. ghstack-source-id: 119825594 Test Plan: CI Reviewed By: navahgar Differential Revision: D25912439 fbshipit-source-id: 5d9ca45810fff8931a3cfbd03965e11050180676
-
Use separate mypy caches for TestTypeHints cases (#50539)
Summary: Addresses one of the speed points in #50513 by making the `TestTypeHints` suite much faster when run incrementally. Also fixes an issue (at least on 5834438) where running that suite repeatedly results in a failure every other run (see the test plan below). Pull Request resolved: #50539 Test Plan: First clear your [`mypy` cache](https://mypy.readthedocs.io/en/stable/command_line.html#incremental-mode): ``` $ rm -r .mypy_cache ``` Then run this twice: ``` $ python test/test_type_hints.py ``` - *Before:* ``` .... ---------------------------------------------------------------------- Ran 4 tests in 212.340s OK ``` ``` .F.. ====================================================================== FAIL: test_run_mypy (__main__.TestTypeHints) Runs mypy over all files specified in mypy.ini ---------------------------------------------------------------------- Traceback (most recent call last): File "test/test_type_hints.py", line 214, in test_run_mypy self.fail(f"mypy failed: {stdout} {stderr}") AssertionError: mypy failed: torch/quantization/fx/quantize.py:138: error: "Tensor" not callable [operator] Found 1 error in 1 file (checked 1189 source files) ---------------------------------------------------------------------- Ran 4 tests in 199.331s FAILED (failures=1) ``` - *After:* ``` .... ---------------------------------------------------------------------- Ran 4 tests in 212.815s OK ``` ``` .... ---------------------------------------------------------------------- Ran 4 tests in 5.491s OK ``` Reviewed By: xuzhao9 Differential Revision: D25912363 Pulled By: samestep fbshipit-source-id: dac38c890399193699c57b6c9fa8df06a88aee5d
-
Back out "Revert D25717510: Clean up some type annotations in benchma…
-
Fix warnings in "ForeachOpsKernels" (#50482)
Summary: Pull Request resolved: #50482 Compiling currently shows: ``` Jan 13 16:46:28 In file included from ../aten/src/ATen/native/ForeachOpsKernels.cpp:2: Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:28:21: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:44:21: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:149:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) { Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:164:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) { Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:183:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) { Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:198:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) { Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:150:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(add); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:74:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA' Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:150:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(add); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:84:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA' Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:151:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(sub); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:74:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA' Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:151:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(sub); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:84:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA' Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:158:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(add); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:158:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(add); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:159:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(sub); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:159:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(sub); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:160:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(mul); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:160:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(mul); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:161:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(div); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:161:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(div); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:163:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(mul); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:53:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST' Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:163:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(mul); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:63:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST' Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:164:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(div); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:53:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST' Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:164:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(div); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:63:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST' Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:195:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcdiv); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:115:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR' Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:195:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcdiv); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:125:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR' Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:196:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcmul); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:115:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR' Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:196:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcmul); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:125:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR' Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:198:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcdiv); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:135:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:198:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcdiv); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:145:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:199:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcmul); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:135:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \ Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:199:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcmul); Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:145:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST' Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { ``` this diff fixes that Test Plan: Sandcastle tests Reviewed By: xush6528 Differential Revision: D25901744 fbshipit-source-id: 2cb665358a103d85e07c690d73b3f4a557d4c135
-
Fix warnings in TensorShape (#50486)
Summary: Pull Request resolved: #50486 Compiling currently gives: ``` an 13 16:46:39 In file included from ../aten/src/ATen/native/TensorShape.cpp:12: Jan 13 16:46:39 ../aten/src/ATen/native/Resize.h:37:24: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:39 if (new_size_bytes > self->storage().nbytes()) { Jan 13 16:46:39 ~~~~~~~~~~~~~~ ^ ~~~~~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:32:24: warning: comparison of integers of different signs: 'size_t' (aka 'unsigned long') and 'int64_t' (aka 'long long') [-Wsign-compare] Jan 13 16:46:39 for (size_t i = 0; i < shape_tensor.numel(); ++i) { Jan 13 16:46:39 ~ ^ ~~~~~~~~~~~~~~~~~~~~ Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:122:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:39 for (int64_t i = 0; i < tensors.size(); i++) { Jan 13 16:46:39 ~ ^ ~~~~~~~~~~~~~~ Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:162:21: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:39 for (int i = 0; i < tensors.size(); i++) { Jan 13 16:46:39 ~ ^ ~~~~~~~~~~~~~~ Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:300:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:39 for (int64_t i = 0; i < s1.size(); ++i) { Jan 13 16:46:39 ~ ^ ~~~~~~~~~ Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:807:21: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:39 TORCH_CHECK(dim < self_sizes.size()); Jan 13 16:46:39 ~~~ ^ ~~~~~~~~~~~~~~~~~ Jan 13 16:46:39 ../c10/util/Exception.h:361:31: note: expanded from macro 'TORCH_CHECK' Jan 13 16:46:39 if (C10_UNLIKELY_OR_CONST(!(cond))) { \ Jan 13 16:46:39 ^~~~ Jan 13 16:46:39 ../c10/util/Exception.h:244:47: note: expanded from macro 'C10_UNLIKELY_OR_CONST' Jan 13 16:46:39 #define C10_UNLIKELY_OR_CONST(e) C10_UNLIKELY(e) Jan 13 16:46:39 ^ Jan 13 16:46:39 ../c10/macros/Macros.h:173:65: note: expanded from macro 'C10_UNLIKELY' Jan 13 16:46:39 #define C10_UNLIKELY(expr) (__builtin_expect(static_cast<bool>(expr), 0)) Jan 13 16:46:39 ^~~~ Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:855:24: warning: comparison of integers of different signs: 'size_t' (aka 'unsigned long') and 'const int64_t' (aka 'const long long') [-Wsign-compare] Jan 13 16:46:39 for (size_t i = 0; i < num_blocks; ++i) { Jan 13 16:46:39 ~ ^ ~~~~~~~~~~ Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:2055:23: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:39 for (int i = 0; i < vec.size(); i++) { Jan 13 16:46:39 ~ ^ ~~~~~~~~~~ Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:2100:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare] Jan 13 16:46:39 for (int64_t i = 0; i < src.size(); ++i) { ``` This fixes issues with loop iteration variable types Test Plan: Sandcastle tests Reviewed By: xush6528 Differential Revision: D25901799 fbshipit-source-id: c68d9ab93ab0142b5057ce4ca9e75c620a1425f0
{kind=link}
Commits on Jan 15, 2021
-
Drop blacklist from glow (#50480)
Summary: Pull Request resolved: #50480 Test Plan: Sandcastle tests Reviewed By: xush6528 Differential Revision: D25893858 fbshipit-source-id: 297440997473c037e8f59a460306569d0a4aa67c
-
[TensorExpr] Hook Fuser Pass to JIT opt-limit utility. (#50518)
Summary: Pull Request resolved: #50518 That new feature allows to bisect the pass easily by hard-stopping it after a given number of hits. Test Plan: Imported from OSS Reviewed By: tugsbayasgalan Differential Revision: D25908597 Pulled By: ZolotukhinM fbshipit-source-id: 8ee547989078c7b1747a4b02ce6e71027cb3055f
-
Minor doc improvement(?) on ArrayRef::slice (#50541)
Summary: Pull Request resolved: #50541 I found the current phrasing to be confusing Test Plan: N/A Reviewed By: ngimel Differential Revision: D25909205 fbshipit-source-id: 483151d01848ab41d57b3f3b3775ef69f1451dcf
-
Revert D25563542: Add batched grad testing to gradcheck, turn it on i…
…n test_autograd Test Plan: revert-hammer Differential Revision: D25563542 (443412e) Original commit changeset: 125dea554abe fbshipit-source-id: 0564735f977431350b75147ef209e56620dbab64
-
[TensorExpr] Add python bindings. (#49698)
Summary: Pull Request resolved: #49698 Reincarnation of #47620 by jamesr66a. It's just an initial bunch of things that we're exposing to python, more is expected to come in future. Some things can probably be done better, but I'm putting this out anyway, since some other people were interested in using and/or developing this. Differential Revision: D25668694 Test Plan: Imported from OSS Reviewed By: bertmaher Pulled By: ZolotukhinM fbshipit-source-id: fb0fd1b31e851ef9ab724686b9ac2d172fa4905a
-
[ONNX] Handle sequence output shape and type inference (#46542)
Summary: Handle sequence output shape and type inference. This PR fixes value type of sequence outputs. Prior to this, all model sequence type outputs were unfolded for ONNX models. This PR also enable shape inference for sequence outputs to represent the dynamic shape of these values. Pull Request resolved: #46542 Reviewed By: ezyang Differential Revision: D24924236 Pulled By: bzinodev fbshipit-source-id: 506e70a38cfe31069191d7f40fc6375239c6aafe
-
[FX] Add wrap() docstring to docs and add decorator example (#50555)
Summary: Pull Request resolved: #50555 Test Plan: Imported from OSS Reviewed By: Chillee Differential Revision: D25917564 Pulled By: jamesr66a fbshipit-source-id: 20c7c8b1192fa80c6a0bb9e18910791bd7167232
-
[WIP][FX] new sections in docs (#50562)
Summary: Pull Request resolved: #50562 Adding new top-level sections to the docs to be filled out  Test Plan: Imported from OSS Reviewed By: Chillee Differential Revision: D25919592 Pulled By: jamesr66a fbshipit-source-id: 45f564eb8fddc7a42abb5501e160cca0dd0745c8
-
Automated submodule update: tensorpipe (#50572)
Summary: This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe). New submodule commit: pytorch/tensorpipe@161500f Pull Request resolved: #50572 Test Plan: Ensure that CI jobs succeed on GitHub before landing. Reviewed By: lw Differential Revision: D25920888 fbshipit-source-id: fa73ba50a2d9429ea1e0beaac6edc2fd8d3ce244
-
[AutoAccept][Codemod][FBSourceClangFormatLinter] Daily `arc lint --ta…
…ke CLANGFORMAT` Reviewed By: zertosh Differential Revision: D25921551 fbshipit-source-id: df0445864751c18eaa240deff6a142dd791d32ff
-
Revert D24924236: [pytorch][PR] [ONNX] Handle sequence output shape a…
…nd type inference Test Plan: revert-hammer Differential Revision: D24924236 (adc65e7) Original commit changeset: 506e70a38cfe fbshipit-source-id: 78069a33fb3df825af1cb482da06a07f7b26ab48
-
[BE] add warning message to cmake against env var "-std=c++xx" (#50491)
Summary: this was discovered when working on #50230. environment variables such as CXXFLAGS="-std=c++17" will not work because we use CMAKE_CXX_STANDARD 14. Adding this warning to alert users when environment variable was set. See: [CMake env var usage](https://cmake.org/cmake/help/latest/manual/cmake-env-variables.7.html#id4) and [CXXFLAGS usage](https://cmake.org/cmake/help/latest/envvar/CXXFLAGS.html) for more details. Pull Request resolved: #50491 Reviewed By: mrshenli Differential Revision: D25907851 Pulled By: walterddr fbshipit-source-id: 5af5eec76f79f9d35456af1f2663cafbc54e7dc8
-
Remove optional for veiw_fn during View Tracking (#50067)
Summary: Pull Request resolved: #50067 Fixes #49257 Using the `Callgrind` to test the performance. ```python import torch import timeit from torch.utils.benchmark import Timer timer = Timer("x.view({100, 5, 20});", setup="torch::Tensor x = torch::ones({10, 10, 100});", language="c++", timer=timeit.default_timer) res = timer.collect_callgrind(number=10) ``` ### Nightly ```python torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f7949138c40> x.view({100, 5, 20}); setup: torch::Tensor x = torch::ones({10, 10, 100}); All Noisy symbols removed Instructions: 42310 42310 Baseline: 0 0 10 runs per measurement, 1 thread Warning: PyTorch was not built with debug symbols. Source information may be limited. Rebuild with REL_WITH_DEB_INFO=1 for more detailed results. ``` ### Current ```python <torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f78f271a580> x.view({100, 5, 20}); setup: torch::Tensor x = torch::ones({10, 10, 100}); All Noisy symbols removed Instructions: 42480 42480 Baseline: 0 0 10 runs per measurement, 1 thread Warning: PyTorch was not built with debug symbols. Source information may be limited. Rebuild with REL_WITH_DEB_INFO=1 for more detailed results. ``` ### Compare There are 170 instructions reduced ```python torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.FunctionCounts object at 0x7f7941b7a7c0> 970 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, std::function<at::Tensor (at::Tensor const&)>, torch::autograd::CreationMeta, bool) 240 ???:torch::autograd::ViewInfo::~ViewInfo() 180 ???:torch::autograd::ViewInfo::ViewInfo(at::Tensor, std::function<at::Tensor (at::Tensor const&)>) 130 ???:torch::autograd::make_variable_differentiable_view(at::Tensor const&, c10::optional<torch::autograd::ViewInfo>, c10::optional<torch::autograd::ViewInfo>, torch::autograd::CreationMeta, bool) 105 /tmp/benchmark_utils_jit_build_69e2f1710544485588feeca0719a3a57/timer_cpp_4435526292782672407/timer_src.cpp:main 100 ???:std::function<at::Tensor (at::Tensor const&)>::function(std::function<at::Tensor (at::Tensor const&)> const&) 70 ???:torch::autograd::DifferentiableViewMeta::~DifferentiableViewMeta() 70 ???:torch::autograd::DifferentiableViewMeta::DifferentiableViewMeta(c10::TensorImpl*, c10::optional<torch::autograd::ViewInfo>, c10::optional<torch::autograd::ViewInfo>, torch::autograd::CreationMeta) -100 ???:c10::optional_base<torch::autograd::ViewInfo>::optional_base(c10::optional_base<torch::autograd::ViewInfo>&&) -105 /tmp/benchmark_utils_jit_build_2e75f38b553e42eba00523a86ad9aa05/timer_cpp_3360771523810516633/timer_src.cpp:main -120 ???:torch::autograd::ViewInfo::ViewInfo(at::Tensor, c10::optional<std::function<at::Tensor (at::Tensor const&)> >) -210 ???:c10::optional_base<std::function<at::Tensor (at::Tensor const&)> >::~optional_base() -240 ???:c10::optional_base<torch::autograd::ViewInfo>::~optional_base() -920 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, c10::optional<std::function<at::Tensor (at::Tensor const&)> >, torch::autograd::CreationMeta, bool) ``` Test Plan: Imported from OSS Reviewed By: albanD Differential Revision: D25900495 Pulled By: ejguan fbshipit-source-id: dedd30e69db6b48601a18ae98d6b28faeae30d90
-
-
.circleci: Set +u for all conda install commands (#50505)
Summary: Pull Request resolved: #50505 Even with +u set for the the conda install it still seems to fail out with an unbound variable error. Let's try and give it a default value instead. Signed-off-by: Eli Uriegas <eliuriegas@fb.com> Test Plan: Imported from OSS Reviewed By: pbelevich Differential Revision: D25913692 Pulled By: seemethere fbshipit-source-id: 4b898f56bff25c7523f10b4933ea6cd17a57df80
-
Summary: Pull Request resolved: #46414 For loops are often written with mismatched data types which causes silent type and sign coercion in the absence of integer conversion warnings. Getting around this in templated code requires convoluted patterns such as ``` for(auto i=decltype(var){0};i<var;i++) ``` with this diff we can instead write ``` for(const auto i = c10::irange(var)) ``` Note that this loop is type-safe and const-safe. The function introduced here (`c10::irange`) allows for type-safety and const-ness within for loops, which prevents the accidental truncation or modification of integers and other types, improving code safety. Test Plan: ``` buck test //caffe2/c10:c10_test_0 ``` Reviewed By: ngimel Differential Revision: D24334732 fbshipit-source-id: fec5ebda3643ec5589f7ea3a8e7bbea4432ed771
-
Clarify, make consistent, and test the behavior of logspace when dtyp…
…e is integral (#47647) Summary: torch.logspace doesn't seem to have explained how integers are handled. Add some clarification and some test when dtype is integral. The CUDA implementation is also updated to be consistent with CPU implementation. Pull Request resolved: #47647 Reviewed By: gchanan Differential Revision: D25843351 Pulled By: walterddr fbshipit-source-id: 45237574d04c56992c18766667ff1ed71be77ac3
-
[PyTorch] Remove unnecessary dispatcher.h include in builtin_function…
-
[PyTorch] Remove unnecessary dispatcher.h include in op_registration.h (
-
[PyTorch] Remove unnecessary dispatcher.h include in mobile/interpret…
-
[RPC] Support timeout in rref._get_type() (#50498)
Summary: Pull Request resolved: #50498 This change is mostly needed for the next diff in this stack, where rref._get_type() is called in the rpc_async/rpc_sync RRef proxy function and can block indefinitely if there is no timeout. It will also be useful to have a timeout argument when we publicize this API to keep it consistent with other RPC APIs. ghstack-source-id: 119859767 Test Plan: Added UT Reviewed By: pritamdamania87 Differential Revision: D25897588 fbshipit-source-id: 2e84aaf7e4faecf80005c78ee2ac8710f387503e
-
[RPC] Support timeout for RRef proxy functions (#50499)
Summary: Pull Request resolved: #50499 Adds a timeout API to the following functions: ``` rref.rpc_sync() rref.rpc_async() rref.remote() ``` so that RPCs initiated by these proxy calls can be appropriately timed out similar to the regular RPC APIs. Timeouts are supported in the following use cases: 1. rpc.remote finishes in time and successfully, but function run by rref.rpc_async() is slow and times out. Timeout error will be raised 2. rref.rpc_async() function is fast, but rpc.remote() is slow/hanging. Then when rref.rpc_async() is called, it will still timeout with the passed in timeout (and won't block for the rpc.remote() to succeed, which is what happens currently). Although, the timeout will occur during the future creation itself (and not the wait) since it calls `rref._get_type` which blocks. We can consider making this nonblocking by modifying rref._get_type to return a future, although that is likely a larger change. Test Plan: Added UT Reviewed By: wanchaol Differential Revision: D25897495 fbshipit-source-id: f9ad5b8f75121f50537677056a5ab16cf262847e
-
Add complex support for torch.nn.L1Loss (#49912)
Summary: Building on top of the work of anjali411 (#46640) Things added in this PR: 1. Modify backward and double-backward formulas 2. Add complex support for `new module tests` and criterion tests (and add complex tests for L1) 3. Modify some existing tests to support complex Pull Request resolved: #49912 Reviewed By: zhangguanheng66 Differential Revision: D25853036 Pulled By: soulitzer fbshipit-source-id: df619f1b71c450ab2818eb17804e0c55990aa8ad
{kind=link}
Commits on Jan 16, 2021
-
add RequiresGradCheck (#50392)
Summary: This change improves perf by 3-4% on fastrnns. Pull Request resolved: #50392 Reviewed By: izdeby Differential Revision: D25891392 Pulled By: Krovatkin fbshipit-source-id: 44d9b6907d3975742c9d77102fe6a85aab2c08c0
-
Reapply D25859132: [te] Optimize allocation of kernel outputs (#50546)
Summary: Pull Request resolved: #50546 And fix the ROCm build ghstack-source-id: 119837166 Test Plan: CI Reviewed By: ZolotukhinM Differential Revision: D25912464 fbshipit-source-id: 023e1f6c9fc131815c5a7a31f4860dfe271f7ae1
-
Summary: Fix build with llvm-trunk. With D25877605 (cb37709), we need to explicitly include `llvm/Support/Host.h` in `llvm_jit.cpp`. Test Plan: `buck build mode/opt-clang -j 56 sigrid/predictor/v2:sigrid_remote_predictor -c cxx.extra_cxxflags="-Wforce-no-error" -c cxx.modules=False -c cxx.use_default_autofdo_profile=False` Reviewed By: bertmaher Differential Revision: D25920968 fbshipit-source-id: 4b80d5072907f50d01e8fbef41cda8a89dd66a96
-
Updated codecov config settings (#50601)
Summary: - Do not generate inline comments on PRs - Increase number of signals to wait until generating a comment to 5 (2 for codecov configs, 2 for onnx and 1 for windows_test1) Pull Request resolved: #50601 Reviewed By: albanD Differential Revision: D25928920 Pulled By: malfet fbshipit-source-id: 8a4ff70024c948cb65a4bdf31d269080d2cff945
-
[FX] Make len traceable and scriptable with wrap (#50184)
Summary: Pull Request resolved: #50184 Test Plan: Imported from OSS Reviewed By: bertmaher Differential Revision: D25819832 Pulled By: jamesr66a fbshipit-source-id: ab16138ee26ef2f92f3478c56f0db1873fcc5dd0
-
Revert D25843351: [pytorch][PR] Clarify, make consistent, and test th…
…e behavior of logspace when dtype is integral Test Plan: revert-hammer Differential Revision: D25843351 (0ae0fac) Original commit changeset: 45237574d04c fbshipit-source-id: fb5343d509b277158b14d1b61e10433793889842
-
-
[PyTorch] Add missing Dispatcher.h include in quantized_ops.cpp (#50646)
Summary: Pull Request resolved: #50646 Master build broke (see https://app.circleci.com/pipelines/github/pytorch/pytorch/260715/workflows/948c9235-8844-4747-b40d-c14ed33f8dbb/jobs/10195595) ghstack-source-id: 119906225 (Note: this ignores all push blocking failures!) Test Plan: CI? Reviewed By: malfet Differential Revision: D25935300 fbshipit-source-id: 549eba1af24305728a5a0a84cb84142ec4807d95
-
remove dulicate newlines (#50648)
Summary: Pull Request resolved: #50648 Reviewed By: malfet Differential Revision: D25935513 Pulled By: walterddr fbshipit-source-id: 1a8419b4fdb25368975ac8e72181c2c4b6295278
-
Fix pytorch-doc build (#50651)
Summary: Fixes `docstring of torch.distributed.rpc.RRef.remote:14: WARNING: Field list ends without a blank line; unexpected unindent.` by indenting multiline fieldlist Pull Request resolved: #50651 Reviewed By: SplitInfinity Differential Revision: D25935839 Pulled By: malfet fbshipit-source-id: e2613ae75334d01ab57f4b071cb0fddf80c6bd78
-
Finished fleshing out the tensor expr bindings in expr.cpp (#50643)
Summary: Adds the rest of the ops. Pull Request resolved: #50643 Reviewed By: pbelevich Differential Revision: D25936346 Pulled By: Chillee fbshipit-source-id: 4e2a7afbeabde51991c39d187a8c35e766950ffe
Commits on Jan 17, 2021
-
[distributed_test_c10d]Enable disabled ROCm tests. (#50629)
Summary: Signed-off-by: Jagadish Krishnamoorthy <jagdish.krishna@gmail.com> Pull Request resolved: #50629 Reviewed By: albanD Differential Revision: D25935005 Pulled By: rohan-varma fbshipit-source-id: e0969afecac2f319833189a7a8897d78068a2cda
Commits on Jan 18, 2021
-
fix bn channels_last contiguity check (#50659)
Summary: Fixes #42588 The contiguity check used to be for memory format suggested by `grad_output->suggest_memory_format()`, but an invariant guaranteed by derivatives.yaml is `input->suggest_memory_format()` Pull Request resolved: #50659 Reviewed By: mruberry Differential Revision: D25938921 Pulled By: ngimel fbshipit-source-id: a945bfef6ce3d91b17e7ff96babe89ffd508939a
-
[BE] Fix the broken test -- caffe2/caffe2/python:hypothesis_test - te…
…st_recurrent (#50668) Summary: Pull Request resolved: #50668 GPU initialization sometimes is slow Test Plan: buck test mode/opt //caffe2/caffe2/python:hypothesis_test -- --exact 'caffe2/caffe2/python:hypothesis_test - test_recurrent (caffe2.caffe2.python.hypothesis_test.TestOperators)' --run-disabled Reviewed By: hl475 Differential Revision: D25939037 fbshipit-source-id: 832700cf42ece848cda66dd629a06ecda207f086
-
Remove unnecessary dtype checks for complex types & disable complex d…
…ispatch for CPU min/max pointwise ops (#50465) Summary: Fixes #50064 **PROBLEM DESCRIPTION:** 1. Had not removed dtype checks for complex types in the previous PR (#50347) for this issue. These type-checks were added in #36377, but are no longer necessary, as we now rely upon dispatch macros to produce error messages. 2. dtype checks in `clamp_max()` and `clamp_min()` for complex inputs had not been removed either. 3. For min/max pointwise ops in TensorCompareKernel.cpp, complex dispatch had not been removed for min/max functions. ### **FIX DESCRIPTION:** **FIX SUMMARY:** 1. Removed dtype checks added in #36377, and added 3 more in TensorCompare.cpp. 2. Removed dtype checks for complex inputs in `clamp_max()` and `clamp_min()`. 3. Disabled complex dispatch for min/max pointwise ops in TensorCompareKernel.cpp. 4. Error messages in the exceptions raised due to min/max ops not being implemented are now checked for containing the text _not support_ (which can also be present in _not supported_), or _not implemented_, so one of them should be a part of error messages, in order for them to be informative. **REASON FOR NOT CHANGING DISPATCH FOR CUDA AND CLAMP OPS**: As for the CUDA min/max operations, their kernels do not seem to be compiled & dispatched for complex types anyway, so no further changes seem to be required. Basically, the dispatch macros currently being used don't have cases for complex types. For example, 1. the reduce CUDA ops use [AT_DISPATCH_ALL_TYPES_AND2 (https://github.com/pytorch/pytorch/commit/678fe9f0771a5cd98ead214363d70480ba03000d)](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/Dispatch.h#L548-L575) in [ReduceMinMaxKernel.cu](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/ReduceMinMaxKernel.cu), and that macro doesn't allow complex types. 2. In [MinMaxElementwiseKernel.cu](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/MaxMinElementwiseKernel.cu), the CUDA pointwise ops use [`AT_DISPATCH_FLOATING_TYPES_AND2 (https://github.com/pytorch/pytorch/commit/678fe9f0771a5cd98ead214363d70480ba03000d)`](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/Dispatch.h#L240-L263) for non-integral & non-boolean types, and this marco doesn't have a case for complex types either. 3. [clamp CUDA ops](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/UnaryOpsKernel.cu#L170-L211) use `AT_DISPATCH_ALL_TYPES_AND2 (https://github.com/pytorch/pytorch/commit/678fe9f0771a5cd98ead214363d70480ba03000d)`, which doesn't have a case for complex types. Similarly, [CPU clamp min/max ops](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cpu/UnaryOpsKernel.cpp#L428-L458) use the `AT_DISPATCH_ALL_TYPES_AND `dispatch macro, which doesn't have a case for complex types. **REASON FOR ADDING 3 dtype CHECKS:** There are a few cases in which the methods corresponding to `min_stub()` or `max_stub()` are not called, so dispatch macros don't get invoked, resulting in no exceptions being raised. Hence, `dtype` checks are necessary at 3 places to raise exceptions: 1. https://github.com/pytorch/pytorch/blob/52dcc7299925de055d330781d2fe0dad71182829/aten/src/ATen/native/TensorCompare.cpp#L342 2. https://github.com/pytorch/pytorch/blob/52dcc7299925de055d330781d2fe0dad71182829/aten/src/ATen/native/TensorCompare.cpp#L422 3. https://github.com/pytorch/pytorch/blob/52dcc7299925de055d330781d2fe0dad71182829/aten/src/ATen/native/TensorCompare.cpp#L389 The first dtype check requirement can be verified from the following example Python code based on `test_complex_unsupported()`: ``` import unittest import torch class MyTestCase(unittest.TestCase): def test_1(self): t = torch.tensor((1 + 1j), device='cpu', dtype=torch.complex128) with self.assertRaises(Exception): torch.max(t, dim=0) if __name__ == '__main__': unittest.main() ``` Pull Request resolved: #50465 Reviewed By: mruberry Differential Revision: D25938106 Pulled By: ngimel fbshipit-source-id: 95e2df02ba8583fa3ce87d4a2fdcd60b912dda46
-
-
-
Complex autograd support for torch.{baddbmm, addbmm, addmm, addmv} (#…
…50632) Summary: Pull Request resolved: #50632 I'll port the following method tests in follow-up PRs: `'baddbmm', 'addbmm', 'addmv', 'addr'` After the tests are ported to OpInfo based tests, it would also be much easier to add tests with complex alpha and beta values. Edit- it seems like it's hard to port the broadcasting variant tests because one ends up skipping `test_inplace_grad` and `test_variant_consistency_eager` even for the case when inputs are not required to be broadcasted. Test Plan: Imported from OSS Reviewed By: navahgar Differential Revision: D25947471 Pulled By: anjali411 fbshipit-source-id: 9faa7f1fd55a1269bad282adac2b39d19bfa4591
-
Optimize implementation of torch.pow (#46830)
Summary: - Related with #44937 - Use `resize_output` instead of `resize_as` - Tuning the `native_functions.yaml`, move the inplace variant `pow_` next to the other `pow` entries Pull Request resolved: #46830 Reviewed By: mrshenli Differential Revision: D24567702 Pulled By: anjali411 fbshipit-source-id: a352422c9d4e356574dbfdf21fb57f7ca7c6075d
Commits on Jan 19, 2021
-
[BE] Fix the broken test caffe2/caffe2/python:lazy_dyndep_test - test…
…_allcompare (#50696) Summary: Pull Request resolved: #50696 set no deadline for test_alklcompare Test Plan: buck test mode/dev //caffe2/caffe2/python:lazy_dyndep_test -- --exact 'caffe2/caffe2/python:lazy_dyndep_test - test_allcompare (caffe2.caffe2.python.lazy_dyndep_test.TestLazyDynDepAllCompare)' --run-disabled Reviewed By: hl475 Differential Revision: D25947800 fbshipit-source-id: d2043f97128e257ef06ebca9b68262bb1c0c5e6b
-
Fix memory leak in TensorPipeAgent. (#50564)
Summary: Pull Request resolved: #50564 When an RPC was sent, the associated future was stored in two maps: pendingResponseMessage_ and timeoutMap_. Once the response was received, the entry was only removed from pendingResponseMessage_ and not timeoutMap_. The pollTimedoudRpcs method then eventually removed the entry from timeoutMap_ after the time out duration had passed. Although, in scenarios where there is a large timeout and a large number of RPCs being used, it is very easy for the timeoutMap_ to grow without any bounds. This was discovered in #50522. To fix this issue, I've added some code to cleanup timeoutMap_ as well once we receive a response. ghstack-source-id: 119925182 Test Plan: 1) Unit test added. 2) Tested with repro in #50522 #Closes: #50522 Reviewed By: mrshenli Differential Revision: D25919650 fbshipit-source-id: a0a42647e706d598fce2ca2c92963e540b9d9dbb
-
Enable TensorPipe CUDA sending to self (#50674)
Summary: Pull Request resolved: #50674 Test Plan: Imported from OSS Reviewed By: beauby Differential Revision: D25941964 Pulled By: mrshenli fbshipit-source-id: b53454efdce01f7c06f67dfb890d3c3bdc2c648f
-
Enable TensorPipe CUDA fallback channel (#50675)
Summary: Pull Request resolved: #50675 Test Plan: Imported from OSS Reviewed By: beauby Differential Revision: D25941963 Pulled By: mrshenli fbshipit-source-id: 205786d7366f36d659a3a3374081a458cfcb4dd1
-
Add SELU Activation to calculate_gain (#50664)
Summary: Fixes #{[24991](#24991)} I used a value of 0.75 as suggested in the forums by Thomas: https://discuss.pytorch.org/t/calculate-gain-tanh/20854/6 I verified that the value keeps the gradient stable for a 100-layer network. Code to reproduce (from [jpeg729](https://discuss.pytorch.org/t/calculate-gain-tanh/20854/4)): ```python import torch import torch.nn.functional as F import sys a = torch.randn(1000,1000, requires_grad=True) b = a print (f"in: {a.std().item():.4f}") for i in range(100): l = torch.nn.Linear(1000,1000, bias=False) torch.nn.init.xavier_normal_(l.weight, torch.nn.init.calculate_gain("selu")) b = getattr(F, 'selu')(l(b)) if i % 10 == 0: print (f"out: {b.std().item():.4f}", end=" ") a.grad = None b.sum().backward(retain_graph=True) print (f"grad: {a.grad.abs().mean().item():.4f}") ``` Output: ``` in: 1.0008 out: 0.7968 grad: 0.6509 out: 0.3127 grad: 0.2760 out: 0.2404 grad: 0.2337 out: 0.2062 grad: 0.2039 out: 0.2056 grad: 0.1795 out: 0.2044 grad: 0.1977 out: 0.2005 grad: 0.2045 out: 0.2042 grad: 0.2273 out: 0.1944 grad: 0.2034 out: 0.2085 grad: 0.2464 ``` I included the necessary documentation change, and it passes the _test_calculate_gain_nonlinear_ unittest. Pull Request resolved: #50664 Reviewed By: mruberry Differential Revision: D25942217 Pulled By: ngimel fbshipit-source-id: 29ff1be25713484fa7c516df71b12fdaecfb9af8 -
[ROCm] re-enable test_sparse.py tests (#50557)
Summary: Signed-off-by: Kyle Chen <kylechen@amd.com> cc: jeffdaily Pull Request resolved: #50557 Reviewed By: mruberry Differential Revision: D25941432 Pulled By: ngimel fbshipit-source-id: 534fc8a91a48fa8b3b397e63423cd8347b41bbe2
-
[package] Properly demangle all accesses of
__name__in importer.py (… -
[pytorch] clean up unused util srcs under tools/autograd (#50611)
Summary: Pull Request resolved: #50611 Removed the unused old-style code to prevent it from being used. Added all autograd/gen_pyi sources to mypy-strict.ini config. Confirmed byte-for-byte compatible with the old codegen: ``` Run it before and after this PR: .jenkins/pytorch/codegen-test.sh <baseline_output_dir> .jenkins/pytorch/codegen-test.sh <test_output_dir> Then run diff to compare the generated files: diff -Naur <baseline_output_dir> <test_output_dir> ``` Confirmed clean mypy-strict run: ``` mypy --config mypy-strict.ini ``` Test Plan: Imported from OSS Reviewed By: ezyang Differential Revision: D25929730 Pulled By: ljk53 fbshipit-source-id: 1fc94436fd4a6b9b368ee0736e99bfb3c01d38ef
-
-
Automated submodule update: tensorpipe (#50684)
Summary: This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe). New submodule commit: pytorch/tensorpipe@eabfe52 Pull Request resolved: #50684 Test Plan: Ensure that CI jobs succeed on GitHub before landing. Reviewed By: lw Differential Revision: D25944553 fbshipit-source-id: e2bbcc48472cd79df89d87a0e61dcffa783c659d
-
[testing] Port
torch.{repeat, tile}tests to use OpInfo machinery (#… -
Add batched grad testing to gradcheck, turn it on in test_autograd (#…
…50592) Summary: Pull Request resolved: #50592 This adds a `check_batched_grad=False` option to gradcheck and gradgradcheck. It defaults to False because gradcheck is a public API and I don't want to break any existing non-pytorch users of gradcheck. This: - runs grad twice with two grad outputs, a & b - runs a vmapped grad with torch.stack([a, b]) - compares the results of the above against each other. Furthermore: - `check_batched_grad=True` is set to be the default for gradcheck/gradgradcheck inside of test_autograd.py. This is done by reassigning to the gradcheck object inside test_autograd - I manually added `check_batched_grad=False` to gradcheck instances that don't support batched grad. - I added a denylist for operations that don't support batched grad. Question: - Should we have a testing only gradcheck (e.g., torch.testing.gradcheck) that has different defaults from our public API, torch.autograd.gradcheck? Future: - The future plan for this is to repeat the above for test_nn.py (the autogenerated test will require a denylist) - Finally, we can repeat the above for all pytorch test files that use gradcheck. Test Plan: - run tests Reviewed By: albanD Differential Revision: D25925942 Pulled By: zou3519 fbshipit-source-id: 4803c389953469d0bacb285774c895009059522f
-
Summary: This PR adds `torch.linalg.slogdet`. Changes compared to the original torch.slogdet: - Complex input now works as in NumPy - Added out= variant (allocates temporary and makes a copy for now) - Updated `slogdet_backward` to work with complex input Ref. #42666 Pull Request resolved: #49194 Reviewed By: VitalyFedyunin Differential Revision: D25916959 Pulled By: mruberry fbshipit-source-id: cf9be8c5c044870200dcce38be48cd0d10e61a48
-
Adding missing decorator for test_device_map_gpu_mixed_self_4 (#50732)
Summary: Pull Request resolved: #50732 Test Plan: Imported from OSS Reviewed By: beauby Differential Revision: D25954041 Pulled By: mrshenli fbshipit-source-id: b2eeb1a77753cb8696613bfdc7bbc5001ae4c972
-
Add complex support for
torch.{acosh, asinh, atanh}(#50387)Summary: Pull Request resolved: #50387 Test Plan: Imported from OSS Reviewed By: heitorschueroff Differential Revision: D25947496 Pulled By: anjali411 fbshipit-source-id: c70886a73378501421ff94cdc0dc737f1738bf6f
-
Add instructional error message for cudnn RNN double backward workaro…
…und (#33884) Summary: Pull Request resolved: #33884 Mitigates #5261. It's not possible for us to support cudnn RNN double backwards due to limitations in the cudnn API. This PR makes it so that we raise an error message if users try to get the double backward on a cudnn RNN; in the error message we suggest using the non-cudnn RNN. Test Plan: - added some tests to check the error message Reviewed By: albanD Differential Revision: D20143544 Pulled By: zou3519 fbshipit-source-id: c2e49b3d8bdb9b34b561f006150e4c7551a78fac
-
Striding for lists Part 1 (#48719)
Summary: Pull Request resolved: #48719 Attempt to break this PR (#33019) into two parts. As per our discussion with eellison, the first part is to make sure our aten::slice operator take optional parameters for begin/step/end. This will help with refactoring ir_emitter.cpp for genering handling for list and slice striding. Once this PR merged, we will submit a second PR with compiler change. Test Plan: None for this PR, but new tests will be added for the second part. Imported from OSS Reviewed By: jamesr66a Differential Revision: D25929902 fbshipit-source-id: 5385df04e6d61ded0699b09bbfec6691396b56c3
-
Consolidate mypy tests and args (#50631)
Summary: This PR helps with #50513 by reducing the complexity of our `mypy` test suite and making it easier to reproduce on the command line. Previously, to reproduce how `mypy` was actually run on tracked source files (ignoring the doctest typechecking) in CI, you technically needed to run 9 different commands with various arguments: ``` $ mypy --cache-dir=.mypy_cache/normal --check-untyped-defs --follow-imports silent $ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/module_list.py $ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/namedtuple.py $ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/opt_size.py $ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/size.py $ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/tensor_copy.py $ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/torch_cuda_random.py $ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/torch_optim.py $ mypy --cache-dir=.mypy_cache/strict --config mypy-strict.ini ``` Now you only have to run 2 much simpler commands: ``` $ mypy $ mypy --config mypy-strict.ini ``` One reason this is useful is because it will make it easier to integrate PyTorch's `mypy` setup into editors (remaining work on this to be done in a followup PR). Also, as shown in the test plan, this also reduces the time it takes to run `test/test_type_hints.py` incrementally, by reducing the number of times `mypy` is invoked while still checking the same set of files with the same configs. (Because this PR merges `test_type_hint_examples` (added in #34595) into `test_run_mypy` (added in #36584), I've added some people involved in those PRs as reviewers, in case there's a specific reason they weren't combined in the first place.) Pull Request resolved: #50631 Test Plan: Run this twice (the first time is to warm the cache): ``` $ python test/test_type_hints.py -v ``` - *Before:* ``` test_doc_examples (__main__.TestTypeHints) Run documentation examples through mypy. ... ok test_run_mypy (__main__.TestTypeHints) Runs mypy over all files specified in mypy.ini ... ok test_run_mypy_strict (__main__.TestTypeHints) Runs mypy over all files specified in mypy-strict.ini ... ok test_type_hint_examples (__main__.TestTypeHints) Runs mypy over all the test examples present in ... ok ---------------------------------------------------------------------- Ran 4 tests in 5.090s OK ``` You can also just run `mypy` to see how many files it checks: ``` $ mypy --cache-dir=.mypy_cache/normal --check-untyped-defs --follow-imports silent Success: no issues found in 1192 source files ``` - *After:* ``` test_doc_examples (__main__.TestTypeHints) Run documentation examples through mypy. ... ok test_run_mypy (__main__.TestTypeHints) Runs mypy over all files specified in mypy.ini ... ok test_run_mypy_strict (__main__.TestTypeHints) Runs mypy over all files specified in mypy-strict.ini ... ok ---------------------------------------------------------------------- Ran 3 tests in 2.404s OK ``` Now `mypy` checks 7 more files, which is the number in `test/type_hint_tests`: ``` $ mypy Success: no issues found in 1199 source files ``` Reviewed By: zou3519 Differential Revision: D25932660 Pulled By: samestep fbshipit-source-id: 26c6f00f338e7b44954e5ed89522ce24e2fdc5f0
-
Clean up complex autograd test list (#50615)
Summary: Pull Request resolved: #50615 The method tests for some of the ops have been ported to the new OpInfo based tests. This PR removes those op names from `complex_list` in `test_autograd.py` Test Plan: Imported from OSS Reviewed By: mruberry Differential Revision: D25931268 Pulled By: anjali411 fbshipit-source-id: 4d08626431c61c34cdca18044933e4f5b9b25232